





russtedrake PRO
Roboticist at MIT and TRI
If yes, why (precisely)?
Deep learning theory (for supervised learning):
Are we really doing "Deep RL"?
Certainly the deep learning echo system has helped! (big compute, Adam, weight initializations, hyper parameter searches, ...)
Classic control problems can be solved with policy gradient
More direct path to (dynamic) output feedback policies (aka "pixels to torques")
Terry Suh
Tao Pang
vs
SOCP
gravity
contact forces
mass
stiffness
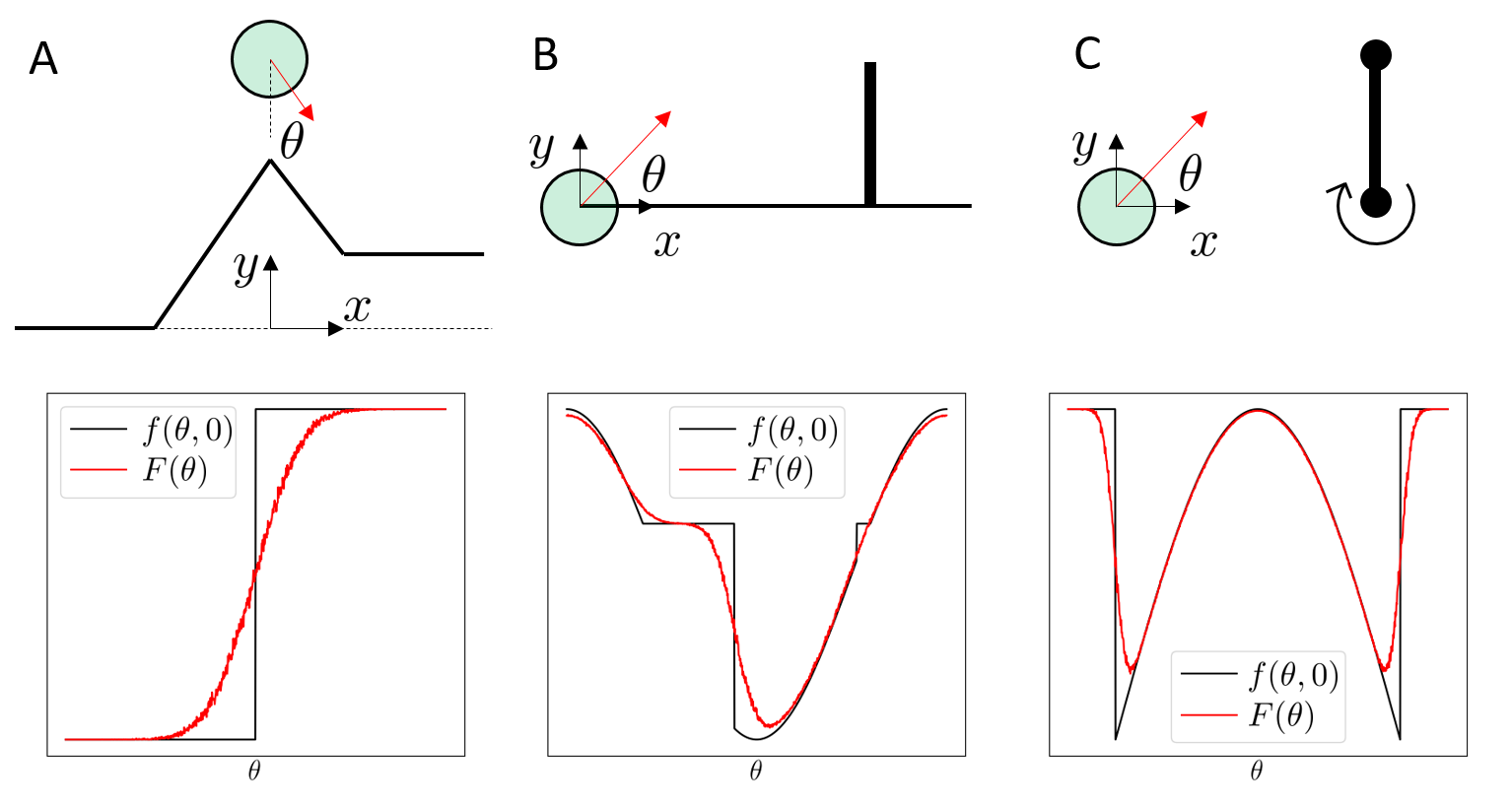
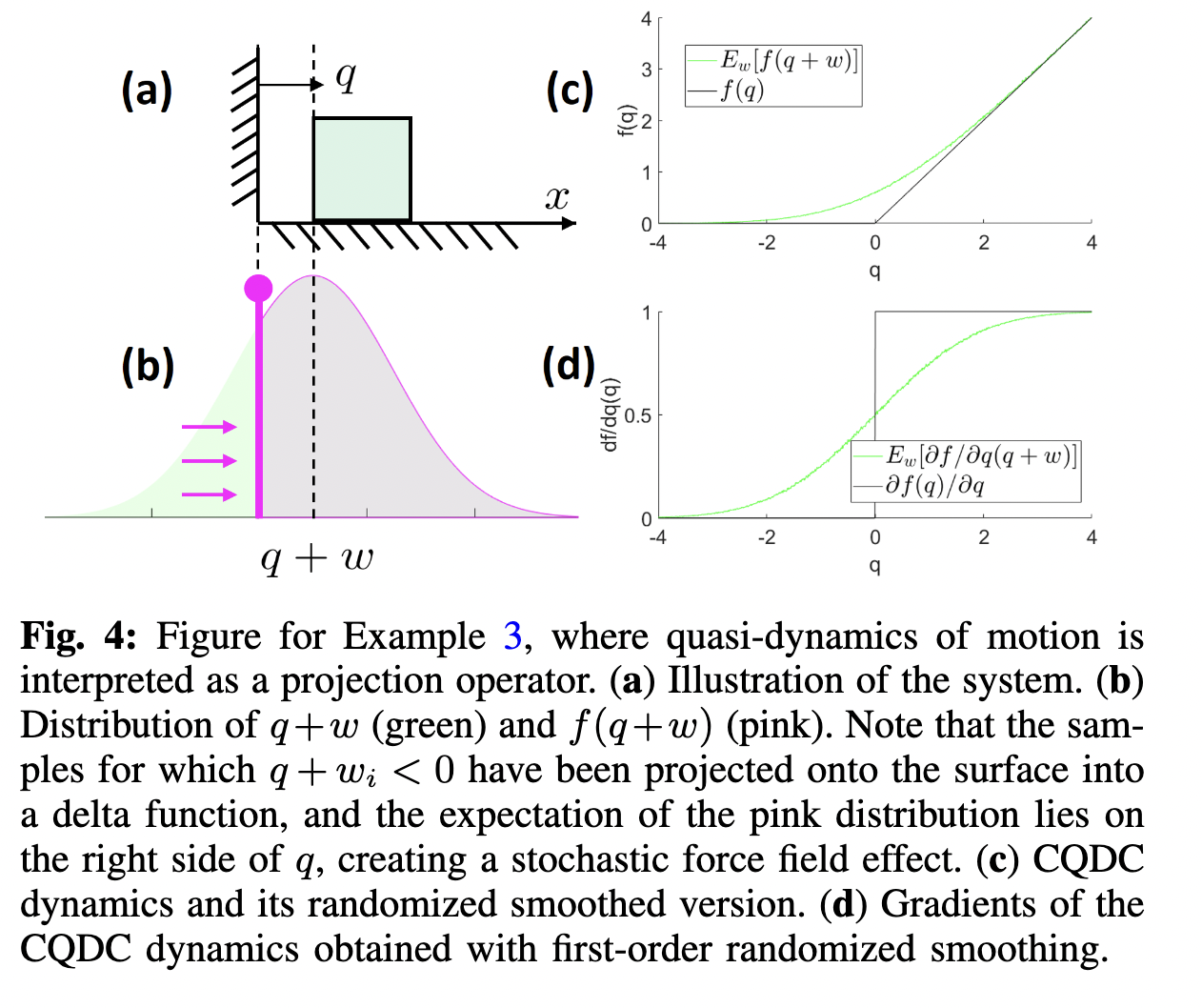
Linearizing a smoothed function
This can be approximated by (zero-order or first-order) Monte-carlo gradient estimation; as seen in RL.
Randomized smoothing of quasi-dynamic model gives "force at a distance"
Log-barrier penalty method
In simple cases, can establish equivalence with the randomized smoothing (from RL)
Idea: Grow RRT only in unactuated DOFs; distance metric based on smoothed linearization
2022 International Conference on Machine Learning (ICML), Accepted as Long Talk
will be submitted (and available on arxiv) very soon!
For more details:
By russtedrake
TRI dexterous group meeting


