





海之音
INFOR 36th 學術長 @小海_夢想特急_夢城前
Data Structure
# 前言
如果你對我之前發的資料結構簡報有印象那很正常,因為我之前在建中校內資讀有講這門課
為什麼要重做?很簡單,因為那不適合放課,講的東西太深,而且我覺得我那份簡報有點爛
當然,你可以將舊簡報當做一份資源使用,裡面有很多沒講的東西
還有一點是以前的簡報很醜,傷眼
講師表達能力不是很好,不懂要問
今天會大量用到遞迴、分治等等觀念
在我做這份簡報時另一位講師還沒做分治簡報,所以我就不丟連結了
"Data structures, not algorithms, are central to programming."
- Pike:Notes on Programming in C
原陣列
前綴和
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
| 1 | 3 | 6 | 10 | 15 | 21 | 28 |
|---|
品項
單價
蘋果
10
香蕉
13
芭樂
11
橘子
15
原陣列
前綴和
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
| 1 | 3 | 6 | 10 | 15 | 21 | 28 |
|---|
原陣列
差分陣列
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|
現在在哪不重要
重要的是前面 / 下一個是誰
struct Node {
int data;
Node *next;
};struct Node {
int data;
int next;
};
Node linked_list[n];next
索引
0
290
data
1
1
2
3
2
89
3
314
2
21
-1
next
索引
0
290
data
1
1
2
3
2
89
3
314
2
21
-1
next
索引
0
290
data
2
1
2
3
2
89
3
21
-1
314
2
next
索引
0
290
data
2
1
2
3
2
89
3
21
-1
314
2
next
索引
0
290
data
2
1
2
3
2
89
3
21
-1
314
2
next
索引
0
290
data
2
1
2
3
2
89
3
21
-1
314
2
next
索引
0
290
data
2
1
2
3
2
89
3
21
-1
314
2
next
索引
0
290
data
1
1
2
3
2
89
3
314
2
21
-1
struct Linked_list {
struct Node {
int data = 0;
int next = -1;
};
Node list[n];
int front = 0;
int back = 0;
// 範例:從後面插入
void push_back(int new_data) {
List[back].next = back++;
List[back].data = new_data;
}
};# EXAMPLE
缺點
O(n) 搜尋
競程幾乎用不到
優點
如果真的使用指標,大小是可變的
如果有前後的 index 可以 O(1) 插入 / 刪除
O(1) 刪除頭 / 尾
對於相鄰節點處理方便
其實 Linked List 沒有很重要
重要的只有雙指針和偽指標的觀念
題目看過去確定會解法就好了
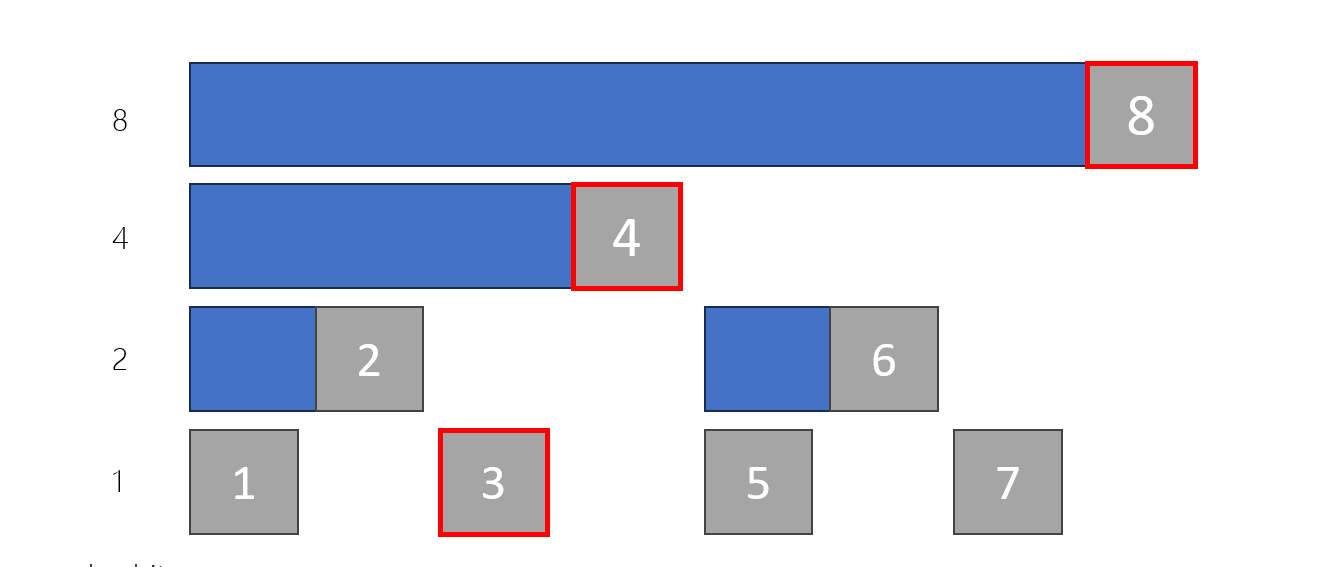
前綴和
單一個數重疊的範圍太多
每疊到一條藍線就要修改一個值
線段樹?
