Эмбеддинги
изменение размерности признакового пространства
Метод главных компонент (PCA)

Представим выборку в ортогональном базисе
Метод главных компонент (PCA)

Как отобразить большую кучу признаков в маленькую кучу признаков?
Метод главных компонент (PCA)
cov(X_i, X_j) = E[(X_i - \mu_i) (X_j - \mu_j)] = E[X_i X_j] - \mu_i \mu_j
Ковариация признаков:
\Sigma = E[(\mathbf{X} - E[\mathbf{X}]) (\mathbf{X} - E[\mathbf{X}])^{T}]
Матрица ковариации:
Матрица ковариации представляет собой симметричную матрицу, где на диагонали лежат дисперсии соответствующих признаков, а вне диагонали — ковариации соответствующих пар признаков
Главные компоненты - собственные вектора матрицы (\(M w_i = \lambda_i w_i\))
Метод главных компонент (PCA)
Подпространство исходных признаков
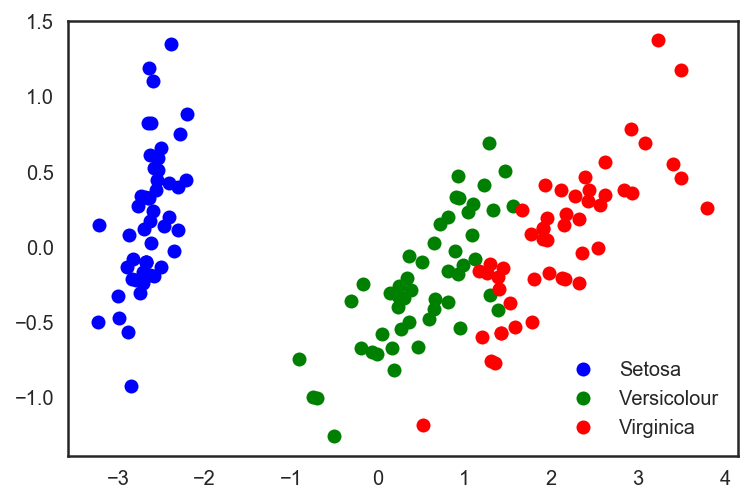
Метод главных компонент (пример)
Метод главных компонент (пример)
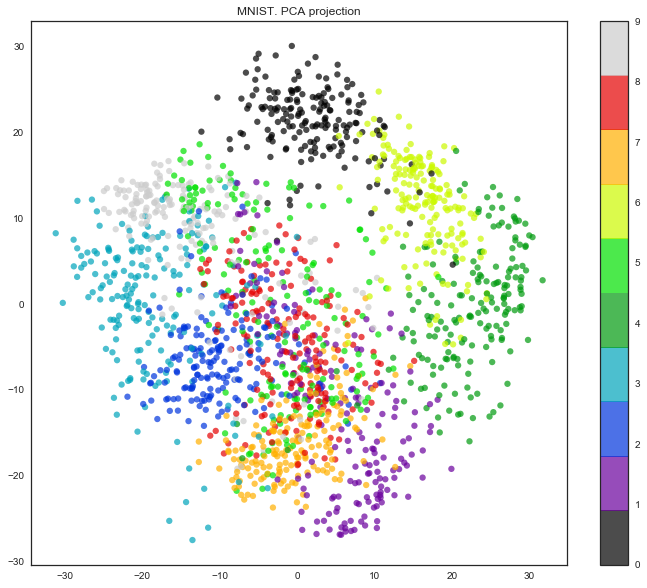
Метод главных компонент (пример)

