From
Style Transfer
to
Text-Driven Image Manipulation

湯沂達
台灣人工智慧學校技術處
2021/12/10
Replay

講者




湯沂達
Email
changethewhat@gmail.com / yidar@aiacademy.tw

Did you see these?
(A) https://nightcafe.studio/blogs/blog/top-20-ai-generated-artworks
(B) https://twitter.com/CitizenPlain/status/1316760510709338112/photo/1
(C)https://www.ettoday.net/news/20210616/2007703.htm
(D) https://github.com/orpatashnik/StyleCLIP


<= only with
text & input



A
C
B
D
Content
- Style Transfer
- GAN & StyleGAN
- Image Manipulation with StyleGAN
- Text Driven Image Manipulation/Generation
- Related Topics
- Applications/Resource List
- Paper List
This Talk
Spirit of some famous methods
Prerequisite
- Mean / Std
- Convolution & Activation
- Loss Function
- Gradient Descent
This Talk
Spirit of some famous methods
Warning
The following pages have some math equations.
However, I will explain them from the idea of the algorithms, not from the equations.
Style Transfer
Before Style Transfer

How to summarize texture?
https://paperswithcode.com/dataset/psu-near-regular-texture-database
Before Style Transfer
How to summarize texture?
Define some handmade feature representation
like color, gradient, frequency...
Then use statistics
Image => Feature Extract => Summarize => Distance
https://paperswithcode.com/dataset/psu-near-regular-texture-database
How to summarize texture?
Image
Feature
Extract
Summarize
Distance
Distance measure for vector/distribution
Manjunath , B. S., & Ma, W. Y. (1996). Texture features for browsing and retrieval of image data. pattern analysis and machine intelligence , 18 (8), 837IEEE Transactions on 52 842.
Ojala, Timo, Matti Pietikainen, and Topi Maenpaa. "Multiresolution gray-scale and rotation invariant texture classification with local binary patterns." IEEE Transactions on pattern analysis and machine intelligence 24.7 (2002): 971-987.
How to summarize texture?
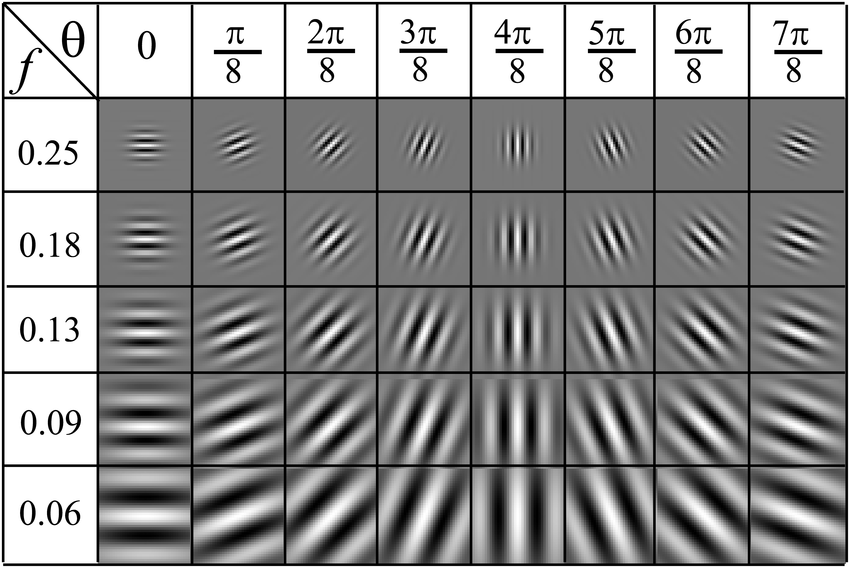
Gabor Filter Bank
\( (H, W, 1) \rightarrow (H, W, f \cdot \theta)\)
Image
Feature
Extract
Summarize
Distance
use \(\mu, \sigma\)
\( (H, W, f \cdot \theta) \rightarrow (2\cdot f \cdot \theta)\)
Distance measure for vector/distribution
Manjunath , B. S., & Ma, W. Y. (1996). Texture features for browsing and retrieval of image data. pattern analysis and machine intelligence , 18 (8), 837IEEE Transactions on 52 842.
Ojala, Timo, Matti Pietikainen, and Topi Maenpaa. "Multiresolution gray-scale and rotation invariant texture classification with local binary patterns." IEEE Transactions on pattern analysis and machine intelligence 24.7 (2002): 971-987.
How to summarize texture?
Gabor Filter Bank
\( (H, W, 1) \rightarrow (H, W, f \cdot \theta)\)
Image
Feature
Extract
Summarize
Distance

use \(\mu, \sigma\)
\( (H, W, f \cdot \theta) \rightarrow (2\cdot f \cdot \theta)\)
Use Histogram
\( (H, W, 1)_{\in \{0,1,...,9\}} \rightarrow\)
Distance measure for vector/distribution
Manjunath , B. S., & Ma, W. Y. (1996). Texture features for browsing and retrieval of image data. pattern analysis and machine intelligence , 18 (8), 837IEEE Transactions on 52 842.
Ojala, Timo, Matti Pietikainen, and Topi Maenpaa. "Multiresolution gray-scale and rotation invariant texture classification with local binary patterns." IEEE Transactions on pattern analysis and machine intelligence 24.7 (2002): 971-987.
9
Rotation Invariant Local Binary Pattern
\( (H, W, 1)_{\in \{0,1,...,255\}} \rightarrow (H, W, 1)_{\in \{0,1,...,9\}}\)
How to summarize texture?
Gabor Filter Bank
\( (H, W, 1) \rightarrow (H, W, f \cdot \theta)\)
Image
Feature
Extract
Summarize
Distance
use \(\mu, \sigma\)
\( (H, W, f \cdot \theta) \rightarrow (2\cdot f \cdot \theta)\)
Use Histogram
\( (H, W, 1)_{\in \{0,1,...,9\}} \rightarrow\)
Distance measure for vector/distribution
Manjunath , B. S., & Ma, W. Y. (1996). Texture features for browsing and retrieval of image data. pattern analysis and machine intelligence , 18 (8), 837IEEE Transactions on 52 842.
Ojala, Timo, Matti Pietikainen, and Topi Maenpaa. "Multiresolution gray-scale and rotation invariant texture classification with local binary patterns." IEEE Transactions on pattern analysis and machine intelligence 24.7 (2002): 971-987.
9
<
\(\geq\)
Thresholding
Rotation Invariant Local Binary Pattern
\( (H, W, 1)_{\in \{0,1,...,255\}} \rightarrow (H, W, 1)_{\in \{0,1,...,9\}}\)
11000000
How to summarize texture?
Gabor Filter Bank
\( (H, W, 1) \rightarrow (H, W, f \cdot \theta)\)
Rotation Invariant Local Binary Pattern
\( (H, W, 1)_{\in \{0,1,...,255\}} \rightarrow (H, W, 1)_{\in \{0,1,...,9\}}\)
Image
Feature
Extract
Summarize
Distance
use \(\mu, \sigma\)
\( (H, W, f \cdot \theta) \rightarrow (2\cdot f \cdot \theta)\)
Use Histogram
\( (H, W, 1)_{\in \{0,1,...,9\}} \rightarrow\)
Distance measure for vector/distribution
Manjunath , B. S., & Ma, W. Y. (1996). Texture features for browsing and retrieval of image data. pattern analysis and machine intelligence , 18 (8), 837IEEE Transactions on 52 842.
Ojala, Timo, Matti Pietikainen, and Topi Maenpaa. "Multiresolution gray-scale and rotation invariant texture classification with local binary patterns." IEEE Transactions on pattern analysis and machine intelligence 24.7 (2002): 971-987.
9
rotation invariant
<
\(\geq\)
Thresholding
<
>
How to summarize data?
Data
Feature
Extract
Describe
Distance
If we have good feature extractor...


Distance measure for vector/distribution
Describe data w/ or w/o statistic...
A Cute Dog Staring You
Feature
Extract
Distance
If we have good feature extractor...
- Use Other Task's Pretrained Weight
- Create It By Yourself
Distance measure for vector/distribution
Describe
Describe data w/ or w/o statistic...
A Cute Dog Staring You
How to summarize data?
Data
Style Transfer
Lin, Tianwei, et al. "Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer." arXiv preprint arXiv:2104.05376 (2021).

