From Style Transfer to StyleGAN-NADA
2021 Sep
Yi-Dar, Tang
Contents
- Recall : StyleTransfer / CIN / AdaIN / FiLM
- StyleGAN (2018)
- StyleGAN2 (2019)
- StyleGAN2-ADA (2020)
- Alias-Free GAN (2021)
- CLIP (2021)
- Before StyleCLIP
- StyleCLIP (2021)
- StyleGAN-NADA(2021)
- Some off-topic things
- Reference and Cited number(at 2021 Sep)

Motivation :
Matching Images' Statistic
Motivation :
Matching Images' Statistic
Naive Approache (Adjust each channel's statistic):
Color Affine Transform
\( f(c) = (\frac{c - \mu_{source}}{\sigma_{\text{source}}}) \cdot \sigma_{\text{target}} + \mu_{\text{target}} \)
Neural Style Transfer



Advertisement

Neural Style Transfer
Use a good feature extration
Find an image \(\overrightarrow x\) has feature map which
Close to \(\overrightarrow p\) content image's deep feature respect to pixel
Close to \(\overrightarrow a\) style image's deep feature respect to statistic
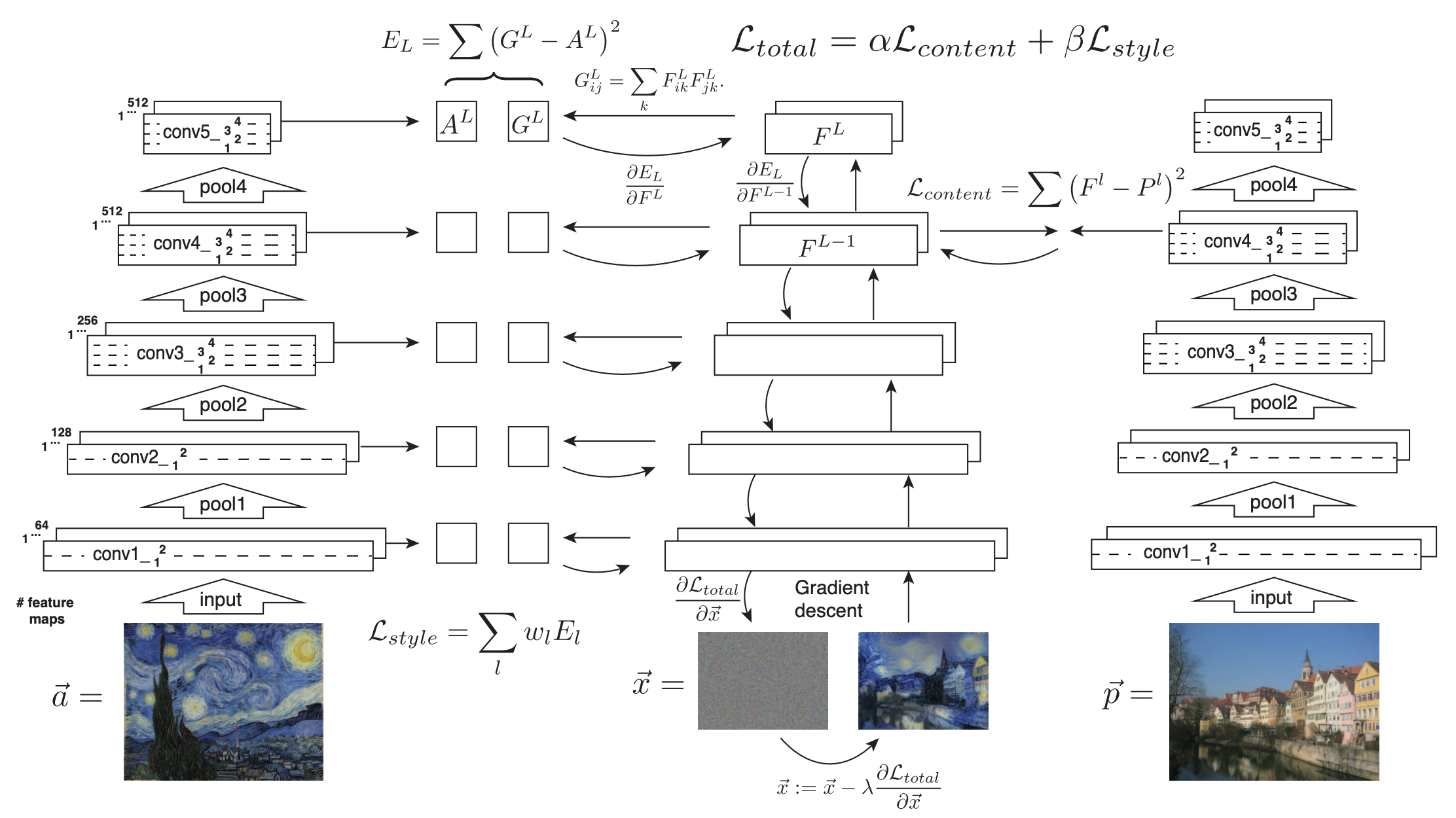
Neural Style Transfer
\(\text{content loss : }L_{\text{content}}^{layer}(y, CI) = \sum_{i,j,c} (F_{layer}(y)(i,j,c)-F_{layer}(CI)(i,j,c))^{2}\)
\(\text{style loss : } L_{\text{style}}^{layer}(y, SI) = \sum_{c_1,c_2}(G_y^{layer}(c_1, c_2)-G_{SI}^{layer}(c_1, c_2))^{2}\)
\(\text{gram matrix : } G^{layer}(I,c1,c2) = \sum_{i,j}F_{layer}(I)(i,j,c1)\times F_{layer}(I)(i,j,c2)\)
Objective
- Image-Optimisation-Based
\(argmin_x \mathcal{L}(x,CI,SI)\) - Per-Style-Per-Model Neural Methods
\(argmin_{M_{SI}} \mathbb{E}_{CI}[\mathcal{L}(M_{SI}(CI),CI,SI)]\) - Multiple-Style-Per-Model Neural Methods
\(argmin_{M} \mathbb{E}_{CI, SI}[\mathcal{L}(M(CI,SI),CI,SI)]\)
Instance Normalization
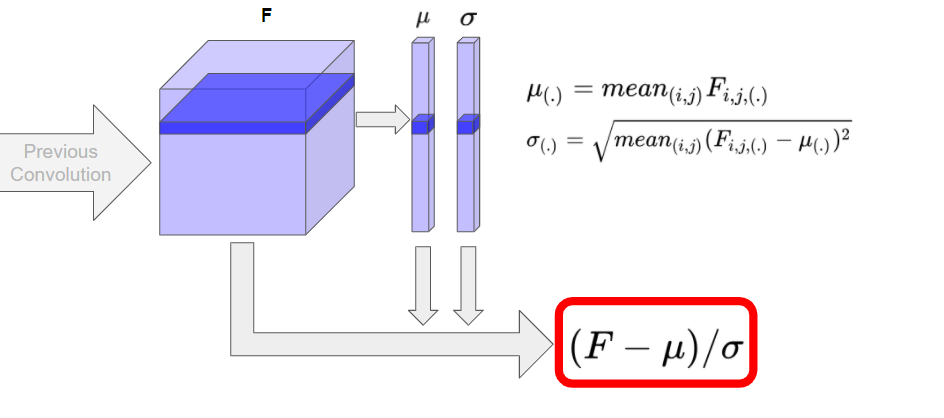
Conditional Instance Normalization
