Back-end programming

DATA PERSISTENCE
DAtabases
What is a database?
A data is a piece or collection of information. By itself it might not mean anything concrete, and needs to be interpreted to become information.
A database is an organized collection of data.
This information is typically stored electronically in a computer system.
What is a database?
Currently, a computer database is usually controlled by a database management system (DBMS), and the data is written and queried using a structured query language (SQL).
The database and the DBMS software are usually referred to as the database system. These systems allow users to store, maintain and manipulate data.
Database evolution
Files and navigational databases such as the hierarchical database were the original systems used to store and manipulate data.
Although simple, these early systems were inflexible, so new systems arose which allowed for more specifications, such as database structure data relationships.
In the 80's, these relational databases became popular.

Database evolution
More recently, NoSQL databases appeared as a response to the need for faster speed and processing of unstructured data brought on by the popularization of the Internet.
It isn't uncommon for larger systems to use different types of data storage and database systems, in order to solve different problems with more effective solutions.
Database challenges
Database administrators face a few common challenges:
- Absorbing significant increases in data volume
- Ensuring data security
- Keeping up with demand
- Managing and maintaining the database and infrastructure
- Removing limits on scalability
Database Models
A database model determines the design and structure of a database. Through the years, different models emerged, such as:
- Flat model
- Hierarchical model
- Network Model
- Relational Model
- ... and others
Next
Let's take a closer look at some specific types of databases.
FLAT-FILE Database
Flat-file Database
A flat file is also known as a text database. It basically consists of a database that stores data in plain text format. These files usually contain one record per line, and are often created in spreadsheet format
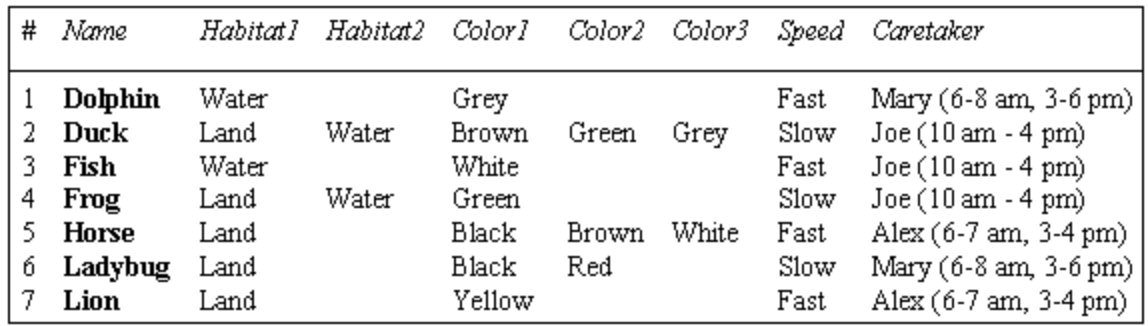
Flat-file Database
Relationships between entries are not explicitly defined in this type of database: it must be interpreted by a user.
It is still widely used in different formats, as it is quite simple and easy to use. Flat-file databases can be implemented using regular text files or spreadsheets (e.g., comma-separated values).
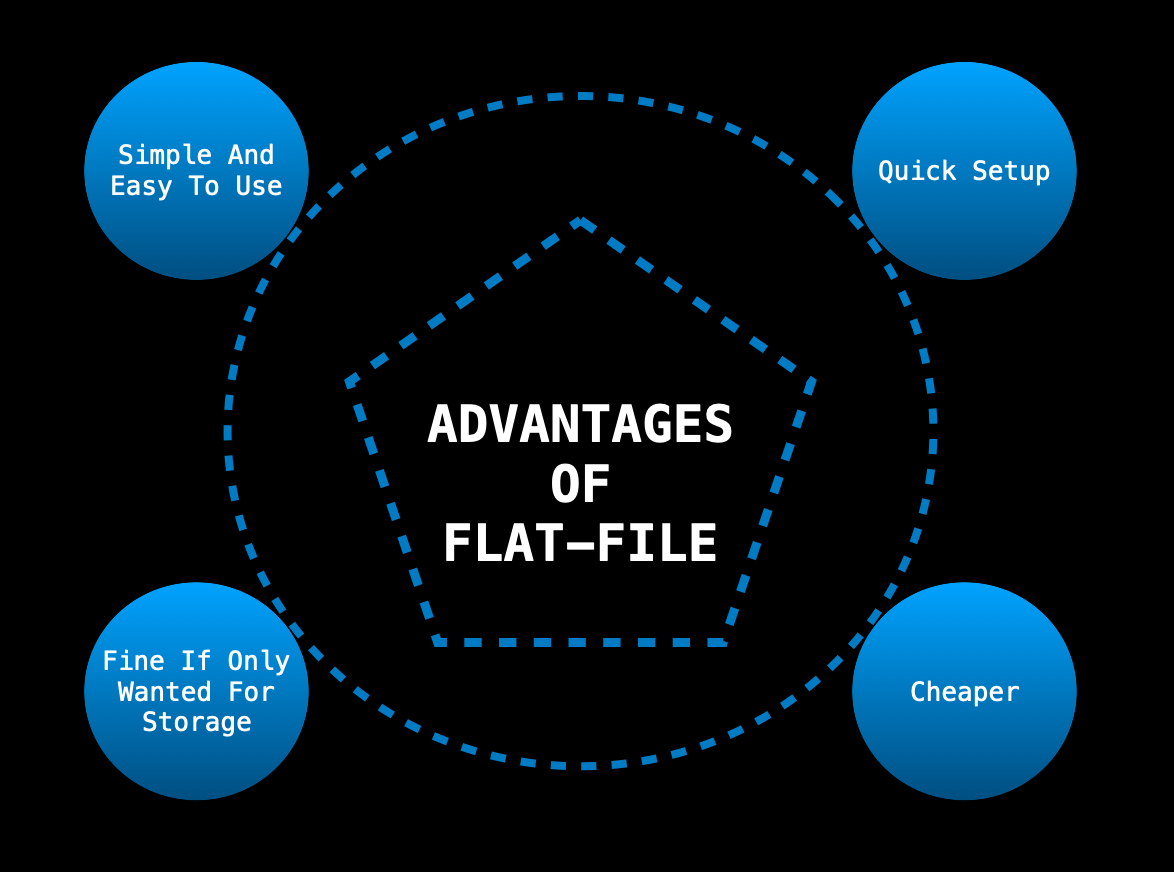
Flat-file Database ADVANTAGES
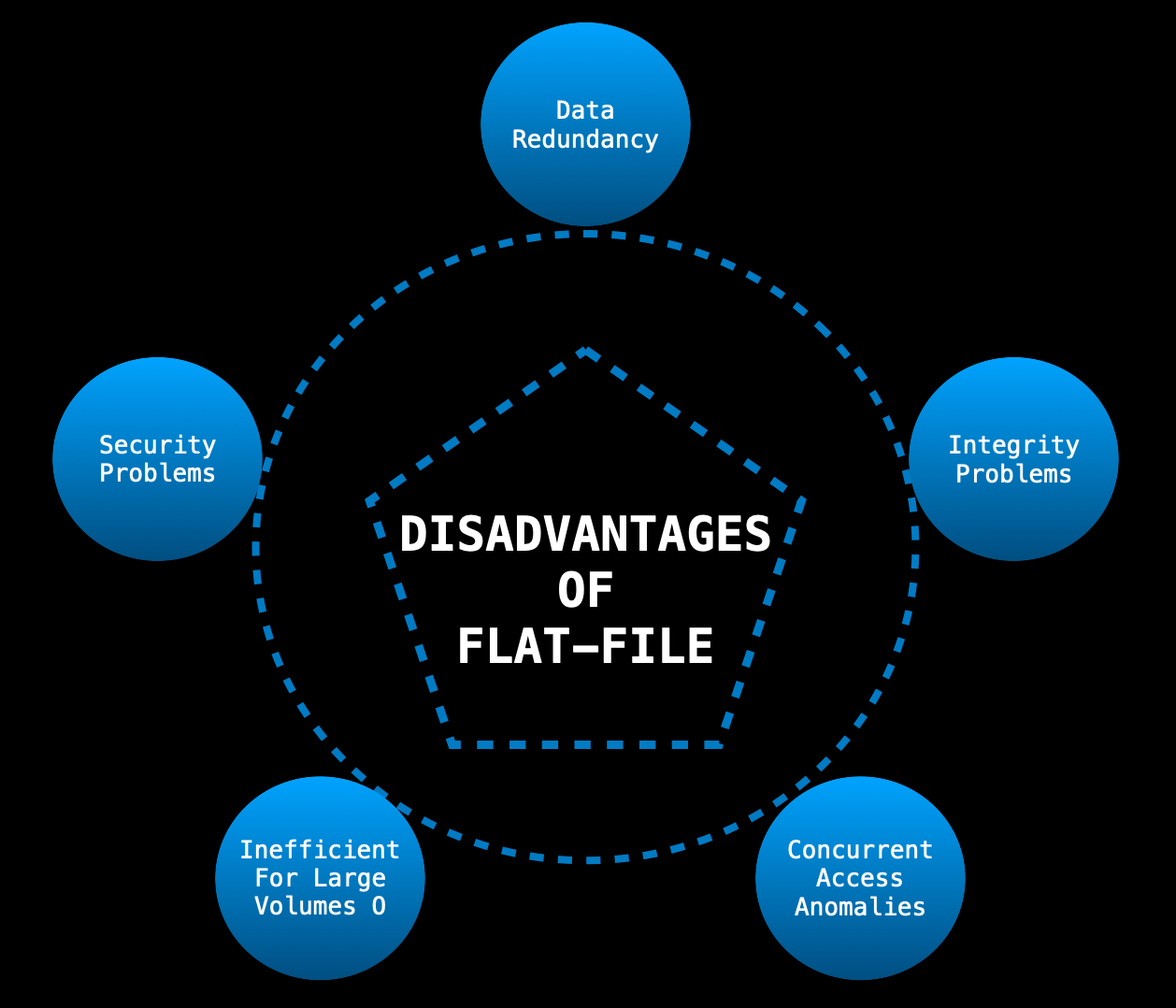
Flat-file Database DISADVANTAGES
Relational Database Management Systems
Relational Model
In the relational model, data is organized into tables, composed of rows and columns. Tables usually represent a type of entity, also called 'relation' (e.g., "User").
Each column corresponds to an attribute (e.g., "name"). Each row corresponds to an entry or tuple, with values for each attribute.
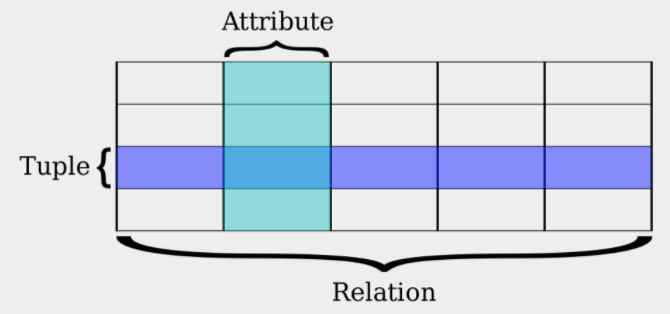
Relational Model
One or more columns can be defined as primary keys, that is, their value(s) could be used to uniquely identify a row or tuple.
These keys can then be used to make cross-references between tables, which establish relationships.
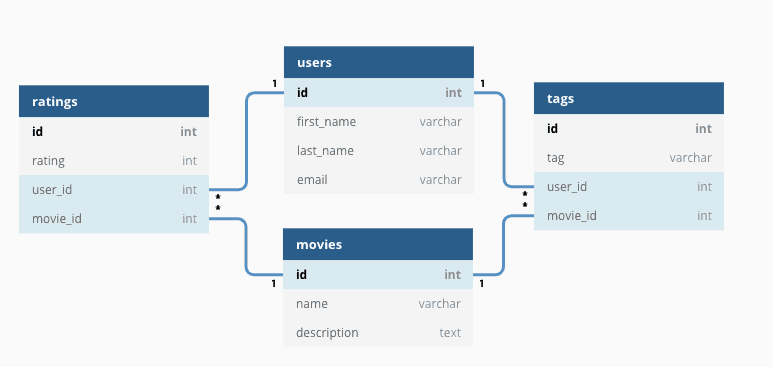
The values within each table are related to each other.
