
















russtedrake PRO
Roboticist at MIT and TRI
(Part 3)
MIT 6.800/6.843:
Robotic Manipulation
Fall 2021, Lecture 20
Follow live at https://slides.com/d/Tb84VxM/live
(or later at https://slides.com/russtedrake/fall21-lec20)
OpenAI - Learning Dexterity
Recipe:
OpenAI - Learning Dexterity
"PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance."
https://openai.com/blog/openai-baselines-ppo/
A System for General In-Hand Object Re-Orientation
Tao Chen, Jie Xu, Pulkit Agrawal
Conference on Robot Learning (CoRL), 2021 (Best Paper Award)
https://taochenshh.github.io/projects/in-hand-reorientation
“The sheer scope and variation across objects tested with this method, and the range of different policy architectures and approaches tested makes this paper extremely thorough in its analysis of this reorientation task.”
"We use PPO to optimize \(\pi\)."
import gym
from stable_baselines3 import PPO
gym.envs.register(id="BoxFlipUp-v0",
entry_point="manipulation.envs.box_flipup:BoxFlipUpEnv")
model = PPO('MlpPolicy', "BoxFlipUp-v0")
model.learn(total_timesteps=100000)
...
# Now Animate some roll outs.
env = gym.make("BoxFlipUp-v0", meshcat=meshcat)
obs = env.reset()
for i in range(500):
action, _state = model.predict(obs, deterministic=True)
obs, reward, done, info = env.step(action)
env.render()
if done:
obs = env.reset()cost = 2 * angle_from_vertical**2 # box angle
cost += 0.1 * box_state[5]**2 # box velocity
cost += 0.1 * effort.dot(effort) # effort
cost += 0.1 * finger_state[2:].dot(finger_state[2:]) # finger velocity
reward = 10 - cost # Add 10 to avoid rewarding simulator crashes.
cost = 2 * angle_from_vertical**2 # box angle
cost += 0.1 * box_state[5]**2 # box velocity
cost += 0.1 * effort.dot(effort) # effort
cost += 0.1 * finger_state[2:].dot(finger_state[2:]) # finger velocity
reward = 10 - cost # Add 10 to avoid rewarding simulator crashes.Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
https://spinningup.openai.com/en/latest/algorithms/ppo.html
NeurIPS, 1999
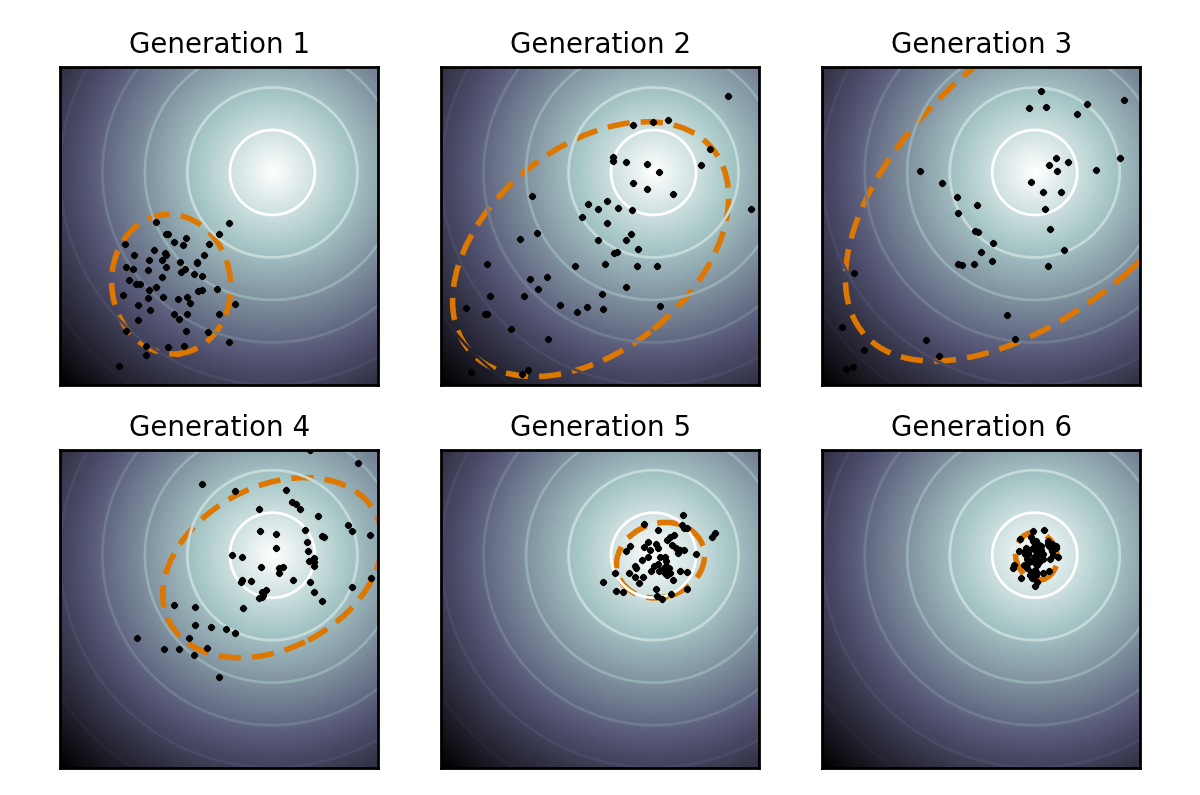
PPO Learned Critic: Box angle (x) vs box angular velocity (y)
2005
2018
https://en.wikipedia.org/wiki/CMA-ES
"By studying both ES and RL gradient estimators mathematically we can see that ES is an attractive choice especially when the number of time steps in an episode is long, where actions have long-lasting effects, or if no good value function estimates are available."
By russtedrake
MIT Robotic Manipulation Fall 2020 http://manipulation.csail.mit.edu


