R語言(一)
自我介紹
什麼是 R 語言?
R 是一種專門用來進行統計分析與資料處理的程式語言。它免費、開源,擁有大量專門針對數據分析、圖表視覺化與統計建模的套件,因此被廣泛應用於學術研究、商業分析、生物醫學、金融等領域。R 語言的特色是語法靈活、功能完整,特別適合做報告、分析資料或建立統計模型。透過 R我們可以快速處理數據、計算統計量,並繪製出專業又美觀的圖表。如果你對資料有興趣,或是未來想從事資料科學、商業分析、研究報告等工作,R 會是非常實用的工具。
(-from chatgpt)
為什麼要學 R?
R 可以幫你:
- 整理數據 📂
- 畫出圖表 📈
- 做出報告 📄
- 發現趨勢 🔍
安裝
本地編譯器
R、Rstudio : RStudio 是一個專門用來寫 R 的整合開發環境(IDE)

線上版
Posit Cloud (原 RStudio Cloud) :
- 官方提供的雲端版 RStudio 可直接執行 R 程式、畫圖、做報告
- 完整 RStudio IDE,支援 R Markdown、R Notebook、套件
- 安裝免費有空間限制,但對教學、專案最友善
-
免費帳號有 15 小時/月計算時間
💻步驟二:建立第一個 RStudio 專案
-
登入後點選
New Project→New RStudio Project -
等待數秒,系統會自動幫你開啟 RStudio
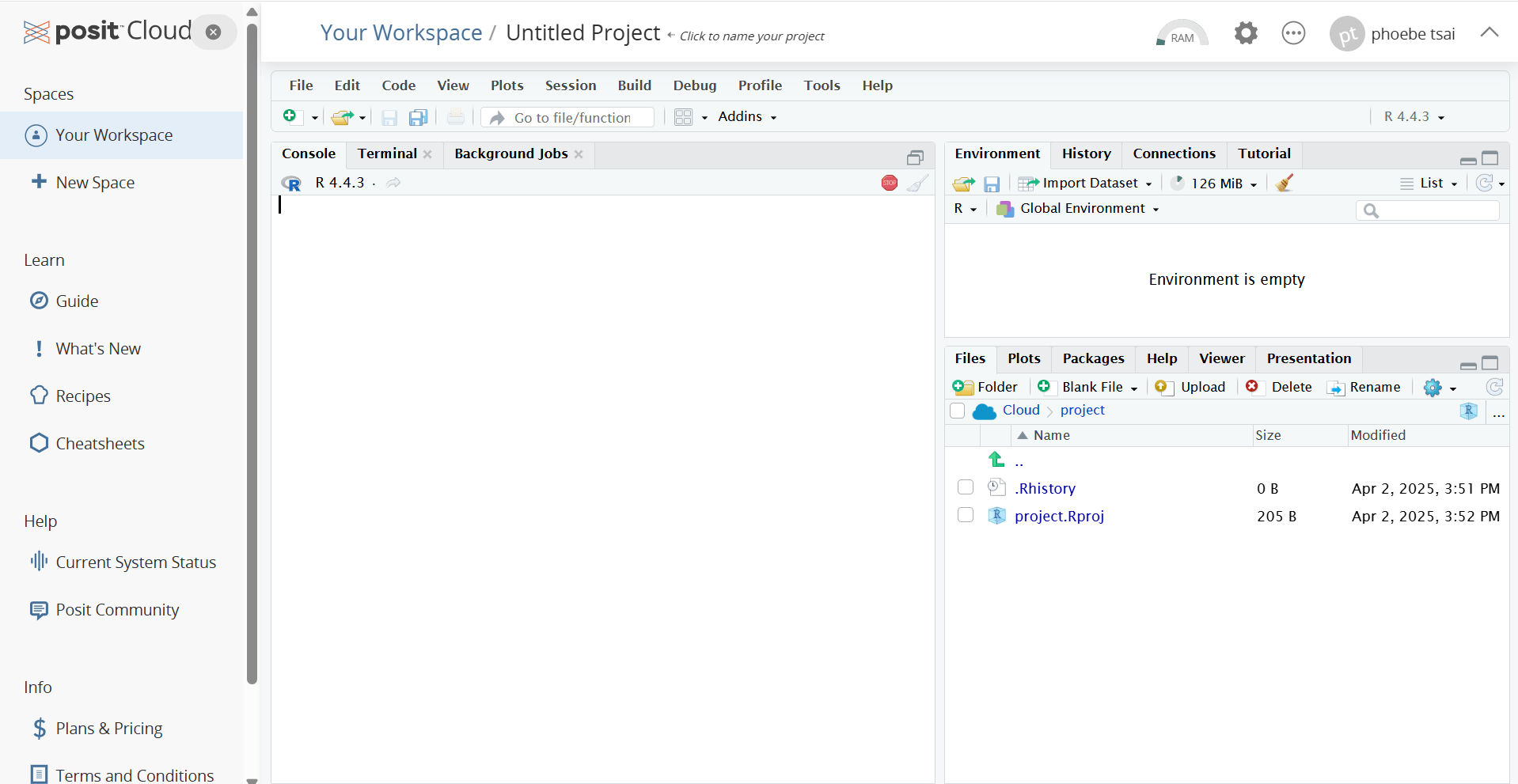
💻 步驟三:認識線上 RStudio 介面
① Script(左上):程式編輯區
寫 R 程式碼的地方可儲存為 .R 或 .Rmd 檔
適合寫多行程式、分析步驟、報告
(快捷鍵:Ctrl + Enter 執行選取的程式碼)
💻 步驟三:認識線上 RStudio 介面
② Console(左下):指令執行區
R 語言的互動命令列
可以直接輸入程式碼,立刻看到結果
適合快速測試、即時執行
💻 步驟三:認識線上 RStudio 介面
③ Environment / History(右上):變數與紀錄區
Environment:列出目前建立的變數與資料
History:記錄你輸入過的所有指令
可直接點選變數檢視內容、清除或重新執行變數
💻 步驟三:認識線上 RStudio 介面
④ Files / Plots / Packages / Help(右下):輔助功能區
Files:檔案總管
Plots:圖表顯示區
Packages:安裝、載入套件
Help:查詢說明文件(?mean)
💻 步驟四:寫下第一行 R 程式
print("Hello R World!")💻 步驟五:建立 R 腳本(.R 檔)
-
點選左上角
File → New File → R Script -
在編輯區寫入:
x <- c(1, 2, 3, 4, 5)
mean(x)💻 步驟六:安裝套件
install.packages("tidyverse")
library(tidyverse)
R Markdown
&
R Notebook
| 標題 |
# 大標題## 中標題### 小標題
|
建立標題,類似 word 標題層級 |
| 粗體 | **文字** |
粗體字 |
| 斜體 | *文字* |
斜體字 |
| 有序清單 |
1. 項目12. 項目2
|
編號清單 |
| 無序清單 |
- 項目1- 項目2
|
圓點清單 |
| 公式 |
$y = mx + b$ (行內)$$E=mc^2$$ (置中) |
LaTeX 公式 |
| 插入圖片 |  |
插入圖片 |
| 超連結 | [文字](網址) |
建立超連結 |
| 區塊引用 | > 引用內容 |
顯示引用文字 |
| 程式區塊 |
```{r}R程式碼 ```
|
