R語言(6)
基本作圖
R base graphics 內建繪圖系統 (不需要額外安裝套件)
| 比較項目 | Base R | ggplot2 |
|---|---|---|
| 難度 | 簡單直觀 | 需學習語法結構與語意 |
| 使用方式 | 函數式語法如 plot(x, y)
|
建構式語法,如 ggplot(data, aes(...)) +
|
| 圖層控制 | 單層為主,較難重疊多層 | 可疊加多圖層(layer),如 + geom_point()
|
| 資料結構需求 | 吃向量、matrix、list 皆可 | 通常需要 data.frame 或 tibble 格式 |
| 適合對象 | 初學者、簡單快速產圖 | 中高階使用者、報告美化、資料探索 |
因為R偏實際操作,它有很多工具函示包含美編或細節處理可以,所以會有點雜可能要花一點時間摸索,加油啊:)
library(tibble)
coffee_data <- tibble(
week = 1:10,
coffee_sold = c(80, 175, 150, 150, 100, 175, 90, 100, 130, 200),
avg_temp = c(18, 20, 22, 23, 25, 27, 28, 30, 29, 31),
drink_type = rep(c("拿鐵", "美式", "摩卡", "拿鐵", "美式"), 2),
store = rep(c("A店", "B店"), 5)
)
以 咖啡店營運數據 作為範例
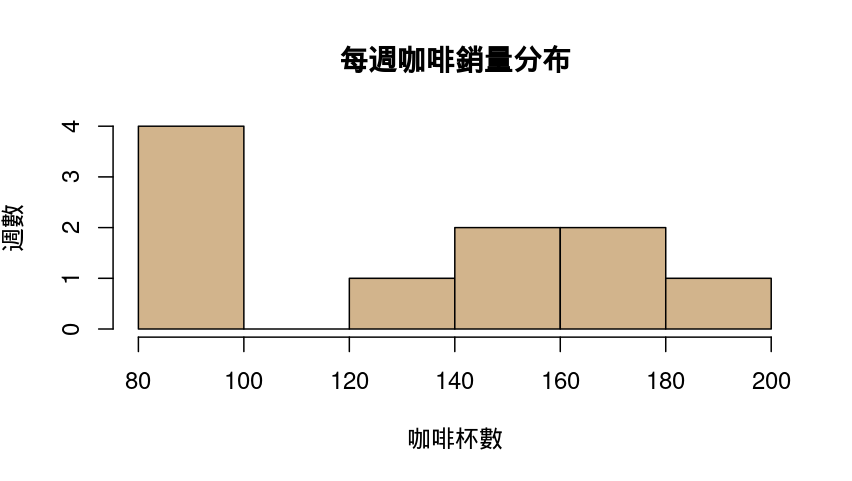
1. 直方圖 Histogram : 查看「數值型變數」的分布情況 (頻率)
hist(coffee_data$coffee_sold, col = "tan", main = "每週咖啡銷量分布",
xlab = "咖啡杯數", ylab = "週數")| 程式 | 說明 |
hist(...) |
呼叫R的內建函數 hist()用來畫直方圖
|
| coffee_data$coffee_sold | 告訴 hist() 要畫哪筆資料: coffee_data 資料表中的 coffee_sold 欄位,即「每週咖啡銷售杯數」 |
col = "tan" |
把柱子的顏色設為「淺棕色」,這個顏色可以換成其他如 "blue", "pink", "lightgreen" 等 |