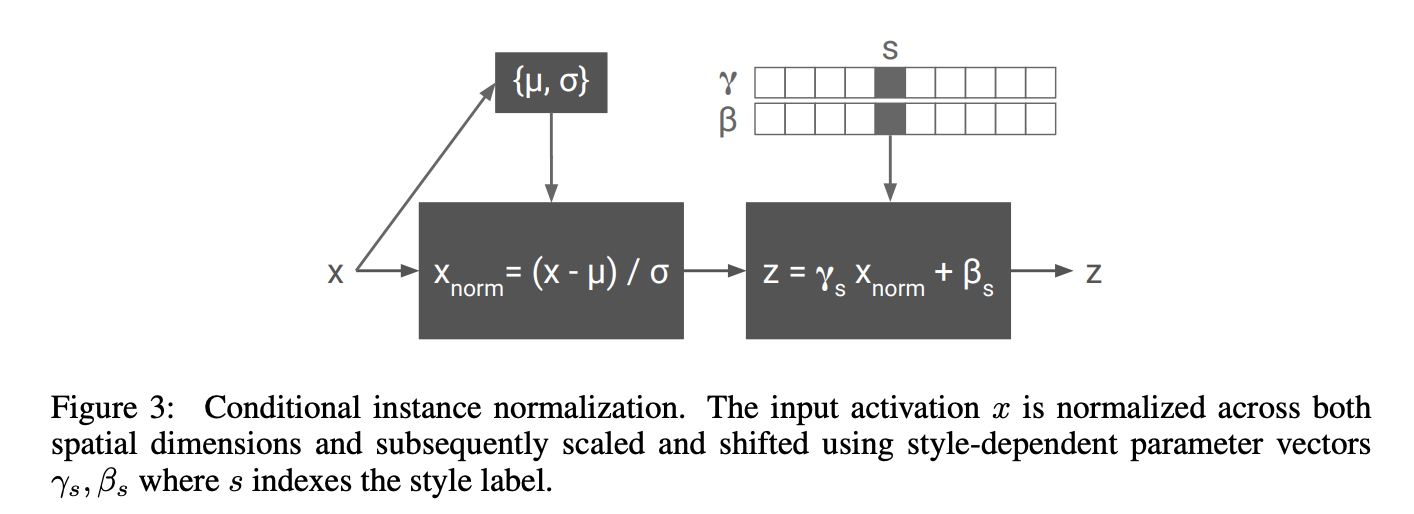
Different style with
- Same : Convolution Parameter
- Different : Scale & Bias
(1 style cost about 0.2% compare to ConvParams)
Note : Since the computation architecture, we do not need bias term in ConvLayer
"""Conditional Instance Normalization in Pytorch"""
import torch
from torch import nn
from functools import partial
class CIN(nn.Module):
def __init__(self, n_channels, n_conditionals):
self.norm = nn.InstanceNorm2d(n_channels)
self.scale = nn.Parameter(
1 + 0.02 * (
torch.randn(n_conditionals, n_channels)
).view(n_conditionals, n_channels, 1, 1)
)
self.bias = nn.Parameter(torch.zeros_like(self.scale))
def forward(self, x, style_idx):
assert style_idx.shape[0] == x.shape[0], "batch size should equal"
x = self.norm(x)
_get = partial(torch.index_select, dim=0, index=style_idx)
x = x * _get(self.scale) + _get(self.bias)
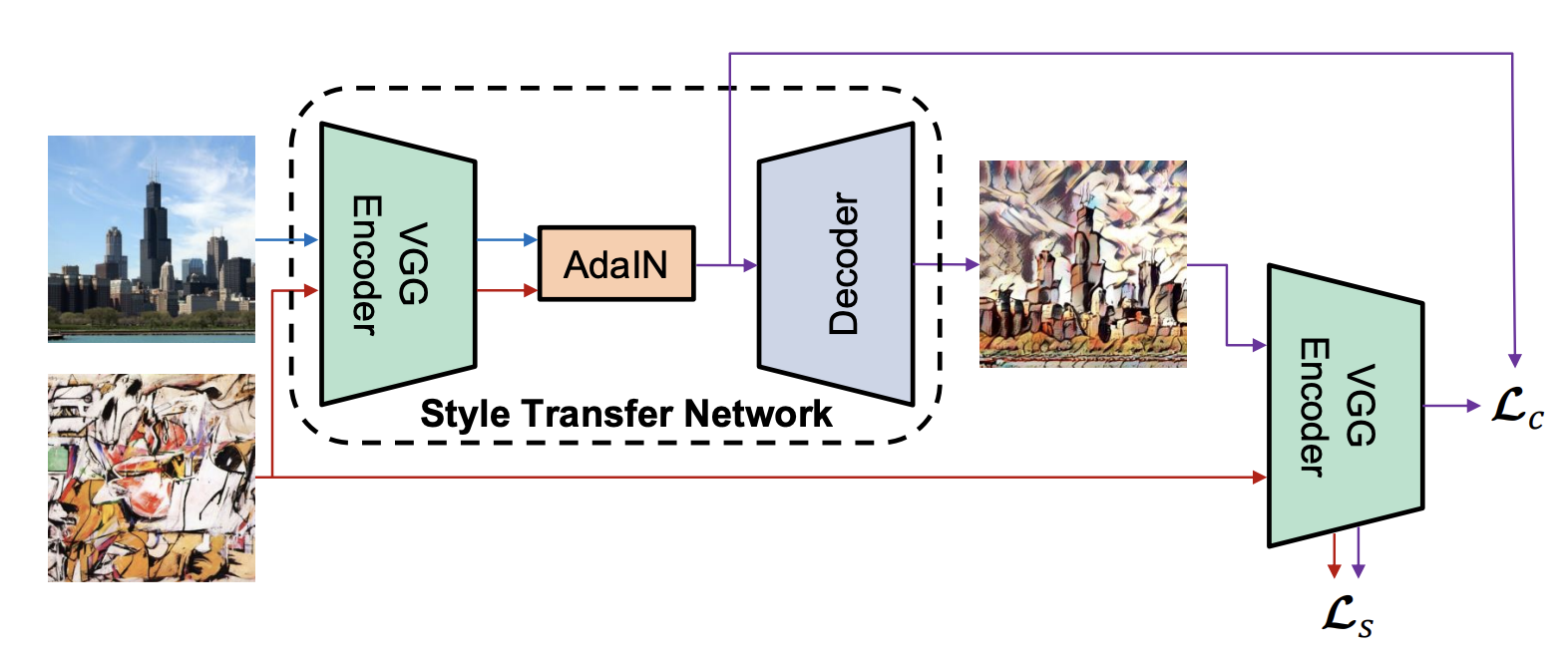
return xAdaptive Instance Normalization
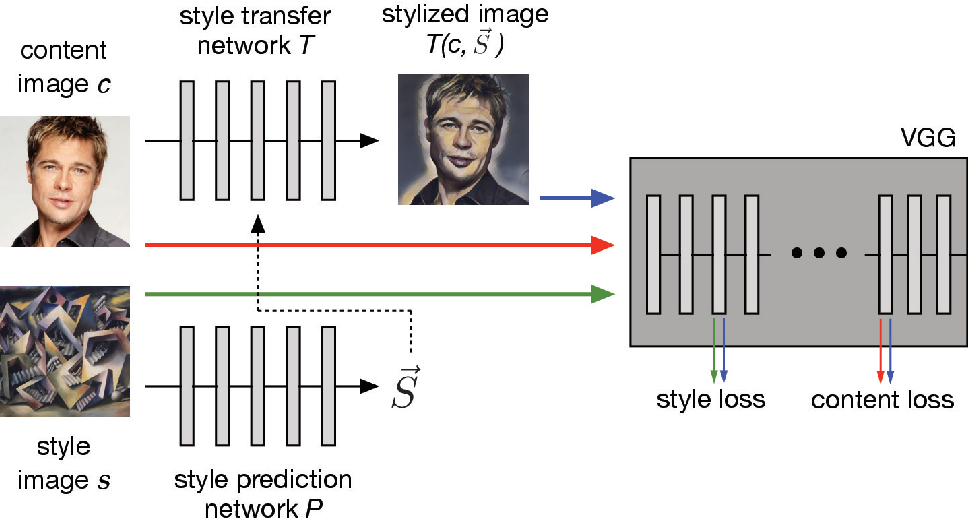
exploring the structure of a real-time, arbitrary neural artistic stylization network
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
StyleGAN Official Branch

Tero Karras
StyleGAN Un-Official Bush

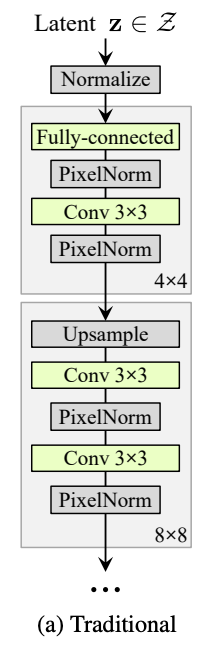
Before StyleGAN
A drawback for traditional generator was pointed out at Sec 3.2 in StyleGAN:
For traditional generator
All variaition should be embedded in Z.
However, there are plenty of natural variation in data
For human face as example, somethings are stochastic : such as the exact placement of hairs, stubble, freckles, or skin pores.
It will decrease the model capacity if we want to embed all this things in the input noise.
StyleGAN
Why named as "Style"GAN