程式碼區塊 (Chunk) |
| 表格 | ` | 欄1 |
| 分隔線 | --- |
水平分隔線 |
R Markdown vs R Notebook
| 特點R | MarkdownR | Notebook |
|---|---|---|
| 是否即時執行 | ❌ | ✅ |
| 適合 | 最終報告、論文 | 平時做筆記、互動教學 |
| 產出 | pdf, html, word | Notebook 互動文件或轉成 Markdown 報告 |
| 常見用法 | 論文、專題報告 | 實驗記錄、課堂互動筆記 |
# 📘 R 語言介紹與應用(教案簡報內容)
## 🧠 R 是什麼?
R 是一種專門用來進行「統計分析與資料處理」的程式語言。
- 免費、開源,可自由擴充
- 擅長數據分析、圖表視覺化、模型建構
- 全球學術界與資料分析師廣泛使用
## ✨ R 的特色
- 免費開源,自由使用與擴充
- 有數千個套件支援統計、圖表、機器學習等
- 搭配 RStudio 使用體驗更佳
- 支援 R Markdown 報告與互動教學
- 適合學生與非資工背景學習
## 📦 R 常見應用範圍
- 🎓 教育與學術:統計推論、回歸分析、論文報表
- 📊 商業分析:顧客行為分析、視覺化報表
- 🧬 生物醫學:基因資料、生存分析、臨床統計
- 🏦 金融應用:股票分析、風險管理、回測模型
- 🤖 資料科學與機器學習:模型建立與預測
## 🧪 R 語法範例
```r
# 建立向量
scores <- c(80, 90, 70, 100)
# 計算平均
mean(scores)
# 繪製直方圖
hist(scores, main = "分數分布圖", col = "lightblue")
R 基本語法與資料型態
向量 (Vectors)
向量是 R 語言中最基本的資料結構,用來儲存一維資料的變數類型。
數值numeric
整數integer
邏輯logical
文字character
日期date
日期時間POSIXct
*單一類型
a=100
class(a)
a=100L
class(a)
a=FALSE
class(a)
a="hello"
class(a)
a=Sys.Date()
class(a)
a
as.numeric(a)
a=Sys.time()
a
is.numeric(a)向量類型
class()
is.numeric()
as.numeric()
數值numeric
整數integer
邏輯logical
文字character
日期date
日期時間POSIXct
- c() (combine) : 將類別相同的元素合併同一個向量
- length() : 向量長度
- rep(物件, 重複次數)
- 1 %in% a : 檢查
1是不是在向量a裡面,會回傳TRUE或FALSE - 中括號[ ]
a <- c(1,5.3,6,-2)
a
length(a)
rep(a, 3)
seq(1, 5, 2)
1 %in% aa = c(1, 3, 5, 7, 9, 11)
a[1]
a[1:3]
a[a>8|a<2]運算子
| 加 | + |
| 減 | - |
| 乘 | * |
| 除 | / |
| 商數 | %/% |
| 餘數 | %% |
| ! | 否 |
| 小於 |
< |
|---|---|
| 大於 | > |
| 等於 | == |
| 不等於 | != |
| 且 | & |
向量中每個元素個別比較 |
|---|---|---|
| && | 單一元素比較 | |
| 或 | || | |
| | |
x <- c(TRUE, FALSE, TRUE)
y <- c(TRUE, TRUE, FALSE)
x & y
x[1] && y[1]