| main = "每週咖啡銷量分布" | 設定整張圖的標題為這段文字 |
| xlab = "咖啡杯數" | 設定 X 軸的標籤文字 |
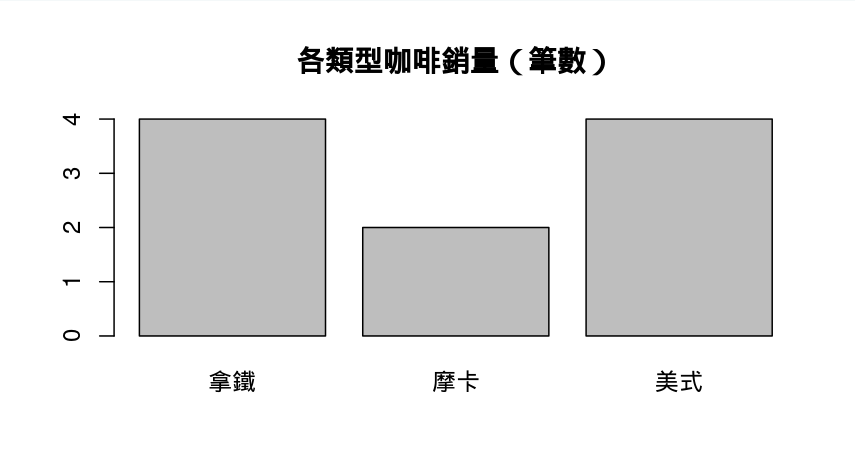
2. 長條圖 Barplot:查看「分類型變數」的類別個數
barplot(table(coffee_data$drink_type), main = "各類型咖啡銷量(筆數)")
| 程式 | 說明 |
barplot(...) |
R base 的長條圖函數,用來畫已經整理好的資料 |
table() |
table() 回傳一個命名好的向量,例如 : 拿鐵:2, 美式:2, 摩卡:2... |
table(coffee_data$drink_type) |
先把 drink_type 這欄資料統計各類型出現次數 |
main = "各類型咖啡銷量(筆數)" |
設定圖的標題會顯示在圖的最上方 |
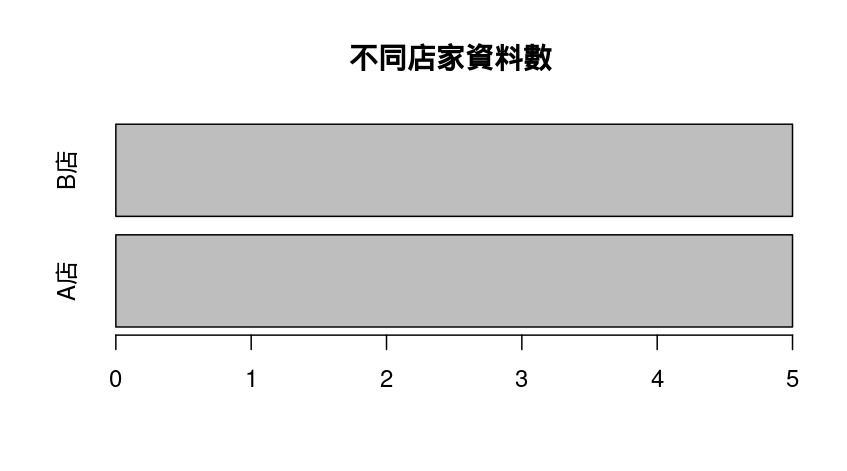
3. 水平長條圖 Barplot : 功能同上只是橫向呈現,有時更適合文字較長的分類
barplot(table(coffee_data$store), horiz = TRUE, main = "不同店家資料數")
| 程式 | 說明 |
horiz = TRUE |
把長條圖轉為「橫向」排列。 |
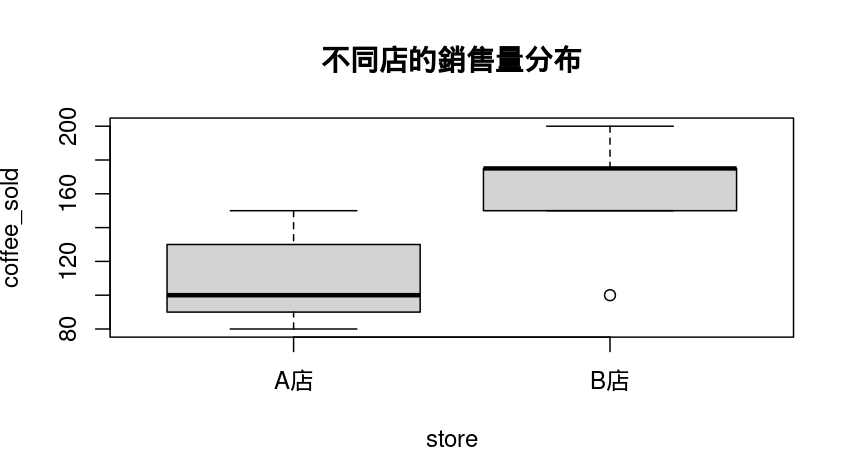
4. 盒狀圖 Boxplot : 查看數值資料在不同分類下的分布情況。可以看出中位數、上下四分位數、異常值。
boxplot(coffee_sold ~ store, data = coffee_data, main = "不同店的銷售量分布")| 程式 | 說明 |
boxplot(...) |
畫出盒狀圖(Boxplot)用來呈現資料的分布情況 |
coffee_sold ~ store |
公式語法,意思是:將 coffee_sold 的資料按照 store 的類別來分組比較。 這是 R 中常見的公式格式: y ~ x(y 對 x) |
data = coffee_data |
指資料都是來自 coffee_data 這張資料表 |
main = "不同店的銷售量分布" |
