Kafka with Spring Boot Part 2
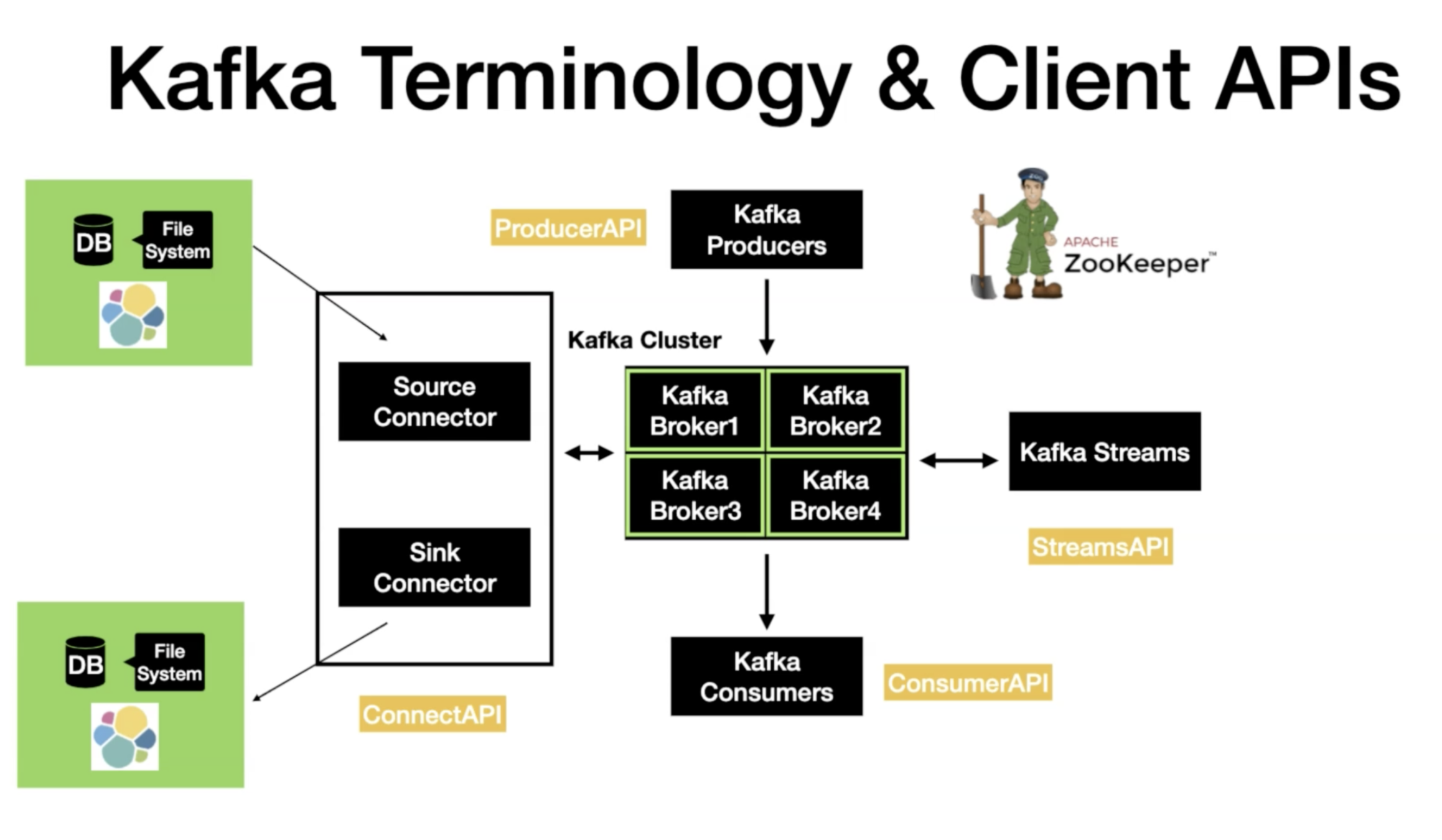
4 common use case of Kafka API
- Source -> Kafka. (Producer API) (Kafka Connect Source)
- Kafka -> Kafka (Producer/ Consumer API) (Kafka Streams)
- Kafka -> Sink (Consumer API) (Kafka Connect Sink)
- Kafka -> App (Consumer API)
Kafka Connect - High Level
- Source Connectors to get data from common data source
- Sink Connectors that data in common data stores
- Make it easy to get data reliably in Kafka
- Part of ETL pipeline
Kafka Connect Concepts
- Kafka Connect cluster has multiple loaded connectors
- Each connector is a re-usable piece of code (java jars)
- Most of the connectors exist in open source world
- Connector + User Configuration = Tasks
- Tasks are executed by Kafka connect worker server
Getting Confluent
- Go to https://docs.confluent.io/platform/current/installation/installing_cp/zip-tar.html
- Download the zip file of latest version i.e http://packages.confluent.io/archive/6.1/confluent-6.1.0.zip
- Extract the zip file once it is download
SetUp for Kafka Connect
- Go inside the bin folder and start the zookeeper
- Start Kafka Broker
- Start the Schema Registery
./zookeeper-server-start ../etc/kafka/zookeeper.properties ./kafka-server-start ../etc/kafka/server.properties./schema-registry-start ../etc/schema-registry/schema-registry.properties Reading file data with connect
-
We require two configuration files to startup a FileStreamSourceConnector to read data from a file and output it to Kafka
- ./etc/schema-registry/connect-avro-standalone.properties : It stores the data conversion format via AvroConverter
- ./etc/kafka/connect-file-source.properties : It stores file related configuration from which we need to read data
- Create a file test.txt and in the connect-file-source.properties specify its absolve path in file property
- Enter some data in test.txt file
- Start Kafka connect instance
- Start console consumer in another console to inspect the contents of the topic
./connect-standalone ../etc/schema-registry/connect-avro-standalone.properties \
../etc/kafka/connect-file-source.properties ./kafka-avro-console-consumer --bootstrap-server localhost:9092
--topic connect-test --from-beginningWrite File Data with connect
- Create a file test.sink.txt
- Open the file ./etc/kafka/connect-file-sink.properties
- In the file property mention the absolute path for test.sink.txt
- Run the command below to run source file and sink file process
- Now enter the data in test.txt you will observe that the data will persist in test.sink.txt
./connect-standalone ../etc/schema-registry/connect-avro-standalone.properties \
../etc/kafka/connect-file-source.properties ../etc/kafka/connect-file-sink.propertiesKafka Connector to Mysql source
- Download the mysql jar from the link https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.23/mysql-connector-java-8.0.23.jar
- Install kafka connect jdbc
- Now paste the Mysql jar file in the location : confluent-6.1.0/share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib
- Create a folder kafka-connect-jdbc in confluent-6.1.0/etc/
./confluent-hub install confluentinc/kafka-connect-jdbc:latest- Inside the kafka-connect-jdbc folder create a file source-quickstart-mysql.properties
- Enter the following properties in the file
- Create table and enter some values
