


海之音
INFOR 36th 學術長 @小海_夢想特急_夢城前
Artificial Neural Network, ANN
INFOR 36th. @小海_夢想特急_夢城前
Concept
神經網路
像素點 1
像素點 2
像素點 3
...
像素點 n
目標 1
目標 2
目標 3
...
目標 m
Matrix and Vector
sudo apt-get install python3/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"brew install python3python3 --versionpip install numpy
import numpy as np導入 numpy 模組,稱為 np
import numpy as np
# 使用 python 的 list 宣告陣列
arr = np.array(
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
)
# 宣告一個全是 0 的陣列
arr1 = np.zeros((2, 3))
# 宣告一個隨機填充的陣列
arr2 = np.random.random((2, 3))
print(arr, arr1, arr2, sep = '\n')import numpy as np
# 宣告一個 fp16 的陣列
arr = np.array(
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
dtype = np.float16
)
print(arr)import numpy as np
arr = np.array(
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
)
print(arr + arr, arr - arr, sep = '\n')import numpy as np
arr = np.array(
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
)
print(arr.T)import numpy as np
arr = np.array(
[[1, 2, 3],
[4, 5, 6]]
)
print(arr.dot(arr.T), arr.T.dot(arr), sep = '\n')#include <cassert>
#include <cmath>
#include <concepts>
#include <functional>
#include <iostream>
#include <random>
#include <utility>
#include <vector>
template <typename Tp>
concept addable = requires(Tp a, Tp b) {
a + b;
};
template <typename Tp>
concept minusable = requires(Tp a, Tp b) {
a - b;
};
template <typename Tp>
concept multiplyable = requires(Tp a, Tp b) {
a * b;
};
template <typename Tp>
requires addable<Tp> && minusable<Tp> && multiplyable<Tp>
class Matrix {
std::vector<std::vector<Tp>> data;
int R, C;
public:
Matrix() = default;
Matrix(const Matrix<Tp> &) = default;
Matrix(Matrix<Tp> &&) = default;
Matrix &operator=(const Matrix<Tp> &) = default;
Matrix &operator=(Matrix<Tp> &&) = default;
Matrix(int _R)
: R(_R), C(1), data(_R, std::vector<Tp>(1)) {}
Matrix(int _R, std::function<Tp()> &&generator)
: R(_R), C(1), data(_R, std::vector<Tp>(1)) {
for (int i = 0; i < _R; i++)
data[i][0] = generator();
}
Matrix(int _R, std::function<Tp(int)> &&generator)
: R(_R), C(1), data(_R, std::vector<Tp>(1)) {
for (int i = 0; i < _R; i++)
data[i][0] = generator(i);
}
Matrix(int _R, int _C)
: R(_R), C(_C), data(_R, std::vector<Tp>(_C)) {}
Matrix(int _R, int _C, std::function<Tp()> &&generator)
: R(_R), C(_C), data(_R, std::vector<Tp>(_C)) {
for (int i = 0; i < _R; i++)
for (int j = 0; j < _C; j++)
data[i][j] = generator();
}
Matrix(int _R, int _C, std::function<Tp(int, int)> &&generator)
: R(_R), C(_C), data(_R, std::vector<Tp>(_C)) {
for (int i = 0; i < _R; i++)
for (int j = 0; j < _C; j++)
data[i][j] = generator(i, j);
}
Matrix(std::vector<std::vector<Tp>> &&_data) {
assert(_data.size() > 0);
R = _data.size();
assert(_data[0].size() > 0);
C = _data[0].size();
data = std::forward<std::vector<std::vector<Tp>>>(_data);
}
Matrix(const std::vector<Tp> &_data) {
assert(_data.size() > 0);