Content
Style
Styllized
Objective
Find a stylized image, which has
- Content image's content
- Style image's style
Style Transfer
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017).
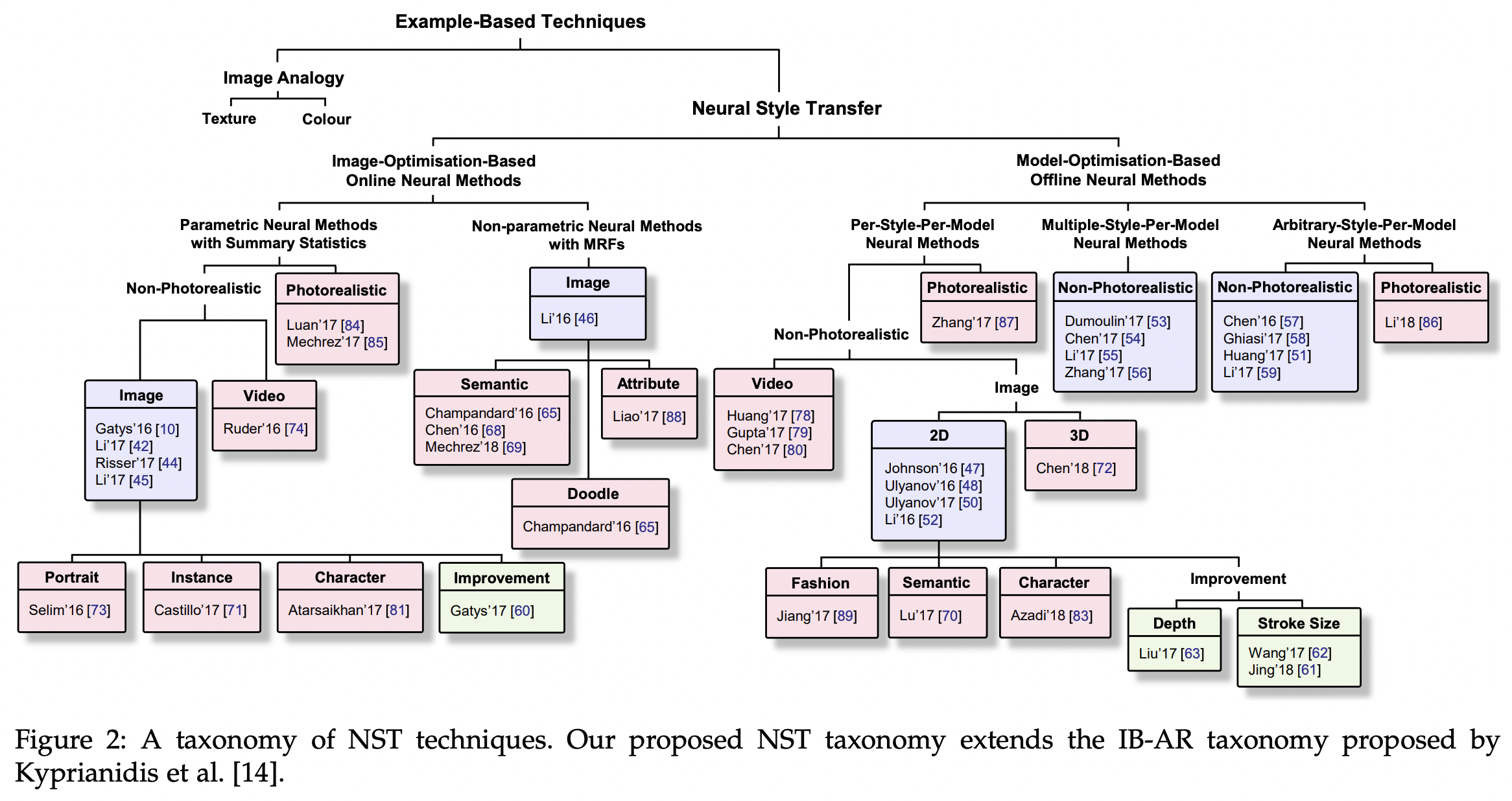
Style Transfer
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017).
Style Transfer
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017).
Style Transfer
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017).
- Image Optimization (Inference \(\equiv\) train:minutes)
Find an image - Model Optimization (Inference:real time; Train:hours)
Find a model can transfer image- Per-Style-Per-Model (PSPM)
Model contain 1 style - Multiple-Style-Per-Model (MSPM)
Model contain n style - Arbitrary-Style-Per-Model (ASPM)
Model contain any style
- Per-Style-Per-Model (PSPM)
Style Transfer
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017).
- Image Optimization (Inference \(\equiv\) train:minutes)
Find an image - Model Optimization (Inference:real time; Train:hours)
Find a model can transfer image- Per-Style-Per-Model (PSPM)
Model contain 1 style - Multiple-Style-Per-Model (MSPM)
Model contain n style - Arbitrary-Style-Per-Model (ASPM)
Model contain any style
- Per-Style-Per-Model (PSPM)
Style Transfer
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017).
- Image Optimization (Inference \(\equiv\) train:minutes)
Find an image - Model Optimization (Inference:real time; Train:hours)
Find a model can transfer image- Per-Style-Per-Model (PSPM)
1 style - Multiple-Style-Per-Model (MSPM)
n styles - Arbitrary-Style-Per-Model (ASPM)
any style
- Per-Style-Per-Model (PSPM)
Image style transfer using convolutional neural networks
Notes
- Arxiv : 1508.06576
- First paper for "Neural" Style Transfer
- Get the result by optimize the image
- Plenty of later papers use their loss function
- Cost minutes to generate an image
- Cited by 3267 at 2021 Nov
Feature
Extract
Distance
If we have good feature extractor...
- Use Other Task's Pretrained Weight
- Create It By Yourself
Distance measure for vector/distribution
Describe
Describe data w/ or w/o statistic...
A Cute Dog Staring You
Data


VGG
(A Pretrained Model)
\(\mathcal{L}_{content}\) : Feature tensor close to content image's feature tensor
\(\mathcal{L}_{style}\) : Stat(feature) close to style image's stat(feature)
\(\mathcal{L}_{total} = \mathcal{L}_{content} + \lambda \mathcal{L}_{style}\)
\(\hat{I}\)
VGG
(A Pretrained Model)
\(\mathcal{L}_{content}\)=( - )\(^2\)
\(\mathcal{L}_{content}\) : Feature tensor close to content image's feature tensor
\(\mathcal{L}_{style}\) : Stat(feature) close to style image's stat(feature)
\(\mathcal{L}_{total} = \mathcal{L}_{content} + \lambda \mathcal{L}_{style}\)
\(\hat{I}\)
\(\hat{I}\)
VGG
(A Pretrained Model)
\(\mathcal{L}_{style}\)=(G( )-G( ))\(^2\)
\(\mathcal{L}_{content}\)=( - )\(^2\)
\(\mathcal{L}_{content}\) : Feature tensor close to content image's feature tensor
\(\mathcal{L}_{style}\) : Stat(feature) close to style image's stat(feature)
\(\mathcal{L}_{total} = \mathcal{L}_{content} + \lambda \mathcal{L}_{style}\)
\(\hat{I}\)
VGG
(A Pretrained Model)
\(\mathcal{L}_{style}\)=(G( )-G( ))\(^2\)
\(\mathcal{L}_{content}\)=( - )\(^2\)
\(\mathcal{L}_{content}\) : Feature tensor close to content image's feature tensor
\(\mathcal{L}_{style}\) : Stat(feature) close to style image's stat(feature)
\(\mathcal{L}_{total} = \mathcal{L}_{content} + \lambda \mathcal{L}_{style}\)
result \(\leftarrow argmin_{\color{red}\hat{I}}\mathcal{L}_{total}({\color{red}\hat{I}})\)
\(\hat{I}\)
VGG
(A Pretrained Model)
\(\mathcal{L}_{style}\)=(G( )-G( ))\(^2\)
\(\mathcal{L}_{content}\)=( - )\(^2\)
\(\mathcal{L}_{content}\) : Feature tensor close to content image's feature tensor
\(\mathcal{L}_{style}\) : Stat(feature) close to style image's stat(feature)
\(\mathcal{L}_{total} = \mathcal{L}_{content} + \lambda \mathcal{L}_{style}\)
result \(\leftarrow argmin_{\color{red}\hat{I}}\mathcal{L}_{total}({\color{red}\hat{I}})\)
$$\hat{I} = \hat{I} - \alpha\frac{\partial \mathcal{L}_{total}}{\partial \hat{I}}$$
\(\hat{I}\)
VGG
(A Pretrained Model)
\(\mathcal{L}_{style}\)=(G( )-G( ))\(^2\)
\(\mathcal{L}_{content}\)=( - )\(^2\)
\(\mathcal{L}_{content}\) : Feature tensor close to content image's feature tensor
\(\mathcal{L}_{style}\) : Stat(feature) close to style image's stat(feature)
\(\mathcal{L}_{total} = \mathcal{L}_{content} + \lambda \mathcal{L}_{style}\)
$$F \in R^{C \times X \times Y}, G(F) \in R^{C \times C}$$
$$G(F)_{c1, c2} = \frac{1}{X\cdot Y}\sum_{x, y}[F_{c1,x,y} \cdot F_{c2,x,y}]$$
\(G\) : gram matrix
result \(\leftarrow argmin_{\color{red}\hat{I}}\mathcal{L}_{total}({\color{red}\hat{I}})\)
$$\hat{I} = \hat{I} - \alpha\frac{\partial \mathcal{L}_{total}}{\partial \hat{I}}$$
Get more abstract result while use deeper layer for content loss


