Secret Techniques from the Toughest Tableau Server Deployments
Tamas Foldi
Starschema, CTO
tfoldi@starschema.com - @tfoldi
Who am I?

OK, so large deployments?
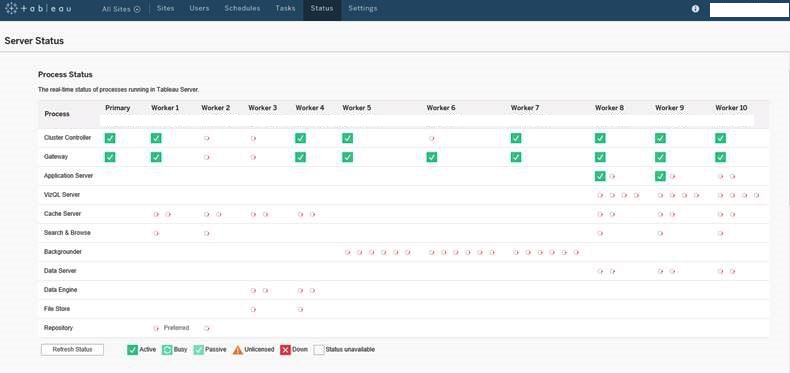
How do you survive with this complexity?
Automate.
Analyse.
Extend.
Automation
Basic AWS Tableau Infrastructure
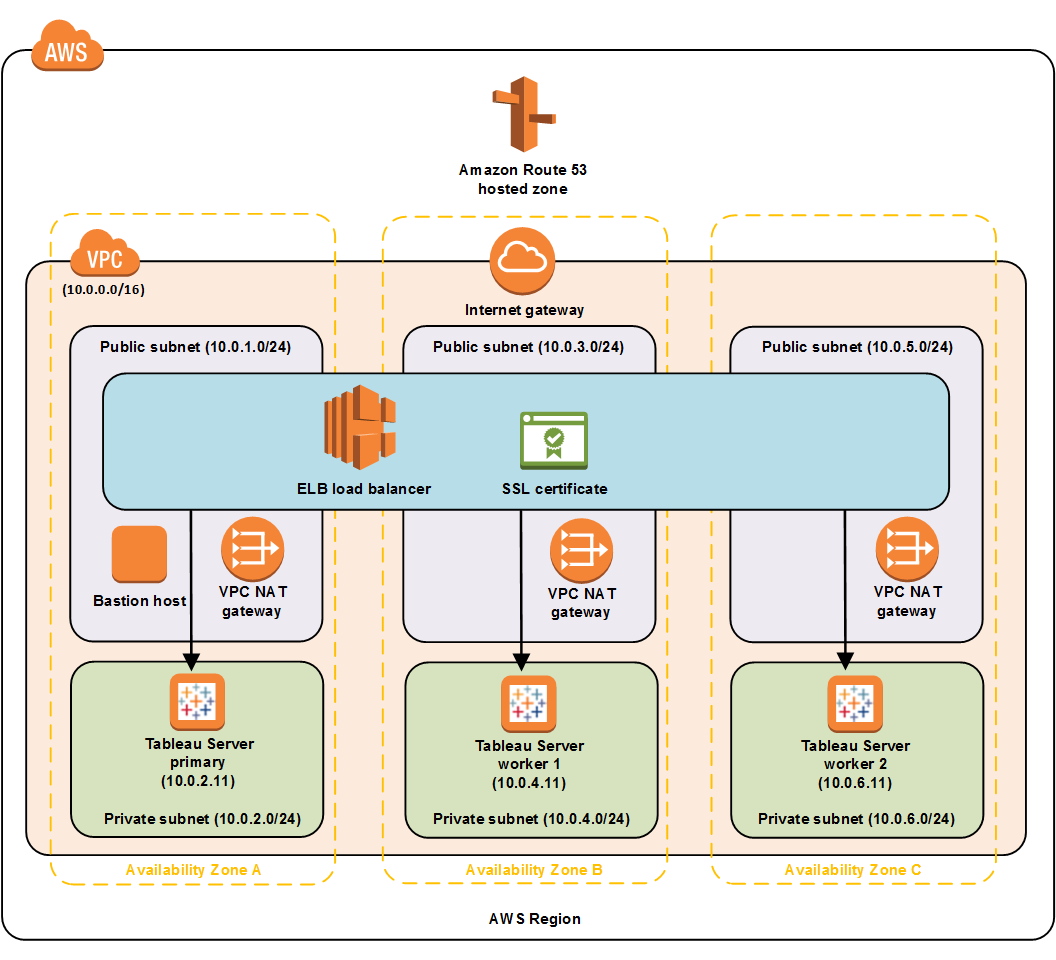

Tons of manual processes
Problem
Human work does not scale well.