Tables may also be related to other tables.
Queries may be run across multiple tables at once.
Relational Database and schemas
A relational database structures data according to the relational model.
A database schema represents the definition and structure of a relational database, that is, its tables, columns, relationships, and all other elements.
A relational database can be managed and accessed using queries, through database management systems.
What are Relational Database Management Systems?
A DBMS is a software system that allows users to manage databases, more specifically:
- Defining and managing database structure
- Inserting, obtaining and updating data
- Defining and enforcing data constraints
A RDBMS is a DBMS specifically used for relational databases.



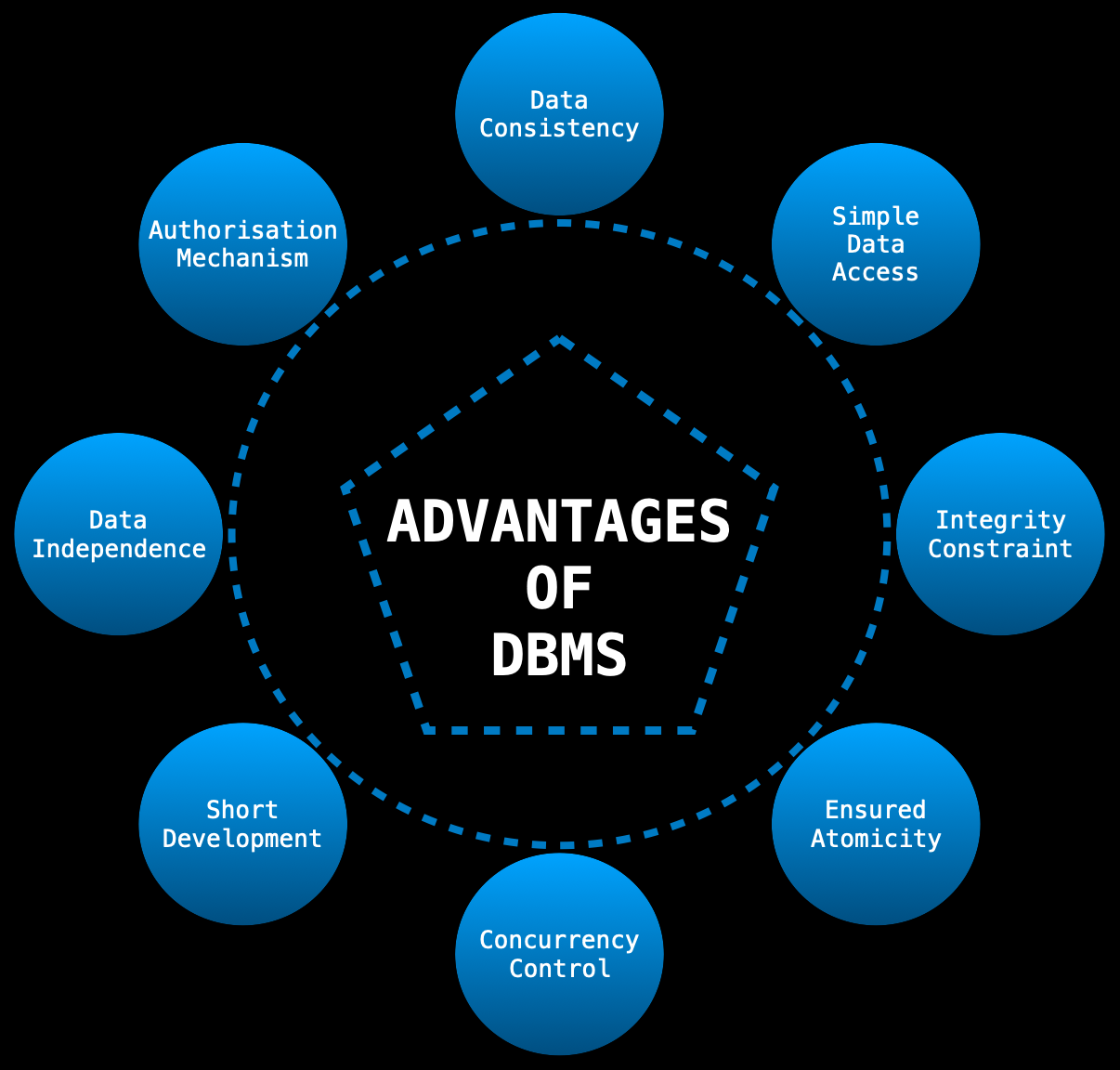
ADVANTAGES Of USING A DBMS
DISADVANTAGES OF USING A DBMS
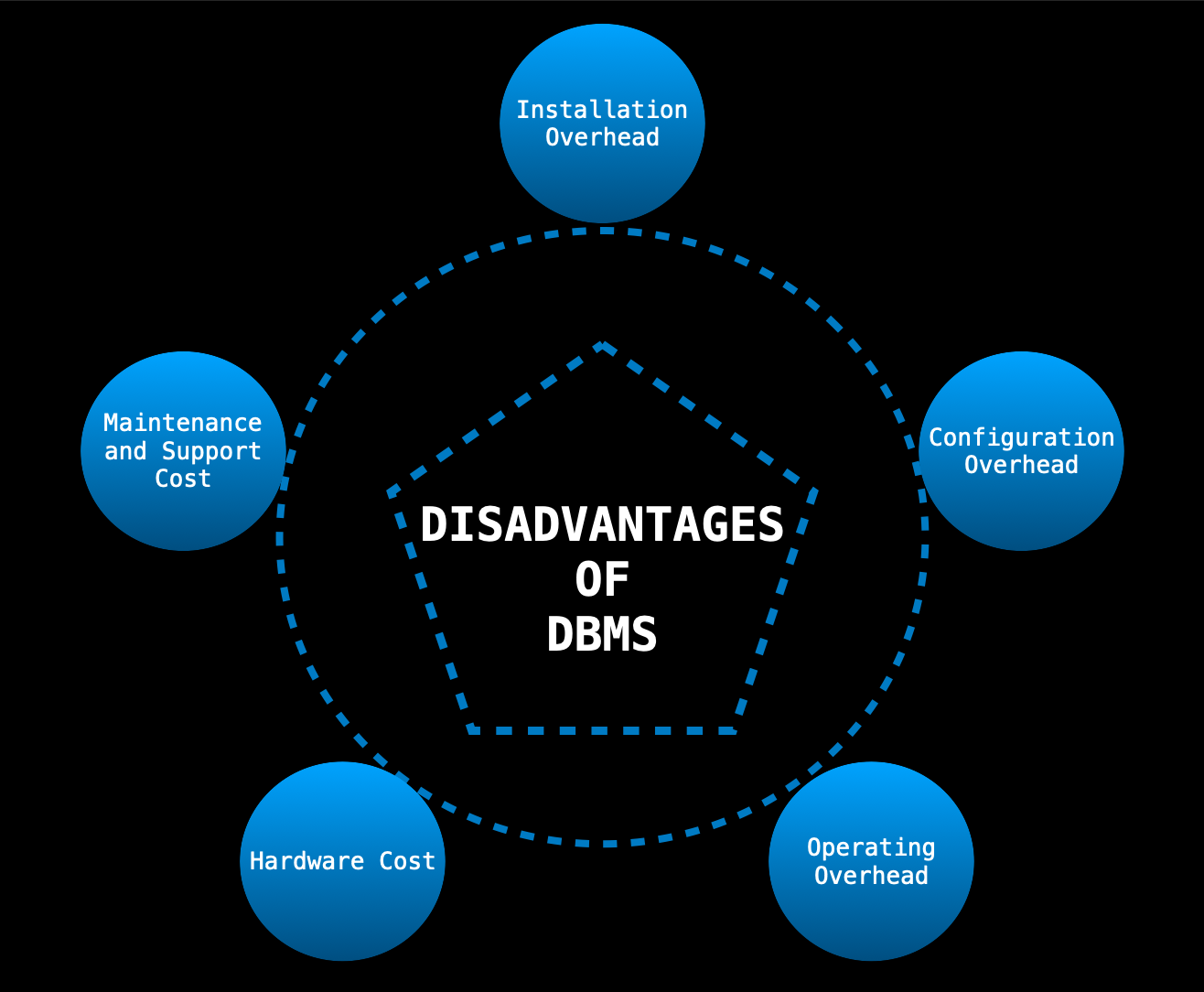
The need for usage of a DBMS should always be carefully evaluated.
NON-RelationAL DATABASES
WHAT ARE NON-RELATIONAL DATABASES?
Non-relational databases, often called NoSQL databases, store their data in a non-tabular form.
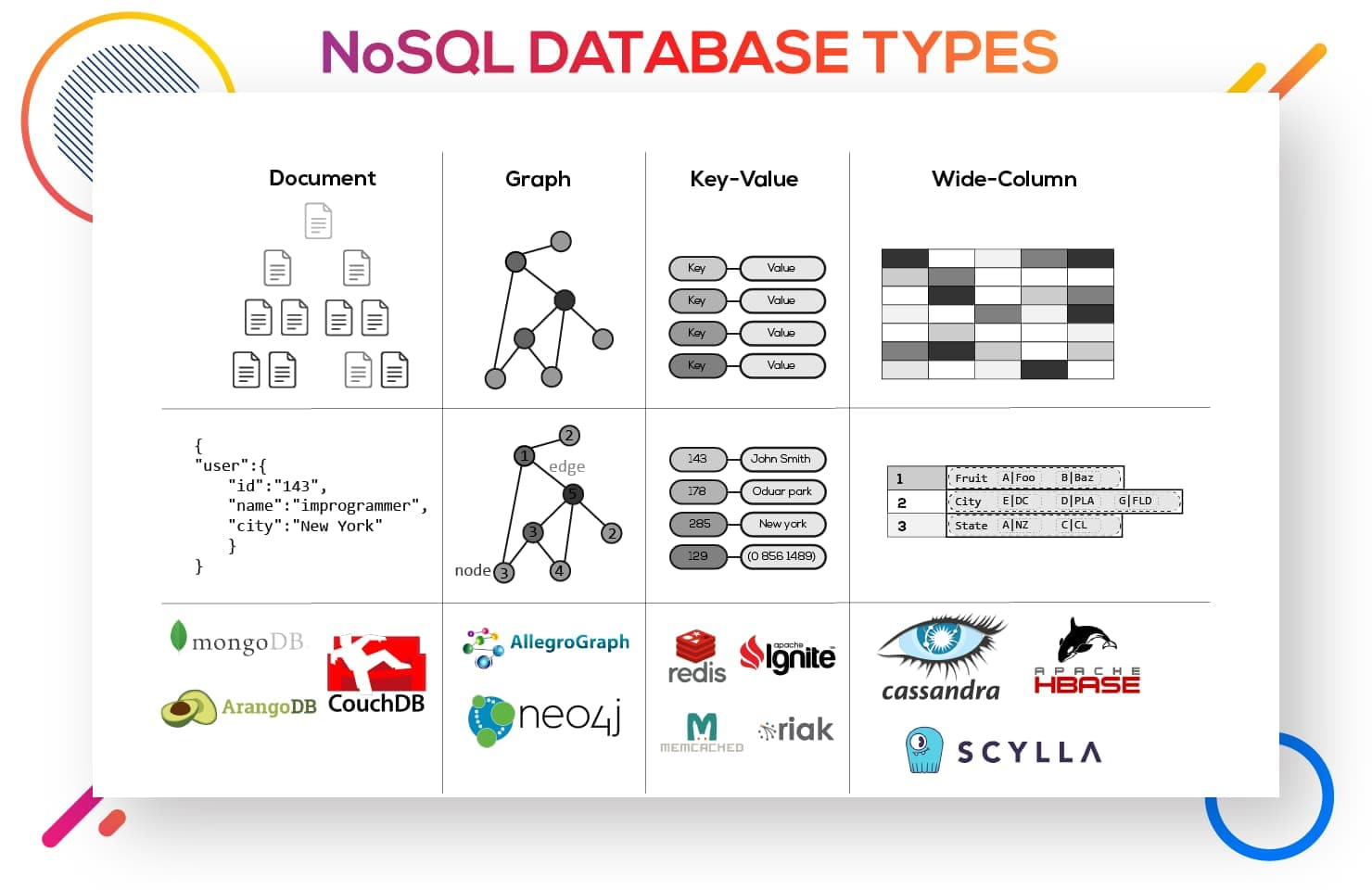
NoSQL databases come in a variety of types based on their data model.