較複雜的資料結構
- 清單 list
- 陣列 array
- 因素 factor
- 矩陣 matrix
- 資料框架 dataframe
1. 清單 list
列表 (list) 跟向量很相似,但最大的不同在於列表可以包含不同資料屬性的資料。
# Create a list.
list1 <- list(c(2,5,3), 21.3, sin)
# Print the list.
print(list1)
# Create list and asign variable names.
list2 <- list(vector = c(2,5,3),
numeric = 21.3,
func = sin)
# Print names of list and list itself.
names(list2)
print(list2)
2.陣列 array
array 是 可以延伸超過 2 維的資料結構,本質上是「多維矩陣」。
# array(data, dim = c(列, 欄, 頁))
a <- array(1:12, dim = c(3, 2, 2))
print(a)
a[1, 2, 1] # 第一頁、第一列、第二欄 → 取出 4
a[,,2] # 第二頁整張矩陣
3.因素 factor
R 的因子(factor)變數是專門用來儲存類別資料的變數,它同時具有字串與整數的特性,主要以向量 (vector) 的形式呈現。在因子 物件中,會儲存:
(1) 所有不重複的數值作為標籤 (labels),會被當成字串 (character)(2) 每一個元素對應到的標籤。
# Create a vector.
apple_colors <- c('green','green','yellow','red','red','red','green')
# Create a factor object.
factor_apple <- factor(apple_colors)
# Print the factor.
print(factor_apple)
print(nlevels(factor_apple))4. matrix 矩陣
R 中的矩陣 (matrix) 用來儲存二維資料,可以透過 matrix 函數填入向量得到。
# Create a matrix.
M <- matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3)
print(M)
# Create a matrix and fill in by row.
M <- matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
print(M)- A * B:矩陣 A 與 矩陣 B 的元素間倆倆相乘
- A %*% B:矩陣乘法 A⋅B
- t(A):轉置矩陣 AT
- solve(A):矩陣 A 的反矩陣
5. dataframe 資料框架
「資料框架」(Data Frame) 作為R最常見的資料型態。一個資料框架具備以下兩個原則:
Rows:通常代表的是個體 / 觀察對象
Columns:通常是變數
name <- c("David", "Hsi", "Jessie")
age <- c("24", "25", "36")
gender <- c("Male", "Male", "Female")
# Create by variables
data1 <- data.frame(name, age, gender)
data1
data2 <- data.frame(
name = c("David", "Hsi", "Jessie"),
age = c("24", "25", "36"),
gender = c("Male", "Male", "Female")
)
data2
head(data2)
colnames(data2) <- c("Var_1", "Var_2","Var_3")
rownames(data2) <- c("1", "2", "3")
data2
summary(data2)
#head:取得資料框架前六比資料(預設是 6)。
#tail:取得資料框架後六比資料(預設是 6)。
#colnames:修改或查詢 column 名稱。
#rownames:設定 row 的名稱
#summary:顯示資料基本資訊。
#dim:回傳資料物件的維度(列數, 欄數)tibble
tibble 是 data.frame 的升級版,讓你更容易讀、更安全地處理資料,在 tidyverse 中幾乎都是用 tibble。
library(tibble)
# 建立 tibble
tb <- tibble(
name = c("Amy", "Ben", "Cindy"),
score = c(90, 85, 88)
)
tb
#data.frame 和 tibble 互轉
df <- as.data.frame(tb) # 將 tibble 轉為 data.frame
tb2 <- as_tibble(df) # 將 data.frame 轉為 tibble
資料結構的常用函數
- length(object) : 元素個素
- unique(object) : 該物件的獨立元素
- str(object) : 輸出該物件的基本架構
- class(object) : 該物件屬於哪種資料結構
- names(object) : 物件中元素的名稱
- c(object,object,...) : 將物件合併為一個向量
- object : 印出物件
- rm(object) : 從工作空間中移除物件
x <- c(1, 1, 2, 2, 3, 3, 4, 4)
length(x)
unique(x)
data2 <- data.frame(
name = c("David", "Hsi", "Jessie", "David", "Hsi"),
age = c("24", "25", "36", "24", "30"),
