

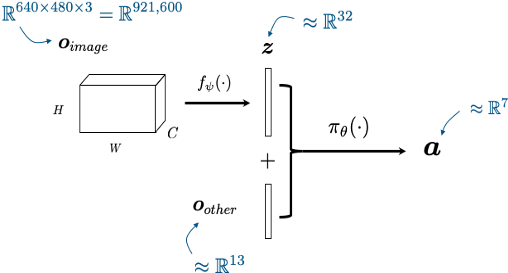












russtedrake PRO
Roboticist at MIT and TRI
(Part 1)
MIT 6.800/6.843:
Robotic Manipulation
Fall 2021, Lecture 18
Follow live at https://slides.com/d/Tb84VxM/live
(or later at https://slides.com/russtedrake/fall21-lec18)
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
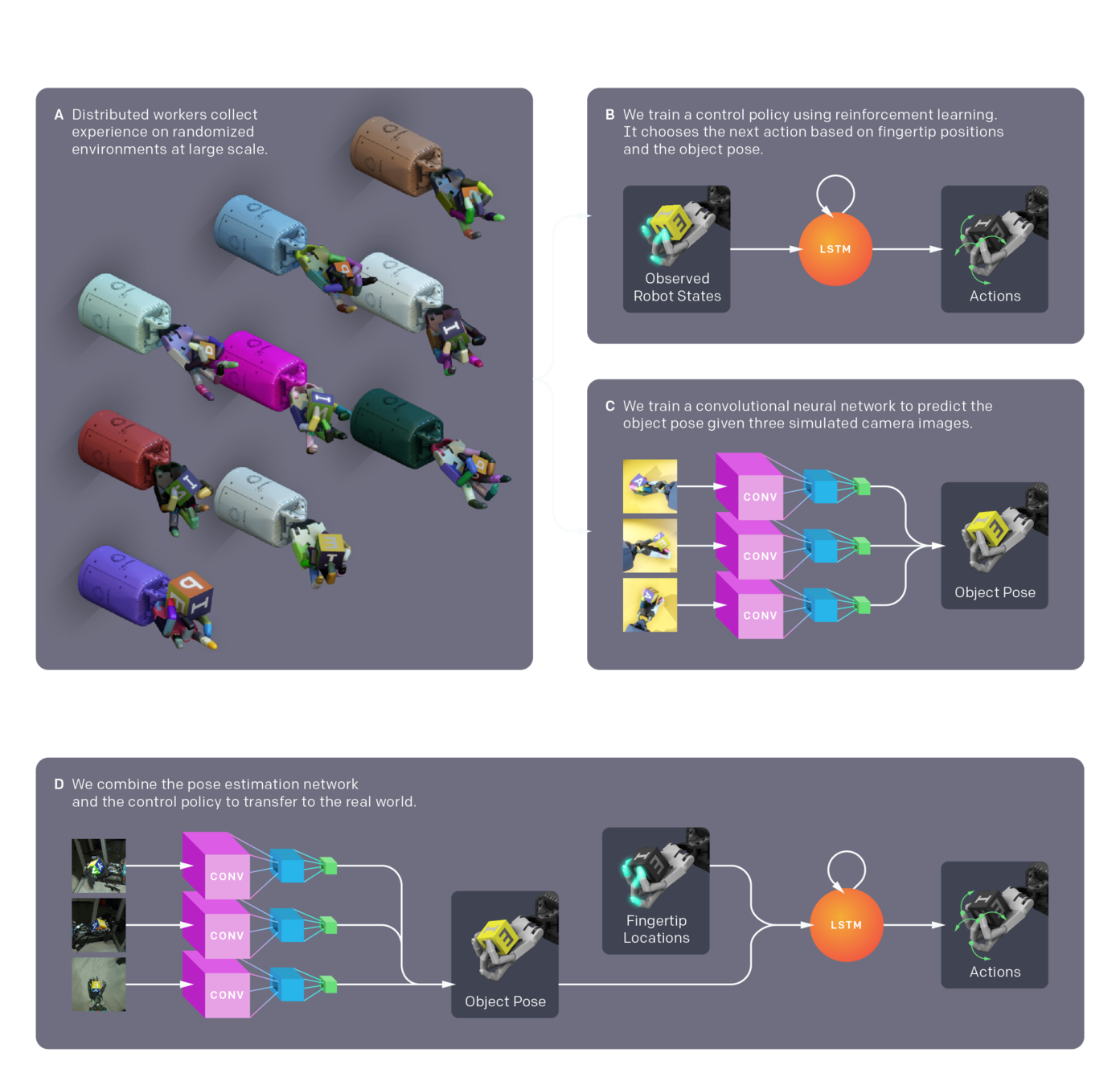
OpenAI - Learning Dexterity
Recipe:
import gym
from gym import error, spaces, utils
from gym.utils import seeding
class FooEnv(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
...
def step(self, action):
...
def reset(self):
...
def render(self, mode='human'):
...
def close(self):
...http://gym.openai.com/
import pydrake.all
builder = DiagramBuilder()
....
diagram = builder.Build()
simulator = Simulator(diagram)
simulator.AdvanceTo(...)
observation = sensor_output_port->Eval(context)
reward = reward_output_port->Eval(context)
context = diagram.CreateDefaultContext()
meshcat.Publish(context)import gym
import numpy as np
from pydrake.common import RandomGenerator
from pydrake.systems.sensors import ImageRgba8U
from pydrake.systems.framework import (
InputPort, EventStatus, OutputPort, PortDataType, OutputPortSelection
)
from pydrake.systems.analysis import Simulator
class DrakeGymEnv(gym.Env):
"""
DrakeGymEnv provides a gym.Env interface for a Drake System (often a Diagram)
using a Simulator.
