Нейросети
Нейросети

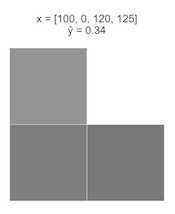
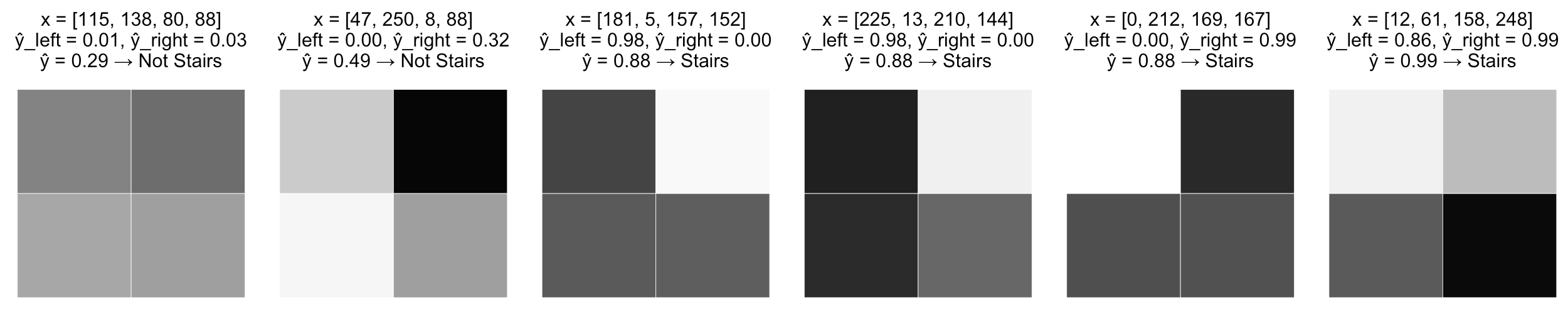
Рассмотрим задачу классификации изображений на два класса: "лестница" и "не лестница"
Нейросети

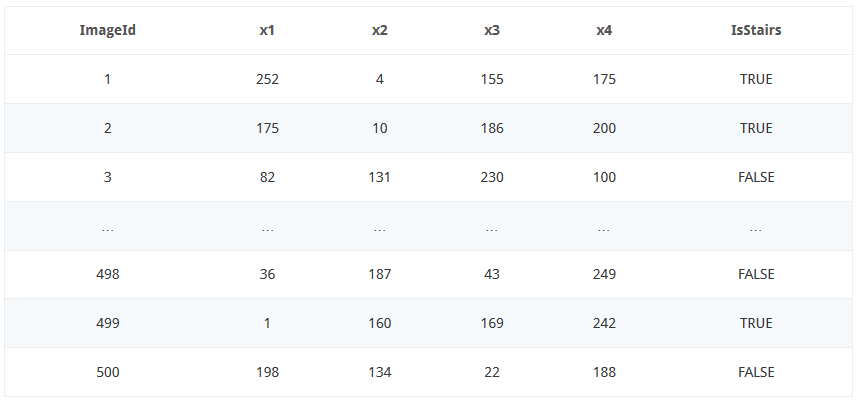
Опишем каждое изображение четырьмя признаками - интенсивностью черного цвета в каждом из пикселей
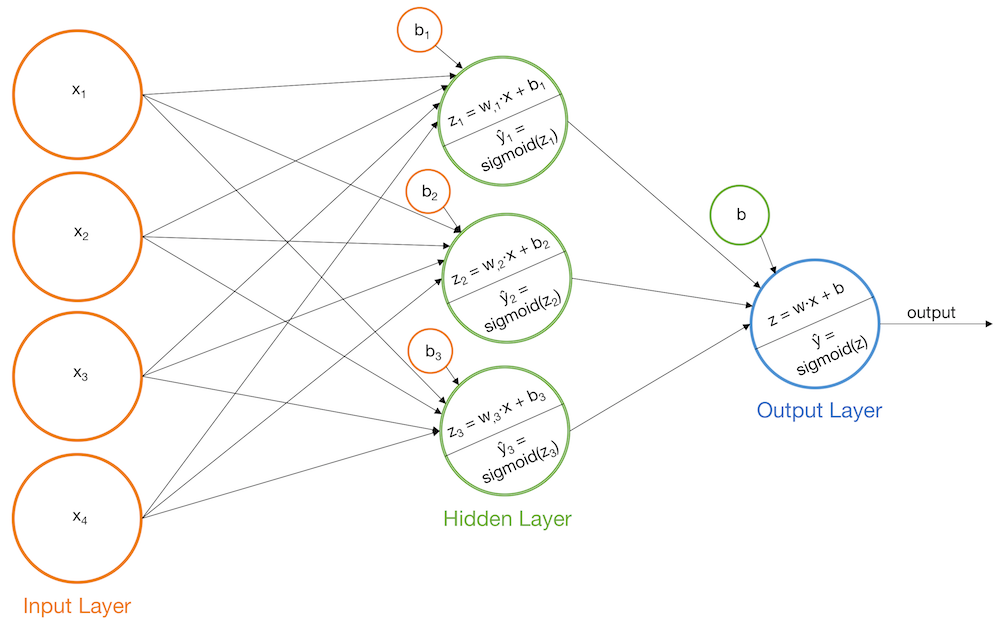
Перцептрон

Перцептрон
f(x) =
\begin{dcases}
1, w_1x_1 + w_2x_2 + w_3 x_3 + w_4 x_4 > threshold,\\