Following slides are focus on the genearator and some tricks, will not discuss about discriminator.
Lots of things are omitted in this slide.
Please read the original papers if you are intersting to this branch.
Generator
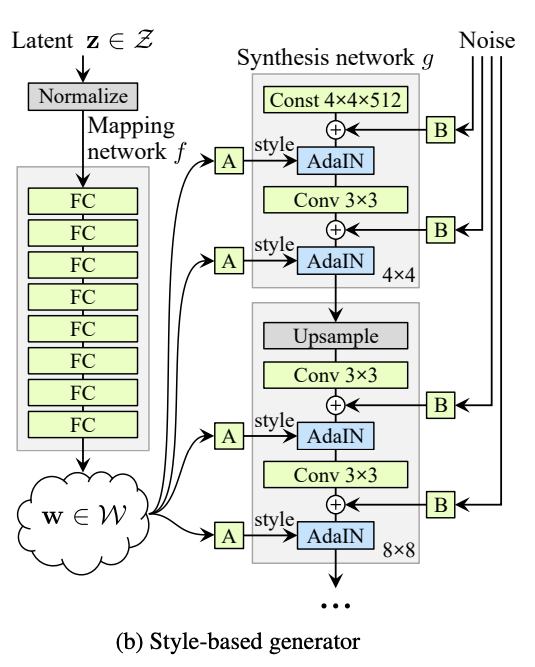
Some Notes
- All 3 x 3 conv with same channels
- Last layer is 1x1 conv with 3 channels output
- Input for \(g\) is a learnable constant tensor
- Bilinear upsample
- Latent \(Z\) is normlized to \(|Z|_2 = 1\)
- Gaussian (0,1) noise is applied before each AdaIN layer
- AdaIN's Scale&Bais are same for each layer for default setting
- AdaIN just adjust the global statistics, have no localize information in it.
Result (Metrics)
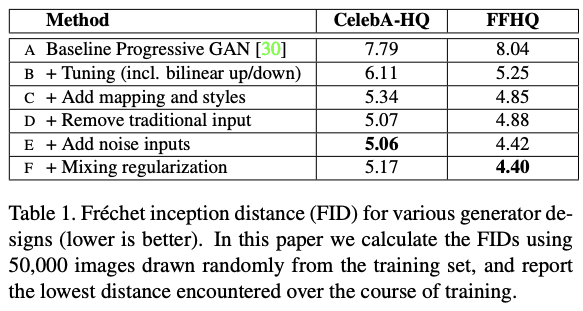
(B)~(E) is straight forward
Mixing Regularizaition during Training
Sample 2 Latent \(Z_1, Z_2\)
Get \(W_1, W_2\)
Random sample a layer, use \(W_1 / W_2\) before/after that layer
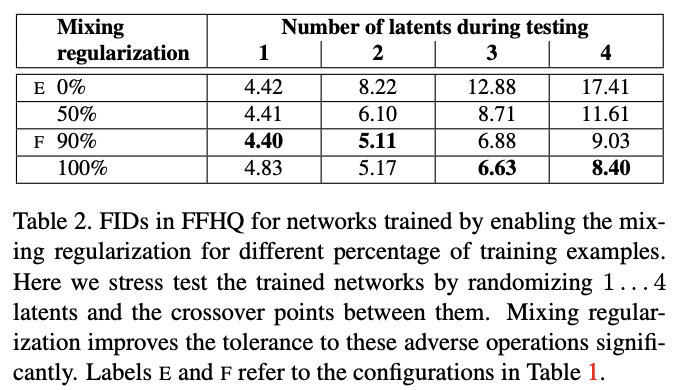
Result (Metrics)
Mapping
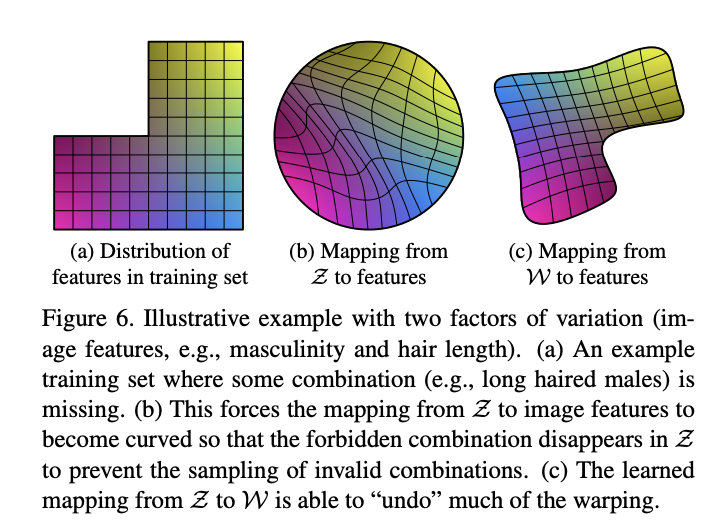
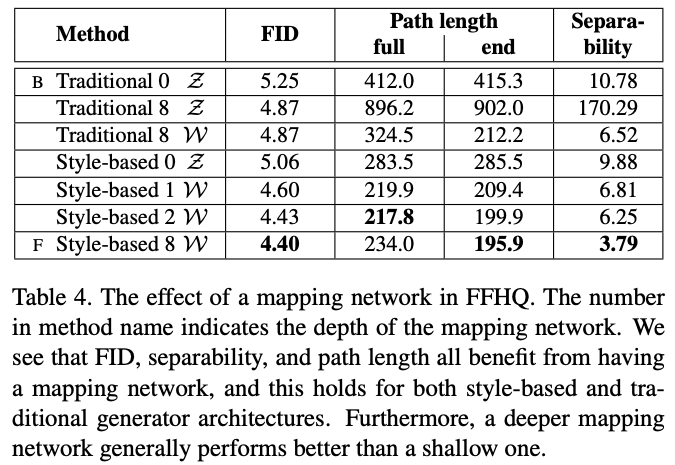
Style Mixing Result
Coarse Styles : pose, hair, face shape
Middle Styles : facial features, eyes
Mind Styles : Color scheme
Noise Result
Coarse Noise : large-scale curling of hair
Fine Noise : finer detail
No Noise: featureless "painterly" look
More About Noise

