Research Talk
Rob Salomone

www.robsalomone.com
"Talk about your research for 25-30 minutes"
Plan: From Big Picture to Small Picture
1. Discuss my research at a high level (\(\approx 10 \) mins.)
2. Discussing the main ideas behind one paper (\(\approx 15 \) mins.)
The Big Picture
Methodology in Statistics and Machine Learning
Research Elevator Pitch
"I use mathematical ideas in creative ways to help improve methods in statistics and machine learning. A large part of this is making methods that work more reliably, more efficiently, or even at all for problems of interest in modern settings."
Some areas I have worked on...
(the symptoms)
- Bayesian Statistics
- Federated Learning
- Markov Chain Monte Carlo
- Variational Inference
- Graphical Models
- Time Series Analysis
- Rare-Event Simulation / Probability Estimation
- Anomaly Detection
- Copulas
- Sequential Monte Carlo
- Likelihood Free-Inference
- Sums of Random Variables
- Kernel Methods
- Deep Learning Theory
The Condition...
Key Focus: The right ideas for the right problem to answer:
- Why do existing methods work?
- Why/When do they not work?
- When they don't, how do you make them work?"
I am mostly interested in solving interesting fundamental problems using whatever ideas work.
- Ideas come from a lot of places: Different models, different algorithms, different maths.
- models, algorithms, and maths are all related
The Medium Picture
Probabilistic (Bayesian)
Inference
In any probabilistic model, there are observations \(\mathbf{y}\) and latent variables \(\mathbf{Z}\). For the latent variables, one assigns a prior distribution \(p(\mathbf{z})\).
Posterior: Via Bayes' rule
\[p(\mathbf{z}|\boldsymbol{y}) = p(\mathbf{z})p(\mathbf{y}|\mathbf{z})\bigg/ \underbrace{\int p(\mathbf{z})p(\mathbf{y}|\mathbf{z}) d \mathbf{z}}_{\textstyle p(\mathbf{y})}.\]
Such models are ubiquitous in statistics and (probabilistic) machine learning.
