Stop vibe-testing:
run real agent evals
2026-05-04 AgentCon Silicon Valley
What are we talking about?
- What an eval is, and why you need them
- Why agents make testing harder
- Capability evals vs. regression evals
- What makes a good eval
- How to validate your evaluator
- Closing the loop
What is an eval?
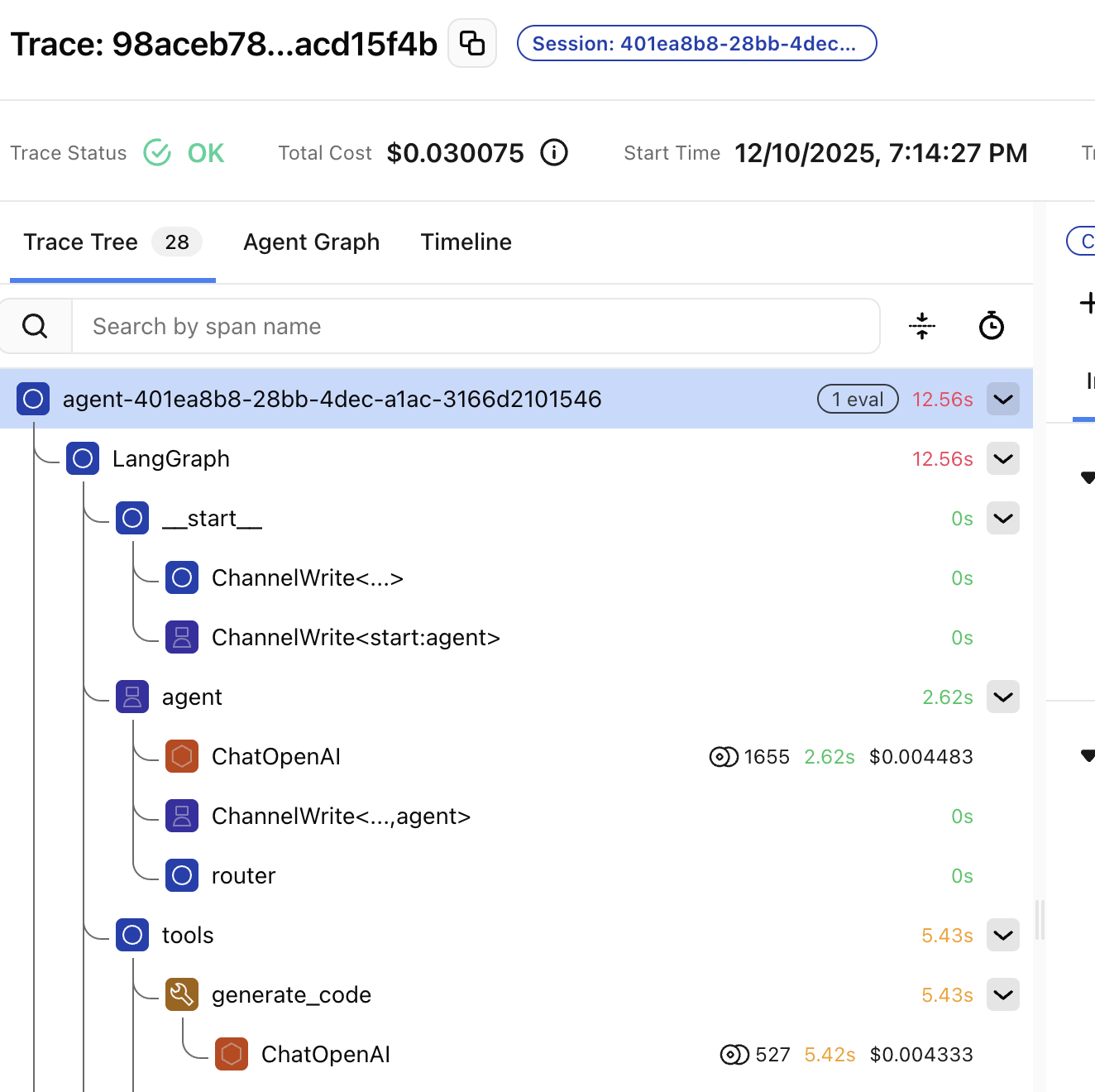
Traces are logs, evals are tests
- Traces = logs, for AI
- Evals = tests, for AI
The vibes problem
What you can't do without evals
- Can't detect regressions when you change a prompt
- Can't compare prompt versions objectively
- Can't know if a new model is actually better
- Can't run quality gates in CI
You can't switch models without evals
- New models drop every few months
- Without evals, switching = weeks of manual testing
- With evals, you know within hours
Two types of evals
- Code evals — deterministic, free, fast
- LLM-as-a-judge — semantic, flexible, powerful
- Human evaluation — validate your evals
When to use which
- Code evals → format, structure, constraints
- LLM judge → accuracy, relevance, tone, faithfulness
- Human review → novel failures, calibrating judges
Why agents make this harder
A ladder of complexity
- Single LLM call: input → output. Done.