Style Truncation Result

StyleGAN2
StyleGAN has sevreal characteristic artifact.
In StyleGAN2, they modify the model architecture and training methods to address them.
StyleGAN Generator Revisited
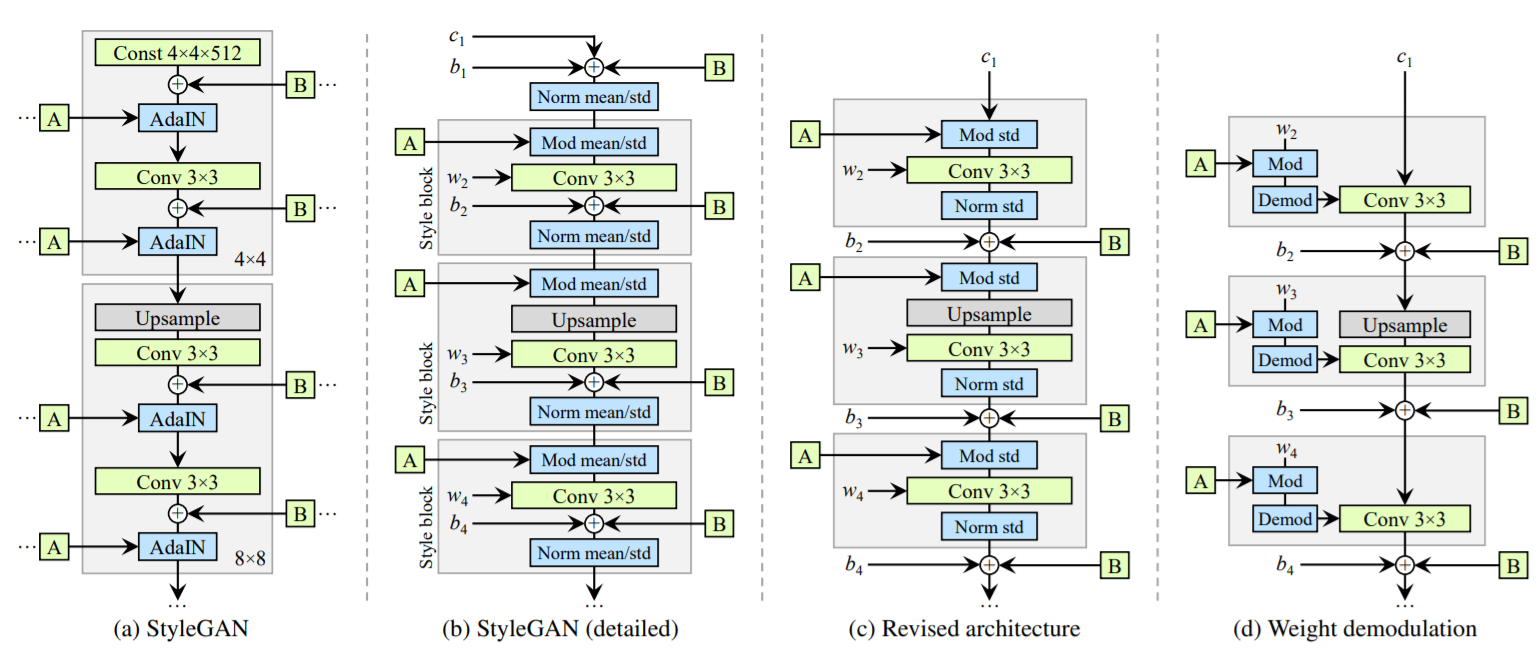
StyleGAN Generator Revisited
Notes In StyleGAN
- The magnitudes of original feature map will be drop in AdaIn operator
- The scale of bias&noise will be affected by the current style scale & conv layer
- AdaIN's standard deviation depends on input explicitly.
- Just a feedforward model(No shortcut, No residual)
StyleGAN2
Notes In StyleGAN / StyleGAN2
- The magnitudes of original feature map will be drop in AdaIn operator
- Not adjust mean in their try
- The scale of bias&noise will be affected by the current style scale & conv layer
- Move them out after norm std
- AdaIN's standard deviation depends on input explicitly.
- Assume the statastic, do not modify the input statastic explicitly. Direct apply conditional scale to the conv kernel, and normalize the kernel parameter. (d)
- Just a feedforward model(No shortcut, No residual)
- More experiment for shortcut, residual
(not in this slide)
StyleGAN2 Weight Demodulation
Assume the statastic, do not modify the input statastic explicitly. Direct apply conditional scale to the conv kernel, and normalize the kernel parameter.
Notation :
i/j ↔ in/out channel
k ↔ spatial footprint
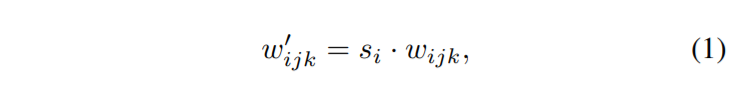
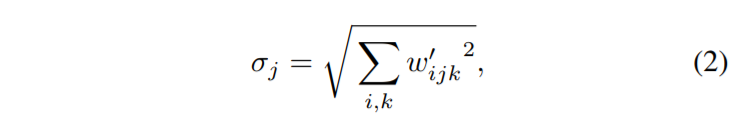
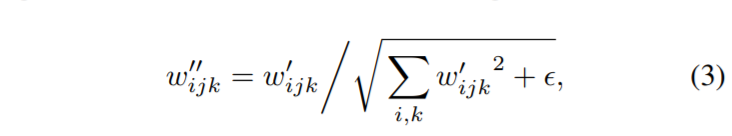
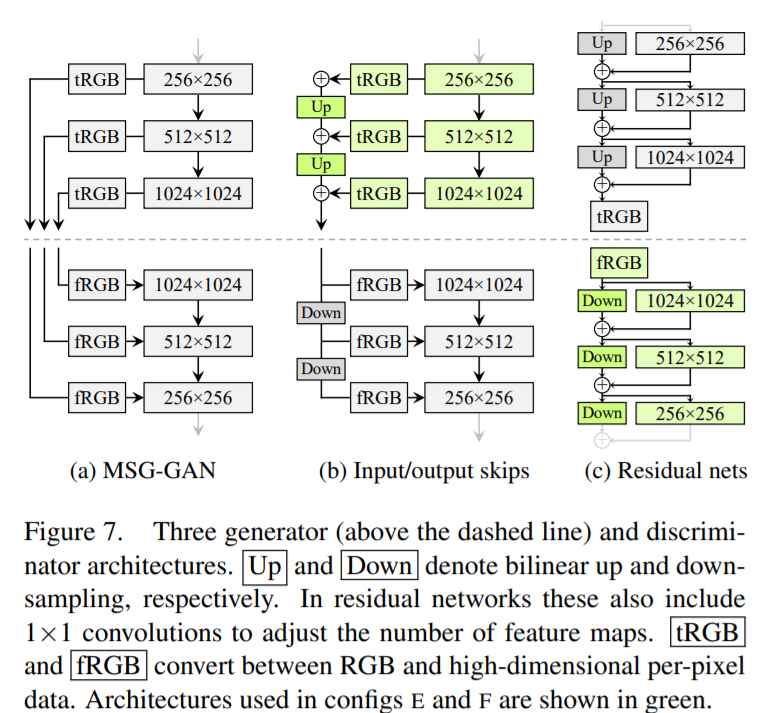
StyleGAN2 Architecture Tries
More experiment for shortcut, residual
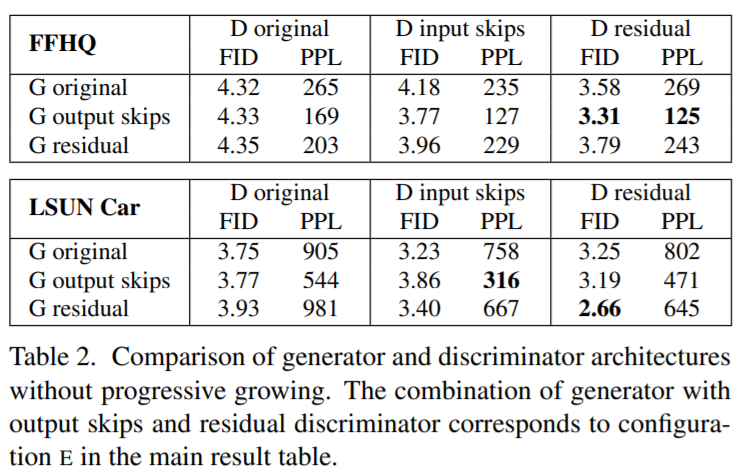
Perceptual path length(PPL)

Described in StyleGAN 1
\(d\) is VGG16 perceptual distance
slerp is spherical interpolation
lerp is normal linear interpolation
Regularization
- Lazy Regularization
- Path length regularization

