Modern adattárház Technológiák:
Hogyan építsünk adattárházat 2018-ban?
Földi Tamás - tfoldi@starschema.com - @tfoldi
Starschema ügyfélek

Szép logói mindenkinek vannak.
Miért releváns ez a modern adattárházakhoz?



Startup = Modern
Nagyvállalat = Modern, Stabil, Integrálható, Biztonságos, ...
(kockázat nélkül)
És akkor most, végre a modern adattárház technológiák
Hogyan épül fel egy adattárház?
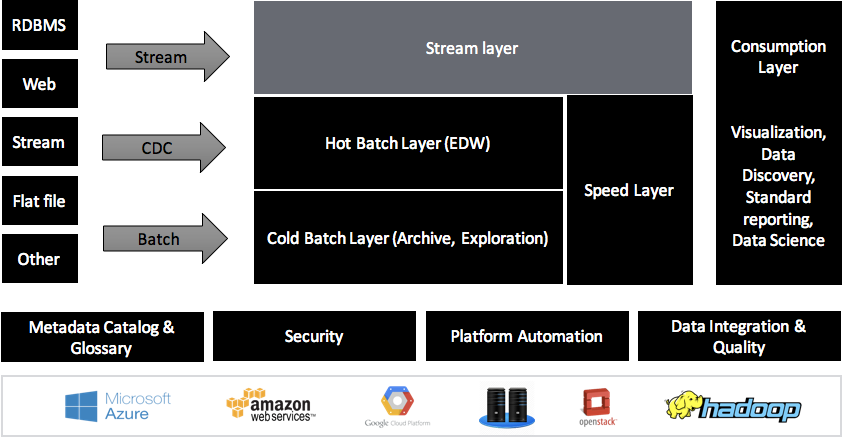
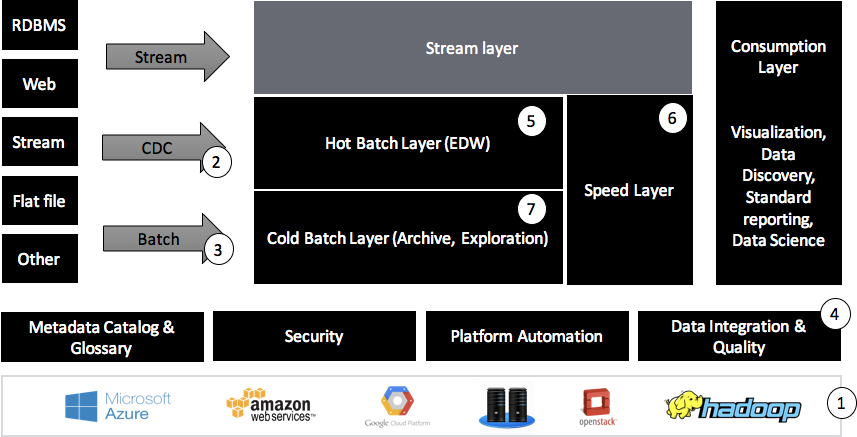
Cloud vagy on-prem?
