


Ronald Kurr
Long time software developer.
Ron Kurr
06/18/2016
We'll be examining the notion of designing systems around a distributed, unified log stream. The concept isn't new and is gaining traction as enabling technologies mature and solutions become increasingly complex. We'll define terms, provide an overview of the concepts and explore a possible application.
Kirk fired phasers at target designate Zulu on Stardate 102435.4
Update user Skywalker's e-mail address to luke@disney.com
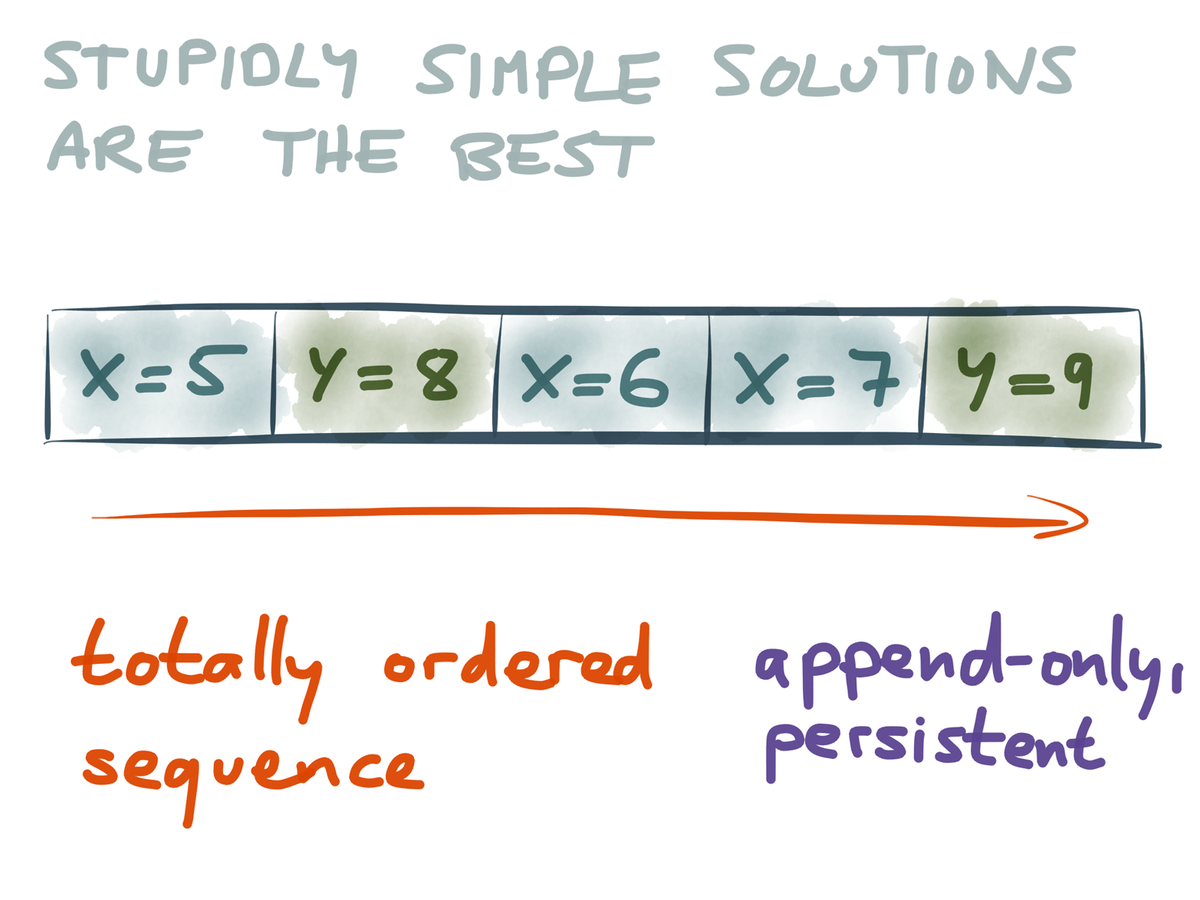