0\ в\ других\ случаях
\end{dcases}
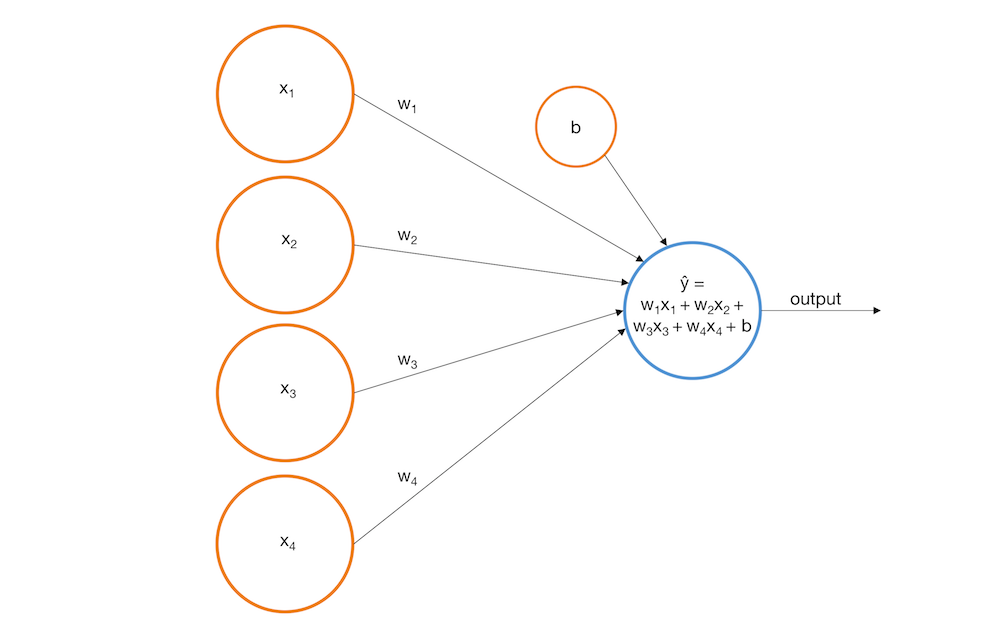
Перцептрон
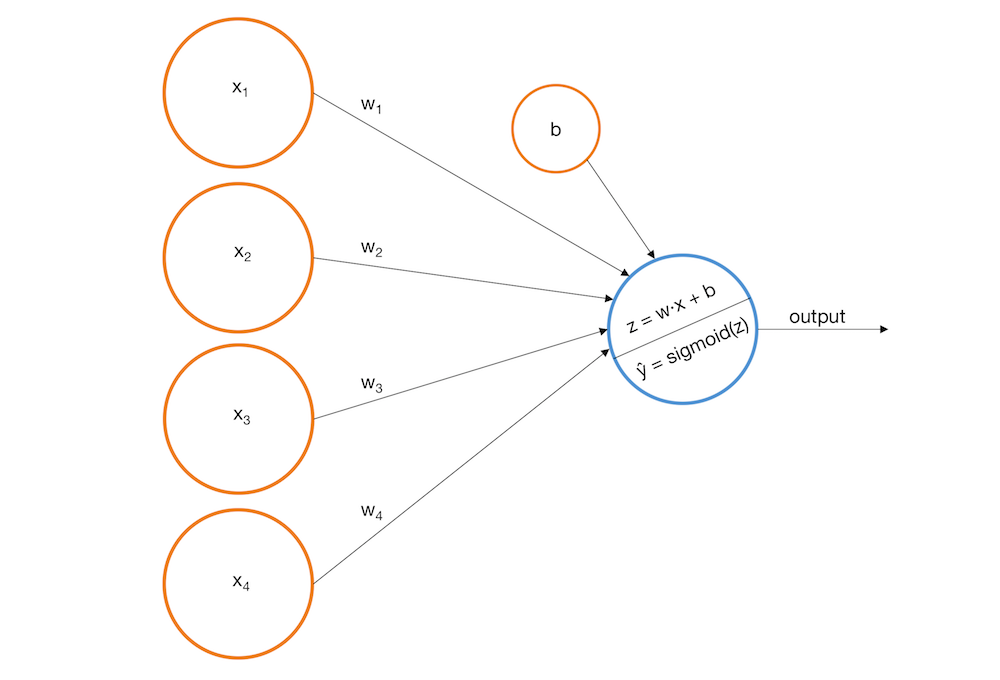
\widehat y = -0.0019x_1 + -0.0016x_2 + 0.0020x_3 + 0.0023x_4 + 0.0003 > 0
\widehat y = \vec{w}\vec{x} + b,\ где\ b = -threshold
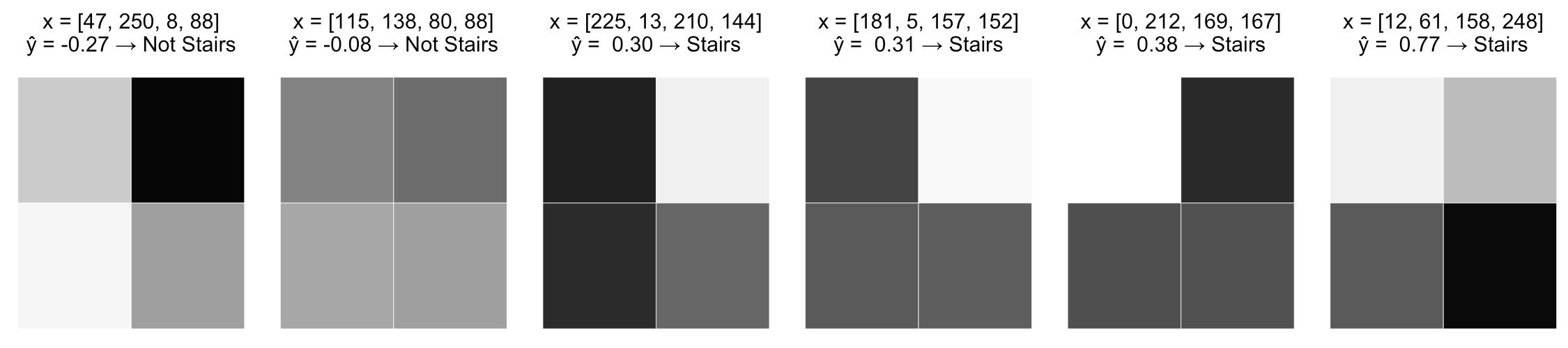
- нет вероятностной интерпретации: \(a(x) \not\subset [0, 1] \)
- модель не может ухватить нелинейные зависимости целевой переменной от признаков
(выглядит знакомо, не правда ли?)