gender = c("Male", "Male", "Female", "Male", "Male")
)
data2
unique(data2)
str(data2)
class(data2)
names(data2)
題目練習
題目 1:學生成績表
請建立一個 data.frame 包含以下欄位:
name:c("Amy", "Ben", "Cindy", "David")
score:c(88, 76, 92, 60)
顯示所有 score 大於 80 的學生
顯示分數小於 90 且大於等於 60 的學生
新增一欄位 pass,若分數 >= 60 則為 TRUE,否則為 FALSE
題目練習
題目 2:銷售紀錄陣列(array + 索引)
建立一個 3 維的 array,表示三位銷售員(A, B, C)在兩個月份(Jan, Feb)中,針對兩項商品(P1, P2)的銷售數量:
sales <- array(1:12, dim = c(3, 2, 2)) # 3人 × 2品項 × 2月份
1.顯示 1 月份的完整資料(也就是第 1 頁)
2.取出 C 員工在 2 月份 P2 商品的銷售量
3.計算整體銷售總和 sum(sales)
4.查出資料的維度
題目練習
題目 3:邏輯條件過濾 + 結構判斷
顯示所有庫存中(
in_stock == TRUE)且價格小於 150 的商品顯示
df的列數與欄數顯示
df的欄位名稱判斷
df$price是否為數值型態(使用is.numeric())
df <- data.frame(
product = c("A", "B", "C", "D"),
price = c(150, 80, 120, 200),
in_stock = c(TRUE, FALSE, TRUE, TRUE)
)df <- data.frame(
name = c("Amy", "Ben", "Cindy", "David"),
score = c(88, 76, 92, 60)
)
df[df$score > 80, ]
df[df$score >= 60 & df$score < 90, ]
df$pass <- df$score >= 60
sales <- array(1:12, dim = c(3, 2, 2))
sales[, , 1]
sales[3, 2, 2]
sum(sales)
dim(sales)
df <- data.frame(
product = c("A", "B", "C", "D"),
price = c(150, 80, 120, 200),
in_stock = c(TRUE, FALSE, TRUE, TRUE)
)
df[df$in_stock & df$price < 150, ]
nrow(df)
ncol(df)
names(df)
is.numeric(df$price)
答
案
自訂函數
函數可以避免複製大量重複的程式碼,並且讓其他使用者可以使用你設計的函數。一個函數的組成包含三個重要部分:
-輸入變數x(可以有很多個)
-輸出變數y
-運算程式碼
f <- function(x){ 運算程式碼; return(y) }
df <- data.frame(
a = rnorm(10), # Generate 10 standard normal random numbers
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
df$a <- (df$a - min(df$a, na.rm = TRUE)) /
(max(df$a, na.rm = TRUE) - min(df$a, na.rm = TRUE))
df$b <- (df$b - min(df$b, na.rm = TRUE)) /
(max(df$b, na.rm = TRUE) - min(df$a, na.rm = TRUE))
df$c <- (df$c - min(df$c, na.rm = TRUE)) /
(max(df$c, na.rm = TRUE) - min(df$c, na.rm = TRUE))
df$d <- (df$d - min(df$d, na.rm = TRUE)) /
(max(df$d, na.rm = TRUE) - min(df$d, na.rm = TRUE))對於一個資料框架的四個變數將原本的尺度轉換到 0-1 之間

建立一個使用者函數時會包含三個部分:
1. 命名一個函數
2. 決定函數的 input (Args) 與 output
3. variables 可以寫成 function(x, y, z)。
開發函數主體的運算程式碼
df <- data.frame(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
RescaleByRange <- function(x){
rng <- range(x, na.rm = TRUE)
return((x - rng[1]) / (rng[2] - rng[1]))
}
RescaleByRange(df$a)
練習題
撰寫一個名為 SummarizeData 的函數,回傳輸入向量的平均值 (mean)、變異數 (var)、最大值 (max)、最小值 (min)、與中位數 (median)。
SummarizeData <- function(x){
summary.df <- data.frame(x_mean = mean(x, na.rm = TRUE),
x_var = var(x, na.rm = TRUE),
x_max = max(x, na.rm = TRUE),
x_min = min(x, na.rm = TRUE),
x_median = median(x, na.rm = TRUE))
return(summary.df)
}
SummarizeData(rnorm(10))deck
By phoebe tsai