1. Költség
2. Technológia
3. Skálázódás
+1. Compliance
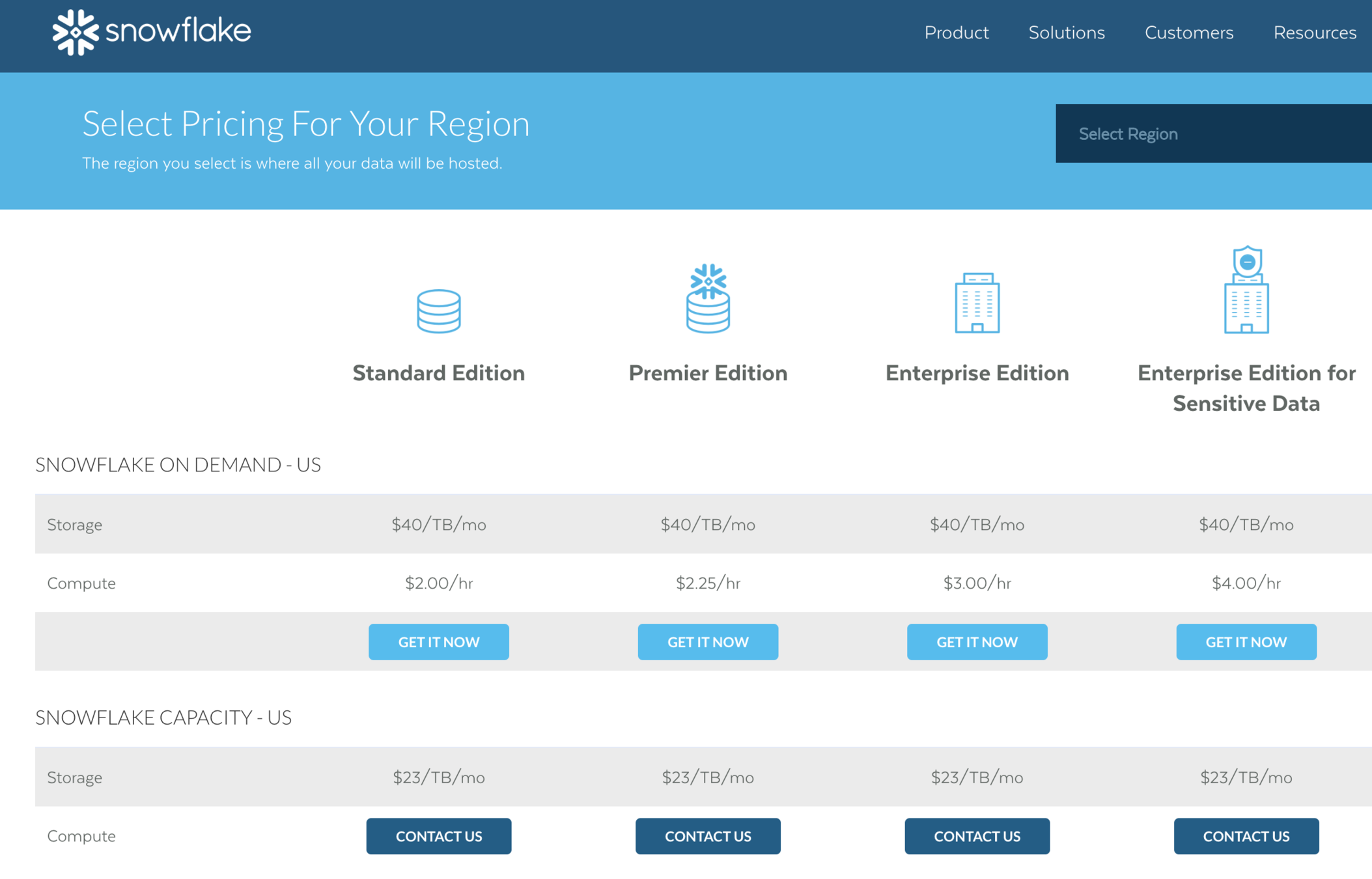
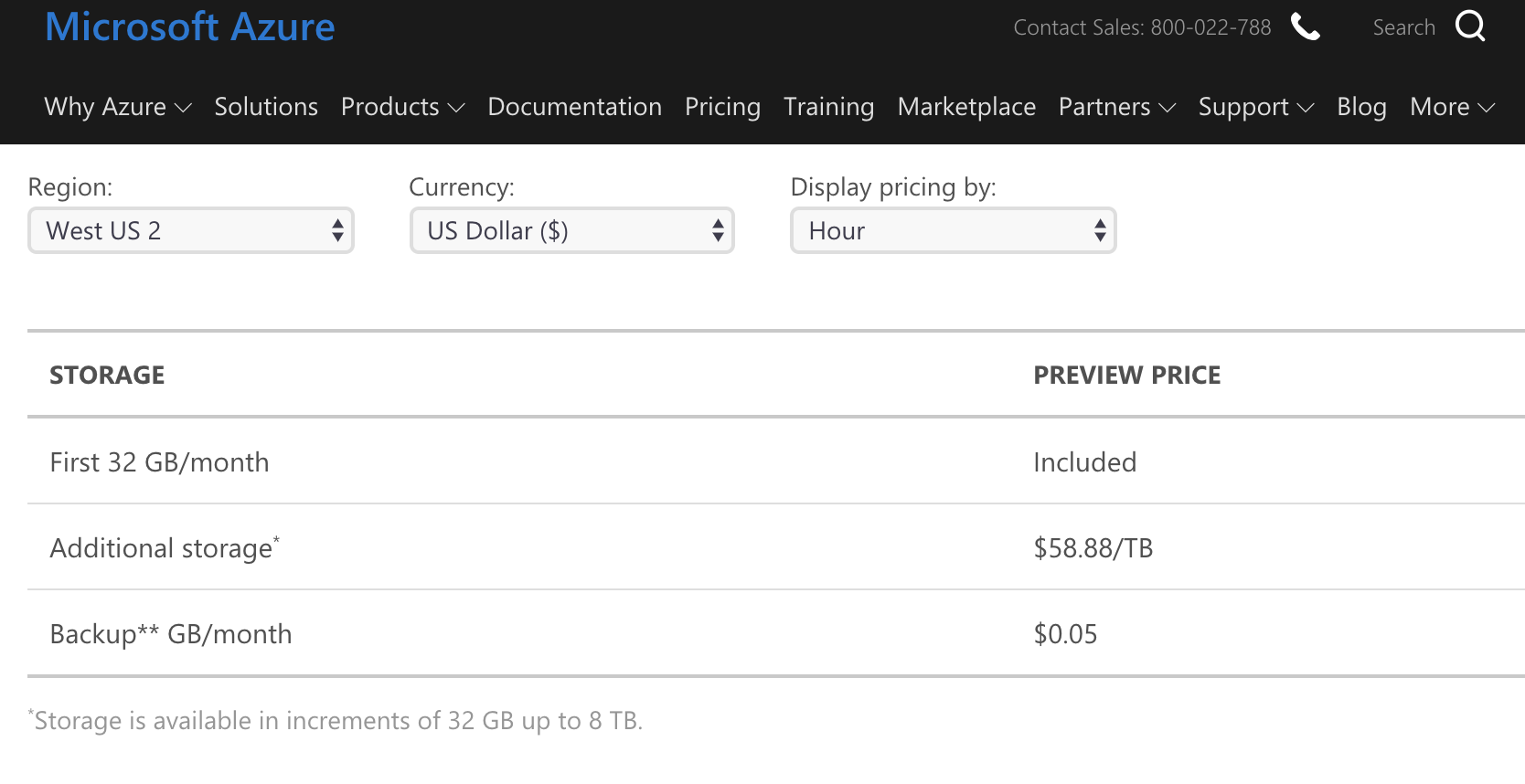
$23-40 / TB / hó
Infra ⇨ DB ⇨ Serverless
Saját adatbázis-kezelő virtuális gépen
AWS RDS
AWS Reshift
Azure CDaaS
Google BigQuery
Amazon Aurora Serverless
Amazon Athena
"Serverless" megoldások
- Google BigQuery
- Amazon Athena
- Amazon Aurora Serverless
World-scale
Nincs hagyományos üzemeltetés és infrastruktúra
Jelenlegi "high-end"
Adatkinyerés
Leválogatás
Üzleti vagy technikai szabály alapján ("Utoljára módosítva" oszlop)
Lassú
Csak kötegelve működik
Sok hibalehetőség
Terheli a forrásrendszert
CSV
Teljesen haszontalan, az iparág szégyene