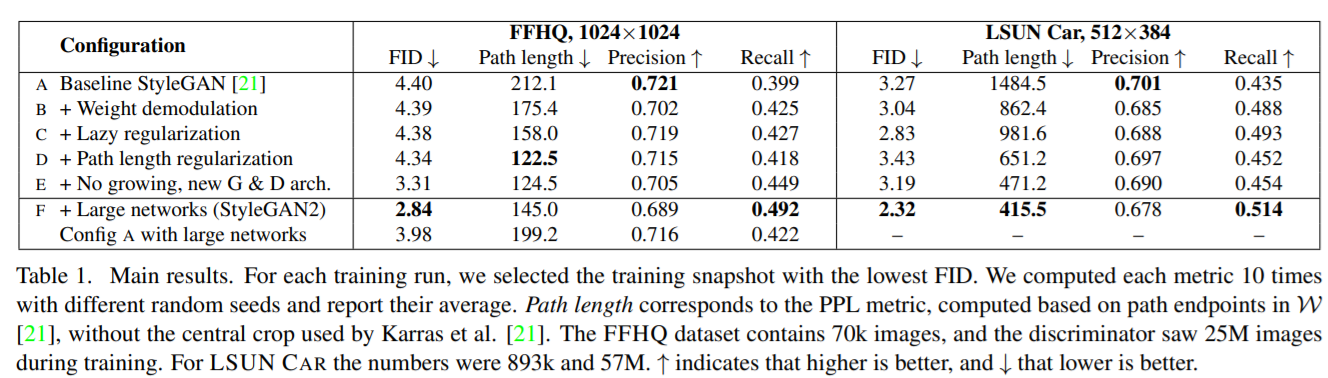
StyleGAN2-ADA
Training Generative Adversarial Networks with Limited Data
ADA :adaptive discriminator augmentation
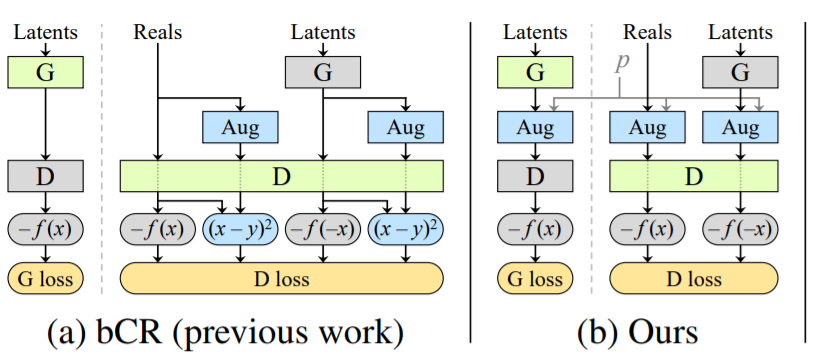

Designing augmentations that do not leak
Aug Prob
G Prob
Real Image Dataset
0.25
0.25
0.25
0.25
Aug G Prob
0.25
0.25
0.25
0.25
a
b
c
d
(a+b+c+d) = 1
0.25(a+b+c+d) = 0.25
Arbritrary a, b, c, d can work
Designing augmentations that do not leak
Aug Prob
G Prob
Real Image Dataset
1-p+.25p
0.25p
0.25p
0.25p
Aug G Prob
a
b
c
d
only $$(a,b,c,d) = (1,0,0,0)$$ can match target distribution for \[\forall p \in [0,1[\]
1-p+.25p
0.25p
0.25p
0.25p
Adaptive Discriminator Augmentation
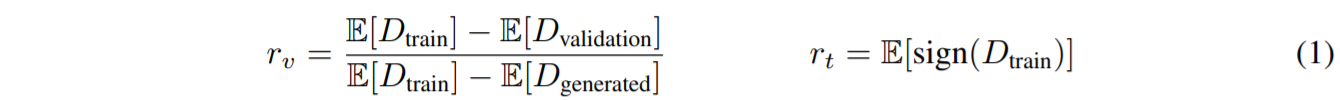
Rise p with fix step if think D is overfit to training data
The heuristic in the paper is
raise \(p\) while \(r_t >= 0.6\)
decrease \(p\) while \(r_t < 0.6\)
Result






All of them in
2020 June
COOL
Alias-Free GAN

Texture should move while pose is moving
But StyleGAN2 is not

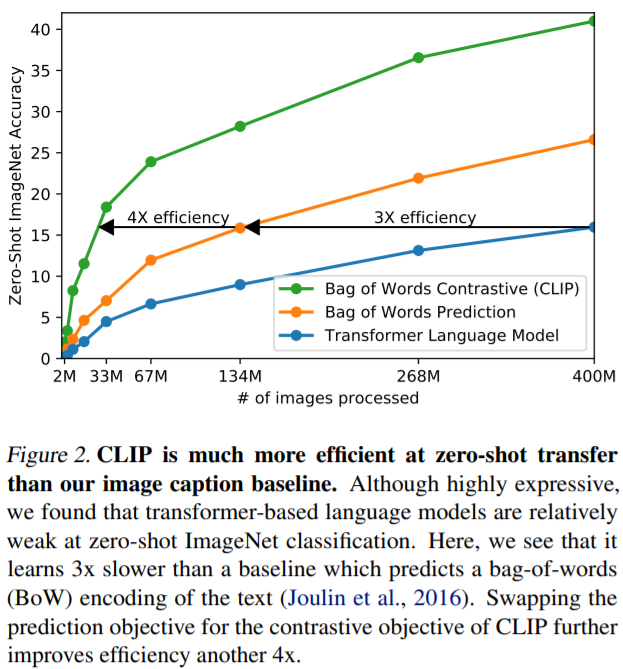
Learning Transferable Visual Models From Natural Language Supervision
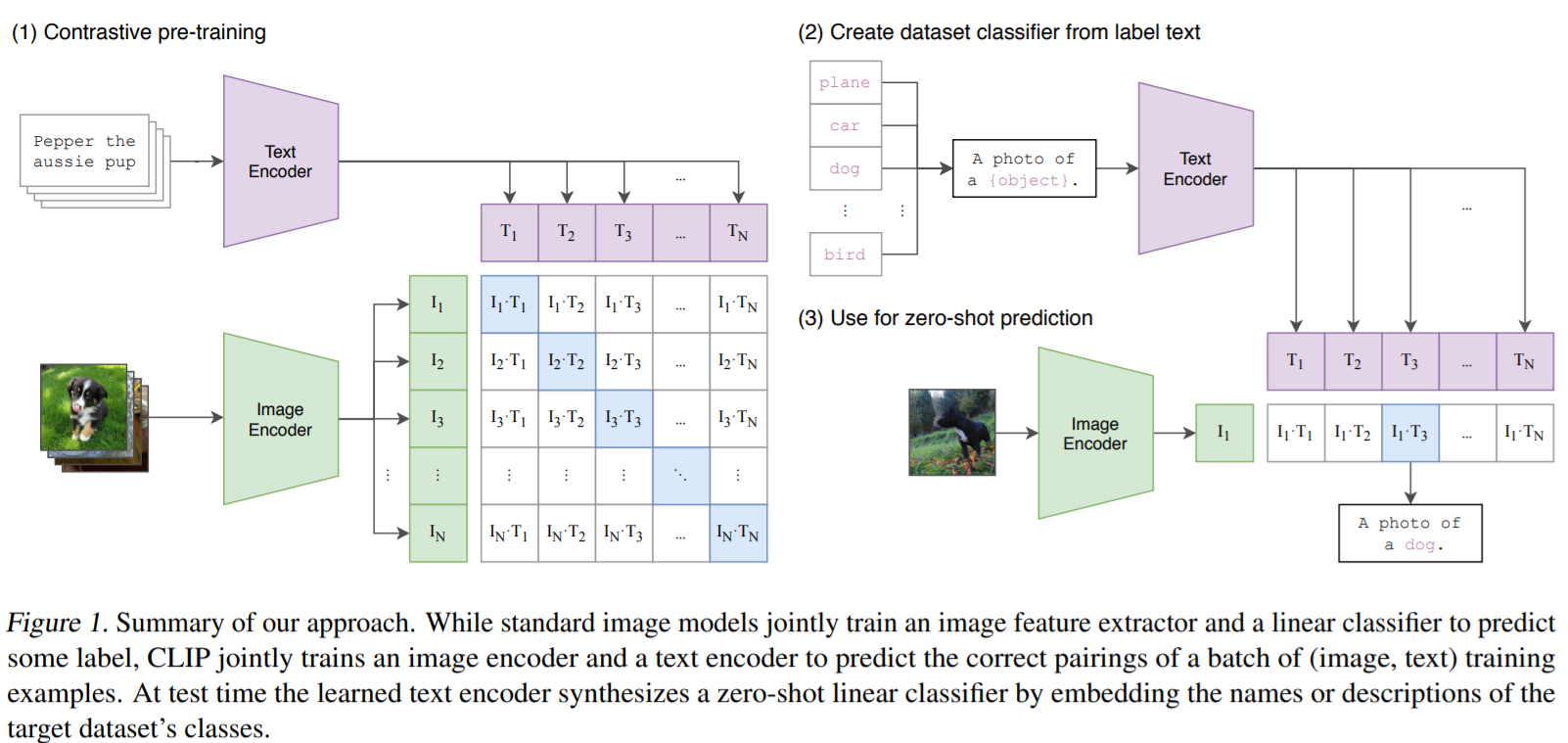
CLIP (Contrastive Language-Image Pre-Training)