Their Result
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. “Perceptual Losses for Real-Time Style Transfer and Super-Resolution.” arXiv preprint arXiv:1603.08155 (2016).
Notes
- Arxiv : 1603.08155
- Get the result by optimize a model
- Thier research has 2 branch :
- style transfer
- super resolution
- Plenty of later papers use the term "Perceptual"
- Per-Style-Per-Model(PSPM)
- Real time while inference
- Cited by 5962 at 2021 Nov
\(\hat{I}\)
Perceptual
\(\hat{I}\)
prev : \(argmin_{{\color{red}\hat{I}}}\mathcal{L}_{total}({\color{red}\hat{I}})\)
Perceptual
\(f_W({\color{blue}I})\)
Model \(f_W\)
prev : \(argmin_{{\color{red}\hat{I}}}\mathcal{L}_{total}({\color{red}\hat{I}})\)
this: \(argmin_{f_W}\sum_{{\color{blue}I}\in dataset}\mathcal{L}_{total}(f_W({\color{blue}I}))\)
A learned representation for artistic style
Notes
- Arxiv : 1610.07629
- Get the result by optimizing a model
- Multiple-Style-Per-Model (MSPM)
- Use conditional instance normalization(CIN) for multiple style transfer
- The standard setting contain 32 styles, each style contain about 0.2% total parameters.
- Real time while inference
- Cited by 727 at 2021 Nov
Before A Learned Representation For Artistic Style

Color Distrbution Matching
Source
Stat(R)
Stat(G)
Stat(B)
Target
Stat(R)
Stat(G)
Stat(B)
Before A Learned Representation For Artistic Style
Color Distrbution Matching
Before A Learned Representation For Artistic Style
Color Distrbution Matching
Target
Stat(R)
Stat(G)
Stat(B)
Normalize
(\(\mu=0, \sigma=1\))
(\(\mu=0, \sigma=1\))
(\(\mu=0, \sigma=1\))
Source
Stat(R)
Stat(G)
Stat(B)
A Learned Representation For Artistic Style
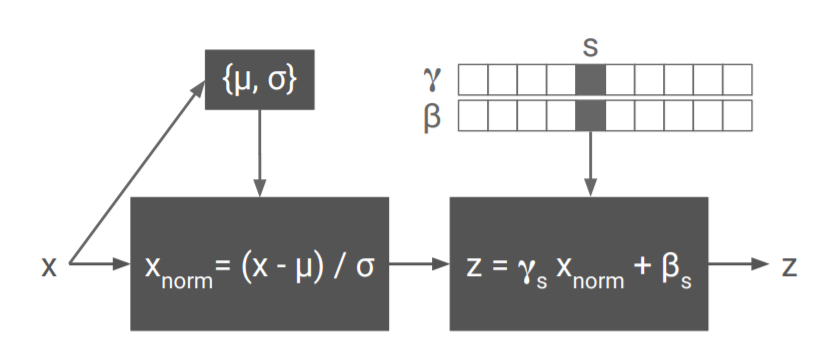
Each Style Use a \((\gamma, \beta)\) pair

Target
Stat(R)
Stat(G)
Stat(B)
Normalize
(\(\mu=0, \sigma=1\))
(\(\mu=0, \sigma=1\))
(\(\mu=0, \sigma=1\))
Source
Stat(R)
Stat(G)
Stat(B)
\(f_W({\color{blue}I})\)
Model \(f_W\)
prev
Conv
\(n \times \)
Act
Conv
\(n \times \)
Act
\(f_W({\color{blue}I})\)
Model \(f_W\)
prev
Conv
\(n \times \)
Act
This
\(S_2\)
\(S_1\)
Interpolate
\(S\) =
\(\alpha S_1+(1-\alpha)S_2\)
\(S_2\)
\(S_1\)
Interpolate
\(S_3\)
\(S_4\)
Exploring the structure of a real-time, arbitrary neural artistic stylization network
Notes
- Arxiv : 1705.06830
- Get the result by optimizing a model
- Arbitrary-Style-Per-Model (ASPM)
- It generalized CIN for adaptive to arbitrary Style
- Real time to generate an image with gpu
- Cited by 180 at 2021 Nov
Prev Work
Style Prediction Network
This Work


Architecture
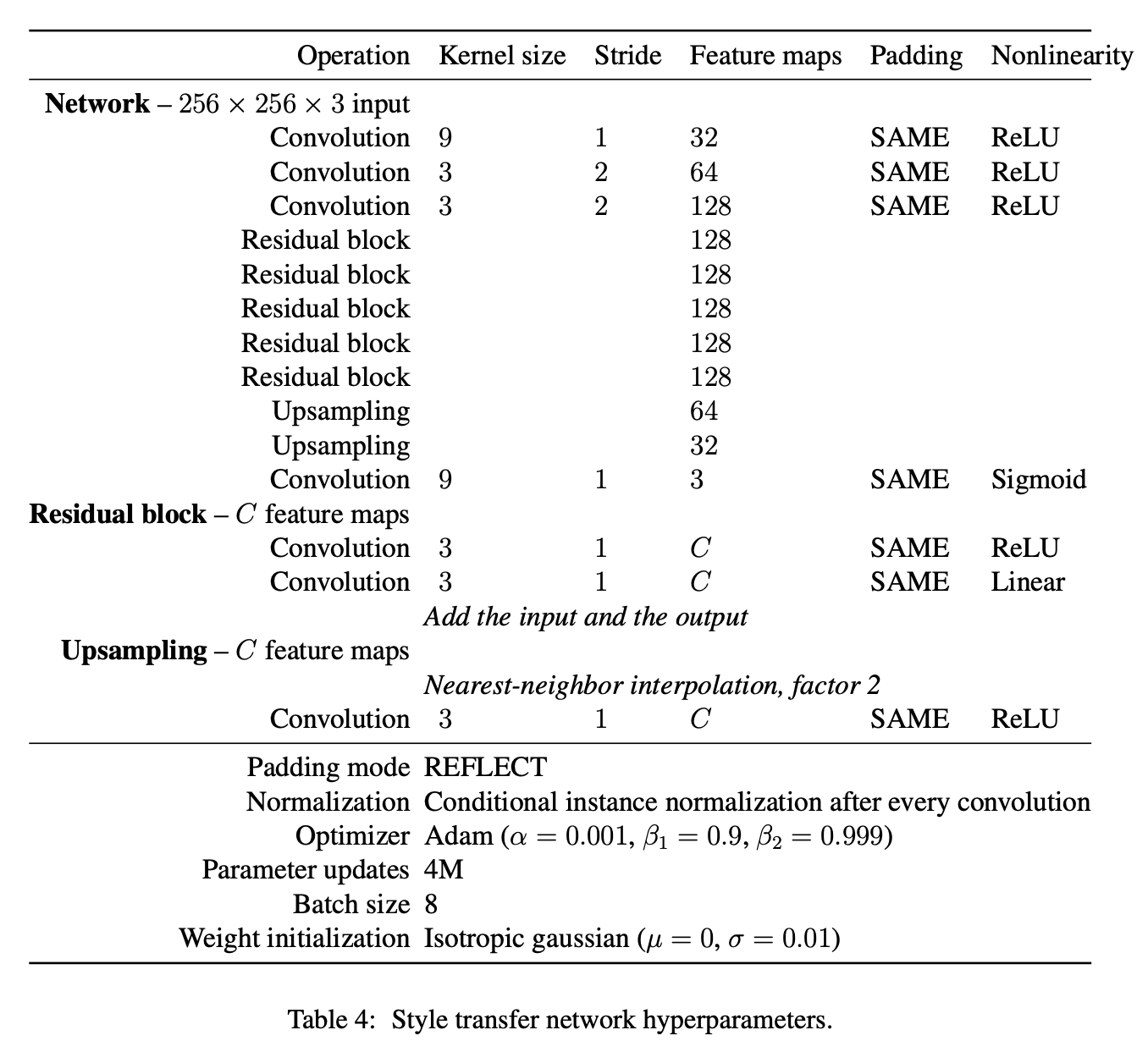
Small Recap
Papers:
- 1508.06576 Image Optimization
- 1603.08155 Per-Style-Per-Model (PSPM)
- 1610.07629 Multiple-Style-Per-Model (MSPM)
- 1705.06830 Arbitrary-Style-Per-Model (ASPM)
About half year a big improve
Small Recap
Papers:
- 1508.06576 Image Optimization
- 1603.08155 Per-Style-Per-Model (PSPM)
- 1610.07629 Multiple-Style-Per-Model (MSPM)
- 1705.06830 Arbitrary-Style-Per-Model (ASPM)
About half year a big improve
Not Enough?
(Methods up to March 2018, Cited by 335 at Nov 2021)
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017).
My Medium
類神經影像藝術風格轉換系列筆記-基礎
GAN & StyleGAN
StyleGAN

