









Sri sai swaroop kommineni
Full Stack Developer at Seven Lakes Technologies
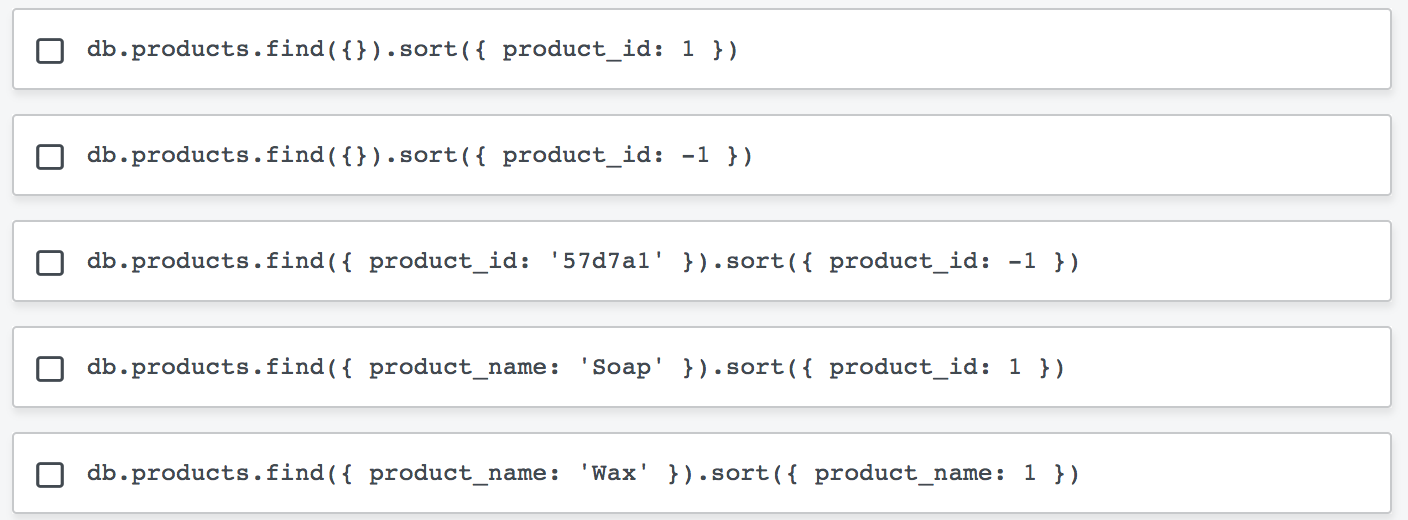
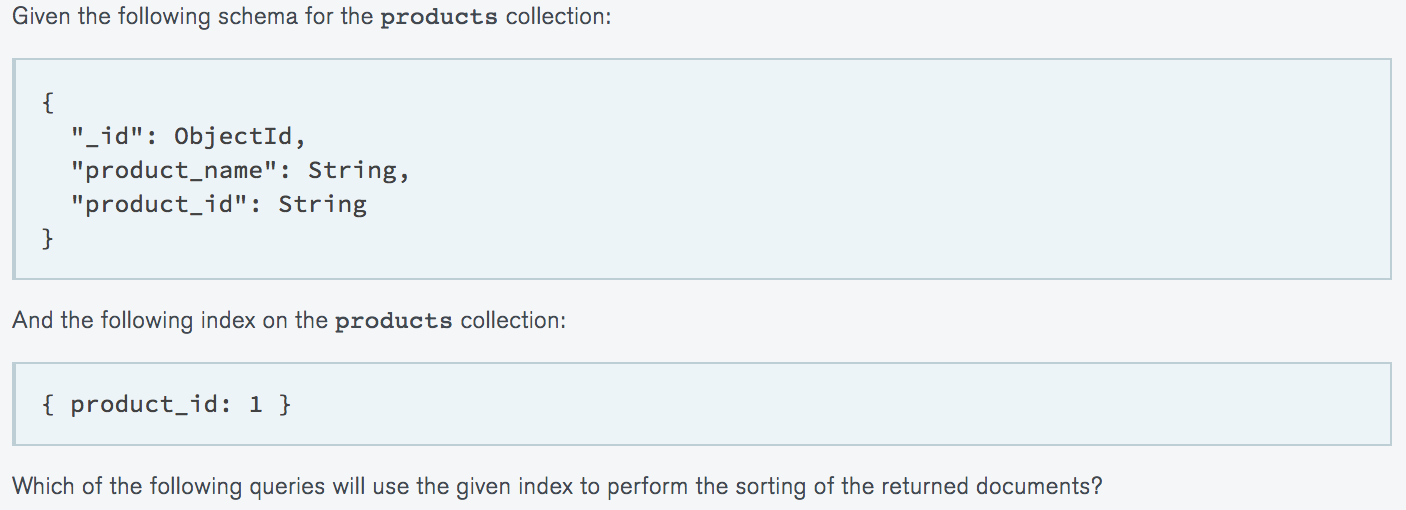
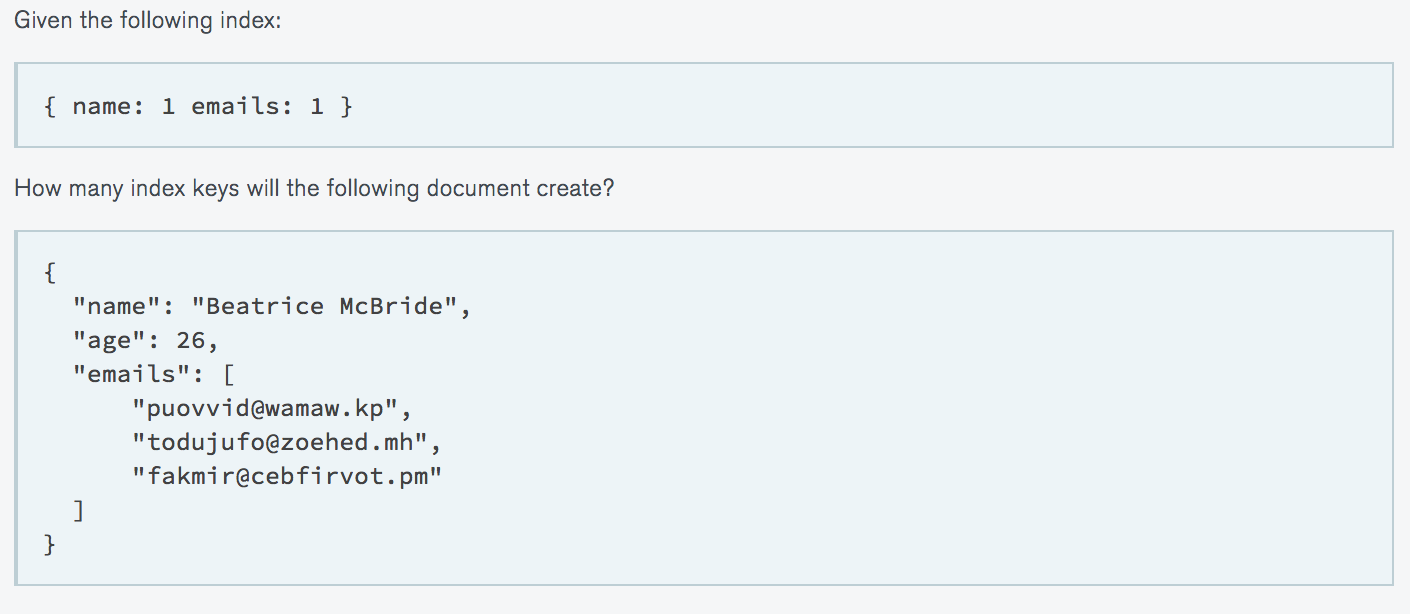