R = _data.size(), C = 1;
data.resize(R, std::vector<Tp>(1));
for (int i = 0; i < R; i++)
data[i][0] = _data[i];
}
public:
inline Tp &operator()(int _r, int _c) {
return data[_r][_c];
}
inline const Tp &operator()(int _r, int _c) const {
return data[_r][_c];
}
Matrix operator+(const Matrix &another) const {
assert(R == another.R && C == another.C);
Matrix result(R, C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
result(i, j) = data[i][j] + another(i, j);
return result;
}
Matrix &operator+=(const Matrix &another) {
assert(R == another.R && C == another.C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
data[i][j] += another(i, j);
return (*this);
}
Matrix operator-(const Matrix &another) const {
assert(R == another.R && C == another.C);
Matrix result(R, C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
result(i, j) = data[i][j] - another(i, j);
return result;
}
Matrix &operator-=(const Matrix &another) {
assert(R == another.R && C == another.C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
data[i][j] -= another(i, j);
return (*this);
}
Matrix operator*(Tp k) const {
Matrix result(*this);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
result(i, j) = data[i][j] * k;
return result;
}
Matrix &operator*=(Tp k) {
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
data[i][j] *= k;
return (*this);
}
Matrix operator*(const Matrix another) const {
assert(C == another.R);
Matrix result(R, another.C);
for (int r = 0; r < R; r++)
for (int c = 0; c < another.C; c++)
for (int i = 0; i < C; i++)
result(r, c) += data[r][i] * another(i, c);
return result;
}
public:
std::pair<int, int> size() {
return {R, C};
}
friend std::ostream &operator<<(std::ostream &out, Matrix<Tp> target) {
out << "[\n";
for (int i = 0; i < target.R; i++) {
out << " [";
for (int j = 0; j < target.C; j++)
out << target.data[i][j] << " ";
out << "\b]\n";
}
out << "]";
return out;
}
Matrix T() {
Matrix<Tp> result(C, R);
for (int i = 0; i < C; i++)
for (int j = 0; j < R; j++)
result(i, j) = data[j][i];
return result;
}
};Forward
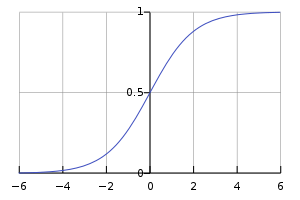
Sigmoid
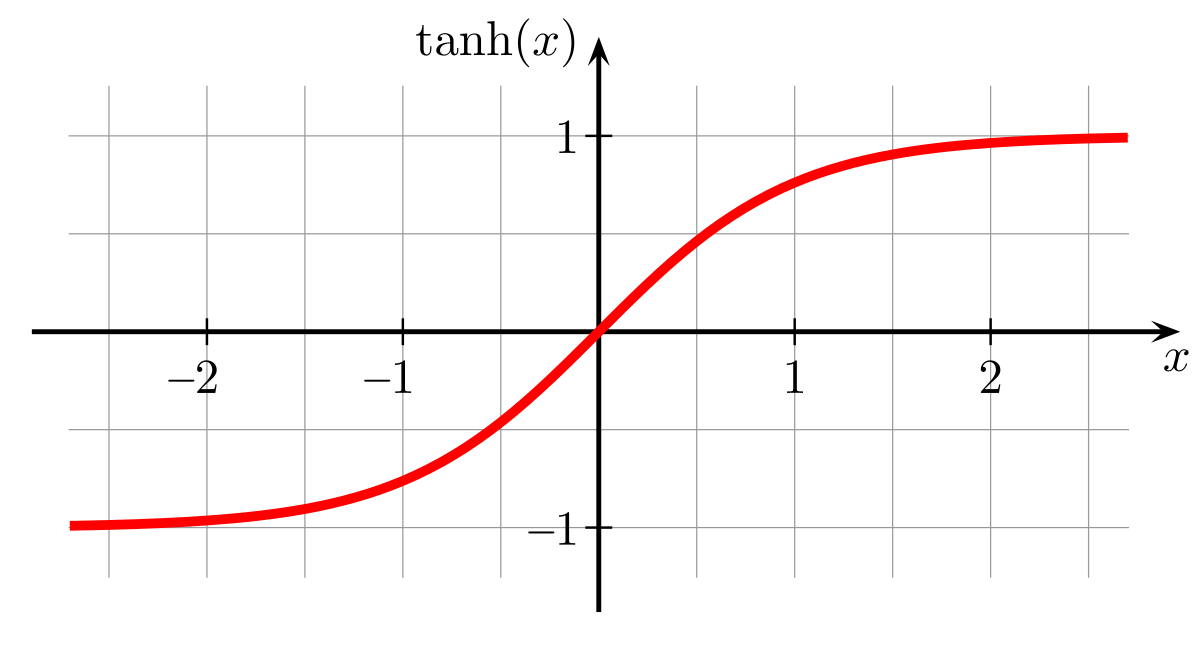
tanh
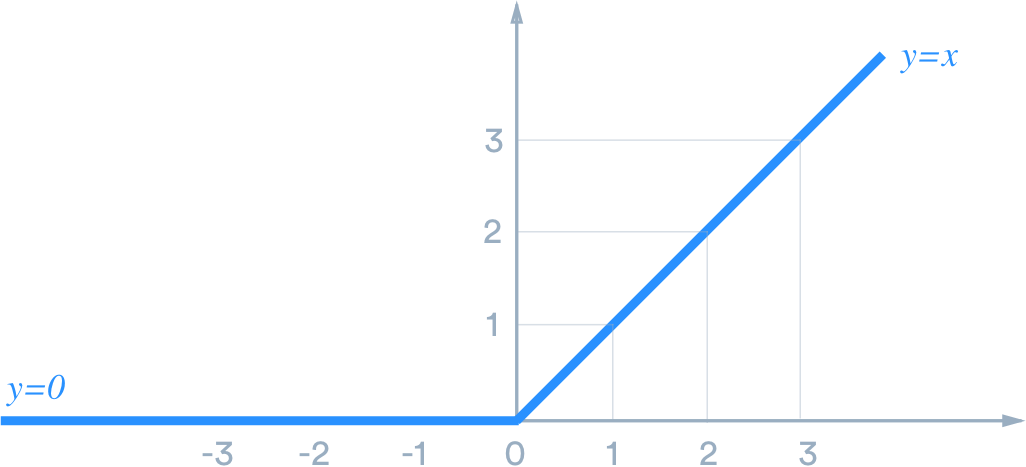
ReLU
然而,只有一層的話經常複雜度不夠
聰明的你肯定能想到怎麼做吧
然而,只有一層的話經常複雜度不夠
聰明的你肯定能想到怎麼做吧
...
以前一層激活後的輸出作為後一層的輸入
看起來就像在把資料往前傳
...
import numpy as np
class NeuralNetwork:
def __init__(self, topo: list[int], act, dact):
self.weight = [np.zeros((0, 0), dtype = np.float16)]
self.bias = [np.zeros((topo[0], 1), dtype = np.float16)]
self.value = [np.zeros((topo[0], 1), dtype = np.float16)]
self.zeta = [np.zeros((topo[0], 1), dtype = np.float16)]
self.act = act
self.dact = dact
self.topo = topo
self.num_layers = len(topo)
for i in range(self.num_layers - 1):
self.weight.append(np.random.randn(topo[i + 1], topo[i]))
self.bias.append(np.random.randn(topo[i + 1], 1))
self.value.append(np.zeros((topo[i + 1], 1), dtype = np.float16))
