Classical
Cipher
古典密碼

Cryptography
密碼學
How does it work ?
金鑰
Cryptography
Classical
Modern
- 資訊的保密書寫和傳遞
- 相對應的破譯方法
- 資訊完整性驗證 ( Data integrity )
(訊息驗證碼) - 資訊發布的不可抵賴性 ( Non-repudiation)(數位簽章)
凱薩密碼
Caesar Cipher
ROT13
維吉尼亞密碼
Vigenère Cipher
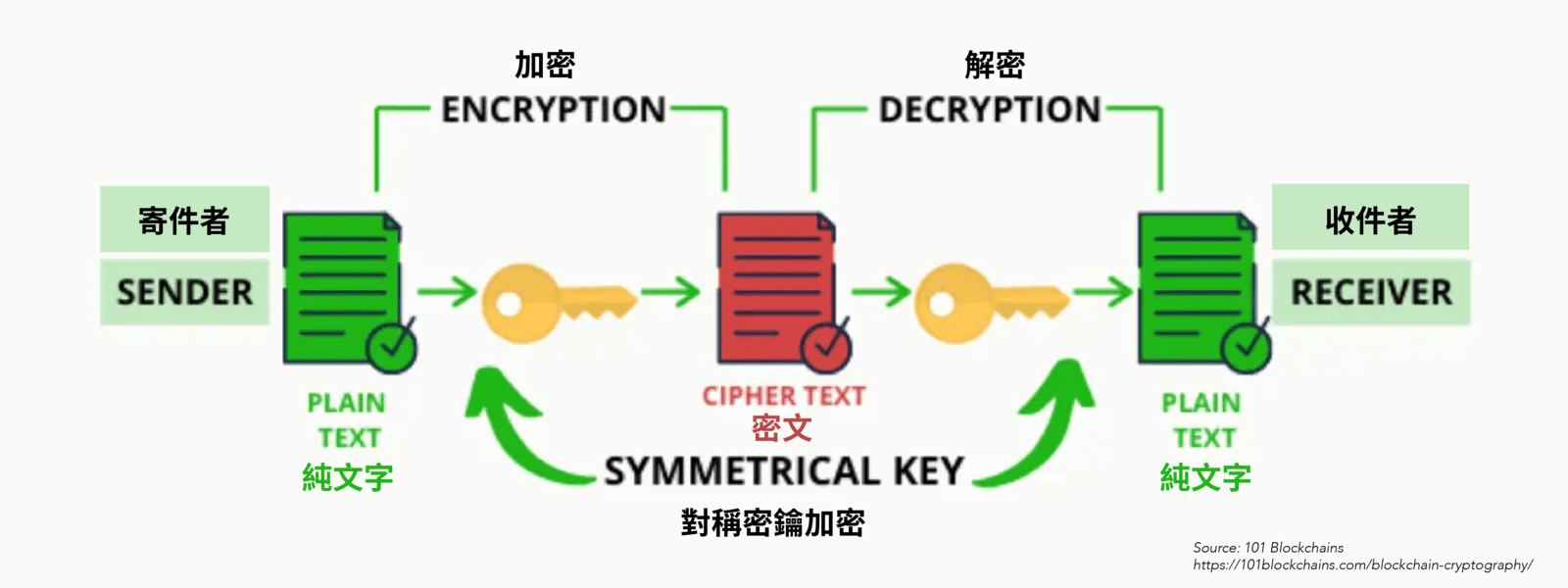
對稱加密
Symmetric Encryption
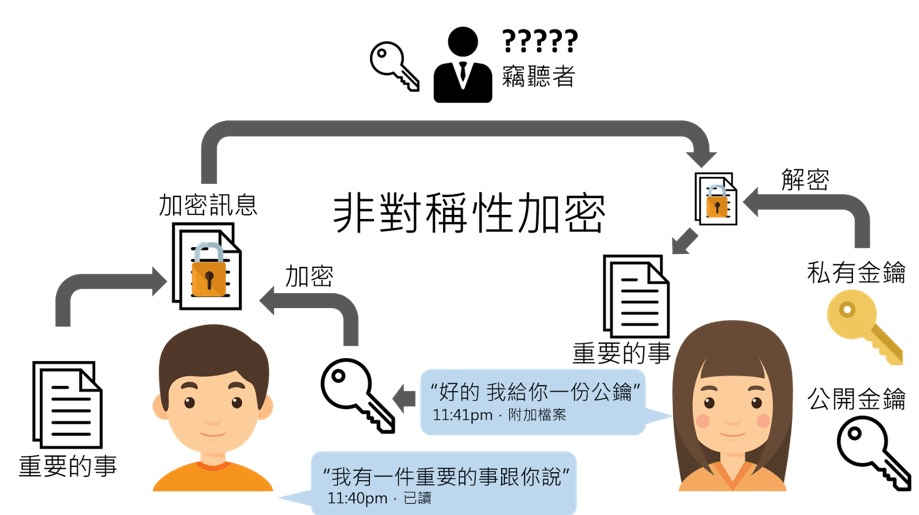
非對稱加密
Asymmetric Encryption
Caesar Cypher
凱薩密碼
Caesar Cipher
- 以羅馬共和時期凱薩命名:據稱當年凱撒曾用此方法與其將軍們進行聯繫
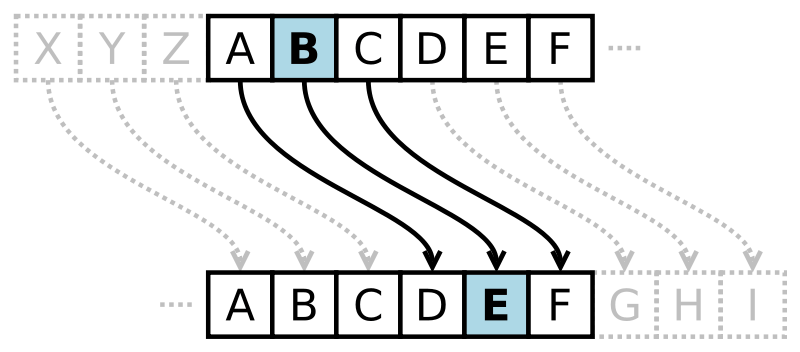
- 替換加密技術:明文中的所有字母都在字母表上向後(或向前)按照一個固定數目進行偏移後被替換成密文
- 例:當偏移量是 3 的時候,所有的字母 A 將被替換成 D,B 變成 E
Caesar Cipher
- 替換加密技術:明文中的所有字母都在字母表上向後(或向前)按照一個固定數目進行偏移後被替換成密文
明文(plaintext):
My iphone password is aEjoPd.
偏移量為 20
明文(ciphertext):
Gs cjbihy jummqilx cm uYdiJx.
Caesar Cipher
明文(plaintext):
My iphone password is aEjoPd.
偏移量為 20
明文(ciphertext):
Gs cjbihy jummqilx cm uYdiJx.