What is the single most important factor in designing your application schema within MongoDB?
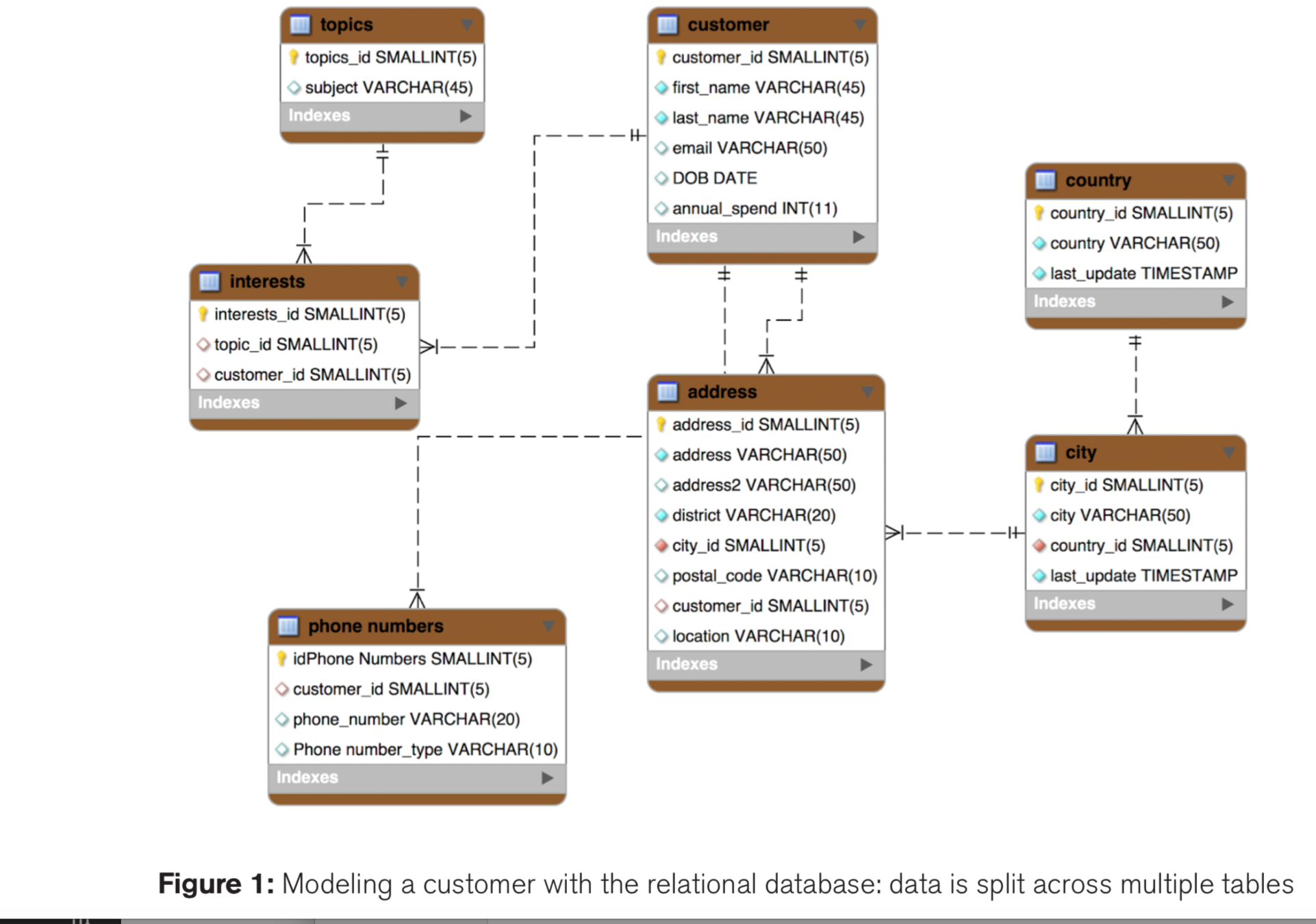
Goals of Normalisation
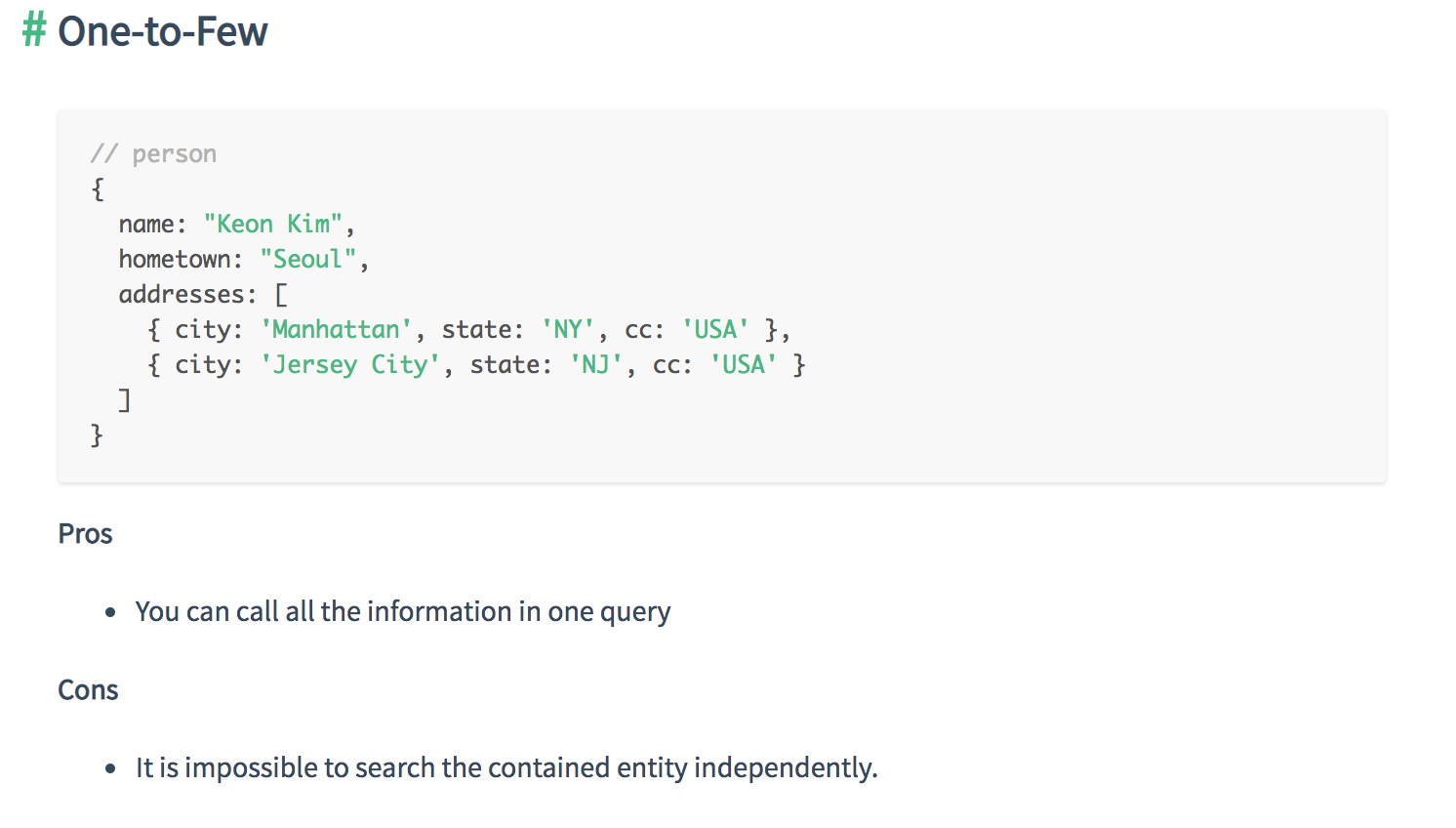