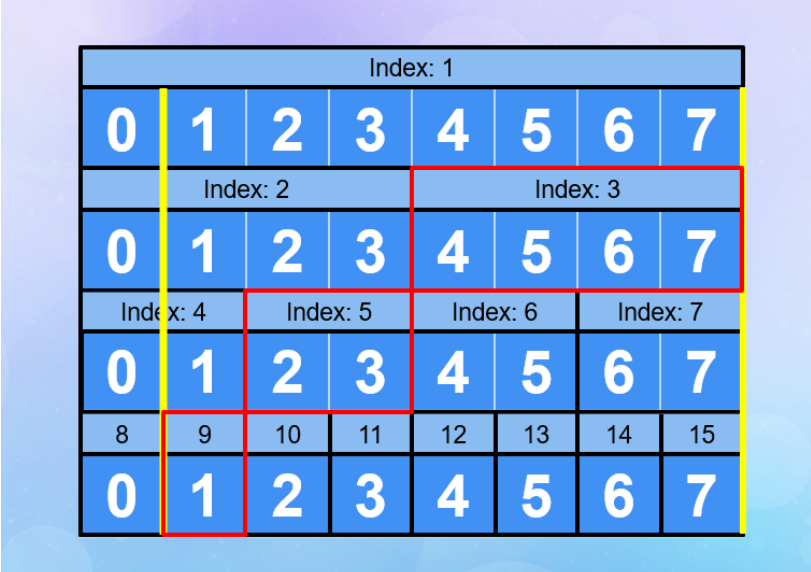
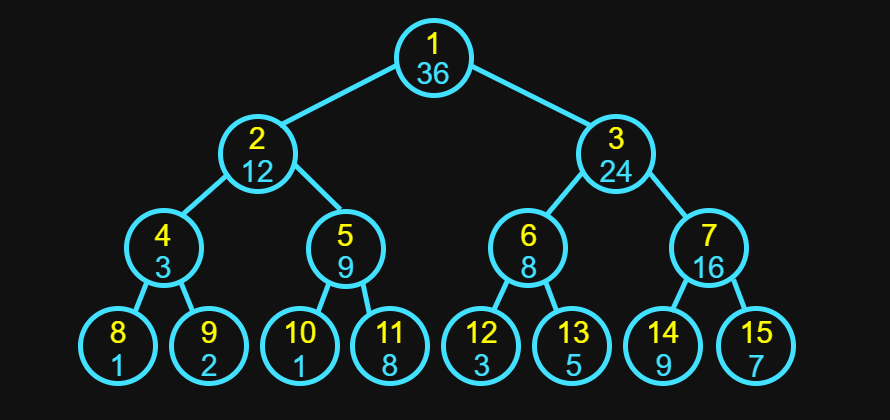
# 線段樹示意圖
線段樹?
以藍線代表涵蓋範圍
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
# 線段樹示意圖
線段樹?
以藍線代表涵蓋範圍
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
# 線段樹示意圖
線段樹?
以藍線代表涵蓋範圍
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
# 線段樹示意圖
線段樹?
以藍線代表涵蓋範圍
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
# 線段樹示意圖
線段樹?
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
原陣列 data
# 線段樹示意圖
線段樹?
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
6
7
# 線段樹示意圖
線段樹?
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
6
7
11
9
8
13
# 線段樹示意圖
線段樹?
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
6
7
11
9
8
13
20
21
# 線段樹示意圖
線段樹?
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
6
7
11
9
8
13
20
21
41
# 線段樹示意圖
修改位置 6 為 9
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
6
7
11
9
8
13
20
21
41
# 線段樹示意圖
修改位置 6 為 9
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
6
7
11
9
8
13
20
21
41
# 線段樹示意圖
修改位置 6 為 9
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
9
7
11
9
8
13
20
21
41
# 線段樹示意圖
修改位置 6 為 9
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
9
7
11
9
8
16
20
21
41
# 線段樹示意圖
修改位置 6 為 9
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
9
7
11
9
8
16
20
24
41
# 線段樹示意圖
修改位置 6 為 9
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
# 線段樹示意圖
修改位置 0 為 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 9 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
# 線段樹示意圖
修改位置 0 為 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 1 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
# 線段樹示意圖
修改位置 0 為 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 1 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
1
2
1
8
3
5
9
7
11
9
8
16
20
24
44
# 線段樹示意圖
修改位置 0 為 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 1 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
1
2
1
8
3
5
9
7
3
9
8
16
20
24
44
# 線段樹示意圖
修改位置 0 為 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 1 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
1
2
1
8
3
5
9
7
3
9
8
16
12
24
44
# 線段樹示意圖
修改位置 0 為 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 1 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
# 線段樹示意圖
查詢位置 [0, 6] 的和
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
| 1 | 2 | 1 | 8 | 3 | 5 | 9 | 7 |
|---|
原陣列 data
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
前綴和
單一個數重疊的範圍太多
每疊到一條藍線就要修改一個值
線段樹
前綴和
單一個數重疊的範圍太多
每疊到一條藍線就要修改一個值
線段樹
# 線段樹示意
幫它的圖瘦身下
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
# 線段樹示意
幫它的圖瘦身下
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
# 線段樹示意
給每個點編號
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 線段樹示意
左節點編號 = 當前節點 * 2
右節點編號 = 當前節點 * 2 + 1
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1
2
3
1
2
3
3
6
21
4
5
9
6
15
| 1 | 2 | 3 | 4 | 5 | 6 |
|---|
1
2
3
3
6
21
4
5
9
6
15
1
| 1 | 2 | 3 | 4 | 5 | 6 |
|---|
2
3
4
5
6
7
8
9
10
11
12
13
struct Box {
int length, width, height;
Box(int l, int w, int h) {
length = l, width = w, height = h;
}
};# Constructor
建構式會在宣告 Struct / Class 變數時觸發
可以當成一種特殊的函數來用
struct Box {