self.zeta.append(np.zeros((topo[i + 1], 1), dtype = np.float16))
def forward(self, input: np.ndarray) -> None:
self.value[0] = input
for i in range(self.num_layers - 1):
self.zeta[i + 1] = np.dot(self.weight[i + 1], self.value[i]) + self.bias[i + 1]
self.value[i + 1] = self.act(self.zeta[i + 1])class NeuralNetwork {
std::vector<Matrix<float>> weight, bias, value, zeta;
std::vector<int> topo;
std::function<float(float)> act_func;
unsigned size;
public:
NeuralNetwork() = delete;
NeuralNetwork(const NeuralNetwork &) = default;
NeuralNetwork(NeuralNetwork &&) = default;
NeuralNetwork(std::vector<int> &&_topo, std::function<float(float)> _act_func)
: topo(std::forward<std::vector<int>>(_topo)), act_func(std::forward<std::function<float(float)>>(_act_func)), size(topo.size()) {
std::default_random_engine random_engine(std::random_device{}());
std::normal_distribution<float> distributor(-1.0, 1.0);
auto random = [&]() -> float { return distributor(random_engine); };
weight.resize(size), bias.resize(size), value.resize(size), zeta.resize(size);
bias[0] = zeta[0] = value[0] = Matrix<float>(topo[0]);
for (int i = 1; i < size; i++) {
weight[i] = Matrix<float>(topo[i], topo[i - 1], random);
zeta[i] = value[i] = bias[i] = Matrix<float>(topo[i], random);
}
}
public:
std::vector<float> forward(std::vector<float> &&input) {
auto activate = [&](int value_index) -> void {
Matrix<float> &x = value[value_index], &z = zeta[value_index];
for (int i = 0; i < topo[value_index]; i++) x(i, 0) = z(i, 0);
};
value[0] = std::forward<std::vector<float>>(input);
for (int i = 1; i < size; i++) {
zeta[i] = weight[i] * value[i - 1] + bias[i];
activate(i);
}
std::vector<float> result(topo[size - 1]);
for (int i = 0; i < topo[size - 1]; i++)
result[i] = value[size - 1](i, 0);
return result;
}
};Calculus
m = 1: 當 x 增加 1 時 y 增加 1
m = 2: 當 x 增加 1 時 y 增加 2
m = 1: 當 x 增加 1 時 y 增加 -1
切線斜率 = -0.23
Partial Derivative
的梯度:
Backward
*在實務上我們通常會在前面乘上 1/2
其中 k 是常數,稱為學習率
上標代表它在第幾層
Python 實作要小心 Vector 和 Matrix 上的差別
import numpy as np
class NeuralNetwork:
def __init__(self, topo: list[int], act, dact):
self.weight = [np.zeros((0, 0), dtype = np.float16)]
self.bias = [np.zeros((topo[0], 1), dtype = np.float16)]
self.value = [np.zeros((topo[0], 1), dtype = np.float16)]
self.zeta = [np.zeros((topo[0], 1), dtype = np.float16)]
self.act = act
self.dact = dact
self.topo = topo
self.num_layers = len(topo)
for i in range(self.num_layers - 1):
self.weight.append(np.random.randn(topo[i + 1], topo[i]))
self.bias.append(np.random.randn(topo[i + 1], 1))
self.value.append(np.zeros((topo[i + 1], 1), dtype = np.float16))
self.zeta.append(np.zeros((topo[i + 1], 1), dtype = np.float16))
def forward(self, input: np.ndarray) -> None:
self.value[0] = input
for i in range(self.num_layers - 1):
self.zeta[i + 1] = np.dot(self.weight[i + 1], self.value[i]) + self.bias[i + 1]
self.value[i + 1] = self.act(self.zeta[i + 1])