"""
def __init__(self,
system,
time_step,
reward_callback_or_port,
action_port=None,
action_space=None,
observation_port=None,
observation_space=None,
render_rgb_port=None):
"""
Args:
system: A Drake System
time_step: Each call to step() will advance the simulator by
`time_step` seconds.
reward_callback_or_port: The reward can be specified in one of
two ways: (1) by passing a callable with the signature
`value = reward(context)` or (2) by passing a scalar
vector-valued output port of `system`.
action_port: An input port of `system` compatible with the
action_space. Each Env *must* have an action port; passing
`None` defaults to using the *first* input port (inspired by
`InputPortSelection.kUseFirstInputIfItExists`).
action_space: Defines the `gym.spaces.space` for the actions.
If action_port is vector-valued, then passing `None` defaults
to a gym.spaces.Box of the correct dimension with bounds
at negative and positive infinity. Note: Stable Baselines 3
strongly encourages normalizing the action_space to [-1, 1].
observation_port: An output port of `system` compatible with the
observation_space. Each Env *must* have an observation port
(it seems that gym doesn't support empty observation spaces /
open-loop policies); passing `None` defaults to using the *first*
input port (inspired by
`OutputPortSelection.kUseFirstOutputIfItExists`).
observation_space: Defines the gym.spaces.space for the observations.
If observation_port is vector-valued, then passing `None`
defaults to a gym.spaces.Box of the correct dimension with
bounds at negative and positive infinity.
render_rgb_port: An optional output port of `system` that returns
an `ImageRgba8U`; often the `color_image` port of Drake's
`RgbdSensor`. When not `None`, this enables the environment
`render_mode` `rgb_array`.
Notes (using `env` as an instance of this class):
- You may set simulator/integrator preferences by using `env.simulator`
directly.
- The `done` condition returned by `step()` is always False by default.
Use `env.simulator.set_monitor()` to use Drake's monitor functionality
for specifying termination conditions.
- You may additionally wish to directly set `env.reward_range` and/or
`env.spec`. See the docs for gym.Env for more details.
"""
self.system = system
self.time_step = time_step
self.simulator = Simulator(self.system)
self.generator = RandomGenerator()
# Setup rewards
if isinstance(reward_callback_or_port, OutputPort):
assert reward_callback_or_port.get_datatype() == PortDataType.kVectorValued
assert reward_callback_or_port.size() == 1
self.reward = lambda context: reward_callback_or_port.Eval(context)[0]
else:
assert callable(reward_callback_or_port)
self.reward = reward_callback_or_port
# Setup actions (resorting to defaults whenever possible)
if action_port:
assert isinstance(action_port, InputPort)
self.action_port = action_port
else:
self.action_port = system.get_input_port(0)
if action_space:
self.action_space = action_space
if self.action_port.get_data_type() == PortDataType.kVectorValued:
assert np.array_equal(self.action_space.shape, [
self.action_port.size()])
elif self.action_port.get_data_type() == PortDataType.kVectorValued:
# TODO(russt): Is this helpful, or is it better to force people to
# specify a bounded box?
num_actions = self.action_port.size()
self.action_space = gym.spaces.Box(
low=np.full((num_actions), -np.inf),
high=np.full((num_actions), np.inf))
else:
raise ValueError(
"Could not infer the action space from your action port; please pass in the action_space argument.")
# Setup observations (resorting to defaults whenever possible)
if observation_port:
assert isinstance(observation_port, OutputPort)
self.observation_port = observation_port
else:
self.observation_port = system.get_output_port(0)
if observation_space:
self.observation_space = observation_space
if self.observation_port.get_data_type() == \
PortDataType.kVectorValued:
assert np.array_equal(self.observation_space.shape, [
self.observation_port.size()])
elif self.observation_port.get_data_type() == \
PortDataType.kVectorValued:
num_obs = self.observation_port.size()
self.observation_space = gym.spaces.Box(
low=np.full((num_obs), -np.inf),
high=np.full((num_obs), np.inf))
else:
raise ValueError(
"Could not infer the observation space from your observation port; please pass in the observation_space argument.")
self.metadata['render.modes'] = ['human', 'ascii']
# (Maybe) setup rendering
if render_rgb_port:
assert isinstance(render_rgb_port, OutputPort)
assert render_rgb_port.get_data_type() == \
PortDataType.kAbstractValued
assert isinstance(render_rgb_port.Allocate().get_value(), ImageRgba8U)
self.metadata['render.modes'].append('rgb_array')
self.render_rgb_port = render_rgb_port
def step(self, action):
"""
Implements gym.Env.step() to advance the simulation forward by one `self.time_step`.