int length, width, height;
Box(int l, int w, int h) {
length = l, width = w, height = h;
cout << "Box generated: length(" << length << "), width(" << width << "), height(" << height << ")\n";
}
};
int main() {
Box box_a(1, 2, 3), box_b(4, 5, 6);
}# Constructor
Output:
Box generated: length(1), width(2), height(3) Box generated: length(4), width(5), height(6)
struct Stree {
vector<int> tree;
void build(int l, int r, int v, vector<int> &data) {
if (r == l + 1) {
tree[v] = data[l];
return;
}
int m = (l + r + 1) / 2;
build(l, m, v * 2, data);
build(m, r, v * 2 + 1, data);
tree[v] = tree[v * 2] + tree[v * 2 + 1];
}
Stree(vector<int> &data) {
tree.resize(data.size() * 4);
build(0, data.size(), 1, data);
}
};# Build Tree
一般來說,我習慣用左閉右開表示區間
並且在取中間線時會把卡在正中間的數丟到左邊
# 建樹
l = 0
r = 8
v = 1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
l = 0
r = 2
v = 4
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
l = 0
r = 2
v = 4
l = 0
r = 1
v = 8
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
l = 0
r = 2
v = 4
l = 0
r = 1
v = 8
9
8
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
l = 0
r = 2
v = 4
9
8
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
l = 0
r = 2
v = 4
l = 1
r = 2
v = 9
9
8
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
l = 0
r = 2
v = 4
l = 1
r = 2
v = 9
9
8
2
9
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
l = 0
r = 2
v = 4
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
l = 2
r = 4
v = 5
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
l = 2
r = 4
v = 5
l = 2
r = 3
v = 10
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
l = 2
r = 4
v = 5
l = 2
r = 3
v = 10
1
10
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
l = 2
r = 4
v = 5
1
10
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
l = 2
r = 4
v = 5
1
10
l = 3
r = 4
v = 11
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
l = 2
r = 4
v = 5
1
10
l = 3
r = 4
v = 11
8
11
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
l = 2
r = 4
v = 5
1
10
8
11
9
5
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
l = 0
r = 4
v = 2
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
l = 4
r = 6
v = 6
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
l = 4
r = 6
v = 6
l = 4
r = 5
v = 12
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
l = 4
r = 6
v = 6
l = 4
r = 5
v = 12
3
12
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
l = 4
r = 6
v = 6
3
12
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
l = 4
r = 6
v = 6
3
12
l = 5
r = 6
v = 13
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
l = 4
r = 6
v = 6
3
12
l = 5
r = 6
v = 13
5
13
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
l = 4
r = 6
v = 6
3
12
5
13
8
6
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
l = 6
r = 8
v = 7
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
l = 6
r = 8
v = 7
l = 6
r = 7
v = 14
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
l = 6
r = 8
v = 7
l = 6
r = 7
v = 14
6
14
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
l = 6
r = 8
v = 7
6
14
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
l = 6
r = 8
v = 7
6
14
l = 7
r = 8
v = 15