Перцептрон
- модель не может ухватить нелинейные зависимости целевой переменной от признаков
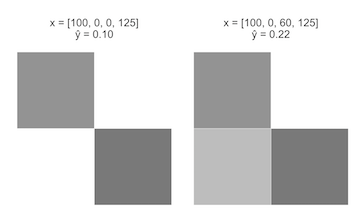
Переход к вероятностной интерпретации модели
sigmoid(z) = \frac{1}{1 + e^{-z}}
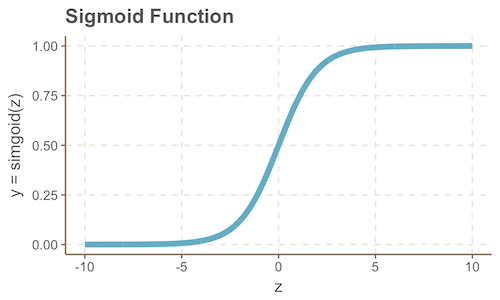
Переход к вероятностной интерпретации модели
Переход к вероятностной интерпретации модели
z = \vec{w} \cdot \vec x = w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4
\\
\widehat y = sigmoid(z) = \frac{1}{1 + e^{-z}}


Да это же логистическая регрессия!

Переход к вероятностной интерпретации модели
f(x) =
\begin{dcases}
1, \widehat y > 0.5,\\
0\ в\ других\ случаях
\end{dcases}
\widehat y = \frac{1}{1 + e^{-(-0.140x_1 -0.145x_2 + 0.121x_3 + 0.092x_4 -0.008)}}
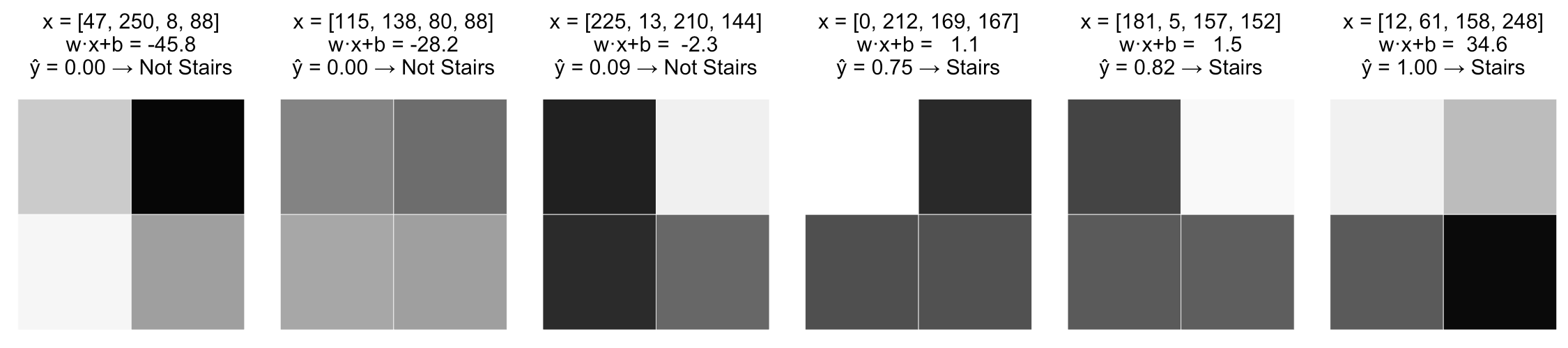
Переход к вероятностной интерпретации модели
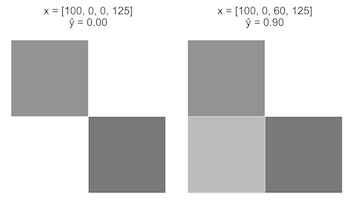

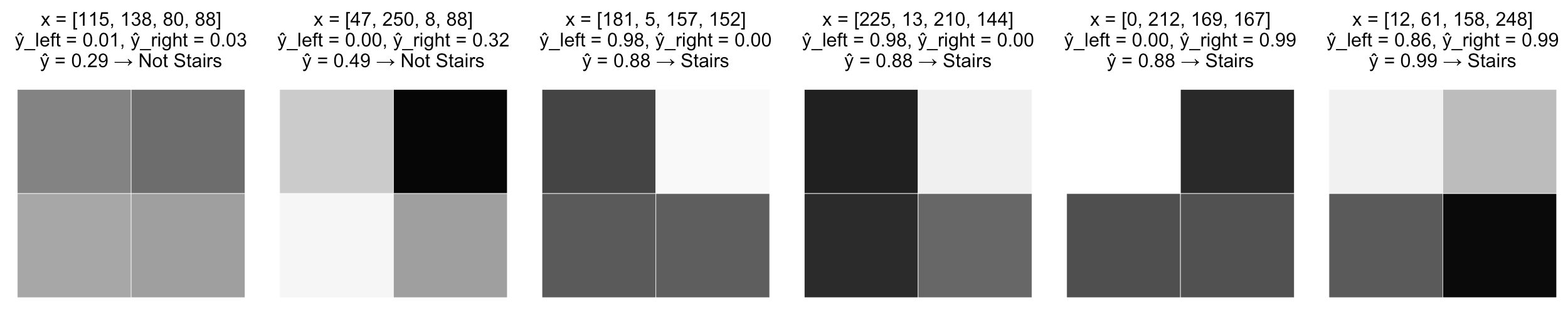
- теперь различия картинок трактуются более адекватно
Многослойные нейросети
Недостатки полученной модели
- \(\widehat y\) монотонно зависит от каждой переменной
- не учитывается взаимодействие переменных
