Reinforcement Learning for Instructional Sequencing:
Learning from Its Past to Meet the Challenges of the Future
Shayan Doroudi
RL4ED Workshop @ EDM 2021



| First Wave (1960s-70s) |
|
|---|---|
| Educational Technology | Teaching Machines / CAI |
| Optimization Methods | Decision Processes |
| Models of Learning | Mathematical Psychology |
| First Wave (1960s-70s) |
Second Wave (2000s-2010s) |
|
|---|---|---|
| Educational Technology | Teaching Machines / CAI | Intelligent Tutoring Systems |
| Optimization Methods | Decision Processes | Reinforcement Learning |
| Models of Learning | Mathematical Psychology | Machine Learning AIED/EDM |
| First Wave (1960s-70s) |
Second Wave (2000s-2010s) |
Third Wave (2010s) |
|
|---|---|---|---|
| Educational Technology | Teaching Machines / CAI | Intelligent Tutoring Systems | Massive Open Online Courses |
| Optimization Methods | Decision Processes | Reinforcement Learning | Deep RL |
| Models of Learning | Mathematical Psychology | Machine Learning AIED/EDM |
Deep Learning |
More data-driven
More data-generating
Over the past 50 years, how successful has RL been in discovering useful adaptive instructional policies?
What are the challenges that we must face if we are to use RL productively in education going forward?
Learning from the Past
Meeting the Challenges of the Future
Over the past 50 years, how successful has RL been in discovering useful adaptive instructional policies?
What are the challenges that we must face if we are to use RL productively in education going forward?
Learning from the Past
Meeting the Challenges of the Future
Searched for all empirical studies (as of December 2018) that compared one or more RL-induced policies (broadly conceived) to one or more baseline policies.
Review of Empirical Studies
Found 41 such studies that were clustered into five qualitatively different clusters.
| Doroudi, S., Aleven, V., & Brunskill, E. (2019). Where’s the reward? A review of reinforcement learning for instructional sequencing. International Journal of Artificial Intelligence in Education, 29(4), 568-620. |
Paired-Associate Learning Tasks
Concept Learning Tasks
Sequencing Activity Types
Sequencing Interdependent Content
Five Clusters of Studies
Not Optimizing Learning
leer

to read
Paired-Associate Learning Tasks
Concept Learning Tasks
Sequencing Activity Types
Sequencing Interdependent Content
Five Clusters of Studies
Not Optimizing Learning
Includes all studies done in 1960s-1970s
Treats each pair as independent
Use psychological models that account for learning and forgetting.
Paired-Associate Learning Tasks
Concept Learning Tasks
Sequencing Activity Types
Sequencing Interdependent Content
Five Clusters of Studies
Not Optimizing Learning


reading
Use cognitive science models that describe how people learn concepts from examples.
Concept Learning Tasks
Sequencing Activity Types
Sequencing Interdependent Content
Five Clusters of Studies
Not Optimizing Learning
Worked Example
Problem
Solving
\(x^2 - 4 = 12\)
Solve for \(x\):
\(x^2 - 4 = 12\)
\(x^2 = 4 + 12\)
\(x^2 = 16\)
\(x = \sqrt{16} = \pm4\)
\(x^2 - 4 = 12\)
Solve for \(x\):
Paired-Associate Learning Tasks
Content is pre-determined.
The decision is what kind of instruction to give for each piece of content.
Concept Learning Tasks
Sequencing Activity Types
Sequencing Interdependent Content
Five Clusters of Studies
Not Optimizing Learning
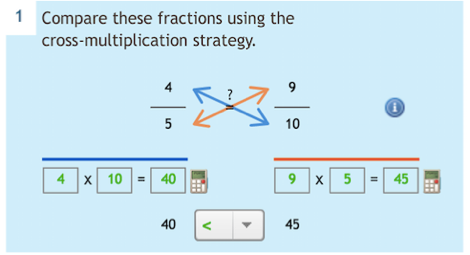
Paired-Associate Learning Tasks
Pieces of content are interrelated.
Instructional methods could also vary.