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
l = 6
r = 8
v = 7
6
14
l = 7
r = 8
v = 15
7
15
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
6
14
7
15
13
7
l = 6
r = 8
v = 7
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
l = 4
r = 8
v = 3
3
12
5
13
8
6
6
14
7
15
13
7
21
3
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
l = 0
r = 8
v = 1
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
3
12
5
13
8
6
6
14
7
15
13
7
21
3
41
1
# 建樹
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
原陣列 Index
遞迴參數
| 9 | 2 | 1 | 8 | 3 | 5 | 6 | 7 |
|---|
9
8
2
9
11
4
1
10
8
11
9
5
20
2
3
12
5
13
8
6
6
14
7
15
13
7
21
3
41
1
struct Stree {
vector<int> tree;
void build(int l, int r, int v, vector<int> &data) {
cout << "Building: (" << l << ", " << r << ", " << v << ")\n";
if (r == l + 1) {
cout << "Leaf: (" << l << ", " << r << ", " << v << ")\n";
tree[v] = data[l];
return;
}
int m = (l + r + 1) / 2;
build(l, m, v * 2, data);
build(m, r, v * 2 + 1, data);
tree[v] = tree[v * 2] + tree[v * 2 + 1];
cout << "Finish: (" << l << ", " << r << ", " << v << ")\n";
}
void print() {
for (int i = 0; i < tree.size(); i++) cout << tree[i] << ' ';
cout << '\n';
}
Stree(vector<int> &data) {
tree.resize(data.size() * 4);
build(0, data.size(), 1, data);
print();
}
};
int main () {
vector<int> data = {9, 2, 1, 8};
Stree sum(data);
}# 實際輸出
Building: (0, 4, 1)
Building: (0, 2, 2)
Building: (0, 1, 4)
Leaf: (0, 1, 4)
Building: (1, 2, 5)
Leaf: (1, 2, 5)
Finish: (0, 2, 2)
Building: (2, 4, 3)
Building: (2, 3, 6)
Leaf: (2, 3, 6)
Building: (3, 4, 7)
Leaf: (3, 4, 7)
Finish: (2, 4, 3)
Finish: (0, 4, 1)
0 20 11 9 9 2 1 8 0 0 0 0 0 0 0 09
2
1
8
3
5
9
7
11
9
8
16
20
24
44
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
9
2
1
8
3
5
9
7
11
9
8
16
20
24
44
struct Stree {
void modify(int l, int r, int v, int pos, int new_val) {
if (r == l + 1) {
tree[v] = new_val;
return;
}
int m = (l + r + 1) / 2;
if (pos < m) modify(l, m, v * 2, pos, new_val);
else modify(m, r, v * 2 + 1, pos, new_val);
tree[v] = tree[v * 2] + tree[v * 2 + 1];
return;
}
};# Modify
修改葉節點後,要更新當前節點的值
struct Stree {
vector<int> tree;
void build(int l, int r, int v, vector<int> &data) {
if (r == l + 1) {
tree[v] = data[l];
return;
}
int m = (l + r + 1) / 2;
build(l, m, v * 2, data);
build(m, r, v * 2 + 1, data);
tree[v] = tree[v * 2] + tree[v * 2 + 1];
}
void print() {
for (int i = 0; i < tree.size(); i++) cout << tree[i] << ' ';
cout << '\n';
}
Stree(vector<int> &data) {
tree.resize(data.size() * 4);
build(0, data.size(), 1, data);
print();
}
void modify(int l, int r, int v, int pos, int new_val) {
cout << "modify: " << l << ' ' << r << ' ' << v << '\n';
if (r == l + 1) {
tree[v] = new_val;
return;
}
int m = (l + r + 1) / 2;
if (pos < m) modify(l, m, v * 2, pos, new_val);
else modify(m, r, v * 2 + 1, pos, new_val);
tree[v] = tree[v * 2] + tree[v * 2 + 1];
return;
}
};
int main () {
vector<int> data = {9, 2, 1, 8, 3, 5, 6, 7};
Stree sum(data);
sum.modify(0, data.size(), 1, 6, 106);
sum.print();
}# 實際輸出
0 41 20 21 11 9 8 13 9 2 1 8 3 5 6 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
modify: 0 8 1
modify: 4 8 3
modify: 6 8 7