設定圖表標題,顯示在圖的上方 |
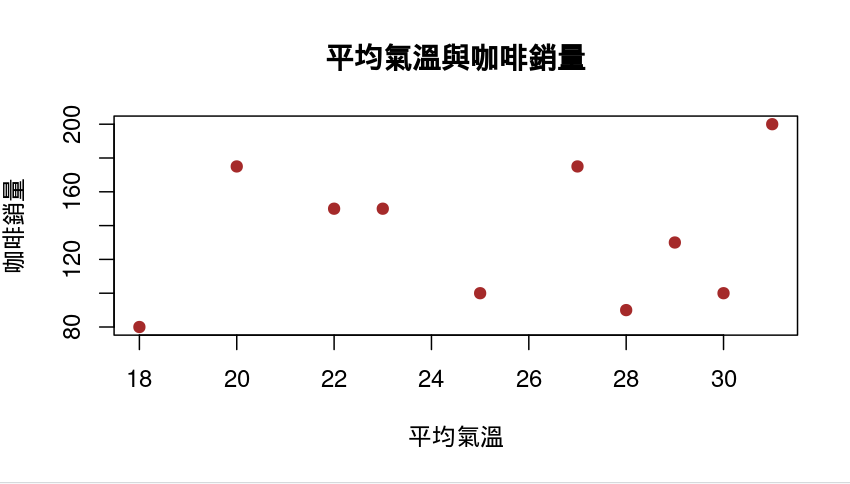
5. 散佈圖 Scatterplot: 觀察兩個數值變數間是否有關聯性
plot(coffee_data$avg_temp, coffee_data$coffee_sold,
main = "平均氣溫與咖啡銷量", xlab = "平均氣溫", ylab = "咖啡銷量", col = "brown", pch = 19)
| 程式 | 說明 |
plot(...) |
R base的繪圖函數(萬用型) 可畫散點圖、折線圖等 |
coffee_data$avg_temp |
X 軸資料:每週的平均氣溫 |
coffee_data$coffee_sold |
Y 軸資料:每週的咖啡銷量 |
main = "平均氣溫與咖啡銷量" |
圖表標題,顯示在最上面 |
xlab = "平均氣溫" |
X 軸標籤:說明 X 軸代表的是什麼 |
ylab = "咖啡銷量" |
Y 軸標籤:說明 Y 軸代表的是什麼 |
col = "brown" |
點的顏色設定為棕色(可用 "blue"、"red" 等替換) |
pch = 19 |
點的樣式,19 是實心圓點;1 是空心圓,2 是三角形...等 |
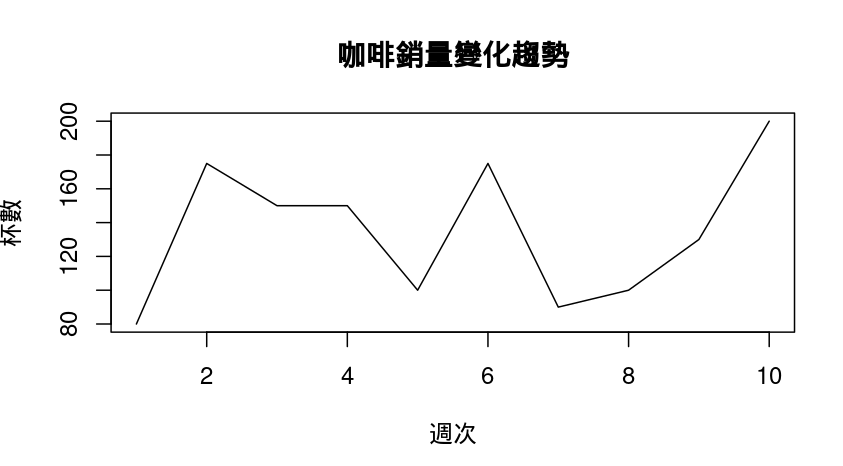
6. 折線圖 Line plot(呈現數值變化): 看連續數值的變化趨勢,常用在時間序列或函數圖形。
plot(coffee_data$week, coffee_data$coffee_sold, type = "l",
main = "咖啡銷量變化趨勢", xlab = "週次", ylab = "杯數")
| 程式 | 說明 |
plot(...) |
R base的繪圖函數(萬用型) 可畫散點圖、折線圖等 |
coffee_data$week |
X 軸資料:週次,代表時間的流動 |
coffee_data$coffee_sold |
Y 軸資料:銷量(杯數) |
main = "咖啡銷量變化趨勢" |
圖表標題,顯示在最上面 |
type = "l" |
1 = line,代表「畫折線」 若不加這行預設畫散點圖 |
xlab = "週次" |
X 軸名稱 |
ylab = "杯數" |
Y 軸名稱 |
練習