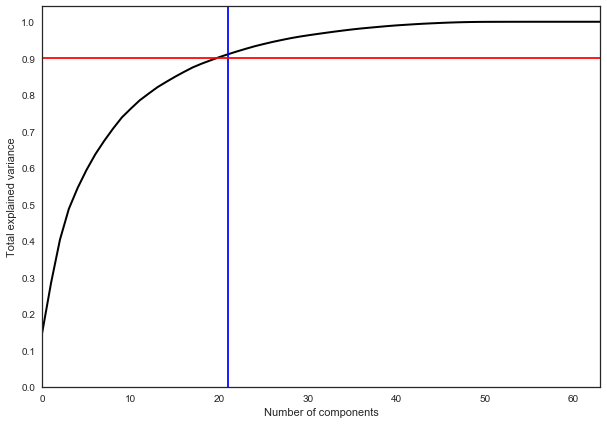
Метод главных компонент (когда остановиться?)
Автоэнкодеры
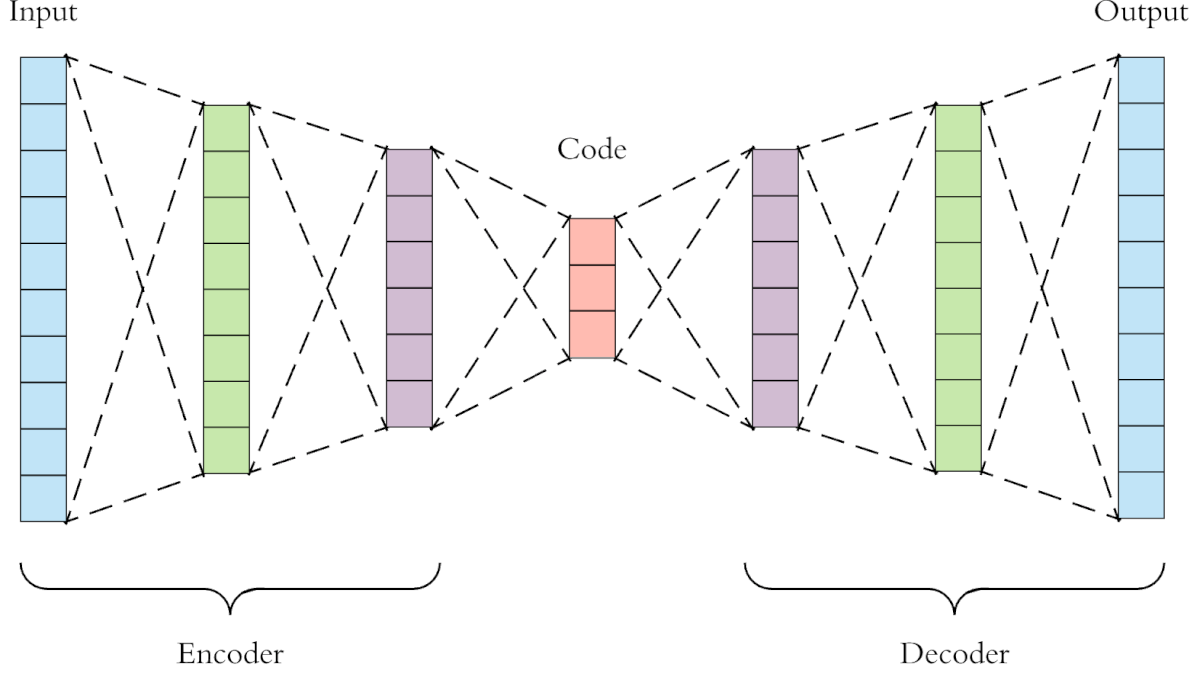
Автоэнкодеры

Основные задачи:
- сглаживание шума;
- снижение размерности.
Эмбеддинги
изменение размерности данных
Текстовые эмбеддинги и задачи NLP
Bag of words

Sparse matrix encoding

TF-IDF
tf(t, d) = \frac{n_t}{\sum\limits_k n_k}
idf(t, D) = log(\frac{\#D}{\#\{d_i \in D|t \in d_i\}})
tf-idf(t, d, D) = tf(t, d) * idf(t, D)
d - документ, D - множество документов, t - слово
TF-IDF
s = ['Mars has an athmosphere', "Saturn 's moon Titan has its own athmosphere",
'Mars has two moons', 'Saturn has many moons', 'Io has cryo-vulcanoes']
Модель Миколова
P(w_o| w_c)=\frac{e^{s(w_o, w_c)}}{\sum_{w_i \in V} e^{s(w_i, w_c)}}
Предположим, что вероятность появления слова в данном месте зависит от контекста, тогда:
\(w_o\) - вектор слова;
\(w_c\) - вектор контекста;
\(s(w_o, w_c)\) - мера расстояния между этими векторами (например, косинусная)
Word2vec