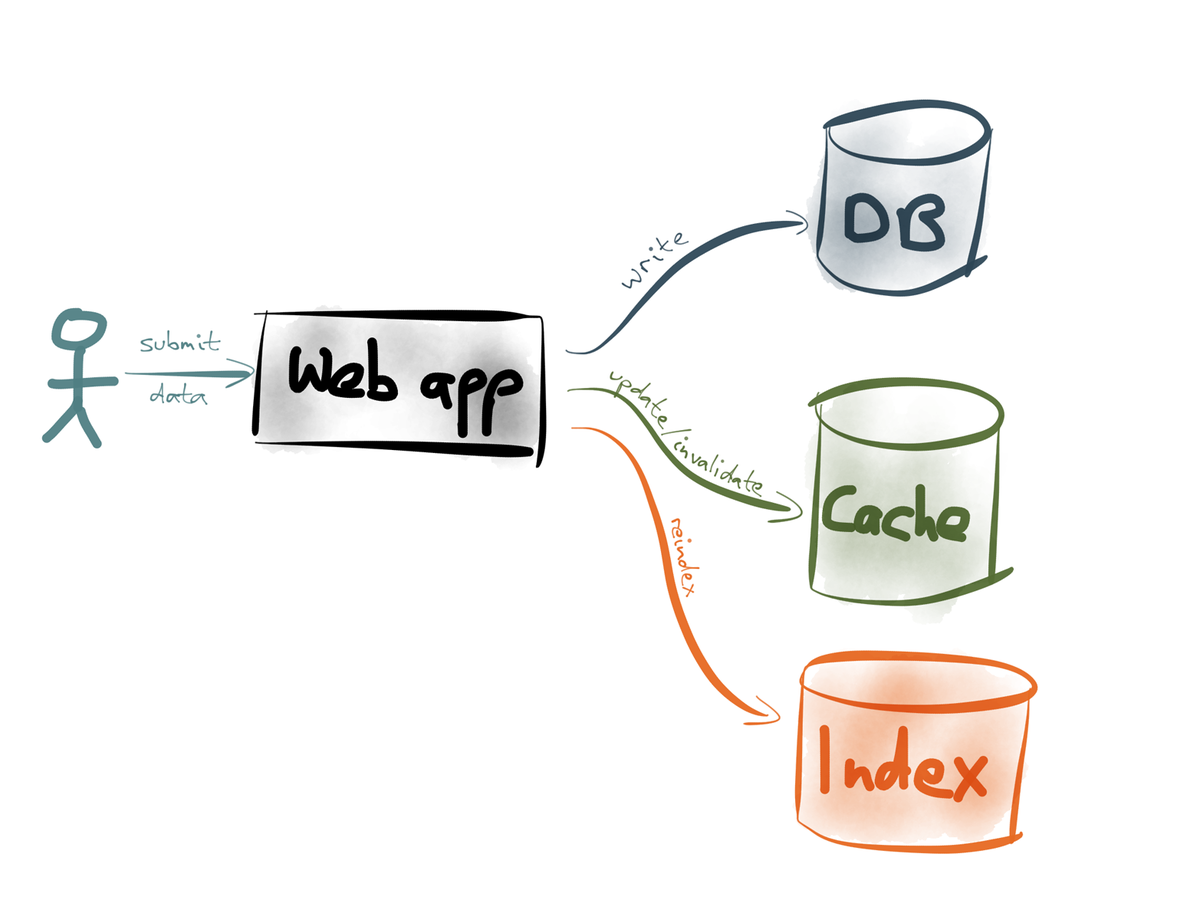
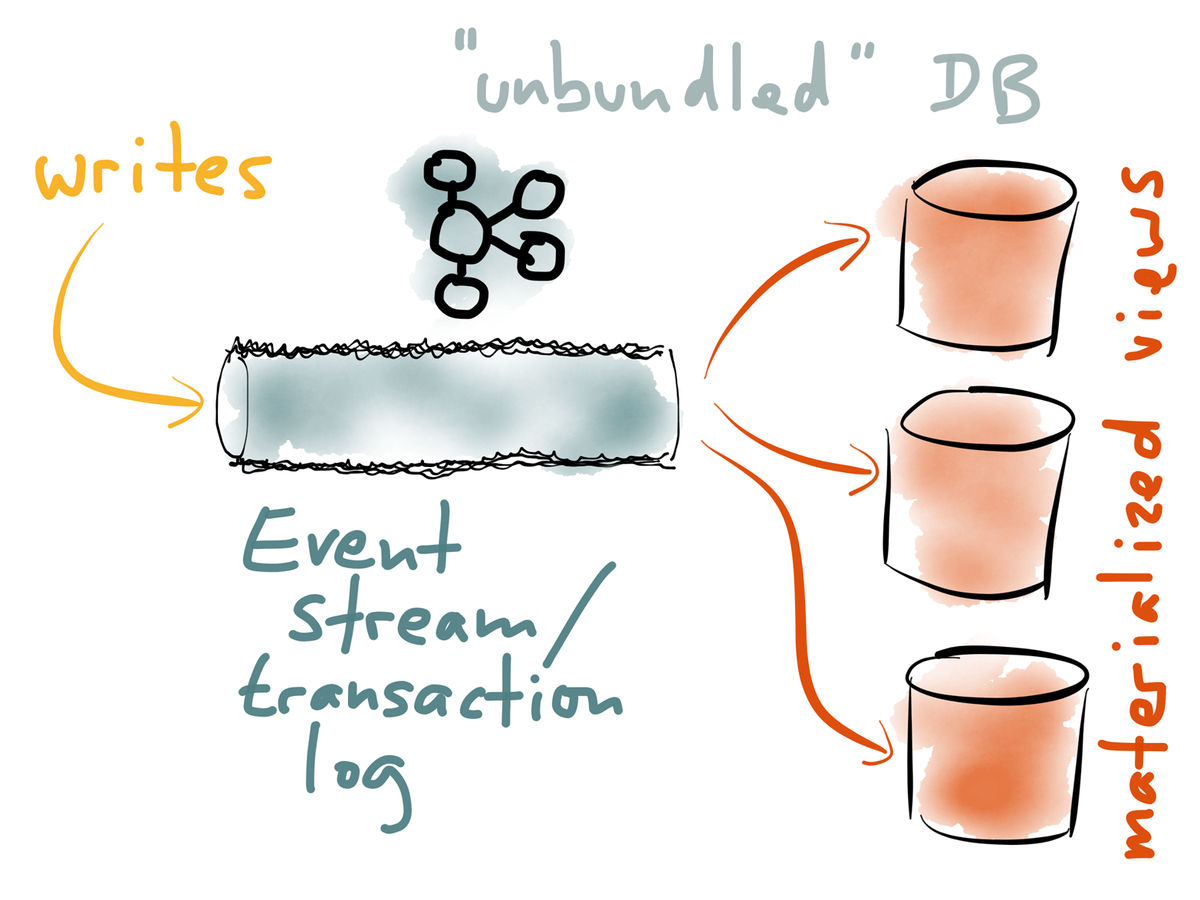
What if we built solutions based on an append-only stream of immutable events?
Possibilities include:
Benefits include:
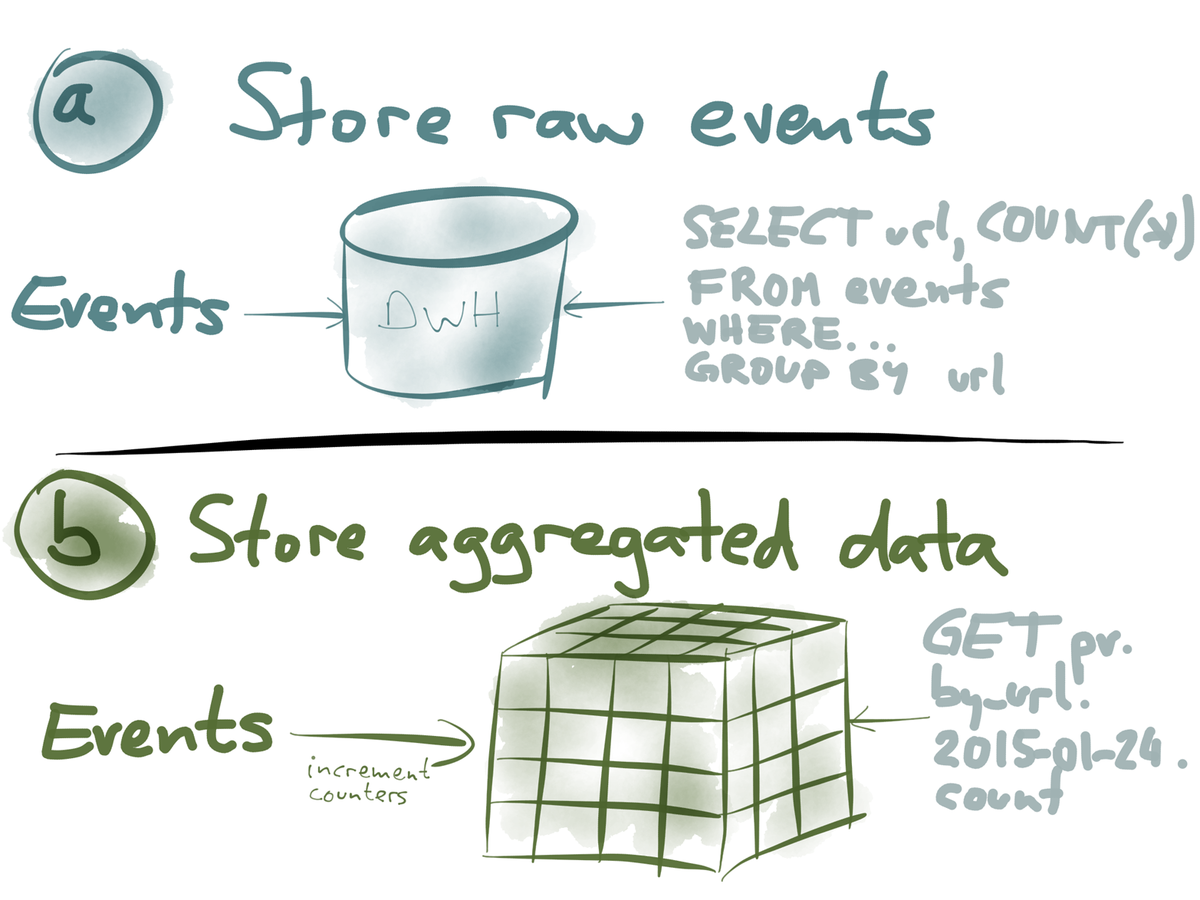
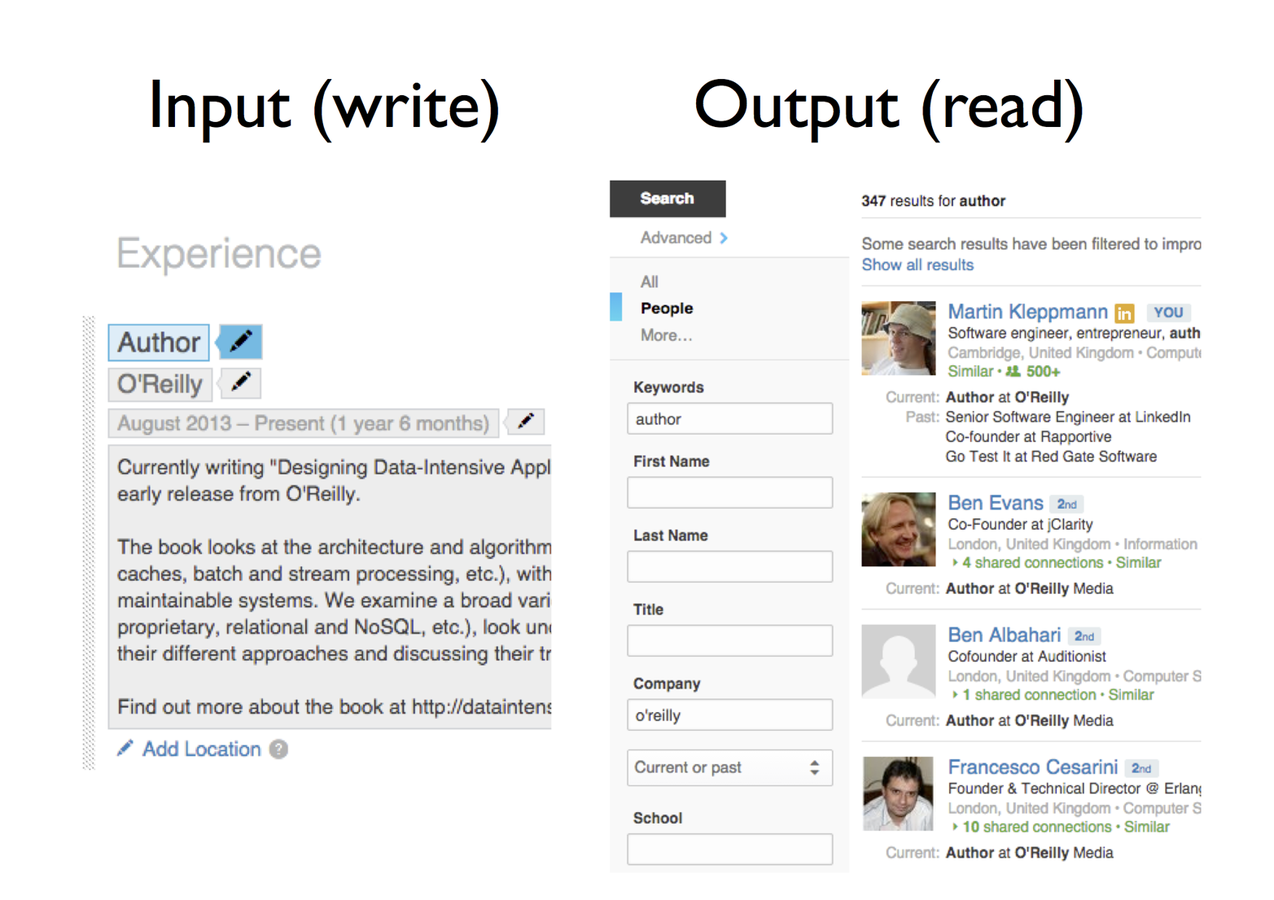
Option A: store raw event data. Great for off-line, high latency processing. You are free to ask almost any question you can imagine. Processing power required to answer questions is large so the number of concurrent questions you can ask is limited.