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://127.0.0.1:3306/mydb?user=root&password=
mode=incrementing
incrementing.column.name=rollno
topic.prefix=test-mysql-jdbc-
table.whitelist=user4create table user4(
fname varchar(30),
rollno int(6) primary key);
insert into user4 values ("sunny",1);
insert into user4 values ("ginny",2);- Start the worker for jdbc source connect
- List the topics
- Launch Consumer to inspect the data
./connect-standalone ../etc/schema-registry/connect-avro-standalone.properties
../etc/kafka-connect-jdbc/source-quickstart-mysql.properties ./kafka-topics --bootstrap-server localhost:9092 --list ./kafka-avro-console-consumer --bootstrap-server localhost:9092
--topic test-mysql-jdbc-user4 --from-beginningJDBC Sink Connector
- Create sink-quickstart-mysql.properties file in /etc/kafka-connect-jdbc/ folder
- Add the following properties in the properties file
name=test-sink
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
tasks.max=1
topics=test-mysql-jdbc-user4
connection.url=jdbc:mysql://127.0.0.1:3306/mydb?user=root&password=
auto.create=true- Run the command to read data from topic and write it in database
- Here we are reading from the topic which we created earlier. Now in the database you will see that table with the name test-mysql-jdbc-user4 has been created and data is read from the topic and inserted in the table
./connect-standalone ../etc/schema-registry/connect-avro-standalone.properties
../etc/kafka-connect-jdbc/sink-quickstart-mysql.propertiesRunning 2 worker threads for JDBC Source and Sink Connector
- Open new terminal and create a copy of /etc/schema-registry/connect-avro-standalone.properties with the name /etc/schema-registry/connect-avro-standalone-1.properties
- In the connect-avro-standalone-1.properties mention the property rest.port=8084
- Run the following command to initiate JDBC Source Worker
- Now you will observe that when you insert data in user4 than that data is also reflection in table select * from `test-mysql-jdbc-user4`;
./connect-standalone ../etc/schema-registry/connect-avro-standalone-1.properties
../etc/kafka-connect-jdbc/source-quickstart-mysql.propertiesInstall and Run mongo 3.6 using docker
- Pull the docker image
- start the docker container
- enter in the container
- Connect with mongo
- Initiate replica sets
- Create db
docker image pull mongo:3.6 docker container run --name mongodb3.6 -d -p 27018:27017 <container-id>
mongod --replSet my-mongo-setdocker exec -it mongo3.6 /bin/bashmongo --host 127.0.0.1:27017rs.initiate()use kafka-topicsMongo sink Connect
- install Mongodb Kafka connector
- Create a file /etc/kafka-connect-mongo/sink-quickstart-mongodb.properties and enter the following properties in it
- Run the Mongo Sink connect worker
- Inspect the data in mongo console
./confluent-hub install mongodb/kafka-connect-mongodb:1.4.0tasks.max=1
connection.uri=mongodb://localhost:27018
database=kafka-topics
connector.class=com.mongodb.kafka.connect.MongoSinkConnector
topics=test-mysql-jdbc-user4
name=mongo-sink-worker
collection=user./connect-standalone ../etc/schema-registry/connect-avro-standalone.properties
../etc/kafka-connect-mongo/sink-quickstart-mongodb.propertiesdb.user.find()Mysql Sink to Mongo Source
- In addition to the mongo sink worker also spin up mysql source worker for the same topic