учитываются:
- синтаксические связи
- семантические связи
Word2vec
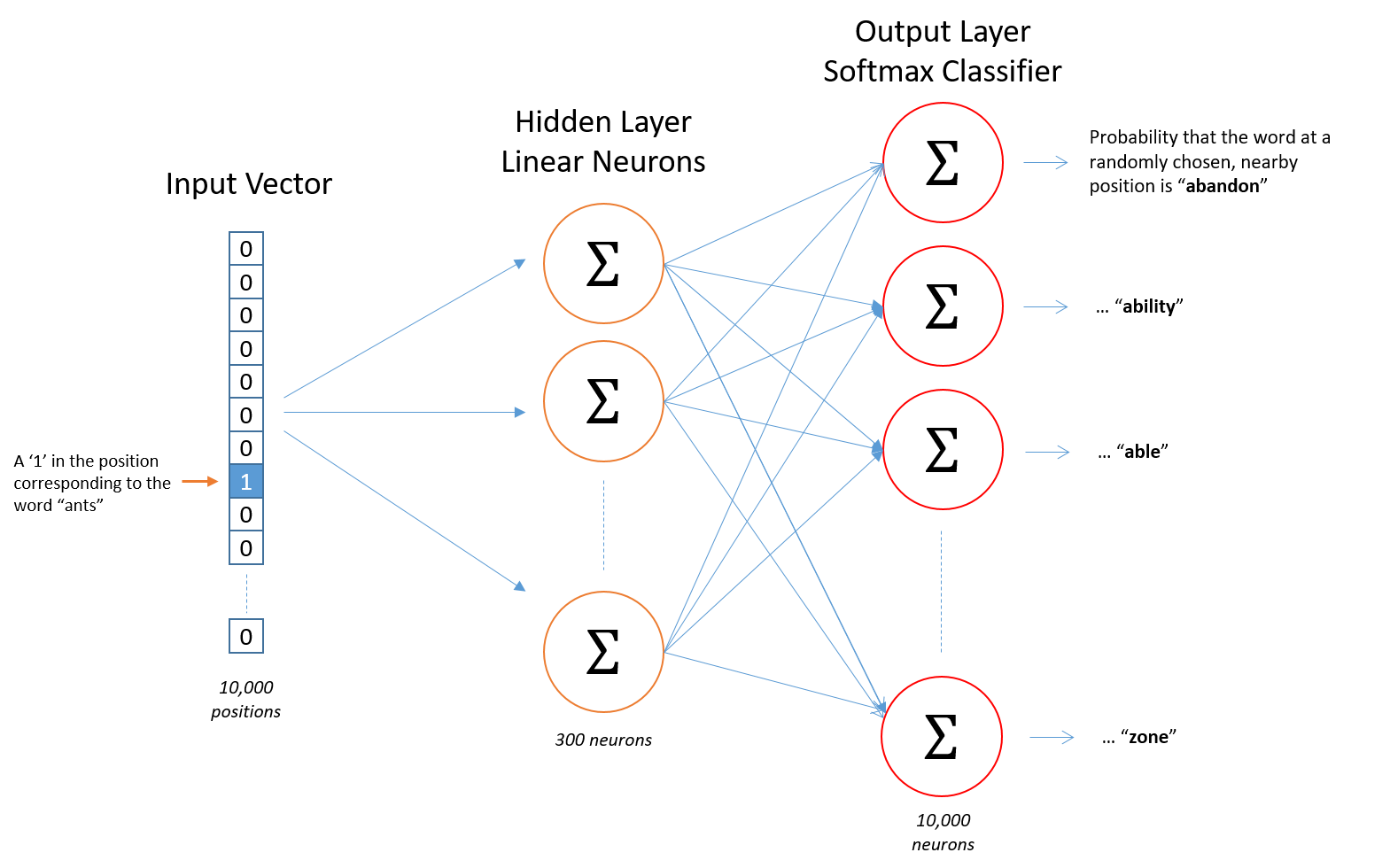
Word2vec: hidden layer
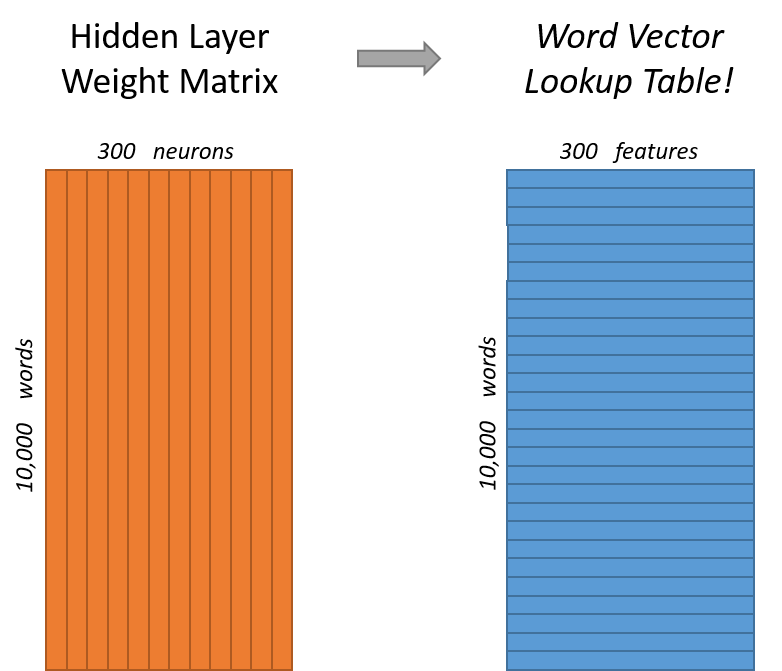