Why Named StyleGAN?
Karras, Tero, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks." arXiv preprint arXiv:1812.04948 (2018).
GAN
Data
Feature
Extract
Distance
If we have good feature extractor...
- Use Other Task's Pretrained Weight
- Create It By Yourself
Distance measure for vector/distribution
Describe
Describe data w/ or w/o statistic...
A Man With Curly Hair
GAN & StyleGAN
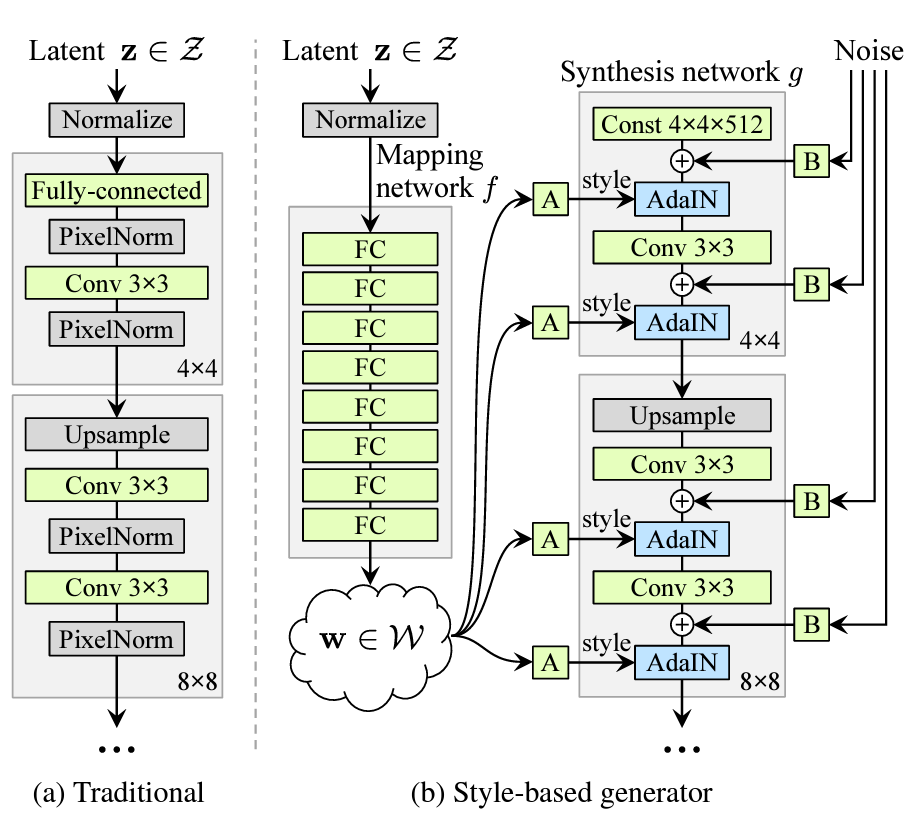
GAN & StyleGAN
Notes :
- Input for conv is a constant tensor
- Apply AdaIN
- Add random noise while inference & training
(stochastic items: hair, freckles, skin pores)
StyleGAN

\(w \in \mathcal{W}\)
StyleMixing
Interpolate
1:10~2:07
StyleGAN
Cost
StyleGAN

Solve Artifact (00:30~1:30)
StyleGAN2
Solve Interpoloate Artifact
StyleGAN3
Tero Karras

Un-Official Forest

Image Manipulation with StyleGAN
Image Manipulation with StyleGAN
Methods shamelessly taken from this video
Image Manipulation with StyleGAN
Warning: We skip a lot
Warning: We skip a lot
Warning: We skip a lot
Data
Feature
Extract
Distance
If we have good feature extractor...
- Use Other Task's Pretrained Weight
- Create It By Yourself
Distance measure for vector/distribution
Describe
Describe data w/ or w/o statistic...
A Man With Curly Hair
Image Manipulation with StyleGAN
Modify
pretrained weight / hidden output
with smart measure
Specific
Image Manipulation with StyleGAN
Contents
- GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
Add/Remove semantic of GAN's output - Semantic Photo Manipulation with a Generative Image Prior
Edit Your Own Photo - Rewriting a Deep Generative Model
Edit The Generative Model(like roof=> tree)
Image Manipulation with StyleGAN
Contents
- GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
Add/Remove semantic of GAN's output - Semantic Photo Manipulation with a Generative Image Prior
Edit Your Own Photo - Rewriting a Deep Generative Model
Edit The Generative Model (like roof=> tree)
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks


Image generated by GAN
Output by zeroing some activation

Step 1 : Which hidden channels have high correlation to segmentation map?
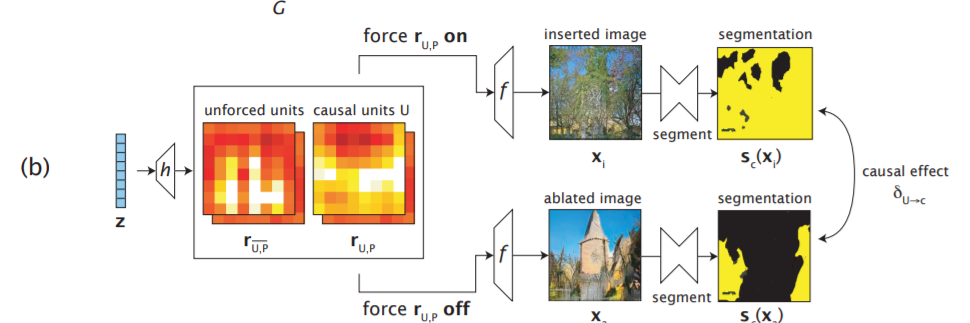
Step 1 : Which hidden channels have high correlation to segmentation map?
Step 2 : Edit these channels (to constant, to 0)
Notes
It need segment model or manual label
Step 1 : Which hidden channels have high correlation to segmentation map?
Step 2 : Edit these channels (to constant, to 0)
Official GIFs

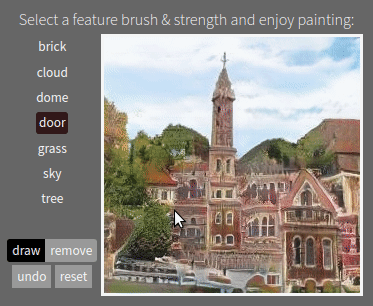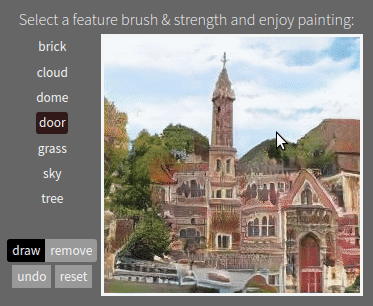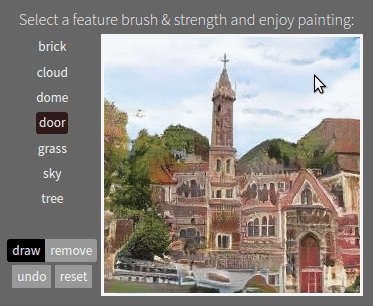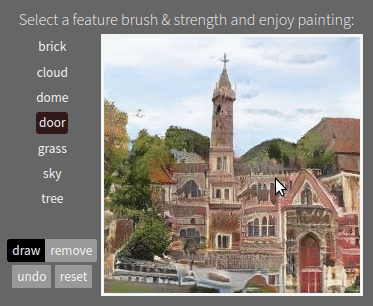

