













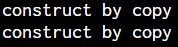


海之音
INFOR 36th 學術長 @小海_夢想特急_夢城前
IZCC 寒訓 / 星河景中建楓成 - C++
自學 C++ 太苦了 不如 試試女裝
這堂課是來勸退各位的,全名 C++: 從入門到入土
現在轉系還來得及 躺平沒有人會笑你的
寫 C++ 是會越寫越多 Bug 的(確信
const int a = 5;const.cpp:4:11: error: uninitialized 'const a' [-fpermissive]
4 | const int a;
|void func() {
static int cnt = 0;
std::cout << ++cnt << "\n";
}
int main() {
for (int i = 0; i < 10; i++)
func();
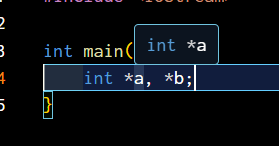
}int *a, *b;int main() {
int a;
std::cout << &a; // 0xbdd19ffe9c
}int a;
int *pt_a = &a;int main() {
int a = 5;
int *pt_a = &a;
std::cout << *pt_a; // 5
}int main() {
int *pt = &5; // compile error
}pointer.cpp:2:20: error: lvalue required as unary '&' operand
2 | int *pt = &5;
|int main() {
int *pt;
std::cout << pt << "\n"; // 0x8 or something unusual
std::cout << *pt; // runtime error
}int main() {
int val = 2;
int* a = &val;
int b = 2 * *a;
std::cout << b; // 4
}int main() {
int a = 5;
int *pt1 = &a, *pt2 = &a;
std::cout << *pt1 << "\n"; // --- 1.
*pt1 = 1;
std::cout << *pt1 << " " << *pt2 << "\n"; // --- 2.
}int *a = nullptr;
int *b = NULL;int main() {
int a = 5;
int *pt_a = &a;
int **pt_pt_a = &pt_a;
std::cout << **pt_pt_a; // 5
}int main() {
int a[10];
for (int i = 0; i < 10; i++) a[i] = i;
std::cout << a << "\n"; // 0x1c5d7ff6b0
std::cout << *(a + 5); // 5
}偷張以前的圖來用
int main() {
int a[5][5];
for (int i = 0; i < 5; i++)
for (int j = 0; j < 5; j++)
a[i][j] = i * 10 + j;
std::cout << a[2][1] << " " << *(*(a + 2) + 1); // 21 21
}不用特別在乎 反正沒人會這樣用(
int main() {
int a;
int *pt_a = &a;
std::cout << pt_a << "\n"; // 0x4ab7fff9c4
std::cout << ++pt_a << "\n"; // 0x4ab7fff9c8
}int main() {
long long a;
long long *pt_a = &a;
std::cout << pt_a << "\n"; // 0x89133ff8d0
std::cout << ++pt_a << "\n"; // 0x89133ff8d8
}int main() {
int a = 8;
void *pt_a = &a;
std::cout << *(int *)pt_a; // 8
}int main() {
int a;
std::cout << sizeof(a) << "\n"; // 4
std::cout << sizeof(long long) << "\n"; // 8
std::cout << sizeof(void *) << "\n"; // 8
}int main() {
int *a = (int *)malloc(sizeof(int));
*a = 5;
std::cout << *a; // 5
int *b;
*b = 5; // runtime error
std::cout << *b;
}int main() {
int *a = (int *)calloc(10, sizeof(int));
std::cout << a[5]; // 0
}int main() {
int *a = (int *)calloc(10, sizeof(int));
int *b = (int *)realloc(a, sizeof(int) * 20);
if (b == NULL) return 0;
a = b;
}int *a = new int;int *a = new int[10];int *a = (int *)malloc(sizeof(int));
free(a);
int *b = new int;
delete b;pointer.cpp:7:17: warning: 'void operator delete(void*, std::size_t)' called on unallocated object 'a' [-Wfree-nonheap-object]
7 | delete &a;
| ^
pointer.cpp:6:13: note: declared here
6 | int a;
| const int val = 5;
const int *ptr_val = &val;
int var;
int* const ptr_var= &var;int add(int a, int b) {
return a + b;
}
int main() {
int (*func)(int, int) = &add; // & 可省略
std::cout << (*func)(1, 2); // 也可直接呼叫 func(1, 2)
}int a = 5;
int &rf_a = a; reference.cpp:4:14: error: 'rf_a' declared as reference but not initialized