def backward(self, label: np.ndarray, learning_rate) -> None:
dx = self.value[-1] - label
for i in range(self.num_layers - 1, 0, -1):
db = dx * self.dact(self.zeta[i])
dW = np.dot(db, self.value[i - 1].T)
dx = np.dot(self.weight[i].T, db)
self.weight[i] -= learning_rate * dW
self.bias[i] -= learning_rate * db
def predict(self, input: np.ndarray) -> np.ndarray:
self.forward(input)
return self.value[-1]
def fit(self, input: np.ndarray, label: np.ndarray, learning_rate) -> None:
self.forward(input)
self.backward(label, learning_rate)C++ 實作一切都自己來,自己肯定比較了解
class NeuralNetwork {
std::vector<Matrix<float>> weight, bias, value, zeta;
std::vector<int> topo;
std::function<float(float)> act_func, dact_func;
unsigned size;
public:
NeuralNetwork() = delete;
NeuralNetwork(const NeuralNetwork &) = default;
NeuralNetwork(NeuralNetwork &&) = default;
NeuralNetwork(std::vector<int> &&_topo, std::function<float(float)> _act_func, std::function<float(float)> _dact_func)
: topo(std::forward<std::vector<int>>(_topo)), act_func(std::forward<std::function<float(float)>>(_act_func)), dact_func(std::forward<std::function<float(float)>>(_dact_func)), size(topo.size()) {
std::default_random_engine random_engine(std::random_device{}());
std::normal_distribution<float> distributor(-1.0, 1.0);
auto random = [&]() -> float { return distributor(random_engine); };
weight.resize(size), bias.resize(size), value.resize(size), zeta.resize(size);
weight[0] = bias[0] = zeta[0] = value[0] = Matrix<float>(topo[0]);
for (int i = 1; i < size; i++) {
weight[i] = Matrix<float>(topo[i], topo[i - 1], random);
zeta[i] = value[i] = bias[i] = Matrix<float>(topo[i], random);
}
}
private:
void forward(const std::vector<float> &input) {
auto activate = [&](int value_index) -> void {
Matrix<float> &x = value[value_index], &z = zeta[value_index];
for (int i = 0; i < topo[value_index]; i++) x(i, 0) = act_func(z(i, 0));
};
value[0] = input;
for (int i = 1; i < size; i++) {
zeta[i] = weight[i] * value[i - 1] + bias[i];
activate(i);
}
}
void backward(const std::vector<float> &output, float learning_rate) {
Matrix<float> label(output);
Matrix<float> dx = value[size - 1] - label;
for (int i = size - 1; i > 0; i--) {
Matrix<float> db(dx);
for (int j = 0; i < topo[j]; j++)
db(j, 0) *= dact_func(zeta[i](j, 0));
Matrix<float> dW(db * value[i - 1].T());
dx = weight[i].T() * db;
weight[i] -= dW * learning_rate;
bias[i] -= db * learning_rate;
}
}
public:
std::vector<float> predict(const std::vector<float> &input) {
forward(input);
std::vector<float> result(topo[size - 1]);
for (int i = 0; i < topo[size - 1]; i++)
result[i] = value[size - 1](i, 0);
return result;
}
void fit(const std::vector<float> &input, const std::vector<float> &output, double learning_rate) {
forward(input);
backward(output, learning_rate);
}
};XOR 是簡單的非線性問題
可以拿來驗證神經網路具有非線性函數的擬合
import numpy as np
class NeuralNetwork:
def __init__(self, topo: list[int], act, dact):
self.weight = [np.zeros((0, 0), dtype = np.float16)]
self.bias = [np.zeros((topo[0], 1), dtype = np.float16)]
self.value = [np.zeros((topo[0], 1), dtype = np.float16)]
self.zeta = [np.zeros((topo[0], 1), dtype = np.float16)]
self.act = act
self.dact = dact
self.topo = topo
self.num_layers = len(topo)
for i in range(self.num_layers - 1):
self.weight.append(np.random.randn(topo[i + 1], topo[i]))
self.bias.append(np.random.randn(topo[i + 1], 1))
self.value.append(np.zeros((topo[i + 1], 1), dtype = np.float16))
self.zeta.append(np.zeros((topo[i + 1], 1), dtype = np.float16))
def forward(self, input: np.ndarray) -> None:
self.value[0] = input
for i in range(self.num_layers - 1):
self.zeta[i + 1] = np.dot(self.weight[i + 1], self.value[i]) + self.bias[i + 1]
self.value[i + 1] = self.act(self.zeta[i + 1])
def backward(self, label: np.ndarray, learning_rate) -> None:
dx = self.value[-1] - label
for i in range(self.num_layers - 1, 0, -1):
db = dx * self.dact(self.zeta[i])
dW = np.dot(db, self.value[i - 1].T)
dx = np.dot(self.weight[i].T, db)
self.weight[i] -= learning_rate * dW
self.bias[i] -= learning_rate * db
def predict(self, input: np.ndarray) -> np.ndarray:
self.forward(input)
return self.value[-1]
def fit(self, input: np.ndarray, label: np.ndarray, learning_rate) -> None:
self.forward(input)
self.backward(label, learning_rate)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def dsigmoid(x):
return sigmoid(x) * (1 - sigmoid(x))
nn = NeuralNetwork([2, 3, 1], sigmoid, dsigmoid)
for i in range(1000):
nn.fit(np.array([[0], [0]]), np.array([[0]]), 2)
nn.fit(np.array([[0], [1]]), np.array([[1]]), 2)
nn.fit(np.array([[1], [0]]), np.array([[1]]), 2)
nn.fit(np.array([[1], [1]]), np.array([[0]]), 2)
print(nn.predict(np.array([[0], [0]])))
print(nn.predict(np.array([[0], [1]])))
print(nn.predict(np.array([[1], [0]])))
print(nn.predict(np.array([[1], [1]])))XOR 是簡單的非線性問題
可以拿來驗證神經網路具有非線性函數的擬合
#include <cassert>
#include <cmath>
#include <concepts>
#include <functional>
#include <iostream>
#include <random>
#include <utility>
#include <vector>
template <typename Tp>
concept addable = requires(Tp a, Tp b) {
a + b;
};
template <typename Tp>
concept minusable = requires(Tp a, Tp b) {
a + b;
};
template <typename Tp>
concept multiplyable = requires(Tp a, Tp b) {
a * b;
};
template <typename Tp>
requires addable<Tp> && minusable<Tp> && multiplyable<Tp>
class Matrix {
std::vector<std::vector<Tp>> data;
int R, C;
public:
Matrix() = default;
Matrix(const Matrix<Tp> &) = default;
Matrix(Matrix<Tp> &&) = default;
Matrix &operator=(const Matrix<Tp> &) = default;
Matrix &operator=(Matrix<Tp> &&) = default;
Matrix(int _R)
: R(_R), C(1), data(_R, std::vector<Tp>(1)) {}
Matrix(int _R, std::function<Tp()> &&generator)
: R(_R), C(1), data(_R, std::vector<Tp>(1)) {
for (int i = 0; i < _R; i++)
data[i][0] = generator();
