The Misidentified Identifiability Problem of Bayesian Knowledge Tracing
Shayan Doroudi, Emma Brunskill


How we fit student models can have unforeseen consequences on how they impact student learning.
Identifiability Problem
The Problem:
Multiple sets of model parameters lead to identical predictions about student performance.
Implication:
May lead to making inaccurate predictions about whether a student has mastered material or not.
Our Contribution:
We show that this problem does not exist
for Bayesian Knowledge Tracing.
Semantic Model Degeneracy
The Problem:
Best fitting model parameters can be inconsistent with what it means for a student to learn a skill.
Our Contribution:
We show one possible source of this problem:
model mismatch.
Implication:
May lead to making inaccurate predictions about whether a student has mastered material or not.
- Bayesian Knowledge Tracing
- Identifiability
- Semantic Model Degeneracy
Overview
Bayesian Knowledge Tracing (BKT)
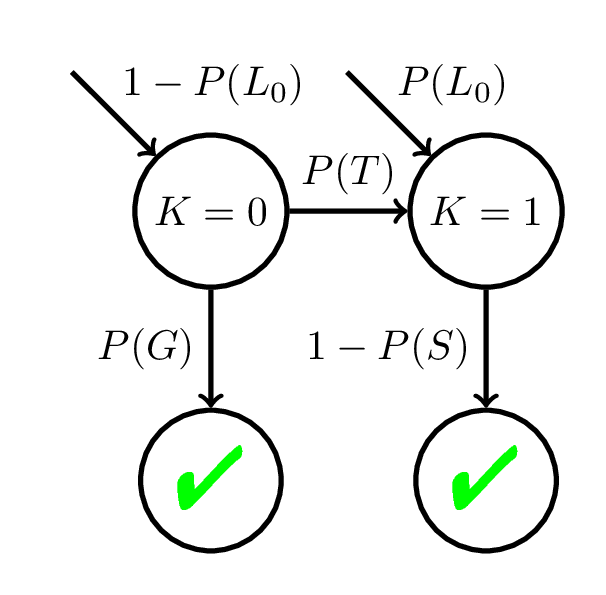
Identifiability
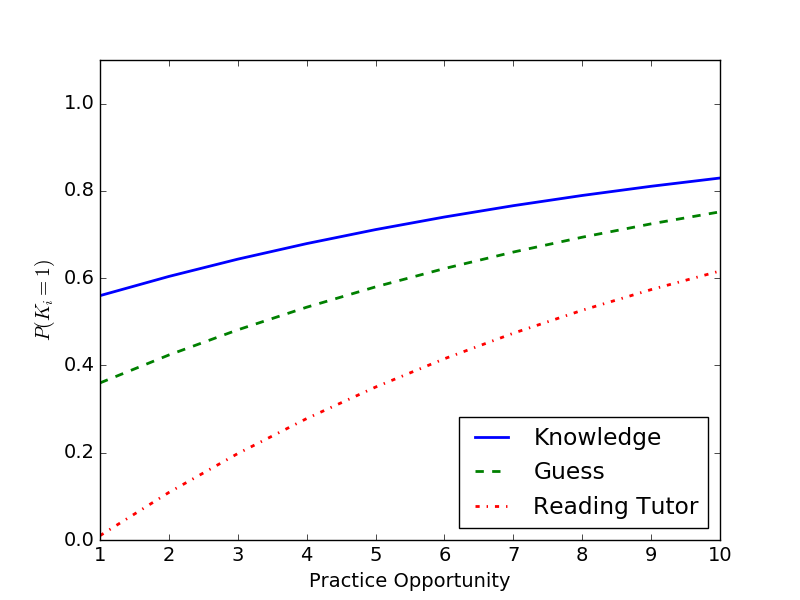
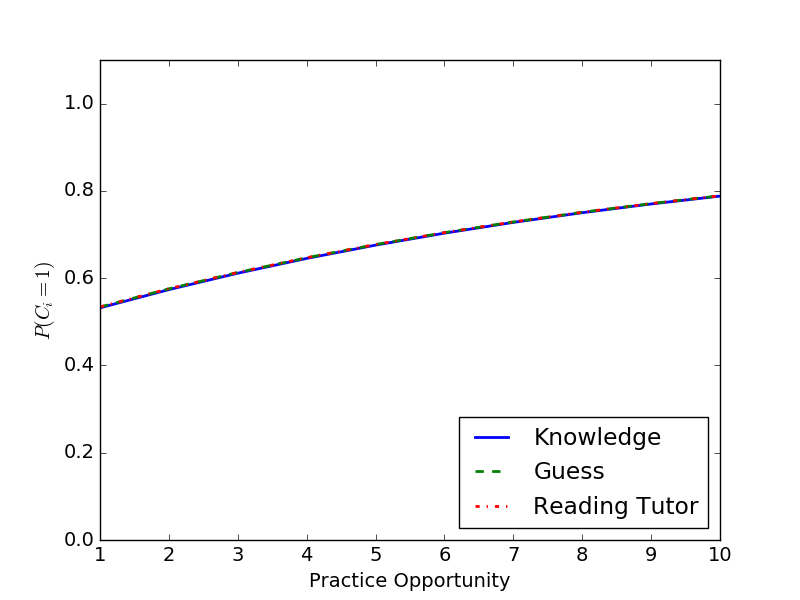
All three models make identical predictions
about student performance
prior to observing student responses.