4 | int &rf_a;
| ^~~~int sum(std::vector<int> &target) {
int result = 0;
for (int i = 0; i < target.size(); i++)
result += target[i];
return result;
}
int main() {
std::vector<int> data(100, 100);
std::cout << sum(data); // 10000
}void modify(int &target) {
target = 5;
}
int main() {
int a = 10;
modify(a);
std::cout << a; // 5
}int sum(const std::vector<int> &target) {
int result = 0;
for (int i = 0; i < target.size(); i++)
result += target[i];
return result;
}
int main() {
std::vector<int> data(100, 100);
std::cout << sum(data); // 10000
}const int &a = 10;const int tmp = 10;
const int &a = tmp;int a; // a is lvalue
int &b = a; // b is lvalue
a + 1; // a + 1 is rvalue
int func1();
func1(); // func1() is rvalue
int &func2();
func2() = a; // func2() is lvalueint &&a = 5;int a = 5, b = 4;
int &&c = a + b;std::string a = "very long string";
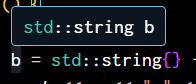
std::string b = "another very long string";
std::string &&c = a + b;int main() {
int a = 5;
int &&b = std::move(a);
b = 1;
std::cout << a; // 1
}int main() {
int a = 5;
int b = std::move(a);
b = 1;
std::cout << b << " " << a; // 1 5
}int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
std::vector<int>::iterator it = data.begin();
for (; it != data.end(); it++)
std::cout << *it << " ";
}double length, weight, color;
void meow() {
std::cout << "meow";
}double len1, wei1, color1;
double len2, wei2, color2;
double len3, wei3, color3;
...
void meow() {
std::cout << meow;
}身長
體重
顏色(R, G, B)
我會喵喵叫而且很可愛喔
貓
class Cat {
double length;
double weight;
double color;
void meow() {
std::cout << "meow";
}
};
class Dog {
double length;
double weight;
double color;
void bark() {
std::cout << "woof";
}
};class Cat {
double length;
double weight;
double color;
void meow() {
std::cout << "meow";
}
};
int main() {
Cat cat1, cat2;
}| public: 公有成員 | protected: 受保護 | private: 私有成員 |
|---|---|---|
| 外部可存取 | 外部不可存取 | 外部不可存取 |
| 衍生類可存取 | 衍生類可存取 | 衍生類不可存取 |
寬鬆
嚴格
class Cat {
private:
double length;
double weight;
double color;
public:
void meow() {
std::cout << "meow\n";
}
};
int main() {
Cat cat;
cat.meow(); // meow
}class Cat {
private:
double length;
double weight;
double color;
public:
void meow() {
std::cout << "meow\n";
}
};
int main() {
Cat *cat;
cat->meow(); // meow
}cat.cpp: In function 'int main()':
cat.cpp:17:26: error: 'double Cat::color' is private within this context
17 | std::cout << cat.color;
| ^~~~~
cat.cpp:7:16: note: declared private here
7 | double color;
| ^~~~~class Cat {
private:
double length;
double weight;
double color;
public:
void print_data() {
std::cout << length << " "
<< weight << " "
<< color << "\n";
}
};
int main() {
Cat cat;
cat.print_data();
}class TicTacToe {
static const char self = 'O', opp = 'X';
...
};class TicTacToe {
static char self = 'O', opp = 'X';
...
};
char TicTacToe::self = 'O', TicTacTor::opp = 'X';class TicTacToe {
inline static char self = 'O', opp = 'X';
...
};class vector {
class iterator {
...
};
...