Word2vec: output layer
- каждый нейрон в выходном слое соответствует слову из словаря
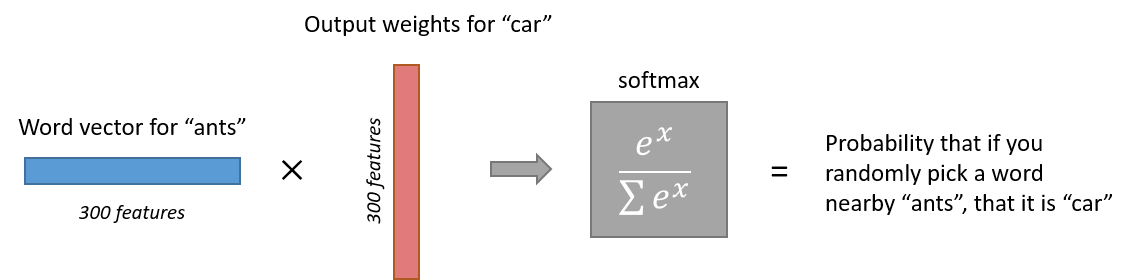
- перемножая выход предыдущего слоя для одного слоя с весами другого и оборачивая результат в сигмоиду, получаем вероятность того, что эти два слова будут расположены рядом в контексте
Представление текстовых эмбеддингов

Представление текстовых эмбеддингов

Представление текстовых эмбеддингов

Текстовые эмбеддинги: практика
Задание на лабу
- провести классификацию русских текстов на несколько категорий. Лучше всего, если корпус текстов будет реально большим
- провести предобработку текстов: нормализацию, лемматизацию и т.д.
- сравнить эмбеддинги
- попробовать несколько методов классификации
Эмбеддинги и обработка текстов
By romvano