Concept Learning Tasks
Sequencing Activity Types
Sequencing Interdependent Content
Five Clusters of Studies
Not Optimizing Learning
Paired-Associate Learning Tasks
Five Clusters of Studies
| RL Policy Outperformed Baseline | Mixed Results / ATI |
RL Policy Did Not Outperform Baseline |
|
|---|---|---|---|
| Paired-Associate Learning Tasks | 11 | 0 | 3 |
Five Clusters of Studies
| RL Policy Outperformed Baseline | Mixed Results / ATI |
RL Policy Did Not Outperform Baseline |
|
|---|---|---|---|
| Paired-Associate Learning Tasks | 11 | 0 | 3 |
| Concept Learning Tasks | 4 | 2 | 1 |
Five Clusters of Studies
| RL Policy Outperformed Baseline | Mixed Results / ATI |
RL Policy Did Not Outperform Baseline |
|
|---|---|---|---|
| Paired-Associate Learning Tasks | 11 | 0 | 3 |
| Concept Learning Tasks | 4 | 2 | 1 |
| Sequencing Activity Types | 4 | 4 | 2 |
Five Clusters of Studies
| RL Policy Outperformed Baseline | Mixed Results / ATI |
RL Policy Did Not Outperform Baseline |
|
|---|---|---|---|
| Paired-Associate Learning Tasks | 11 | 0 | 3 |
| Concept Learning Tasks | 4 | 2 | 1 |
| Sequencing Activity Types | 4 | 4 | 2 |
| Sequencing Interdependent Content | 0 | 2 | 6 |
Five Clusters of Studies
| RL Policy Outperformed Baseline | Mixed Results / ATI |
RL Policy Did Not Outperform Baseline |
|
|---|---|---|---|
| Paired-Associate Learning Tasks | 11 | 0 | 3 |
| Concept Learning Tasks | 4 | 2 | 1 |
| Sequencing Activity Types | 4 | 4 | 2 |
| Sequencing Interdependent Content | 0 | 2 | 6 |
| Not Optimizing Learning | 2 | 0 | 0 |
The Role of Theory
Use Psychologically-Inspired Models
Spacing Effect
Expertise Reversal Effect
Use Data-Driven
Models
Theoretical Basis
More
Less
Concept Learning Tasks
Sequencing Activity Types
Sequencing Interdependent Content
Paired-Associate Learning Tasks
Over the past 50 years, how successful has RL been in discovering useful adaptive instructional policies?
What are the challenges that we must face if we are to use RL productively in education going forward?
Learning from the Past
Meeting the Challenges of the Future
Three Challenges
How do we most effectively leverage RL to enhance student learning?
How do we know if RL actually enhances student learning?
How do we ensure RL-based systems actually enhance student learning in the real world?
Three Challenges
Effectiveness
Evaluation
External Validity
Effectiveness
How do we most effectively leverage RL to enhance student learning?
“We argue that despite the power of big data, psychological theory provides essential constraints on models, and that despite the success of psychological theory in providing a qualitative understanding of phenomena, big data enables quantitative, individualized predictions of learning and performance”
Mozer, M. C., & Lindsey, R. V. (2017). Predicting and Improving memory retention: Psychological theory matters in the big data era. In Big data in cognitive science (pp. 34-64).
Data-driven models should be combined with insights from psychological theories.
Effectiveness
How do we most effectively leverage RL to enhance student learning?
Data-driven models should be combined with insights from psychological theories.
Choice of models
Types of actions
Theory can inform:
Space of policies
Evaluation
We need to compare RL-induced policies to the most effective baseline policies we can think of.
How do we know if RL actually enhances student learning?
In our review, 71% studies with sig. effect compared to random sequencing or other RL-induced policies as baselines.
Only 35% of studies with no sig. effect compared to random sequencing or other RL-induced policies as baselines
Evaluation
We need to compare RL-induced policies to the most effective baseline policies we can think of.
How do we know if RL actually enhances student learning?
For paired-associate learning tasks, there are advanced heuristics used in commercial systems that we could compare to:
SuperMemo
Leitner system
Only Lindsey (2016) conducted a study comparing an RL-induced policy to SuperMemo.
Evaluation
We need to compare RL-induced policies to the most effective baseline policies we can think of.
How do we know if RL actually enhances student learning?
For sequencing activity types, we could compare to policies based on principles such as the expertise-reversal effect.
For sequencing interdependent content, we could compare to heuristics that sequence based-on expert-curated knowledge maps.
Evaluation
Even when RL-induced policies outperform baselines, there could be at least three reasons:
How do we know if RL actually enhances student learning?
Content
Order
Adaptivity
Just because a data-driven policy does better does not necessarily mean adaptivity matters.
Evaluation
In order to determine if adaptivity matters, we can use yoked control designs.
How do we know if RL actually enhances student learning?