果汁攤每週銷售紀錄 : 你經營一間果汁攤,記錄了 10 週以來不同類型果汁的銷售情況,包括週次、每週平均氣溫、果汁類型、銷量與攤位地點。可以依據下方資料自己練習看看~
library(tibble)
juice_data <- tibble(
week = 1:10,
juice_sold = c(100, 130, 110, 180, 150, 190, 160, 200, 170, 210),
avg_temp = c(20, 21, 23, 24, 25, 27, 29, 30, 28, 31),
juice_type = rep(c("柳橙", "葡萄柚", "蘋果", "柳橙", "葡萄柚"), 2),
stall = rep(c("東區攤", "西區攤"), 5)
)
plotly
酷東東!
plotly
什麼是 Plotly?
Plotly 是一個可以在 R 或 Python 中使用的互動式資料視覺化工具套件。
-
它不僅支援靜態圖,也可以讓你:
-
滑鼠移到圖上看到數值(hover tooltip)
-
點擊圖例篩選分類
-
放大、縮小、平移
-
-
在 R 中使用的是
plotly套件,能夠直接把 ggplot2 的圖「轉成互動版本」
python 也有
1. 搭配 ggplot2:最簡單
library(ggplot2)
library(plotly)
coffee_data <- tibble(
week = 1:10,
coffee_sold = c(80, 175, 150, 150, 100, 175, 90, 100, 130, 200),
avg_temp = c(18, 20, 22, 23, 25, 27, 28, 30, 29, 31),
drink_type = rep(c("拿鐵", "美式", "摩卡", "拿鐵", "美式"), 2),
store = rep(c("A店", "B店"), 5)
)
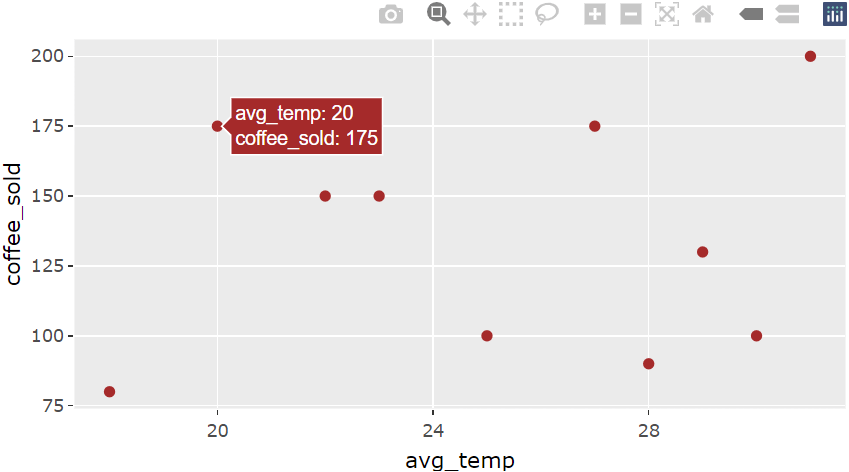
p <- ggplot(coffee_data, aes(x = avg_temp, y = coffee_sold)) +
geom_point(color = "brown")
ggplotly(p)
ggplot可以參考上一周的簡報,只要在 ggplot() 物件外面加上 ggplotly() 就能變成互動式圖表!