- Now if you insert the record in user4 table of mydb mysql database you will observe that the same record in reflected in mongodb user collection under kafka-topics database
./connect-standalone ../etc/schema-registry/connect-avro-standalone-1.properties
../etc/kafka-connect-jdbc/source-quickstart-mysql.propertiesExercise 1 (Do any two)
- Push the data of one file in another file using Kafka connect using File source and Sink connector.
- Reflect the inserts in one mysql table into another mysql table using JDBC source and sink connectors.
- Reflect the inserts in one mysql table into a Mongo DB collection.
Kafka Stream
- It is a stream processing framework
- It is an alternative to apache spark, nifi and Flink
- It reads the data from one topic and place it in the different topic after some transformation
Stream Processors
- Stream processor process incoming data stream
- Stream Processor can create new output stream
- Data flow from parent to child
- Child stream processor can define another child
Streams
Stream Processor
Source Processor
Sink Processor
Source Processor
- Does not have upstream
- Consumes from one or more kafka topics
- Forwarding data to downstream
Sink Processor
- Does not have downstream
- Receive data from upstream
- Send data to specific data topic
KStreams
- Ordered Sequence messages
- Unbounded
- Insert data
- Use case
- Topic is not log compacted
- Data is partial information (Bank Transaction)
KTable
- Unbounded
- Insert and update based on key
- Delete on null Value
- Topic is log compacted
- Data is self sufficient (Bank Balance)
Log Compacting
- Kafka admin process
- Keep at least latest values and delete the older
- Based on record Key
- Useful if we need latest snapshot
- Configure when creating topics
- Keeps the Order
Create 2 topics
- promotion-code
- promotion-code-upper
- Spin up a producer for promotion-code
- Spin up a consumer for promotion-code-upper
./kafka-topics --create --topic promotion-code-upper -zookeeper localhost:2181
--replication-factor 1 --partitions 3./kafka-topics --create --topic promotion-code -zookeeper localhost:2181
--replication-factor 1 --partitions 3./kafka-console-producer --topic promotion-code --broker-list localhost:9092
--property parse.key=true --property key.separator="-" ./kafka-console-consumer --topic promotion-code-upper --bootstrap-server localhost:9092 \
--from-beginning \
--property print.key=true \Note : Command to delete the topic
./kafka-topics --zookeeper localhost:2181 --delete --topic <topic-name>Set Up
- Go to start https://start.spring.io/
- Create a gradle project with following dependencies
- Spring for apache Kafka
- Spring for apache Kafka stream
- Lombok
- Spring Boot dev tools
- Download the zip file for the project
- Extract the project and Import it in intellij Idea
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.annotation.EnableKafkaStreams;
@SpringBootApplication
@EnableKafkaStreams
@EnableKafka
public class KafkaStreamApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaStreamApplication.class, args);
}
}
Enable Kafka and Kafka Stream for Spring Boot application
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaStreamsDefaultConfiguration;
import org.springframework.kafka.config.KafkaStreamsConfiguration;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaStreamPropertyConfiguration {