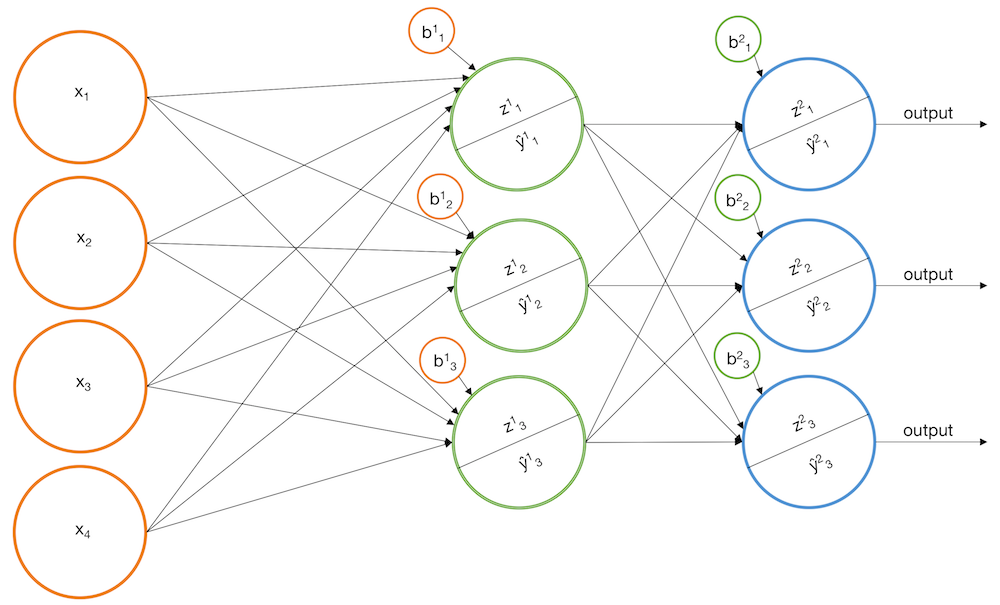
Добавим слои
- построим две модели: для "левых" и "правых" лестниц
- будем давать положительный ответ, если оба классификатора дают высокие значения вероятности
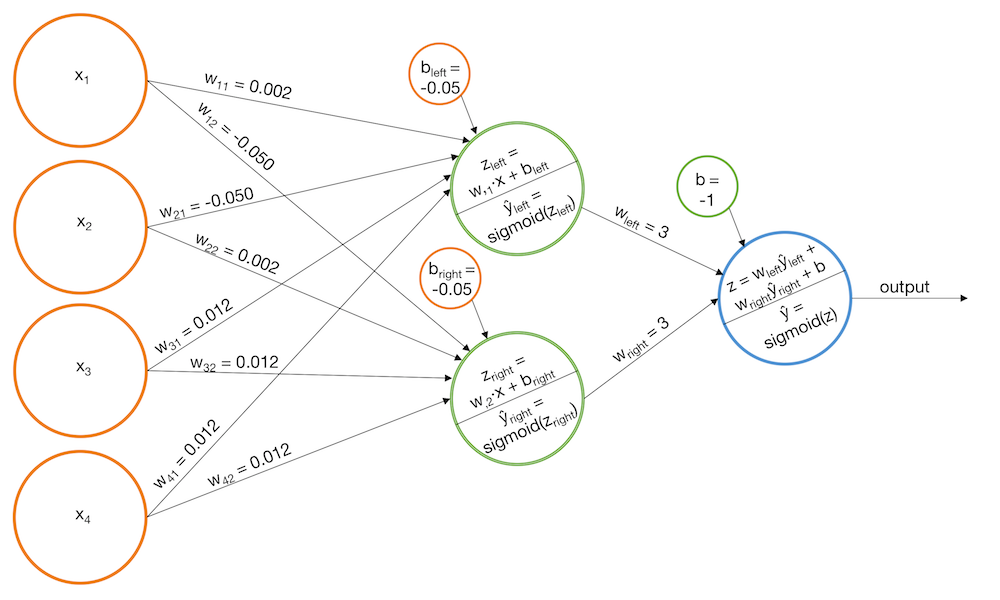
Добавим слои
- построим две модели: для "левых" и "правых" лестниц
- будем давать положительный ответ, если оба классификатора дают высокие значения вероятности
Другой вариант новых слоев
- построим модель, срабатывающую на темный нижний ряд
- модель, когда верхний левый пиксель темный, правый верхний - светлый и модель, когда верхний правый пиксель темный, верхний левый светлый
- финальная модель срабатывает тогда, когда 1 и 2 значения велики либо когда 1 и 3 значения велики
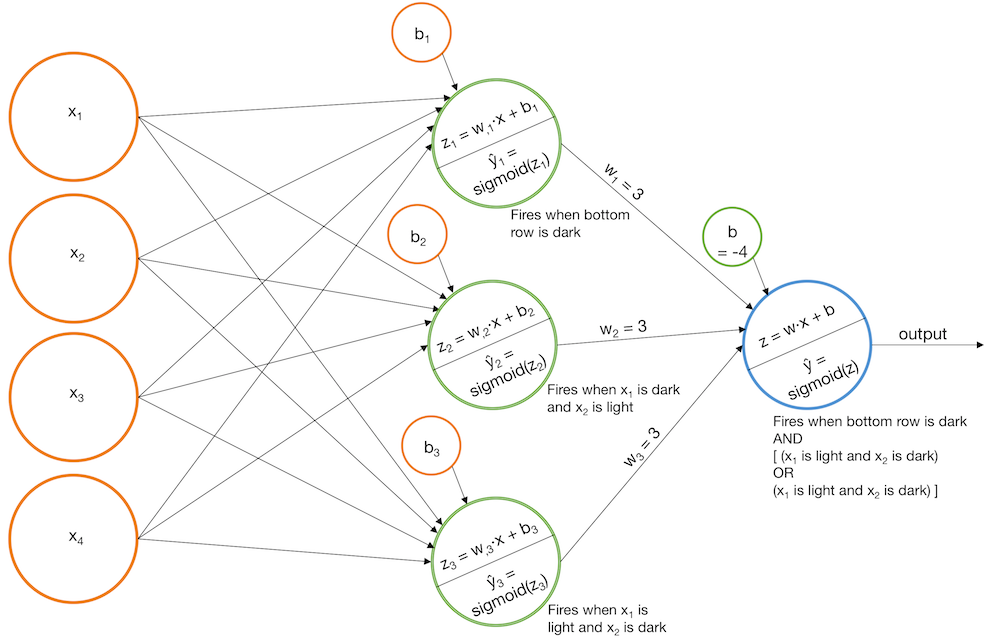
Другой вариант новых слоев
- построим модель, срабатывающую на темный нижний ряд
- модель, когда верхний левый пиксель темный, правый верхний - светлый и модель, когда верхний правый пиксель темный, верхний левый светлый
- финальная модель срабатывает тогда, когда 1 и 2 значения велики либо когда 1 и 3 значения велики
Нейронная реализация логических функций