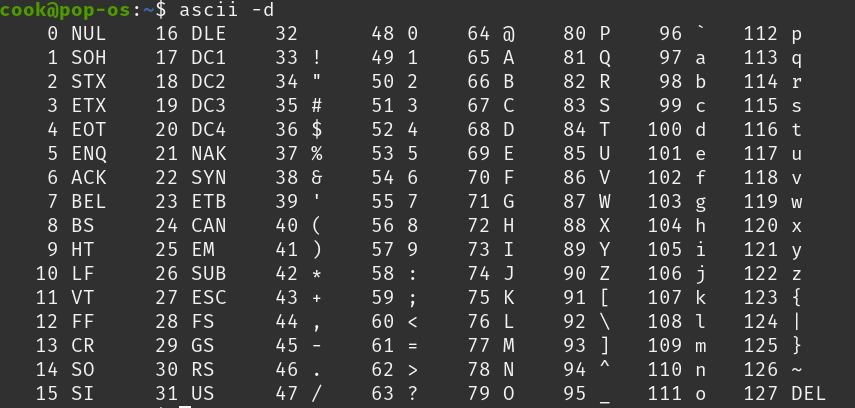
參考英文字母的 Ascii code
a(97) → 97+20=117 → u(117)
M(77) → 77+20=97 → over Z(90)
→ 97-26=71 → G(71)
Encode & Decode
加密與解密
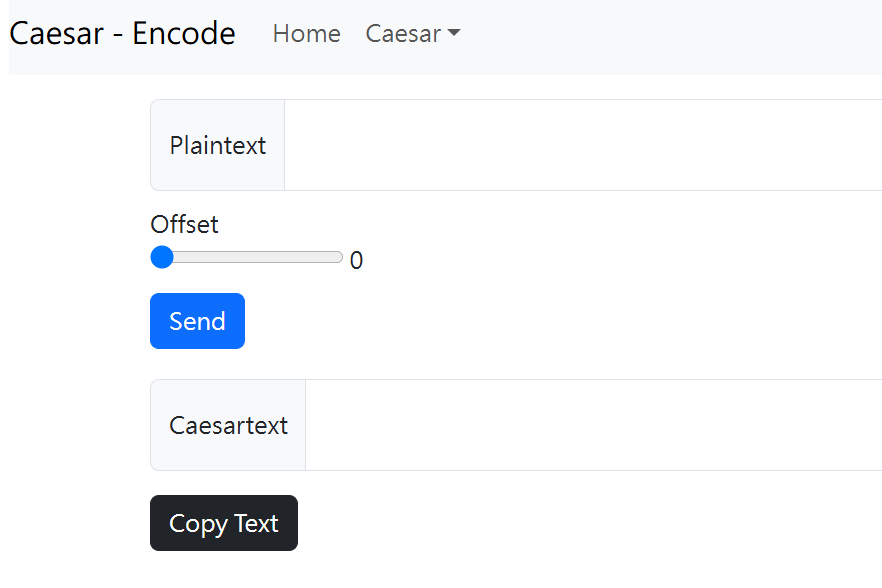
Cryptii - Caesar
能夠加密明文跟解密密文、自選偏移量
可以上去玩玩看
Encode
將明文加密需要:
- 明文內容
- 偏移量
plaintext = "Hello"
offset = 7
caesartext = ""
for c in plaintext:
n = ord(c) + offset # ord: 返回字元對應的Ascii碼
caesartext += chr(n) # chr: 返回數字對應的字元
print(caesartext) # OlssvEncode
plaintext = "Hello"
offset = 7
caesartext = ""
for c in plaintext:
n = ord(c) + offset # ord: 返回字元對應的Ascii碼
caesartext += chr(n) # chr: 返回數字對應的字元
print(caesartext) # Olssv如果加了偏移量後超過字元範圍
要怎麼修改程式碼?
★ 直接減 26 會有一點問題ㄛ
Encode
plaintext = "Weather"
offset = 15
caesartext = ""
offset %= 26 # 將偏移量控制在0~26
for c in plaintext:
n = ord(c) + offset
if c.isupper(): # 判斷是不是大寫字母
if n > ord('Z'):
n -= 26
else:
if n > ord('z'):
n -= 26
