









russtedrake PRO
Roboticist at MIT and TRI
Russ Tedrake and Sadra Saddradini
(+ joint work w/ Guy and Hadas)
Image credit: Andy Biewener (Harvard)
Good algorithms for feedback motion planning (developed largely in previous MURI)
Biggest limitation: assumed full-state feedback.
Vision has become a primary sensor...
Sensor
Plant
Sensor
Sensor
Perception / Estimation
Planning & Control
\(y\)
\(\hat{x}\)
\(u\)
\(x\)
Perception / Estimation
Planning & Control
\(y\)
\(p(x | history)\)
\(u\)
But is Deep RL the only viable approach?
Estimating the full state (or belief state) is unreasonable and unnecessary...
Output feedback
vs
\(y\)
\(u\)
aka "pixels-to-torques"
N.B. Ben Recht on feedback from pixels: "\(y=g(x), \) we assume \(g\) is invertible". In my view, that's unreasonable.
There are more general approaches to solving the LQG problem:
These solve joint perception + control (not only state estimation \(\Rightarrow\) control)
Key idea: Don't solve the full POMDP, search over the restricted class of policies, e.g.
feedback gain at time 2
https://keypointnet.github.io/
https://nanonets.com/blog/human-pose-estimation-2d-guide/
Core technology: dense correspondences
(built on Schmidt, Newcombe, Fox, RA-L 2017)
Peter R. Florence*, Lucas Manuelli*, and Russ Tedrake. Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation. CoRL, 2018.
dense 3D reconstruction
+ pixelwise contrastive loss
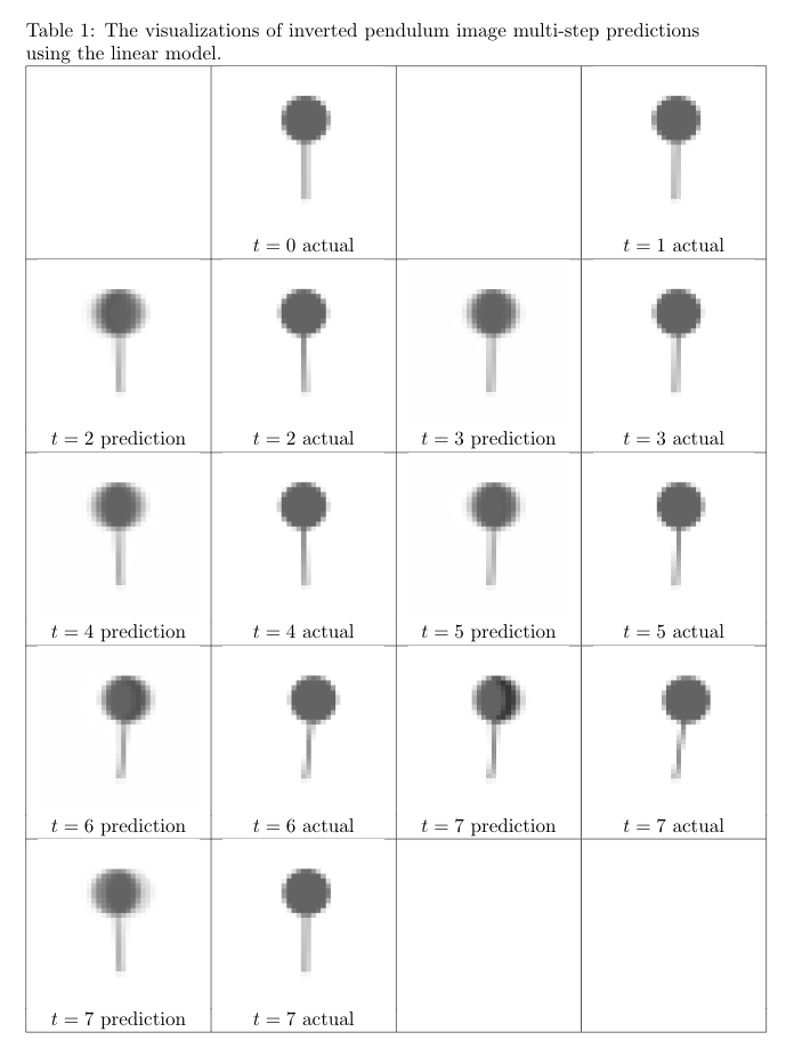
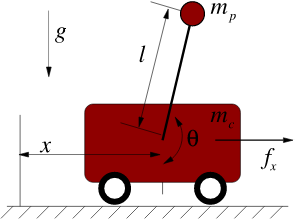
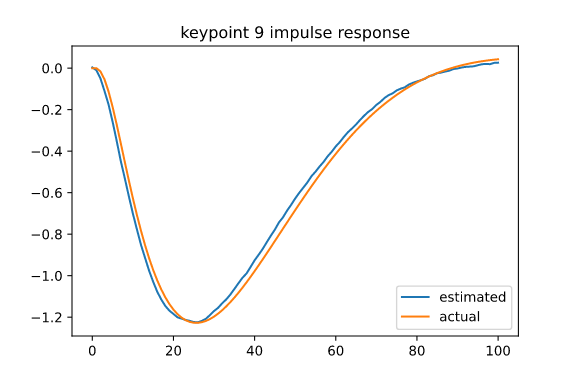
Learn descriptor keypoint dynamics + trajectory MPC
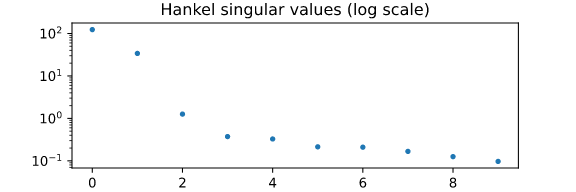
New results suggest models can be very simple (e.g. < 10 ReLUs)
Learn descriptor keypoint dynamics + trajectory MPC
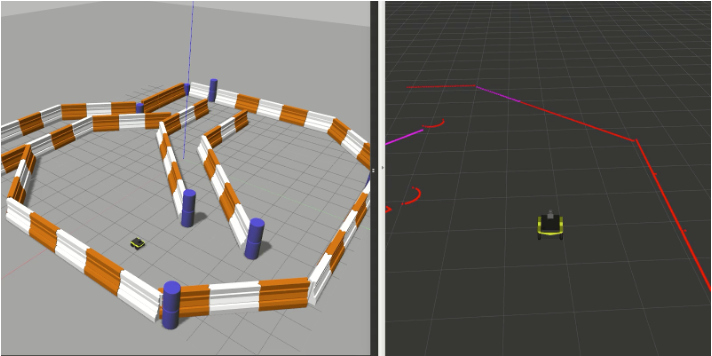
Sadra, Guy, Hadas, Russ
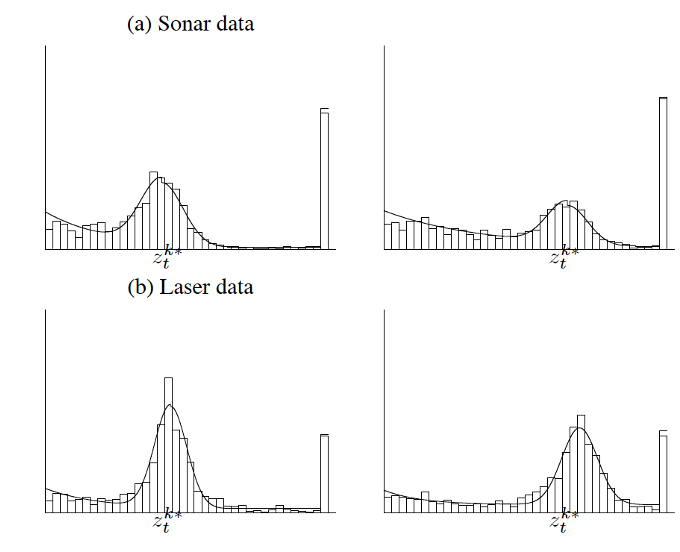
Thrun, Burgard, Fox, Probabilistic Robotics
Key idea: Piecewise sensors models + integral quadratic constraints (IQCs) to bound # of switches
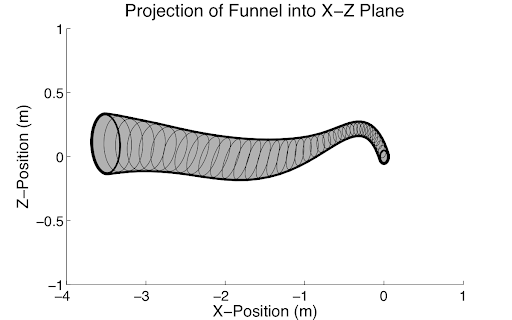
Shortest path, \(P:\) \[ \min_P \min_{(x_i)_{i \in P}} \sum_{(i,j) \in P} \ell(x_i,x_j).\]
is the convex relaxation. (it's tight!)
By russtedrake
PERISCOPE MURI Review — short results talk