}
Matrix(int _R, std::function<Tp(int)> &&generator)
: R(_R), C(1), data(_R, std::vector<Tp>(1)) {
for (int i = 0; i < _R; i++)
data[i][0] = generator(i);
}
Matrix(int _R, int _C)
: R(_R), C(_C), data(_R, std::vector<Tp>(_C)) {}
Matrix(int _R, int _C, std::function<Tp()> &&generator)
: R(_R), C(_C), data(_R, std::vector<Tp>(_C)) {
for (int i = 0; i < _R; i++)
for (int j = 0; j < _C; j++)
(*this)(i, j) = generator();
}
Matrix(int _R, int _C, std::function<Tp(int, int)> &&generator)
: R(_R), C(_C), data(_R, std::vector<Tp>(_C)) {
for (int i = 0; i < _R; i++)
for (int j = 0; j < _C; j++)
(*this)(i, j) = generator(i, j);
}
Matrix(std::vector<std::vector<Tp>> &&_data) {
assert(_data.size() > 0);
R = _data.size();
assert(_data[0].size() > 0);
C = _data[0].size();
data = std::forward<std::vector<std::vector<Tp>>>(_data);
}
Matrix(const std::vector<Tp> &_data) {
assert(_data.size() > 0);
R = _data.size(), C = 1;
data.resize(R, std::vector<Tp>(1));
for (int i = 0; i < R; i++)
data[i][0] = _data[i];
}
public:
inline Tp &operator()(int _r, int _c) {
return data[_r][_c];
}
inline const Tp &operator()(int _r, int _c) const {
return data[_r][_c];
}
Matrix operator+(const Matrix &another) const {
assert(R == another.R && C == another.C);
Matrix result(R, C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
result(i, j) = (*this)(i, j) + another(i, j);
return result;
}
Matrix &operator+=(const Matrix &another) {
assert(R == another.R && C == another.C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
(*this)(i, j) += another(i, j);
return (*this);
}
Matrix operator-(const Matrix &another) const {
assert(R == another.R && C == another.C);
Matrix result(R, C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
result(i, j) = (*this)(i, j) - another(i, j);
return result;
}
Matrix &operator-=(const Matrix &another) {
assert(R == another.R && C == another.C);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
(*this)(i, j) -= another(i, j);
return (*this);
}
Matrix operator*(Tp k) const {
Matrix result(*this);
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
result(i, j) *= k;
return result;
}
Matrix &operator*=(Tp k) {
for (int i = 0; i < R; i++)
for (int j = 0; j < C; j++)
(*this)(i, j) *= k;
return (*this);
}
Matrix operator*(const Matrix another) const {
assert(C == another.R);
Matrix result(R, another.C);
for (int r = 0; r < R; r++)
for (int c = 0; c < another.C; c++)
for (int i = 0; i < C; i++)
result(r, c) += (*this)(r, i) * another(i, c);
return result;
}
public:
std::pair<int, int> size() {
return {R, C};
}
friend std::ostream &operator<<(std::ostream &out, const Matrix<Tp> &target) {
out << "[\n";
for (int i = 0; i < target.R; i++) {
out << " [";
for (int j = 0; j < target.C; j++)
out << target.data[i][j] << " ";
out << "\b]\n";
}
out << "]";
return out;
}
Matrix T() {
Matrix<Tp> result(C, R);
for (int i = 0; i < C; i++)
