R語言(2)
條件執行
如果(…){執行片段}
不然的話,如果(…){執行片段}
不然的話{執行片段}
x <- 1
if (x > 0) {
y <- 5
} else if (x <- 0){
y <- 0
} else {
y <- 10
}
yifelse() : 與 EXCEL 中的 if 函數用法一致
#ifelse(條件, 為TRUE時的結果, 為FALSE時的結果)
x <- c(-5, 0, 5)
y <- ifelse(x > 0, 5, 10)
y switch(): 執行指定名稱的程式片段
fruit <- "apple"
switch(fruit,
apple = "蘋果",
banana = "香蕉",
orange = "柳橙",
"沒有這個水果")
練習:
寫一段程式,根據以下分類規則,將一組學生分數分類為:
90 分以上 →「優秀」/ 60~89 分 →「及格」/ 60 分以下 →「不及格」
並將每個分數對應的分類結果儲存在新的向量中,最後輸出。
輸入 : scores <- c(95, 82, 60, 45, 100, 73, 58)
預期輸出 : "優秀" "及格" "及格" "不及格" "優秀" "及格" "不及格"
scores <- c(95, 82, 60, 45, 100, 73, 58)
# 分層 ifelse 巢狀邏輯
result <- ifelse(scores >= 90, "優秀",
ifelse(scores >= 60, "及格", "不及格"))
print(result)
迴圈控制
for() 迴圈
for (i in 1:5) {
cat(i)
}
#12345cat()(concatenate and print)是一個輸出函數也就是「連接並印出」。它會將多個輸出值合併成一行,然後直接印出(不含引號,也不自動換行)
for (i in 1:5) {
print(i)
}
#[1] 1
#[1] 2
#[1] 3
#[1] 4
#[1] 5cat("Hello", "world", "!\n")
for (str in c("R", "math", "sleeping")) {
cat(str, "is super interesting!\n")
}計數變數也可以是非數值變數
跳出迴圈
for (i in 1:10) {
if (i == 5) break
print(i)
}
- break : 當條件成立時,直接停止整個迴圈的執行
- next:跳過這次,繼續下一圈(類似 continue)
for (i in 1:5) {
if (i == 3) next
print(i)
}
巢狀 for() 迴圈