Kalyuga, S., & Sweller, J. (2005). Rapid dynamic assessment of expertise to improve the efficiency of adaptive e-learning. Educational Technology Research and Development, 53(3), 83-93.




External Validity
We need to take into account the realities of real-world educational environments.
How do we ensure RL-based systems actually enhance student learning in the real world?
Just because an RL-based system is shown to be effective in an experiment does not necessarily mean it will be effective in the real world.
Does the policy work well when used in conjunction with other instructional practices?
Does the policy work well in educationally-relevant time scales?
External Validity
We need to take into account the realities of real-world educational environments.
How do we ensure RL-based systems actually enhance student learning in the real world?
Do teachers have enough control/flexibility?
Do students have enough control?
Just because an RL-based system is shown to be effective does not necessarily mean it will get used.
[T]he development of a theory of instruction cannot progress if one holds the view that a complete theory of learning is a prerequisite.
Rather, advances in learning theory will affect the development of a theory of instruction,
and conversely the development of a theory of instruction will influence research on learning.
Atkinson (1972)
Acknowledgements
The research reported here was supported, in whole or in part, by the Institute of Education Sciences, U.S. Department of Education, through Grants R305A130215 and R305B150008 to Carnegie Mellon University. The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Dept. of Education.
Inclusion Criteria
We consider any papers published before December 2018 where:
- There is (implicitly) a model of the learning process, where different instructional actions probabilistically change the state of a student.
- There is an instructional policy that maps past observations from a student (e.g., responses to questions) to instructional actions.
- Data collected from students are used to learn either:
- the model
- an adaptive policy
- If the model is learned, the instructional policy is designed to (approximately) optimize that model according to some reward function
What's Not Included?
- Adaptive policies that use hand-made or heuristic decision rules (rather than data-driven/optimized decision rules)
- Experiments that do not control for everything other than sequence of instruction
- Experiments that use RL for other educational purposes, such as:
- generating data-driven hints (Stamper et al., 2013) or
- giving feedback (Rafferty et al., 2015)
“The mathematical techniques of optimization used in theories of instruction draw upon a wealth of results from other areas of science, especially from tools developed in mathematical economics and operations research over the past two decades, and it would be my prediction that we will see increasingly sophisticated theories of instruction in the near future.”
Suppes (1974)
The Place of Theory in Educational Research
AERA Presidential Address
RL's Status in Education Research
The Role of Theory
Psychological theory can help determine both when sequencing might matter as well as how to most effectively leverage RL for instructional sequencing.
Case Study
- Fractions Tutor
- Two experiments testing RL-induced policies (both no sig difference)
- Off-policy policy evaluation
Fractions Tutor
Experiment 1
-
Used prior data to fit G-SCOPE Model (Hallak et al., 2015).
-
Used G-SCOPE Model to derive two new Adaptive Policies.
-
Wanted to compare Adaptive Policies to a Baseline Policy (fixed, spiraling curriculum).
-
Simulated both policies on G-SCOPE Model to predict posttest scores (out of 16 points).
Experiment 1:
Policy Evaluation
| Baseline | Adaptive Policy | |
|---|---|---|
| Simulated Posttest | 5.9 ± 0.9 | 9.1 ± 0.8 |
Doroudi, Aleven, and Brunskill, L@S 2017
| Baseline | Adaptive Policy | |
|---|---|---|
| Simulated Posttest | 5.9 ± 0.9 | 9.1 ± 0.8 |
| Actual Posttest | 5.5 ± 2.6 | 4.9 ± 2.6 |
Doroudi, Aleven, and Brunskill, L@S 2017
Experiment 1:
Policy Evaluation
Single Model Simulation
- Used by Chi, VanLehn, Littman, and Jordan (2011) and Rowe, Mott, and Lester (2014) in educational settings.
- Rowe, Mott, and Lester (2014): New adaptive policy estimated to be much better than random policy.
- But in experiment, no significant difference found (Rowe and Lester, 2015).
Importance Sampling
- Estimator that gives unbiased and consistent estimates for a policy!
- Can have very high variance when policy is different from prior data.
- Example: Worked example or problem-solving?
- 20 sequential decisions ⇒ need over \(2^{20}\) students
- 50 sequential decisions ⇒ need over \(2^{50}\) students!
- Importance sampling can prefer the worse of two policies more often than not (Doroudi et al., 2017b).
