









Sri sai swaroop kommineni
Full Stack Developer at Seven Lakes Technologies
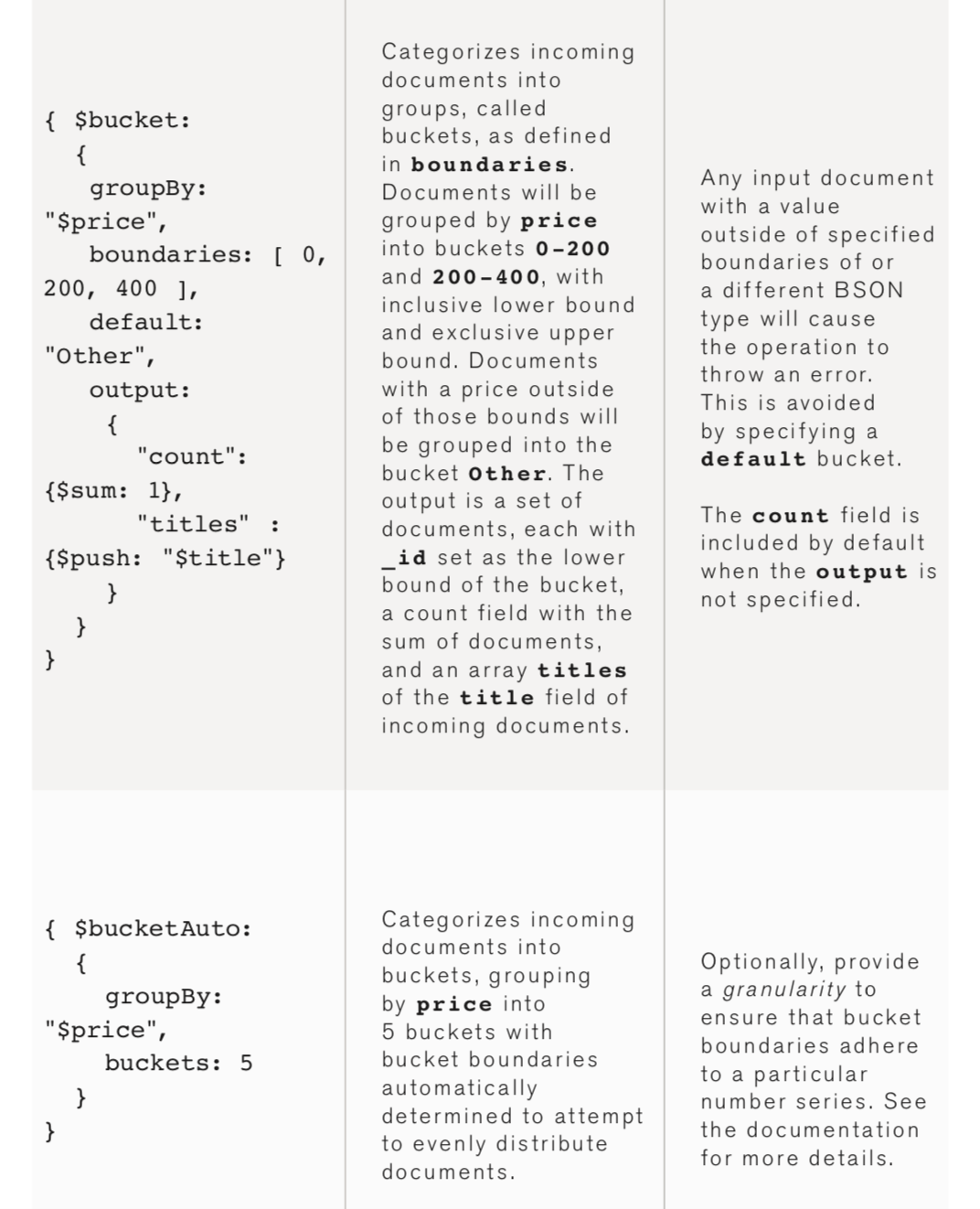
Aggregation
Similar to queries, aggregation operations in MongoDB use collections of documents as an input and return results in the form of one or more documents.
The aggregation framework in MongoDB is based on data processing pipelines.
Documents pass through multi-stage pipelines and get transformed into an aggregated result.
The most basic pipeline stage in the aggregation framework provides filters that function like queries.
It also provides document transformations that modify the output document.
The pipeline operations group and sort documents by defined field or fields. In addition, they perform aggregation on arrays.
Pipeline stages can use operators to perform tasks such as calculate the average or concatenate a string.