for (i in 1:4) {
for (j in 1:i^2) {
cat(j,"")
}
cat("\n")
}while() 迴圈
i <- 1
while(i < 5) {
i <- i + 1
cat(i, "\n")
}無限迴圈:
while(TRUE) 或 repeat
i <- 1
repeat {
print(i)
i <- i + 1
if (i > 5) break
}
周年慶活動要整理以下商品的庫存資料,根據下列條件進行篩選與輸出:如果某商品的 stock 為 0,使用 next 跳過該商品,如果某商品的 price 超過 45,使用 break 結束整個迴圈,其他符合條件的商品,輸出其名稱、價格與庫存。
products <- list(
apple = list(price = 30, stock = 50),
banana = list(price = 20, stock = 0),
milk = list(price = 50, stock = 10),
bread = list(price = 40, stock = 5),
eggs = list(price = 10, stock = 0)
)
練習:
輸出 : 商品名稱: apple 價格: 30 庫存: 50
products <- list(
apple = list(price = 30, stock = 50),
banana = list(price = 20, stock = 0),
milk = list(price = 50, stock = 10),
bread = list(price = 40, stock = 5),
eggs = list(price = 10, stock = 0)
)
for (name in names(products)) {
item <- products[[name]]
if (item$stock == 0) next
if (item$price > 45) break
cat("商品名稱:", name, "價格:", item$price, "庫存:", item$stock)
}
資料分析的流程
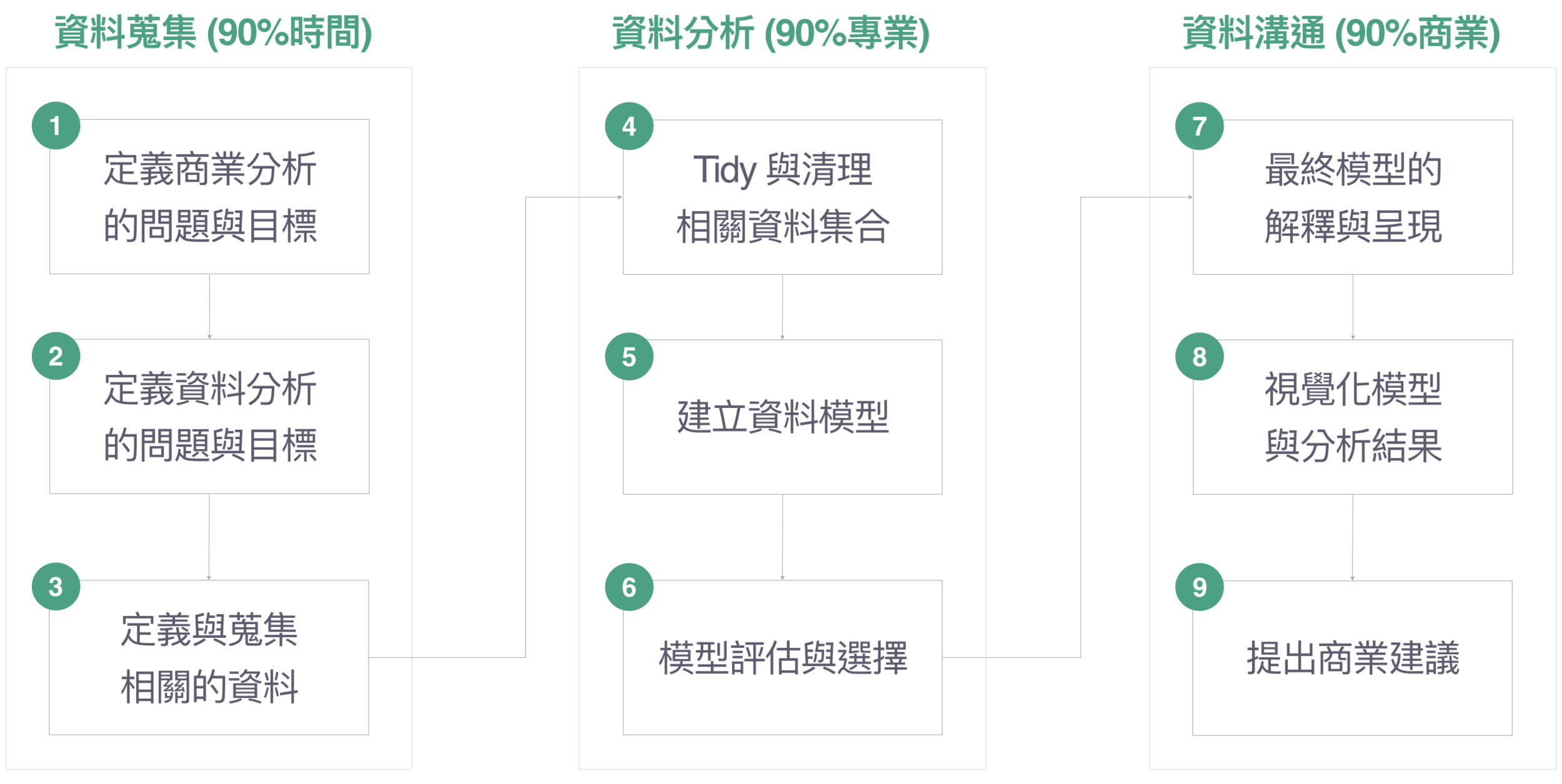
資料科學專案流程
第一階段:資料蒐集
① 確定你要解決什麼問題
就像做專題一樣,先想清楚要問的問題。
例:我想知道「為什麼某人每次都可以拿類排一,跟睡眠時間有關係嗎 ?」
② 想清楚你要分析什麼東西
問題太大會沒辦法做,要再精確一點。
例:我要找出「睡眠時間」和「考試成績」之間的關係。
③ 找到可以用的資料
你要的資料在哪裡?是問卷?網站?政府開放資料?