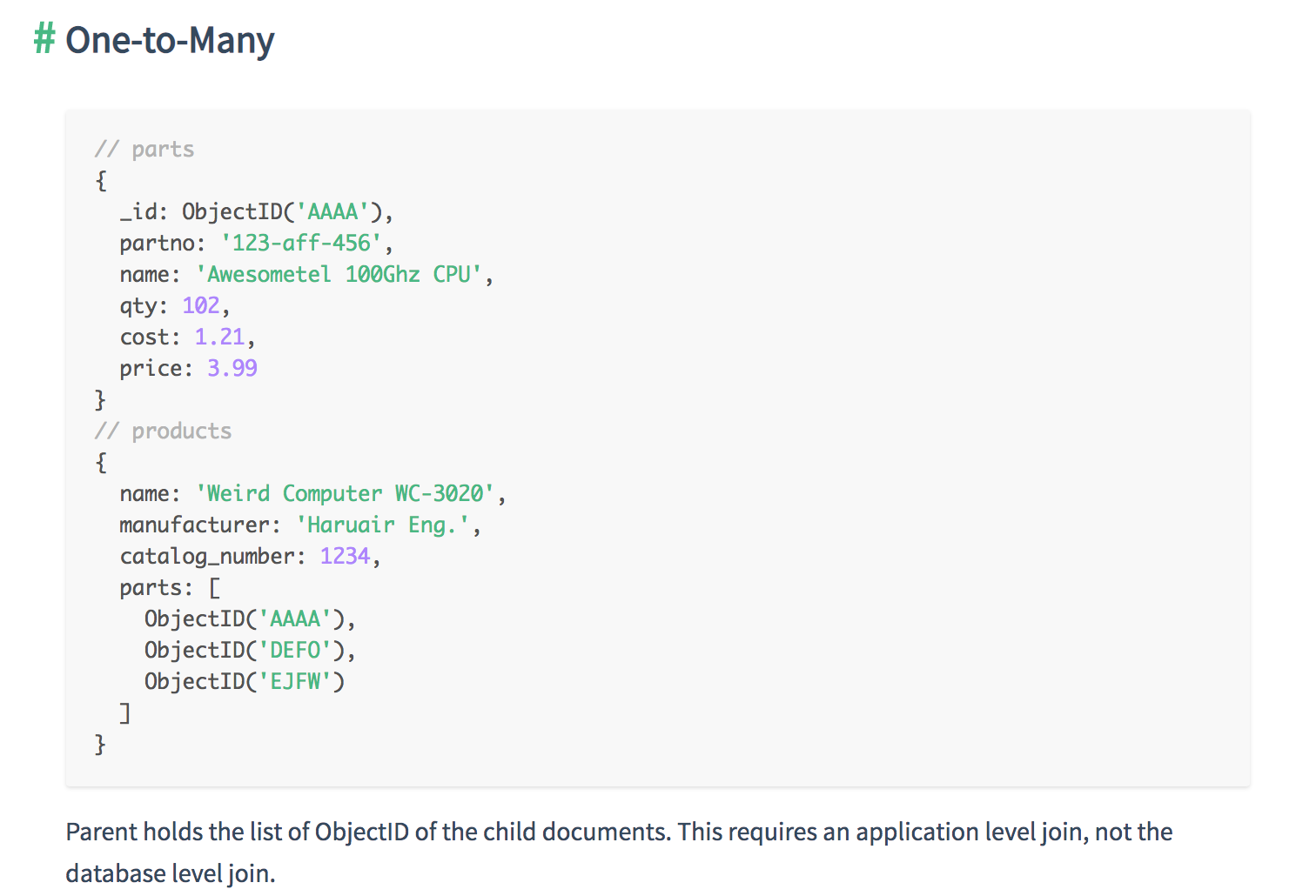
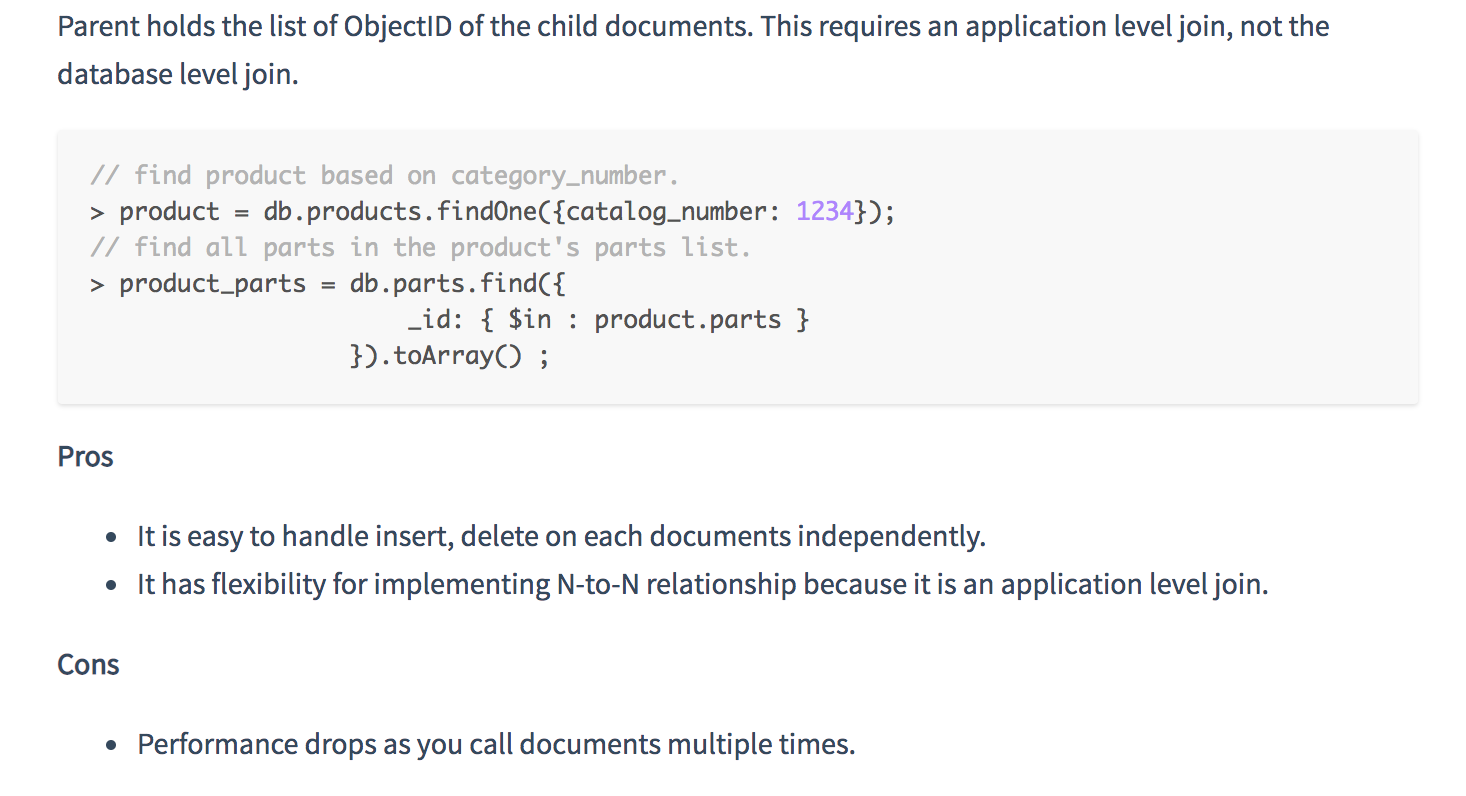