ps. 將鼠標碰點點就會有資料跑出來,或是選取捧個區塊就會放大, 點兩下可恢復原狀
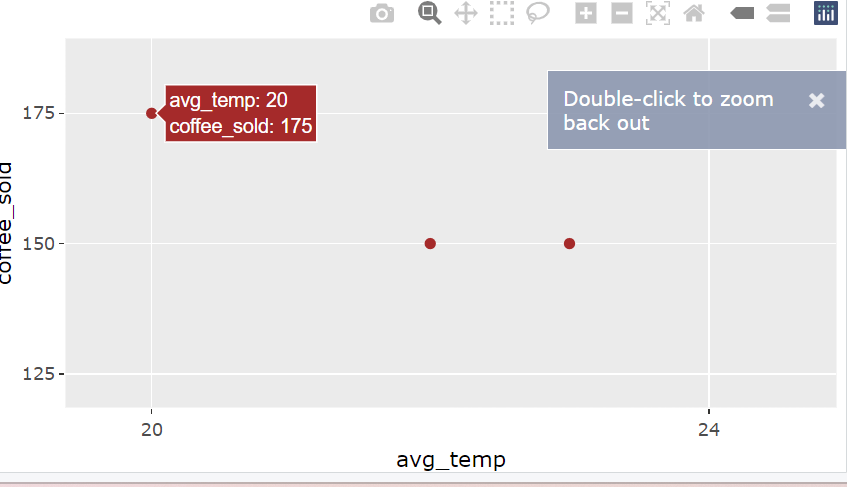
2. 原生語法(更自由): plot_ly() 是 plotly 套件中最核心的函數,可以從零開始建立一張圖表,比 ggplotly() 更靈活:
plot_ly(data = ..., x = ~..., y = ~..., type = ..., mode = ..., color = ~...)
| plot_ly() 參數 | 意思 | 類似 ggplot2 的什麼? |
|---|---|---|
| data = ... | 資料來源 | ggplot(data = ...) |
| x = ~欄位 | X 軸資料(前面要加 ~) | aes(x = ...) |
| y = ~欄位 | Y 軸資料 | aes(y = ...) |
| type = "..." | 圖表類型:scatter、bar、box、pie、line 等 | geom_point() 等 |
| mode = "..." | 圖表顯示樣式(限 scatter / line) | 不需特別寫ggplot 自動處理 |
| color = ~欄位 | 顏色依照哪個分類變數區分 | aes(color = ...) |
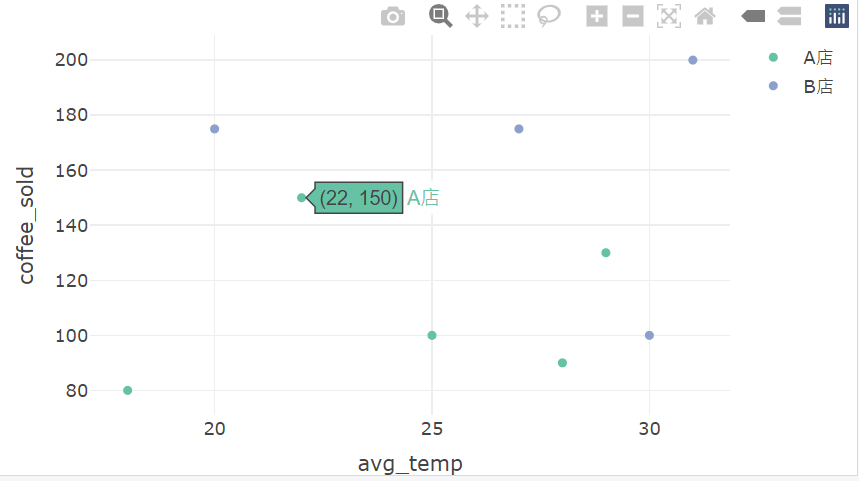
library(plotly)
plot_ly(data = coffee_data,
x = ~avg_temp,
y = ~coffee_sold,
type = 'scatter',
mode = 'markers',
color = ~store)
-
用
avg_temp當 X 軸(平均氣溫) -
用
coffee_sold當 Y 軸(銷量) -
用
store決定點的顏色(例如 A店 vs B店) -
滑鼠移上去會自動顯示點的所有資訊!
