

Ronald Kurr
Long time software developer.
Create an S3-backed, point-in-time snapshot of a running instance from the AWS console.
Create an image of an operating system that is pre-configured for a particular purpose
The scale up pattern is a method that allows a server to change size and specifications dynamically, and as needed.
Tie 2 or more instances together to add processing power without incurring downtime
Increase the disk on an already running EC2 instance
A variation of the scale-out pattern where availability is the primary concern and is not dynamic
A nuanced version of the multi-server pattern where multiple availability zones are used
Provides a way to apply zero downtime updates when a load balancer is not being used.
The deep health check pattern lets the instances connected to the load balancer notify the load balancer of health checks beyond the grasp of the load balancer itself.
Leverage S3 to store static text and binary web assets, letting Amazon deal with the redundancy, encryption and failover
For static web sites, remove the web server from the Direct Storage Hosting pattern and let S3 serve up the entire site.
Secure access to S3 assets using a time-sensitive URL
Ensure that data does not have to travel far to reach the end user, reducing latency and improving the end user experience.
Gets new versions of data out to the user in such a way as to ensure that old data is not being used. Also known as "cache busting"
Dynamically created clones of a static master server are created as needed.
Similar to the Clone Server pattern but we replace rsync with NFS
Share session information between applications via a fast, in-memory cache.
Improve upon the Clone Server and NFS Sharing patterns by storing data in S3.
If CloudFront is taking too long replicating your data out to its edge nodes, cache the data yourself
Instead of using HTML form uploads to add data, use alternative protocols to upload the data and have the web front-end read it back from S3.
To avoid unnecessary S3 API calls, and the cost associated with them, keep and index of meta-data associated with each uploaded item.
Leverage S3's robust HTTP upload support and allow direct uploads to S3.
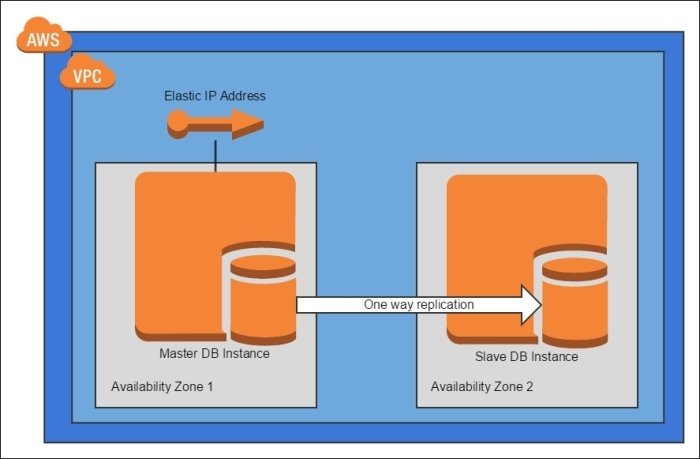
Create two instances of your database and use its master-slave support to deal with network partitions and server crashes
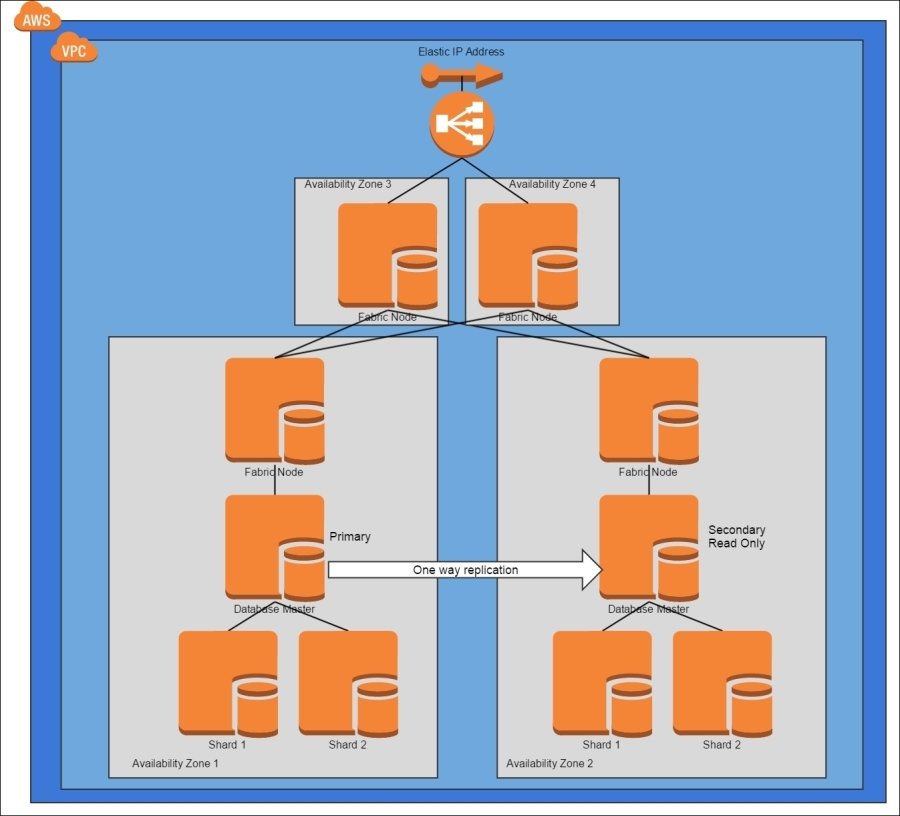
Variation of the Database Replication pattern where the secondary is used for read-only operations
Applications avoid hitting the database by caching previous query results
Improve the Read Replica pattern by sending writes to multiple databases
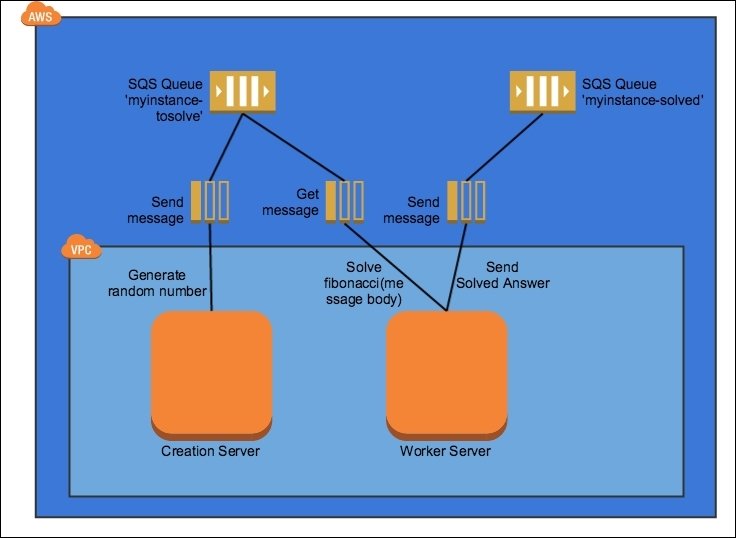
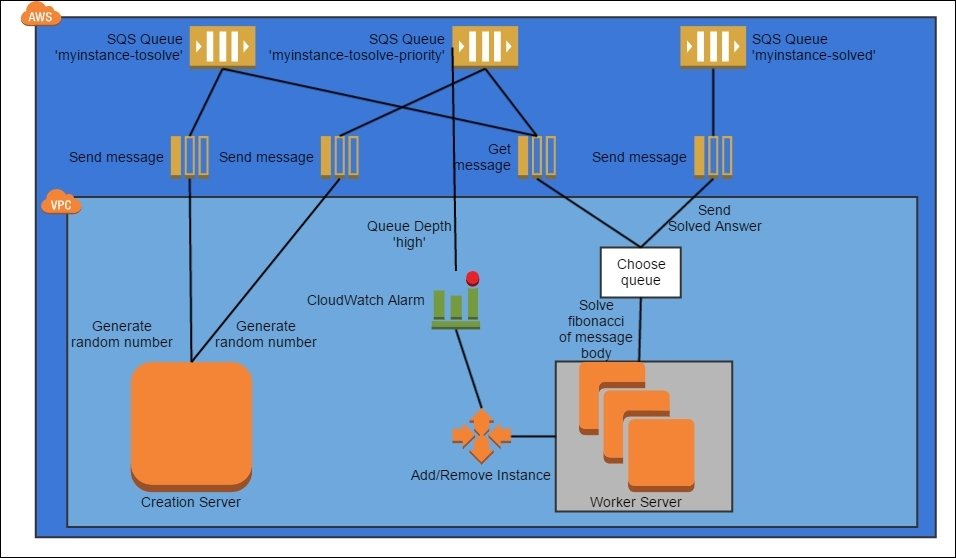
Move work through the system via a series of message queues.