The pipeline uses native operations within MongoDB to allow efficient data aggregation and is the favored method for data aggregation.
The aggregate command in MongoDB functions on a single collection and logically passes the collection through the aggregation pipeline.
Which of the following is true about pipelines and the Aggregation Framework?
Pipeline stages appear in an array.
Documents are passed through the pipeline stages in a proper order one after the other.
Barring $out and $geoNear, all stages of the pipeline can appear multiple times.
The db.collection.aggregate() method provides access to the aggregation pipeline and returns a cursor and result sets of any size.
AGGREGATE PIPELINE STAGES
$project:
$match:
Which of the following is/are true of the $match stage?
Which of the following statements are true of the $project stage?
$group:
$sort:
$skip:
$limit:
$unwind:
Which of the following statements is true?
Which of the following statements apply to $graphLookup operator?
Example
db.zipcodes.aggregate([
{
"$group": {
"_id": "$state",
"totalPop": {
"$sum": "$pop"
}
}
},
{
"$match": {
"totalPop": {
"$gte": 10000000
}
}
}
]); $group stage does three things:
db.users.aggregate([
{
"$project": {
"month_joined": {
"$month": "$joined"
},
"name": "$_id",
"_id": 0
}
},
{
"$sort": {
"month_joined": 1
}
}
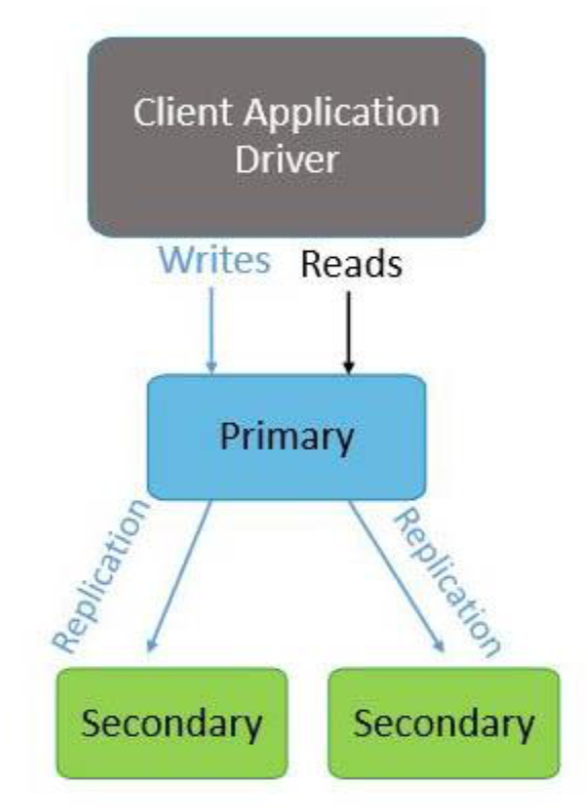
]);Replication
It helps you manage data in the event of hardware failure and any kind of service interruptions.
Having multiple copies of data stored on various servers across various locales, you can perform tasks, such as disaster recovery, backup, or reporting with ease.
You can also use replication to enhance read operations.
Typically, clients send read and write operations to different servers.
