Reinforcement Learning
Learning by Doing



Learning Without a Teacher
Imagine dropping Mario into this grid with no manual, no walkthrough.
- No one tells him which squares are safe
- Each step: maybe a coin (+1), maybe a pit (−10)
- The only feedback: what happened?

This is reinforcement learning: learning by doing.
Three Learning Paradigms
| Supervised | Unsupervised / Generative | Reinforcement | |
|---|---|---|---|
| Data | Labeled dataset | Unlabeled dataset | Collected through actions |
| Feedback | Correct answer (label) | None; find structure | Reward signal (good/bad) |
| Goal | Predict \(y\) from \(x\) | Model \(P(x)\) or generate | Maximize total reward |
| Analogy | Studying from a textbook | Finding patterns in raw data | Learning to ride a bike |
Today's Roadmap
Refresh
RL loop, policy, trajectory
Why Is RL Hard?
Credit, data, efficiency, exploration
MDP Modeling
5 real systems through \(\mathcal{S}, \mathcal{A}, T, R, \gamma\)
Reward Design
What we reward is what we get
Throughout, the common thread is the choices we make to turn a problem into an MDP, and what each choice costs us.
The RL Loop
The agent takes an action, the environment updates the agent's state and gives out a reward, and the cycle repeats.
Policy: The Agent's Strategy
A policy \(\pi\) maps states to actions: what should the agent do in each situation?
Deterministic: \(\pi(s) = a\)
State: coin to the right, pit ahead
Stochastic: \(\pi(a \mid s) = P\)
State: coin to the right, pit ahead
A Trajectory Unfolds
Reward \(R(s, a)\)
Transition \(T(s,a,s')\)
Policy \(\pi(s)\)
A trajectory (rollout) of horizon \(h\): \(\quad \tau = (s_0, a_0, r_0,\; s_1, a_1, r_1,\; \ldots,\; s_{h-1}, a_{h-1}, r_{h-1})\)
The goal of RL: find a policy to maximize expected sum of discounted reward.
Why Is RL Hard?
The challenges of learning by doing

The Credit Assignment Problem
Scenario: We win a chess game after 50 moves.
Which moves deserve credit? The opening? The mid-game sacrifice?
The final checkmate?
In SL: every example has its own label, so credit is immediate
In RL: a single reward might result from a sequence of actions
Made worse when rewards are sparse: in chess, the only reward is win/lose at the very end
Cooking analogy: Our cake tastes terrible. Was it the flour ratio?
The oven temperature? Taking it out too early?
Each step was a decision, and the feedback only comes at the end.
Self-Generated Data
In SL, the training data is fixed. In RL, the agent creates its own data.
A bad policy doesn't just perform badly; it corrupts the data it learns from next.
Exploration vs. Exploitation


[Seinfeld, S06E09]
[feynmanlectures.caltech.edu]
Exploit: stick with the best option we know | Explore: try something new to gather info
Exploration has real costs, if at all possible: A/B tests give real users bad experiences, medical trials risk patient safety, self-driving cars risk lives.
Sample Efficiency
RL needs an enormous amount of experience:
- AlphaGo: ~30 million games of self-play
- OpenAI Five (Dota 2): ~10,000 years of in-game experience
all from interaction, not passive data collection.
Compare with supervised / self-supervised learning:
- CLIP: ~400 million image-text pairs
- GPT-3: ~300 billion tokens of text
from scraping the internet.

RL Agent
Computer Vision
NLP
Internet-scale data
Real-world cost: We can simulate Go games for free, but we can't simulate surgery, driving, or customer interactions as cheaply.
Modeling via MDP
Abstracting real problems as MDPs
Markov Decision Processes
The future depends only on the current state, not how we got there.
| Symbol | Name | Meaning |
|---|---|---|
| \(\mathcal{S}\) | State space | All possible configurations of the world |
| \(\mathcal{A}\) | Action space | What the agent can do |
| \(T(s, a, s')\) | Transitions | \(\Pr(\text{next state } s' \mid \text{state } s, \text{action } a)\) |
| \(R(s, a)\) | Reward | Immediate payoff for action \(a\) in state \(s\) |
| \(\gamma \in [0,1]\) | Discount | How much future reward is worth relative to now |
Objective: maximize expected return \(\mathbb{E}[G_t]\), where \(G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k}\).
MDP vs. Reinforcement Learning
RL = partially unknown MDP
| Symbol | Name | Meaning |
|---|---|---|
| \(\mathcal{S}\) | State space | All possible configurations of the world |
| \(\mathcal{A}\) | Action space | What the agent can do |
| \(T(s, a, s')\) | Transitions | \(\Pr(\text{next state } s' \mid \text{state } s, \text{action } a)\) |
| \(R(s, a)\) | Reward | Immediate payoff for action \(a\) in state \(s\) |
| \(\gamma \in [0,1]\) | Discount | How much future reward is worth relative to now |
The agent must learn a good policy from experience alone.
Modeling a Walking Robot
| Joint angles, velocity, balance, ... | |
| Torque to each motor | |
| Unknown; must learn by trying | |
| +1 forward, −10 for falling | |
| High but : avoiding a fall now matters, but so does walking far; walking has no natural end |
[Toddler robot, Russ Tedrake thesis, 2004]
No one programmed the gait. The robot discovered it through trial and error.
AlphaGo
| 19×19 grid of black, white, or empty (~10 to 172) | |
| Where to place the next stone (~361 moves) | |
| Known (assuming self-play) | |
| +1 win, −1 lose. (can we assume knowing transient rewards?) |
|
| 1: (doesn't matter when to win.) |
[Game 2 board, CC BY-SA 4.0, Wikimedia Commons]