Error prone
Upgrades, test and dev systems deploymens are not agile enough
Lack of integration with modern CI/CD pipelines
Solution
Automate all processes with infrastructure provision scripts
Do not perform in-place upgrades: always build new from scratch and drop the old. Seriously.
Automate!
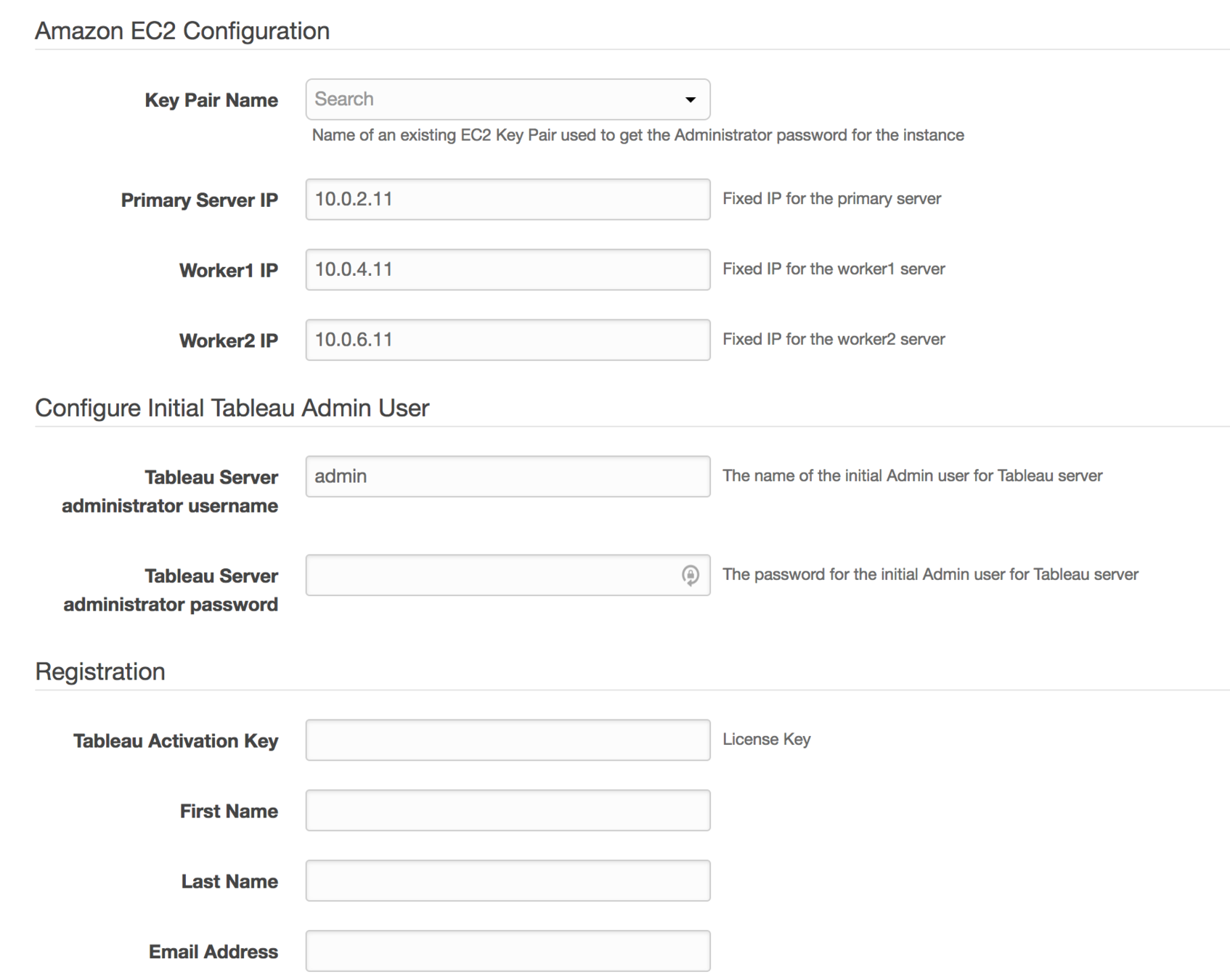
Automate using
- CloudFormation scripts
- Chef, Ansible, Terraform
- Docker
- ANYTHING JUST
DON'T DO MANUALLY
Docker Demo
Communication

Communication vs Tableau
Problem