Semantic Photo Manipulation with a Generative Image Prior
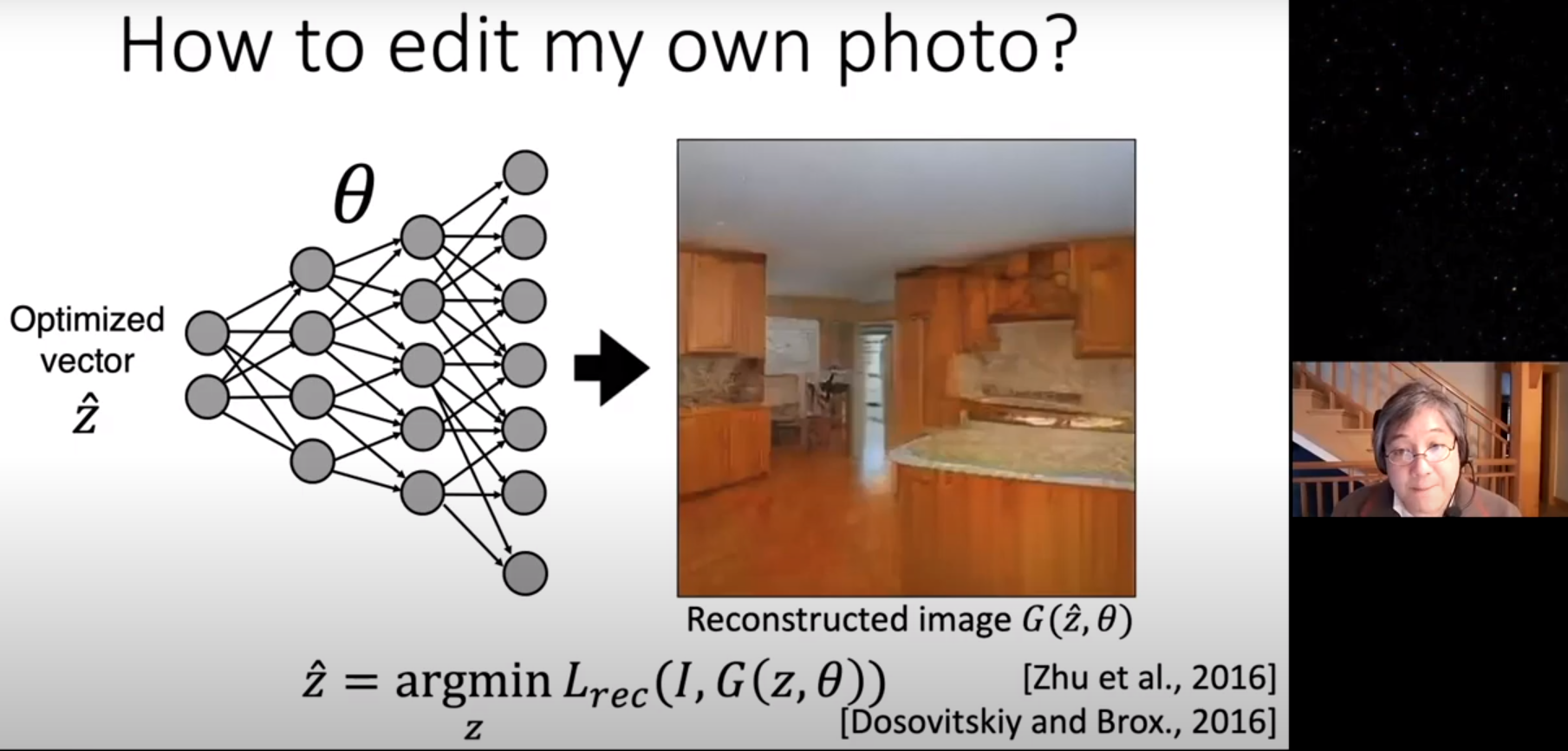

Find best matching latents in GAN.
Bad result :(
Find best matching latents in GAN
Allow slight weight modification
Nice :)
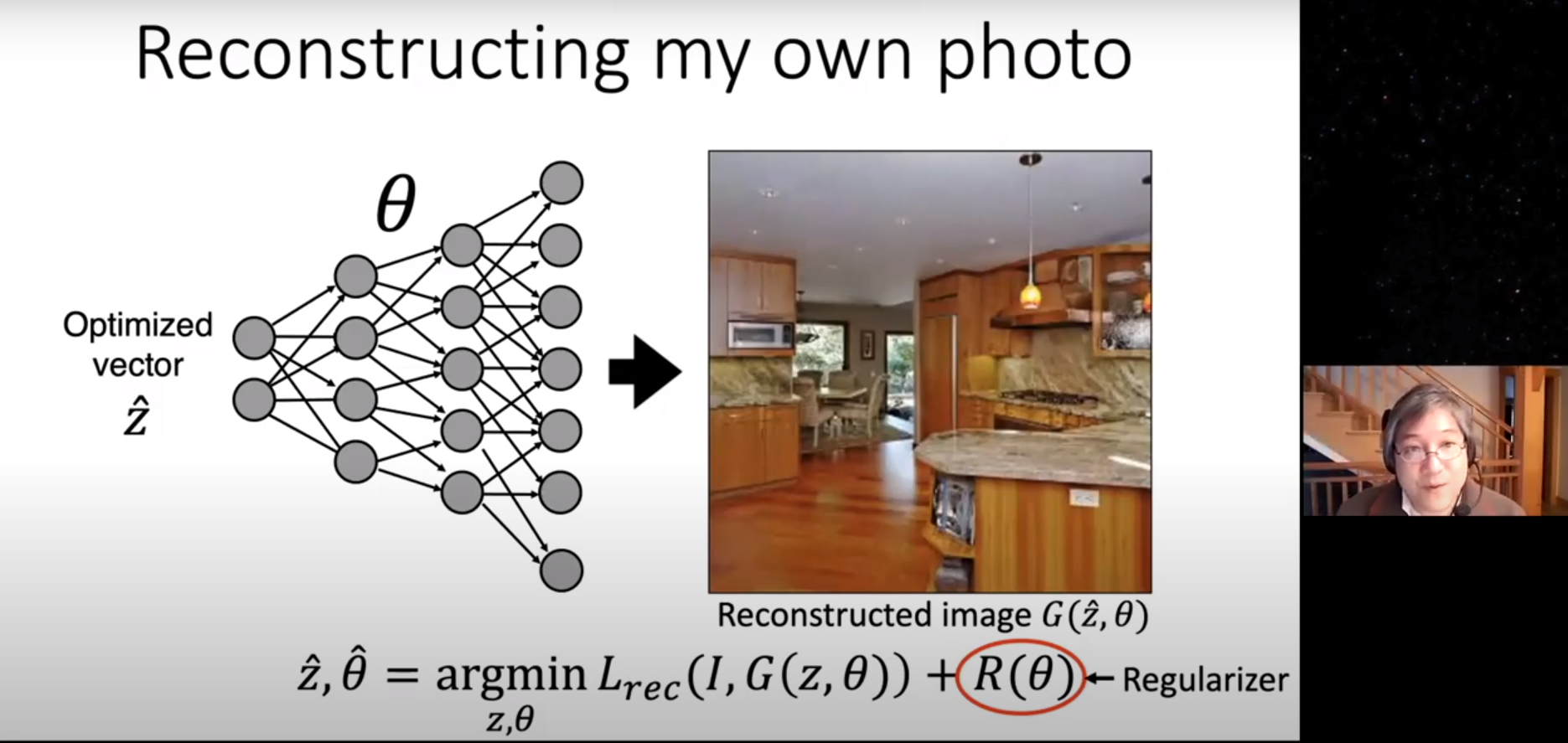