};
int main() {
vector<int>::iterator it;
}class TicTacToe {
static int use_cnt;
public:
static void print_cnt();
};
int TicTacToe::use_cnt = 0;
void TicTacToe::print_cnt() {
std::cout << TicTacToe::use_cnt << "\n";
}int main() {
TicTacToe::print_cnt();
}class A {
int a = 5;
public:
void modify() {
a = 10;
}
};
int main() {
const A const_object;
const_object.modify();
}class A {
int a = 5;
public:
void print() const {
std::cout << a << "\n";
}
};
int main() {
const A const_object;
const_object.print();
}int a = 5;
int a(5);std::vector<int> a(5, 0);class Box {
int length;
int width;
int height;
public:
Box(int _l, int _w, int _h)
: length(_l), width(_w), height(_h) {}
Box(int _l)
: length(_l), width(_l), height(_l) {}
};class Box {
int length;
int width;
int height;
public:
Box(int _l, int _w, int _h)
: length(_l), width(_w), height(_h) {
std::cout << "Box: "
<< length << ", "
<< width << ", "
<< height << "\n";
}
};class Box {
int length, width, height;
public:
~Box () {
std::cout << "A box disappreared.\n";
}
};
int main() {
Box test;
}class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
complex operator+(const complex& another) {
return {Re + another.Re, Im + another.Im};
}
};class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
complex operator-() {
return {-Re, -Im};
}
};class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
complex operator-(const complex& another) {
return {Re - another.Re, Im - another.Im};
}
};class Cmp {
public:
bool operator()(int a, int b) {
return a < b;
}
};
int main() {
Cmp cmp;
std::cout << cmp(1, 2);
}class Human;
class Bot;
class TicTacToe {
private:
char board[3][3];
public:
friend class Human;
friend class Bot;
};class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
friend std::ostream& operator<<(std::ostream& out, const complex& target) {
out << target.Re << " + " << target.Im << "i";
return out;
}
};
int main() {
complex a(1, 2);
std::cout << a;
}身長
體重
顏色(R, G, B)
動物
喵喵叫
貓
汪汪叫
狗
| public: 公有成員 | protected: 受保護 | private: 私有成員 |
|---|---|---|
| 外部可存取 | 外部不可存取 | 外部不可存取 |
| 衍生類可存取 | 衍生類可存取 | 衍生類不可存取 |
寬鬆
嚴格
| public: public | protected: protected | private: 無法存取 |
public 繼承
| public: protected | protected: protected | private: 無法存取 |
protected 繼承
| public: private | protected: private | private: 無法存取 |
private 繼承
基類成員權限: 繼承後權限
繼承方式
class Box {
protected:
int length;
int width;
int height;
};
class Gift_box : public Box {
int gift_type;
};class A: public B, private C {
...
};class Bot {
};
class Bot1 : public Bot {
};
class Bot2 : public Bot {
};
void run(Bot &bot);class Bot {
public:
void hello() {
std::cout << "hello, world!";
}
};
class Bot1 : public Bot {
public:
void hello() {
std::cout << "hello, world! I'm bot1\n";
}
};
void run(Bot &bot) {
bot.hello();
}
int main() {
Bot1 test_bot;
run(test_bot);
}int add(int a, int b) {
return a + b;
}
std::string add(const std::string &a, const std::string &b) {
return a + b;
}
int main () {
std::cout << add(1, 2) << "\n"; // 3
std::cout << add("apple", "banana") << "\n"; // applebanana
}class Bot {
public:
virtual void hello() {
std::cout << "hello, world!";
}
};
class Bot1 : public Bot {
public:
virtual void hello() {
std::cout << "hello, world! I'm bot1\n";
}
};
void run(Bot &bot) {
bot.hello();
}
int main() {
Bot1 test_bot;
run(test_bot);
}class Bot {
public:
virtual void hello() = 0;
};class.cpp:13:14: error: cannot declare variable 'test_bot' to be of abstract type 'Bot1'
13 | Bot1 test_bot;
| ^~~~~~~~
class.cpp:9:7: note: because the following virtual functions are pure within 'Bot1':
9 | class Bot1 : public Bot {
| ^~~~
class.cpp:6:22: note: 'virtual void Bot::hello()'
6 | virtual void hello() = 0;class Bot {
public:
virtual void say(std::string &output) {
std::cout << output << "\n";
}
};
class Bot1 : public Bot {
public:
virtual void say(const std::string &output) {
std::cout << output << "\n";
}
};class Bot {
public:
virtual void say(std::string &output) {
std::cout << output << "\n";
}
};
class Bot1 : public Bot {
public:
virtual void say(const std::string &output) override {
std::cout << output << "\n";
}
};class.cpp:13:22: error: 'virtual void Bot1::say(const std::string&)' marked 'override', but does not override
13 | virtual void say(const std::string &output) override {
|int add(int a, int b) {
return a + b;
}
std::string add(const std::string &a, const std::string &b) {
return a + b;
}template <typename T>
T add(const T& a, const T& b) {
return a + b;
}template <typename T>
T add(const T& a, const T& b) {
return a + b;
}
int main() {
std::cout << add<int>(1, 2) << "\n";
std::cout << add<std::string>("apple", "banana") << "\n";
}int add(const int &a, const int &b) {
return a + b;
}
std::string add(const std::string &a, const std::string &b) {
return a + b;
}
int main() {
std::cout << add(1, 2) << "\n";
std::cout << add("apple", "banana") << "\n";
}template <typename T>
class array {
T* data;
public:
T& operator[](int index) {
return *(data + index);
}
};int main() {
std::vector<int> array;
}template<typename T>
T add(T a, T b) {
return a + b;
}
int main() {
std::cout << add(1, 2);
}template <typename T, const int SIZE>
class array {
T* data;
public:
T& operator[](int index) {
if (index < SIZE && index >= 0)
return *(data + index);
}
};template<typename T>
void print(T&& target) {
std::cout << target << "\n";
}
int main() {
int a = 4;
print(a);
print(1);
}class BotData {
};
class Bot {
public:
Bot(const BotData&) {
std::cout << "construct by copy\n";
}
Bot(BotData&&) {
std::cout << "construct by move\n";
}
};
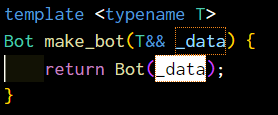
template <typename T>
Bot make_bot(T&& _data) {
return Bot(_data);
}
int main() {
BotData lvalue;
make_bot(lvalue);
make_bot(BotData()); // rvalue
}...