- Agent: tool call → result → reasoning → another tool call → output
- Multi-agent: handoffs, routing, specialists
Cascading failures
- Bad retrieval → bad reasoning → confidently wrong output
- Worse than an obvious failure
Capability evals
vs. regression evals
- Capability: can my agent do this new thing?
- Regression: can my agent still do the stuff it used to do?
Capability evals
- "Can my agent do this at all?"
- Expected to mostly fail at first
- Give you a hill to climb
Regression evals
- "Can my agent still do the stuff it used to do?"
- Expected to mostly pass
- Tell you when something has broken
Eval-driven development
- Write the capability eval first
- The eval defines what "done" means
- Then build until it passes
What makes a good eval
Read your data first
- 15 minutes reading traces beats an hour building dashboards
- The highest-leverage activity in agent dev
You need requirements first
You can't say "it doesn't work" if you haven't defined what "works" means
Categorize failures
by root cause
- "The response was wrong" → not actionable. Ask why.
- Retrieval / reasoning / hallucination / scope / format
Frequency × severity = priority
- Fix expensive, frequent failures first
Five parts of a good eval prompt
- Define the judge's role
- Explicit pass/fail criteria
- Present the data clearly
- Add labeled examples
- Constrain the output to a label
Part 1: Define the role
- "You are an expert financial analyst evaluator..."
Part 2: Explicit criteria
ACTIONABLE — contains specific recommendations,
identifies concrete risks, includes forward-looking analysis
NOT ACTIONABLE — only summarizes data,
lacks recommendations, presents risks without evidencePart 3: Present the data clearly
- [BEGIN DATA] / [END DATA] delimiters
- XML also works well
- Label each piece: "User query", "Agent response"
Part 4: Add labeled examples
- One pass example, one fail example
- The single biggest improvement to judge prompt quality
Part 5: Constrain the output
- Binary pass/fail beats 1-to-10 every time
- Or three categories at most: pass / partial / fail
Grade outcomes, not trajectories
- Don't check that the agent followed specific steps
- Agents find valid approaches you didn't anticipate
Can you trust your judges?
Your judge is a classifier
- Just like any classifier, it can be measured
- Compare predictions against ground truth
Without ground truth, you climb a random hill
- You can tune a judge until it loves your output
- If it doesn't agree with humans, you've optimized for nothing
Building a golden dataset
- A small set of human-labeled examples
- The encoded judgment of the people who know your domain best
- 50 examples is enough to start
Be specific. Stay disciplined.
- Don't say "this was good" — say why
- Eliminate ambiguity before fatigue eliminates it for you
Precision and recall
- Precision: when judge says "fail," is it really a fail?
- Recall: of all real fails, how many does the judge catch?