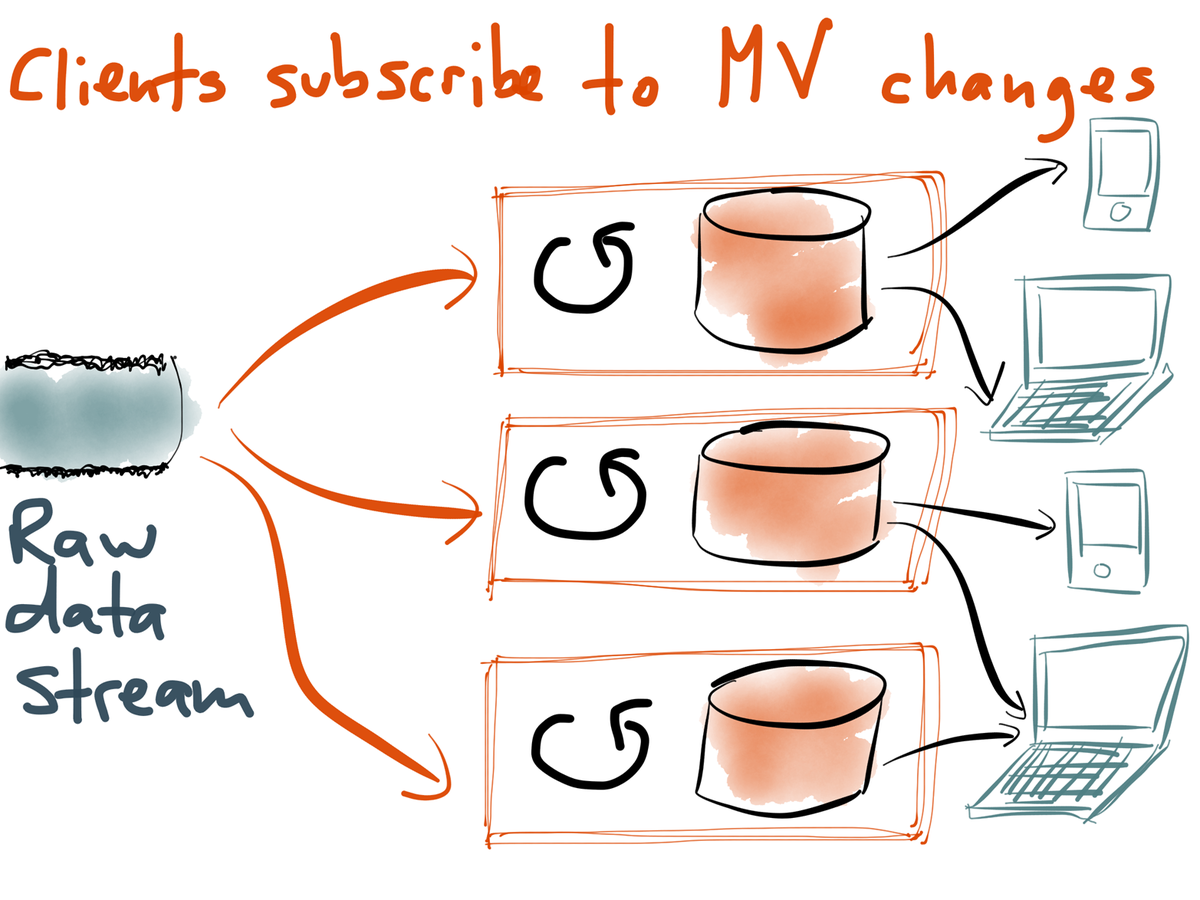
Option B: aggregate the data immediately. Great for low-latency queries, alerting and monitoring. Questions that can be asked are limited but required processing power is low so many concurrent questions can be handled.