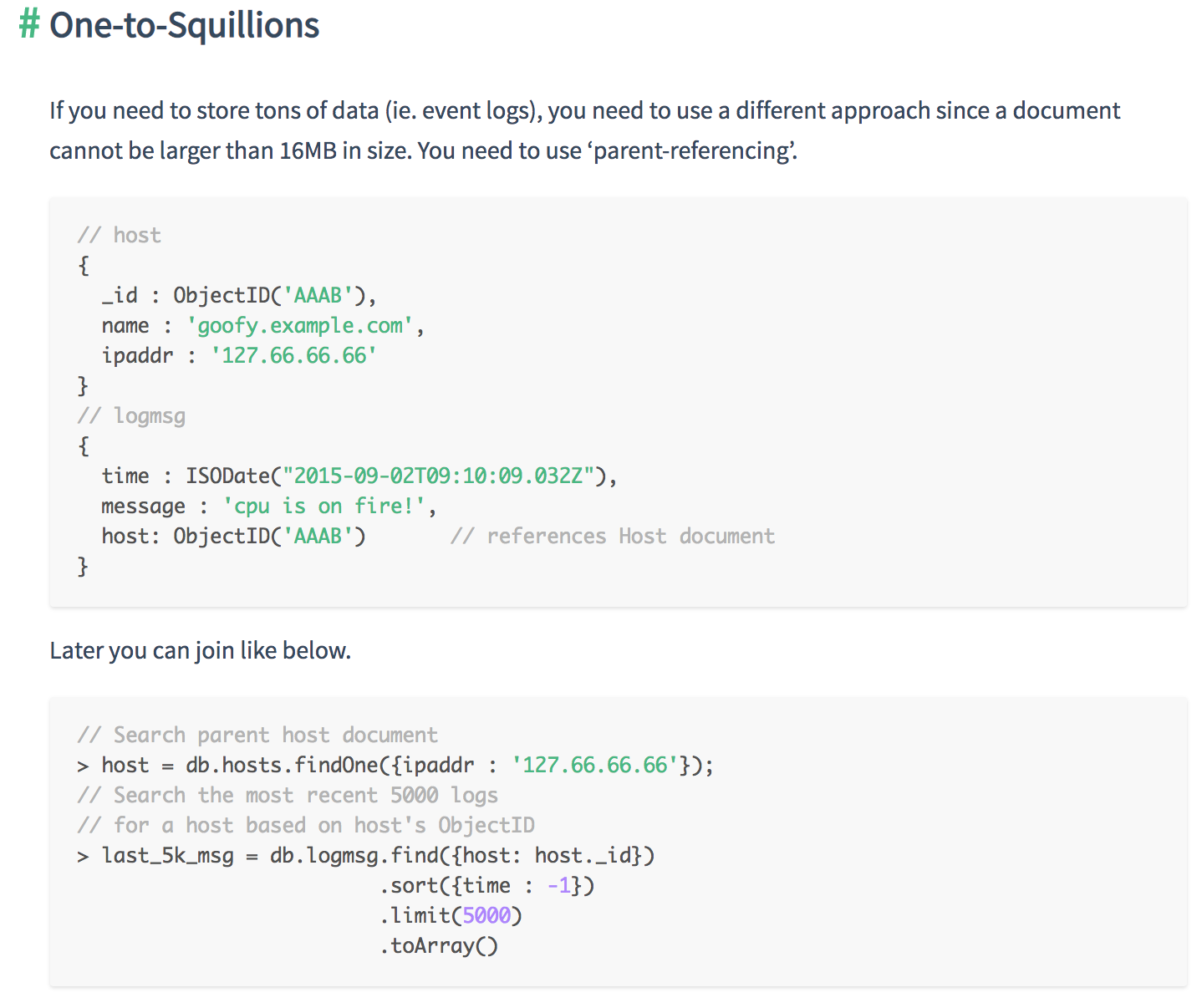
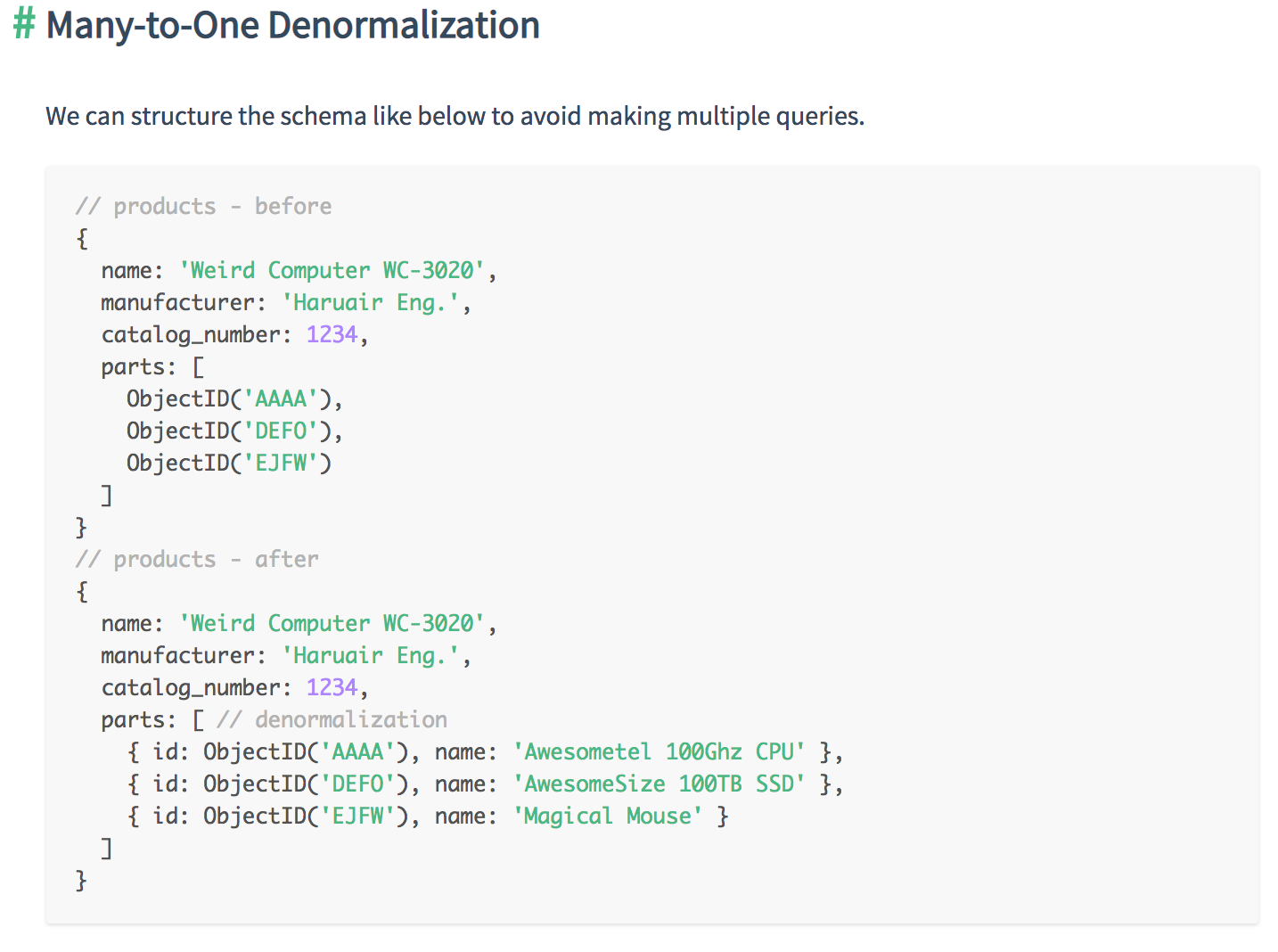
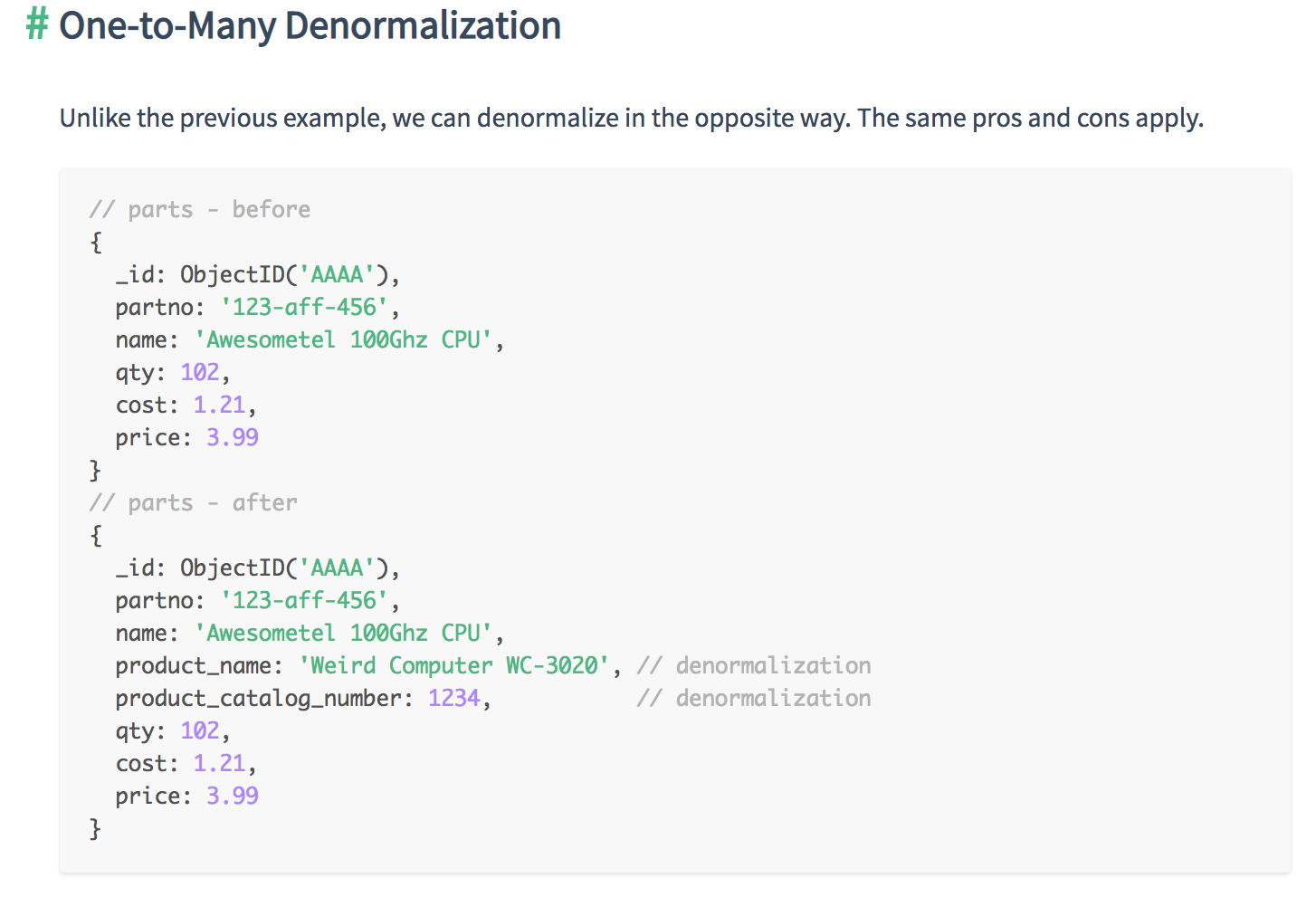