Doroudi, Thomas, and Brunskill, UAI 2017, Best Paper
Robust Evaluation Matrix
Policy 1 |
Policy 2 |
Policy 3 |
|
|---|---|---|---|
Student Model 1 |
|||
Student Model 2 |
|||
Student Model 3 |
\(V_{SM_1,P_1}\)
\(V_{SM_2,P_1}\)
\(V_{SM_3,P_1}\)
\(V_{SM_1,P_2}\)
\(V_{SM_2,P_2}\)
\(V_{SM_3,P_2}\)
\(V_{SM_1,P_3}\)
\(V_{SM_2,P_3}\)
\(V_{SM_3,P_3}\)
Robust Evaluation Matrix
|
Baseline |
Adaptive Policy |
|
|---|---|---|
|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
Doroudi, Aleven, and Brunskill, L@S 2017
Robust Evaluation Matrix
|
Baseline |
Adaptive Policy |
|
|---|---|---|
|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
|
Bayesian Knowledge Tracing |
6.5 ± 0.8 |
7.0 ± 1.0 |
Doroudi, Aleven, and Brunskill, L@S 2017
Robust Evaluation Matrix
|
Baseline |
Adaptive Policy |
|
|---|---|---|
|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
|
Bayesian Knowledge Tracing |
6.5 ± 0.8 |
7.0 ± 1.0 |
|
Deep Knowledge Tracing |
9.9 ± 1.5 |
8.6 ± 2.1 |
Doroudi, Aleven, and Brunskill, L@S 2017
Robust Evaluation Matrix
|
Baseline |
Adaptive Policy |
Awesome Policy |
|
|---|---|---|---|
|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
16 |
|
Bayesian Knowledge Tracing |
6.5 ± 0.8 |
7.0 ± 1.0 |
16 |
|
Deep Knowledge Tracing |
9.9 ± 1.5 |
8.6 ± 2.1 |
16 |
Doroudi, Aleven, and Brunskill, L@S 2017
Experiment 2
- Used Robust Evaluation Matrix to test new policies
- Found that a New Adaptive Policy that was very simple but robustly expected to do well:
- sequence problems in increasing order of avg. time
- skip any problems where students have demonstrated mastery of all skills (according to BKT)
- Ran an experiment testing New Adaptive Policy
Experiment 2
| Baseline | New Adaptive Policy | |
|---|---|---|
| Actual Posttest | 8.12 ± 2.9 | 7.97 ± 2.7 |
Experiment 2:
Insights
-
Even though we did robust evaluation, two things were not considered adequately:
-
How long each problem takes per student
-
Student population mismatch
-
Robust evaluation can help us identify where our models are lacking and lead to building better models over time.
Overview
- Reinforcement Learning: Towards a "Theory of Instruction"
- Part 1: Historical Perspective
- Part 2: Systematic Review
- Discussion: Where's the Reward?
- Part 3: Case Study: Fractions Tutor and Policy Selection
- Planning for the Future
Planning for the Future
-
Data-Driven + Theory-Driven Approach
-
Reinforcement learning researchers should work with learning scientists and psychologists.
-
Work on domains where we have or can develop decent cognitive models.
-
Work in settings where the set of actions is restricted but that are still meaningful
(e.g., worked examples vs. problem solving) -
Compare to good baselines based on learning sciences (e.g., expertise reversal effect)
-
-
Do thoughtful and extensive offline evaluations.
-
Iterate and replicate! Develop theories of instruction that can help us see where the reward might be.
Is Data-Driven Sufficient?
- Might we see a revolution in data-driven instructional sequencing?
- More data
- More computational power
- Better RL algorithms
- Similar advances have recently revolutionized the fields of computer vision, natural language processing, and computational game-playing.
- Why not instruction?
- Learning is fundamentally different from images, language, and games.
- Baselines are much stronger for instructional sequencing.
So, where is the reward?
- In the coming years, will likely see both purely data-driven (deep learning) approaches as well as theory+data-driven approaches to instructional sequencing.
- Only time can tell where the reward lies, but our robust evaluation suggests combining theory and data.
- By reviewing the history and prior empirical literature, we can have a better sense of the terrain we are operating in.
So, where is the reward?
- Applying RL to instructional sequencing has been rewarding in other ways:
- Advances have been made to the field of RL.
- The Optimal Control of Partially Observable Markov Processes
- Our work on importance sampling (Doroudi et al., 2017b)
- Advances have been made to student modeling.
- Advances have been made to the field of RL.
By continuing to try to optimize instruction, we will likely continue to expand the frontiers of the study of human and machine learning.
RL4ED Talk
By Shayan Doroudi
RL4ED Talk
EDM 2021 RL4ED Workshop