Args:
action: an element from self.action_space
"""
context = self.simulator.get_context()
time = context.get_time()
self.action_port.FixValue(context, action)
self.simulator.AdvanceTo(time + self.time_step)
observation = self.observation_port.Eval(context)
reward = self.reward(context)
done = False
monitor = self.simulator.get_monitor()
if monitor:
status = monitor(context)
done = status == EventStatus.kReachedTermination or \
status == EventStatus.kFailed
info = dict()
return observation, reward, done, info
def reset(self):
""" Resets the `simulator` and its Context . """
context = self.simulator.get_mutable_context()
self.system.SetRandomContext(context, self.generator)
self.simulator.Initialize()
# Note: The output port will be evaluated without fixing the input port.
return self.observation_port.Eval(context)
def render(self, mode='human'):
"""
Rendering in `human` mode is accomplished by calling Publish on `self.system`. This should
cause visualizers inside the System (e.g. MeshcatVisualizer, PlanarSceneGraphVisualizer, etc.) to
draw their outputs. To be fully compliant, those visualizers should set their default
publishing period to `np.inf` (do not publish periodically).
Rendering in `ascii` mode calls __repr__ on the system Context.
Rendering in `rgb_array` mode is enabled by passing a compatible `render_rgb_port` to the
class constructor.
"""
if mode == 'human':
self.system.Publish(self.simulator.get_context())
return
elif mode == 'ansi':
return __repr__(self.simulator.get_context())
elif mode == 'rgb_array':
assert self.render_rgb_port, \
"You must set render_rgb_port in the constructor"
return self.render_rgb_port.Eval(self.simulator.get_context()).data[:,:,:3]
else:
super(DrakeGymEnv, self).render(mode=mode)
def seed(self, seed=None):
""" Implements gym.Env.seed() using Drake's RandomGenerator. """
if seed:
self.generator = RandomGenerator(seed)
else:
seed = self.generator()
# Note: One could call self.action_space.seed(self.generator()) here,
# but it appears that is not the standard approach:
# https://github.com/openai/gym/issues/681
return [seed]
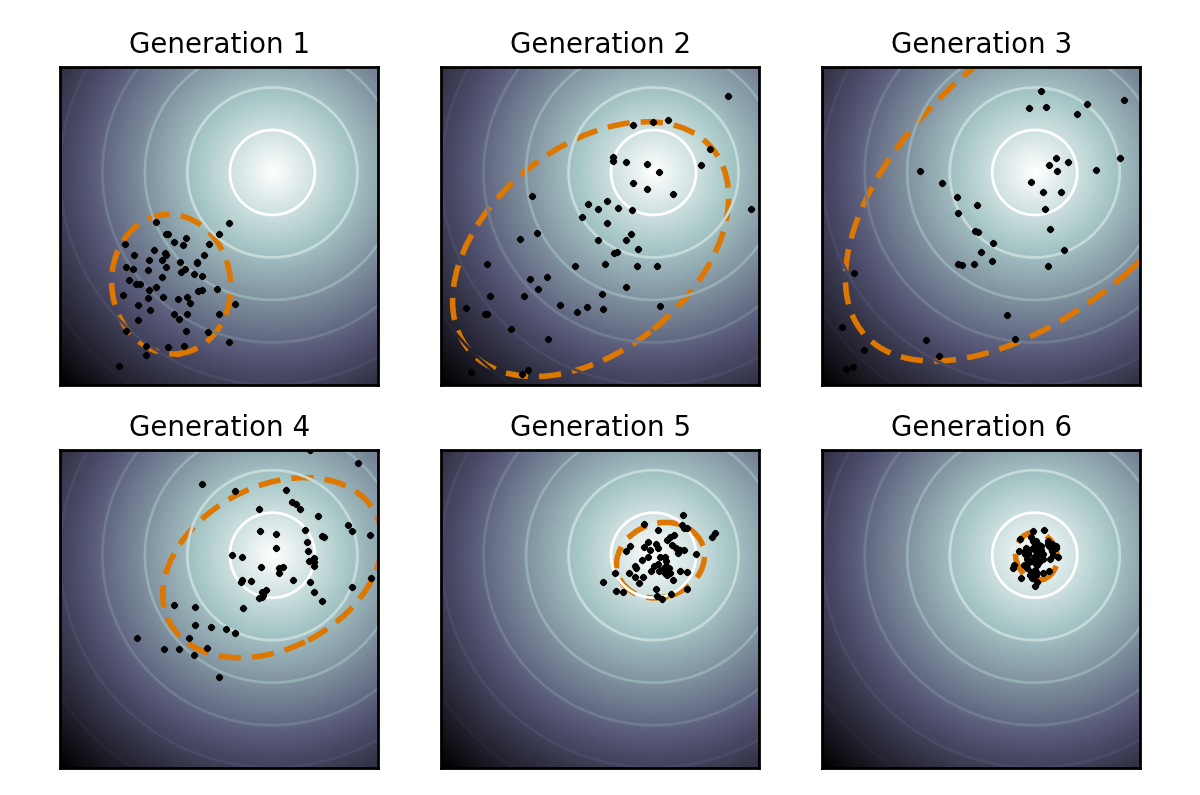
https://en.wikipedia.org/wiki/CMA-ES
(Image source: Tobin et al, 2017)
"By studying both ES and RL gradient estimators mathematically we can see that ES is an attractive choice especially when the number of time steps in an episode is long, where actions have long-lasting effects, or if no good value function estimates are available."
