















russtedrake PRO
Roboticist at MIT and TRI
Follow along at https://slides.com/russtedrake/rss2020-visual/live
Lucas Manuelli*, Wei Gao*, Peter R. Florence and Russ Tedrake. kPAM: KeyPoint Affordances for Category Level Manipulation. ISRR 2019
Follow along at: https://slides.com/russtedrake/rss2020-visual/live
Manipulate potentially unknown rigid objects from a category (e.g. mugs, shoes) into desired target configurations.
SE(3) pose is difficult to generalize across a category
So how do we even specify the task?
What's the cost function?
(Images of mugs on the rack?)
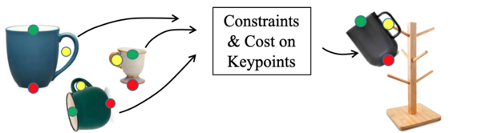
3D Keypoints provide rich, class-general semantics
Constraints & Cost on Keypoints
... and robust performance in practice
subject to:
relative to Sonia, this separates semantics from the dense geometry
No template model nor pose appears in this pipeline.
Custom annotation
tool
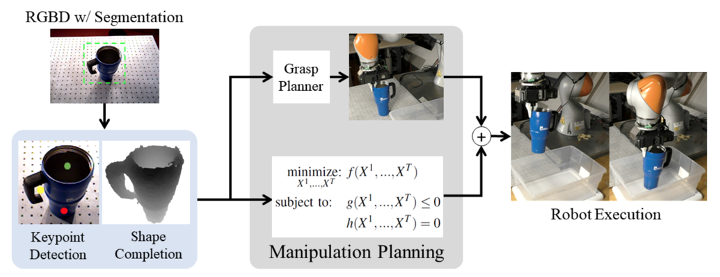
RGBD image w/ instance segmentation
Grasp
Planner
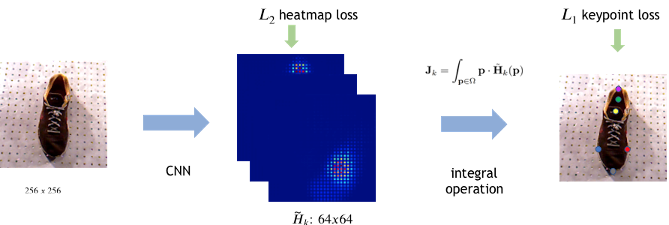
3D Keypoint Detection Network
Image
3D
Inverse Kinematics Planner
Architecture based on Sun, Xiao, et al. "Integral human pose regression." ECCV, 2018
Custom annotation tool
Sample of results
(shoes on rack)
| # train objects | 10 |
| # test objects | 20 |
| # trials | 100 |
| placed on shelf | 98% |
| heel error (cm) | 1.09 ± (1.29) |
| toe error (cm) | 4.34 ± (3.05) |
to include collision-avoidance constraints
So far, keypoints are geometric and semantic
(mug handle, front toe of shoe), but required human labels
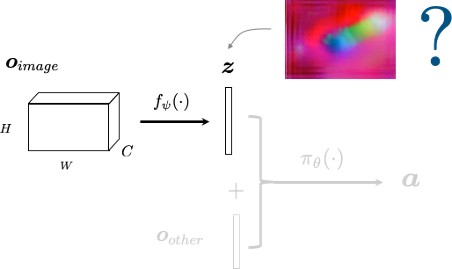
If we forgo semantics, can we self-supervise?
Follow along at: https://slides.com/russtedrake/rss2020-visual/live
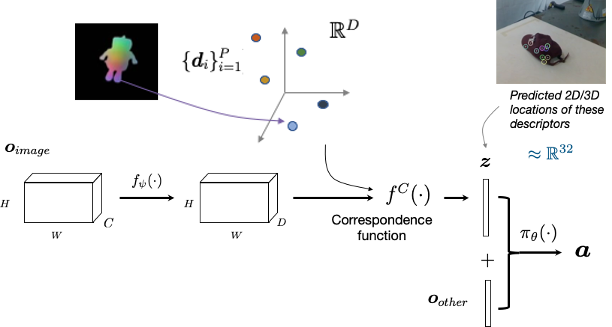
Core technology: dense correspondences
(built on Schmidt, Newcombe, Fox, RA-L 2017)
Peter R. Florence*, Lucas Manuelli*, and Russ Tedrake. Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation. CoRL, 2018.
dense 3d reconstruction
+ pixelwise contrastive loss
New loss function sharpens correspondences
Now 3d correspondences, trained with multiview
Dense descriptors as self-supervised keypoints
But without semantics, how do we specify the task?
Peter R. Florence, Lucas Manuelli, and Russ Tedrake. Self-Supervised Correspondence in Visuomotor Policy Learning. RA-L, April 2020
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
Estimate object/hand pose
(but hard for category-level)
from hand-coded policies in sim
and teleop on the real robot
Standard "behavior-cloning" object + data augmentation
"push box"
"flip box"
Policy is a small LSTM network (~100 LSTMs)
Late-breaking results:
Learn descriptor keypoint dynamics + trajectory MPC
Late-breaking results:
Learn descriptor keypoint dynamics + trajectory MPC
For all the details, check out
Lucas' PhD defense next Monday.
July 20, 2020 02:00PM Eastern
(ping Lucas for zoom info, or watch youtube just after)
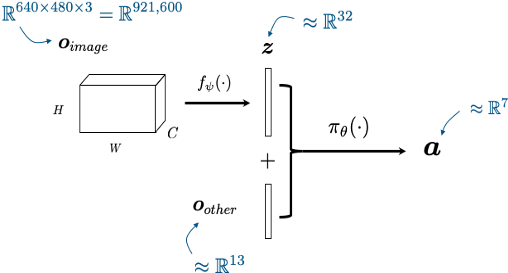
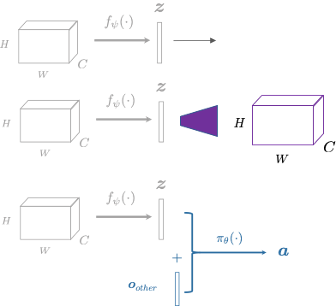
Wanted: State representations for "category-level" dexterous manipulation
This fall: my manipulation class at MIT will be online.
By russtedrake
A presentation at the RSS 2020 workshop on "Visual Learning and Reasoning for Robotic Manipulation" https://sites.google.com/view/rss20vlrrm