for (int j = 0; j < R; j++)
result(i, j) = (*this)(j, i);
return result;
}
};
class NeuralNetwork {
std::vector<Matrix<float>> weight, bias, value, zeta;
std::vector<int> topo;
std::function<float(float)> act_func, dact_func;
unsigned size;
public:
NeuralNetwork() = delete;
NeuralNetwork(const NeuralNetwork &) = default;
NeuralNetwork(NeuralNetwork &&) = default;
NeuralNetwork(std::vector<int> &&_topo, std::function<float(float)> _act_func, std::function<float(float)> _dact_func)
: topo(std::forward<std::vector<int>>(_topo)), act_func(std::forward<std::function<float(float)>>(_act_func)), dact_func(std::forward<std::function<float(float)>>(_dact_func)), size(topo.size()) {
std::default_random_engine random_engine(std::random_device{}());
std::normal_distribution<float> distributor(-1.0, 1.0);
auto random = [&]() -> float { return distributor(random_engine); };
weight.resize(size), bias.resize(size), value.resize(size), zeta.resize(size);
weight[0] = bias[0] = zeta[0] = value[0] = Matrix<float>(topo[0]);
for (int i = 1; i < size; i++) {
weight[i] = Matrix<float>(topo[i], topo[i - 1], random);
zeta[i] = value[i] = bias[i] = Matrix<float>(topo[i], random);
}
}
private:
void forward(const std::vector<float> &input) {
auto activate = [&](int value_index) -> void {
Matrix<float> &x = value[value_index], &z = zeta[value_index];
for (int i = 0; i < topo[value_index]; i++) x(i, 0) = act_func(z(i, 0));
};
value[0] = input;
for (int i = 1; i < size; i++) {
zeta[i] = weight[i] * value[i - 1] + bias[i];
activate(i);
}
}
void backward(const std::vector<float> &output, float learning_rate) {
Matrix<float> label(output);
Matrix<float> dx = value[size - 1] - label;
for (int i = size - 1; i > 0; i--) {
Matrix<float> db(dx);
for (int j = 0; i < topo[j]; j++)
db(j, 0) *= dact_func(zeta[i](j, 0));
Matrix<float> dW(db * value[i - 1].T());
dx = weight[i].T() * db;
weight[i] -= dW * learning_rate;
bias[i] -= db * learning_rate;
}
}
public:
std::vector<float> predict(const std::vector<float> &input) {
forward(input);
std::vector<float> result(topo[size - 1]);
for (int i = 0; i < topo[size - 1]; i++)
result[i] = value[size - 1](i, 0);
return result;
}
void fit(const std::vector<float> &input, const std::vector<float> &output, double learning_rate) {
forward(input);
backward(output, learning_rate);
}
};
int main() {
auto sigmoid = [](float x) -> float { return 1.0 / (1 + exp(-x)); };
auto dsigmoid = [sigmoid](float x) -> float { return sigmoid(x) * (1 - sigmoid(x)); };
NeuralNetwork nn({2, 3, 1}, sigmoid, dsigmoid);
for (int i = 0; i < 1000; i++) {
nn.fit({0, 0}, {0}, 0.5);
nn.fit({0, 1}, {1}, 0.5);
nn.fit({1, 0}, {1}, 0.5);
nn.fit({1, 1}, {0}, 0.5);
}
std::cout << nn.predict({0, 0})[0] << "\n";
std::cout << nn.predict({0, 1})[0] << "\n";
std::cout << nn.predict({1, 0})[0] << "\n";
std::cout << nn.predict({1, 1})[0] << "\n";
}By 海之音
四校聯合放課 - 彈性時間,手刻神經網路