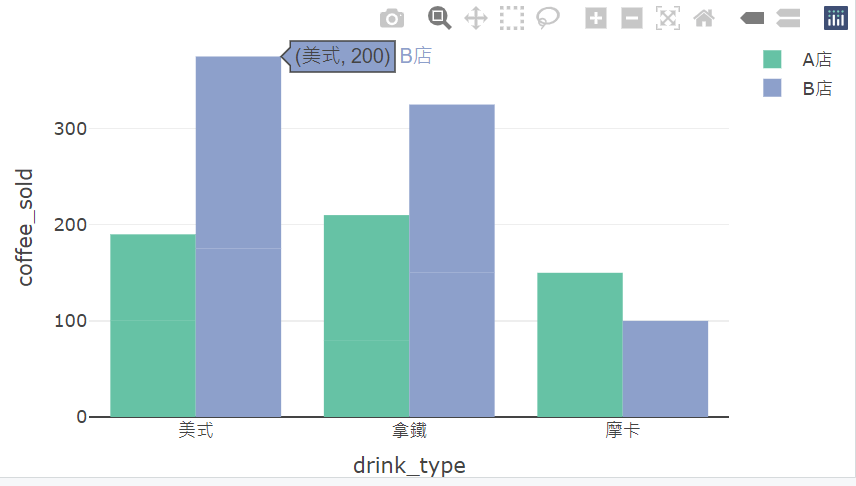
plot_ly(
data = coffee_data,
x = ~drink_type,
y = ~coffee_sold,
type = "bar",
color = ~store
)長條圖
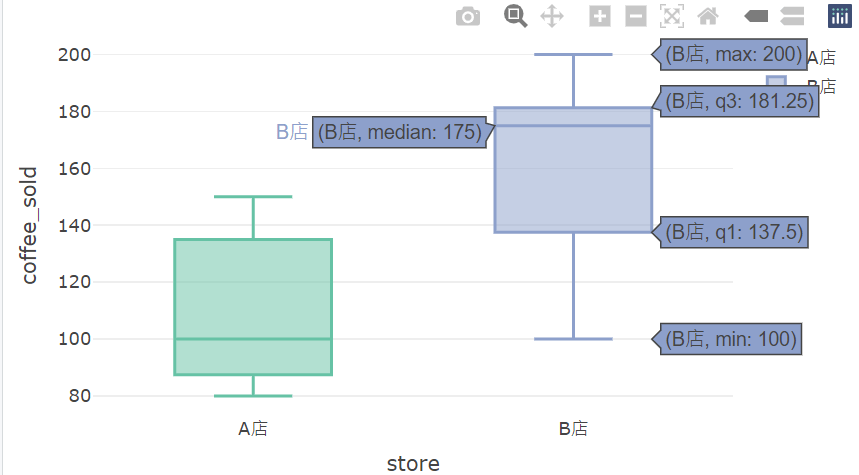
盒狀圖
plot_ly(
data = coffee_data,
x = ~store,
y = ~coffee_sold,
type = "box",
color = ~store
)
plot_ly(
data = coffee_data,
labels = ~drink_type,
values = ~coffee_sold,
type = "pie"
)圓餅圖
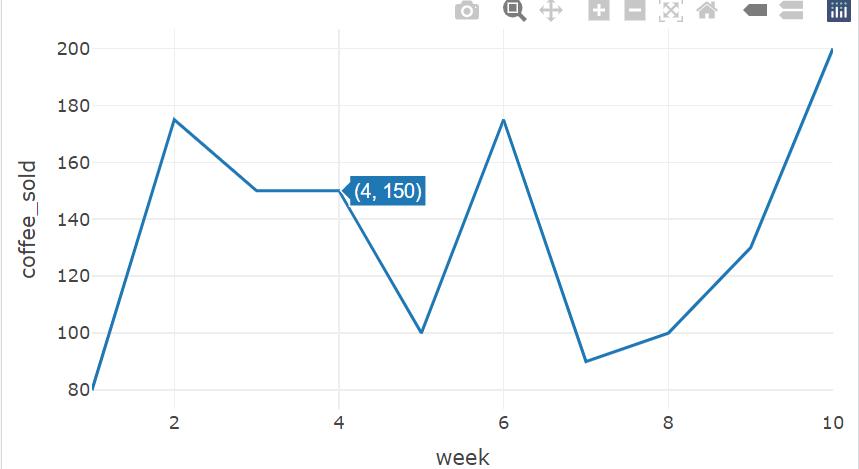
折線圖
plot_ly(
data = coffee_data,
x = ~week,
y = ~coffee_sold,
type = "scatter",
mode = "lines"
)
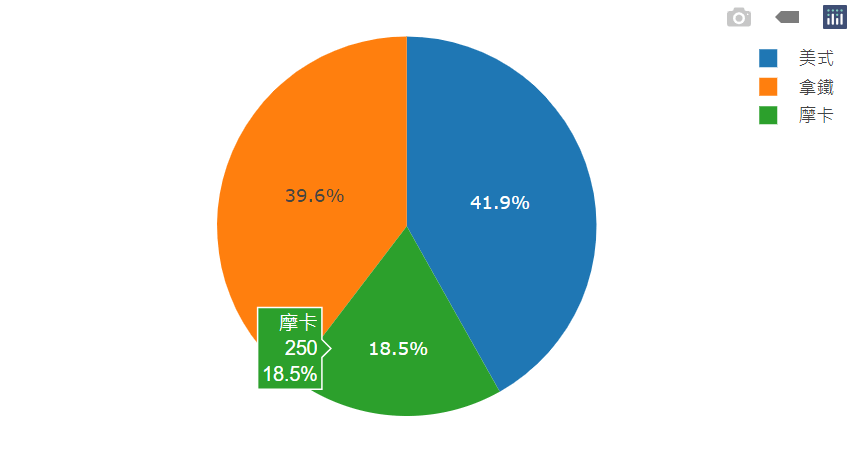
ps. pie 沒有 x 和 y,要用 labels 和 values