Pseudocode
Maybe a New Star : Or Patashnik
Stats : 2021/09/09
Before StyleCLIP
There are some "forward" methods can convert real world image to StyleGAN2's latent



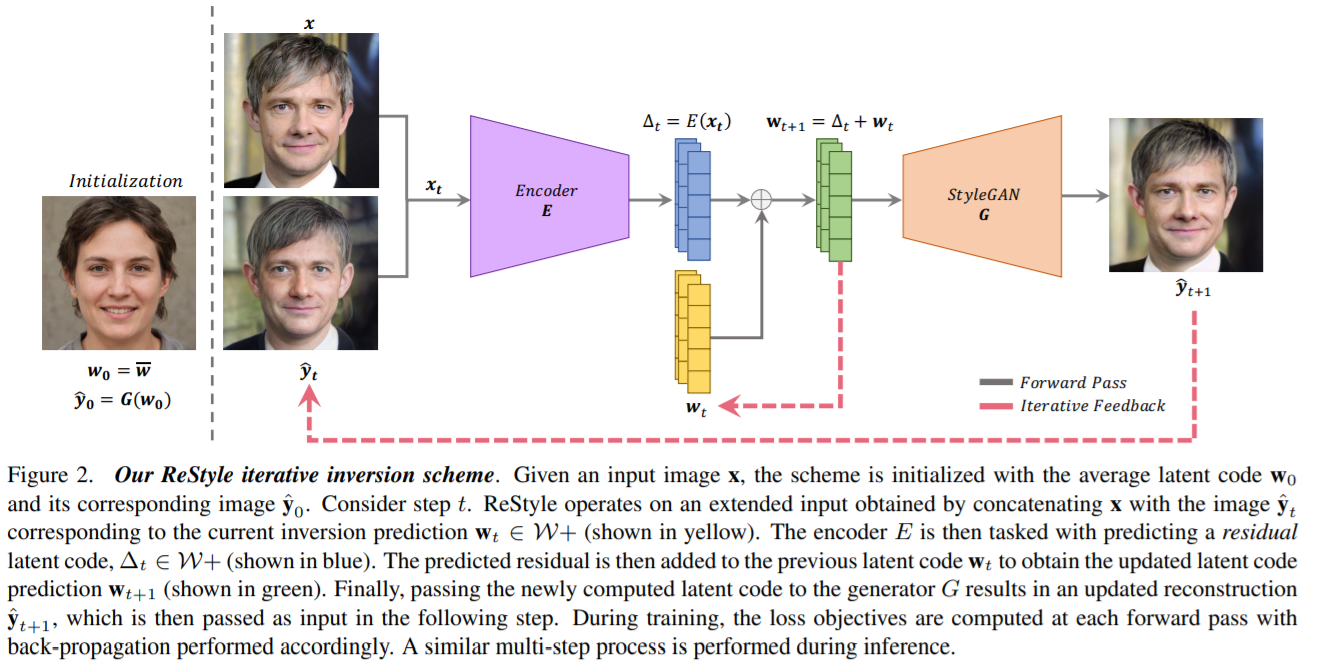
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery

Zero data feature transform.
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
Recall Recall
Objective
- Image-Optimisation-Based
\(argmin_x \mathcal{L}(x,CI,SI)\) - Per-Style-Per-Model Neural Methods
\(argmin_{M_{SI}} \mathbb{E}_{CI}[\mathcal{L}(M_{SI}(CI),CI,SI)]\) - Multiple-Style-Per-Model Neural Methods
\(argmin_{M} \mathbb{E}_{CI, SI}[\mathcal{L}(M(CI,SI),CI,SI)]\)
Three Approaches In StyleCLIP
Objective
- Image-Optimisation-Based
\(argmin_x \mathcal{L}(x,CI,SI)\) - Per-Style-Per-Model Neural Methods
\(argmin_{M_{SI}} \mathbb{E}_{CI}[\mathcal{L}(M_{SI}(CI),CI,SI)]\) - Multiple-Style-Per-Model Neural Methods
\(argmin_{M} \mathbb{E}_{CI, SI}[\mathcal{L}(M(CI,SI),CI,SI)]\)
- Latent Optimization
- Latent Mapper
- Global Directions

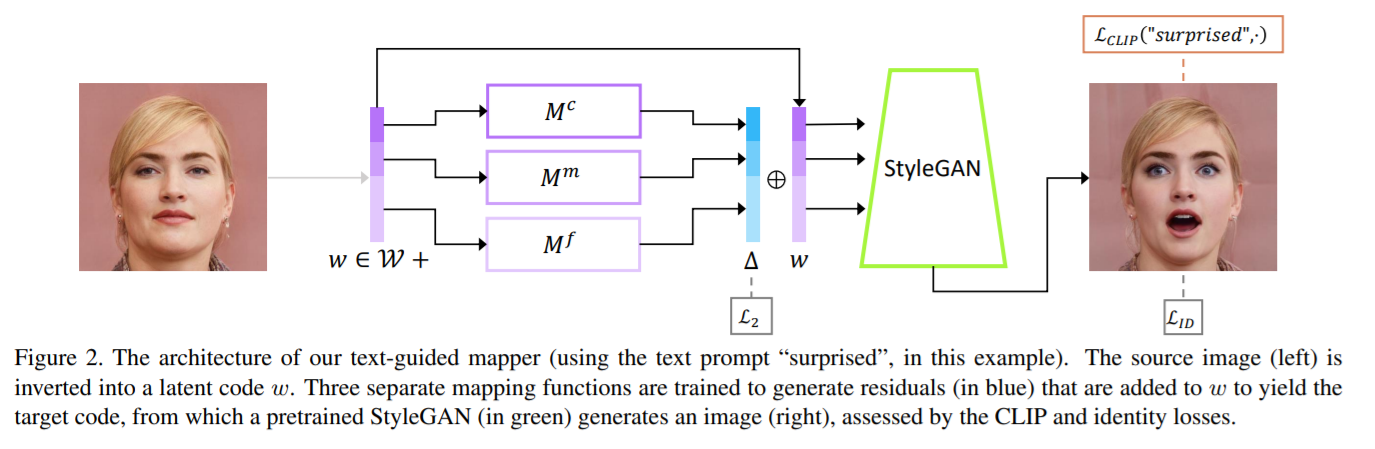
Where 3 mappers are just simple 4 layer dense.
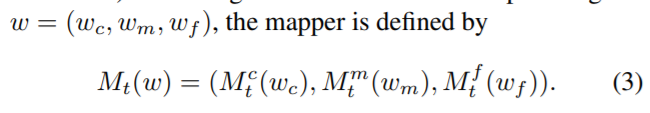
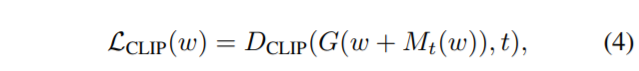
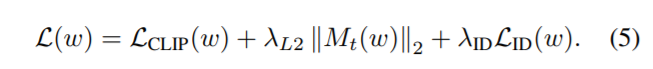
Settings
- Default : \(\lambda_{L2}:0.8, \lambda_{ID}:0.1\)
- Trump : \(\lambda_{L2}:2, \lambda_{ID}:0\)

Notation:
- \(s\) : Style Code
- \(i\) : CLIP Image Encode
- \(t\) : CLIP Text Encode
Motivation :
Find the collinearity between
- Style Code Direction \(\Delta s\)
- Text Encode Direction \(\Delta t\)
Assume :
- Image Encode Direction \(\Delta i\) = \(\Delta t\)

Channelwise relevance
\(\Delta i_{c} = E_{s\in S}[I_{CLIP}(G(s+\alpha\Delta s_c)) -I_{CLIP}(G(s+\alpha\Delta s_c))]\)