modify: 6 7 14
0 141 20 121 11 9 8 113 9 2 1 8 3 5 106 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 01
2
1
8
3
5
9
7
3
9
8
16
12
24
36
Case 1: 剛好覆蓋
節點區間
目標區間
Case 2: 左半邊
Case 3: 右半邊
Case 4: 中間
Case 1: 剛好覆蓋
節點區間
目標區間
Case 2: 左半邊
Case 3: 右半邊
Case 4: 中間
Case 1: 剛好覆蓋
節點區間
目標區間
Case 2: 左半邊
Case 3: 右半邊
Case 4: 中間
Case 1: 剛好覆蓋
節點區間
目標區間
Case 2: 左半邊
Case 3: 右半邊
Case 4: 中間
Case 1: 剛好覆蓋
節點區間
目標區間
Case 2: 左半邊
Case 3: 右半邊
Case 4: 中間
struct Stree {
int query(int vl, int vr, int v, int tl, int tr) {
if (vl == tl && vr == tr) return tree[v];
int vm = (vl + vr + 1) / 2;
if (tr <= vm) return query(vl, vm, v * 2, tl, tr);
if (tl >= vm) return query(vm, vr, v * 2 + 1, tl, tr);
return query(vl, vm, v * 2, tl, vm) + query(vm, vr, v * 2 + 1, vm, tr);
}
};# Query
要特別注意特判時因為寫左閉右開所以都要加等於
以及特判的順序要對
# 實際輸出
node: [0, 8), target: [0, 7)
node: [0, 4), target: [0, 4)
use node: (0, 4)
node: [4, 8), target: [4, 7)
node: [4, 6), target: [4, 6)
use node: (4, 6)
node: [6, 8), target: [6, 7)
node: [6, 7), target: [6, 7)
use node: (6, 7)
34struct Stree {
vector<int> tree;
void build(int l, int r, int v, vector<int> &data) {
if (r == l + 1) {
tree[v] = data[l];
return;
}
int m = (l + r + 1) / 2;
build(l, m, v * 2, data);
build(m, r, v * 2 + 1, data);
tree[v] = tree[v * 2] + tree[v * 2 + 1];
}
Stree(vector<int> &data) {
tree.resize(data.size() * 4);
build(0, data.size(), 1, data);
}
int query(int vl, int vr, int v, int tl, int tr) {
cout << "node: [" << vl << ", " << vr << "), "
<< "target: [" << tl << ", " << tr << ")\n";
if (vl == tl && vr == tr) {
cout << "use node: (" << vl << ", " << vr << ")\n";
return tree[v];
}
int vm = (vl + vr + 1) / 2;
if (tr <= vm) return query(vl, vm, v * 2, tl, tr);
if (tl >= vm) return query(vm, vr, v * 2 + 1, tl, tr);
return query(vl, vm, v * 2, tl, vm) + query(vm, vr, v * 2 + 1, vm, tr);
}
};
int main() {
vector<int> data = {9, 2, 1, 8, 3, 5, 6, 7};
Stree sum(data);
cout << sum.query(0, data.size(), 1, 0, 7);
}因為還沒講到線段樹最重要的功能
所以題單就先這樣
然後只要符合結合律的運算都可以用線段樹維護
# 線段樹示意
原線段樹
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
val
tag
# 線段樹示意
[1, 5) 加上 3
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
val
tag
# 線段樹示意
[1, 5) 加上 3
1
2
1
8
3
5
9
7
3
9
8
16
12
24
36
0
0
0
0
3
0
0
0
3
0
0
3
0
0
0
val
tag
# 線段樹示意
[1, 5) 加上 3
1
2
1
8
3
5
9
7
6
9
11
16
21
27
48
0
0
0
0
3
0
0
0
3
0
0
3
0
0
0
val
tag
# 線段樹示意
查詢 [4, 6)
1
2
1
8
3
5
9
7
6
9
11
16
21
27
48
0
0
0
0
3
0
0
0
3
0
0
3
0
0
0
val
tag
# 線段樹示意
查詢 [4, 6)
1
2
1
8
3
5
9
7
6
15
11
16
21
27
48
0
0
0
0
0
0
0
0
3
3
3
3
0
0
0
val
tag
# 線段樹示意
查詢 [4, 6)
1
2
1
11
3
5
9
7
6
15
11
16
21
27
48
0
0
0
0
0
0
0
0
3
3
0
3
0
0
0
val
tag
# 線段樹示意
查詢 [4, 6)
1
2
1
11
3
5
9
7
6
15
11
16
21
27
48
0
0
0
0
0
0
0
0
3
3
0
3
0
0
0
val
tag
# 線段樹示意
查詢 [4, 6)
1
2
1
11
6
5
9
7
6
15
11
16
21
27
48
0
0
0
0
0
0
0
0
3
3
0
0
0
0
0
val
tag
# Modify
非常類似於 query
多記錄 tag
struct Stree {
vector<int> tree, tag;
void push(int target, int l, int r) {
int lchild = target << 1, rchild = target << 1 | 1;
tree[target] += tag[target] * (r - l);
tag[lchild] += tag[target];
tag[rchild] += tag[target];
tag[target] = 0;
}
void pull(int target, int l, int r) {
int m = l + r + 1 >> 1;