Use previous work's editing skill
00:27~00:55

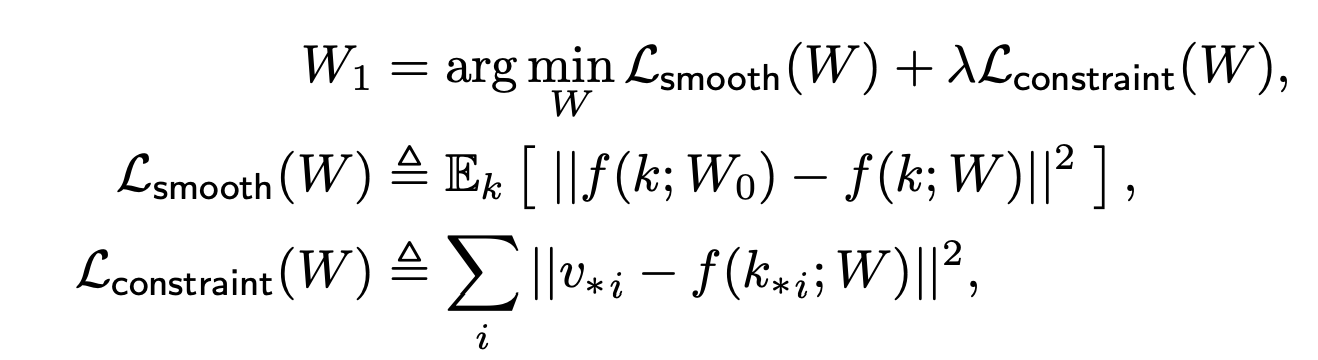
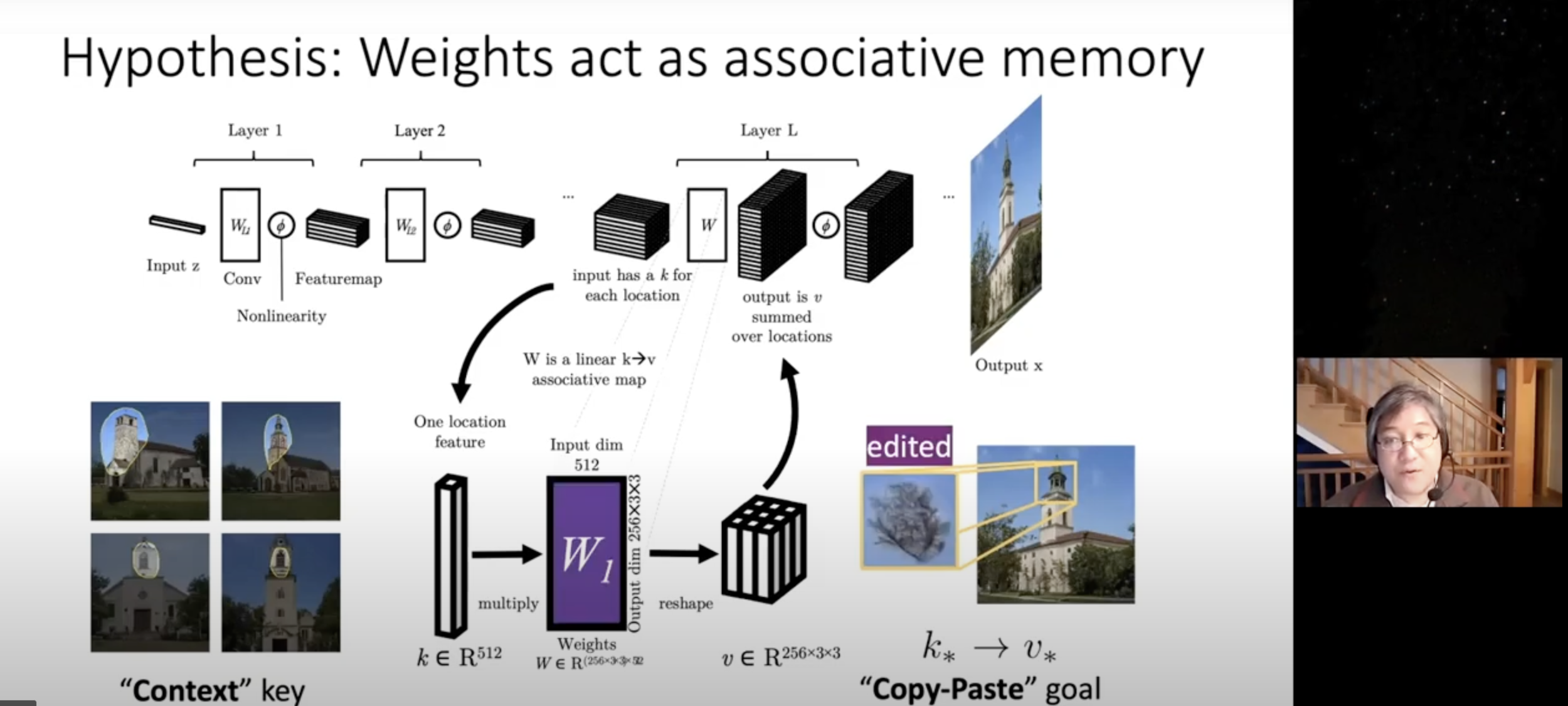
\(W\) : weight of layer \(L \)
\(k\) : normal input at layer \(L\)
\(k_*\) : selected input at layer \(L\)
\(v_*\): desired output for \(k_*\) at layer \(L\)
normal output should not change
change source to target
go "Example Results"
Text Driven Image Manipulation/Generation
- OpenAI : CLIP
- StyleCLIP
- CLIPDraw & StyleCLIPDraw
- My Method : StyleTransferCLIP
- OpenAI : Dall E
Contents
CLIP
Connecting Text and Images
Radford, Alec, et al. "Learning transferable visual models from natural language supervision." arXiv preprint arXiv:2103.00020 (2021).
dog
cat
hen
bee
Traditional Classification
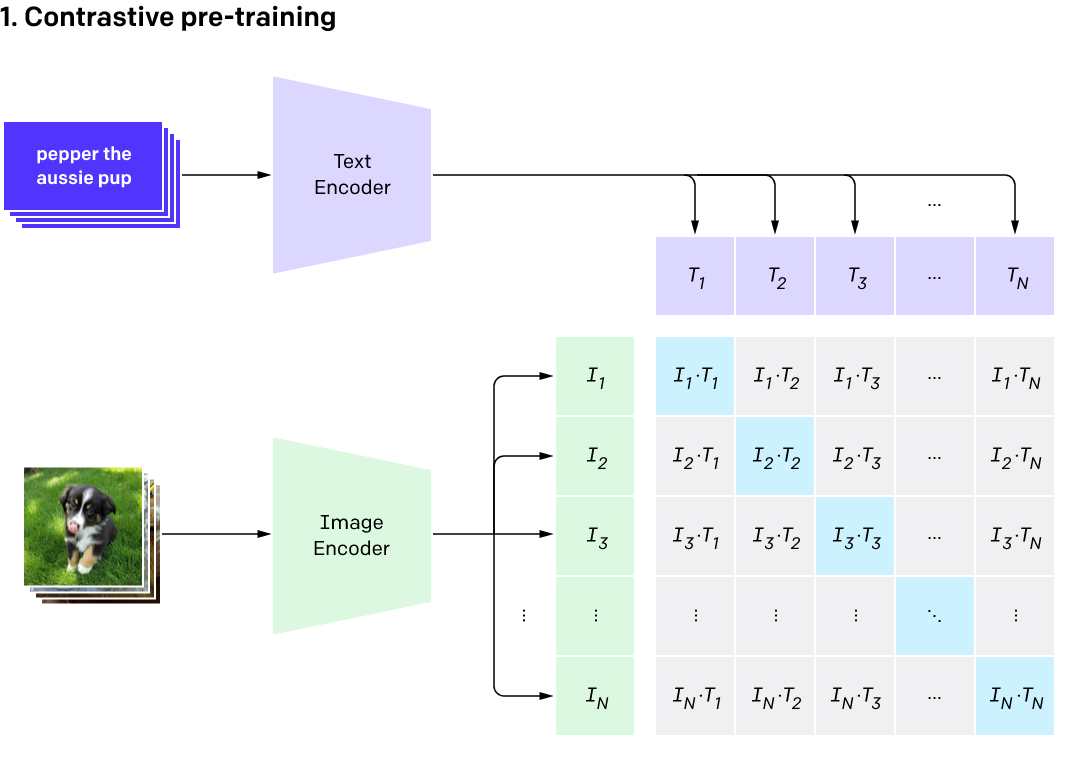
CLIP
Connecting Text and Images
Radford, Alec, et al. "Learning transferable visual models from natural language supervision." arXiv preprint arXiv:2103.00020 (2021).
CLIP (Contrastive Language–Image Pre-training)
dog
cat
hen
bee
Traditional Classification

# https://github.com/openai/CLIP#usage
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]

StyleCLIP


StyleCLIPDraw
Image Manipulation/Generation with
1 Image, 1 Text
Use CLIP Encoder
\(-CLIP_{I}(img)\cdot CLIP_{T}(text)=\mathcal{L}_{CLIP}\)
"...."
2021 Sep 09
2021 Nov 12
StyleCLIP Author : A Newstar
2021 Dec 08
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery. (2021 Mar)
Patashnik, Or, et al. "StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery." arXiv e-prints (2021): arXiv-2103.
In Style Transfer/In StyleCLIP
- Image Optimization
Latent Optimization - Model Optimization
- Per-Style-Per-Model
Latent Mapper - Multiple-Style-Per-Model
No - Arbitrary-Style-Per-Model
Global Directions
- Per-Style-Per-Model
In Style Transfer/In StyleCLIP
- Image Optimization
Latent Optimization - Model Optimization
- Per-Style-Per-Model
Latent Mapper (skip) - Multiple-Style-Per-Model
No - Arbitrary-Style-Per-Model
Global Directions (skip)
- Per-Style-Per-Model
In Style Transfer/In StyleCLIP
- Image Optimization
Latent Optimization - Model Optimization
- Per-Style-Per-Model
Latent Mapper (skip) - Multiple-Style-Per-Model
No - Arbitrary-Style-Per-Model
Global Directions (skip)
- Per-Style-Per-Model


StyleCLIP(GAN Inv with e4e + official mapper)
\(w\)
"Curly Hair"
Genertate
Latent
StyleGan
(G)
\(w_s\)
StyleGan
Get reconstructed latent : \(w_s\)
Latent optimization
Face Regonition
Same Person?
\(\mathcal{L}_{ID}\)
Same Description?
\(\mathcal{L}_{CLIP}\)
\(\textcolor{red}{w^*} = argmin_{\color{red} w}\mathcal{L}_{CLIP}+\lambda_{L2}||\textcolor{red}{w}-w_s||_2 + \lambda_{ID}\mathcal{L}_{ID}\)
G(\(w\))
CLIPDraw (2021 Jun) & StyleCLIPDraw (2021 Nov)

\(\mathcal{L}_{total} = \mathcal{L}_{content}+ \beta\mathcal{L}_{style}\)
CLIPDraw : \(\beta = 0\)
StyleCLIPDraw : \(\beta > 0\)
Schaldenbrand, Peter, Zhixuan Liu, and Jean Oh. "StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis." arXiv preprint arXiv:2111.03133 (2021).
CLIPDraw (2021 Jun) & StyleCLIPDraw (2021 Nov)
In Style Transfer/CLIPDraw
- Image Optimization
Line Parameter Optimization - Model Optimization
- Per-Style-Per-Model
No - Multiple-Style-Per-Model
No - Arbitrary-Style-Per-Model
No
- Per-Style-Per-Model
Before CLIPDraw
Gradient decent from loss to curve's parameters is possible, i.e.
$$\frac{\partial \mathcal{L}}{\partial P_i}$$can be computed
Parameter for control points :
position, rgba, thickness
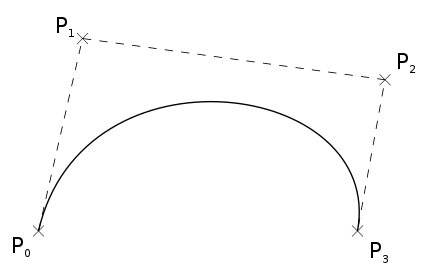
StyleCLIPDraw
If no Augmentation, the result is bad.