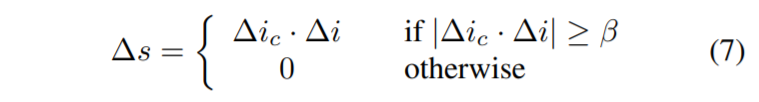

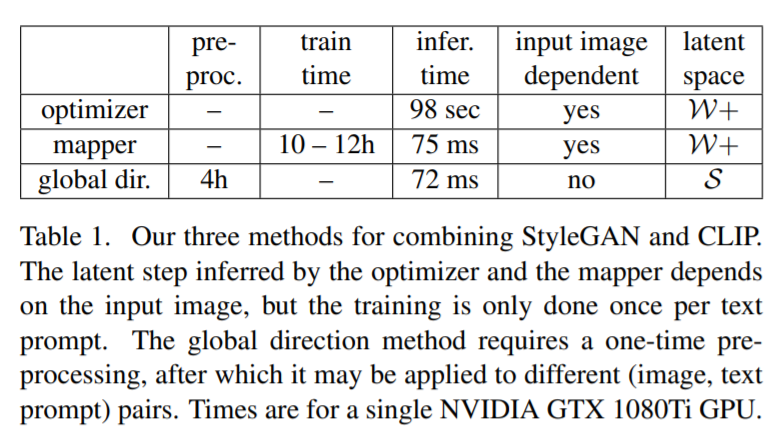
Inference Time
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
(NADA) Non-Adversarial Domain Adaptation
Zero data domain transform.
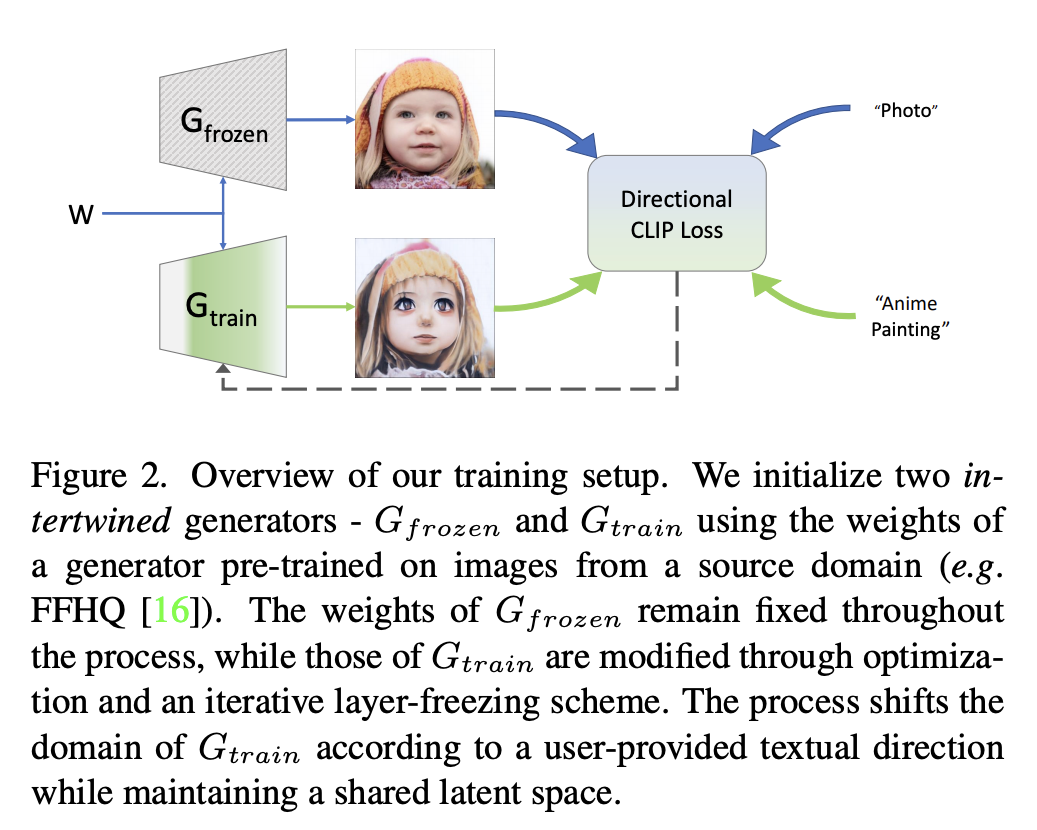
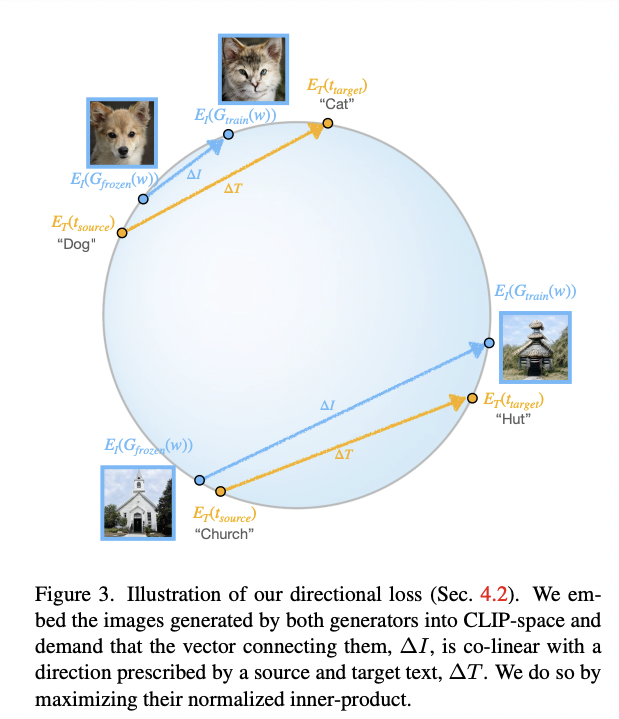
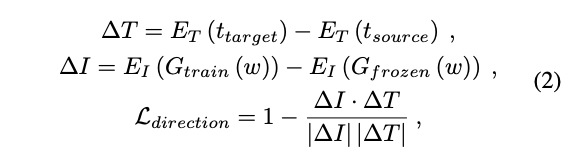
Latent Mapper Regularizer
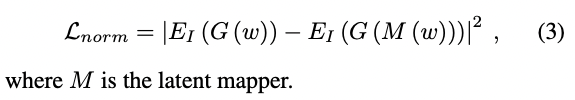
Ulike StyleCLIP.
\(M\) is not learning residual here
Layer-Freezing
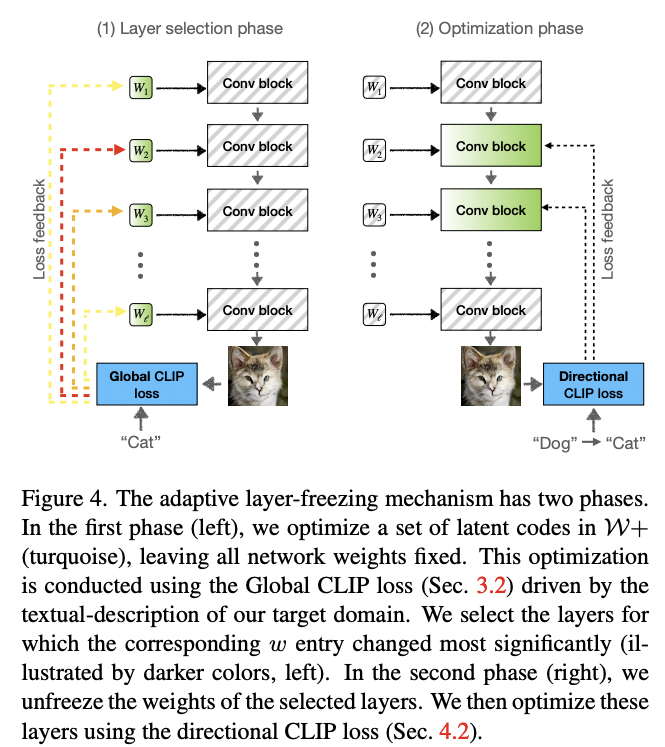
To overcome mode collapse or overfitting for domain changing task
Find top k layers with change fastest in style \(W+\)
Then optimize the \(\mathcal{L}_{direction}\) for top k evident conv block.
Latent-Mapper ‘Mining’
Some times, the domain trainsfer is not complete
Such as the generated result contain both "dog" and "cat"
To over come this issue, they training a mapper.