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
public KafkaStreamsConfiguration kafkaStreamsConfiguration(){
Map<String,Object> props = new HashMap<>();
props.put(StreamsConfig.APPLICATION_ID_CONFIG,"kafka-stream");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG,0);
return new KafkaStreamsConfiguration(props);
}
}
Setup KafkaStreamsConfigurations
Perform transformation of promotion code from promotion-code topic to upper case and place it in promotion-code-upper topic
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Printed;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaStreamPromotionCode {
@Bean
public KStream<String,String> kStreamPromotionUppercase(StreamsBuilder streamsBuilder){
KStream<String,String > sourceStream = streamsBuilder
.stream("promotion-code", Consumed.with(Serdes.String(),Serdes.String()));
KStream<String,String> uppercaseStream = sourceStream.mapValues(e->e.toUpperCase());
uppercaseStream.to("promotion-code-upper");
sourceStream.print(Printed.<String, String>toSysOut().withLabel("code"));
uppercaseStream.print(Printed.<String, String>toSysOut().withLabel("Upper-Case-Code"));
return sourceStream;
}
}
On Publishing data from promotion-code topic producer you will see that the value has been converted in upper case and read by consumer of promotion-code-upper topic
{code:"asdnas"} => {CODE:"ASDNAS"}
Our code has also changed the code attribute to upper but we just want to change its value in upper.
Let's see how we do it.
Create Promotion code class
public class PromotionCode {
private String code;
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
@Override
public String toString() {
return "PromotionCode{" +
"code='" + code + '\'' +
'}';
}
}
Transformation using Spring JSON Serde
import com.course.kafka.kafkastream.entity.PromotionCode;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Printed;
import org.apache.kafka.streams.kstream.Produced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.support.serializer.JsonSerde;
@Configuration
public class KafkaSteamJSONPromotionCode {
@Bean
public KStream<String,PromotionCode> kStreamPromotionUppercase(StreamsBuilder streamsBuilder){
KStream<String,PromotionCode > sourceStream = streamsBuilder
.stream("promotion-code", Consumed.with(Serdes.String(),new JsonSerde<>(PromotionCode.class)));
KStream<String,PromotionCode> uppercaseStream = sourceStream.mapValues(this::uppercasePromotionCode);
uppercaseStream.to("promotion-code-upper", Produced.with(Serdes.String(),new JsonSerde<>(PromotionCode.class)));
sourceStream.print(Printed.<String, PromotionCode>toSysOut().withLabel("code"));
uppercaseStream.print(Printed.<String, PromotionCode>toSysOut().withLabel("Upper-Case-Code"));
return sourceStream;
}
private PromotionCode uppercasePromotionCode(PromotionCode promotionCode){
promotionCode.setCode(promotionCode.getCode().toUpperCase());
return promotionCode;
}
}
Keys and Partitions
- Key and partitions are related
- partitions are allocated according to key
- whenever the key of a message changes it triggers repartitioning.
- Operations on Kafka stream which changes the key trigger repartitioning
- As soon as an operation can possible change the key the streams will be marked for repartition.
- Map
- flatMap
- selectKey
- Repartitioning is done seamlessly behind the scene but will incur a performance cost.