caesartext += chr(n)
print(caesartext) # LtpiwtgEncode
for ...
if c.isalpha() == False: # 判斷字元是否為英文字母
caesartext += c
continue
...最後一步
如果句子中有非英文字母,要怎麼轉換呢?
在 for 迴圈裡加入上面三行就可以了!
Decode
將密文解密需要:
- 密文內容
- 偏移量(未知)
- 所以要一個一個去試
Decode
一個一個去試
caesartext = "Olssv"
plaintext = ""
for i in range(1, 26): # 試所有可能的位移量
for c in caesartext:
n = ord(c) - i
plaintext += chr(n)
print(f"{i}: {plaintext}") # 印出偏移量跟明文
plaintext = "" # 把字串內容清空
# 1: Nkrru
# ...
# 7: HelloDecode
一樣需要改善之前加密會遇到的問題
caesartext = "Wdl xh iwt ltpiwtg idspn?"
plaintext = ""
for i in range(1, 26):
for c in caesartext:
n = ord(c) - i
if c.isalpha() == False:
plaintext += c
continue
if c.isupper(): # 判斷是不是大寫字母
if n < ord('A'):
n += 26
else:
if n < ord('a'):
n += 26
plaintext += chr(n)
print(f"{i}: {plaintext}")
plaintext = ""Practice
實作練習
Practice
設計一個程式
讓使用者選擇要解密 / 加密
並給出相對應的回應
★ 可以使用網頁 / PyQt 等可以將互動介面變得美觀的工具!