Sok hibalehetőség (tizedesjel, dátumforma)
Nincs metaadat
Sok helyet foglal, lassú
(Azonnali segítség: SQLite, Parquet, RC, HDF5, ProtoBuf)
A Dicső Múlt
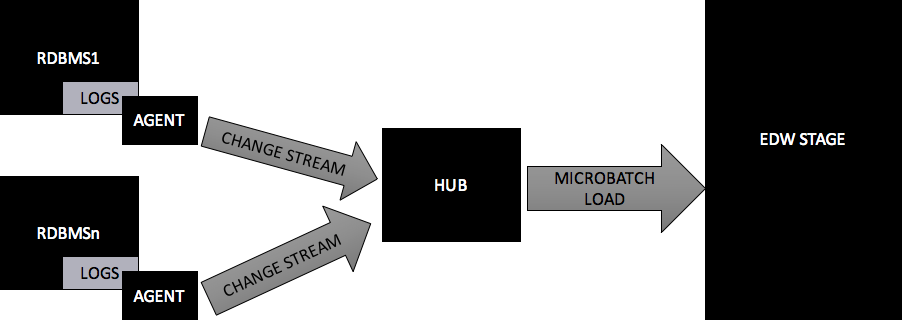
CDC.
(Change Data Capture)
FOLYAMATOS ADATKINYERÉS
Adatbázis tranzakcios logok alapján (redolog, journal, stb)
Nem kell üzleti definició
Valós idejű, de kötegelhető
Nem veszik el adat
Nem terheli a forrást



Adatintegráció,
ETL
ETL Eszköz vagy Framework?
ETL Eszközök
Vagy "rendesen, vagy sehogy":
Amint egyetlen custom SQL vagy tárolt eljárás belekerül, elveszítjük a fő értékét
Szabályzás > Teljesítmény
Lehetőleg kód generálás és ELT




Tárolt eljárások
Adatbázisban tárolni ETL kódokat nem túl jó ötlet:
- Függőségek kezelése
- Csoportmunka hiánya
- Verziókezelés, deployment problémák
- Borzasztó template-zés, nem DRY kód
TÉVEDÉS: A tárolt eljárás nem gyorsabb
Program kód
Miért jobb:
- Rengetek open soure framework (Apache Beam)
- Jó csapatmunka
- Verzió és változáskezelés
- Template kezelés
- Bővíthetőség
- Tesztelhetőség
ETL Framework
Tárolt eljárások
Tárolt eljárások
Apropó, tesztelés
Annyira komplex nálunk a környezet, hogy mi már nem is tesztelünk
banki adattárház vezető
Minél komplexebb egy rendszer, annál jobban kell tesztelni
Validációs és teszt script
⇩
DQ Szabály
EDW
MPP
10-100TB
COLUMNAR
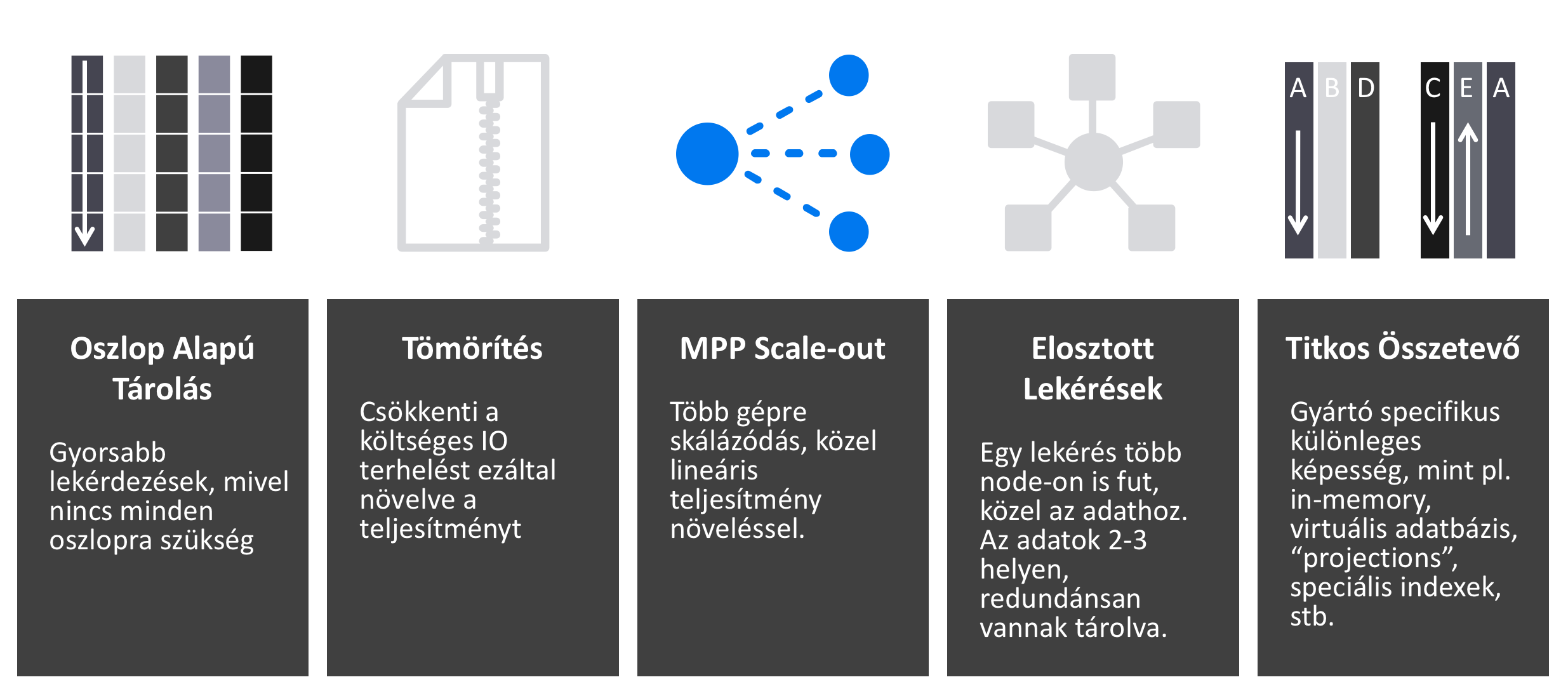
MPP Adatbázis
Néhány különleges képesség