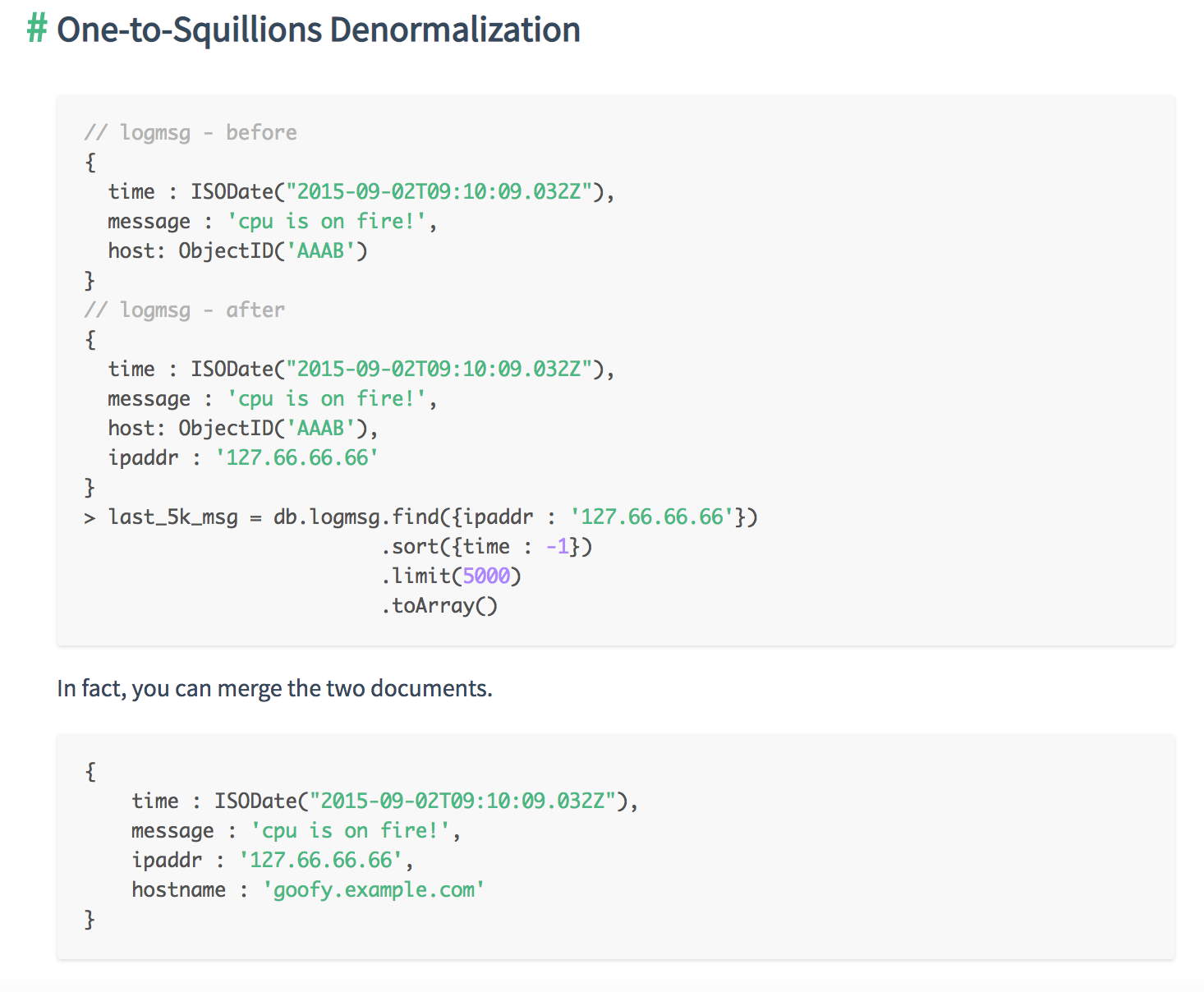
Relationships can be in three different forms.