int lchild = target << 1, rchild = target << 1 | 1;
int lchild_val = tree[lchild] + tag[lchild] * (m - l);
int rchild_val = tree[rchild] + tag[rchild] * (r - m);
tree[target] = lchild_val + rchild_val;
}
void modify(int vl, int vr, int v, int tl, int tr, int d) {
if (vl == tl && vr == tr) {
tag[v] += d;
return;
}
int vm = vl + vr + 1 >> 1;
if (tr <= vm) modify(vl, vm, v << 1, tl, tr, d);
else if (tl >= vm) modify(vm, vr, v << 1 | 1, tl, tr, d);
else modify(vl, vm, v << 1, tl, vm, d), modify(vm, vr, v << 1 | 1, vm, tr, d);
pull(v, vl, vr);
}
int query(int vl, int vr, int v, int tl, int tr, int d) {
push(v, vl, vr);
if (vl == tl && vr == tr) return tree[v] + tag[v] * (vr - vl);
int vm = vl + vr + 1 >> 1;
if (tr <= vm) return query(vl, vm, v << 1, tl, tr, d);
if (tl >= vm) return query(vm, vr, v << 1 | 1, tl, tr, d);
return query(vl, vm, v << 1, tl, vm, d) + query(vm, vr, v << 1 | 1, vm, tr, d);
}
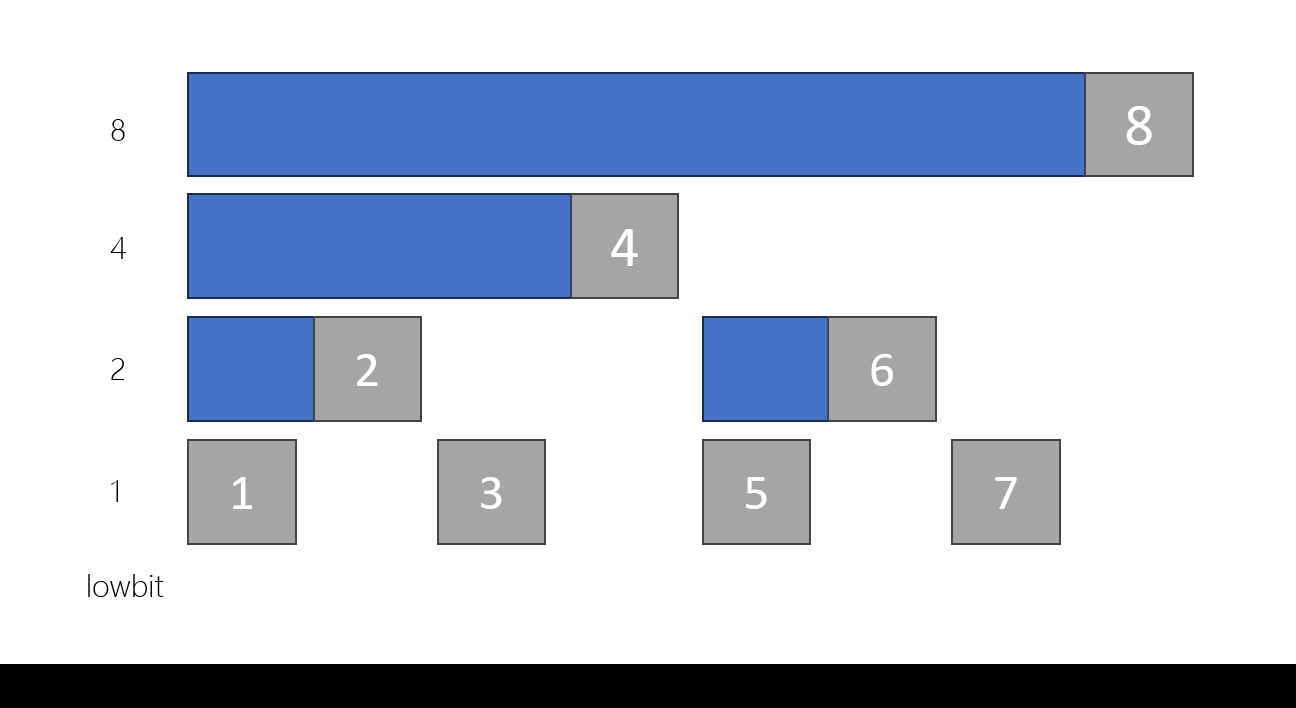
};14 = 1110(2)
lowbit(6) = 10(2) = 2
11 = 1011(2)
lowbit(11) = 1(2) = 1
8 = 1000(2)
lowbit(8) = 1000(2) = 8
12 = 1100(2)
lowbit(12) = 100(2) = 4
x = oooo10000 ~x = xxxx01111 ~x + 1 = xxxx10000
其中 o, x 表示相反的位元
利用 & 運算可以確保前面都是 0
並且後面保持不變
1
2
3
4
5
6
7
1
2
3
4
5
6
7
1
2
3
4
5
6
7
8
1 2 3 4 5 6 7 8
1 2 3 4
1 2 3 4 5 6 7 8
1 2 3 4
#include <time.h>
#include <iostream>
#define iofast ios_base::sync_with_stdio(0), cin.tie(0)
using namespace std;
int main() {
clock_t time1, time2, time3;
time1 = clock();
for (int i = 0; i < 10000; i++)
cout << "Hello\n";
time2 = clock();
iofast;
for (int i = 0; i < 10000; i++)
cout << "Hello\n";
time3 = clock();
cout << time2 - time1 << ' ' << time3 - time2;
}# Define
將空格前面的東西替換成後面的東西
#define lowbit(x) (x & -x)
struct BIT {
vector<int> tree;
int size;
BIT(const vector<int> &data) {
size = data.size() - 1;
tree.resize(size + 1, 0);
for (int i = 1; i <= size; i++) {
tree[i] += data[i];
if (i + lowbit(i) <= size)
tree[i + lowbit(i)] += tree[i];
}
}
};# Build
你會發現,實際上有用的只有三行,超級短
#include <iostream>
#include <vector>
#define lowbit(x) (x & -x)
using std::cout;
using std::vector;
struct BIT {
vector<int> tree;
int size;
// 資料預設 1 - base
BIT(const vector<int> &data) {
size = data.size() - 1;
tree.resize(size + 1, 0);
for (int i = 1; i <= size; i++) {
tree[i] += data[i];
if (i + lowbit(i) <= size)
tree[i + lowbit(i)] += tree[i];
}
}
void print() {
for (int i = 1; i <= size; i++)
cout << tree[i] << " ";
}
};
int main() {
BIT sum(vector<int>{0, 1, 2, 3, 4, 5, 6, 7, 8});
sum.print();
}
# 實際輸出
1 3 3 10 5 11 7 36#define lowbit(x) (x & -x)
struct BIT {
void modify(int pos, int d) {
for (; pos <= size; pos += lowbit(pos))
tree[pos] += d;
}
};# Modify
又是兩行解決
#include <iostream>
#include <vector>
#define lowbit(x) (x & -x)
using std::cout;
using std::vector;
struct BIT {
vector<int> tree;
int size;
// 資料預設 1 - base
BIT(const vector<int> &data) {
size = data.size() - 1;
tree.resize(size + 1, 0);
for (int i = 1; i <= size; i++) {
tree[i] += data[i];
if (i + lowbit(i) <= size)
tree[i + lowbit(i)] += tree[i];
}
}
void print() {
for (int i = 1; i <= size; i++)
cout << tree[i] << " ";
}
void modify(int pos, int d) {