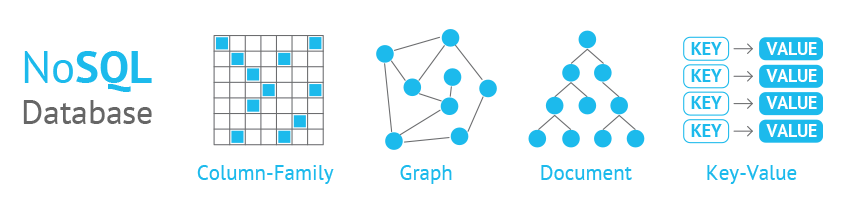
NoSQL databases provide flexible schemas and scale easily with large amounts of data and high user loads.
Popular nosql databases
ADVANTAGES OF NoQSL DATABASES
DISADVANTAGES OF NoQSL DATABASES
NEXT
For the rest of this lesson, we will mostly focus on RDBMS.
MYSQL
MYSQL
MySQL is:
- A RDBMS
- Open Source Software
- Fast, reliable, and easy to use
In 2021, MySQL remains the most popular Open Source SQL database management system.
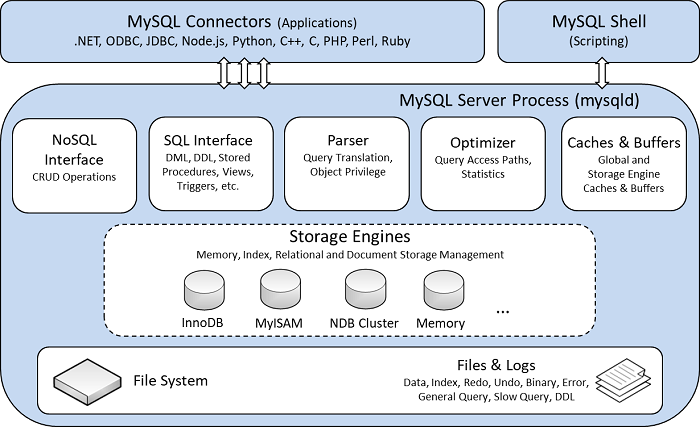
MYSQL STORAGE ENGINE ARCHITECTURE
EXERCISE
Installing and Configuring MySQL Server
LIVE CODING
Server Tutorial
// DATABASE CONNECTION
$ mysql -h host -u user -p
// HELP
$ mysql --helpTABLES
MYSQL TABLES
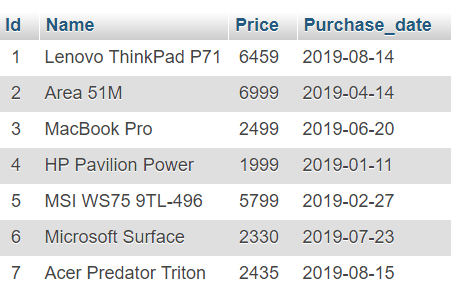
- Each table should have a unique name.
- Each field/attribute (column) should have a name and a value type. Column values can also be subject to constraints.
- Each row represents a record.
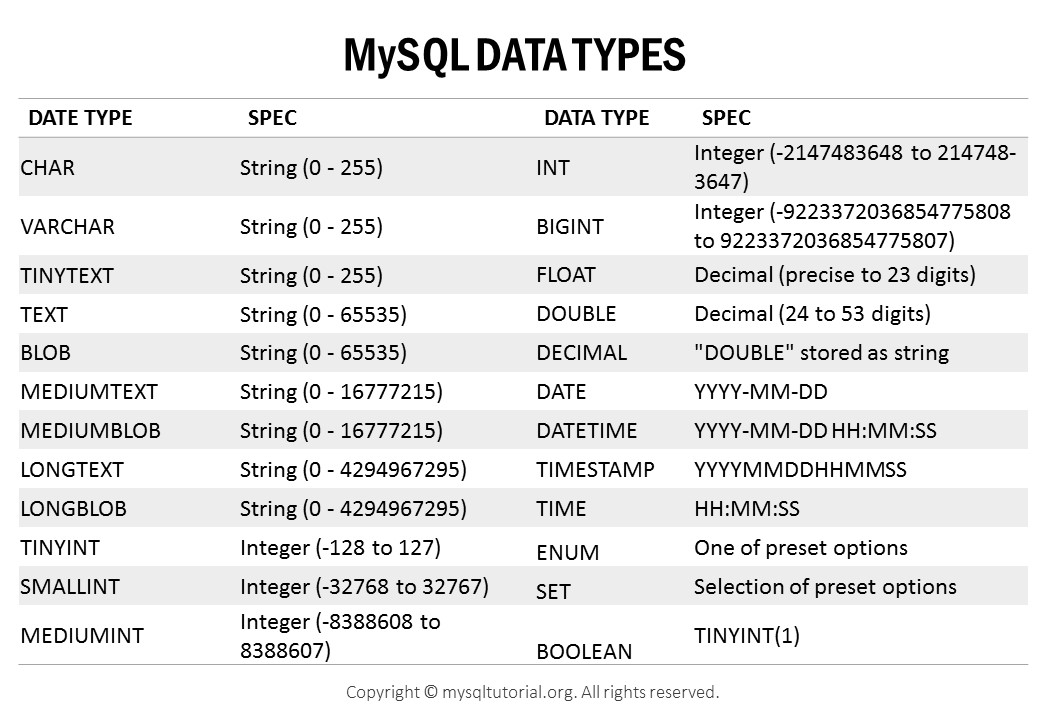
Data types
Constraints
| CONSTRAINT | DEFINITION |
|---|---|
| NOT NULL | Column cannot have null value |
| UNIQUE | All values in column are different |
| PRIMARY KEY | Combination of NOT NULL and UNIQUE. Uniquely identifies each row in a table. |
| FOREIGN KEY | Represents a relationship between tables |
| CHECK | Ensures that values in a column satisfy a specific condition |
| DEFAULT | Sets a default value if none is specified |
| CREATE INDEX | Used to retrieve data from the database more quickly |
PRIMARY KEYS
Every table must have a primary key.
This constraint uniquely identifies a table record.
| class_name | credits | classroom | instructor |
|---|---|---|---|
| Geometry | 5 | 306 | Georgia Miller |
| Advanced Calculus | 6 | 301 | Georgia Miller |
| Intro to Biology | 4 | 213 | Paul Stevens |
| Computer Science | 5 | 418 | Sarah Hughes |
| Political Science | 5 | 101 | Marty Greene |
What would be a good primary key here?
PRIMARY KEYS
| book_name | book edition | author | available |
|---|---|---|---|
| A Song Of Ice And Fire | 2 | George R. R. Martin | true |
| Circe | 1 | Madeline Miller | true |
| Ham On Rye | 5 | Charles Bukowski | false |
| Darkmans | 4 | Nicola Barker | false |
| Ham On Rye | 10 | Charles Bukowski | true |
What about here?
Composite PRIMARY KEYS
In the previous example there was no single attribute for a primary key.
In cases like this, we can follow one of two paths:
- Create an ID attribute
- Create a composite primary key.
Composite primary keys are composed of several attributes.
Composite PRIMARY KEYS
In the example above, assuming there would only be one copy of each book in a particular edition, the appropriate primary key would be composed of book_name and edition.
| book_name | book edition | author | available |
|---|---|---|---|
| A Song Of Ice And Fire | 2 | George R. R. Martin | true |
| Circe | 1 | Madeline Miller | true |
| Ham On Rye | 5 | Charles Bukowski | false |
| Darkmans | 4 | Nicola Barker | false |
| Ham On Rye | 10 | Charles Bukowski | true |
TABLE CREATION
// TABLE CREATION
CREATE TABLE my_table(
column1 DATATYPE [ CONSTRAINT ] ,
column2 DATATYPE [ CONSTRAINT ] ,
PRIMARY KEY (column1, column 2)
);
// OR
CREATE TABLE my_table(
column1 DATATYPE [ CONSTRAINT | PRIMARY KEY ] ,
column2 DATATYPE [ CONSTRAINT ]
);LIVE coding
The Car-Rental Database

(Table creation)
FOREING KEYS
A foreign key is an attribute that creates a relationship between two tables.
Their purpose is to maintain data integrity and allow navigation between two different instances of an entity
| dept_code | dept_name |
|---|---|
| 001 | Science |
| 002 | English |
| 003 | Computer |
| 004 | History |
| teacher_id | first_name | last_name |
|---|---|---|
| 0923 | David | Lee |
| 1423 | Grace | Mason |
| 2390 | Thea | Fowler |
| 2483 | Zack | Brenton |
How would you relate these two tables?
Table Relationships
In a relational database, a relationship is formed by correlating rows belonging to different tables. This relationship is also known as cardinality.
There three 3 types of relationships:
- one-to-many
- one-to-one
- many-to-many
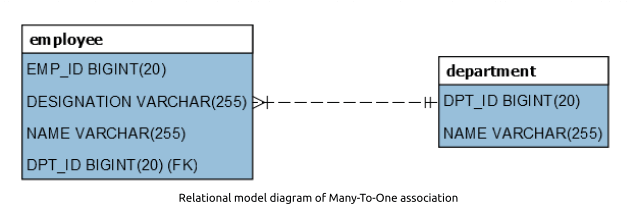
One to Many
The most common relationship.
It associates a row from a parent (one) table to multiple rows in a child (many) table.
One to one
Associates one row from on table to a single row on the other table. One table serves as the parent table, the other one as the child.
This is a special kind of relationship because it is the only one in which both tables may share the same primary key.
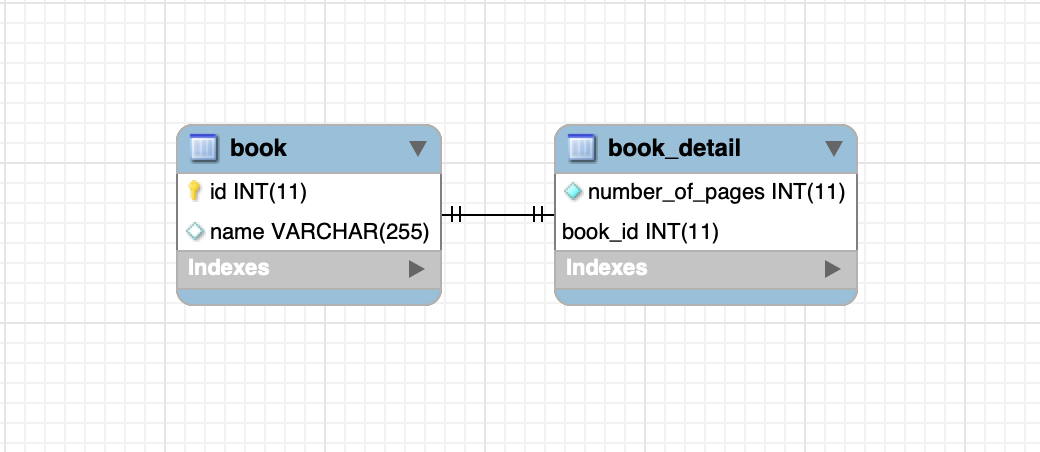
many to many
Associates multiple rows from the parent table to multiple rows from the child table.
Requires a linking-table containing two foreign key columns that reference the two different parent tables.
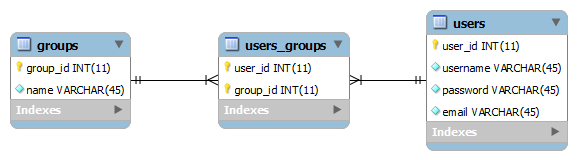
table creation with foreign key
// TABLE CREATION
CREATE TABLE my_table(
column1 DATATYPE [ CONSTRAINT ] ,
column2 DATATYPE [ CONSTRAINT ]
PRIMARY KEY (column1),
FOREIGN KEY (column2) REFERENCES mytable2(column1)
);
// OR
CREATE TABLE my_table(
column1 DATATYPE [ CONSTRAINT | PRIMARY KEY ] ,
column2 DATATYPE [ CONSTRAINT | FOREIGN KEY (column2) REFERENCES mytable2(column1)]
);SCHEMA
A database schema is the collection of table schemas for the whole database.