\(x^1 \land x^2 = [x^1 + x^2 - \frac{3}{2} > 0]\)
\(x^1 \vee x^2 = [x^1 + x^2 - \frac{1}{2} > 0]\)
\(\neg x^1 = [-x^1 + \frac{1}{2} > 0]\)

Нейронная реализация логических функций
\(x^1 \oplus x^2 = [x^1 + x^2 - 2 x^1 x^2 - \frac{1}{2} < 0\)]
\(x^1 \oplus x^2 = [(x^1 \vee x^2) - (x^1 \land x^2) - \frac{1}{2} > 0]\)

Термины в нейросетях
Обобщение на несколько классов
\sigma = softmax(w_1 x, ..., w_K x) = \frac{exp( w_k x)}{\sum\limits_{i=1}^{K} exp(w_i x)}
Функции активации
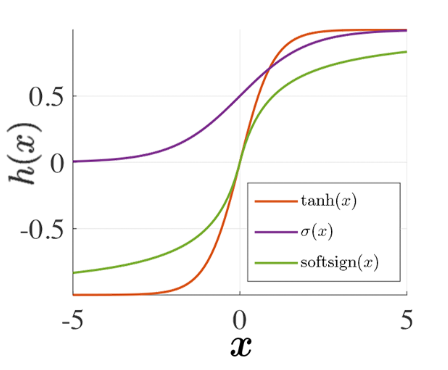
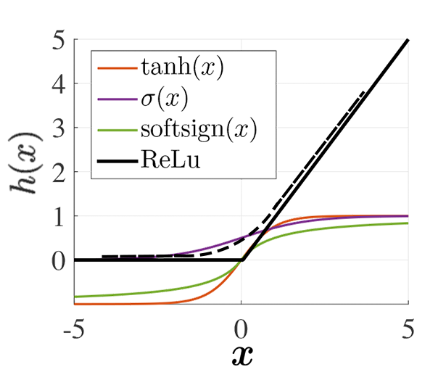
tanh(x) = \frac{exp(2x)-1}{exp(2x)+1}
softsign(x) = \frac{x}{1+|x|}
ReLu(f) = max(0, f)
eLu = ln(1+exp(f))
- непрерывно монотонные, лучше - дифференцируемые
Настройка многослойных нейросетей
Комбинация однослойных сетей
Однослойная сеть:
\(a(\vec x, \vec w) = \sigma(\vec w \vec x) = \sigma(\sum\limits_{j=1}^d w_j^{(1)} x_j + w_0^{(1)} ) \)
Двуслойная сеть:
\( a(\vec x, \vec w) = \sigma^{(2)} (\sum\limits_{j=1}^D w_i^{(2)} \sigma^{(1)} (\sum\limits_{j=1}^d w_{ji}^{(1)} x_j + w_{0i}^{(1)} ) + w_0^{(2)} ) \)
Соединенный вектор параметров:
\( \vec w = \{w_i^{(2)}, w_{ij}^{(1)}, w_{i0}^{(1)}, w_0^{(2)} \} \)
Задача оптимизации:
\(\vec w^{*} = \arg \min\limits_{\vec w} Q(\vec w) \)
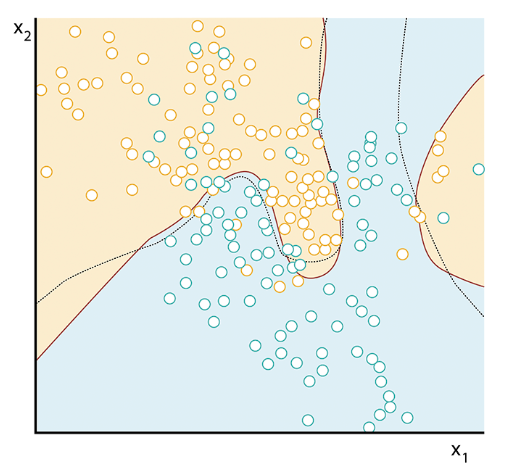
Разделяющая поверхность
уже необязательно линейная
Теорема Колмогорова
Каждая непрерывная функция \(a(x)\), заданная на единичном кубе d-мерного пространства, представима в виде:
a(x) = \sum\limits_{i=1}^{2d+1} \sigma(\sum\limits_{j-1}^d f_{ij}(x_j))
где \(x = [x_1, ..., x_d]^T\), функции \(\sigma_i(\dot), f_{ij}(\dot) \) непрерывны, причем \(f_{ij}\) не зависят от выбора \(a\)
Универсальная теорема аппроксимации (Хорника)
Искусственная нейросеть прямой связи с одним скрытым слоем может аппроксимировать любую непрерывную функцию многих переменных с любой точностью. Условиями для этого являются достаточное количество нейронов скрытого слоя и удачный подбор весов модели.
Причина частого выбора глубоких архитектур нейронных сетей вместо сетей с одним скрытым слоем заключается в том, что при процедуре подбора они обычно сходятся к решению быстрее.
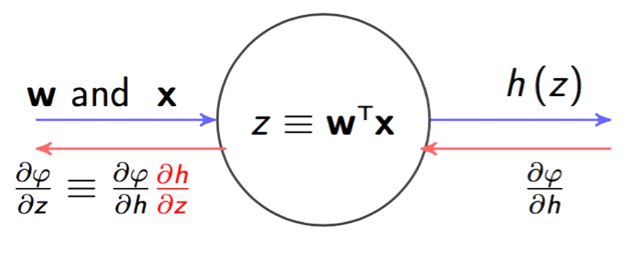
Метод обратного распространения ошибки
