













Sarah Dean PRO
asst prof in CS at Cornell
Prof Sarah Dean
training data
\(\{(x_i, y_i)\}\)
model
\(f:\mathcal X\to\mathcal Y\)
policy
observation
action
training data
\(\{(x_i, y_i)\}\)
model
\(f:\mathcal X\to\mathcal Y\)
observation
prediction
sampled i.i.d. from \(\mathcal D\)
\(x\sim\mathcal D_{x}\)
Goal: for new sample \(x,y\sim \mathcal D\), prediction \(\hat y = f(x)\) is close to true \(y\)
Goal: for new sample \(x,y\sim \mathcal D\), prediction \(\hat y = f(x)\) is close to true \(y\)
\(\ell(y,\hat y)\) measures "loss" of predicting \(\hat y\) when it's actually \(y\)
Encode our goal in risk minimization framework:
$$\min_{f\in\mathcal F}\mathcal R(f) = \mathbb E_{x,y\sim\mathcal D}[\ell(y, f(x))]$$
$$\hat \theta = \arg\min \sum_{i=1}^N(-\theta^\top x_i\cdot y_i)_+$$
predict \(\hat f(x) = \mathbb 1\{\hat\theta^\top x \geq t\}\)
No fairness through unawareness!
\(x_i=\) demographic info and browsing history
\(y_i=\) clicked (1) or not (-1)
The index of \(\hat\theta\) corresponding to "female" is negative!
The index of \(\hat\theta\) corresponding to "visited website for women's clothing store" is negative!
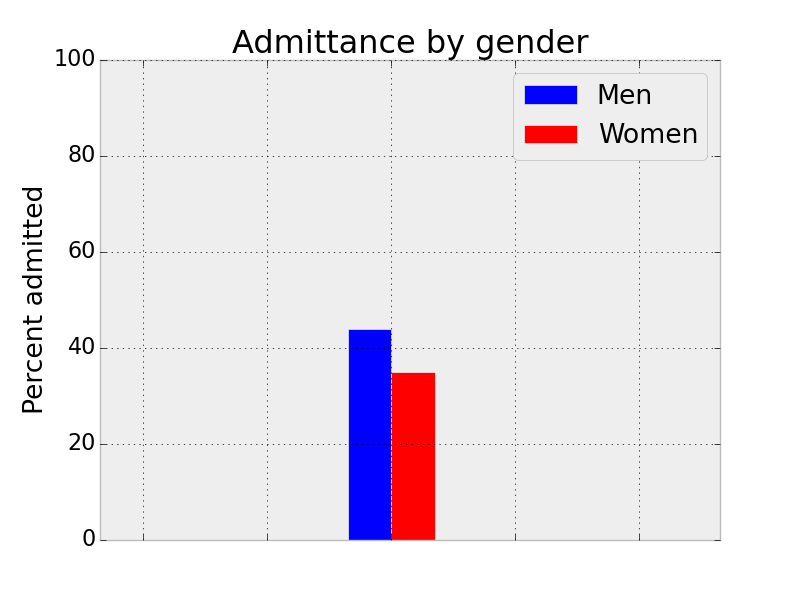
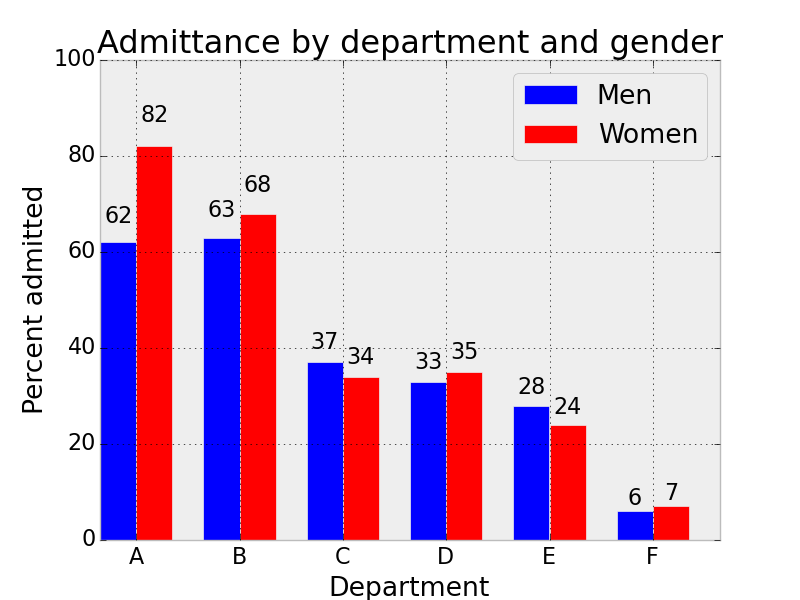
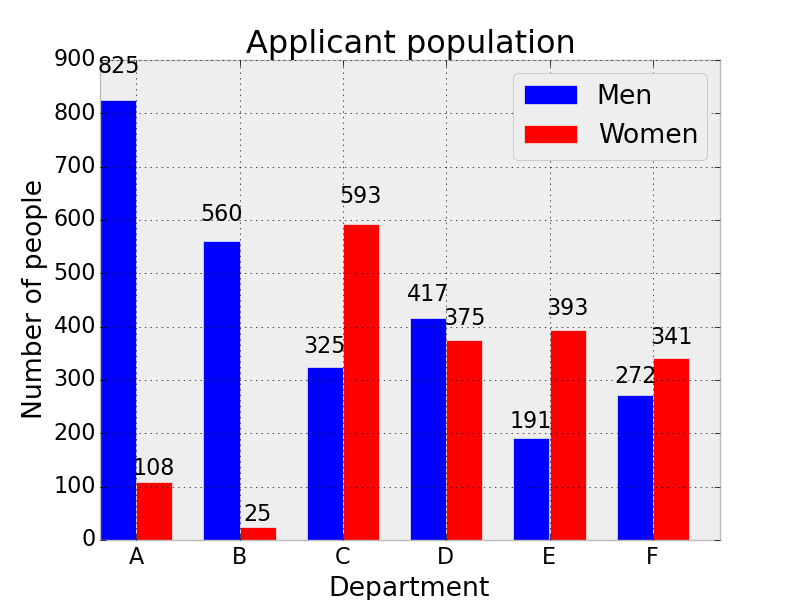
Accuracy
\(\mathbb P( \hat Y = Y)\) = ________
Positive rate
\(\mathbb P( \hat Y = 1)\) = ________
False positive rate
\(\mathbb P( \hat Y = 1\mid Y = 0)\) = ________