Each methods for structuring has its pros and cons. So the user should know how to decide which one is better than the other in the given situation.
You need to consider two factors:
Based on these factors, you can pick one of the three basic One-to-N schema designs:
Additional choices that you have past the basics of embed, child-reference, or parent-reference.
When deciding whether or not to denormalize, consider the following factors:
Rules of Thumb: Your Guide Through the Rainbow
Here are some “rules of thumb” to guide you through these indenumberable (but not infinite) choices
When modeling “One-to-N” relationships in MongoDB, main criteria you need to consider are:
Your main choices for structuring the data are:
Indexes are data structures that store data set in easily traversable form.
Indexes help execute queries efficiently without performing a collection scan.
MongoDB supports the following indexes— single field, compound indexes, hashed indexes, geoIndexes, unique, sparse, partial, text… and so on.
For fast query operation, the system RAM must be able to accommodate index sizes.
You can create, modify, rebuild, and drop indexes.
The geospatial indexes help query geographic location by specifying a specific point.
Default _id based index is created automatically
{
"_id": 3,
"item": "Book",
"available": true,
"soldQty": 144821,
"category": "NoSQL",
"details": {
"ISDN": "1234",
"publisher": "XYZ Company"
},
"onlineSale": true,
"stock" : 25
}db.items.createIndex( { “item" : 1 } )
db.items.createIndex( { "details.ISDN" : 1 } )
db.products.createIndex( { "item": 1, "stock": 1 } )
db.products.createIndex( {
"item": 1,
"available": 1,
"soldQty": -1
})If sorted documents cannot be obtained from an index, the results will get sorted in the memory.
Sort operations executed using an index show better performance than those executed without using an index.
Sort operations performed without an index gets terminated after exhausting 32 MB of memory.
Sort order is important for compound indexes because it helps determine if the index can support a sort operation
SORT ORDER
TTL indexes expire documents after the specified number of seconds has passed since the indexed field value; i.e. the expiration threshold is the indexed field value plus the specified number of seconds.
If more than one field has an array value,
you cannot create a compound multikey index.
The hashing function combines all embedded documents and computes hashes for all field values.
The hashing function does not support multi-key indexes.
Hashed indexes support sharding, uses a hashed shard key to shard a collection, ensures an even distribution of data.
Hashed indexes support equality queries, however, range queries are not supported.
You cannot create a unique or compound index by taking a field whose type is hashed. However, you can create a hashed and non-hashed index for the same field. MongoDB uses the scalar index for range queries.
They are not supported by compound indexes which ignore expireAfterSeconds
The _id field does not support TTL indexes.
TTL indexes cannot be created on a capped collection because MongoDB cannot delete documents from a capped collection.
It does not allow the createIndex() method to change the value of expireAfterSeconds of an existing index.
You cannot create a TTL index for a field if a non-TTL index already exists for the same field. If you want to change a non-TTL single-field index to a TTL index, first drop the index and recreate the index with the expireAfterSeconds option.
The TTL background thread runs on both primary and secondary nodes. However, it deletes documents only from the primary node.
If the index language is English, text indexes are case-insensitive for all alphabets from A to Z.
db.collection.createIndex({subject: "text",content: "text"})
db.collection.createIndex({ "$**": "text" },{ name: "TextIndex" })
db.customer.createIndex({“item”: “Text”},{ default_language: "spanish"})
db.items.createIndex( {item:1},{background: true})
db.accounts.dropIndex( { "tax-id": 1 } ) // -> Single Index drop
db.collection.dropIndexes() // -> Drop all Indexes
To modify an index, first, drop the index and then recreate it. Perform the following steps to modify an index.
db.items.find({item: “Book”, available : true }).hint({item:1}).explain(“executionStats”)
db.items.explain("executionStats").find({item: “Book”, available : true }).hint( { item:1 } )
Which of the following queries can use an index on the zip field?
Which of the following statements are true?
By Sri sai swaroop kommineni