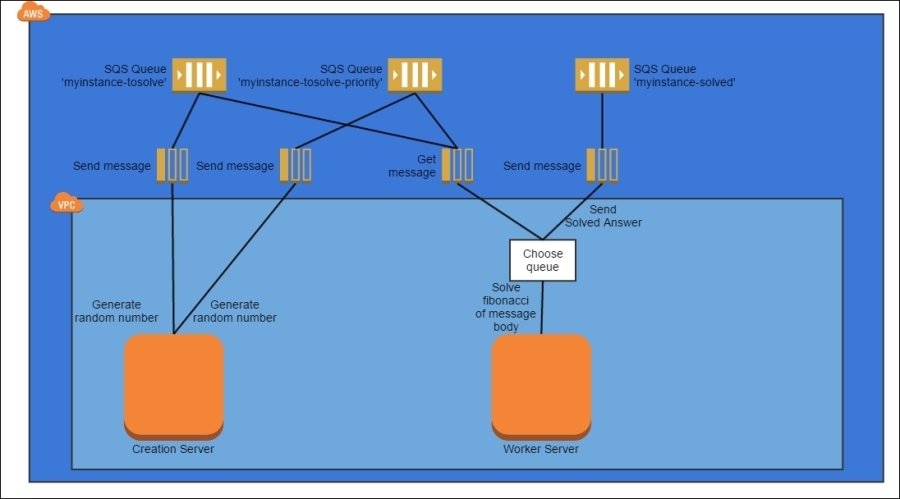
Variation of the Queuing Chain pattern where certain queues are considered more important than others and get priority attention
Dynamically scale message consumers by leveraging CloudWatch
Enhancement to the Stamp pattern where customizations are applied at instance start up
Variation of the Bootstrap pattern where the boot script behavior is controlled by the context of the instance being launched
Use CloudFormation to generate your application stack from a customized template or existing catalog of templates
Use CloudWatch to monitor your infrastructure and alarm you when things become abnormal
The idea that logs are rotated out of the instance into S3
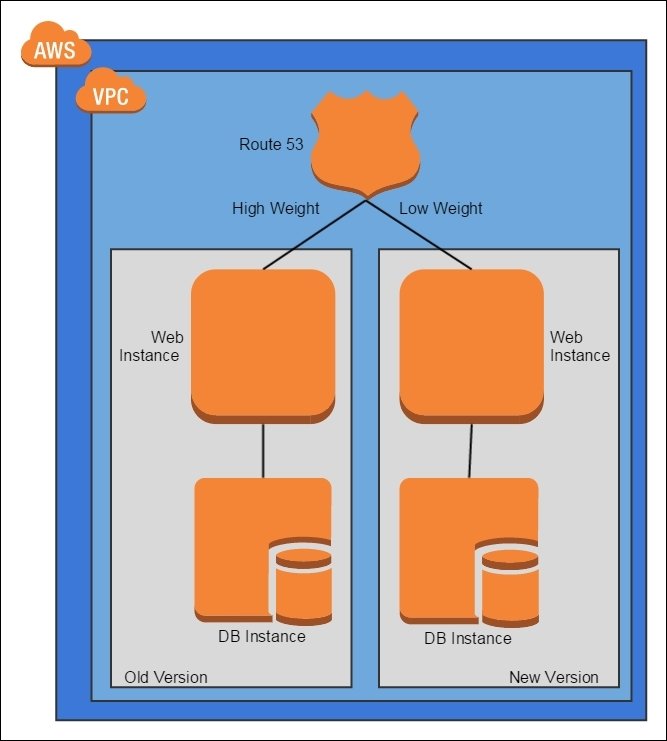
When rolling out new bits, direct a small portion of the traffic to the new bits to prove them out
Not covered in depth but the idea is to backup on-premises application data to the cloud
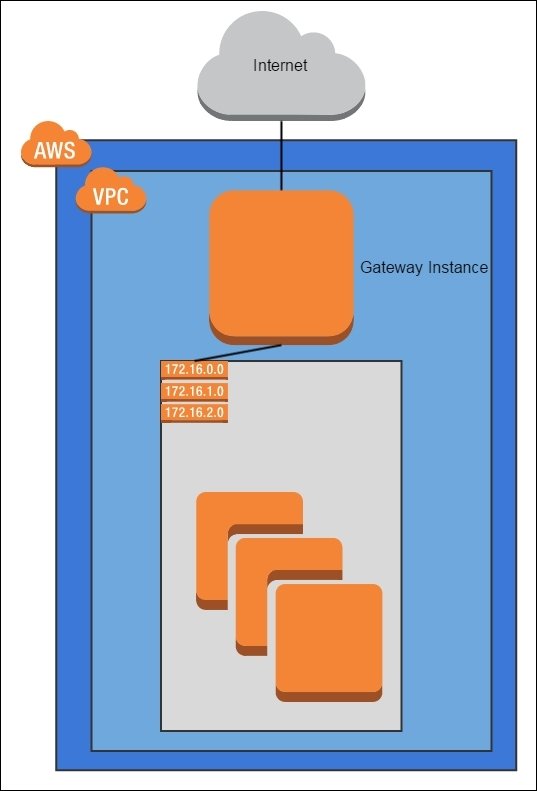
For security reasons, keep your instances off the internet and in a private subnet. Use a NAT router to temporarily enable internet access as needed.