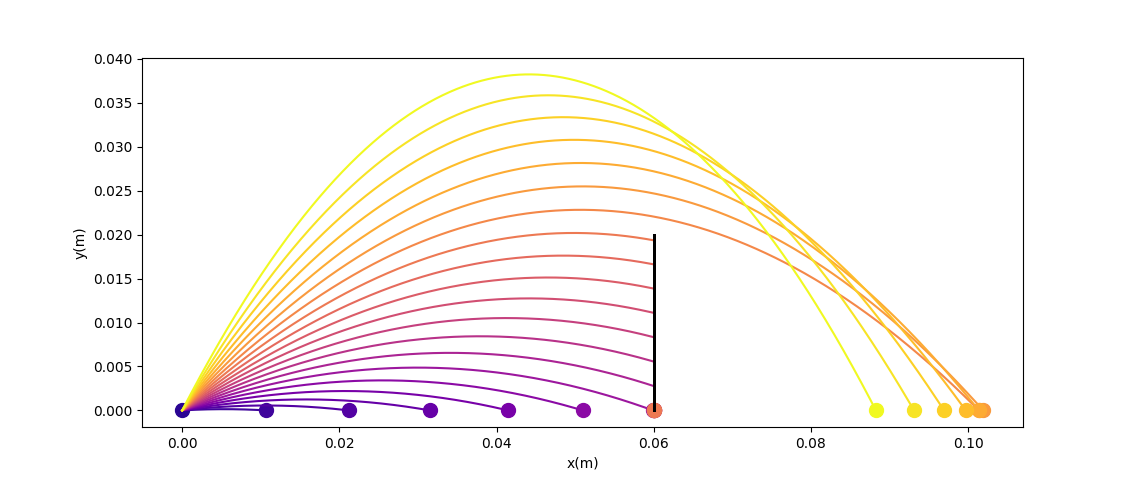
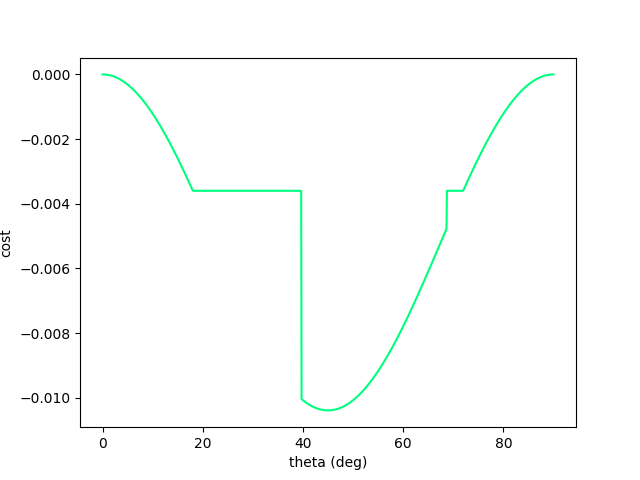
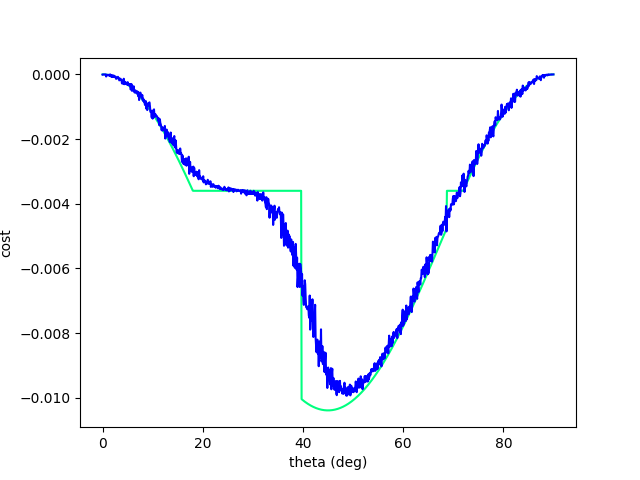
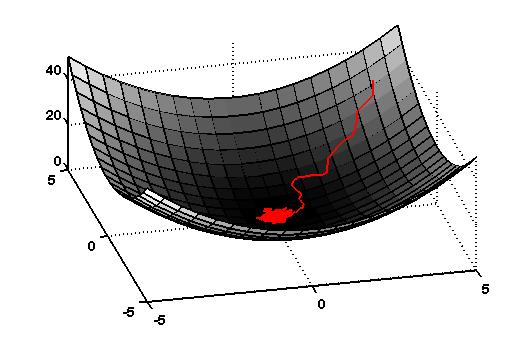
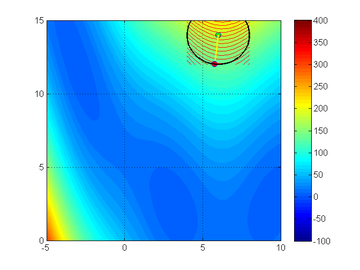
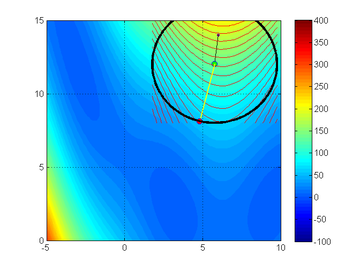
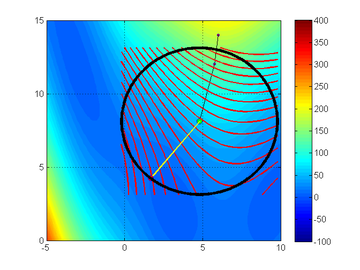
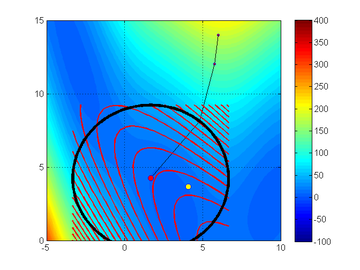
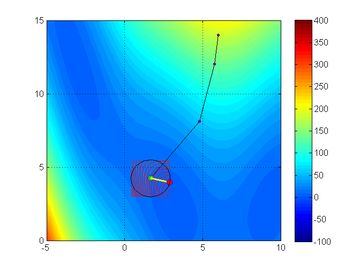
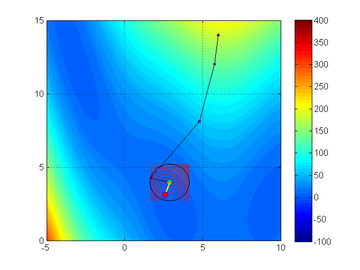
Trust-region method on a 'Branin' function. From Northwestern University Open Text Book on Process Optimization
Kolter, J. Zico, Zachary Jackowski, and Russ Tedrake. "Design, analysis, and learning control of a fully actuated micro wind turbine." 2012 American Control Conference (ACC). IEEE, 2012.
Schulman, John, et al. "Trust region policy optimization." International conference on machine learning. 2015.
def ppo_pendulum(ctxt=None, seed=1):
"""Train PPO with InvertedDoublePendulum-v2 environment.
Args:
ctxt (garage.experiment.ExperimentContext): The experiment
configuration used by Trainer to create the snapshotter.
seed (int): Used to seed the random number generator to produce
determinism.
"""
set_seed(seed)
env = GymEnv('InvertedDoublePendulum-v2')
trainer = Trainer(ctxt)
policy = GaussianMLPPolicy(env.spec,
hidden_sizes=[64, 64],
hidden_nonlinearity=torch.tanh,
output_nonlinearity=None)
value_function = GaussianMLPValueFunction(env_spec=env.spec,
hidden_sizes=(32, 32),
hidden_nonlinearity=torch.tanh,
output_nonlinearity=None)
algo = PPO(env_spec=env.spec,
policy=policy,
value_function=value_function,
discount=0.99,
center_adv=False)
trainer.setup(algo, env)
trainer.train(n_epochs=100, batch_size=10000)OpenAI - Learning Dexterity
"PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance."
