Object Detection
What is Object Recognition?
Object recognition is a general term to describe a collection of related computer vision tasks that involve identifying objects in digital photographs.
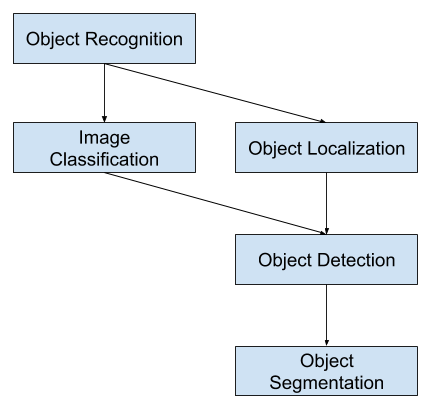
Image classification involves predicting the class of one object in an image. Object localization refers to identifying the location of one or more objects in an image and drawing abounding box around their extent. Object detection combines these two tasks and localizes and classifies one or more objects in an image.
When a user or practitioner refers to “object recognition“, they often mean “object detection“.
As such, we can distinguish between these three computer vision tasks:
-
Image Classification: Predict the type or class of an object in an image.
- Input: An image with a single object, such as a photograph.
- Output: A class label (e.g. one or more integers that are mapped to class labels).
-
Object Localization: Locate the presence of objects in an image and indicate their location with a bounding box.
- Input: An image with one or more objects, such as a photograph.
- Output: One or more bounding boxes (e.g. defined by a point, width, and height).
-
Object Detection: Locate the presence of objects with a bounding box and types or classes of the located objects in an image.
- Input: An image with one or more objects, such as a photograph.
- Output: One or more bounding boxes (e.g. defined by a point, width, and height), and a class label for each bounding box.
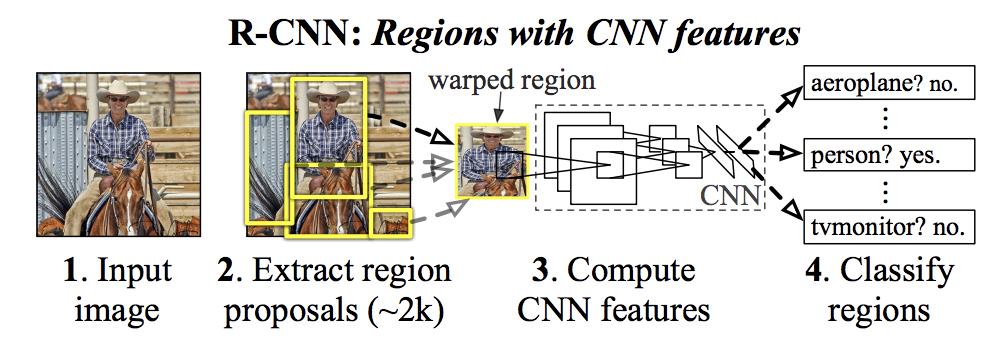
R-CNN Model Family
The R-CNN family of methods refers to the R-CNN, which may stand for “Regions with CNN Features” or “Region-Based Convolutional Neural Network,” developed by Ross Girshick, et al.
This includes the techniques R-CNN, Fast R-CNN, and Faster-RCNN designed and demonstrated for object localization and object recognition.
Let’s take a closer look at the highlights of each of these techniques in turn.
R-CNN
The R-CNN was described in the 2014 paper by Ross Girshick, et al. from UC Berkeley titled “Rich feature hierarchies for accurate object detection and semantic segmentation.”
It may have been one of the first large and successful application of convolutional neural networks to the problem of object localization, detection, and segmentation. The approach was demonstrated on benchmark datasets, achieving then state-of-the-art results on the VOC-2012 dataset and the 200-class ILSVRC-2013 object detection dataset.
Their proposed R-CNN model is comprised of three modules; they are:
- Module 1: Region Proposal. Generate and extract category independent region proposals, e.g. candidate bounding boxes.
- Module 2: Feature Extractor. Extract feature from each candidate region, e.g. using a deep convolutional neural network.
- Module 3: Classifier. Classify features as one of the known class, e.g. linear SVM classifier model.