例:發問卷蒐集每個同學的睡眠時間和上次段考成績。
第二階段:資料分析
④ 整理資料
原始資料常常會有空格、亂碼、打錯字,要整理乾淨才能用。
例:把「8 小時」、「八小時」、「8hr」都改成一樣的格式。
⑤ 建立分析方法
決定你要用什麼方式看資料。
例:做出一張圖,看睡得多的人成績是不是真的比較好。
⑥ 看哪種分析方法最好用
有時候會試好幾種方式,選效果最好的。
例:試畫散佈圖、算相關係數,找出最清楚的方式來說明。
第三階段:資料溝通
⑦ 解釋你的結果
數據算出來還不夠,要用簡單明白的話來說明它的意義。
例:「我們發現睡眠少於 6 小時的人,平均分數真的比較低。」
⑧ 做出漂亮又有用的圖表
用圖或表格來呈現結果,大家一看就懂。
例:用 R 畫出圖表呈現結果
⑨ 提出你的建議
告訴大家你從資料中學到什麼,有什麼可以改進的。
例:「建議同學盡量保持 7 小時以上的睡眠,有助學習。」
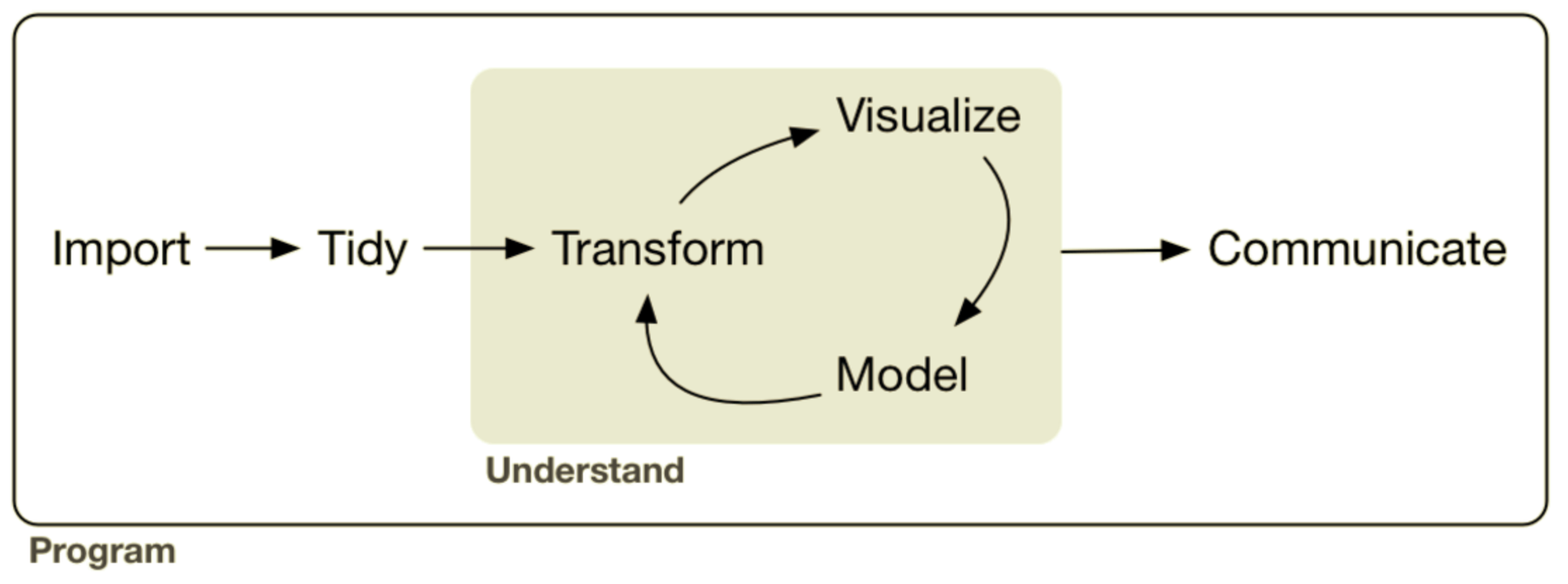
| 階段 | 意義 | 用途 |
|---|---|---|
| Program | 準備與整理資料 | 載入並把資料變乾淨 |
| Understand | 分析與理解資料 | 轉換、分析、畫圖、建模 |
| Communicate | 呈現資料價值 | 做圖、寫報告、給建議 |
tidyverse
tidyverse 是什麼?