Some programs like MySQL Workbench allow you to visually design, model, generate, and manage databases.
Exercise
The Car-Rental Database
(Establishing relationships)
In this exercise you should:
- Create the cars table
- Create the clients table
- Create a rentals table
- Establish the necessary relationships
TABLE OPERATIONS
structured query language
SQL is a programming language used to query, manipulate, and define data in databases.
Major commands include:
- INSERT
- SELECT
- UPDATE
- DELETE

INSERT
When adding values for all the columns of the table, we don't need to specify the column names.
INSERT INTO mytable(column1, column2)
VALUES (column1_value, column2_value);INSERT INTO mytable
VALUES (column1_value, column2_value);SELECT
Selecting all attributes from a table.
// SELECTING EACH COLUMN
SELECT column1, column2 FROM mytable;
// SELECTING ALL COLUMNS
SELECT * FROM mytable;SELECT column1 FROM mytable;Selecting one attribute from a table.
SELECT
Selecting all attributes from a table.
// SELECTING EACH COLUMN
SELECT column1, column2 FROM mytable;
// SELECTING ALL COLUMNS
SELECT * FROM mytable;SELECT column1 FROM mytable;Selecting one attribute from a table.
UPDATE
UPDATE table
SET column1=column1_value
WHERE column2=column2_value;ALTER TABLE mytable
ADD column3 DATATYPE [ CONSTRAINTS ]Updating the table schema is a little bit different:
DELETE
Delete specific records:
DELETE FROM mytable WHERE column=column_value;Delete all data from a table:
DELETE FROM mytable;Delete the table itself:
DROP TABLE mytableDelete the database itself:
DROP DATABASE mydatabaseExercise
The Car-Rental Database
(Populating the Database)
In this exercise you should:
- Populate the clients table
- Populate the cars table
- Populate the rentals table
MORE ON DATABASE QUERIES
Select queries always return a result-set.
The beauty of select queries is in the conditional clauses.
WHERE CLAUSE
SELECT * FROM mytable
WHERE { condition };The where clause can also be used in update and delete statements.
WHERE CLAUSE OPERATIONS
| OPERATOR | DESCRIPTION |
|---|---|
| = | Equal |
| >, >= | Greater than (or equal) |
| <, <= | Less than (or equal) |
| != | Not equal |
| BETWEEN | Between a certain range |
| LIKE | Search for a pattern |
| IN | Specify multiple possible values |
You can also use AND, OR, and NOT operators.
Exercise
The Car-Rental Database
(Query the Database)
In this exercise you should:
- List all the cars manufactured before 2020
- List all cars with hourly price between 4 and 6
- List all client names that start with A
- List all the active rentals
SQL Functions
SELECT COUNT(column_name) FROM mytable
WHERE { condition };COUNT() returns the number of rows that match the specified criteria.
SELECT AVG(column_name) FROM mytable;AVG() returns the average value of a numeric column.
SELECT SUM(column_name) FROM mytable;SUM() returns the total sum of a numeric column.
SQL Functions
MIN() returns the smallest value of the selected column.
SELECT MAX(column_name) FROM mytable;MIN() returns the highest value of the selected column.
SELECT MIN(column_name) FROM mytable;ORDER BY
SELECT column1, column2 FROM mytable
ORDER BY column1, column2 { ASC|DESC };Used to sort the result-set in ascending or descending order.
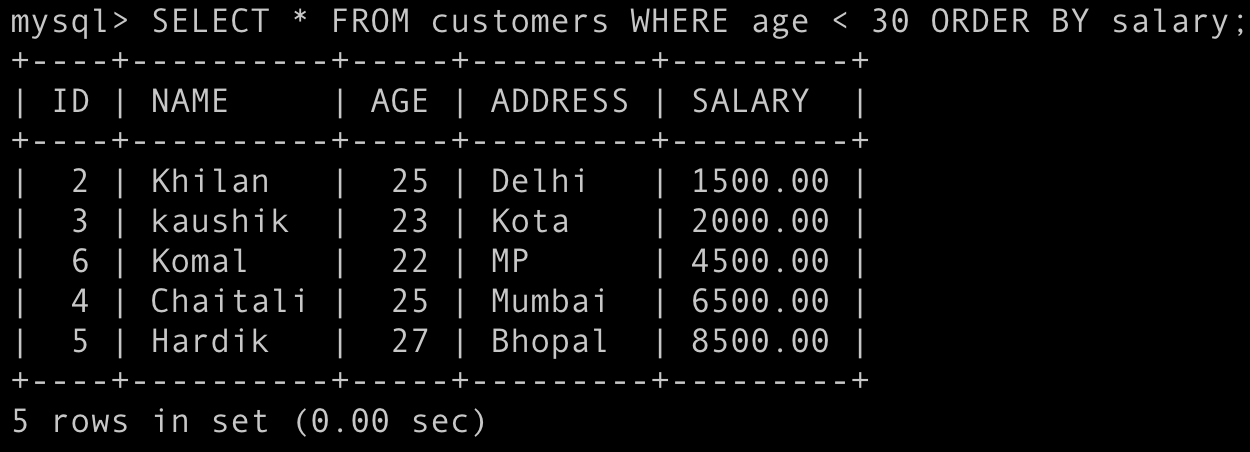
SQL ALIASES
SELECT column_name AS alias_name FROM mytable;
Used to give a table, or a column in a table, a temporary name.
An alias only exists for the duration of that query.
JOINING TABLES
A join clause is used to combine rows from two or more tables, based on a related column between them.
There are 4 different types of joins:
- Inner Join
- Left Join
- Right Join
- Full Join
JOINING TABLES - EXAMple
SELECT column_name
FROM mytable1
INNER JOIN mytable2
ON mytable1.column_name = mytable2.column_name;
// A REAL EXAMPLE:
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id;As a result of the query above, we will have a table with the order IDs related to the customers names.
a few Extra operators
SELECT DISTINCT column_name
FROM mytable1
WHERE { condition }
GROUP BY { grouping-columns }
HAVING { condition }DISTINCT - used to return only different (distinct) values
Example query: "Find all the countries in the database"
GROUP BY - groups rows that have the same values
Example query: "Find the number of customers in each country"
HAVING - Functions as WHERE, except WHERE can't be used with aggregate functions.
a few Extra operators II
WITH temporarytable AS (
SELECT DISTINCT column_name
FROM mytable1)
SELECT * FROM temporarytable
LIMIT { number }WITH - Lets us store the result of a query in a temporary table, using an alias.
LIMIT - Lets us specify the maximum number of rows of the result set
Exercise
The Car-Rental Database
(Query the database... Again.)
In this exercise you should:
- Find the number of cars manufactured after 2019
- List the car plates of the cars that were rented more than once
- List the rental ids, associated with the name of the customers who rented the cars
OTHER OPERATIONS
STored procedures
A batch of SQL statements that you can group as a logical unit, so they can be reused over and over again. Stored procedures are useful when whenever we have a series of SQL statements that we often repeat.
DELIMITER //
CREATE PROCEDURE myProcedure
( { statements } );
END //
DELIMITER ;Stored procedures are easily modified, and fairly secure and performant.
However, they are often platform-specific, and separate the data access logic from the application itself.
TRIGGERS
A special type of stored procedure that automatically runs when a certain event occurs in the database server.
DELIMITER //
CREATE TRIGGER mytrigger
{BEFORE / AFTER / INSTEAD OF } { action } ON mytable
FOR EACH ROW
BEGIN
{ statement }
END //
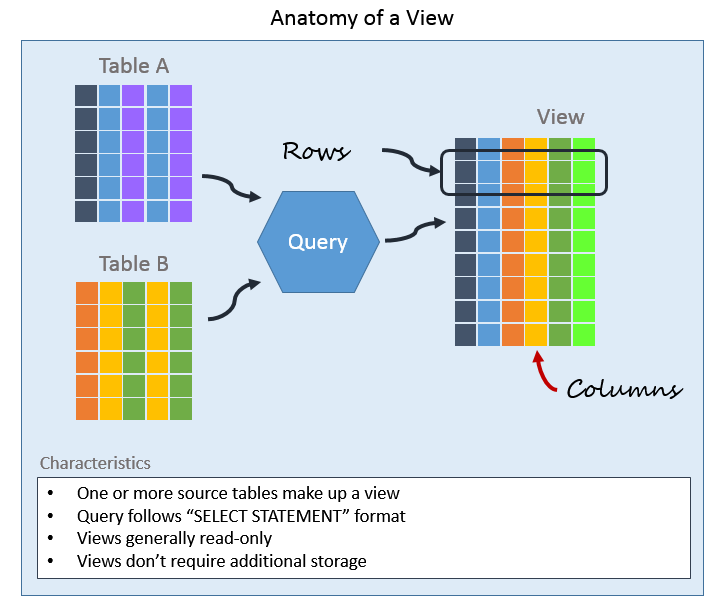
DELIMITER ;views
A view is a virtual table based on the result set of an SQL statement.
The CREATE VIEW statement works very similar to the WITH clause, except the first actually creates an object in the database.
CREATE VIEW myview AS
SELECT { columns }
FROM mytable1
WHERE { condition };WHY views?
SECURITY - Views can be made accessible to users while the underlying tables are not directly accessible.
SIMPLICITY - Views can be used to hide and reuse complex queries.
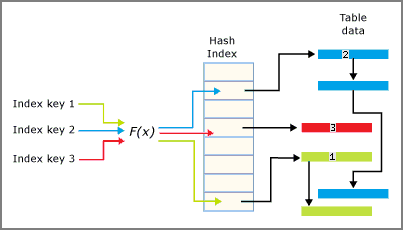
INDEXES
Indexes are used to retrieve data from the database more quickly.
CREATE INDEX myindex
ON mytable1 { columns };An index helps to speed up SELECT queries and WHERE clauses, but it slows down data input.
DATABASE DESIGN
What is database design?
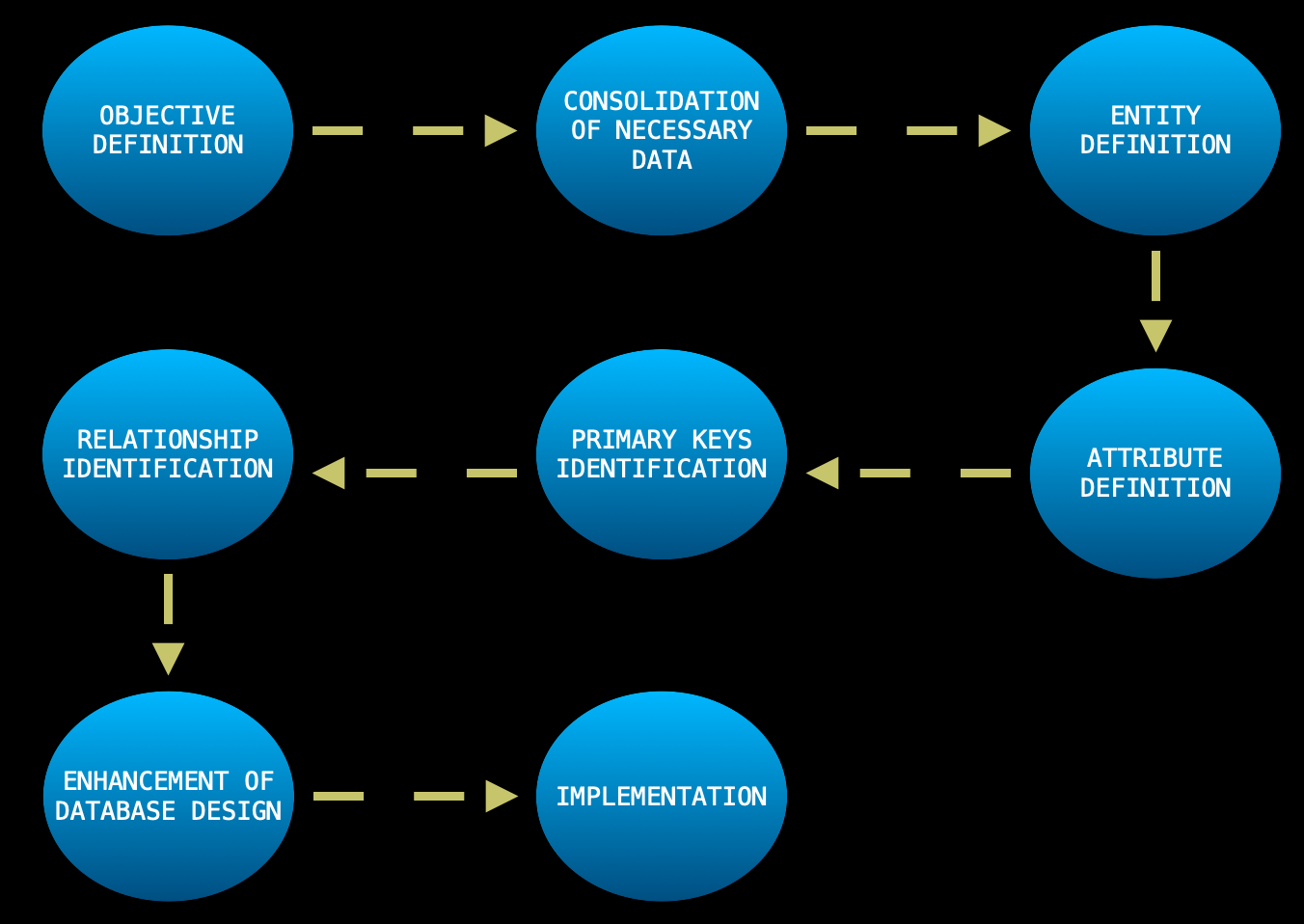
Database design is a set of steps that help with designing, creating, implementing and maintaining it.