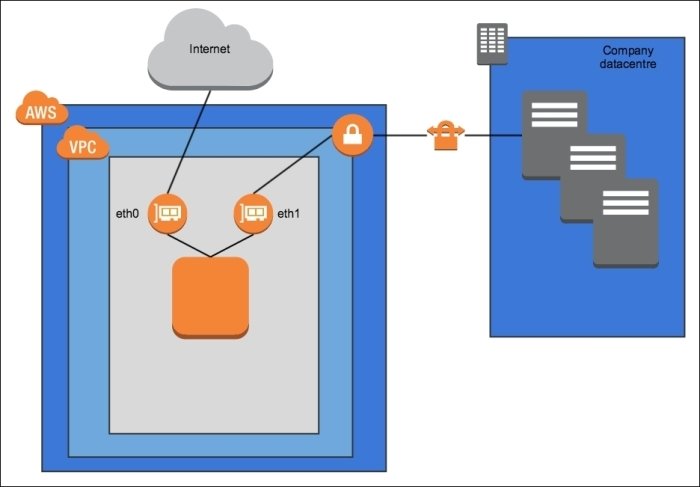
Use dual NICs to control data meant for the internet and data meant for the corporate network
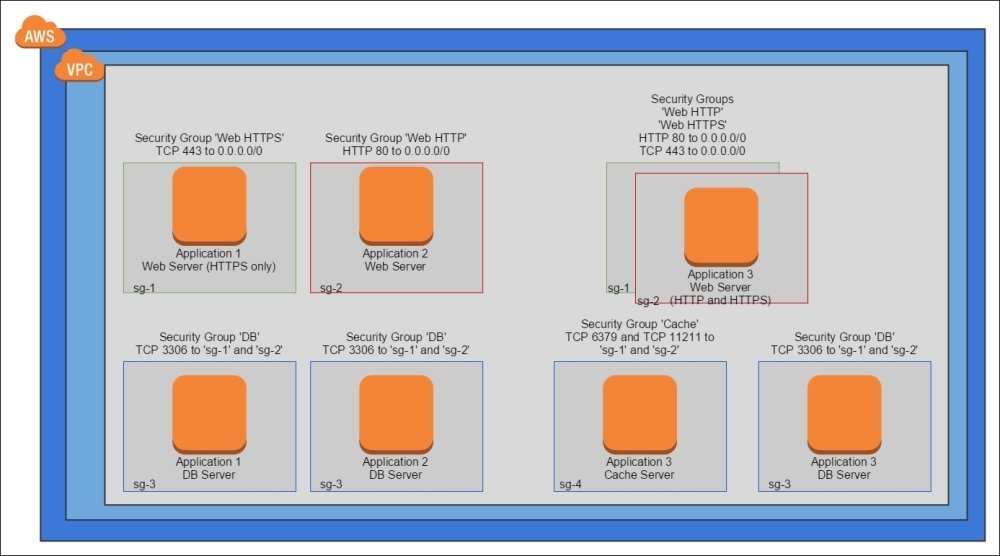
Stack individual security groups to achieve firewall rules that are easier to manage
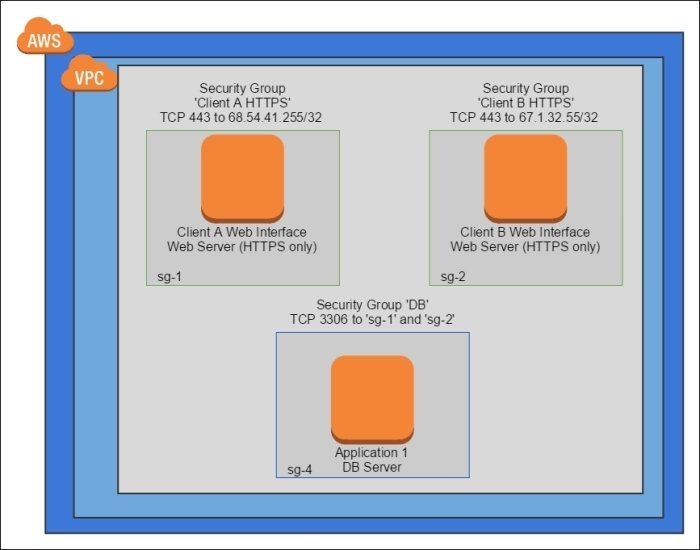
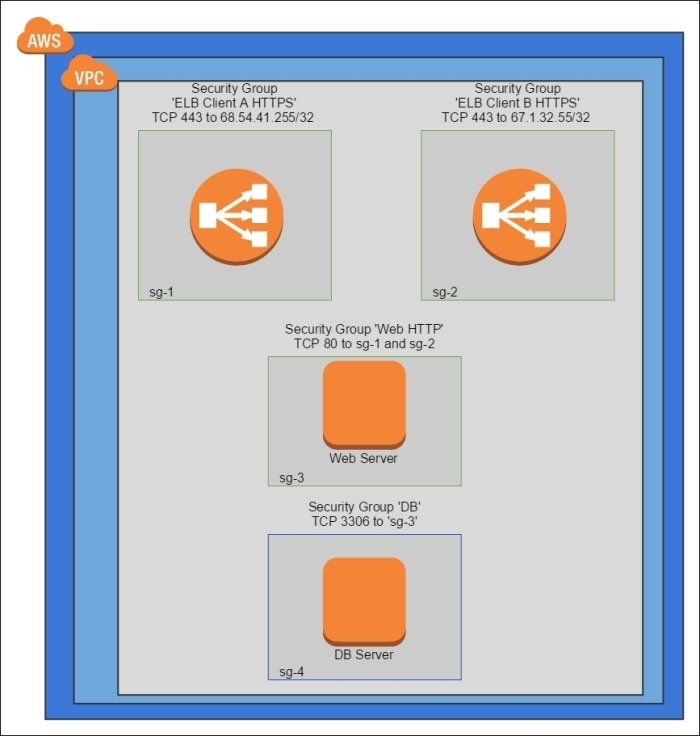
Stricter version of the Functional Firewall that restricts the incoming traffic from a specific source
Not cloud-specific but a general approach.
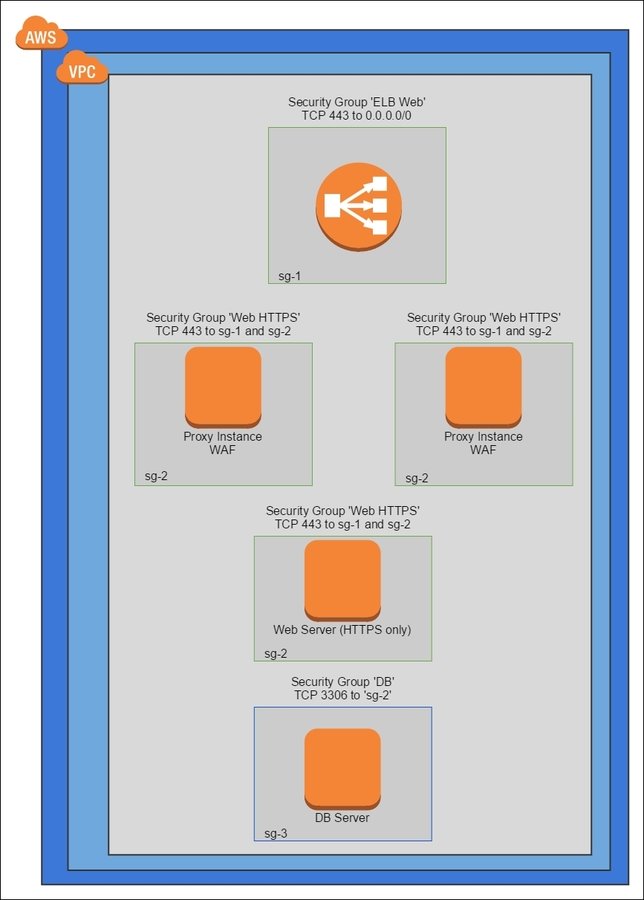
AWS WAF is a web application firewall that helps protect your web applications from common web exploits that could affect application availability, compromise security, or consume excessive resources. AWS WAF gives you control over which traffic to allow or block to your web applications by defining customizable web security rules. You can use AWS WAF to create custom rules that block common attack patterns, such as SQL injection or cross-site scripting, and rules that are designed for your specific application. New rules can be deployed within minutes, letting you respond quickly to changing traffic patterns.
Variation of the Operational Firewall
Apply the same techniques to operational concerns that you do to production code
Use virtualized environment coupled with automated AWS scripting to develop in near production environment
Leverage AWS to run your CI builds
By Ronald Kurr
A summary of the patterns described in the book "Implementing Cloud Design Patterns for AWS"




