ANALIZA PORÓWNAWCZA ROZWIĄZAŃ APACHE HADOOP I APACHE SPARK DEDYKOWANYCH RÓWNOLEGŁEMU PRZETWARZANIU DANYCH
MASOWYCH
Cel pracy
Wykazanie przewagi zastosowania Apache Hadoop bądź Apache Spark
Badania
-
Dane wsadowe o wielkości 4GB
-
Word Count
-
Filter
-
Reject
Wnioski
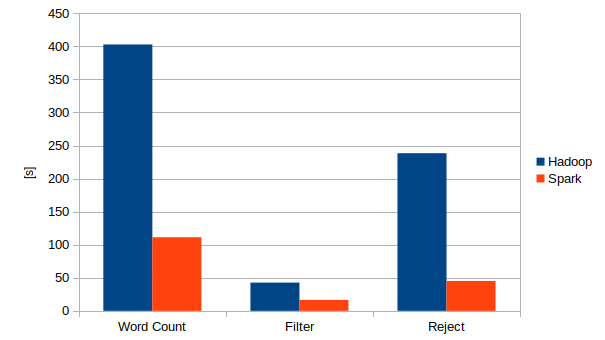
Wyniki wydajności operacji: Word Count, Filter i Reject na platformach Apache Spark oraz Apache Hadoop dla najbardziej wydajnej strategii przechowywania danych.
Wnioski
Wyniki wydajności operacji: Word Count, Filter i Reject na platformie Apache Spark ze względu na zastosowaną strategię przechowywania danych.
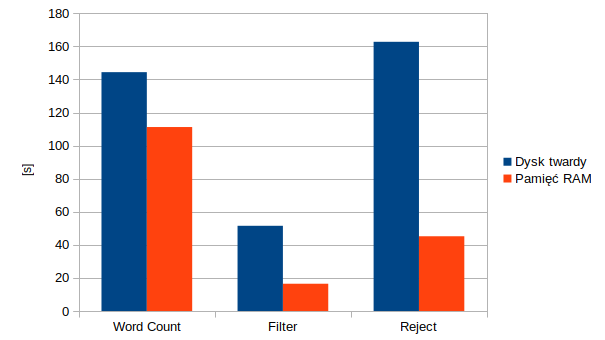
Wnioski
Wyniki zbiorcze wszystkich operacji wykonanych podczas badań.
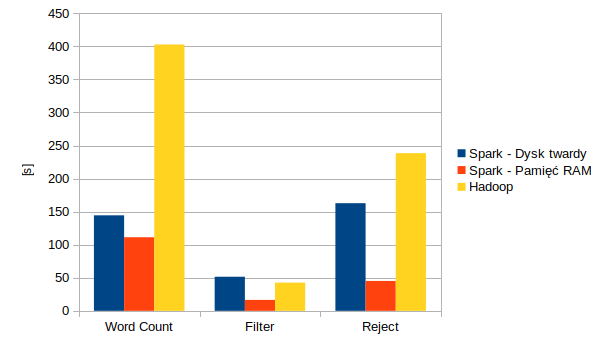
Wnioski
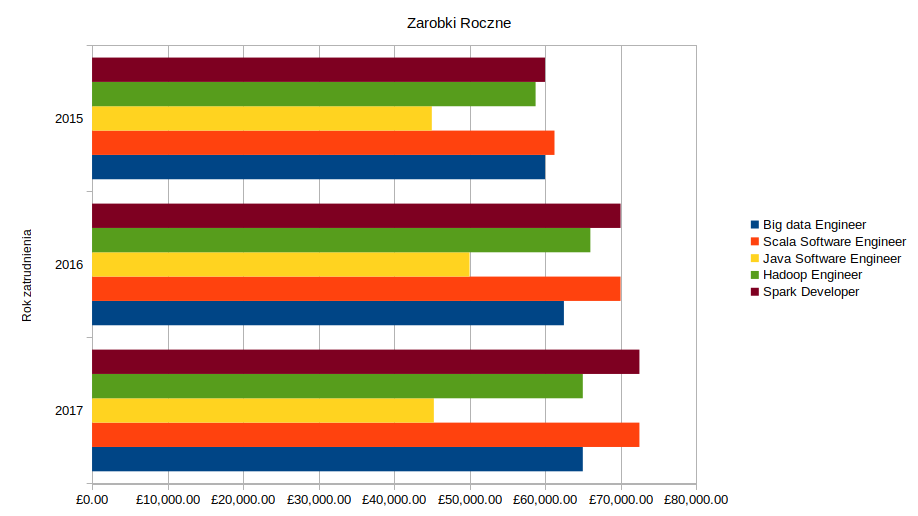
Trendy zarobków rocznych na terenie Wielkiej Brytanii w latach 2015, 2016 oraz 2017 dla formy zatrudnienia stałego (umowy o pracę).
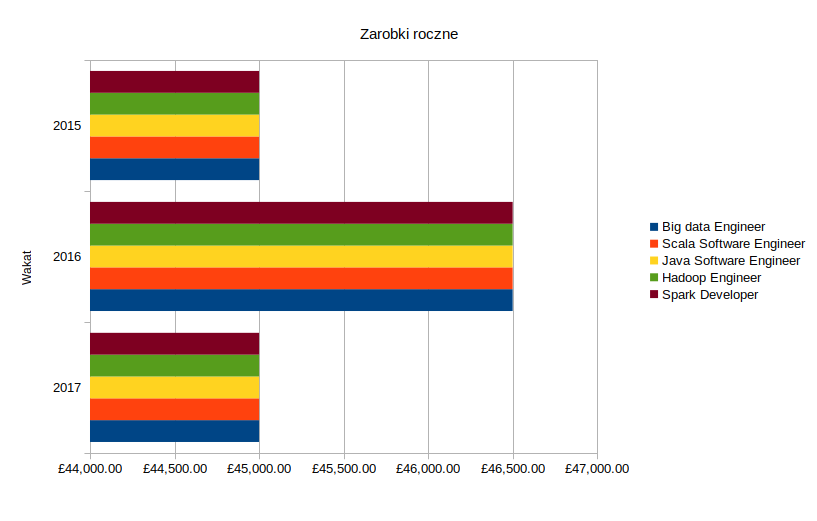
Wnioski
Trendy zarobków rocznych na terenie Wielkiej Brytanii w latach 2015, 2016 oraz 2017 dla formy zatrudnienia na kontrakt.
deck
By Szymon Łyszkowski