3D 作圖
plot_ly(
x = ..., # X 軸數據
y = ..., # Y 軸數據
z = ..., # Z 軸數據
type = "scatter3d",
mode = "markers"
)library(plotly)
plot_ly(
data = coffee_data,
x = ~week,
y = ~avg_temp,
z = ~coffee_sold,
type = "scatter3d",
mode = "markers"
)
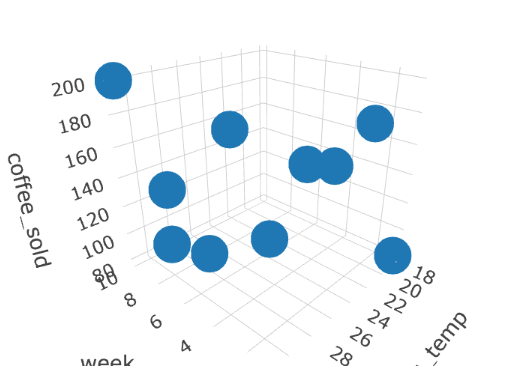
一樣的資料練習看看!!
概念都一樣
library(tibble)
juice_data <- tibble(
week = 1:10,
juice_sold = c(100, 130, 110, 180, 150, 190, 160, 200, 170, 210),
avg_temp = c(20, 21, 23, 24, 25, 27, 29, 30, 28, 31),
juice_type = rep(c("柳橙", "葡萄柚", "蘋果", "柳橙", "葡萄柚"), 2),
stall = rep(c("東區攤", "西區攤"), 5)
)
R語言(6)
By phoebe tsai