CLIPDraw Results

The Eiffel Tower


StyleCLIPDraw Results



My Method : StyleTransferCLIP
edit style embedding
\(E_{initial} = SP(S)\)
with \(\mathcal{L}_{CLIP}\)
Input Image
(C)
Style Image
(S)
Output Image
NST(C, \(E_{initial}\))
CLIP Result
Next pages

E
$$argmin_{\red E}(\mathcal{L}_{CLIP}(NST(C,{\red E}), Text))$$
clouds
starry night
colorful dots
honey
jewels
hentai
golf ball
pudding
My Experiment on Neural Style Transfer
clouds
starry night
colorful dots
honey
jewels
hentai
golf ball
pudding
My Experiment on Neural Style Transfer with Augmentation
You can play my method with replicate.ai

# https://github.com/huggingface/tokenizers
output = tokenizer.encode("Hello, y'all! How are you 😁 ?")
print(output.tokens)
# ["Hello", ",", "y", "'", "all", "!", "How", "are", "you", "[UNK]", "?"]
# string => tokens
# token => idx => embeddingTokenize text
# https://github.com/huggingface/tokenizers
output = tokenizer.encode("Hello, y'all! How are you 😁 ?")
print(output.tokens)
# ["Hello", ",", "y", "'", "all", "!", "How", "are", "you", "[UNK]", "?"]
# string => tokens
# token => idx => embeddingTokenize text
Autoregressive Model (Next token prediction)
$$P_{\theta}(\textbf{x})=\Pi_{i=1}^{n} P_{\theta}(x_i|x_1, x_2, \dots, x_{i-1})$$
# https://github.com/huggingface/tokenizers
output = tokenizer.encode("Hello, y'all! How are you 😁 ?")
print(output.tokens)
# ["Hello", ",", "y", "'", "all", "!", "How", "are", "you", "[UNK]", "?"]
# string => tokens
# token => idx => embeddingTokenize text
Autoregressive Model (Next token prediction)
$$P_{\theta}(\textbf{x})=\Pi_{i=1}^{n} P_{\theta}(x_i|x_1, x_2, \dots, x_{i-1})$$
\(P_{\theta}(\text{"sunny"}|\text{"The weather is"})\)
\(P_{\theta}(\text{"cookie"}|\text{"The weather is"})\)
\(P_{\theta}(\text{"furry"}|\text{"The weather is"})\)
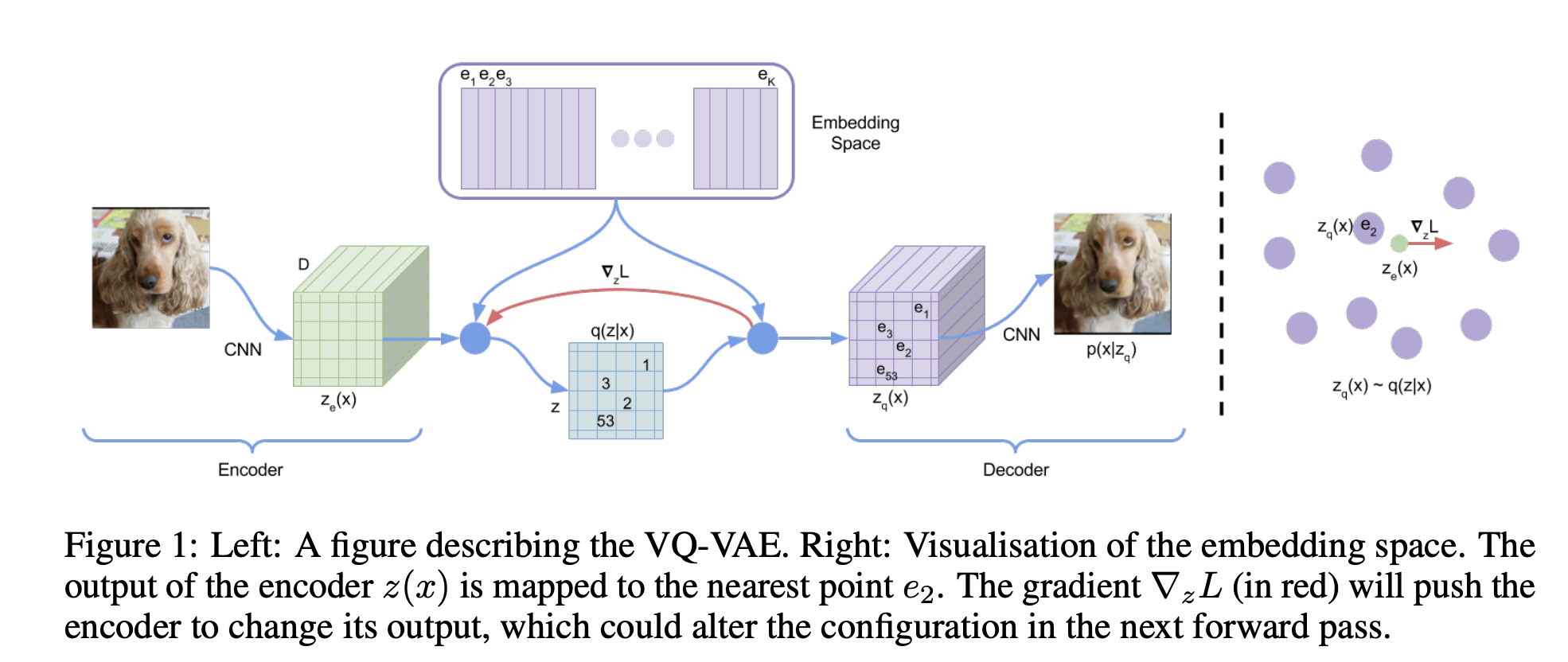
VQ-VAE can tokenize image to \(n \times n\) tokens
Image Tokenization
VQ-VAE can tokenize image to \(n \times n\) tokens
Autoregressive Model (Next token prediction)
$$P_{\theta}(\textbf{x})=\Pi_{i=1}^{n} P_{\theta}(x_i|x_1, x_2, \dots, x_{i-1})$$
Image Tokenization
Autoregressive Model (Next token prediction)
"a dog is watching you"
\(\color{green}x_{t_1}, x_{t_2}, \dots, x_{t_n}\)
\(\color{blue}x_{i_1}, x_{i_2}, \dots, x_{i_m}\)
$$P_{\theta}(\textbf{x})=\Pi_{i=1}^{n} P_{\theta}(x_i|x_1, x_2, \dots, x_{i-1})$$
Autoregressive Model (Next token prediction)
$$ P_{\theta}({\color{green} {x_t}}, {\color{blue}{x_i}}) = \Pi_{p=1}^{m}P_{\theta}({\color{blue}x_{i_p}}|{\color{green} x_{t_1}, x_{t_2}, \dots, x_{t_n}},{\color{blue} x_{i_1}, x_{i_2}, \dots, x_{i_p-1}})$$
Dall E
"a dog is watching you"
\(\color{green}x_{t_1}, x_{t_2}, \dots, x_{t_n}\)
\(\color{blue}x_{i_1}, x_{i_2}, \dots, x_{i_m}\)
$$P_{\theta}(\textbf{x})=\Pi_{i=1}^{n} P_{\theta}(x_i|x_1, x_2, \dots, x_{i-1})$$
Core Concept
- Image to image token with VQ-VAE
- Text to text token
- Concat them and make this become an next token prediction problem.
Sad Things
- 12-billion parameter
(\(\approx\) 2264 \(\times\) efficient-B0) - 250 milllion (image, text) pairs
(\(\approx\)18 \(\times\) ImageNet)
Core Concept
- Image to image token with VQ-VAE
- Text to text token
- Concat them and make this become an next token prediction problem.
An Explain
Not Enough?
Paper & Code