Latent Parameters: Bayesian Statistics, or "fully-Bayesian" modelling -
The model parameters themselves are modelled as latent and assigned a prior (i.e., are part of \(\mathbf{Z}\)).
Probabilistic Inference: Computing quantities related to posterior distributions (also required for prediction in Bayesian statistics)
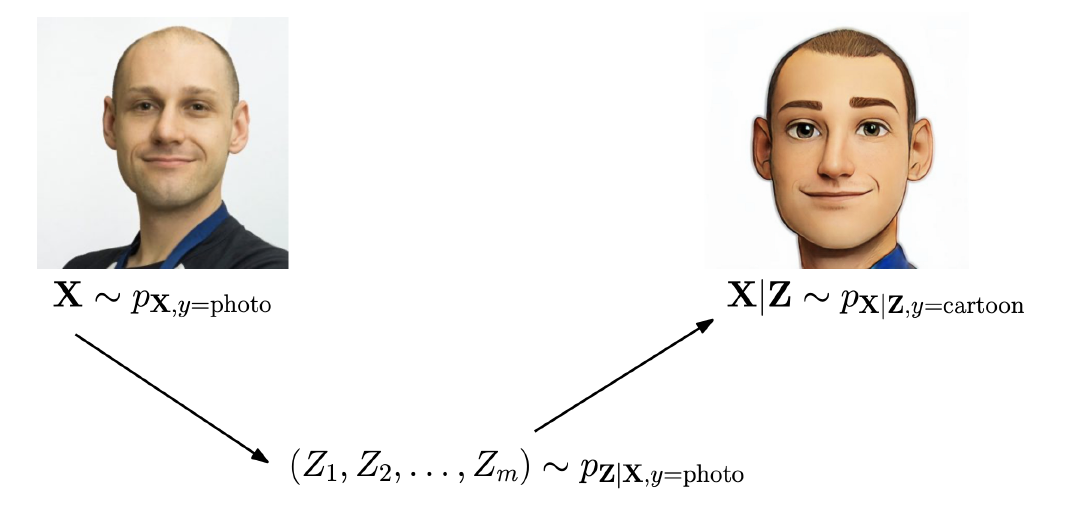
\(p(\boldsymbol{\theta} | \mathbf{y}) = p(\boldsymbol{\theta})p( \mathbf{y}| \boldsymbol{\theta} )\bigg/ p(\mathbf{y})\)
Bayesian Machine Learning
Bayesian Statistics
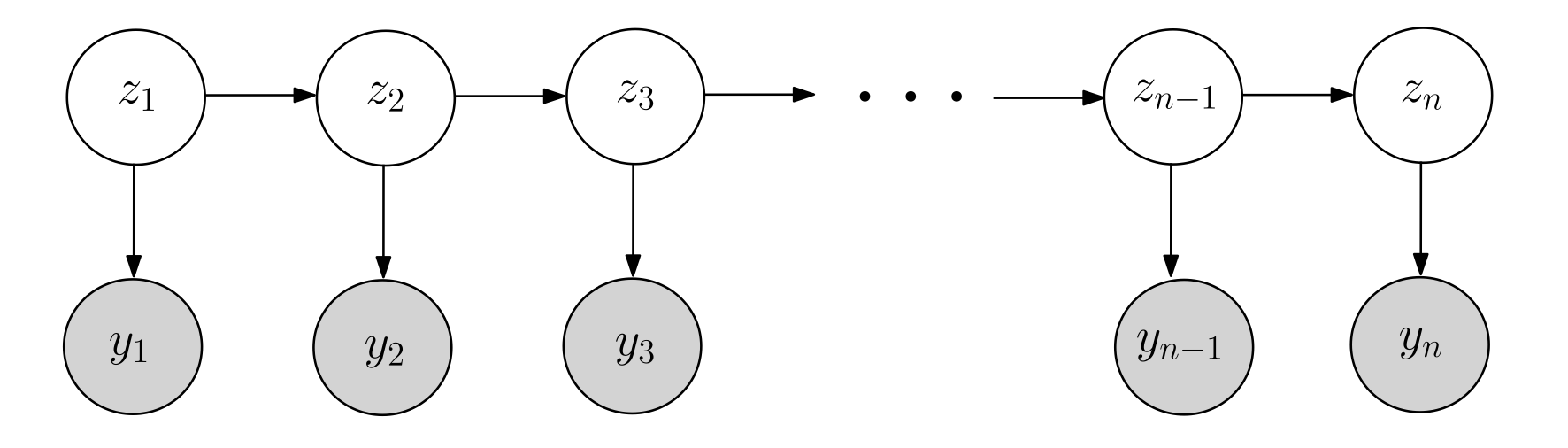
State Space Model
- Markov Chain Monte Carlo
- Variational Inference
- Time Series Analysis
- Sequential Monte Carlo
- Likelihood Free-Inference

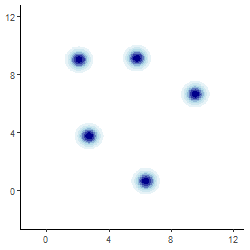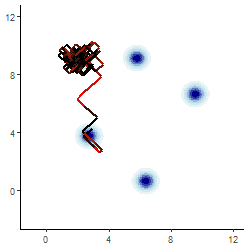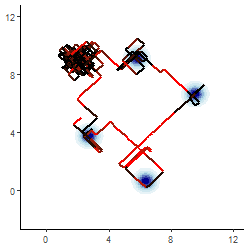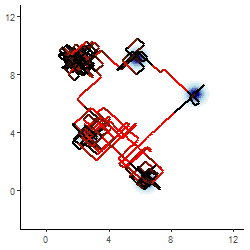