The same data can take different forms and must be handled:
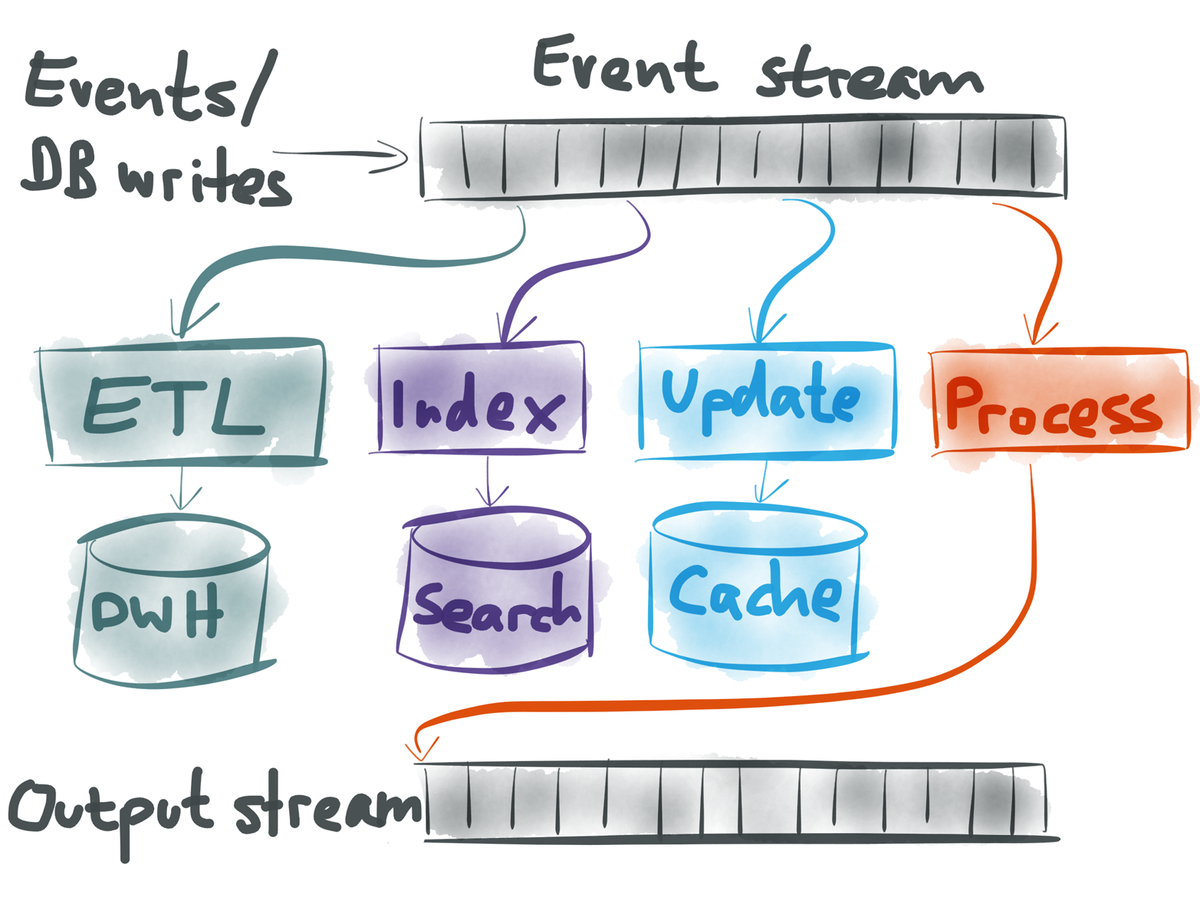
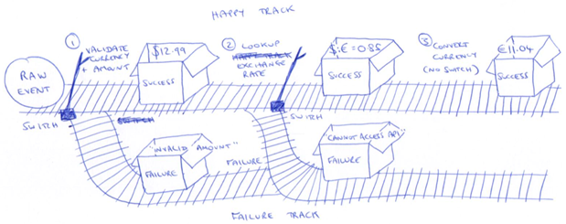
Read from one stream and write to another, either the happy path stream or the failure stream. Since we are using events and streams for both normal and failure processing, existing tooling still apply.
At 2015-07-03T12:01:35Z , in our production environment, SimpleEnricher v1 failed to enrich InboundEvent 428 because it failed Avro schema validation.
Instead of throwing an exception, return a failure object.