Not Enough?
Paper & Code
Takeaway
- Style Transfer
- Loss function
- Image Optimization
- Model Optimization
- CIN
- StyleGAN
- Borrow from style transfer
- Add noise
- Official Branch StyleGAN, StyleGAN2, StyleGAN-ADA, StyleGAN3
- Image Manipulation with StyleGAN
- Modify weight / activation with smart way
- Text Driven Image Manipulation/Genearation
- CLIP Method & CLIP Loss
- Dall E : Text & Image Next Token Prediction
Related Topics

2021 Jan

2021 Jan
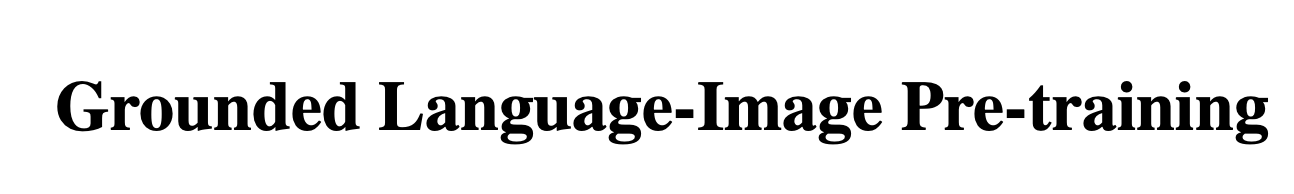
Edit model without additional image

StyleGAN-NADA (2021 Aug)
Next work of StyleCLIP


2021 Dec
It can train a forward model in about 1 min
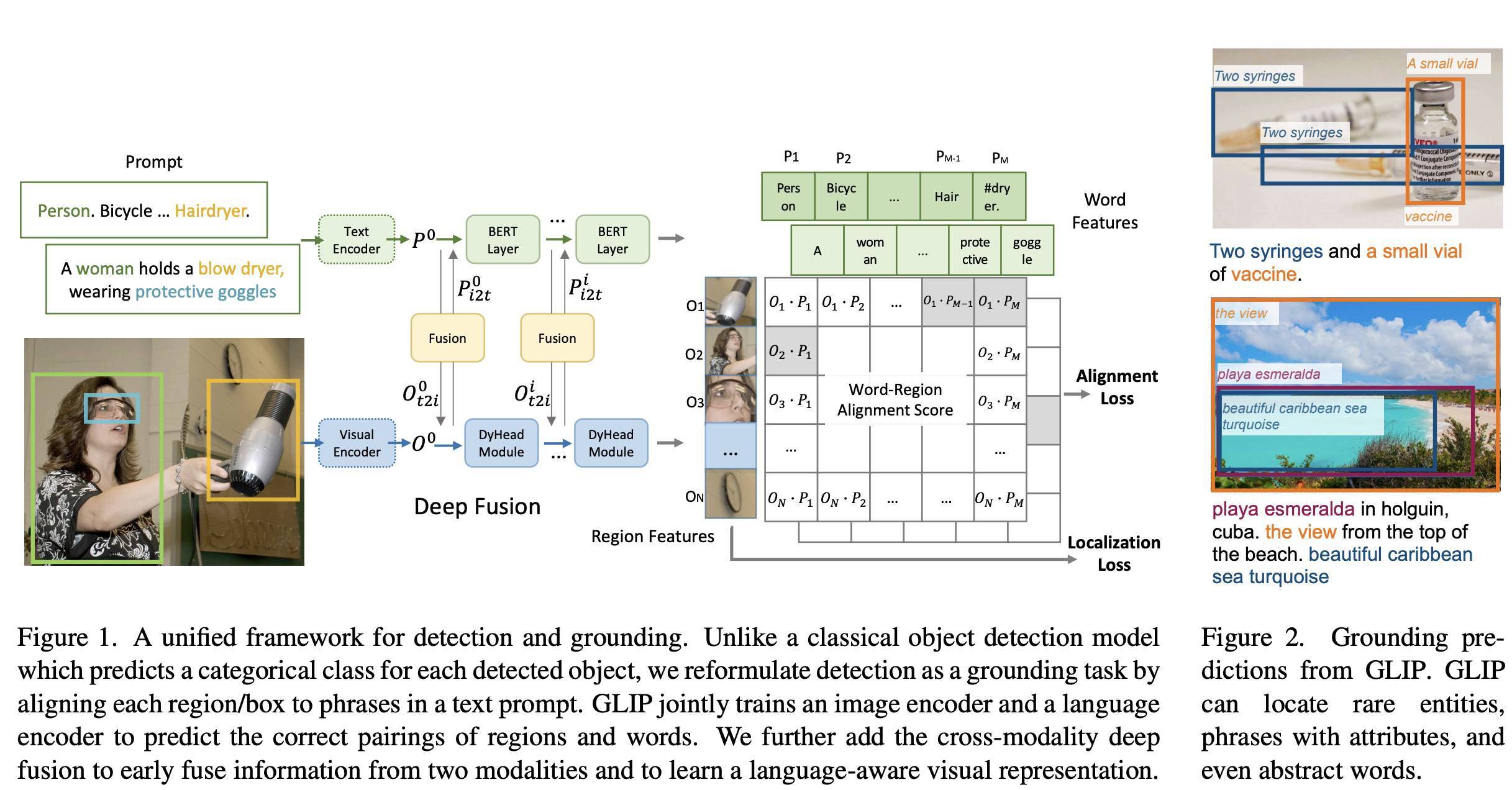
An old method : StarGAN(2017)

Choi, Yunjey, et al. "StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation." arXiv e-prints (2017): arXiv-1711.
VQ-GAN (2020 Dec)
a parallel method to DALL E
2021 Nov
2020 Apr




Novel view synthesis
Semantic photo manipulation (This Slide)
Facial and Body Reenactment
Relighting
Free-Viewpoint Video
Photo-realistic avatars for AR/VR

2021 Dec
2021 Dec
Applications
Resource List





Paper List
Style Transfer
-
Manjunath , B. S., & Ma, W. Y. (1996). Texture features for browsing and retrieval of image data. pattern analysis and machine intelligence , 18 (8), 837IEEE Transactions on 52 842.
-
Ojala, Timo, Matti Pietikainen, and Topi Maenpaa. "Multiresolution gray-scale and rotation invariant texture classification with local binary patterns." IEEE Transactions on pattern analysis and machine intelligence 24.7 (2002): 971-987.
- Lin, Tianwei, et al. "Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer." arXiv preprint arXiv:2104.05376 (2021).
- Jing, Yongcheng, et al. "Neural Style Transfer: A Review." _arXiv preprint arXiv:1705.04058_ (2017).
- Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. "Image style transfer using convolutional neural networks." _Proceedings of the IEEE conference on computer vision and pattern recognition_. 2016.
- Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. "Perceptual Losses for Real-Time Style Transfer and Super-Resolution." arXiv preprint arXiv:1603.08155 (2016).
- Dumoulin, Vincent, Jonathon Shlens, and Manjunath Kudlur. "A learned representation for artistic style." _arXiv preprint arXiv:1610.07629_ (2016).
- Ghiasi, Golnaz, et al. "Exploring the structure of a real-time, arbitrary neural artistic stylization network." _arXiv preprint arXiv:1705.06830_ (2017).
GAN & StyleGAN & StyleGAN Manipulation
- Karras, Tero, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks." _arXiv preprint arXiv:1812.04948_ (2018).
- Karras, Tero, et al. "Analyzing and Improving the Image Quality of StyleGAN." arXiv preprint arXiv:1912.04958 (2019).
- Karras, Tero, et al. "Alias-Free Generative Adversarial Networks." _arXiv preprint arXiv:2106.12423_ (2021).
-
Bau, David, et al. "Gan dissection: Visualizing and understanding generative adversarial networks." _arXiv preprint arXiv:1811.10597_ (2018).
-
Bau, David, et al. "Semantic photo manipulation with a generative image prior." _arXiv preprint arXiv:2005.07727_ (2020).
-
Bau, David, et al. "Rewriting a deep generative model." _European Conference on Computer Vision_. Springer, Cham, 2020.
Text Driven Image Manipulation/Genearation
-
Radford, Alec, et al. "Learning transferable visual models from natural language supervision." _arXiv preprint arXiv:2103.00020_ (2021).
-
Patashnik, Or, et al. "StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery." arXiv preprint arXiv:2103.17249 (2021).
-
Frans, Kevin, L. B. Soros, and Olaf Witkowski. "Clipdraw: Exploring text-to-drawing synthesis through language-image encoders." arXiv preprint arXiv:2106.14843 (2021).
-
Schaldenbrand, Peter, Zhixuan Liu, and Jean Oh. "StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis." arXiv preprint arXiv:2111.03133 (2021).
-
Ramesh, Aditya, et al. "Zero-shot text-to-image generation." _arXiv preprint arXiv:2102.12092_ (2021).
Thanks
If have any feedback, please contact me
changethewhat+NST@gmail.com
yidar+NST@aiacademy.tw
From Style Transfer to Text-Driven Image Manipulation
By sin_dar_soup



