
What is Hadoop?
- Open-source programming framework
- Distributed storage
- Processing of large amounts of data on commodity hardware
Why Hadoop?
- Store and manage large amount of data efficiently
- Process this data to obtain meaningful information
- Allow the system to scale for future expansion
Hadoop Architecture
- Hadoop framework is built using Java,
but can support many different languages through the use of plugins
because of its modular architecture
- Is designed to run on multiple machines,
each with its own memory, storage and processing power
- When data is loaded into Hadoop, the framework divides that data into multiple pieces,
they are spread and replicated across the available machines
Hadoop Architecture
- To run a job on the data, each piece of the data is processed individually on the machine it is stored on
instead of retrieving, combining and working on a single large dataset.
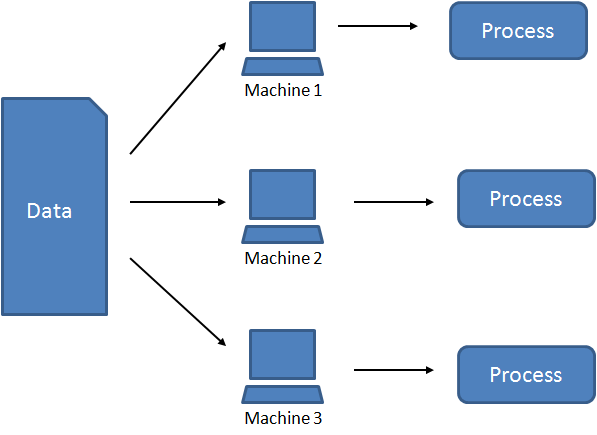
- This provides parallel processing of the data thus it reducing the time required to generate output
Component of Hadoop
Clients
Masters
Slaves
Component of Hadoop
Clients

- Clients are users of the Hadoop system and submit data/jobs and retrieve the output once a job completes
Component of Hadoop
Masters
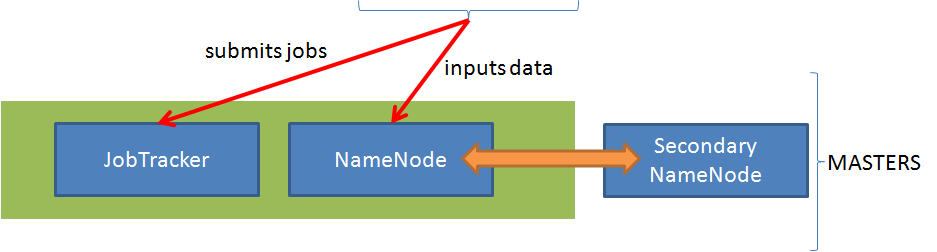
- Masters consists of the machines (servers) themselves and are sometimes called NameNodes or JobTrackers
- A secondary NameNode is always recommended to provide for disaster recovery.
Component of Hadoop
Slaves
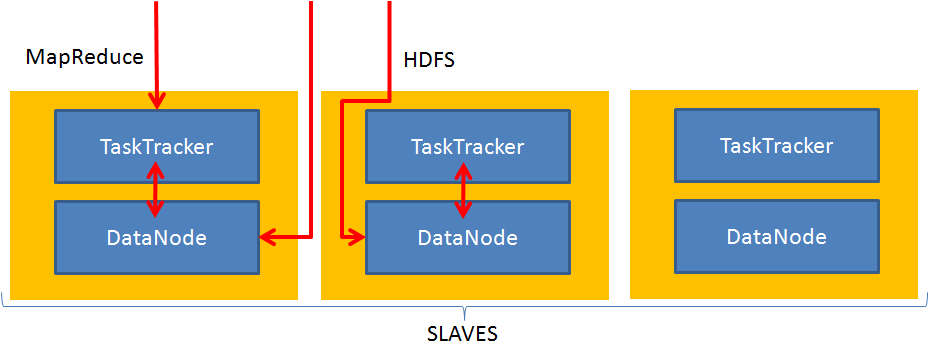
-
Slaves perform the actual storage and processing of data
-
Sometimes called DataNodes or TaskTrackers
-
Multiple DataNodes will provide for better parallel processing power
What is HDFS?
- Hadoop Distributed File System
- A Java-based file system
- provides scalable and reliable data storage
- designed to span large clusters of commodity servers.
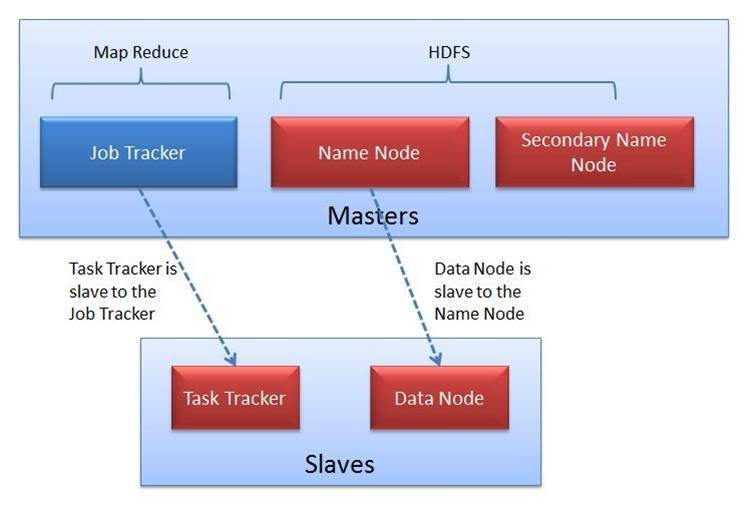
HDFS Architecture
- a master/slave architecture
- with NameNodes as masters and DataNodes as slaves
What does the NameNode do?
- manages the file system namespace and regulates access to files by clients
- keeps track of the file metadata:
- Which portion of a file is saved in which part of the cluster
- Last access time for files
- Access control lists
What does the secondary NameNode do?
- works almost like a backup to the main NameNode but it is NOT a backup
- It does NOT mirror the content of the main NameNode
- acts as a checkpoint node that updates the running instance from the main NameNode
- so that in failure, the corrections are faster
What does the DataNode do?
- responsible for serving read and write request from clients
- perform block creation, deletion and replication based upon instruction from a NameNode
- run the task tracker to receives job instructions from masters
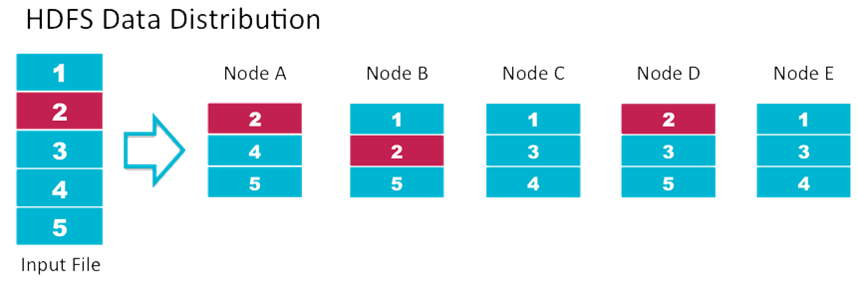
How HDFS store data?
- NameNode decides which DataNode the blocks will be stored in
- NameNode is also responsible to perform replication of the blocks
How are failures detected?
- Every DataNode sends a periodic message to the NameNode. For example: a heartbeat
- Upon loss of recent heartbeats, a NameNode may decide that a DataNode is dead
- No futher I/O requests will be send to the dead DataNode
- Affected blocks lost on the dead DataNode will be replicated again on other available DataNodes
Thank you
Please take out your phone and open Kahoot.
Let's play!
Hadoop
By shirlin1028




