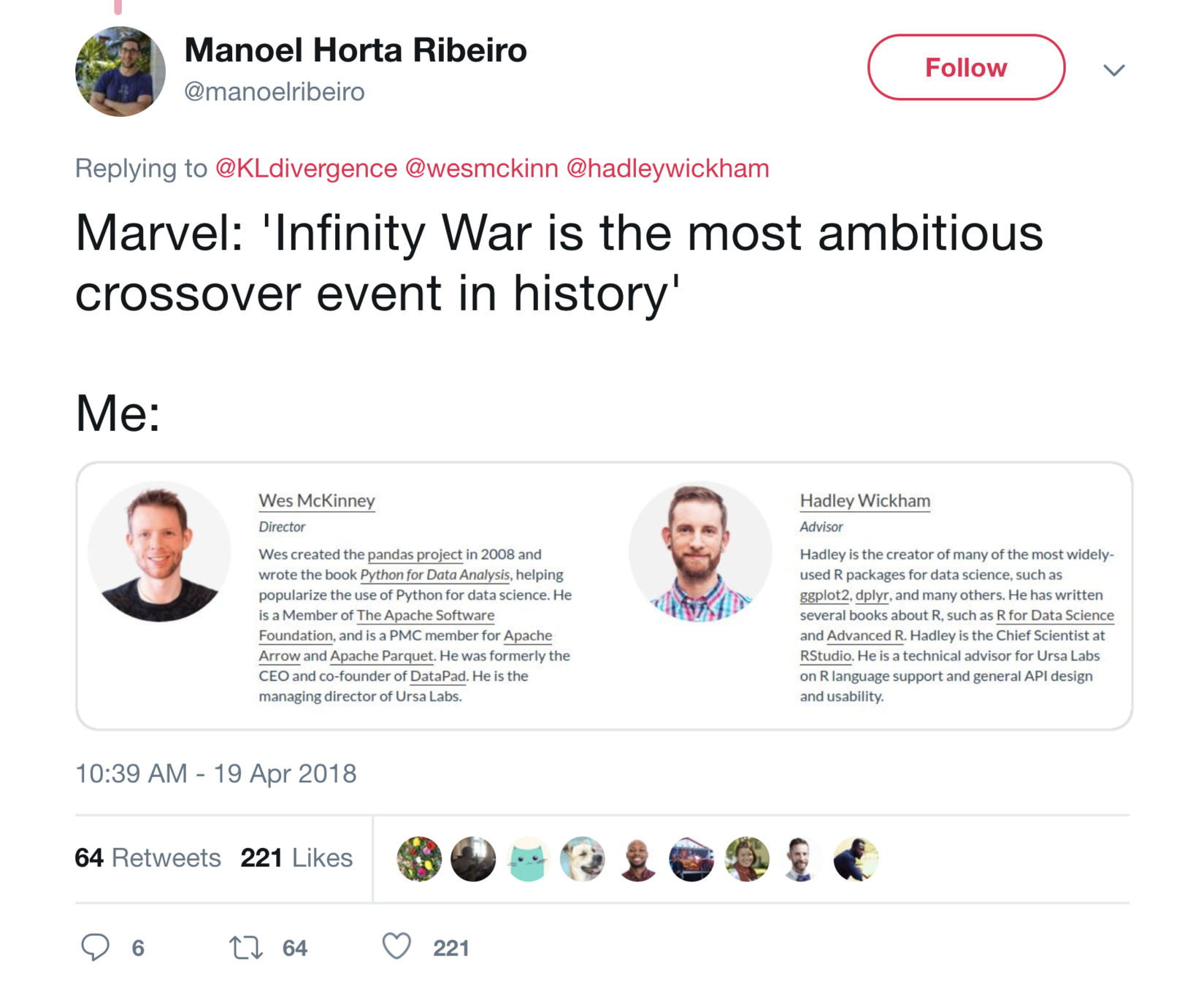








Tanya Schlusser
I like you!
bit.ly/quick-arrow-lunch
28 Feb 2019
Before:
After:
Images lifted from arrow.apache.org/
Image lifted from arrow.apache.org/
Image lifted from arrow.apache.org/
*Except for the Google File System paper (HDFS) from 2003 (Ghemawat, Gobioff, Leung)
In Chicago, people were throwing poo in the river...