Some Off-Topic Things
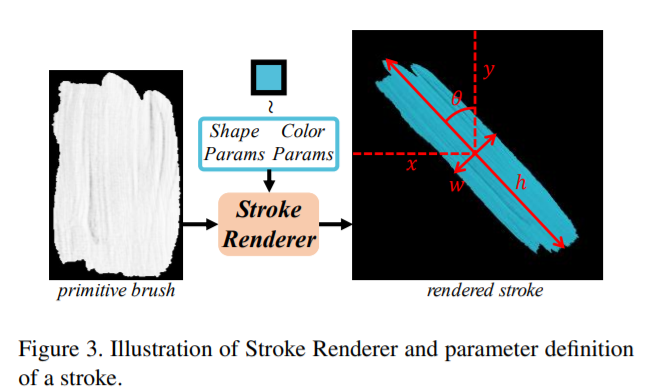
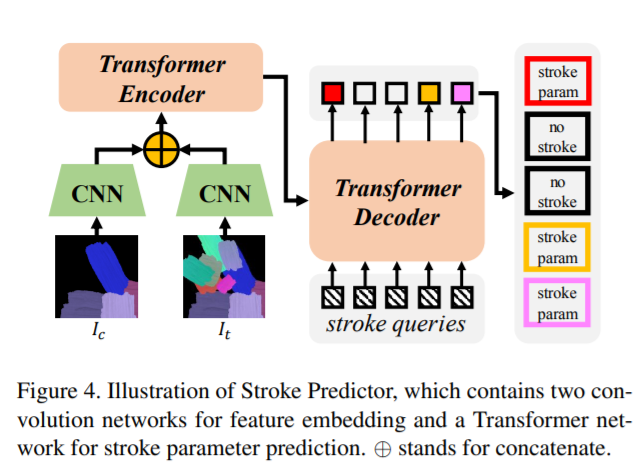
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction


Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
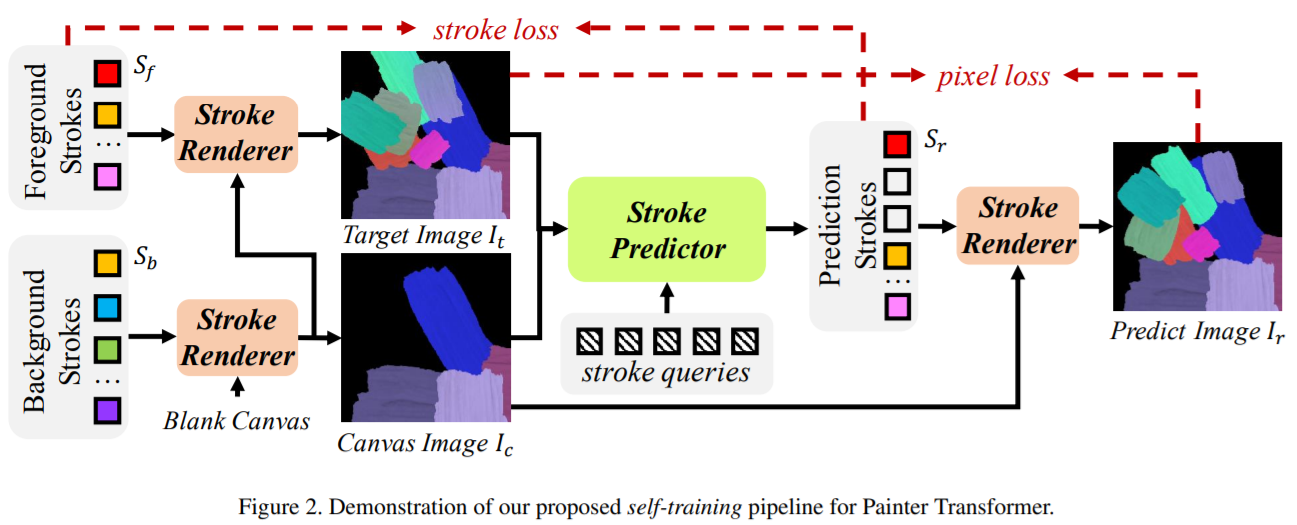
Dataset : 1 Stroke Image
No Pretrain

Advance ML/DL University Lectures
MLSS 2021 : Machine Learning Summer School
Cost-sensitive Classification: Techniques and Stories | National Taiwan University | MLSS 2021
Fundamentals and Application of Deep Reinforcement Learning | National Taiwan University | MLSS 2021
Machine Learning in Practice | National Taiwan University | MLSS 2021
Deep Learning for Speech Processing | National Taiwan University | MLSS 2021
Machine Learning as a Service: Challenges and Opportunities | National Taiwan University | MLSS 2021
Google Efforts on AI Research and Talent Development | Google Taiwan | MLSS 2021
Interpretable machine learning | Google Brain | MLSS 2021
Machine Learning Summer School | MLSS 2021
Large Scale Learning and Planning in Reinforcement Learning | University of Alberta | MLSS 2021
Neural Architecture Search and AutoML | University of California, Los Angeles | MLSS 2021
Privacy and Machine Learning/Data Analytics | Princeton University | MLSS 2021
Optimal transport | Google Brain | MLSS 2021
Geometric Deep Learning | Imperial College London | MLSS 2021
Trustworthy Machine Learning: Challenges and Opportunities | Panel Discussion | MLSS 2021
Theory of deep learning | IBM Research | Princeton University | MLSS 2021
Transform the Beauty Industry through AI + AR | CTO of Perfect Corp | MLSS 2021
Pre-training for Natural Language Processing | Google Research | MLSS 2021
Bias and Fairness in NLP | University of California, Los Angeles | MLSS 2021
Developing a World-Class AI Facial Recognition Solution | CyberLink Corp | MLSS 2021
Holistic Adversarial Robustness for Deep Learning | IBM Research | MLSS 2021
TinyML and Efficient Deep Learning | Massachusetts Institute of Technology | MLSS 2021
Computer Vision | University of Texas at Austin | MLSS 2021
Neuro-Symbolic Systems and the History of AI | University of Rochester | MLSS 2021
Continual Visual Learning | Inria, France | MLSS 2021
Overview of learning quantum states | IBM Research | MLSS 2021
An introduction to Statistical Learning Theory and PAC-Bayes Analysis | College London | MLSS 2021

Reference and Cited number (at 2021 Sep)
-
(1843)
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. "A neural algorithm of artistic style." arXiv preprint arXiv:1508.06576 (2015). - (317)
Jing, Yongcheng, et al. "Neural Style Transfer: A Review." arXiv preprint arXiv:1705.04058 (2017). - (1747)
Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. "Instance normalization: The missing ingredient for fast stylization." arXiv preprint arXiv:1607.08022 (2016). -
(680)
Dumoulin, Vincent, Jonathon Shlens, and Manjunath Kudlur. "A learned representation for artistic style." arXiv preprint arXiv:1610.07629 (2016). - (1513)
Huang, Xun, and Serge Belongie. "Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization." arXiv preprint arXiv:1703.06868 (2017). - (166)
Ghiasi, Golnaz, et al. "Exploring the structure of a real-time, arbitrary neural artistic stylization network." arXiv preprint arXiv:1705.06830 (2017). -
(45)
Dumoulin, Vincent, et al. "Feature-wise transformations." Distill 3.7 (2018): e11.
Style Transfer
StyleGAN
- (2199)
Karras, Tero, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks." arXiv preprint arXiv:1812.04948 (2018). - (869)
Karras, Tero, et al. "Analyzing and Improving the Image Quality of StyleGAN." arXiv e-prints (2019): arXiv-1912. - (158)
Karras, Tero, et al. "Training generative adversarial networks with limited data." arXiv preprint arXiv:2006.06676 (2020). -
(2)
Karras, Tero, et al. "Alias-Free Generative Adversarial Networks." arXiv preprint arXiv:2106.12423 (2021). - (159)
Radford, Alec, et al. "Learning transferable visual models from natural language supervision." arXiv preprint arXiv:2103.00020 (2021). - (13)
Patashnik, Or, et al. "Styleclip: Text-driven manipulation of stylegan imagery." arXiv preprint arXiv:2103.17249 (2021). - (0)
Gal, Rinon, et al. "StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators." arXiv preprint arXiv:2108.00946 (2021).
From Style Transfer to StyleGAN NADA
By sin_dar_soup