- Prioritize recall — better to flag too much than miss real failures
Judge pitfalls
- Length bias — longer = scores higher
- Self-preference — same model rates itself higher
Failures should seem fair
- If the failing trace looks fine, the eval is broken — not the agent
Closing the loop
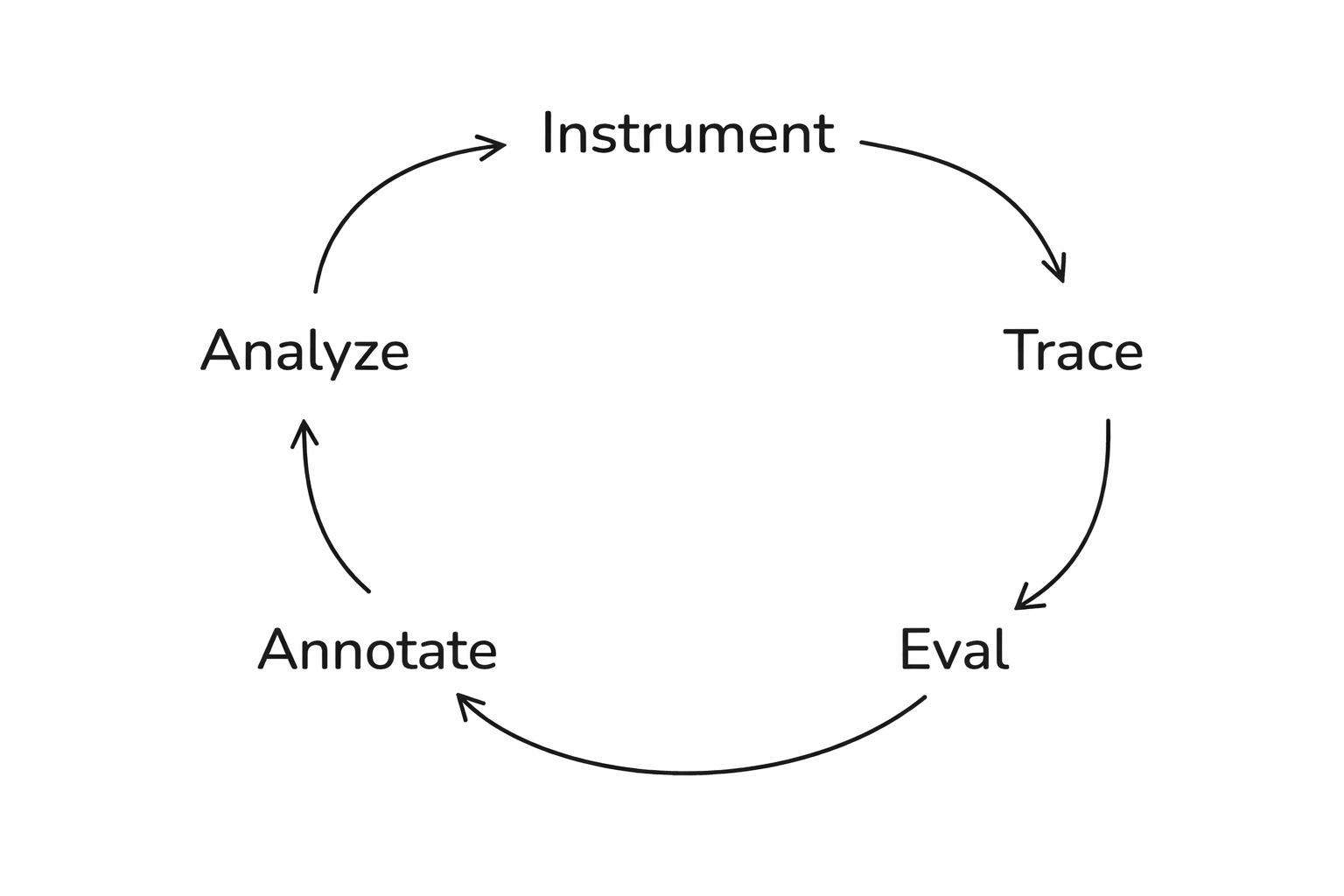
The problem with one-off fixes
Save failures as a dataset
- A curated set of test cases pulled from real traces
- A fixed benchmark you can rerun after every change
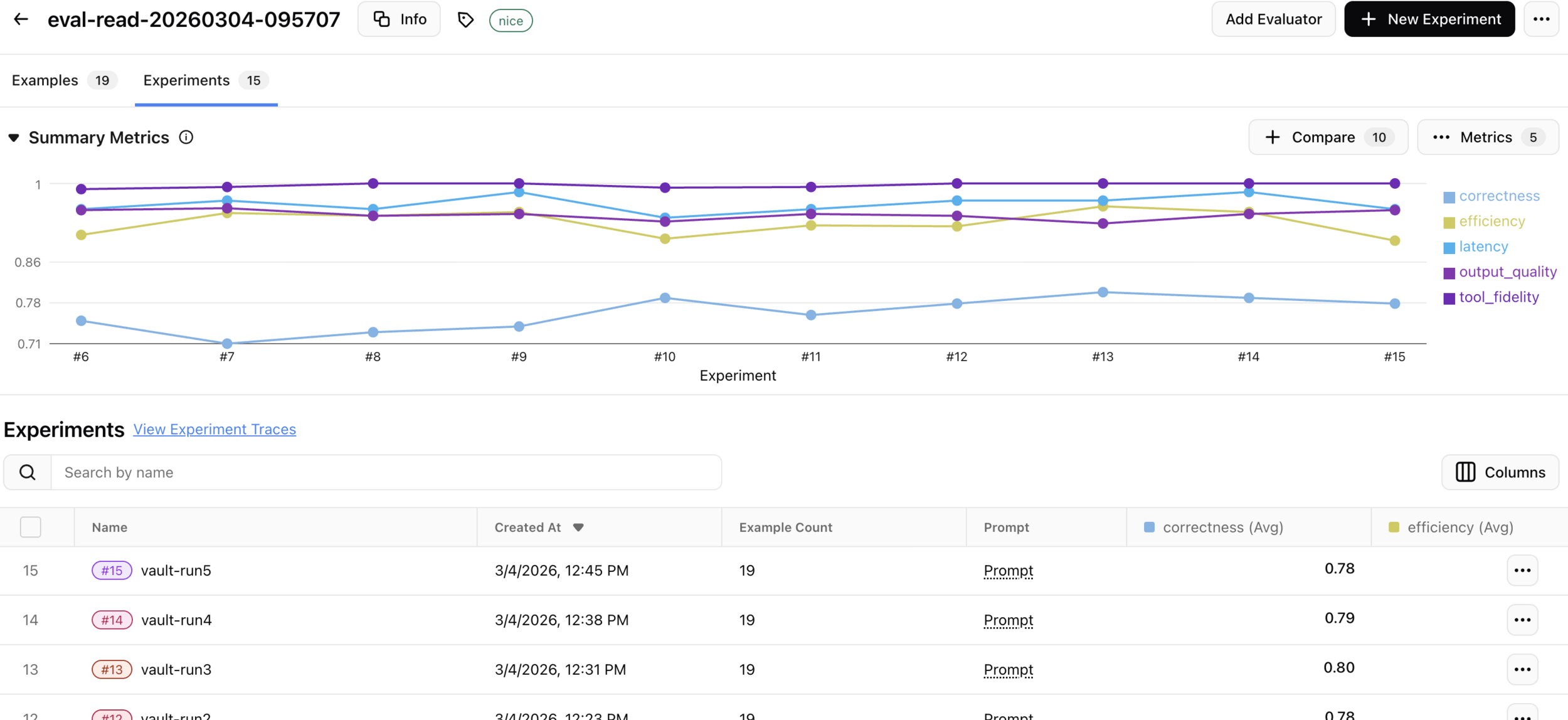
Run experiments
- Same inputs, same evaluators, different agent version
- The only variable is your change
Data-driven prompt engineering
- Every prompt change should map to a finding from the evals
- Not intuition — evidence
The impact hierarchy
- Data quality — highest impact
- Prompting
- Model selection
- Hyperparameters — lowest impact
The data flywheel
- Log → sample → review → improve → repeat
- Production failures become tomorrow's test cases
- Each iteration compounds
Start small
Evals are infrastructure
- Treat evals as core infrastructure, not an afterthought
- The value compounds — but only if you keep investing
Don't hope for great. Specify it. Measure it. Improve toward it.
Get a ticket for just $50 using code ARIZECOMMUNITY50
Want to hear more?
June 4, San Francisco
Thank you!
🦋 @seldo.com on BlueSky
arize.com/docs/phoenix
These slides:
Stop vibe-testing (AgentCon Silicon Valley)
By Laurie Voss