Kafka Stream Operations
- mapValues
- Take one record produce one record
- Does not change key
- Affect only value
- Does not trigger repartition
- Intermediate Operation
- Available on KStream and KTable
stream.mapValues(v->v+10);- map
- Takes one record and produce one record
- Change key
- Change value
- Trigger repartition
- Intermediate Operation
- KStream
stream.map((k,v)->KeyValue.pair("X"+k,v*5));- filter
- Takes one record, produces one or zero record
- Produce record that match condition
- Does not change key and value
- Does not trigger repartition
- Intermediate Operation
- KStream and KTable
stream.filter((k,v)->v%2==0)- filterNot
- Takes one record, produces one or zero record
- Produce record that not match condition
- Does not change key and value
- Does not trigger repartition
- Intermediate Operation
- KStream and KTable
stream.filterNot((k,v)->v%2==0)- branch
- split stream based on predicate
- evaluate predicate in order
- record only placed once on first match, drop unmatched records
- Returns array of Stream
- Intermediate operation
- KStream
stream.branch(
(k,v)->v>100,
(k,v)->v>20,
(k,v)->v>10,
)- selectKey
- Takes one record and produce one record
- Set / replace record key
- possible to change key data type
- Trigger repartitioning
- Does not change value
- Intermediate Operation
- KStream
stream.selectKey((k,v)->"A"+k)- flatMapValues
- Takes one record, produces zero and more records
- Does not change key
- Affect only value
- Does not trigger repartitioning
- Intermediate Operation
- Kstream
//split a sentence into words
sentencesStream.flatMapValues(value->Arrays.asList(value.split("\\s+")));
// (alice, alice is nice) tranfroms to (alice,alice), (alice,is), (alice, nice) - flatMap
- Takes one record, produce zero or more record
- Change key
- Change value
- Trigger Repartitioning
- Intermediate Operation
- KStream
KStream<Long, String> stream = ...;
KStream<String, Integer> transformed = stream.flatMap(
// Here, we generate two output records for each input record.
// We also change the key and value types.
// Example: (345L, "Hello") -> ("HELLO", 1000), ("hello", 9000)
(key, value) -> {
List<KeyValue<String, Integer>> result = new LinkedList<>();
result.add(KeyValue.pair(value.toUpperCase(), 1000));
result.add(KeyValue.pair(value.toLowerCase(), 9000));
return result;
}
);- groupByKey
- Intermediate Operation
- group records by existing key
stream.groupByKey()- groupBy
- Intermediate Operation
- group records by new key
stream.groupBy((k,v)->v%2)- forEach
- Terminal Operation
- Takes one record, produce none
- KStream and KTable
strea.forEach((k,v)->insertToDatabase(v))- Peek
- Produce unchanged stream
- Result stream can be further processed
- Intermediate Operation
- KStream
stream.peek((k,v)->insertIntoDatabase(v)).[nextProcess]- print
- Terminal operation
- Print each record
- print to file or console
- KStream
stream.print(Printed.toSysout())- to
- Terminal operation
- Write the stream to destination topic
- KStream
stream.to("output-topic")- through
- Intermediate operation
- Write stream to destination topic
- Continue record processing
- KStream
stream.through("output-topic").[nextProcess]Problem statement
Find out word count from a stream of sentences
- Create sentence topic
- Create work-count topic
- Spin up producer for topic sentence
- Spin up consumer for word-count sentence
./kafka-topics --create --topic sentence -zookeeper localhost:2181
--replication-factor 1 --partitions 3./kafka-topics --create --topic word-count -zookeeper localhost:2181
--replication-factor 1 --partitions 3./kafka-console-producer --topic sentence --broker-list localhost:9092./kafka-console-consumer --topic word-count --bootstrap-server localhost:9092 \
--property print.key=true \
--property key.separator="-"
High level DSL for find out word count from sentences
- Stream from kafka <null, Kafka Kafka Stream>
- MapValues lowercase <null, kafka kafka stream>
- FlatMapValues split by space <null,kafka><null,kafka><null,stream>
- SelectKey <kafka,kafka><kafka,kafka><stream,stream>
- GroupByKey (<kafka,kafka><kafka,kafka>) (<stream,stream>)
- Count occurrence in each group <kafka,2> <stream,1>
Spring kafka sentence to word-count stream transformation