Имеем размеченные данные, выбрали дифференцируемую функцию потерь и архитектуру сети
- инициализируем сеть со случайными параметрами
- считаем предсказания на обучающей выборке, получаем первоначальный \(L(\widehat Y, Y)\)
- вычисляем \(\nabla L\) с учетом каждого веса в сети
- шаг в сторону антиградиента

Регуляризация нейросетей
Как и у других линейных методов:
\vec w^* = \arg\min\limits_{\vec w} [Q(\vec w) + \tau \sum\limits_{i, j, k}(w_{ij}^{(k)})^2]
- не снижает число параметров, не упрощает структуру сети
- при увеличении \(\tau\) параметры перестают изменяться
Прореживание нейросетей
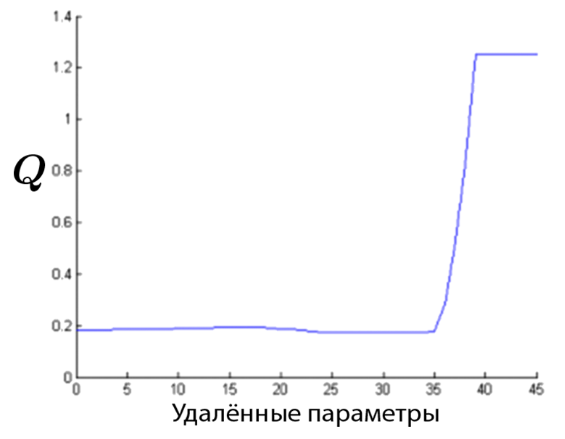
Удаляем параметр, если:
- его значение близко к 0
- его значение сильно изменяется при изменении выборки
- его удаление незначительно влияет на значение функционала ошибки
Dropout
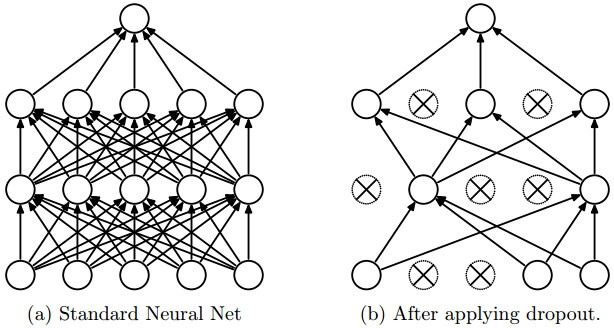
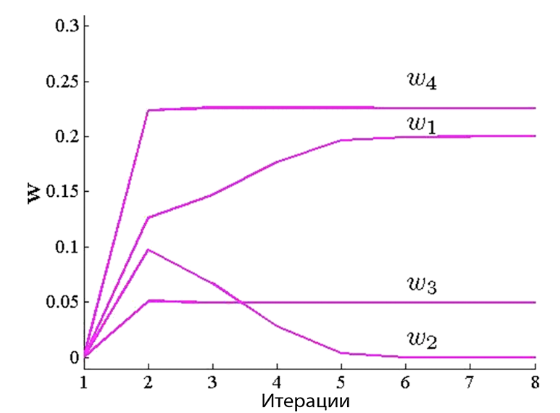
Стабилизация параметров нейросетей
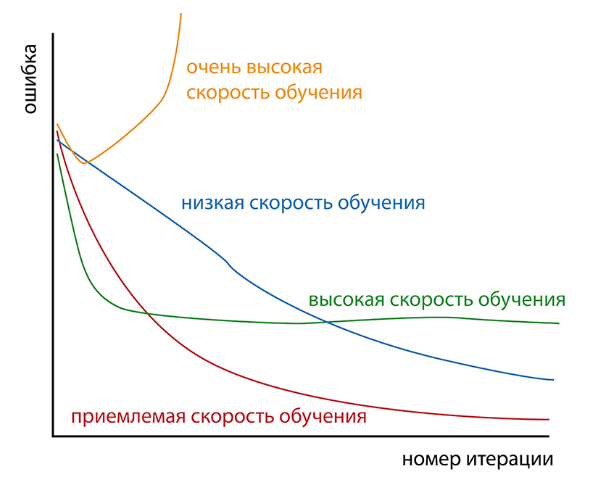
Скорость обучения нейросетей
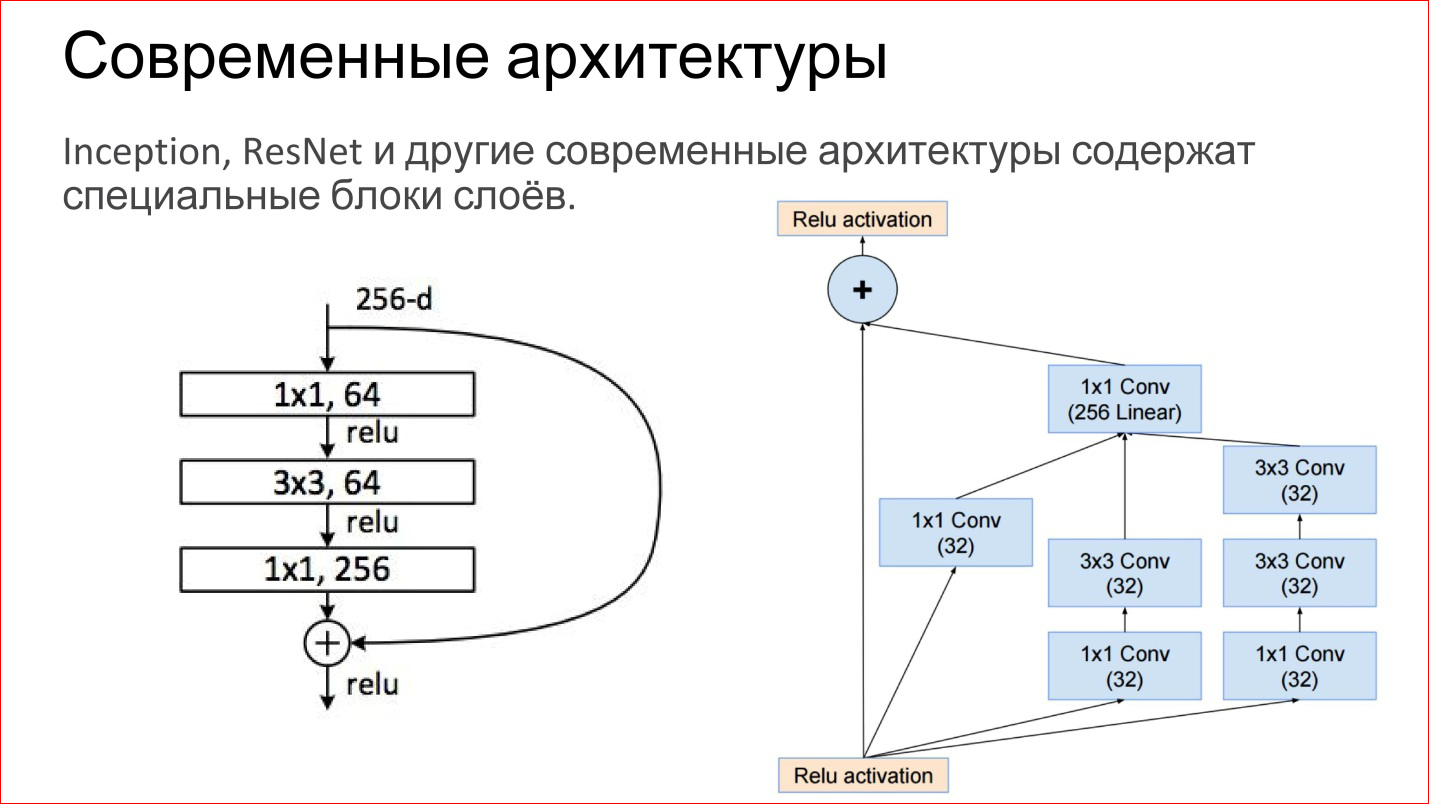
Архитектуры нейросетей
Сверточные нейросети