You can store copies of these operations in different data centers to increase the locality and availability of data for distributed applications.
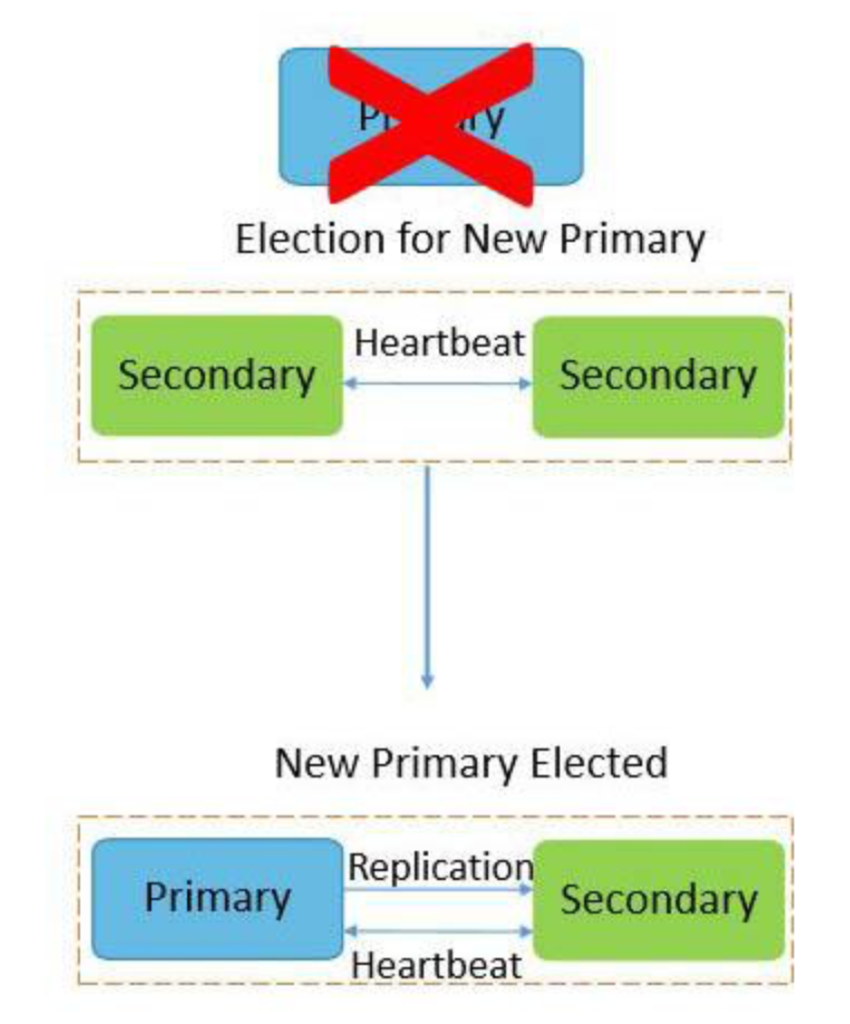
A replica set consists of a group of mongod instances that host the same data set.
In a replica set, the primary mongod receives all write operations and the secondary mongod replicates the operations from the primary and thus both have the same data set.
The primary node receives write operations from clients.
A replica set can have only one primary and therefore only one member of the replica set can receive write operations.
A replica set provides strict consistency for all read operations from the primary.
Replica Sets
AUTOMATIC FAILOVER IN MONGODB
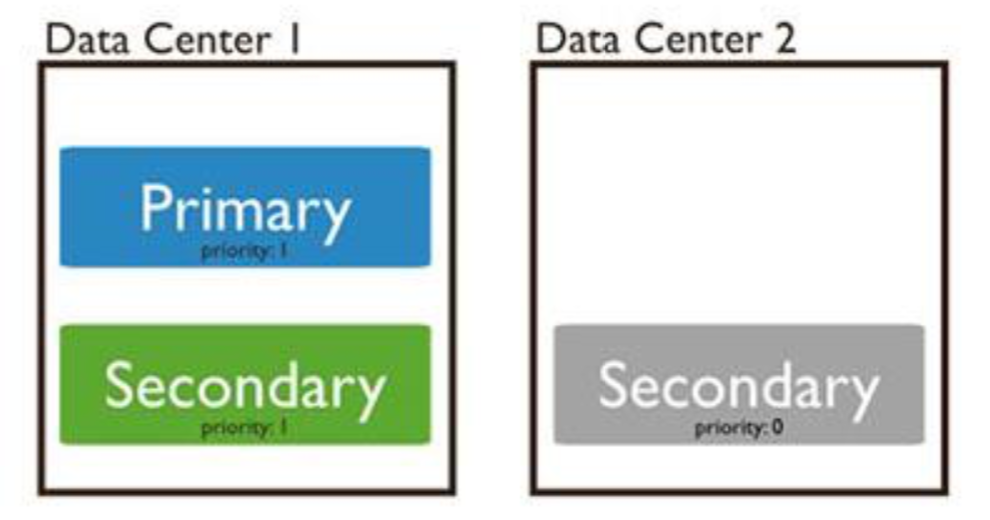
A replica set typically contains:
Arbiter
Priority 0
HIDDEN MONGODB REPLICA SET MEMBERS
You can utilize the hidden members for dedicated functions like reporting and backups.
DELAYED MONGODB REPLICA SET MEMBERS
Delayed replica set members are those secondaries that copy data from the primary node’s oplog file after a certain delay.
Delayed replica set members store their data set copies. However, they reflect a previous version, or a delayed state of the set.
If the data shown in the primary is for 10 AM then the delayed member will show data for 9 AM. Delayed members perform a “roll backup” or run a “historical” snapshot of the dataset.
Therefore, they help you manage various human errors and recover from errors, such as unsuccessful application upgrade, and dropped databases and collections.
DELAYED MONGODB REPLICA SET MEMBERS
To be considered delayed member, a replica set member must:
You can configure a delayed secondary member with the following settings:
Write concern
Read preference
sharding
By Sri sai swaroop kommineni