A well-designed database contains accurate and up-to-date information, allowing data to be fetched easily whenever needed.
Good database design
BAD database design
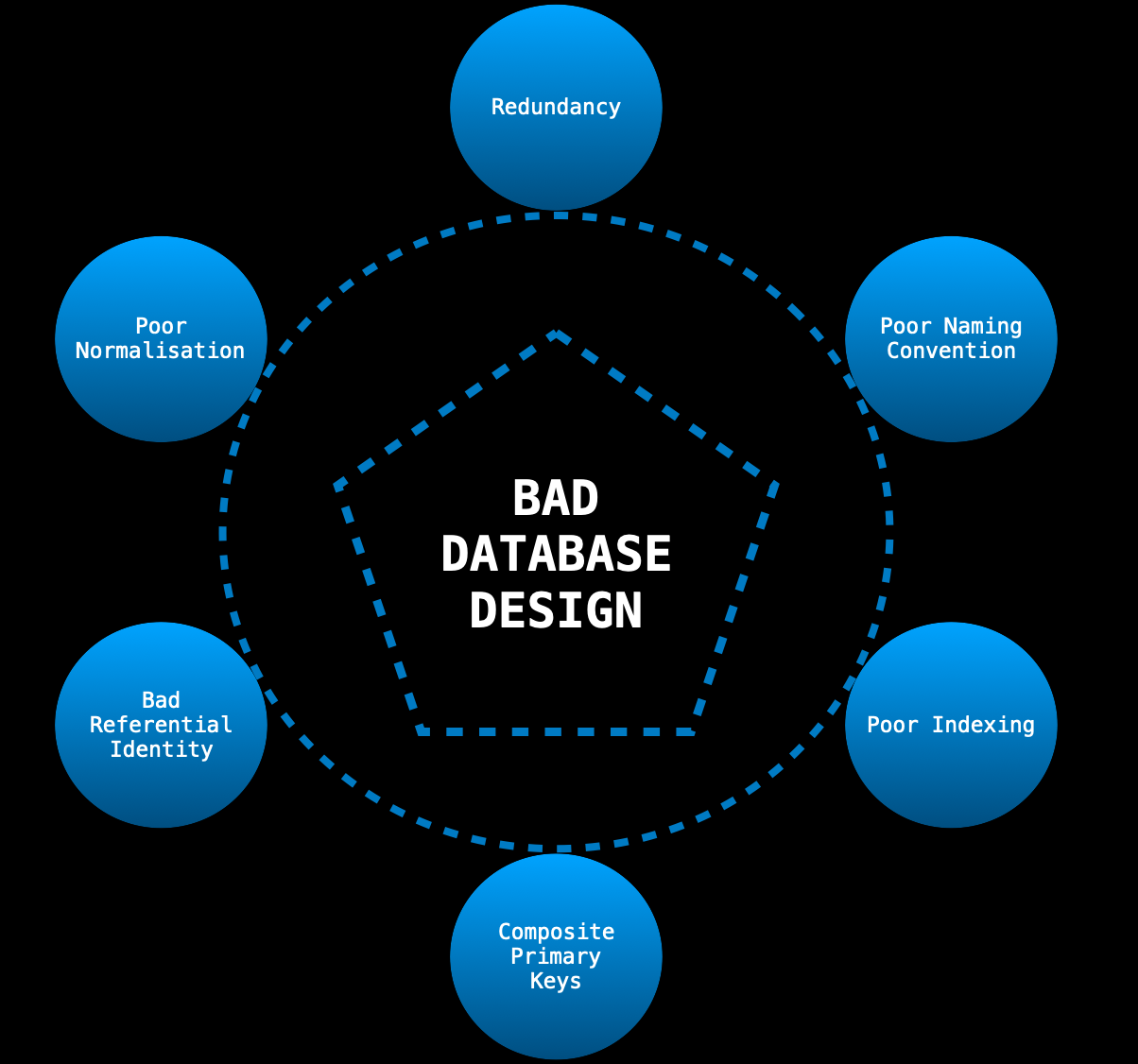
database development STEPS
database NORMALIZATION
A set of rules designed to organize data in a database in a way that protects the data and, at the same time, makes the database more flexible by eliminating redundancy and inconsistent dependency.
Each rule is called a "normal form".
If the database is designed in a way that respects the first rule, we say it's in the first normal form.
Third normal form is considered a satisfactory database design for most applications.
First normal form
1. An attribute on a table should not hold multiple values
2. Each row should be uniquely identified by a primary key
| student_id | first_name | last_name | languages |
|---|---|---|---|
| 2340 | Ursula | Granger | Java, C++ |
| 2431 | Dean | Cooper | PHP, Python |
| 2478 | Archie | Mueller | Java |
Is this table in the 1NF?
First normal form
| student_id | first_name | last_name | languages |
|---|---|---|---|
| 2340 | Ursula | Granger | Java |
| 2340 | Ursula | Granger | C++ |
| 2431 | Dean | Cooper | PHP |
| 2431 | Dean | Cooper | Python |
| 2478 | Archie | Mueller | Java |
SECOND normal form
1. It's in the 1NF
2. Every non-key attribute is functionally dependent on the Primary Key.
Is this table in the 2NF?
| student_id | first_name | last_name | languages |
|---|---|---|---|
| 2340 | Ursula | Granger | Java |
| 2340 | Ursula | Granger | C++ |
| 2431 | Dean | Cooper | PHP |
| 2431 | Dean | Cooper | Python |
| 2478 | Archie | Mueller | Java |
SECOND normal form
| student_id | first_name | last_name |
|---|---|---|
| 2340 | Ursula | Granger |
| 2340 | Ursula | Granger |
| 2431 | Dean | Cooper |
| 2431 | Dean | Cooper |
| 2478 | Archie | Mueller |
| student_id | languages |
|---|---|
| 2340 | Java |
| 2340 | C++ |
| 2431 | PHP |
| 2431 | Python |
| 2478 | Java |
Third normal form
1. It's in the 2NF
2. Transitive dependencies of non-key attributes on any key should be removed.
Are these tables in the 3NF?
| student_id | first_name | last_name |
|---|---|---|
| 2340 | Ursula | Granger |
| 2340 | Ursula | Granger |
| 2431 | Dean | Cooper |
| 2431 | Dean | Cooper |
| 2478 | Archie | Mueller |
| student_id | languages |
|---|---|
| 2340 | Java |
| 2340 | C++ |
| 2431 | PHP |
| 2431 | Python |
| 2478 | Java |
should we continue?
Maybe; there is still a little bit of repetition in our tables.
But is the current design sufficient for what we need to do? If it is, there's no need to continue normalising our database.
Exercise
The MindSwap Database
We need a database to save data regarding the MindSwap students. Typical queries done to this database include:
- How many students enrolled in the first edition?
- Did any student ever make a presentation on the Builder Design Pattern?
- How many presentations were made on Linus Torvalds?
- How many presentations are scheduled but yet to be presented?
- Which teachers were present during the Alan Turing presentations?
- How many workshops were lectured on the first edition?
- Which teacher lectured the first Security workshop?
DATABASE CONCURRENCY
Database concurrency
Database concurrency is the ability of a database to allow multiple users to affect multiple transactions.
The ability to offer concurrency is unique to databases, compared to other forms of data storage, like files.
As we know, with concurrency comes efficiency but also problems...
Transactions
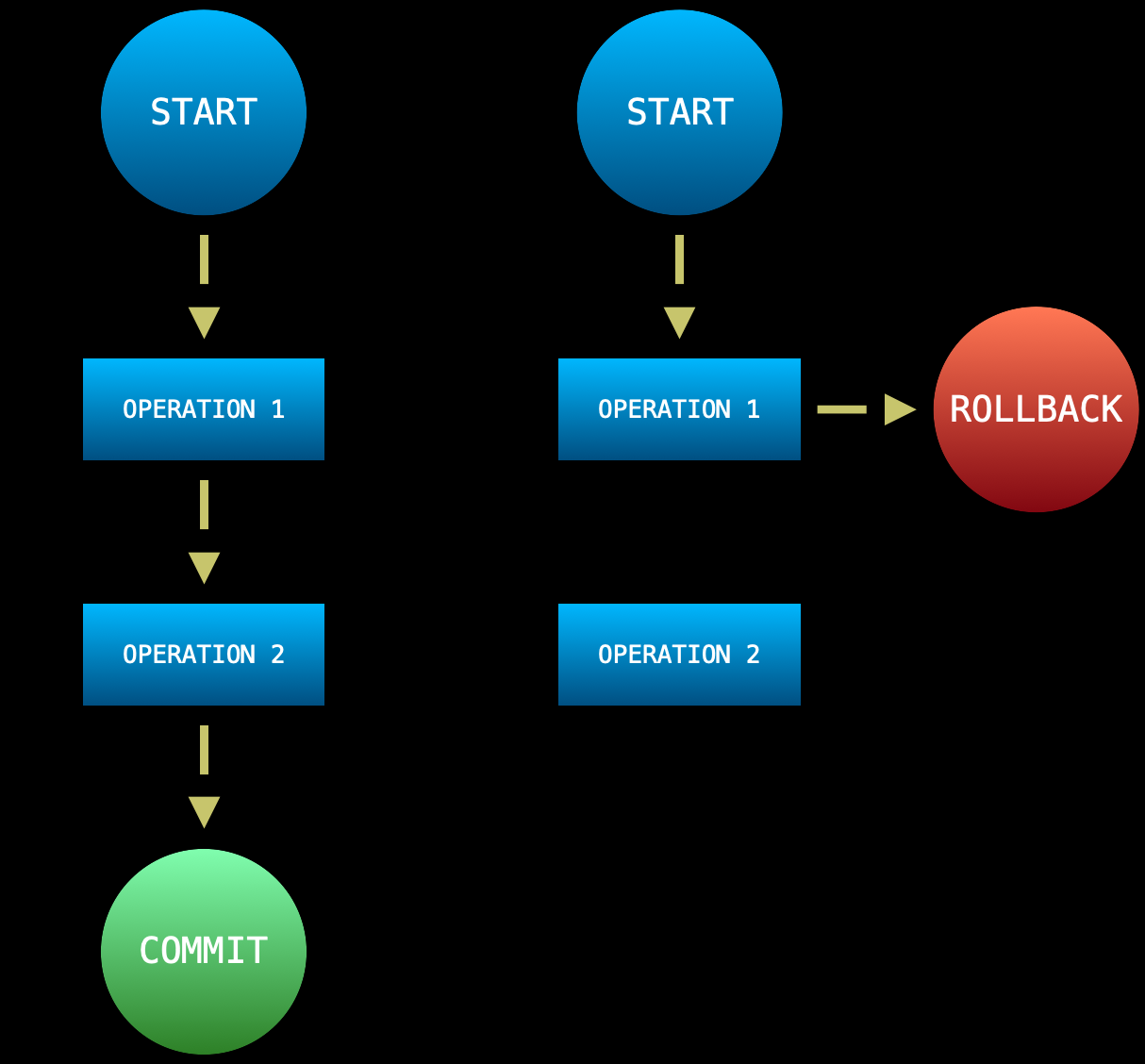
A transaction is a logical, atomic unit of work that contains one or more SQL statements.