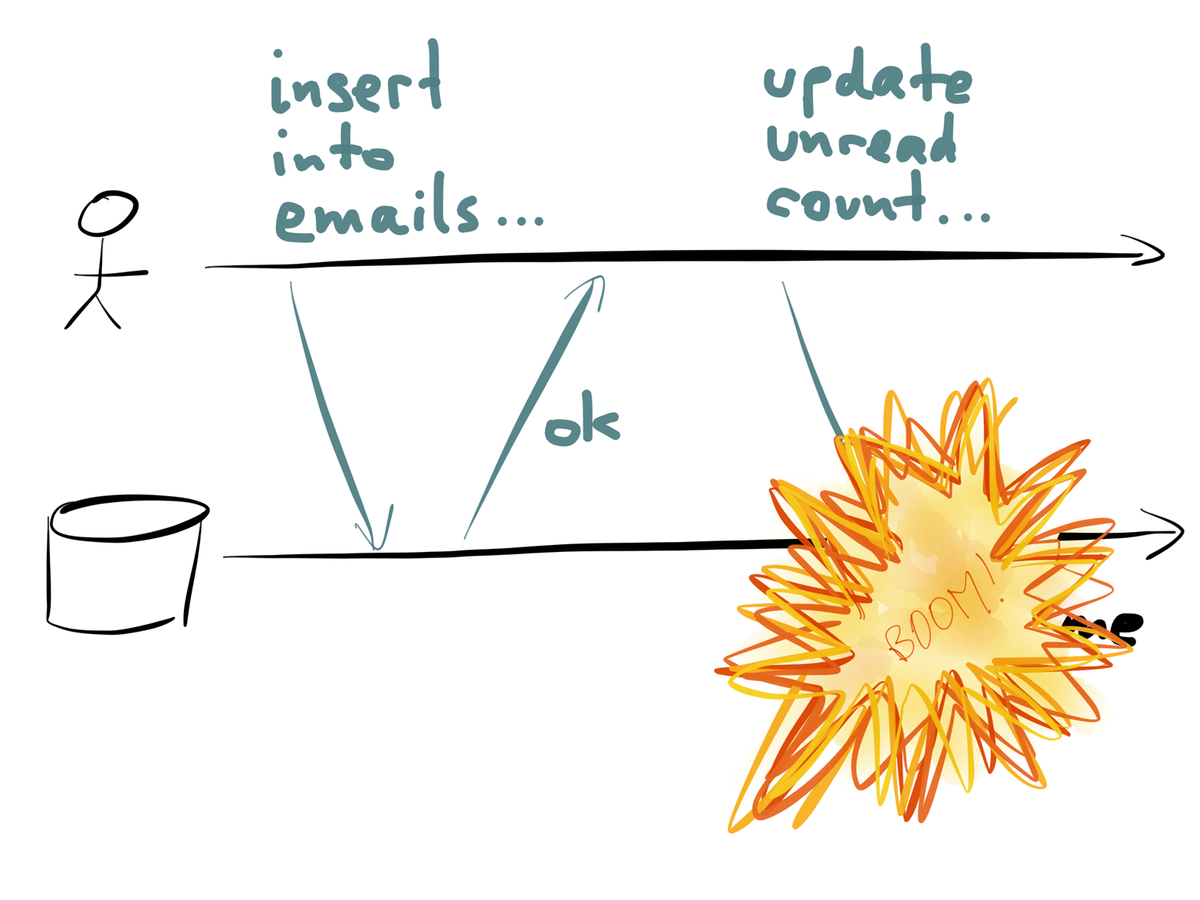
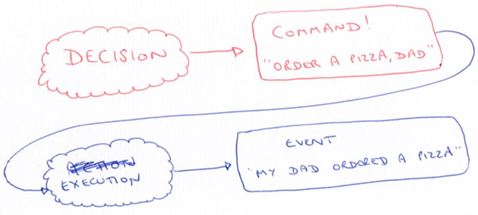
The separation of concerns makes it easier to test. You can have one process make the decision and write to the command stream and another process that consumes the command and runs them.
Unrecoverable but expected errors are handled by:
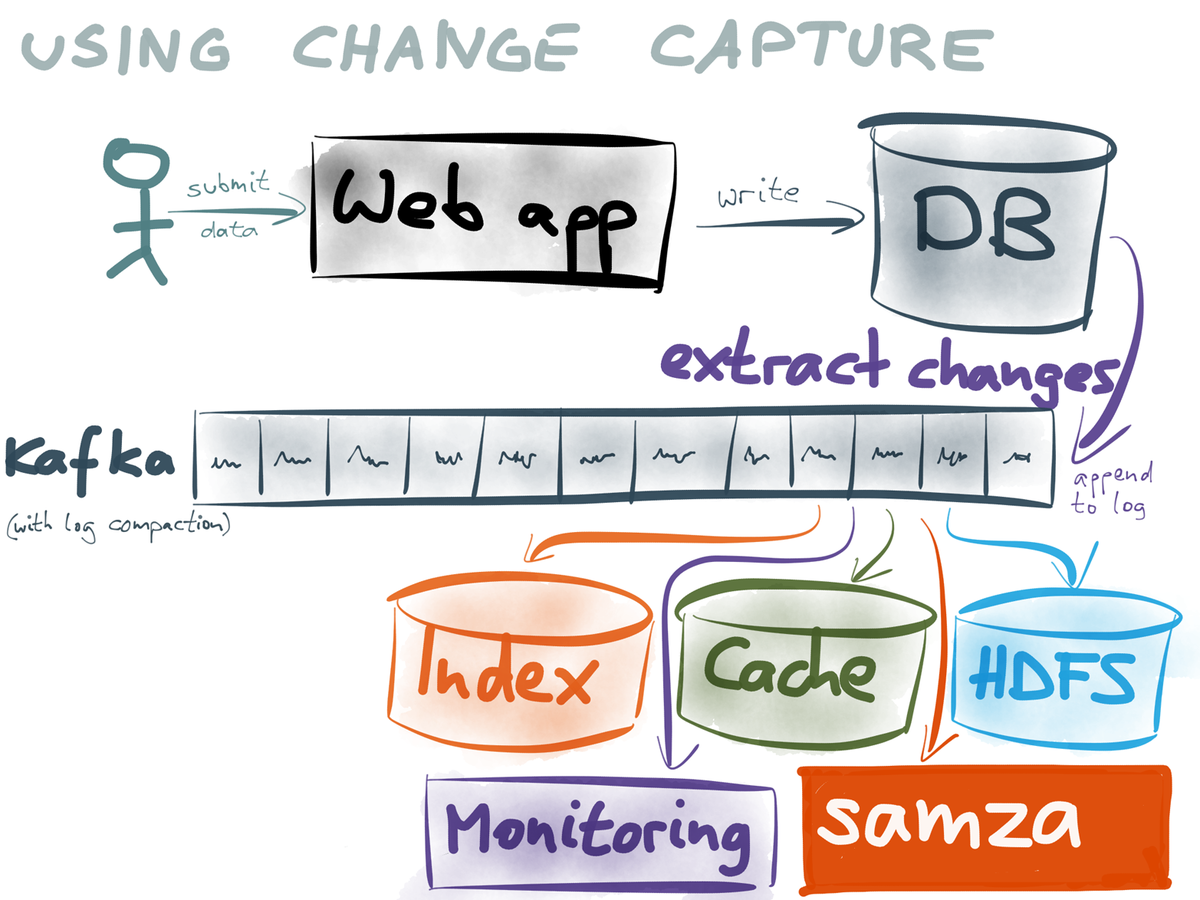
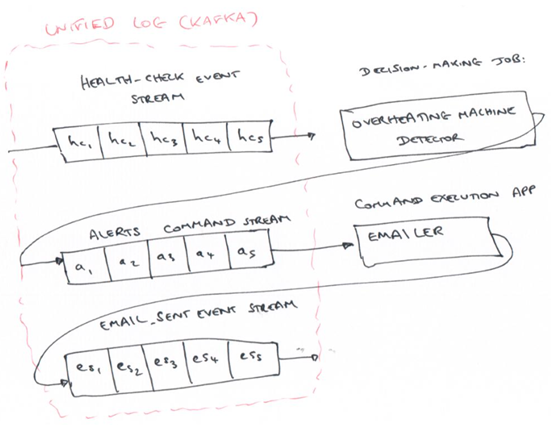
Apache Kafka: distributed event log
Apache Samza: a stream processing framework that works well with Kafka
Actor frameworks, like Akka, use immutable events to control concurrency. Reactive programming brings event streams to the UI.
The AMQP protocol does not guarantee ordering so RabbitMQ is not appropriate as an event log.
put rabbit ordering image here
Integrity Check: reserving a username
One Solution:
Another Solution: assume success, correct and apologize afterwards
Add Avro example
Most distributed logs and messaging systems provide at-least-once semantics which means your system has to deal with duplicates. Maybe store the event id in the database along with the data and do a conditional update only if the event has not been seen already.
Events should have an "effective date" fields which can be used to reorder history when synthetic events are injected into the stream to compensate for some sort of bad data or defect in the code.
Describe events using subject-verb-object convention.
Shopper viewed a product at time X.
Log implementations store raw bytes and do not care about the event format.
{
"event": "shopper_viewed_product",
"shopper": {
"id": 1234,
"name": "Jane"
}
"product": {
"id": 456,
"name": "iPad Pro"
}
"timestamp": "2015-07-03T12:01:035Z"
}Another way to look at it:
Event Stream Processing: watching one stream and transforming it into another stream
Single Event Processing: a single event results in one or more data points or events.
Multiple Event Processing: multiple events collectively produce one or more data points or events.
Processing Window: bounding the continuous stream, usually by time or count.
Streams are divided into Shards or Partitions.
A Shard Key is used to direct an event to a particular Shard. A Shard Key should use a property available on all events and is evenly distributed.
Consumer Options:
Resilience: resistant to failure.
Reprocessing: replay the entire stream.
Refinement: transformation due to:
Archive the rawest events possible as far upstream as possible.
Batch processing expects a terminated set of records.
Book used Scalaz but it looks a lot like the functional Either object where the instance can contain either the result or the failure, not both. The failure object needs to be composable and "flattened" so you don't get lists of lists of lists. Use a convenience routine that can combine a stream of Eithers based whether or not a failure is in the chain.
code example
By Ronald Kurr
The thinking behind a unified log stream and possible applications.