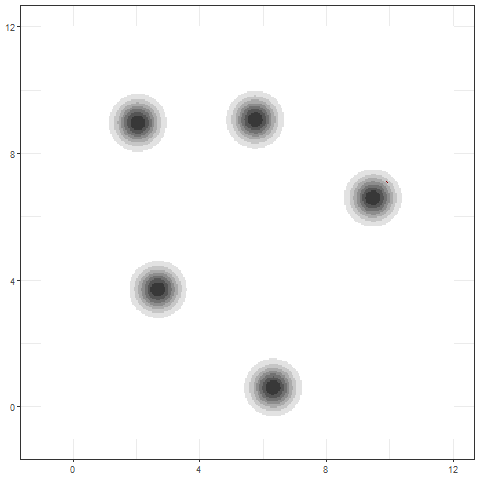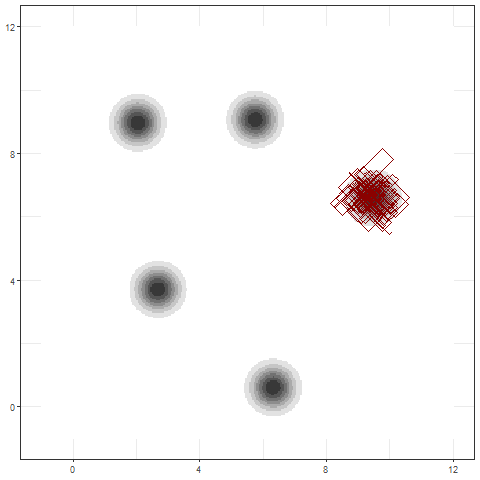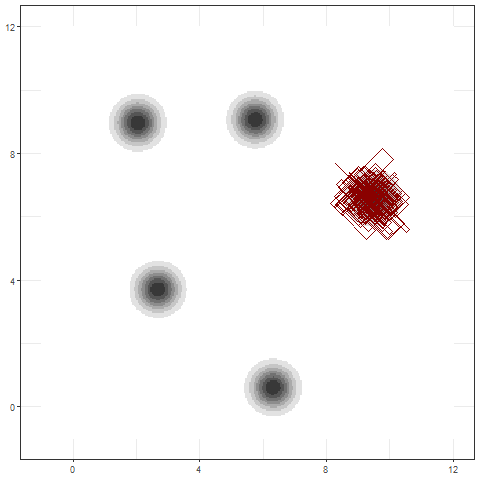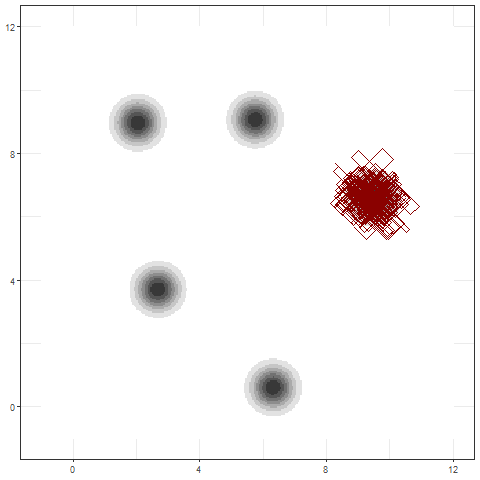
Infering \( \mathbf{Z}|\mathbf{y} \)
Smaller Picture
An Idea from One Paper
- Bayesian Statistics
- Markov Chain Monte Carlo
- Time Series Analysis
Sharing one idea...
Why this one?
Salomone R., Quiroz, M., Kohn, R., Villani, M., and Tran, M.N. (2020), Spectral Subsampling MCMC for Stationary Time Series, Proceedings of the International Conference on Machine Learning (ICML) 2020.
To other slides...
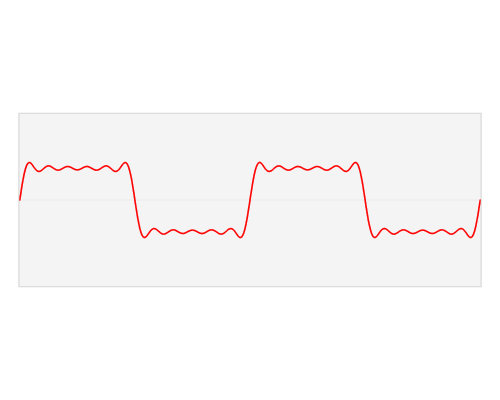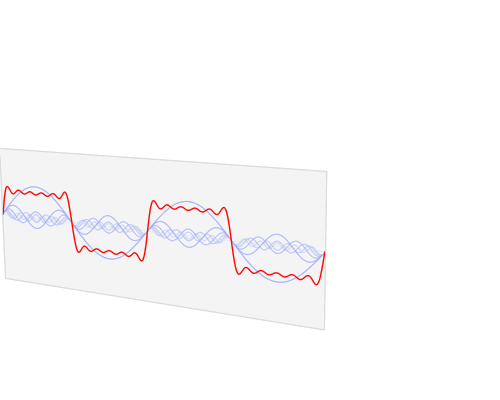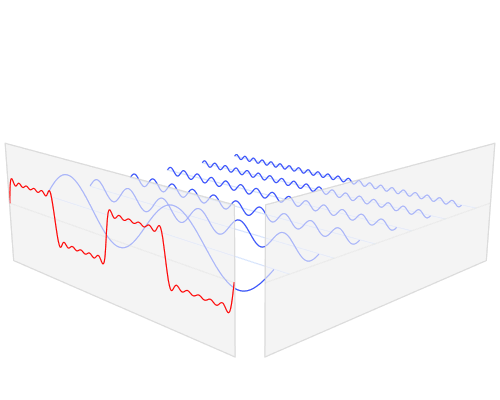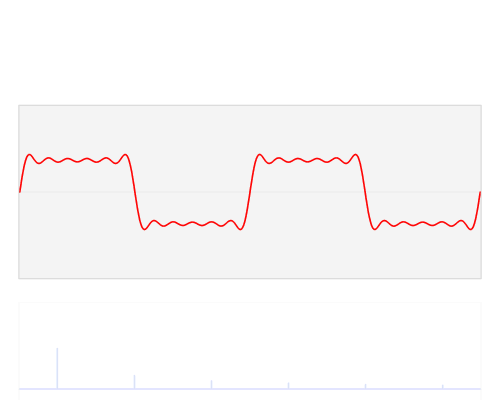
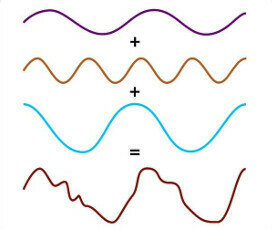
Fourier Series and Spectral Density
Autocovariance Function (Time Domain)
Spectral Density (Frequency Domain)
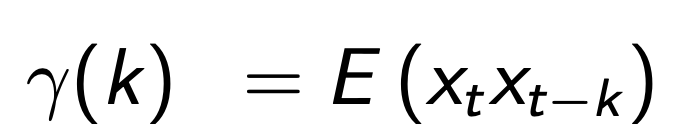
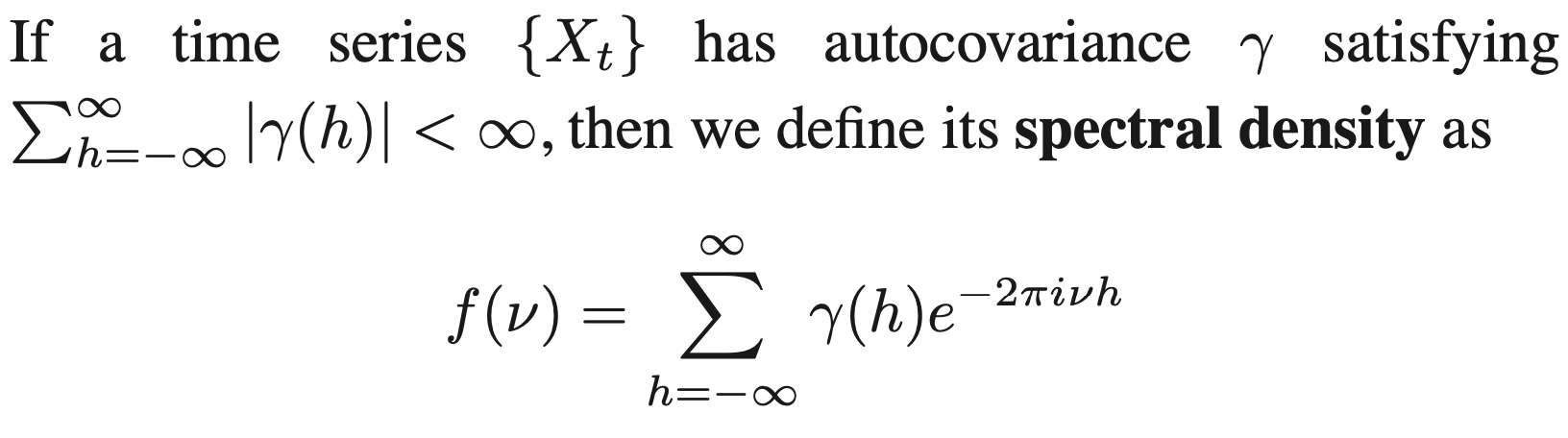
deck
By Rob Salomone


