











russtedrake PRO
Roboticist at MIT and TRI
MIT 6.8210: Underactuated Robotics
Spring 2023, Lecture 23
Follow live at https://slides.com/d/1UFnQdo/live
(or later at https://slides.com/russtedrake/spring23-lec23)
Image credit: Boston Dynamics
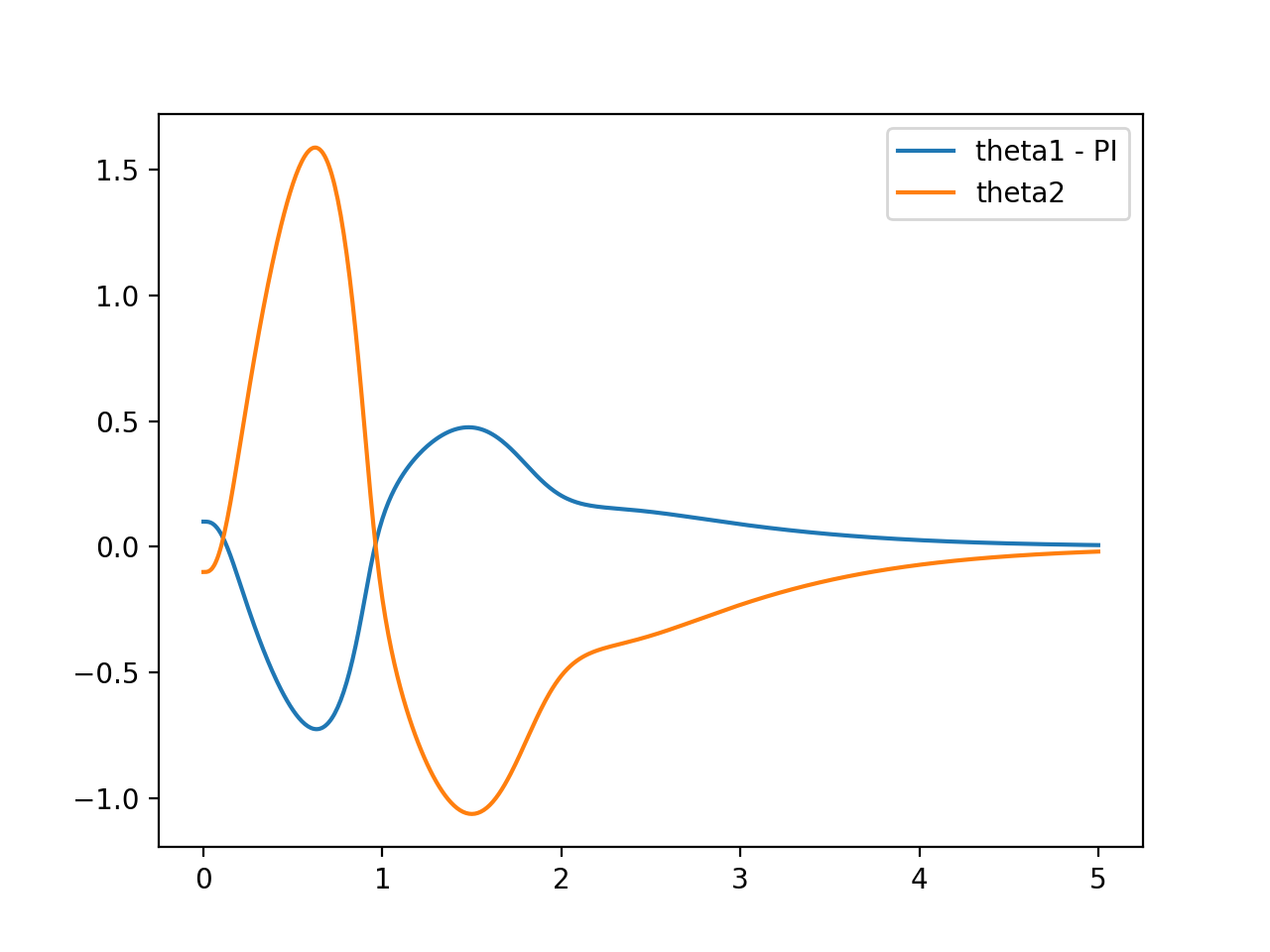
True acrobot state
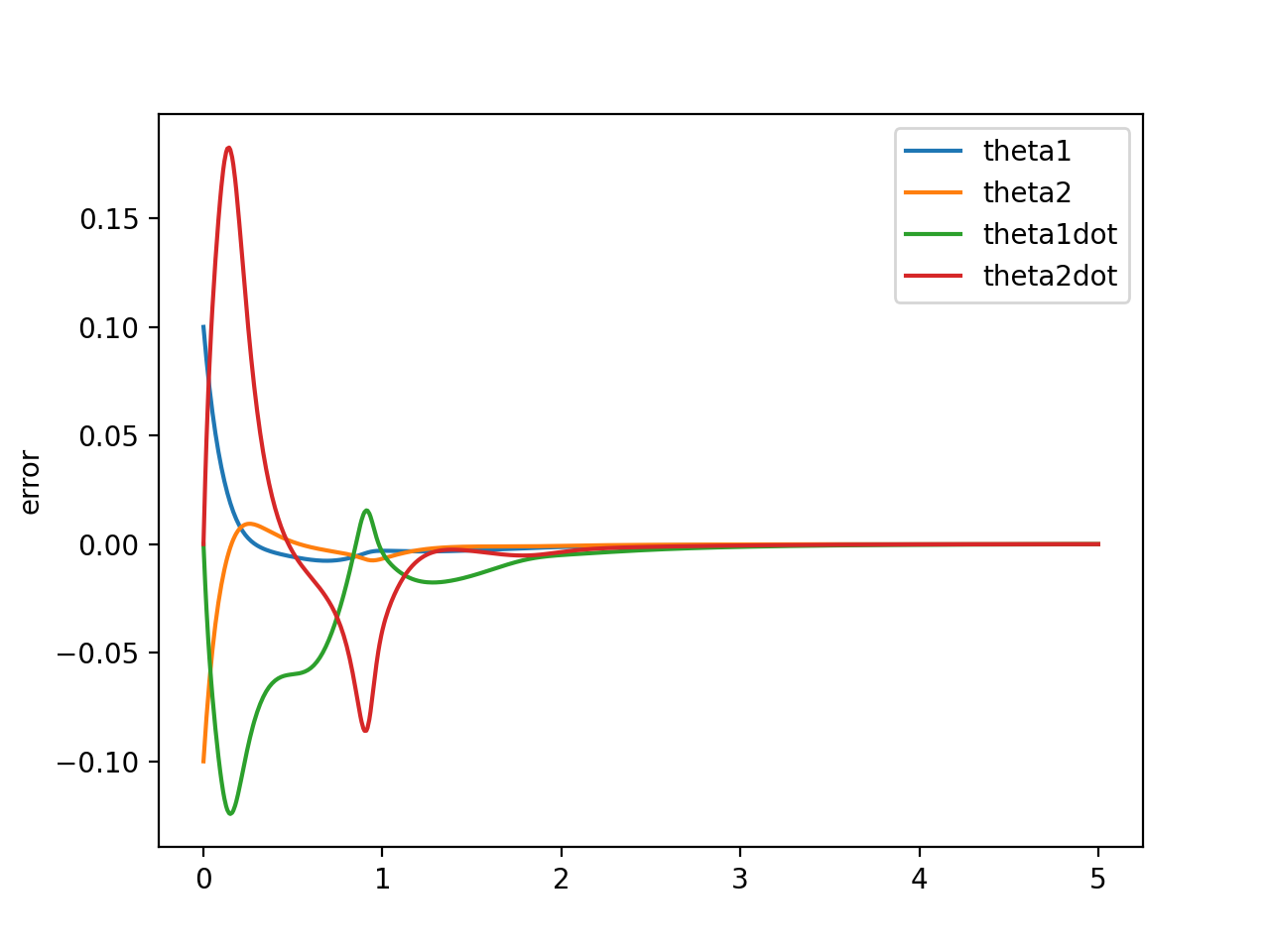
Estimator error \( (\hat{x} - x) \)
Key advance:
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
OpenAI - Learning Dexterity