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Arrays;
@Configuration
public class KafkaSentenceToWordCountStreamConfig {
@Bean
KStream<String,String> sentenceToWordsStreamProcessor(StreamsBuilder streamsBuilder){
KStream<String,String> kStream = streamsBuilder.stream("sentence");
kStream
.mapValues(s->s.toLowerCase())
.flatMapValues(s-> Arrays.asList(s.split("\\s+")))
.selectKey((k,v)->v)
.groupByKey()
.count()
.toStream()
.mapValues(e->e.toString())
.peek((key,value)-> System.out.println(String.format("Key :: %s, Value :: %s",key, value)))
.to("word-count");
return kStream;
}
}
Most Favourite Colour with KTable
- Create colour topic
- Create a producer for colour topic
./kafka-topics --create --topic colour -zookeeper localhost:2181
--replication-factor 1 --partitions 3./kafka-console-producer --topic colour --broker-list localhost:9092
--property parse.key=true --property key.separator="-"Reading from topic as KTable
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaColourCountStream {
@Bean
KStream<String,String> colourCount(StreamsBuilder streamsBuilder){
return streamsBuilder.table("colour")
.groupBy((key, value) -> KeyValue.pair(value,value) )
.count()
.toStream()
.map((k,v)->KeyValue.pair(k.toString(),v.toString()))
.peek((key, value) -> System.out.println(String.format("Key :: %s, Value :: %s",key,value)));
}
}
Start producing messages with producer
>a-yellow
>b-yellow
>a-green
>b-green
>a-blue
>b-blueProblem Statement
On the Basis on Bank Transactions calculate the Bank Balance
- Create a Topic Bank Transaction
- Spin up producer for the topic
./kafka-topics --create --topic bank-transaction -zookeeper localhost:2181
--replication-factor 1 --partitions 3./kafka-console-producer --topic bank-transaction --broker-list localhost:9092Create BankTransaction Entity
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString
public class BankTransaction {
private String name;
private Long amount;
}
Create Stream to calculate total balance
import com.course.kafka.kafkastream.entity.BankTransaction;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Printed;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.support.serializer.JsonSerde;
@Configuration
public class KafkaBankTransactionStream {
@Bean
public KStream<String,BankTransaction> bankTransactionKStream(StreamsBuilder streamsBuilder) {
KStream<String,BankTransaction> sourceBankTransactionKStream=streamsBuilder.stream("bank-transaction", Consumed.with(Serdes.String(),new JsonSerde<>(BankTransaction.class)));
sourceBankTransactionKStream
.groupBy((k, v) -> v.getName()).aggregate(
() -> 0L,
(k, v, a) -> {
a=a+v.getAmount();
return a;
},Materialized.with(Serdes.String(),Serdes.Long())).toStream()
.print(Printed.toSysOut());
return sourceBankTransactionKStream;
}
}
Exercise 2
- Create a topic employee and produce data to the topic in the form of JSON i.e
{"id":"1","gender":"Male","age":"32","name","Sunny","salary":"500000"}
- Use Kafka stream to file which does the following operations
- For all the employees with age greater that 30
- If the gender is male then prepend name with Mr or else prepend it with Ms/Mrs
- Assuming that salary is in rupee convert it to dollar
- publish the transformed data in updated-employee topic
Exactly once semantic
- Exactly once is the ability to guarantee that data processing on each message will only happen at once. Following scenarios explains the problem with atleast once semantic
kafka
kafka
Kafka Stream, Producer or Consumer
1. Receive Message
2. Send Output
4. Commit Offset
3. Receive
Ack
- If Kafka server reboots after step 3 the same message will be received twice. (As a Kafka Consumer)
- If After step 3 a network error occurs then the message will be send twice. (As a Kafka Producer)
How Kafka solves this problem ?
- The producer is now idempotent. If the same message is send twice or more Kafka will make sure to keep only one copy of it.
- You can write multiple messages to different Kafka topics as a part of one transaction. Either all are written or none is written.
- We just need to add following property in
KafkaStreamsConfiguration
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG,StreamsConfig.EXACTLY_ONCE);
Kafka with Spring Boot Part 2
By Pulkit Pushkarna