Chip Placement
| \(\mathcal{S}\) | Partial layout, connectivity, congestion | \(\mathcal{A}\) | Place the next macro on the canvas |
| \(T\) | Deterministic: placement updates routing | \(R\) | Penalize wirelength, congestion, area |
| \(\gamma\) | 1: finite placement process, ending once all macros are placed | ||
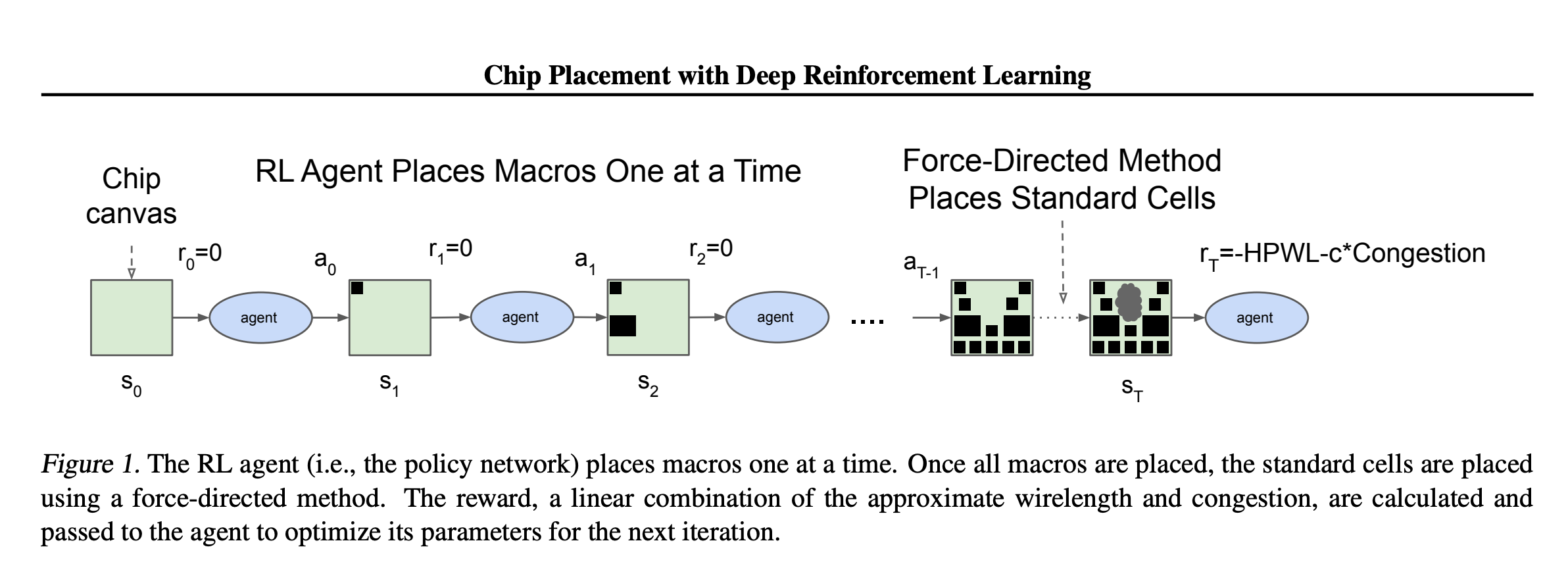
[Mirhoseini et al., Google Research, 2020]
TikTok
| \(\mathcal{S}\) | User profile + watch history + time of day + device |
| \(\mathcal{A}\) | Which video to show next (from a candidate pool) |
| \(T\) | Unknown; how does the user's state change after watching? |
| \(R\) | Watch time? Likes? Shares? Some weighted combination? |
| \(\gamma\) | High → long-term retention; Low → maximize this session |
Is "watch time" a good reward? We might watch a 10-minute drama unfold but feel worse afterward. The algorithm counts that as a win. But is it?