tidyverse 是 R 語言中一組強大的資料處理與視覺化套件集合,幫助我們用一致的語法風格,輕鬆讀取、整理、分析與呈現資料。
install.packages("tidyverse")
library("tidyverse")

上面的意思是你剛剛載入了 tidyverse 套件它幫你一次載入了這些核心工具包:
這邊在提醒你你載入的 dplyr 套件裡有些函數,名稱和 base R 的函數撞名了,所以 dplyr 的版本會覆蓋掉原本的版本
tibble
library(tibble)
iris
iris2 <- as_tibble(iris)
iris2
print(iris2, n = 20)tibble 不會一次 print 出所有的資料,而是只印出前十列 (row)
tibble(x = 1:5, y = 1, z = x ^ 2 + y)
tribble(
~x, ~y, ~z,
"a", 2, 3.6,
"b", 1, 8.5
)建立一個tibble
(tibble第一行是欄位名稱,欄位名稱前必須加 ~,R 才知道這是欄位名稱而不是資料值
add_row 與 add_column 函數 : 建立新的 row 與 column
tb <- tibble(x = 1:3, y = 3:1)
# add_row
add_row(tb, x = 4, y = 0)
add_row(tb, x = 4, y = 0, .before = 2)
add_row(tb, x = 4:5, y = 0:-1)
add_row(tb, x = 4)
add_column(tb, z = -1:1, w = 0)
bind_rows 與 bind_cols 函數 : 將兩個不同資料集合合併 (dplyr套件
library(dplyr)
bind_rows(iris2[1:5, ], iris2[6:10, ])
bind_cols(iris2[, 1:2], iris2[, 3:4])
tibble 與 data.frame 的差異
1. 部分比對
df <- data.frame(
abc = 1:10,
def = runif(10),
xyz = sample(letters, 10)
)
tb <- as_tibble(df)
df$a
tb$atibble 與 data.frame 的差異
2. data.frame 在選取子集合時會回傳向量,但 tibble 仍會回傳 tibble 物件。
df[, 1]
df[, 1:2]
tb[, 1]
tb[, 1:2]
tb[[1]]
項目 |
|
|
| 所屬套件 |
tibble / tidyverse
|
base R |
| 自動轉字串 | 不會自動轉成 factor | 會自動轉 character → factor |
| 預設列印行數與欄數 | 顯示前 10 行 + 省略欄 | 一次列出所有行列(容易爆版) |
| 顯示型別 | 顯示欄位型別<int>, <dbl> 等 | 不顯示 |
| 欄位名稱強制合法 | 可以用空格、數字開頭的欄位名 | 欄位名會強制合法化 |
| 加欄位(向量長度) | 要跟原本資料行數一致 | 會自動補 NA 或重複 |
| 適合 tidyverse? | 非常適合(filter, mutate 等) | 可用但不一致 |
df <- data.frame("123 name" = 1:3)
names(df)