Reinforcement Learning (RL)?
"And then … BC methods started to get good. Really good. So good that our best manipulation system today mostly uses BC, with a sprinkle of Q learning on top to perform high-level action selection. Today, less than 20% of our research investments is on RL, and the research runway for BC-based methods feels more robust."
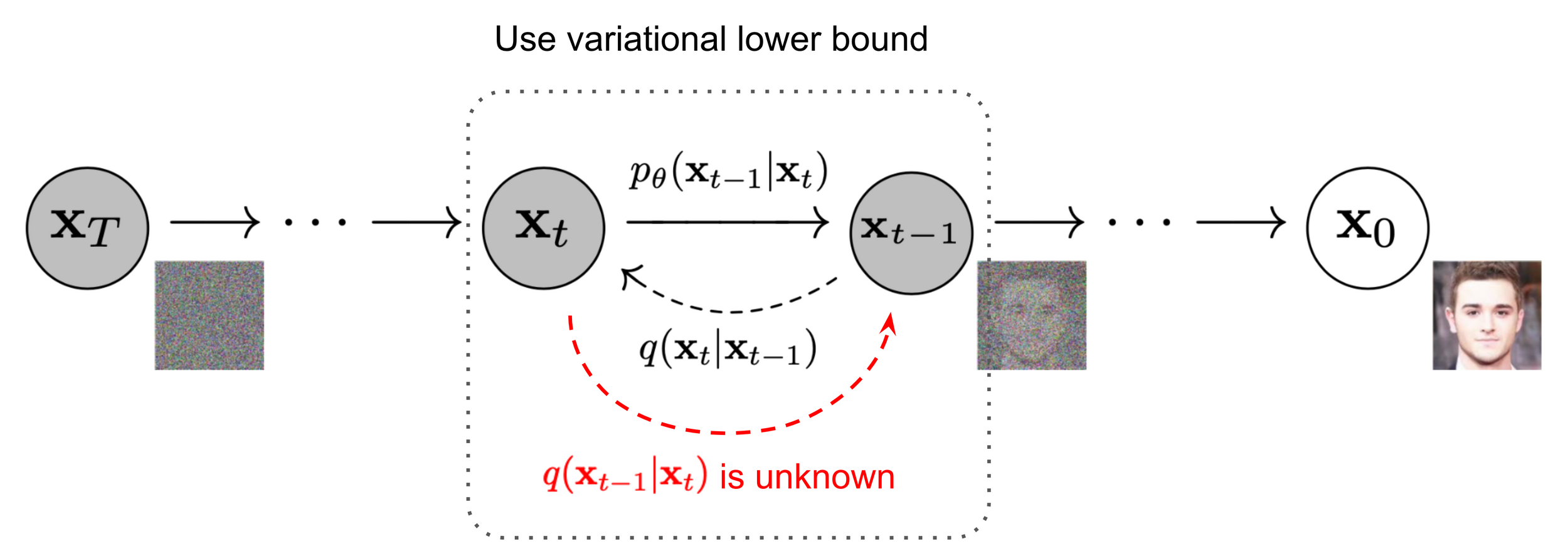
Image source: Ho et al. 2020
By russtedrake
MIT Underactuated Robotics Spring 2023 http://underactuated.csail.mit.edu