Each transaction performs in an all-or-nothing proposition: either each statement completes its execution, or none will have any effect.

- Read
- Calculate
- Write
TRansactions - pattern
ACID PROPERTIES
All database transactions obey the ACID properties.
ACID is an acronym for the following:
- Atomicity
- Consistency
- Isolation
- Durability

atomicity
All tasks of a transaction are performed or none of them are. There are no partial transactions.
Why do transactions fail?
- Hardware errors
- Network errors
- Application software errors
- User interrupts the transaction
consistency
The transaction takes the database from one consistent state to another consistent state
Any data that is written to the database must be validated according to all restrictions (keys, foreign keys, cascades, triggers, etc.). Note that this property isn't related to the correctness of your application's logic.
Example: in a banking transaction that debits an account and credits another account, a failure must not cause the database to alter only one account.
isolation
The effect of a transaction is not visible to other transactions until the transaction is committed.
Example: one user updating a table does not see the uncommitted changes to that table made concurrently by another user.
durability
Changes made by committed transactions are permanent.
After a transaction completes, the database ensures through its recovery mechanisms that changes from the transaction are not lost. Changes are kept in a log.
PESSIMISTIC LOCKING
The pessimistic locking mechanism is provided by the RDBMS itself. It locks the record while it's being read/updated.
Locks are released when the transaction is committed/rolled back.
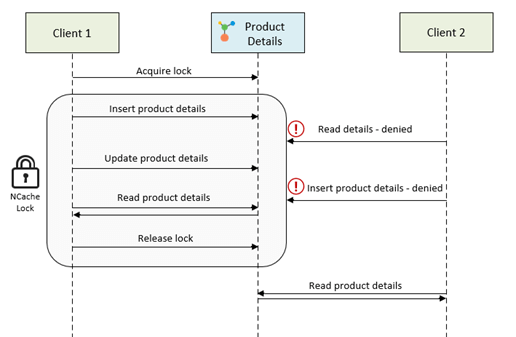
OPTIMISTIC LOCKING
Pessimistic locking doesn't allow for much concurrency.
The solution is to use an optimistic locking mechanism. This mechanism involves the introduction of a version attribute.
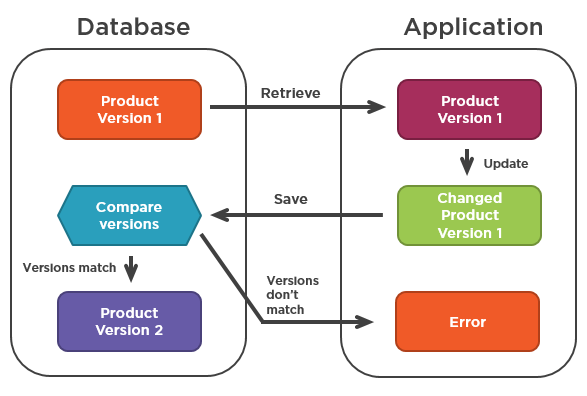
Live coding
Database Transactions
OBJECt-Relational IMPEDANCE MISMATCH
Object-oriented vs. relational
The way that object-oriented languages deal with data is fundamentally different from the way data is dealt with in the relational world.
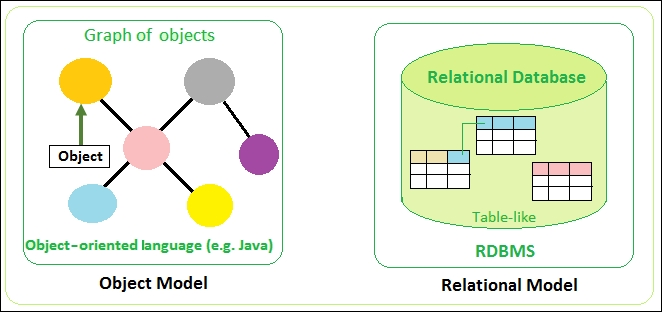
This leads to some mismatch problems.
Object-relational impedance mismatch
Loading and storing graphs of objects using a tabular relational database exposes us to 5 mismatch problems:
- GRANULARITY
- SUBTYPES
- IDENTITY
- ASSOCIATIONS
- DATA NAVIGATION
GRANULARITY
Granularity refers to the extent to which a system can be broken down into smaller parts.
Sometimes you will have an object model which has more classes than the number of corresponding tables in the database.
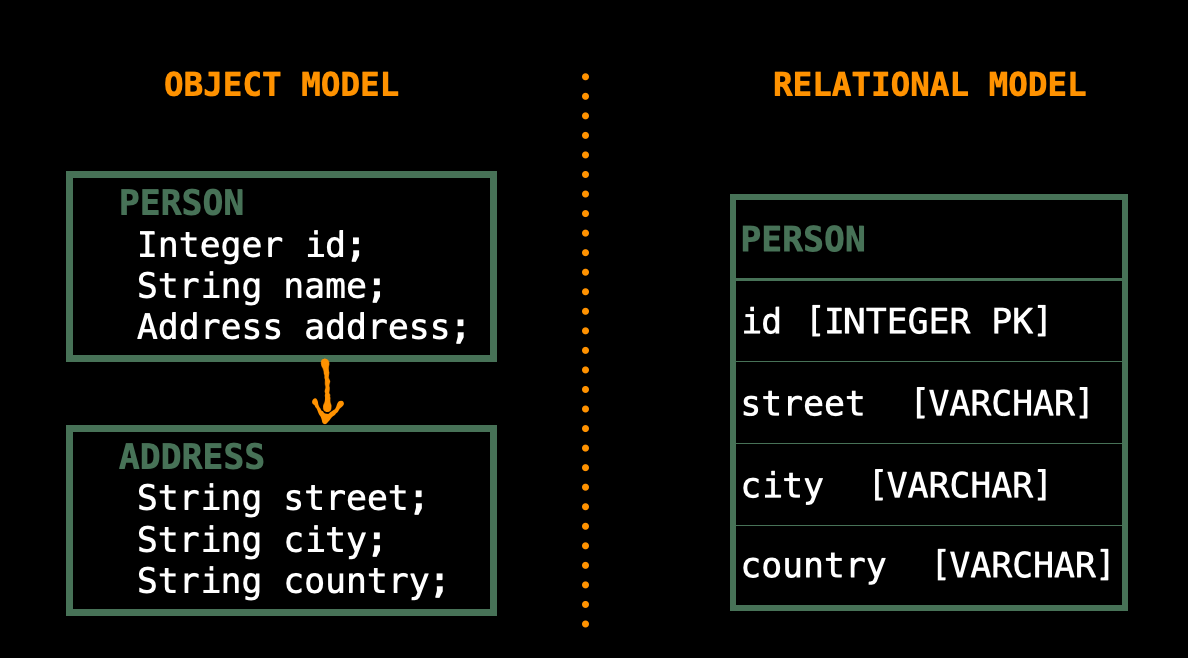
Subtypes
Inheritance is natural in object-oriented programming languages. However, RDBMSs do not define anything similar.
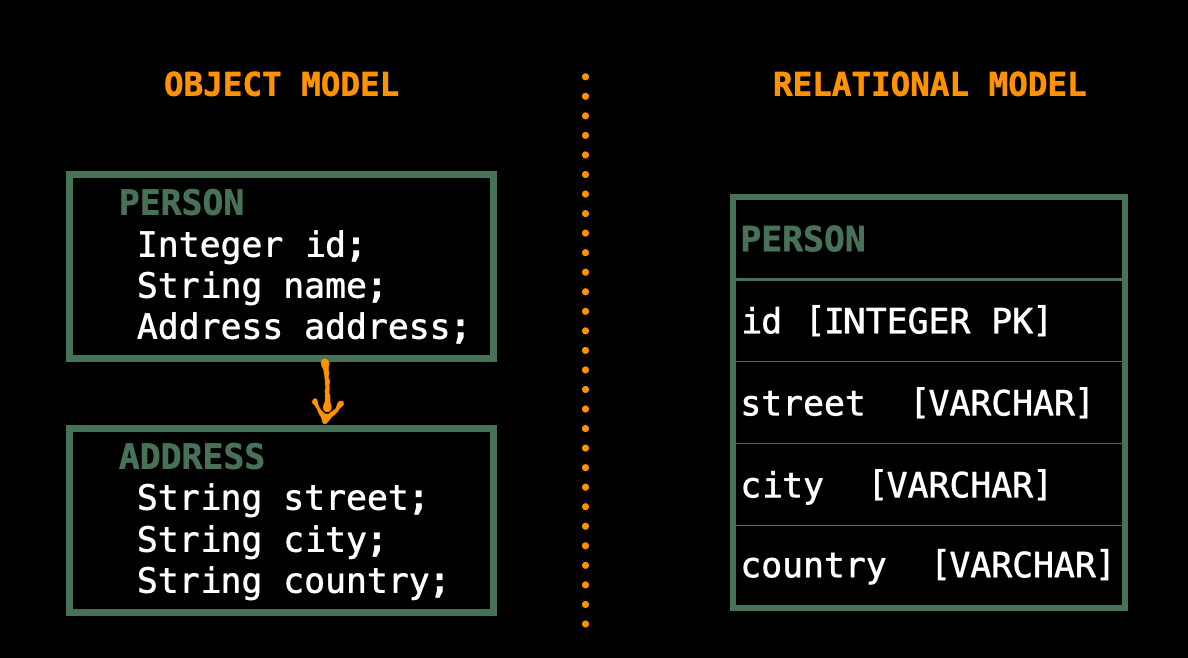
Identity
A RDBMS defines one notion of equality: the primary key.
In Java, we have both object identity (a==b) and object equality (a.equals(b)).
associations
Associations are represented as unidirectional references in object-oriented languages, whereas RDBMSs use the notion of foreign keys.
If bidirectional relationships are needed in Java, we must define the association twice.
Foreign key associations, however, are bidirectional in themselves.
data navigation
The way we access objects in Java and in RDBMS is very different.
In Java , we navigate from one association to another walking through the object graph. This is not an efficient way of retrieving data from a relational database.