# [1] "X123.name" ← 自動加了 X 和點(.)
Tibble 的缺點
比較老的套件可能不支援 tibble 物件,就必須轉換回 data.frame
as.data.frame(tb))練習:
你現在有一份學生成績資料,找出成績低於 60 的學生,並用 add_row() 把他們一筆一筆加到新的 tibble 中:
library(tibble)
students <- tibble(
name = c("Amy", "Ben", "Cindy", "David", "Eva"),
score = c(90, 58, 72, 45, 80)
)
目標輸出:
# A tibble: 2 × 2
name score
<chr> <dbl>
1 Ben 58
2 David 45
提示:1.可先建立空的 tibble
fail_list<-tibble(name = character(),score = numeric())
2. nrow() 回傳橫列數
library(tibble)
# 原始資料
students <- tibble(
name = c("Amy", "Ben", "Cindy", "David", "Eva"),
score = c(90, 58, 72, 45, 80)
)
# 建立空的 tibble 作為不及格名單
fail_list <- tibble(name = character(), score = numeric())
# 使用 for + if 判斷並加到 fail_list
for (i in 1:nrow(students)) {
if (students$score[i] < 60) {
fail_list <- add_row(fail_list,
name = students$name[i],
score = students$score[i])
}
}
# 印出結果
print(fail_list)
資料輸入與輸出
(Data Import and Export)
1. 輸入 csv 類型的資料
一般我們儲存的 csv 資料檔案都遵循以下架構(來源:維基百科):
- 純文字,使用某個字元集,比如ASCII、Unicode、EBCDIC等
- 由記錄組成(典型的是每行一條記錄)
- 每條記錄被分隔符分隔為欄位(典型分隔符有逗號、分號或制表符)
- 每條記錄都有同樣的欄位序列
name,score,pass
Amy,90,TRUE
Ben,58,FALSE
Cindy,75,TRUE
| name | score | pass |
|---|---|---|
| Amy | 90 | TRUE |
| Ben | 58 | FALSE |
| Cindy | 75 | TRUE |
library(readr) #分隔符號為 , 的檔案
read_csv("檔案路徑")常見問題 :
| 問題類型 | 錯誤訊息 / 現象 | 原因說明 | 解法建議 |
|---|---|---|---|
| 路徑錯誤 |
cannot open file...或找不到檔案 |
檔案不存在 / 路徑錯誤 / 沒加引號 |
read_csv(file.choose())自動選擇 |
| 反斜線錯誤 | '\X' is an unrecognized escape... | 路徑裡出現 \ |
改成 "/ ","\\"
|
| 分隔符不符 | 全部資料讀成一欄 | 檔案實際使用 ; 或 \t 不是 , 作分隔符 |
改用⬇️ |
read_csv2("檔案路徑") #隔符號為 ; 的檔案(有些國家的小數點以 , 表示,就會出現這類檔案
read_tsv("檔案路徑") #分隔符號為 tab 的檔案
read_delim("檔案路徑", delim = "|") #可以自行選擇分隔符號資料輸入與輸出的函數都存在於套件 readr 中
write_csv()、write_csv2()、write_tsv()、write_delim()
write_csv(tibble 物件, 檔案連結)
2. 輸出 csv 類型的資料
tb <- read_csv("檔案路徑")
add_row(tb, a=7, b=8, c=9)
write.csv(tb, "檔案路徑")3. 輸入 EXCEL 檔案
tidyverse 架構下要讀取 EXCEL 檔案,會使用 readxl 套件
# install.packages("readxl")
library(readxl)excel_sheets(路徑) #讀取工作表名稱
read_excel(路徑) #得到第一個sheet
read_excel(路徑, sheet = "Inventory") #得到Inventory這個sheet
read_excel(路徑, sheet = 3) #得到第三個sheet
read_excel(路徑, n_max = 2) #得到第一個sheet的前兩列
read_excel(路徑, range = "A1:B2") #得到第一個sheet的A1到B2的資料
read_excel(路徑, range = cell_rows(1:3)) #讀取從第幾個row到第幾個row去
read_excel(路徑, range = cell_cols("A:C")) #讀取從第幾個col到第幾個col去
read_excel(路徑, range = "Inventory!B1:C3")
read_excel(路徑, na = "值")R語言(2)
By phoebe tsai