for (; pos <= size; pos += lowbit(pos))
tree[pos] += d;
}
};
int main() {
BIT sum(vector<int>{0, 1, 2, 3, 4, 5, 6, 7, 8});
sum.modify(1, 100);
sum.print();
}
# 實際輸出
1
2
4
8
101 103 3 110 5 11 7 136#define lowbit(x) (x & -x)
struct BIT {
int query(int pos) {
int ans = 0;
for (; pos > 0; pos -= lowbit(pos))
ans += tree[pos];
return ans;
}
};# Query
又是兩行解決
#include <iostream>
#include <vector>
#define lowbit(x) (x & -x)
using std::cout;
using std::vector;
struct BIT {
vector<int> tree;
int size;
// 資料預設 1 - base
BIT(const vector<int> &data) {
size = data.size() - 1;
tree.resize(size + 1, 0);
for (int i = 1; i <= size; i++) {
tree[i] += data[i];
if (i + lowbit(i) <= size)
tree[i + lowbit(i)] += tree[i];
}
}
int query(int pos) {
int ans = 0;
for (; pos > 0; pos -= lowbit(pos)) {
ans += tree[pos];
cout << pos << "\n";
}
return ans;
}
};
int main() {
BIT sum(vector<int>{0, 1, 2, 3, 4, 5, 6, 7, 8});
cout << sum.query(7);
}
# 實際輸出
7
6
4
28# Example
#include <stdio.h>
#include <algorithm>
#include <functional>
const int max_n = 2e5 + 1;
struct BIT {
int data[max_n];
int size;
inline int query(int pos) {
int ans = 0;
for (; pos > 0; pos -= pos & -pos) ans = std::max(ans, data[pos]);
return ans;
}
inline void modify(int pos, int alt) {
for (; pos <= size; pos += pos & -pos) data[pos] = std::max(alt, data[pos]);
}
} LIS;
int num[max_n], map[max_n];
int main() {
int n;
scanf("%d", &n);
for (int i = 0; i < n; i++) scanf("%d", num + i), map[i] = num[i];
std::sort(map, map + n);
LIS.size = std::unique(map, map + n) - map;
for (int i = 0; i < n; i++) {
int mapped = std::lower_bound(map, map + LIS.size, num[i]) - map + 1;
LIS.modify(mapped, LIS.query(mapped - 1) + 1);
}
printf("%d", LIS.query(LIS.size));
return 0;
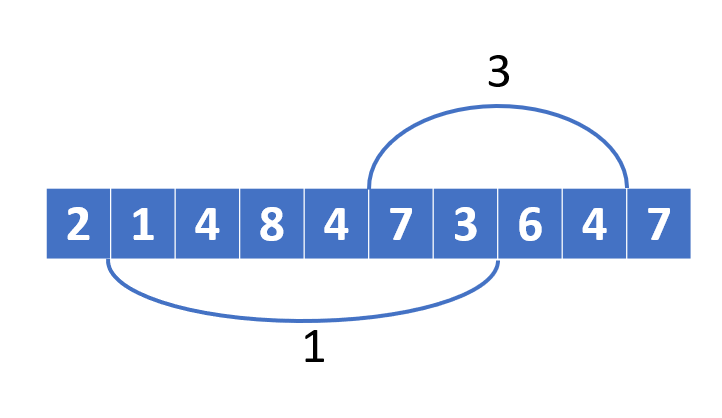
}| 3 | 2 | 4 | 1 | 6 | 5 |
i = 0
| 2 | |||||
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 1
| 2 | 2 | ||||
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 1
| 2 | 2 | 1 | |||
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 1
| 2 | 2 | 1 | 1 | ||
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 1
| 2 | 2 | 1 | 1 | 5 | |
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 1
| 1 | |||||
| 2 | 2 | 1 | 1 | 5 | |
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 2
| 1 | 1 | ||||
| 2 | 2 | 1 | 1 | 5 | |
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 2
| 1 | 1 | 1 | |||
| 2 | 2 | 1 | 1 | 5 | |
| 3 | 2 | 4 | 1 | 6 | 5 |
i = 2
# Build
struct SparseTable {
vector<vector<int>> sp;
int size, lg_size;
SparseTable(const vector<int> &data, int _size)
: size(_size), lg_size(std::__lg(_size)), sp(lg_size + 1, vector<int>(_size, 0)) {
sp[0] = data;
for (int i = 1; i <= lg_size; i++)
for (int l = 0; l + (1 << i - 1) < size; l++)
sp[i][l] = min(sp[i - 1][l], sp[i - 1][l + (1 << i - 1)]);
}
};使用 std::__lg O(1) 取得以 2 為底的 log 值
1 << i 就是 2 的 i 次方
struct SparseTable {
vector<vector<int>> sp;
int size, lg_size;
SparseTable(const vector<int> &data, int _size)
: size(_size), lg_size(std::__lg(_size)), sp(lg_size + 1, vector<int>(_size, 0)) {
sp[0] = data;
for (int i = 1; i <= lg_size; i++)
for (int l = 0; l + (1 << i - 1) < size; l++)