https://openai.com/blog/openai-baselines-ppo/
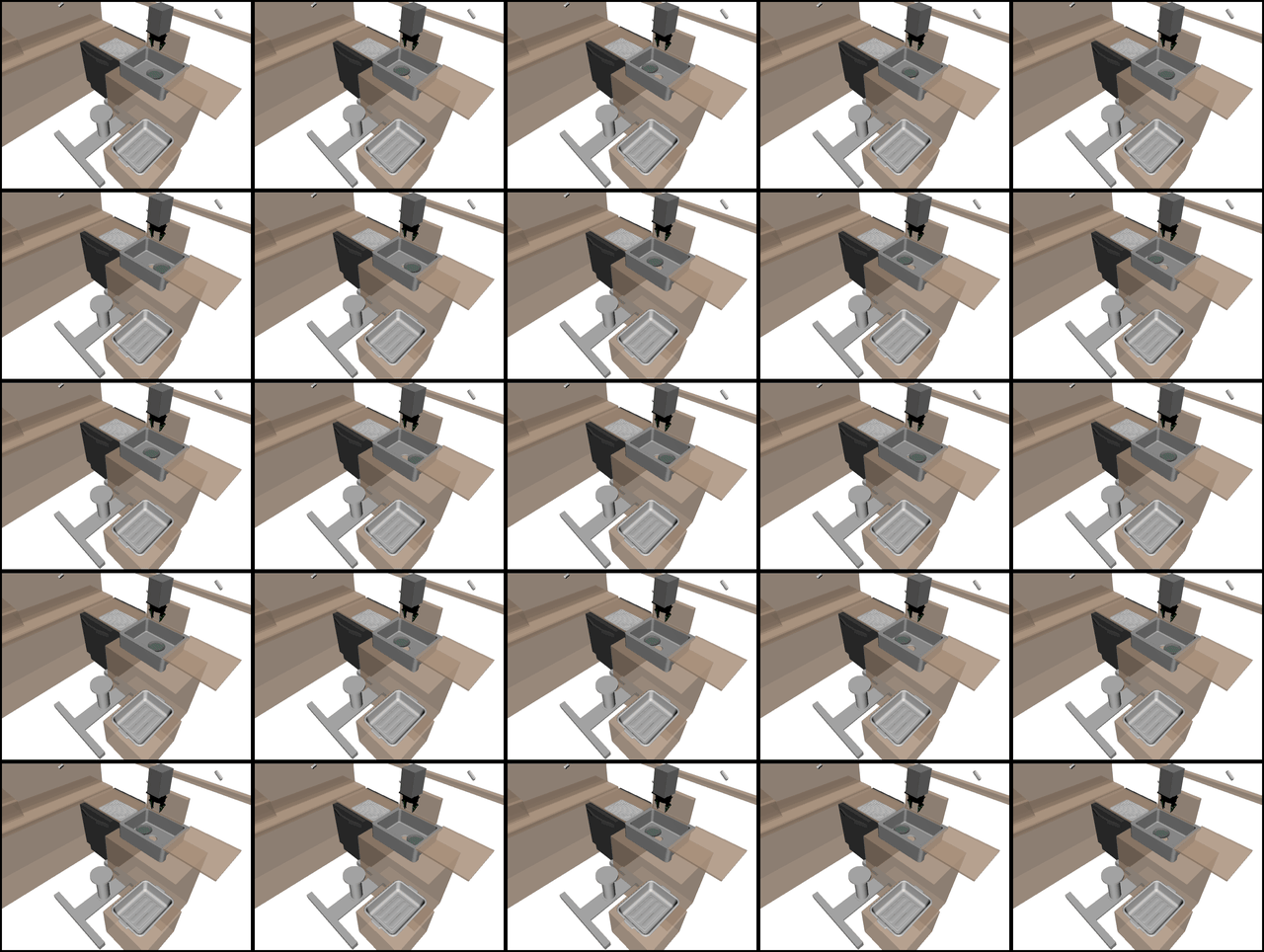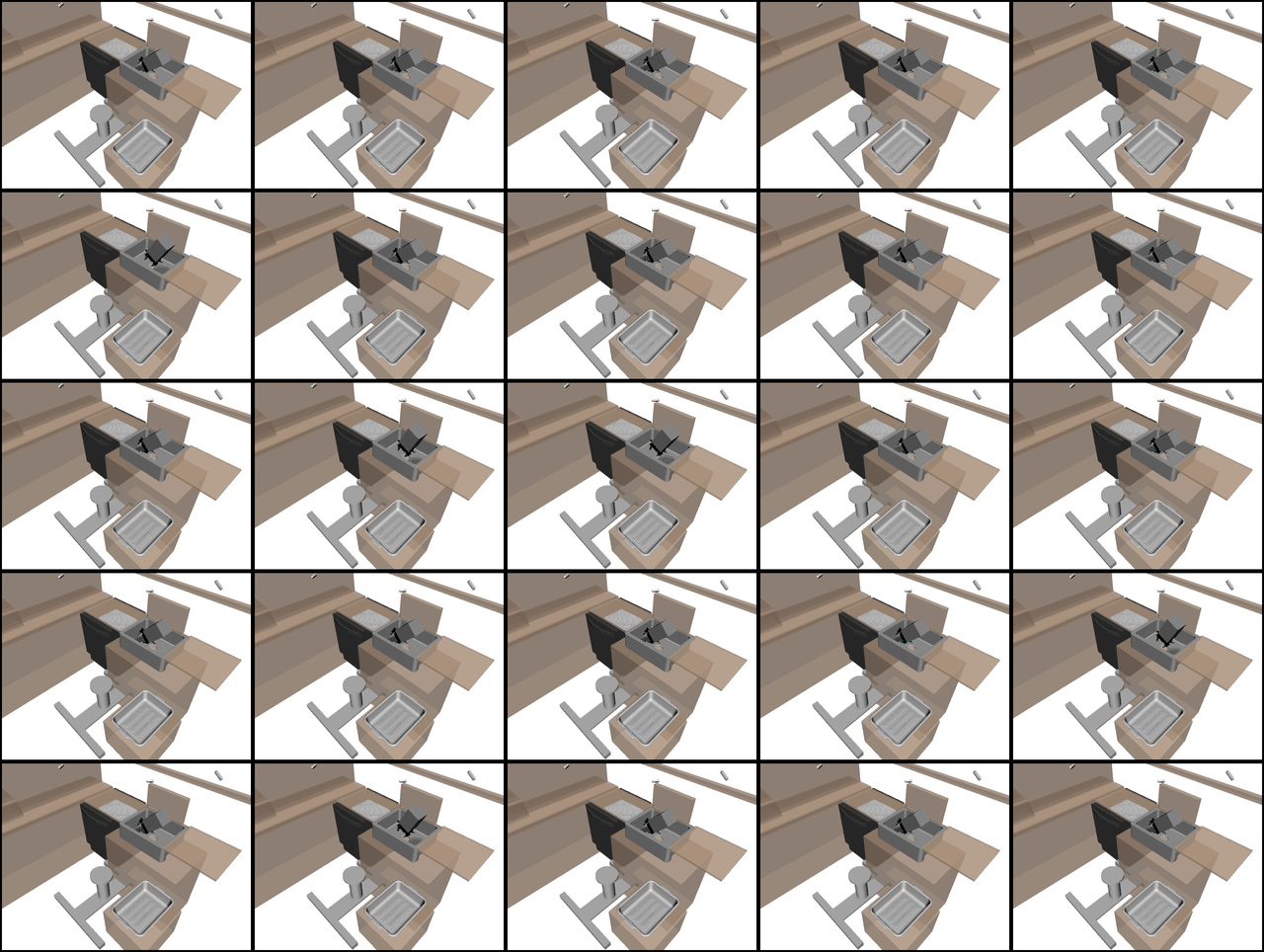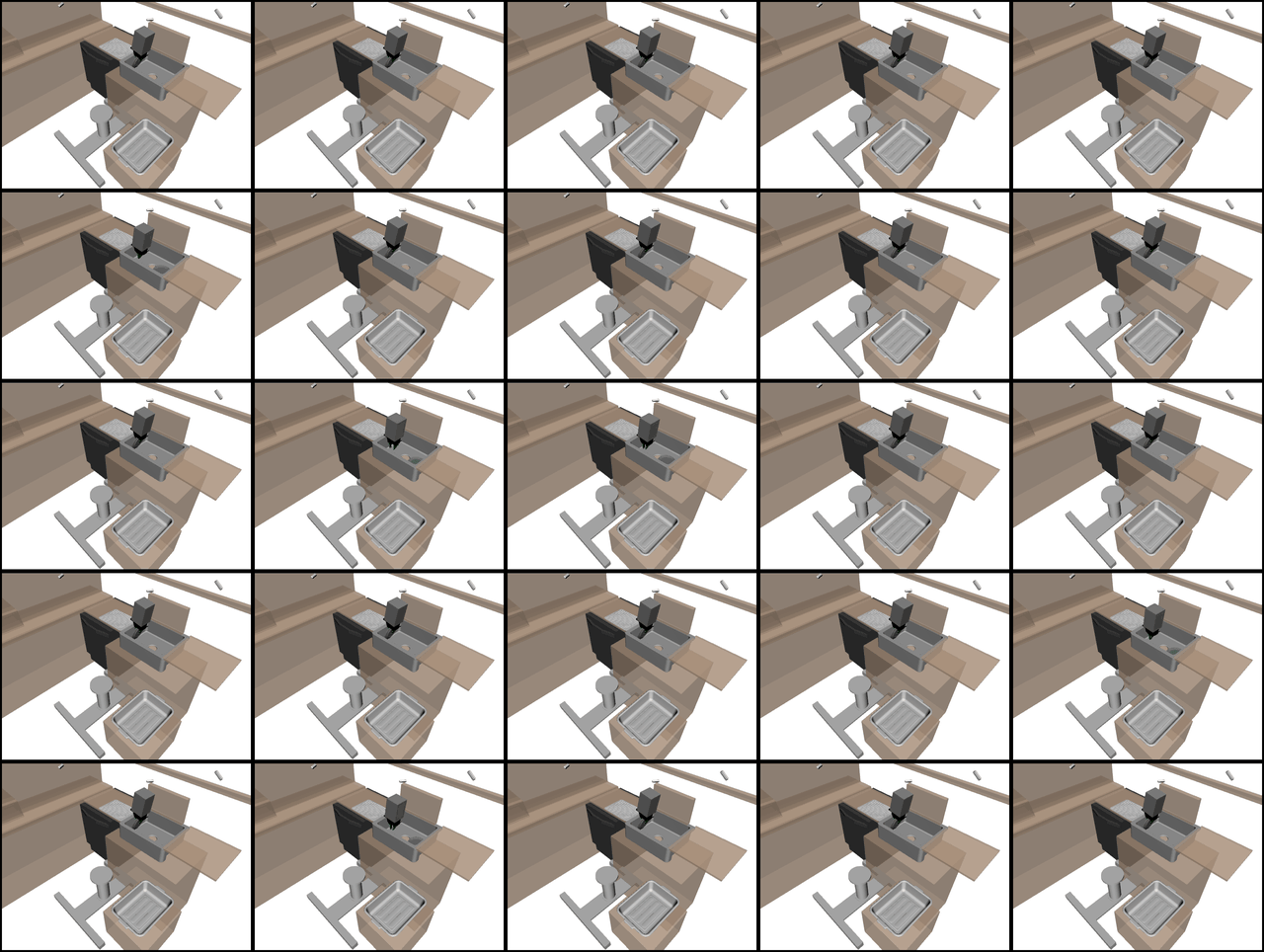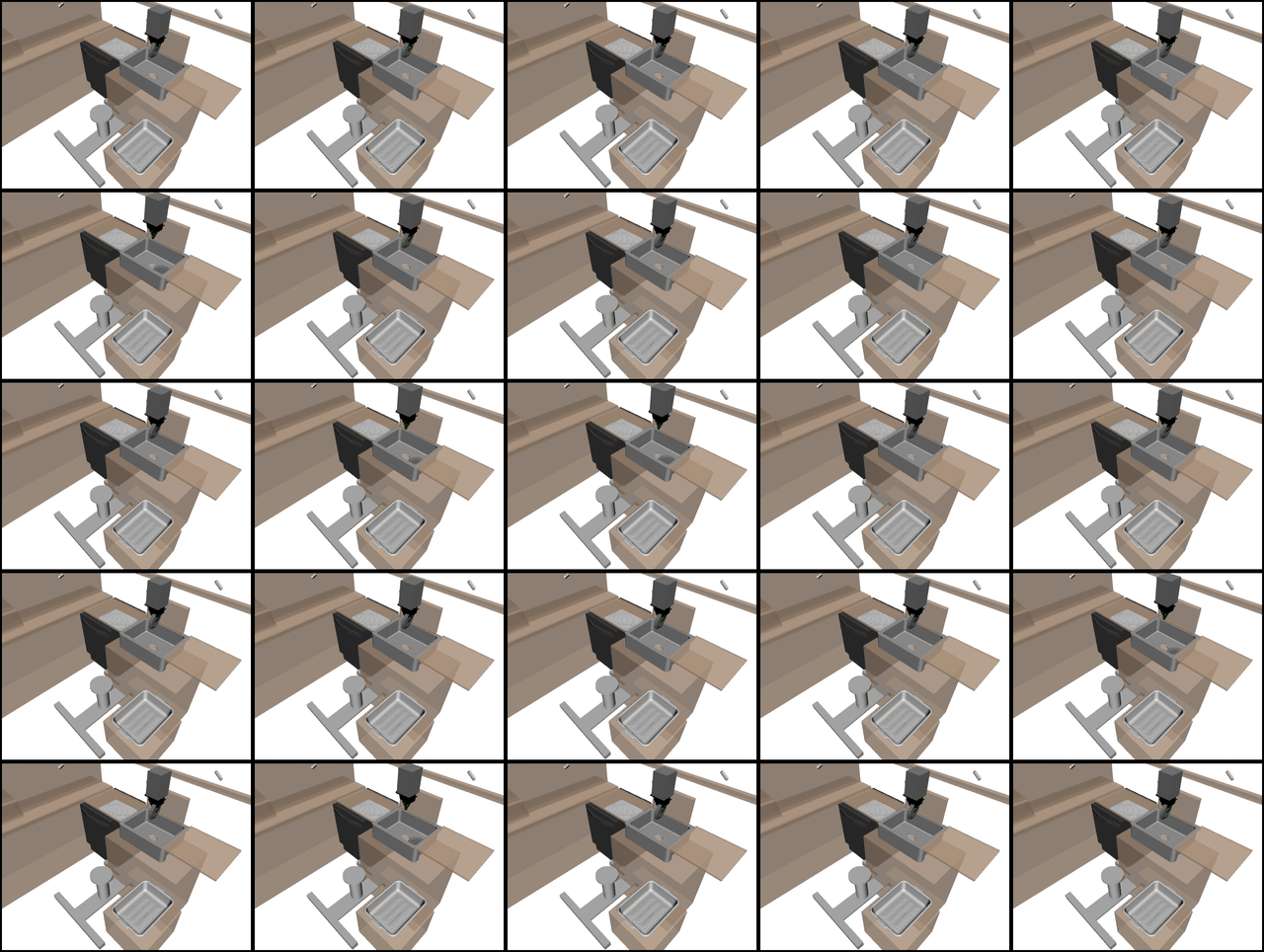
A System for General In-Hand Object Re-Orientation
Tao Chen, Jie Xu, Pulkit Agrawal
Conference on Robot Learning (CoRL), 2021 (Best Paper Award)
https://taochenshh.github.io/projects/in-hand-reorientation
“The sheer scope and variation across objects tested with this method, and the range of different policy architectures and approaches tested makes this paper extremely thorough in its analysis of this reorientation task.”
"We use PPO to optimize \(\pi\)."
Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
https://spinningup.openai.com/en/latest/algorithms/ppo.html
By russtedrake
MIT Robotic Manipulation Fall 2020 http://manipulation.csail.mit.edu