Tableau does not have a good in-built communication system where administrators and CoE leaders can access their users
No out-of-the-box solution to access users in case of system outages
Solution
Add custom communication capabilities to Desktop and Server products
Custom Firewall and Loadbalancer scripts
Outage Notification
(Demo)
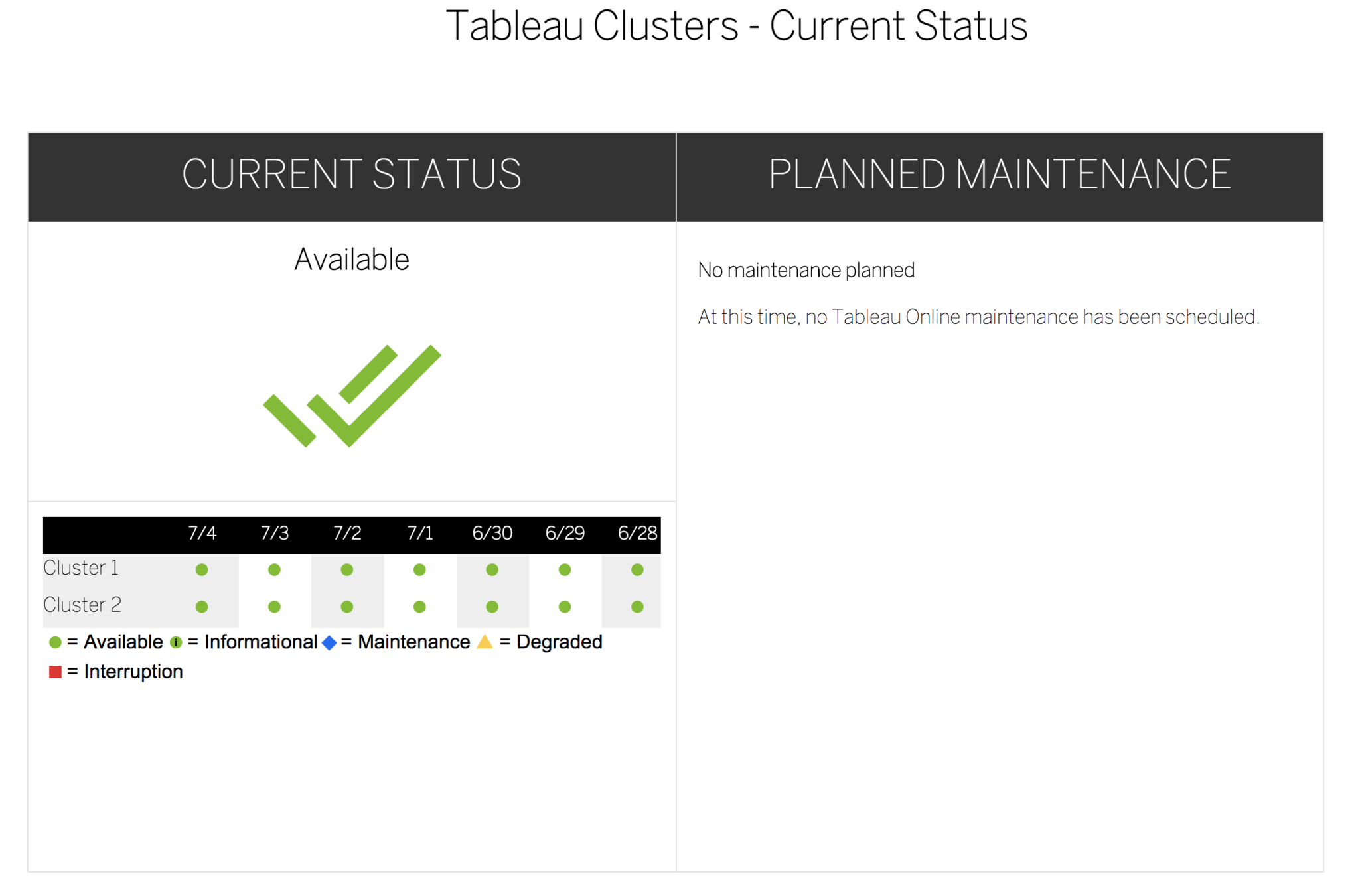
Notification Best Practices
- Custom Load Balancer Setup
- "Trust" or "Status" site
- Eliminate Emails
(use IM or in-vizportal)
CoE Communication
Customized Desktop
Understanding the infrastructure
Understand? What? Why?