Beck and Chang, 2007
Identifiability
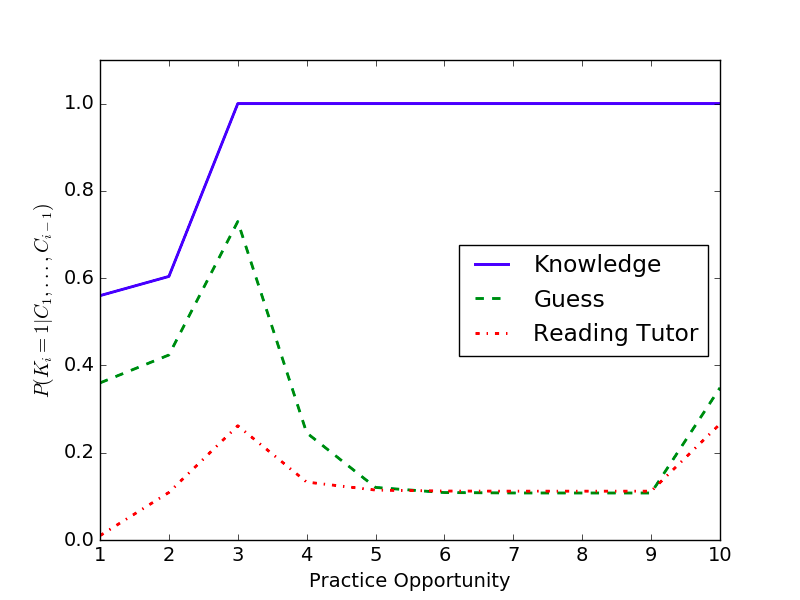
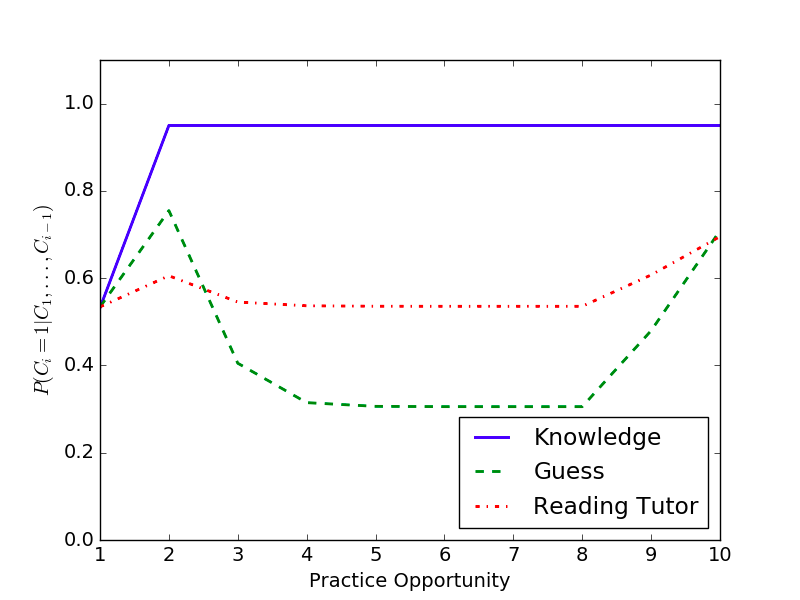
Online predictions given responses (Correct, Incorrect, Incorrect, Incorrect, Incorrect, Incorrect, Incorrect, Correct, Correct)
Identifiability
Models make distinct predictions even after a single student response.
Identifiability
Any HMM (subject to mild conditions) is identifiable with the joint probability distribution of three sequential observations.
Anandkumar et al., 2012
Identifiability
In the context of BKT models:
\(P(C_1), P(C_1, C_2)\), and \(P(C_1, C_2, C_3)\)
are enough to infer the unique model parameters as long as
$$P(L_0) \notin \{0, 1\}, P(T) \neq 1, \text{and } P(G) \neq 1 - P(S)$$
Identifiability
Three sequential responses from students is enough to uniquely identify BKT parameters.