R-CNN
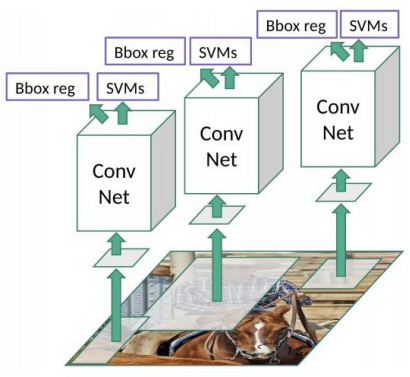
FAST R-CNN
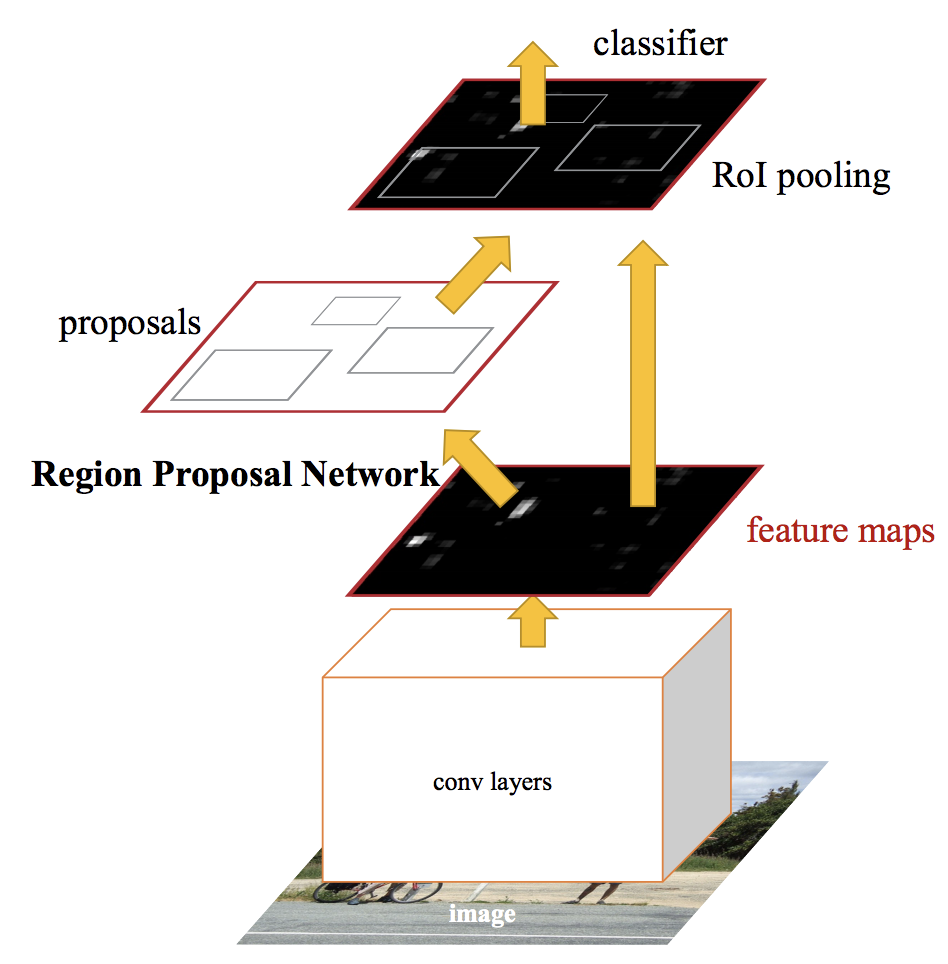
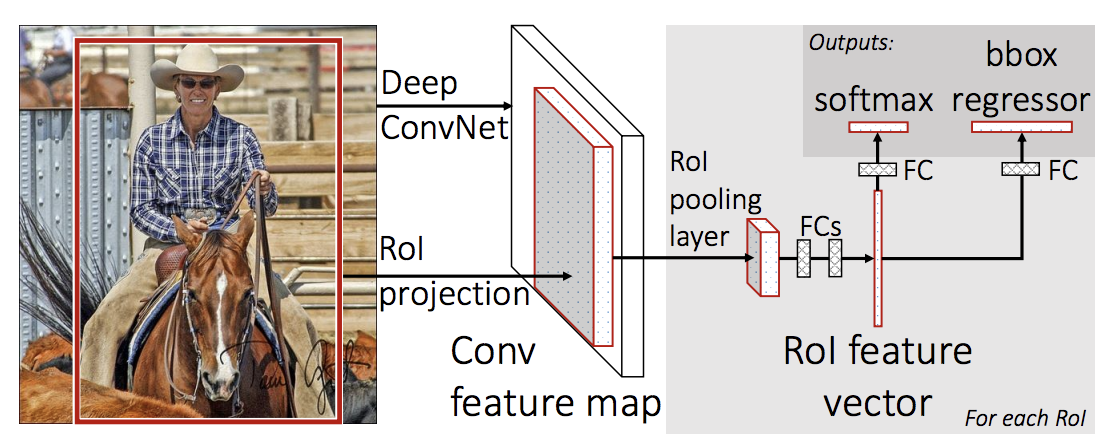
FASTER R-CNN
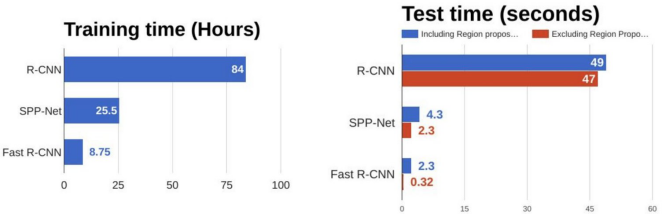
TRAINING TIME
COMPARISON
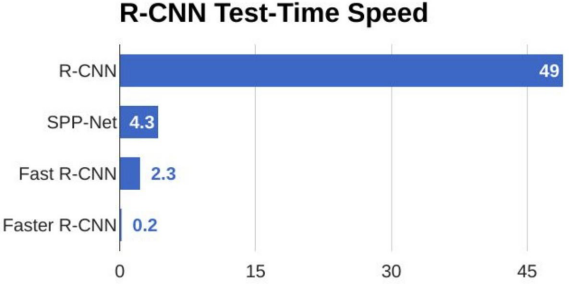
