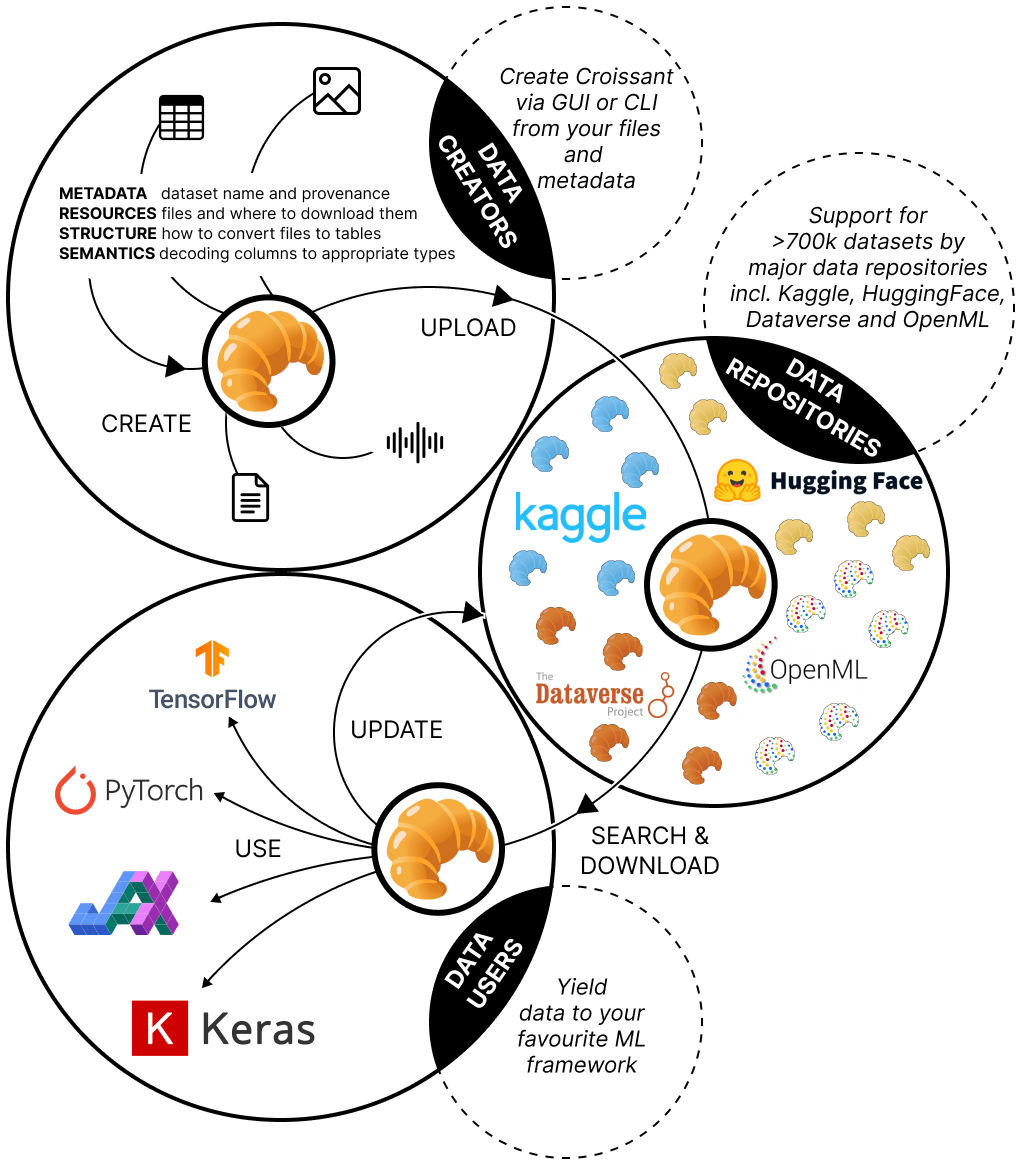
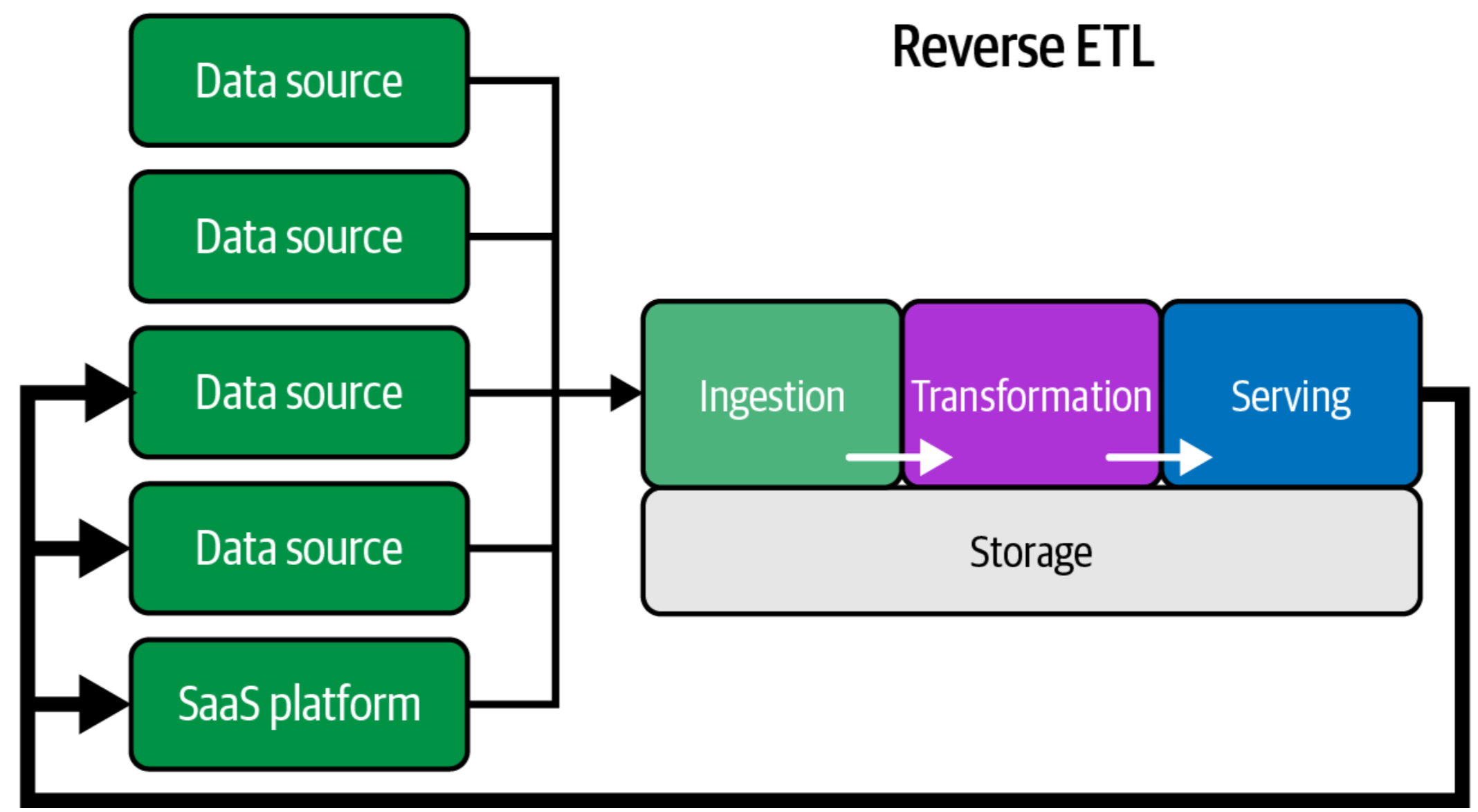
Customer Account
The registered profile containing customer details such as name, contact information, and account preferences.
Trade Account
A special type of customer account for professional tradespeople, usually offering benefits such as credit terms, bulk pricing, or exclusive promotions
Product
An item we sell, such as tools, hardware, equipment, or supplies. Products have attributes like size, material, brand, and specifications.
Product Category
A grouping of similar products (e.g., “Power Tools”, “Plumbing”, “Electrical”). Helps customers navigate the catalogue.
Product Variant
A version of a product that differs by a specific attribute (e.g., size, color, voltage).