Problem
Administrators usually have zero control on what gets published or where their servers connects. Getting answers to "what are my badly designed workbooks?", "what happens if a team changes their data model?" or "Is my Tableau Server fast enough for my overpaid manager?" can help to survive.
TabMon and many other tools do not scale.
Solution
Watch serverlogs, infrastructure events, repository and workbook/datasource XML sources and build sophisticated preventive and detective controls on top of them.
HOW?
The new serverlogs
New "res" block
{ ts: '2018-06-20T14:30:01.122',
pid: 3032,
tid: '20f4',
sev: 'info',
req: 'WypIyAulS@J5itywamnL1wAAASA',
sess: '5D4BA677DDAF4A8BAEDBA44064CEF65F-0:0',
site: 'Default',
user: 'Adminka',
k: 'end-ds-lazy-connect',
l: {},
a:
{ depth: 3,
elapsed: 0.004,
id: 'P////+XZkWNP/////4ekGx',
name: 'ds-lazy-connect',
res:
{ alloc: { e: 72600, i: 515000, ne: 648, ni: 4292 },
free: { e: 61900, i: 447000, ne: 540, ni: 3737 },
kcpu: { e: 0, i: 0 },
ntid: 1,
ucpu: { e: 2, i: 5 } },
rk: 'ok',
rv: {},
sponsor: 'P////+WHU/0JqVb8cD3IGA',
type: 'end',
vw: 'Economy',
wb: 'Regional' },
v:
{ caption: 'Stocks',
elapsed: 0.004,
name: 'dataengine.42038.846130138889' } }What is inside?
a:
{ depth: 3,
elapsed: 0.004,
id: 'P////+XZkWNP/////4ekGx',
name: 'ds-lazy-connect',
res:
{ alloc: { e: 72600, i: 515000, ne: 648, ni: 4292 },
free: { e: 61900, i: 447000, ne: 540, ni: 3737 },
kcpu: { e: 0, i: 0 },
ntid: 1,
ucpu: { e: 2, i: 5 } },
alloc: memory
free: free'd up memory
ucpu: CPU consumption (application side)
kcpu: CPU consumption (kernel side)
ntid: used threads
e = exclusive (self), i = inclusive (self + children), ne = number of exclusive calls, ni = number of inclusive calls.
Real-time, proactive alerting
But what about the metadata?