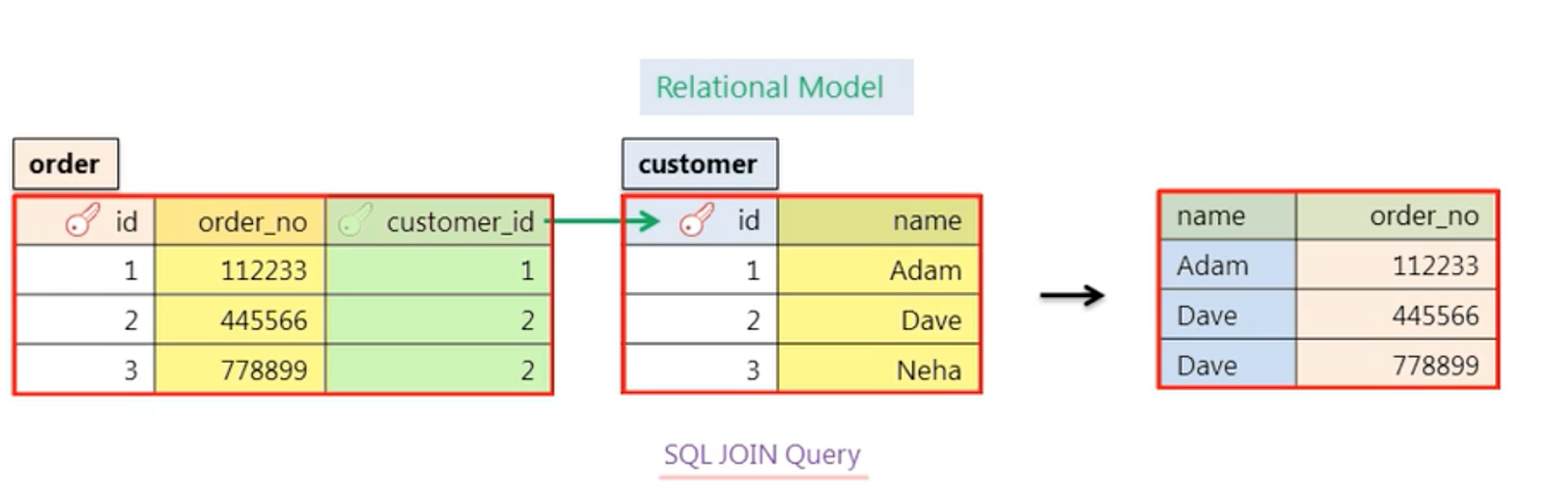
Minimizing SQL queries is crucial to a good performance. If we want to get data from more than one table, we write a SQL join query.
NEXT
We've taken a look at the problems a developer faces when it's time to connect a database system to a Java application, but... How do we solve them?
There are a few software pieces that help us with this task.
java database connectivity
jAva database connectivity
JDBC is a Java API for database connectivity. JDBC allows us to:
- Connect to the database
- Create SQL statements
- ExecuteSQL queries in the database
- View and modify the returned result sets
All these actions are possible with the use of a JDBC driver to access the database.
JDBC ARCHITECTURE
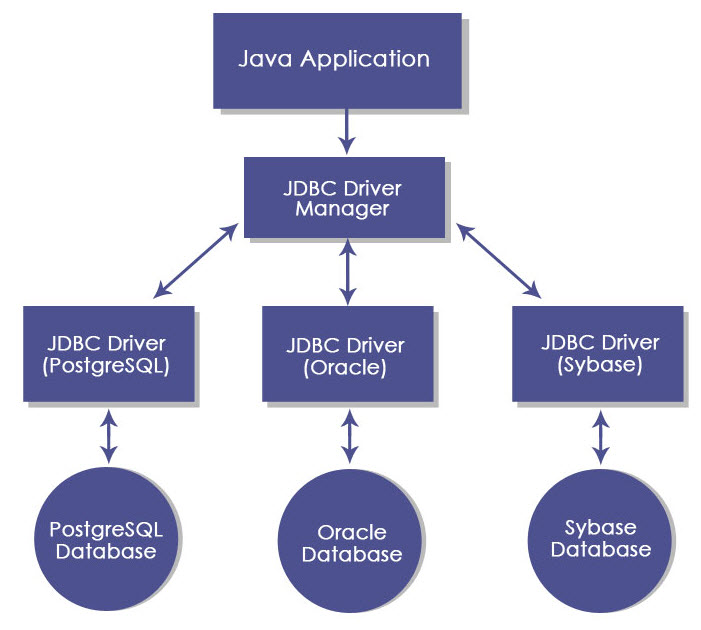
The Driver Manager manages a list of database drivers. It matches connection requests from the Java application with the proper database driver.
The Driver handles communications with the database server.
The data source is specified by a database URL that contains information regarding the name, location, and configuration properties of the database to connect to.
establishing a connection
public Connection getConnection() {
String dbURL = "jdbc:mysql://localhost:3306/myDatabase";
String username = "root";
String password = "";
Connection connection = null;
try {
connection = DriverManager.getConnection(dbURL, username, password);
} catch (SQLException ex) {
System.out.println("Connection failed: " + ex.getMessage());
}
return connection;
}
Closing a connection
public void close(Connection connection) {
try {
if (connection != null) {
connection.close();
}
} catch (SQLException ex) {
System.out.println("Failure to close: " + ex.getMessage());
}
}Creating and executing statements
public List<User> getUsers() {
List<User> users = new LinkedList<>();
// CREATING A STATEMENT
Statement statement = connection.createStatement();
// CREATIING A QUERY
String query = "SELECT * FROM user";
// EXECUTING THE QUERY
ResultSet resultSet = statement.executeQuery(query);
// DEALING WITH THE RESULTS
(...)
return users;
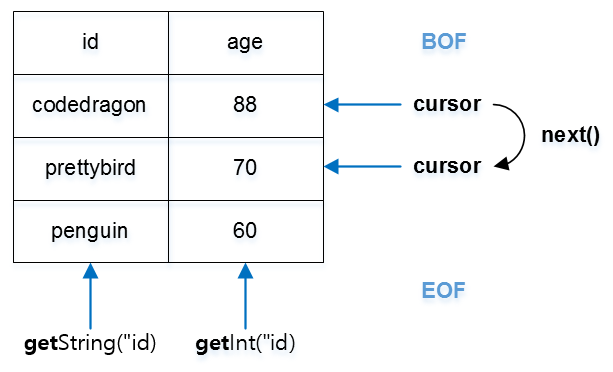
}processing results
public List<User> getUsers() {
// CREATING THE STATEMENT AND EXECUTING THE QUERY
(...)
// DEALING WITH THE RESULTS
while(resultSet.next()){
String firstName = resultSet.getString("firstname");
String lastName = resultSet.getString("lastname");
String email = resultSet.getString("email");
users.add(new User(firstName, lastName, email));
}
return users;
}
Transactions
try {
connection.setAutoCommit(false);
Statement statement = connection.createStatement();
String withdrawQuery = "UPDATE accounts SET balance=45 WHERE id=145";
String depositQuery = "UPDATE accouns SET balance=105 WHERE id=123";
statement.executeUpdate(withdrawQuery);
statement.executeUpdate(depositQuery);
// IF NO ERRORS OCCUR, BOTH ROWS WILL BE AFFECTED
connection.commit();
} catch(SQLException e){
// IF AN ERROR OCCURS, NO ROW WILL BE AFFECTED
connection.rollback();
}JDBC connections are, by default, in auto-commit mode; every SQL statement is committed to the database when it completes.
We can turn off auto-commit and manage our own transactions.
the problem with jdbc
JDBC doesn't come without its downfalls. These include:
- the manual mapping between Java objects and database tables
- the exclusive support of native SQL, making it the developer's responsibility to figure out the most effective queries to perform each task
- the non-availability of a caching mechanism
- the infinite mess of try-catch blocks
next
Because JDBC is somewhat limited, with the developer having the responsibility to manually map between objects and tables being its biggest disadvantage, a new way to connect a Java application to a database started to emerge: ORM tools.
OBJECT-RELATIONAL MAPPING
OBject-relational mapping
ORM is a programming technique that creates a layer between the database and the application, helping us deal with the problems we saw earlier.
The basic idea of ORM is to map database tables to, in our case, Java classes.
One row of the database is represented as a class instance, and vice-versa.
OBject-relational mapping
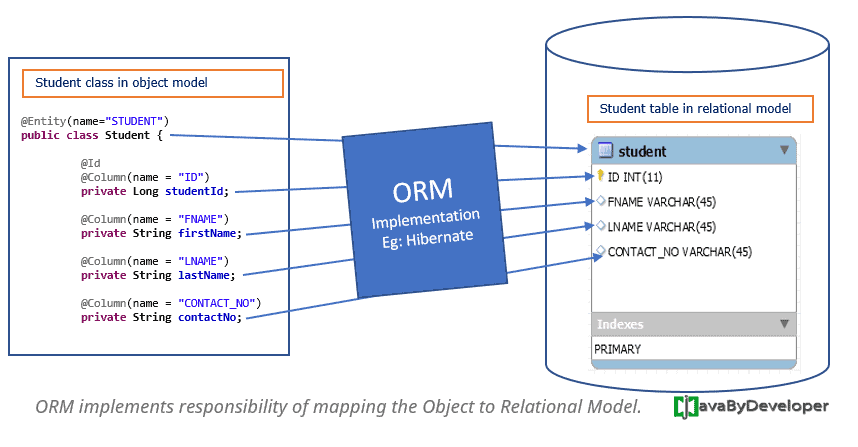
Mapping describes the relationship between an object and the database without knowing much about how the database is structured.
ADvantages
BETTER SYSTEM ARCHITECTURE
ORM tools will implement effective design patterns that force you to use good programming practices in an application.
REDUCED CODING TIME
Without ORM tools, the mapping would have to be done by hand by the developers working on the application.
CACHING AND TRANSACTIONS
Most ORM tools provide support for multiple transactions, locking mechanisms and even versioning.
popular orm tools in java



Java persistence APi
Java Persistence API
JPA is the Java ORM standard for accessing, storing, and managing data between a Java application and a RDBMS.
By itself, JPA is not a tool/framework; it simply defines a set of concepts that can be implement by other tools/frameworks (ex: Hibernate, for example).
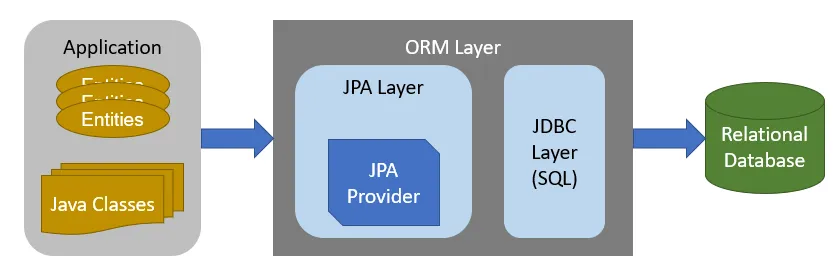
application-rdbms interaction with jpa
The JPA layer interfaces with the application, and the JPA provider transforms object interactions into SQL statements.
Hibernate
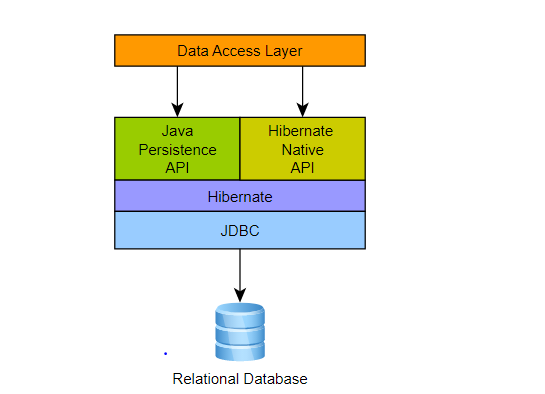
Hibernate is one of the most popular ORM frameworks for Java applications.
It is a standard implementation of the JPA specification with a few additional features that are Hibernate specific.
JPA ARChitecture
Entities
Entity is the basic unit of persistence in JPA.
It's basically a regular class with metadata to specify ho its state maps to the data in the database tables.
We will look at JPA entities in further detail, later.