Jeff Dean and Sanjay Ghemawat were finishing their OSDI paper: MapReduce, the inspiration for Hadoop.
image from giphy search for California
2004
2005
2006
2008
(also Wes McKinney starts learning Python) *source: DataCamp podcast
2009
2010
2012
2011
https://www.datacamp.com/community/blog/data-science-tool-building
The backstory intersects paths with Wes McKinney in 2015, while he's at Cloudera. (story in the DataCamp interview above)
Feather (flatbuffer for serialization Pandas ↔ R)
proof of concept
Parquet (on-disk columnar storage format)
Arrow (in-memory columnar format)
C++, R, Python (use the C++ bindings) even Matlab
Go, Rust, Ruby, Java, Javascript (reimplemented)
Plasma (in-memory shared object store)
Gandiva (SQL engine for Arrow)
Flight (remote procedure calls based on gRPC)
(A proof of concept; still in codebase)
Python (write)
R (read)
import pandas as pd
import pyarrow.feather as feather
import numpy as np
x = np.random.sample(1000)
y = 10 * x**2 + 2 * x + 0.05 * np.random.sample(1000)
df = pd.DataFrame(dict(x=x, y=y))
df.to_feather('testing.feather')library(arrow)
dataframe <- read_feather('testing.feather')
png("rplot.png")
plot(y ~ x, data=dataframe)
dev.off()On-disk data storage format
(Joined with Arrow December 2018)
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
df = pd.DataFrame(
{'one':[-1, np.nan], 'two':['foo', 'bar'], 'three':[True, False]},
index=list('ab'))
table = pa.Table.from_pandas(df)
pq.write_table(table, 'example.parquet')Write
Read
import pyarrow.parquet as pq
table2 = pq.read_table('example.parquet')
df = table2.to_pandas()(cross-language in-memory columnar data format)
Like second-generation on-disk data stores (Parquet, ORC, etc.) in-memory columnar layouts allow faster computation over columns (mean, stdev, count of categories, etc.)
Image lifted from arrow.apache.org/
(speed example: Spark, from the blog)
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.3.0-SNAPSHOT
/_/
Using Python version 2.7.13 (default, Dec 20 2016 23:09:15)
SparkSession available as 'spark'.
In [1]: from pyspark.sql.functions import rand
...: df = spark.range(1 << 22).toDF("id").withColumn("x", rand())
...: df.printSchema()
...:
root
|-- id: long (nullable = false)
|-- x: double (nullable = false)
In [2]: %time pdf = df.toPandas()
CPU times: user 17.4 s, sys: 792 ms, total: 18.1 s
Wall time: 20.7 s
In [3]: spark.conf.set("spark.sql.execution.arrow.enabled", "true")
In [4]: %time pdf = df.toPandas()
CPU times: user 40 ms, sys: 32 ms, total: 72 ms
Wall time: 737 msnot the default
(components)
import pyarrow as pa
arr1 = pa.array([1,2])
arr2 = pa.array([3,4])
field1 = pa.field('col1', pa.int64())
field2 = pa.field('col2', pa.int64())
field1 = field1.add_metadata({'meta': 'foo'})
field2 = field2.add_metadata({'meta': 'bar'})
col1 = pa.column(field1, arr1)
col2 = pa.column(field2, arr2)
table = pa.Table.from_arrays([col1, col2])
batches = table.to_batches(chunksize=1)
print(table.to_pandas())
# col1 col2
# 0 1 3
# 1 2 4
pa.Table.from_pandas(table.to_pandas())An array is a sequence of values with known length and type.
A column name + data type
+ metadata = a field
A field + an array = a column
A table is a set of columns
You can split a table into row batches
You can convert between pyarrow tables and pandas data frames
(both directions)
(announced mid-2017)
# Create an object.
object_id = pyarrow.plasma.ObjectID(20 * b'a')
object_size = 1000
buffer = memoryview(client.create(object_id, object_size))
# Write to the buffer.
for i in range(1000):
buffer[i] = 0
# Seal the object making it immutable and available to other clients.
client.seal(object_id)# Get the object from the store. This blocks until the object has been sealed.
object_id = pyarrow.plasma.ObjectID(20 * b'a')
[buff] = client.get([object_id])
buffer = memoryview(buff)Create:
Use:
Can be copied because it's now immutable.
(Donated by Dremio November 2018)
Named after a mythical bow from an Indian legend that makes the arrows it fires 1000 times more powerful.
(Announced as a new initiative in late 2018)
Wes McKinney has been thinking out loud on the listserv about the future of the project, and posted some ideas here.
(Note to Tanya: Click on this. It will be the start point for discussions. Scroll to "Goals")
To my beautiful Mom, whose only joy in life was her children's happiness.
Rest in peace. You did a wonderful job. I love you.
By Tanya Schlusser