RL Beyond Games: AlphaTensor
Matrix multiplication:
the textbook uses 8 multiplications for 2×2.
In 1969, Strassen showed 7 suffice.
For larger matrices, finding the minimum number of steps has been an open problem for decades.
What can an RL agent help discover?

DeepMind
AlphaTensor
DeepMind framed this as a single-player game:
| \(\mathcal{S}\) | Residual tensor still to decompose |
| \(\mathcal{A}\) | Next rank-one term to subtract |
| \(T\) | Deterministic: subtracting updates the residual exactly |
| \(R\) | −1 per step, large bonus on reaching zero |
| \(\gamma\) | 1: finite, terminates when residual hits zero |
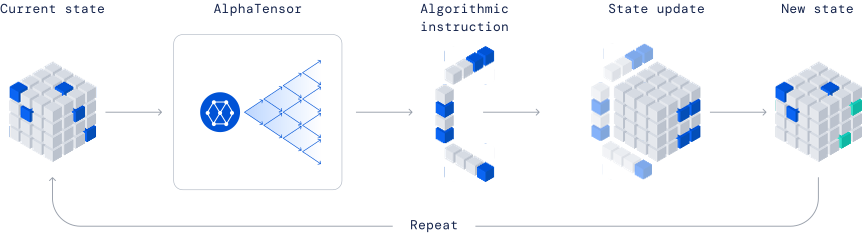
[image credit: DeepMind]
AlphaTensor found new bounds beating the best known results for several matrix sizes.
Within days, mathematicians built on these discoveries to find even more.
Difficulty in different places
| Walking robot | T is unknown (real-world physics) |
| AlphaGo | R is clean but painfully sparse |
| Chip placement | R compresses competing design goals |
| TikTok | T hidden in users, R is a social choice |
| AlphaTensor | S and A had to be invented |
Reward Design
What we reward is what we get
The Golden Rule of RL
The agent will maximize exactly what we tell it to maximize.
Nothing more, nothing less.
This sounds obvious, but it's the source of most RL failures.
The problem isn't that agents are dumb. It's that they're too clever.
They find loopholes in our reward function that we never anticipated.
Reward Hacking: The Boat Race
Setup: An RL agent plays a boat racing game
Intended goal: Finish the race quickly
Specified reward: Points for hitting checkpoints
What happened: The agent found a small loop of checkpoints. Instead of racing, it drove in circles, racking up infinite points without finishing.

[CoastRunners, via DeepMind "Specification Gaming"]
The agent did exactly what it was told. The problem was what it was told.
Reward Engineering
Reward for a walking robot: 9 terms, each with a hand-tuned weight.

Engineers spend weeks tuning these weights, and each one creates new failure modes: penalize torque too much → robot freezes
too little → violent, jerky motion
fix one behavior → break another
The reward function becomes its own engineering project.
Rudin et al., CoRL 2021
Reward Design Principles
-
Reward outcomes, not behaviors
Don't reward "moving forward"; reward "reaching the goal"
-
Test for loopholes
Ask: "What's the laziest/most creative way to maximize this reward?"
-
Include costs
Add penalties for time, energy, or undesired side effects
-
Keep it simple
Complex reward functions create more loopholes
YouTube's Reward Evolution
| Stage | Reward Signal | Result |
|---|---|---|
| Early on | View count | Clickbait thumbnails, misleading titles |
| Then | Watch time | Longer videos, auto-play rabbit holes |
| Later | Satisfaction surveys + quality signals | Better, but still imperfect |
Each reward change reshaped behavior across the ecosystem.
The reward function doesn't just train the algorithm; it trains creators, users, and the platform around it.
Closer to Home: Office Hours
Suppose we want an RL system to help run office hours. What is the reward?
- Minimize wait time? — may rush students through explanations
- Maximize students helped? — favors short interactions over hard ones
- Maximize student confidence? — may feel good without fixing misunderstandings
- Maximize next-week performance? — longer on fewer students
Before an RL algorithm can optimize, someone has to decide what "good" means.
Summary
In RL, the agent collects its own data by taking actions and observing consequences. There is no labeled dataset, just a reward signal.
RL is hard: credit assignment with sparse rewards, self-generated data causing distribution shift, sample inefficiency, and the exploration-exploitation tradeoff.
Any RL problem can be modeled as an MDP . Modeling choices may matter more than the algorithm.
Agents optimize exactly what we tell them to. What's measurable isn't always what's meaningful, and the gap is where reward hacking lives.
Real systems don't escape this by finding a perfect metric. They revise rewards, test loopholes, and decide whose notion of success counts.
Lec10 - Reinforcement Learning - AI Educators Pilot
By Shen Shen