False negative rate
\(\mathbb P( \hat Y = 0\mid Y = 1)\) = ________
Positive predictive value
\(\mathbb P( Y = 1\mid\hat Y = 1)\) = ________
Negative predictive value
\(\mathbb P( Y = 0\mid\hat Y = 0)\) = ________
\(X\)
\(Y=1\)
\(Y=0\)
\(f(X)\)
\(3/4\)
\(9/20\)
\(1/5\)
\(3/10\)
\(7/9\)
\(8/11\)
Independence: prediction does not depend on \(a\)
\(\hat y \perp a\)
e.g. ad displayed at equal rates across gender
Separation: given outcome, prediction does not depend on \(a\)
\(\hat y \perp a~\mid~y\)
e.g. ad displayed to interested users at equal rates across gender
Sufficiency: given prediction, outcome does not depend on \(a\)
\( y \perp a~\mid~\hat y\)
e.g. users viewing ad are interested at equal rates across gender
In addition to features \(x\) and labels \(y\), individuals have protected attribute \(a\) (e.g. gender, race)
Ref: Ch 2 of Hardt & Recht, "Patterns, Predictions, and Actions" mlstory.org; Ch 3 of Barocas, Hardt, Narayanan "Fairness and Machine Learning" fairmlbook.org.
“Black defendants who did not recidivate over a two-year period were nearly twice as likely to be misclassified. [...] White defendants who re-offended within the next two years were mistakenly labeled low risk almost twice as often.”
“In comparison with whites, a slightly lower percentage of blacks were ‘Labeled Higher Risk, But Didn’t Re-Offend.’ [...] A slightly higher percentage of blacks were ‘Labeled Lower Risk, Yet Did Re-Offend.”’