Semantic Model Degeneracy
We have more knowledge about student learning than the data we use to train our models. As cognitive scientists, we have some notion of what learning “looks like.” For example, if a model suggest that a skill gets worse with practice, it is likely the problem is with the modeling approach, not that the students are actually getting less knowledgeable. The question is how can we encode these prior beliefs about learning?
Beck and Chang, 2007
Types of Semantic Model Degeneracy
- Forgetting:
$$P(G) > 1 - P(S)$$ - Low Performance Mastery:
$$P(S) > t$$ - High Performance Guessing:
$$P(G) > t$$ - High Performance \(\nRightarrow\) Learning:
After \(m\) consecutive correct responses, \(P(K_i) < t\)
Motivated by Baker et al., 2008
Source of Semantic Model Degeneracy: Model Mismatch
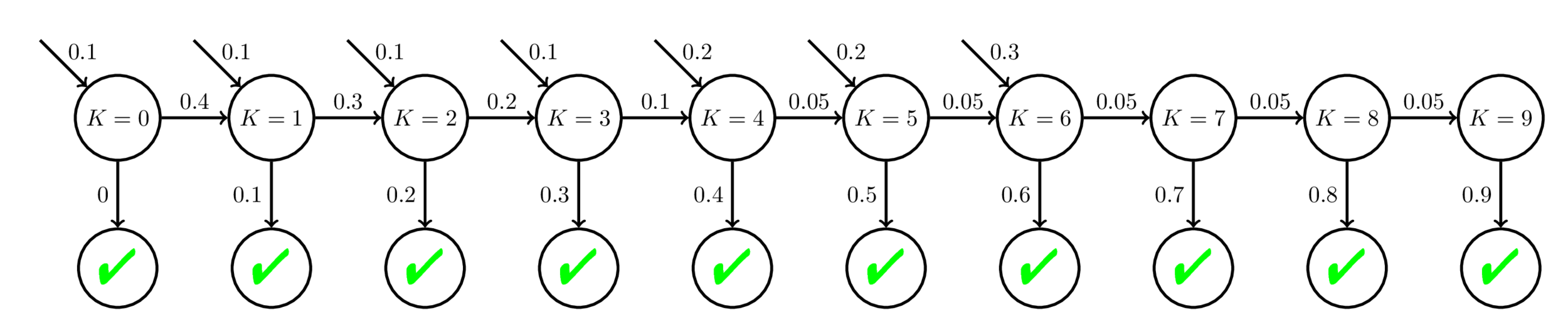
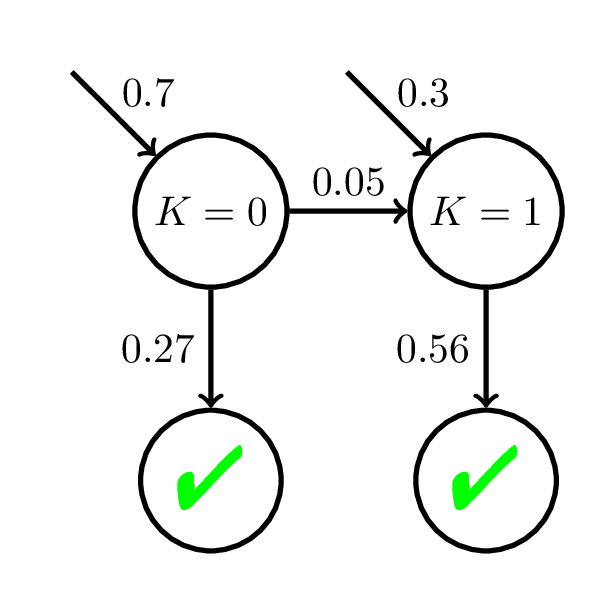
Fit BKT with 20 practice opp
Low Performance Mastery
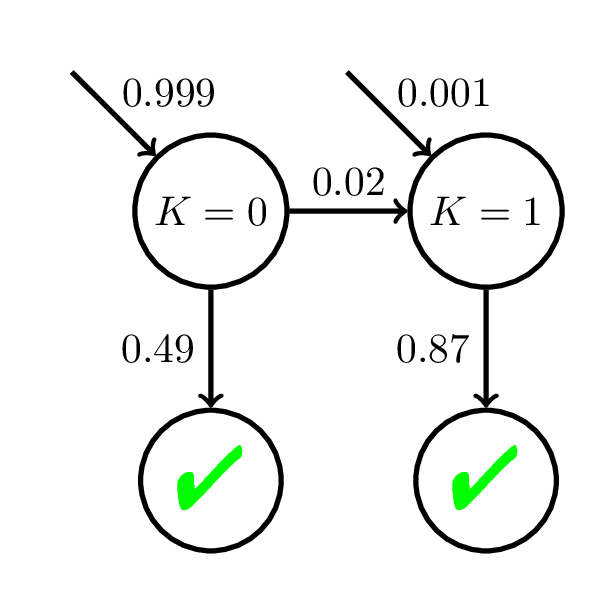
Fit BKT with 200 practice opp
Source of Semantic Model Degeneracy: Model Mismatch
High Performance Guessing
High Performance \(\nRightarrow\) Learning
Model Mismatch: AFM
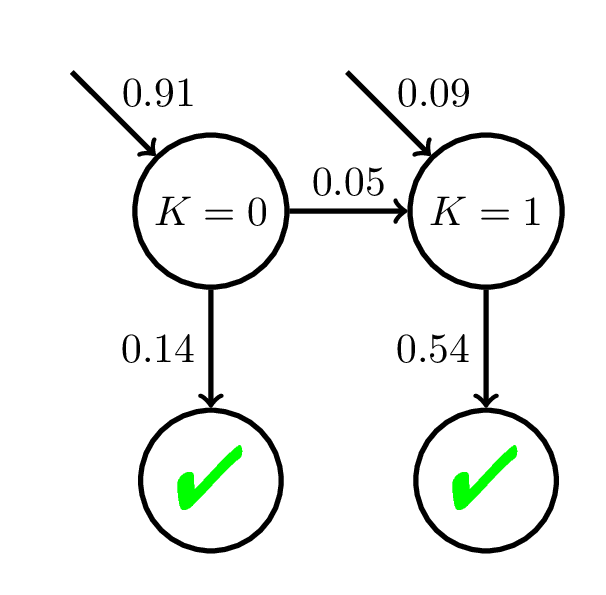
P(C_i = 1) = \frac{1}{1 + \exp(-\theta + 2 - 0.1i)}
\theta \sim \mathcal{N}(0, 1)
(Student Ability)
Fit BKT with 20 practice opp
Model Mismatch: AFM
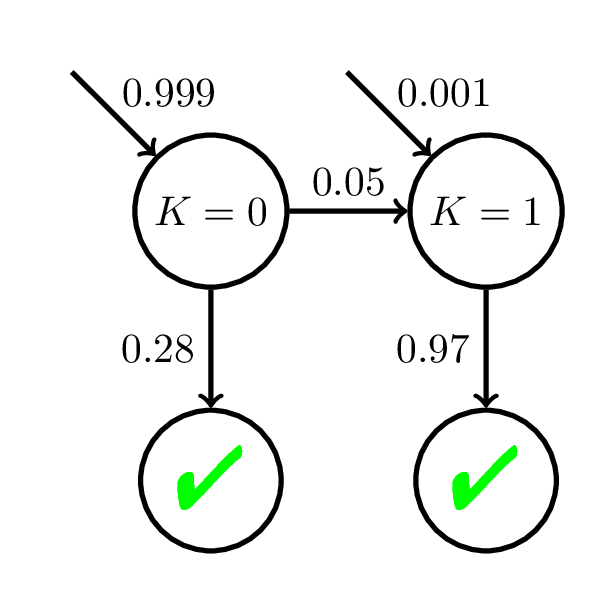
P(C_i = 1) = \frac{1}{1 + \exp(-\theta + 2 - 0.1i)}
\theta \sim \mathcal{N}(0, 1)
(Student Ability)
Fit BKT with 200 practice opp
Implications on Mastery Learning
Fit BKT with 20 practice opp
Perceived Mastery State
Actual Mastery State
We may give fewer practice opportunities to students than they actually need to reach mastery.
What should we do?
- Consider alternative student models.
- Detecting whether a student model is correct by seeing how robust it is to the number of practice opportunities per student.
- A BKT model that is semantically degenerate is not necessarily meaningless.
- Can still try to see how much learning (or forgetting!) is happening.
Conclusion
- BKT is identifiable.
- Model mismatch can lead to parameters that are inconsistent with our notions of student learning.
- How much data we use to train our models could lead to different forms of semantic model degeneracy.
- Model mismatch could have implications for mastery learning.
How we fit student models can have unforeseen consequences on how they impact student learning.
The research reported here was supported, in whole or in part, by the Institute of Education Sciences, U.S. Department of Education, through Grants R305A130215 and R305B150008 to Carnegie Mellon University. The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Dept. of Education.
Take our research survey about models of student learning!
tinyurl.com/student-model-survey
EDM 2017 Presentation
By Shayan Doroudi
EDM 2017 Presentation
Presentation on "The Misidentified Identifiability Problem of Bayesian Knowledge Tracing"