Easy Sample
def encode(plaintext:str, offset:int):
caesartext = ""
offset %= 26 # 將偏移量控制在0~26
for c in plaintext:
n = ord(c) + offset
if c.isalpha() == False:
caesartext += c
continue
if c.isupper(): # 判斷是不是大寫字母
if n > ord('Z'):
n -= 26
else:
if n > ord('z'):
n -= 26
caesartext += chr(n)
print("Your caesartext:", caesartext)
def decode(caesartext:str):
plaintext = ""
for i in range(1, 26):
for c in caesartext:
n = ord(c) - i
if c.isalpha() == False:
plaintext += c
continue
if c.isupper(): # 判斷是不是大寫字母
if n < ord('A'):
n += 26
else:
if n < ord('a'):
n += 26
plaintext += chr(n)
print(f"{i}: {plaintext}")
plaintext = ""
print("Welcome to Caesar Cipher. What do you want today?")
typ = input("Key 1 for Encode, 2 for Decode: ")
try:
int(typ)
except:
print("You can only key 1 or 2!")
else:
typ = int(typ)
if typ == 1:
plaintext = input("Please input your plaintext: ")
offset = int(input("Please input your offset number: "))
encode(plaintext, offset)
elif typ == 2:
caesartext = input("Please input your caesartext: ")
decode(caesartext)
else:
print("You bad :(")Easy Sample
Frequency Analysis
頻率分析
Frequency Analysis
- 在密碼學中,頻率分析是對密文中字母或字母組出現的頻率的研究
- 此方法用於輔助破解替換密碼(例如:單字母替換密碼、凱撒密碼等)
- 頻率分析包括計算文本中每個字母的出現次數
- 在任何給定的文本片段中,某些字母和字母組合會以不同的頻率出現
- 例如:字母 E、T、A 和 O 是最常見的,而字母 Z、Q 和 X 則不常用,因此密文句子中出現頻率最高的字母可能為明文的 E、T、A、O
Frequency Analysis

英文字母出現頻率圖
★ 可能會有不同的頻率圖!
Example
如果已知明文句子中只有 a、n、t 三個英文字母
依照頻率圖,可知他們的出現頻率由高到低為:
a → t → n
密文:r rbq qr
在密文中,字母的出現頻率由高到低為:
r → q → b
所以對照下來,可以得出明文為:a nat ta
Practice
依照頻率分析的作法
解密以下密文(明文為全大寫)
英文字母出現頻率為:
ZNKIGKYGXIOVNKXOYGXKGRREURJIOVNKXCNOINOYXKGRRECKGQOSTUZYAXKNUCURJHKIGAYKOSZUURGFEZURUUQGZZNKCOQOVGMKGZZNKSUSKTZHAZOLOMAXKOZYMUZZUHKGZRKGYZROQKLOLZEEKGXYURJUXCNGZKBKXBGPJADLIVBAYKZNUYKRGYZZKTINGXGIZKXYGYZNKYURAZOUT★ 解密出的明文應該會像一個句子
'e', 't', 'a', 'o', 'i', 's', 'l', 'h', 'r', 'c', 'u', 'w', 'y', 'd', 'f', 'k', 'm', 'n', 'p', 'v', 'b', 'g', 'x', 'z', 'j', 'q'Answer
l = ['e', 't', 'a', 'o', 'i', 's', 'l', 'h', 'r', 'c', 'u', 'w', 'y', 'd', 'f', 'k', 'm', 'n', 'p', 'v', 'b', 'g', 'x', 'z', 'j', 'q']
for i in range(0, 26):
l[i] = l[i].upper()
d = {}
for i in range(65, 91):
d[chr(i)] = 0
s = 'ZNKIGKYGXIOVNKXOYGXKGRREURJIOVNKXCNOINOYXKGRRECKGQOSTUZYAXKNUCURJHKIGAYKOSZUURGFEZURUUQGZZNKCOQOVGMKGZZNKSUSKTZHAZOLOMAXKOZYMUZZUHKGZRKGYZROQKLOLZEEKGXYURJUXCNGZKBKXBGPJADLIVBAYKZNUYKRGYZZKTINGXGIZKXYGYZNKYURAZOUT'
for i in s:
d[i]+=1
d = sorted(d.items(), key = lambda kv: kv[1], reverse=True)
d_l = [d[i][0] for i in range(0, 26)]
dd = {}
for i in range(0, 26):
dd[d_l[i]] = l[i]
ss = ''
for i in range(0, len(s)):
ss += dd[s[i]]
print(ss)Reference

好耶 下課 記得做小社展!
Classical Cipher
By pomer0
Classical Cipher
About classical cipher - caesar ciper.