SPEED COMPARISON
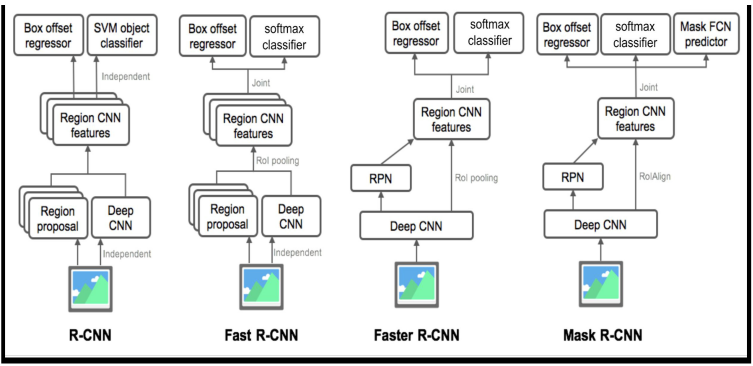
Text
ALL ALGORITHM AND ITS
IMPLEMENTATION
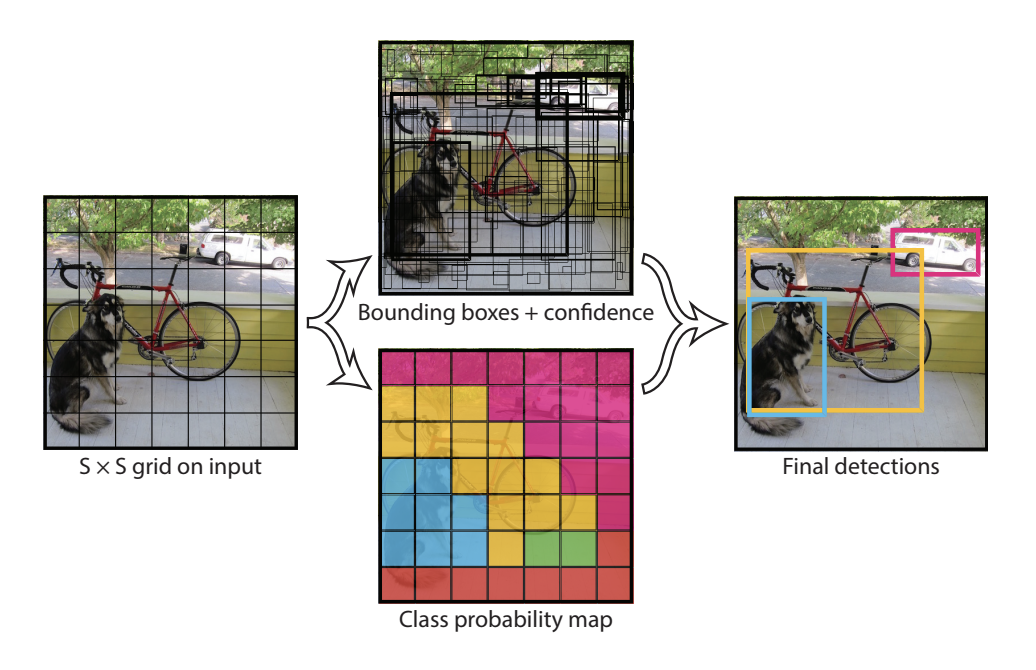
YOLO
Spiral Model
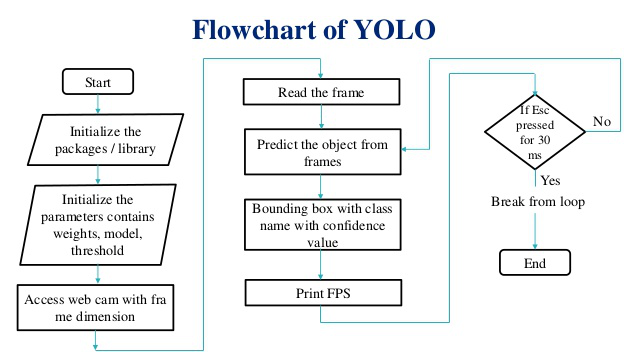
OUTPUT





deck
By pranavkhurana