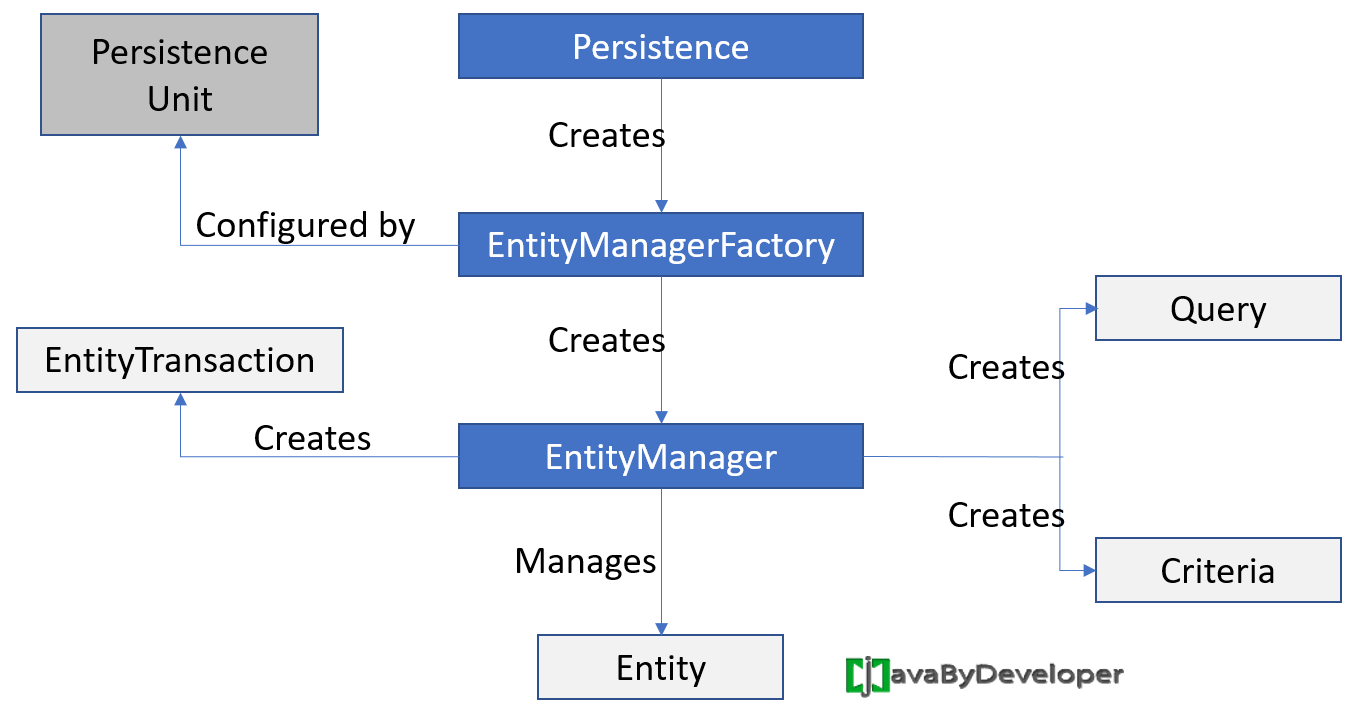
EntitY manager
EntityManager is an interface that abstracts the physical connection to the database.
Entity managers are responsible for managing JPA entities in the persistence context ( set of entities which hold data to be persisted in some persistence storage (e.g. database))
EntitY manager factory
A factory for EntityManager objects.
EntityManagerFactory is a thread-safe object, but heavy, which is why we typically have only one for database in an application.
It contains all the mapping metadata and caches generated SQL statements.
persistence unit
A persistence unit defines a set of all entity classes that are managed in an application.
Persistence units are defined by the persistence.xml configuration file. JPA then uses this file to create the connection and setup the required environment.
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence" version="2.1">
<persistence-unit name="test">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<properties>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/mindswap"/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5Dialect"/>
<property name="hibernate.show_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>JPA Entity mapping
Entities
An entity is basically a POJO representing a table stored in a database. Each instance of an entity represents a row in the table.
@Entity(name="customers")
public class Customer {
// fields, getters and setters
}The entity name defaults to the name of the class. However, we can change it by using the name parameter.
The entity name will be used in the queries done to the database.
To change the name of the table in the database itself, we should use the @Table annotation.
Entities
Entities must have a public, no-arguments constructor, as well as setters and getters for all persisted fields.
Entities should also have an id property to be used as the primary key, and can never be declared final.
@Entity(name="customers")
@Table(name="customers")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
private Integer id;
private String name;
@Transient
private String someProperty;
// getters and setters
}ID Generation
Values for ids can be automatically generated by Hibernate when saving or persisting, by four different strategies:
- AUTO - Indicates that the generation strategy should be chosen by the persistence provider (Hibernate)
- IDENTITY - Relies on an auto-incremented database column and lets the database generate a new value with each insert operation. IDENTITY generation disables batch updates
- SEQUENCE - Hibernate asks the database for the next sequence value. It then performs the database INSERT with the returned sequence value as the Id
- TABLE - It simulates a sequence by storing and updating its current value in a database table. This requires the use of pessimistic locks which put all transactions into a sequential order
VERSIONS
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Version
private Integer version;
@CreationTimestamp
private Date creationTime;
@UpdateTimestamp
private Date updateTime;
private String name;
}JPA entity life cycle
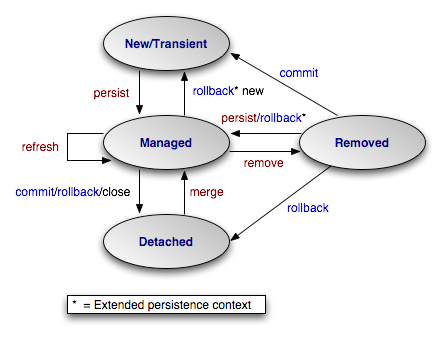
An entity class instance can be in one of 4 possible states:
- TRANSIENT - just instantiated
- PERSISTED/MANAGED - associated with the persistence context (PC)
- REMOVED - associated with the PC but scheduled for removal
- DETACHED - not associated with the PC. Changes made to this object won't be synchronised to the database.
Entity MERGING
(...)
EntityManager em = emf.createEntityManager();
try {
// OPEN TRANSACTION - JPA REQUIRES IT IN ORDER TO TRIGGER THE SYNCHRONIZATION BETWEEN THE APPLICATION AND THE DATABASE
em.getTransaction().begin();
Customer savedCustomer = em.merge(customer);
// CLOSE THE TRANSACTION
em.getTransaction().commit();
} catch (RollbackException ex) {
em.getTransaction().rollback();
} finally {
if (em != null) {
em.close();
}
}
merge() - makes a copy of the instance managed, and returns it; future changes to the original instance will not be tracked. It can be used for INSERT or UPDATE operations.
Entity PERSISTING
(...)
EntityManager em = emf.createEntityManager();
try {
em.getTransaction().begin();
em.persist(customer);
customer.setEmail("johnnysinger@mail.com");
em.getTransaction().commit();
} catch (RollbackException ex) {
em.getTransaction().rollback();
} finally {
if (em != null) {
em.close();
}
}
persist() - makes the instance managed by the persistence context. This means that future changes to the original instance will be tracked. It is used for INSERT operations.
Entity FETCHING
(...)
EntityManager em = emf.createEntityManager();
try {
Customer customer = em.find(Customer.class, id);
} finally {
if (em != null) {
em.close();
}
}find() - Hits the database and returns an object that represents the database row. If no row is found, the method returns null.
LIVE CODING
Entity Persisting And Fetching
EXERCISE
User Details Pages with Spring Boot MVC and JPA
/users → Shows a list of users names
/users/{id} → Shows the details of that particular user
Entity Composition
@Entity
@Table(name = "customers")
public class Customer {
@Id
private Integer id;
private String name;
@Embedded
private CreditCard card;
}In this case, it didn't make sense for CreditCard to be an entity in itself. It is instead a component.
@Embeddable
public class CreditCard {
private Integer number;
private Date expiration;
private Integer cvc;
}Entity Inheritance
There are a few different strategies when it comes to mapping inheritance to the relational world. These include:
- MAPPED SUPERCLASS
- TABLE PER CLASS
- SINGLE TABLE
- JOINED TABLE
Choosing the right strategy will depend on the problem in front of us.
Mapped superclass
@MappedSuperclass
public abstract class Vehicle {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private Integer gas;
@Version
private Integer version;
@CreationTimestamp
private Date creationTime;
@UpdateTimestamp
private Date updateTime;
}Maps each concrete class to its own table.
@Entity
@Table(name = "cars")
public class Car extends Vehicle {
private Integer tireWear;
}@Entity
@Table(name = "boats")
public class Boat extends Vehicle {
private String name;
}Table per class
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Vehicle {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE) // IDENTITY IS NOT ALLOWED
private Integer id;
private Integer gas;
@Version
private Integer version;
@CreationTimestamp
private Date creationTime;
@UpdateTimestamp
private Date updateTime;
}Similar to mapped superclass, except the superclass is its own entity. This allows for the use of polymorphic queries.
@Entity
@Table(name = "cars")
public class Car extends Vehicle {
private Integer tireWear;
}@Entity
@Table(name = "boats")
public class Boat extends Vehicle {
private String name;
}single table
Maps all entities to the same table.
@Entity
@Table(name = "products")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(
name = "product_type",
discriminatorType = DiscriminatorType.STRING
)
public abstract class Product {
@Id
private Integer id;
}@Entity
@DiscriminatorValue("chair")
public class Chair extends Product {
private String color;
}@Entity
@DiscriminatorValue("rug")
public class Rug extends Product {
private String pattern;
private String material;
}joined table
@Entity
@Table(name="animals")
@Inheritance(strategy = InheritanceType.JOINED)
public class Animal {
@Id
private Integer id;
private String species;
}Maps each class to its own table like the table per class, but the super class is now mapped to its own table.
id is both a primary and foreign key.
@Entity
@Table(name = "wild_animals")
public class WildAnimal extends Animal {
}@Entity
@Table(name = "pets")
public class Pet extends Animal {
private String name;
}associations
An association represents the relationship between entities. It can be:
- ONE-TO-ONE
- MANY-TO-ONE
- MANY-TO-MANY
In the relational world, there is no directionality. However, as we've seen before, in Java associations can be unidirectional or bidirectional.
one-to-one
@Entity
@Table(name = "human")
public class Human {
@Id
private Integer id;
private String name;
@OneToOne(mappedBy = "human")
private Pet pet;
} @Entity
@Table(name = "pet")
public class Pet {
@Id
private Integer id;
private String name;
// FOR BIDIRECTIONALITY
@OneToOne
private Human owner;
}mappedBy - required for bidirectional associations. Tells hibernate to use the foreign key on the Pet table to define the owner.
many-to-one
@Entity
@Table(name = "product")
public class Product {
@Id
private Integer id;
private String name;
@ManyToOne
private Category category;
}mappedBy - The category foreign key is used on the product table to establish the many-to-one relationship instead of a join table.
@Entity
@Table(name = "category")
public class Category {
@Id
private Integer id;
private String name;
@OneToMany(
cascade = {CascadeType.ALL},
orphanRemoval = true,
mappedBy = "category"
)
private Set<Product> products;
public void addProduct(Product product) {
products.add(product);
product.setCategory(this);
}
}many-to-many
@Entity
@Table(name = "user")
public class User {
@Id
private Integer id;
private String name;
@ManyToMany(
fetch = FetchType.EAGER
)
private List<Role> roles;
}@Entity
@Table(name = "role")
public class Role {
@Id
private Integer id;
private String name;
@ManyToMany(
mappedBy="role",
fetch = FetchType.LAZY
)
private List<User> users;
}Fetch types
JPA/Hibernate support two types of fetching:
- EAGER FETCHING - Loads all of the relationships related to a particular object. This is the default behaviour, and despite being convenient, it's slows down the boot of our application.
- LAZY FETCHING - Uses proxy objects as a replacement for the associated objects. The proxies will be replaced by Hibernate when needed. If it becomes necessary to do multiple trips to the database, this method becomes inefficient.
Cascades
@Entity
public class Human {
@Id
private Integer id;
private String name;
@OneToOne(
cascade = {CascadeType.ALL},
orphanRemoval = true,
mappedBy = "human"
)
private Car car;
}cascade - Propagates changes on parent entity to child entity. The most common cascade types are all, persist, merge, and remove.
Java Persistence Query Language
(...)
String queryString = "SELECT customer FROM Customer customer WHERE customer.name = :name";
TypedQuery<Customer> query = em.createQuery(queryString, Customer.class);
query.setParameter("name", "John");
List<Customer> customers = query.getResultList();JPQL is very similar to SQL, except it queries the entity model instead of querying tables. It also supports OOP features like inheritance, for example.
User - the entity being queried
user - identification variable, used in the rest of the query
Exercise
Choose (and implement) the adequate inheritance mapping strategy for the following examples:
-
A school needs to implement a system to keep track of teachers parking spots. Vehicles include both cars and motorcycles. Typical queries include:
- listing all the vehicles
- finding the vehicle assigned to an particular spot
- finding the owner of a particular vehicle
-
A bank needs to devise a system to keep track of both customers and accounts.
- listing all the accounts of one customer
- listing all the customers
- retrieve the balance of one particular account
Data Persistence
By Soraia Veríssimo




