
Big Data Analysis Using PySpark
Shagun Sodhani


Agenda
- Introduction to Spark
- Using PySpark for StackExchange Data Analysis
- Do and Don'ts for Spark and PySpark
What is Apache Spark?
- Apache Spark™ is a fast and general engine for large-scale data processing
- Originally developed in AMPLab at UC Berkely (2009), open-sourced in 2010, transferred to Apache 2013
- Claims to run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Advantages Over MapReduce
- Speed.
- Ease of Use - Scala, Java, Python, R.
- Generality - Supports different use cases.
- Runs Everywhere - Hadoop, Mesos, standalone ...
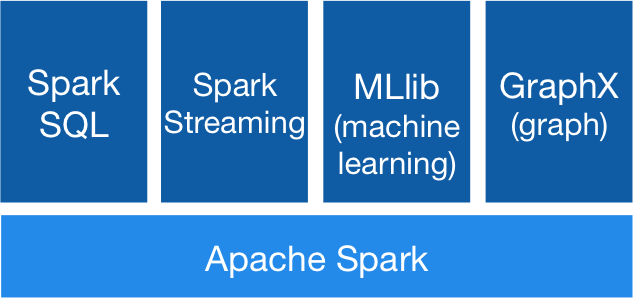
Spark Components
- Spark RDD
- Spark SQL and DataFrames
- Spark Streaming
- MLlib
- GraphX
Talk is cheap. Show me the code.
Linus Torvalds
Do's and Don'ts
- Prefer DataFrame over RDD (Especially with PySpark)
- Avoid UDFs in Python
- Use cache carefully
- Avoid collect
- Be lazy
Thank You

Shagun Sodhani
Big Data Analysis using PySpark
By Shagun Sodhani
Big Data Analysis using PySpark
For PyCon 2016