Menedzselt szolgáltatás - csak felhő
Extra funkciók:
- Time Travel
- Zero copy clone
- Virtuális adattárházak
- Megosztott adattárházak

Oracle 18c In-Memory
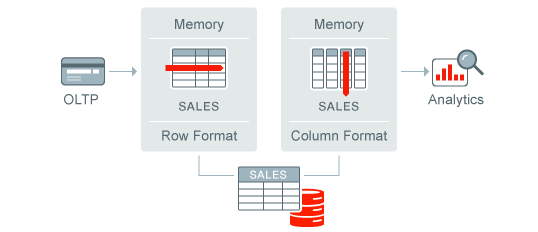
Oracle Database In-Memory a tábla adatait egyszerre tartja sor és oszlop alapú memória tárolóban. Az optimizer a tranzakciós SQL utasításokat a sor alapún, míg az analitikusakat az oszlop alapún hajtja végre.
Speed Layer

Usability Engineering, Jakob Nielsen
Új Generációs
- In-memory
- Deep Analytics
- GPU
OLAP alapú
OLAP Indexek Hadoop vagy Spark adatokon
Speed Layer








Hol érdemes kezdeni?
Köszönöm!
Földi Tamás - tfoldi@starschema.com
@tfoldi
Budapest data
By Tamas Foldi