\(\mathbb P(\hat y = 1\mid y=0, a=\text{Black})> \mathbb P(\hat y = 1\mid y=0, a=\text{White}) \)
\(\mathbb P(\hat y = 0\mid y=1, a=\text{Black})< \mathbb P(\hat y = 0\mid y=1, a=\text{White}) \)
\(\mathbb P(y = 0\mid \hat y=1, a=\text{Black})\approx \mathbb P( y = 0\mid \hat y=1, a=\text{White}) \)
\(\mathbb P(y = 1\mid \hat y=0, a=\text{Black})\approx \mathbb P( y = 1\mid \hat y=0, a=\text{White}) \)
COMPAS risk predictions do not satisfy separation
COMPAS risk predictions do satisfy sufficiency
Kleinberg & Raghavan, Inherent Trade-Offs in the Fair Determination of Risk Scores
Simpson's Paradox, Cory Simon
Barocas & Selbst, Big Data's Disparate Impact
image cropping
facial recognition
information retrieval
generative models
performance depends on risk \(\mathcal R(f)\)
$$\hat f = \min_{f\in\mathcal F} \frac{1}{n} \sum_{i=1}^n \ell(y_i, f(x_i))$$
\(\mathcal R_N(f)\)
(with fairness constraints)
training data
\(\{(x_i, y_i)\}\)
model
\(f:\mathcal X\to\mathcal Y\)
Fundamental Theorem of Supervised Learning:
Empirical risk minimization
$$\hat f = \min_{f\in\mathcal F} \frac{1}{n} \sum_{i=1}^n \ell(y_i, f(x_i))$$
\(\mathcal R_N(f)\)
1. Representation
2. Optimization
3. Generalization
At first glance, linear representation seems limiting
Least-squares linear regression models \(y\approx \theta^\top x\)
$$\min_{\theta\in\mathbb R^d} \frac{1}{n}\sum_{i=1}^n \left(\theta^\top x_i - y_i\right)^2$$
but we can encode rich representations by expanding the features (increasing \(d\))
\(y = (x-1)^2\)
\(y = \begin{bmatrix}1\\-2\\1\end{bmatrix}^\top \begin{bmatrix}1\\x\\x^2\end{bmatrix} \)
\(\varphi(x)\)
For more, see Ch 4 of Hardt & Recht, "Patterns, Predictions, and Actions" mlstory.org.
one global min
infinitely many global min
local and global min
Optimization is straightforward due to differentiable and convex risk
$$\min_{\theta\in\mathbb R^d} \frac{1}{n}\sum_{i=1}^n \left(\theta^\top x_i - y_i\right)^2$$
strongly convex
convex
nonconvex
Derivation of optimal solution
$$\hat\theta\in\arg\min_{\theta\in\mathbb R^d} \frac{1}{n}\sum_{i=1}^n \left(\theta^\top x_i - y_i\right)^2$$
first order optimality condition: \( \displaystyle \sum_{i=1}^n x_i x_i^\top\hat \theta = \sum_{i=1}^n y_ix_i \)
min-norm solution: \( \displaystyle \hat\theta = \left( \sum_{i=1}^n x_i x_i^\top\right)^\dagger\sum_{i=1}^n y_ix_i \)
Proof: exercise. Hint: consider the span of the \(x_i\).
Iterative optimization with gradient descent $$\theta_{t+1} = \theta_t - \alpha\sum_{i=1}^n (\theta_t^\top x_i - y_i)x_i$$
Claim: suppose \(\theta_0=0\) and GD converges to a minimizer. Then it converges to the minimum norm solution.
Generalization: under the fixed design generative model, \(\{x_i\}_{i=1}^n\) are fixed and
\(y_i = \theta_\star^\top x_i + v_i\) with \(v_i\) i.i.d. with mean \(0\) and variance \(\sigma^2\)
\(\mathcal R(\theta) = \frac{1}{n}\sum_{i=1}^n \mathbb E_{y_i}\left[(x_i^\top \theta - y_i)^2\right]\)
Claim: when features span \(\mathbb R^d\), the excess risk \(\mathcal R(\hat\theta) -\mathcal R(\theta_\star) =\frac{\sigma^2 d}{n}\)
Exercises:
Next time: online learning with linear least-squares case study
By Sarah Dean