sp[i][l] = min(sp[i - 1][l], sp[i - 1][l + (1 << i - 1)]);
}
void print() {
for (int i = 0; i <= lg_size; i++) {
for (int l = 0; l < size; l++) {
cout << sp[i][l] << " ";
}
cout << "\n";
}
}
};
int main() {
SparseTable min_val({3, 2, 1, 4, 5, 6}, 6);
min_val.print();
}
# 實際輸出
3 2 1 4 5 6
2 1 1 4 5 0
1 1 1 0 0 0| 1 | 1 | 1 | |||
| 2 | 2 | 1 | 1 | 5 | |
| 3 | 2 | 4 | 1 | 6 | 5 |
查詢 [1, 6) 需要兩個大小為 4 的區間
| 1 | 1 | 1 | |||
| 2 | 2 | 1 | 1 | 5 | |
| 3 | 2 | 4 | 1 | 6 | 5 |
查詢 [2, 5) 需要兩個大小為 2 的區間
# Query
struct SparseTable {
int query(int l, int r) {
int i = std::__lg(r - l);
return min(sp[i][l], sp[i][r - (1 << i)]);
}
// 或
int operator()(int l, int r) {
int i = std::__lg(r - l);
return min(sp[i][l], sp[i][r - (1 << i)]);
}
};如果有聽課可以重載 () 運算子
31
17
23
53
67
47
73
59
53
67
73
31
5
7
73
13
16
19
79
59
37
61
73
3
21
43
63
12
47
36
2
10
7
74
91
24
49
29
69
88
key
pri
37
3
21
43
12
47
36
2
10
7
74
91
24
29
49
61
73
63
69
88
37
3
21
43
12
47
36
2
10
7
74
91
24
29
49
61
73
63
69
88
樹堆 A
樹堆 B
37
61
73
3
21
43
63
12
47
36
2
10
7
74
91
24
49
29
69
88
k = 62
key <= 62 ,此節點歸給 A,向右遞迴
37
61
73
3
21
43
63
12
47
36
2
10
7
74
91
24
49
29
69
88
k = 62
key <= 62 ,此節點歸給 A,向右遞迴
37
61
73
3
21
43
63
12
47
36
2
10
7
74
91
24
49
29
69
88
k = 62
key > 62 ,此節點歸給 B,向左遞迴
37
61
73
3
21
43
63
12
47
36
2
10
7
74
91
24
49
29
69
88
k = 62
key <= 62 ,此節點歸給 A,向右遞迴
37
61
73
3
21
43
63
12
47
36
2
10
7
74
91
24
49
29
69
88
k = 62
當前節點為空,終止遞迴並將 A, B 連接處設為空
# Build
const int max_size = 1e6;
struct Treap {
struct Node {
int key, pri;
int lchild = -1, rchild = -1;
int val;
Node(int _key, int _val)
: key(_key), val(_val) {}
};
Node tree[max_size];
int root_pt = -1;
void split(int v, int k, int &A, int &B) {
if (v == -1) {
A = B = -1;
return;
}
if (tree[v].key <= k) {
A = v;
split(tree[v].rchild, k, tree[v].rchild, B);
}
else {
B = v;
split(tree[v].lchild, k, A, tree[v].lchild);
}
}
};注意節點為空時的做法
37
43
47
7
9
29
保證 B Treap 的 大於 A
B 的節點一定接在 A 的右側
只需要關心 A 右側的節點,反之亦然
A
B
53
44
49
61
73
63
69
88
5
10
8
91
3
74
10
2
14
17
25
27
90
29
37
43
47
7
9
29
保證 B Treap 的 大於 A
B 的節點一定接在 A 的右側
只需要關心 A 右側的節點,反之亦然
A
B
53
44
49
61
73
63
69
88
5
10
8
91
3
74
10
2
14
17
25
27
90
29
37
43
47
7
9
29
保證 B Treap 的 大於 A
B 的節點一定接在 A 的右側
只需要關心 A 右側的節點,反之亦然
A
B
10
2
17
25
90
29
10
2
47
7
37
29
9
43
90
29
17
25
依照 的大小將節點排序
37
29
90
29
17
25
9
43
47
7
10
2
37
29
90
29
17
25
9
43
47
7
10
2
37
29
90
29
10
2
47
7
9
43
17
25
10
2
5
10
8
91
3
74
37
29
90
29
47
7
9
43
17
25
49
61
73
63
69
88
53
44
14
27
# Query
struct Treap {
int merge(int A, int B) {
if (A == -1 || B == -1) return A == -1 ? B : A;
if (tree[A].pri < tree[B].pri) {
tree[A].rchild = merge(tree[A].rchild, B);
return A;
}
else {
tree[B].lchild = merge(A, tree[B].lchild);
return B;
}
}
};# Query
struct Treap {
int back = 0; // 能用的空間的最後
int new_node(int key, int val) {
tree[back].val = val;
tree[back].key = key;
tree[back].pri = rand();
return back++;
}
void insert(int key, int val) {
if (root_pt = -1) {
root_pt = new_node(key, val);
return;
}
int insert_node_pt = new_node(key, val);
int A, B;
split(root_pt, key, A, B);
root_pt = merge(merge(A, insert_node_pt), B);
}
};By 海之音
四校聯合放課 - 資料結構