template <typename T>
Bot make_bot(T&& _data) {
return Bot(std::forward<T>(_data));
}
...
int main() {
BotData lvalue;
make_bot(lvalue);
make_bot(BotData()); // rvalue
}construct by copy
construct by movetemplate <typename T>
void print(T&& target) {
std::cout << target;
}
template <typename T, typename... Ts>
void print(T&& target, Ts&&... Args) {
std::cout << target << " ";
print(std::forward<Ts>(Args)...);
}template <typename... Ts>
void print(Ts&&... Args) {
std::cout << sizeof...(Args);
}
int main() {
print(1, 2, 3, 4, 5); // 5
}template <typename T>
void print(T target) {
std::cout << target;
}
template <typename T, typename... Ts>
void print(T target, Ts... Args) {
std::cout << target << " ";
print(Args...);
}template <typename T>
void print(T&& target) {
std::cout << target;
}
template <typename T, typename... Ts>
void print(T&& target, Ts&&... Args) {
std::cout << target << " ";
print(std::forward<Ts>(Args)...);
}
int main() {
print(1, "XD", 3.1416);
}// auto.c
int main() {
auto int a = 5; // 等同 int a = 5;
printf("%d\n", a);
}int main() {
auto a = 4;
auto b = std::string{} + "apple" + "banana";
std::cout << a << " " << b;
}int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
auto it = data.begin();
}auto add(auto a, auto b) {
return a + b;
}template<typename T1, typename T2>
auto add(T1 a, T2 b) -> decltype(a + b) {
return a + b;
}
int add(int a, int b) {
return a + b;
}
int main() {
auto func = add;
}template<typename T1, typename T2>
auto add(T1 a, T2 b) -> decltype(a + b) {
return a + b;
}
#define INF 0x7FFFFFFF
#define RANDOM#include <iostream>
#define INF 0x7FFFFFFF
int main() {
std::cout << INF;
}#if defined(X)
...
#endif#ifdef X#if __cplusplus >= 202000
do something...
#elif __cplusplus >= 201700
do something...
#else
do something...
#endif#define X 5
...
#undef X#include <iostream>
#define DEBUG
int main() {
int a = 5;
#ifdef DEBUG
std::cout << a;
#endif
}#include <iostream>
#define lowbit(x) (-x & x)
int main() {
std::cout << lowbit(6);
}#include "game_act_type.hpp"a.hpp
const int a = 5;b.hpp
#include "a.hpp"c.cpp
#include "a.hpp"
#incldue "b.hpp"In file included from b.hpp:1,
from c.cpp:2:
a.hpp:1:11: error: redefinition of 'const int a'
1 | const int a = 5;
| ^
In file included from c.cpp:1:
a.hpp:1:11: note: 'const int a' previously defined here
1 | const int a = 5;
|#ifndef _A_HPP_
#define _A_HPP_
const int a = 5;
#endifnamespace Sea {
bool is_Sea_weak() {
return true;
}
}namespace Sea {
}int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
for (int i : data)
std::cout << i << " ";
}int main() {
std::vector<std::vector<int>> graph;
for (auto &v : graph)
v.resize(5);
}int main() {
std::pair<int, int> nums(1, 2);
auto [i, j] = nums;
}By 海之音
四校聯合寒訓 - C++