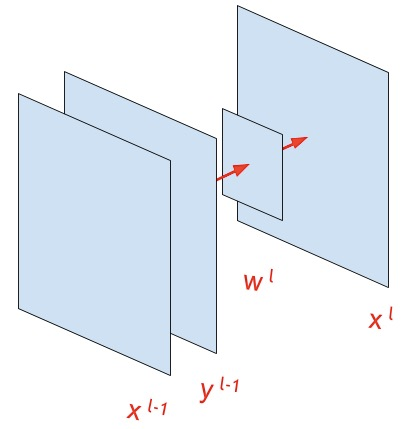
Свертка изображения (convolution)
x^l_{ij}=\sum\limits_{a=-\infty}^{+\infty}\sum\limits_{b=-\infty}^{+\infty}w^l_{ab}\cdot y^{l-1}_{(i\cdot s-a)(j\cdot s-b)}+b^l \qquad \forall i\in (0,...,N) \enspace \forall j\in (0,...,M)
Слой макспуллинга
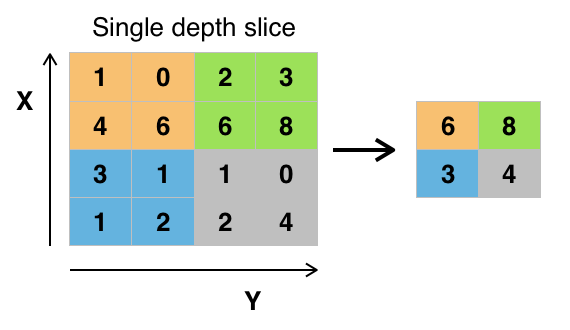
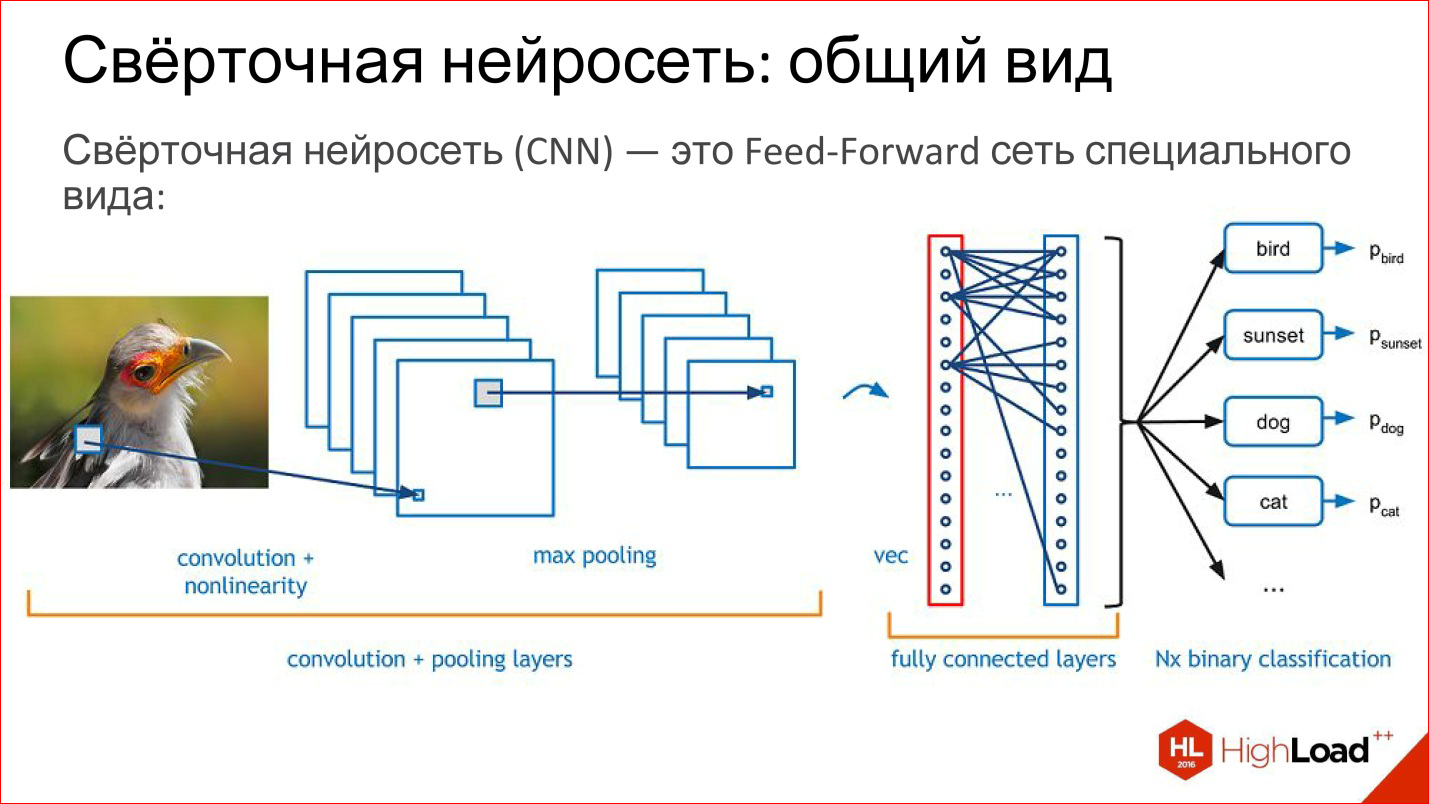
Сверточные сети
Сверточные сети
Рекуррентные нейросети
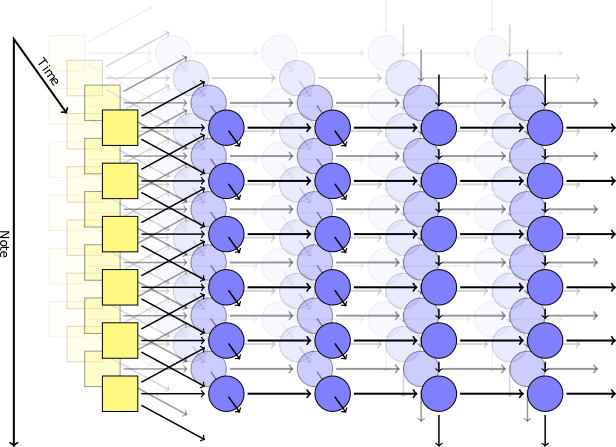
Рекуррентные нейросети
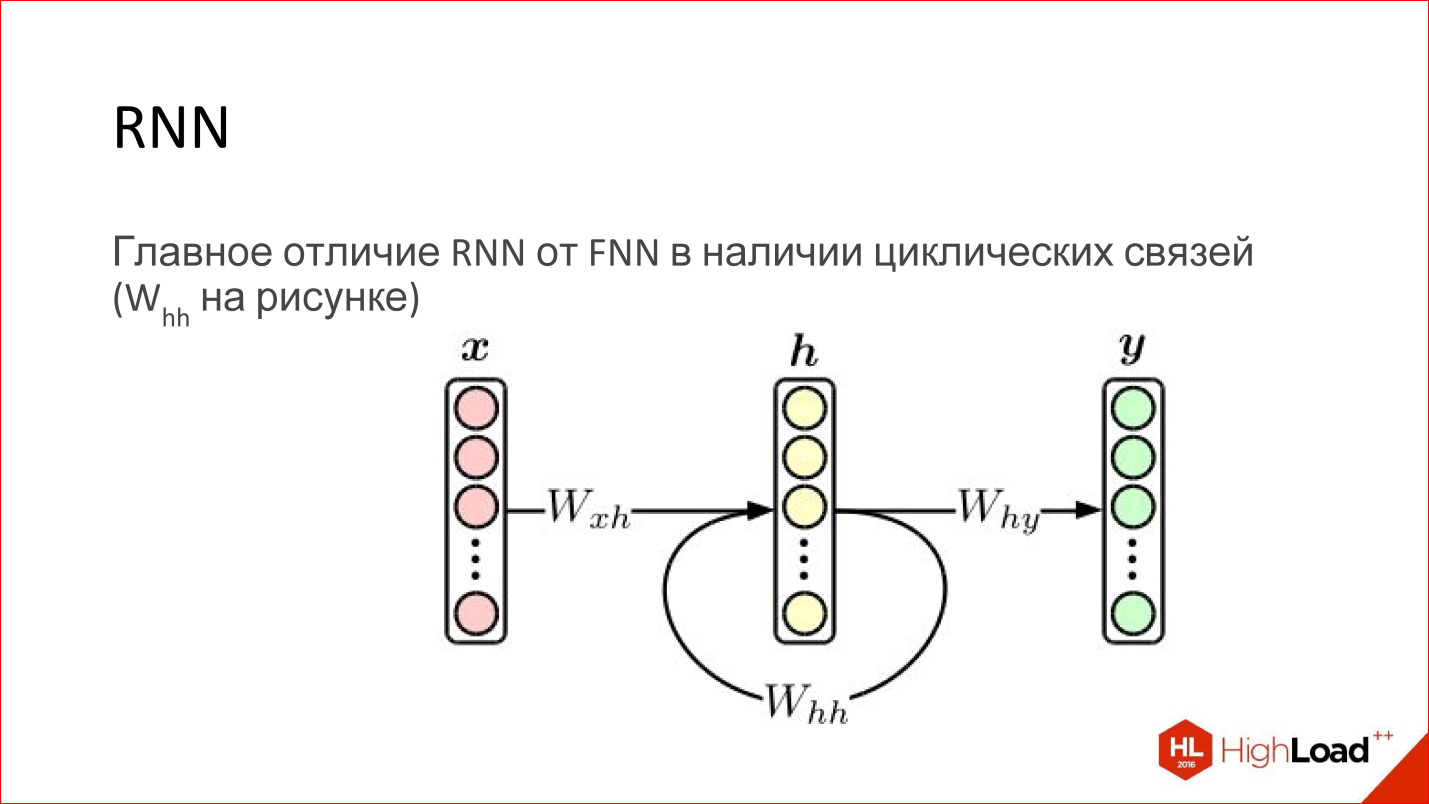
Введение в keras
Серьезное исследование

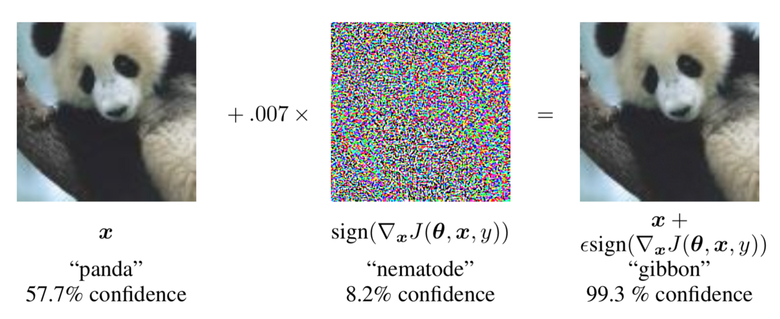
Атаки на нейросети
Ошибочная классификация
\(w^{\top }\widetilde{x}=w^{\top }x + w^{\top }\eta\)
Атака одного пикселя

Атаки-заплатки

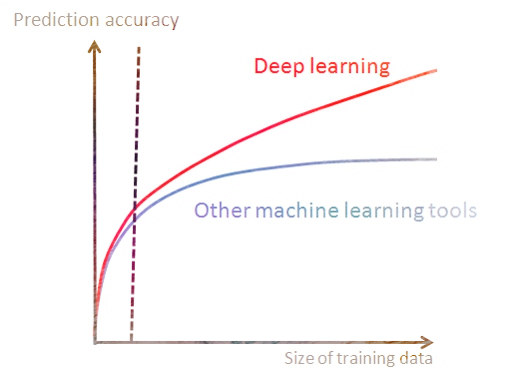
Кривые обучения
Распознавание лиц
Задание на лабу
- собрать набор фотографий участников вашей команды
- обучить нейронку так, чтобы она хорошо классифицировала новые фотографии участников
Рекомендация: сохранить модель или ее веса с помощью методов save или save_weights, чтоб на защите ее быстро подгрузить
Нейросети
By romvano