Lineage, database tables and columns are in the XML files
Metadata directly available in the Dashboard
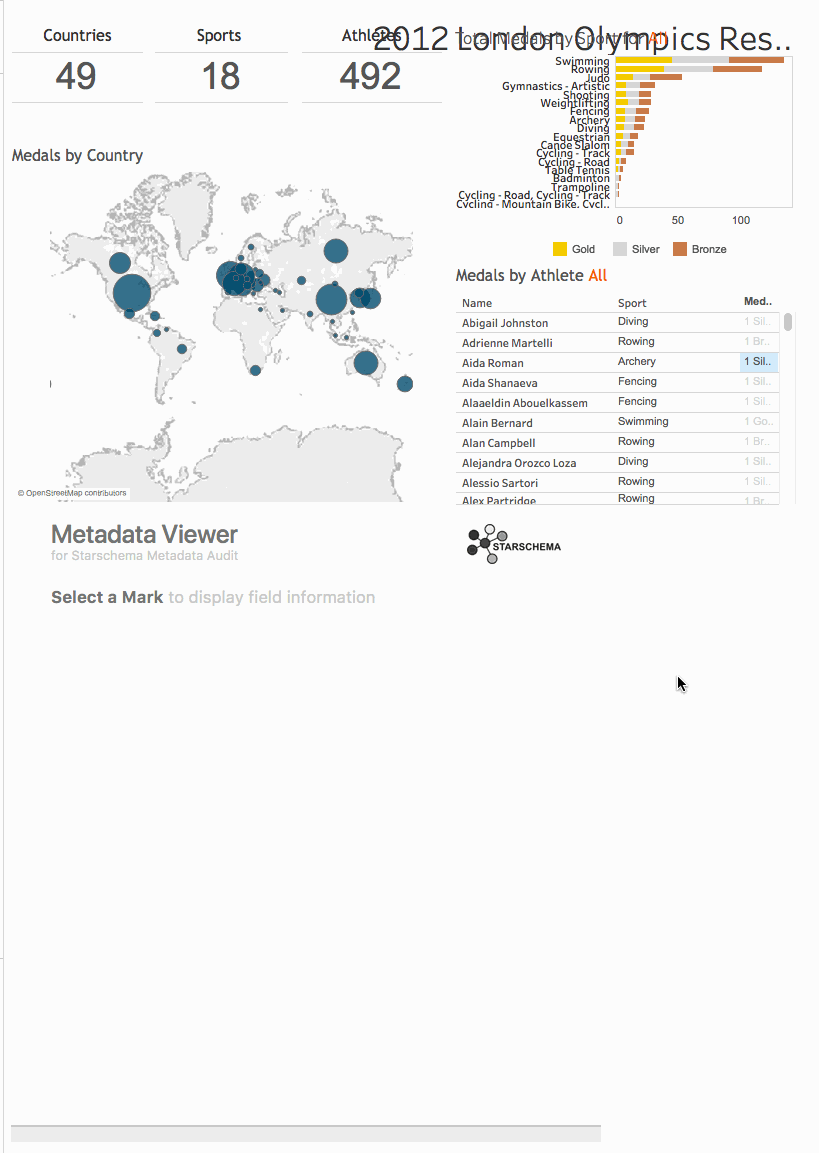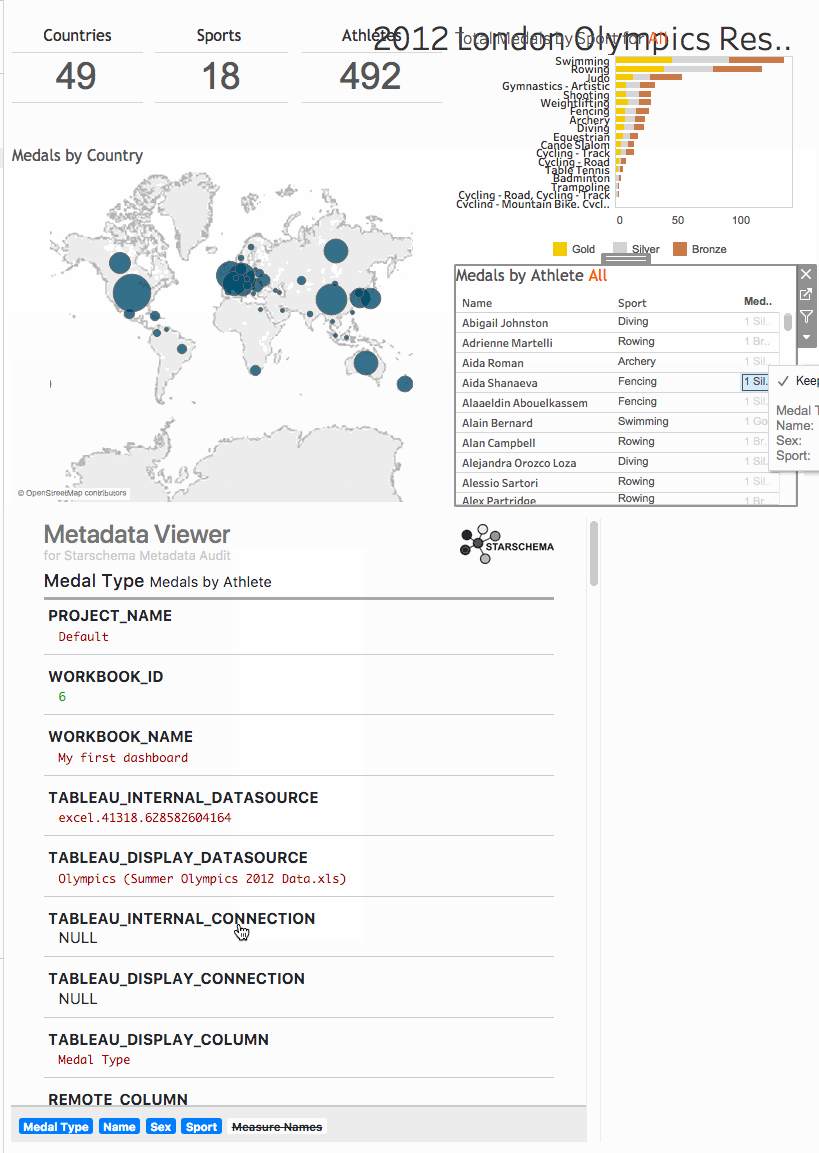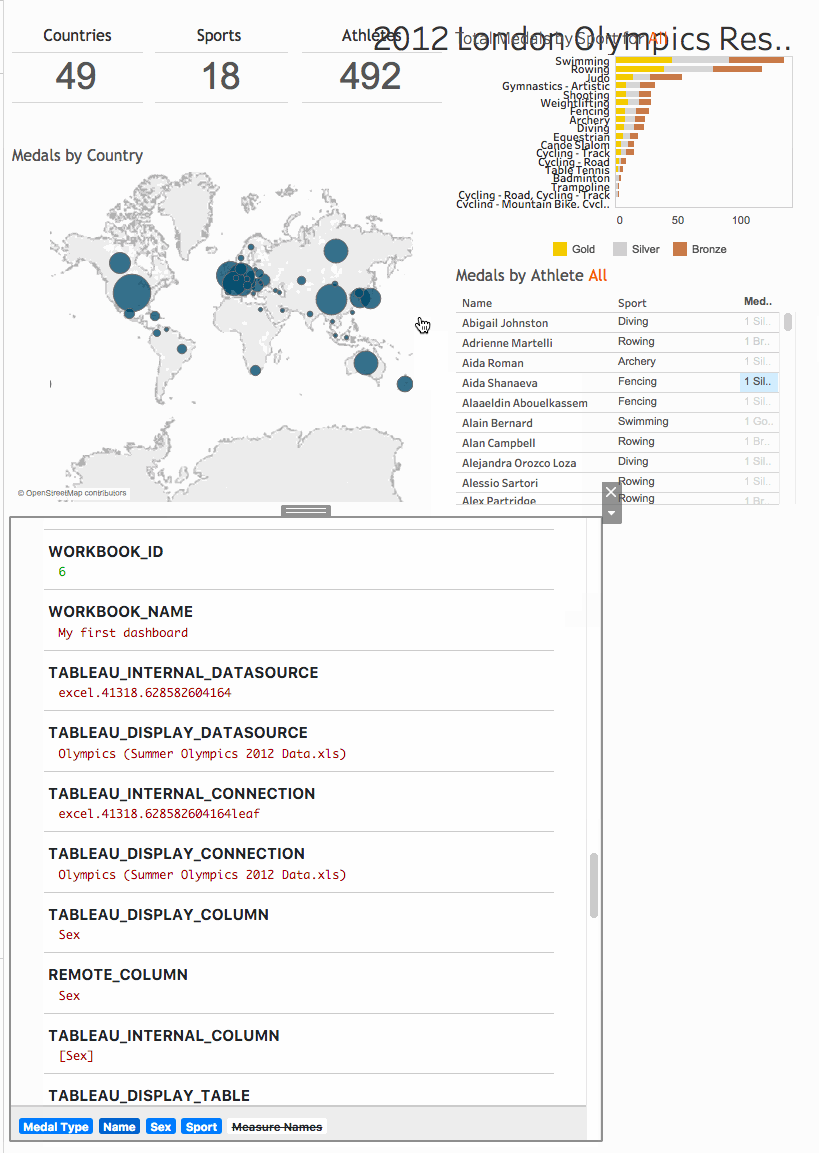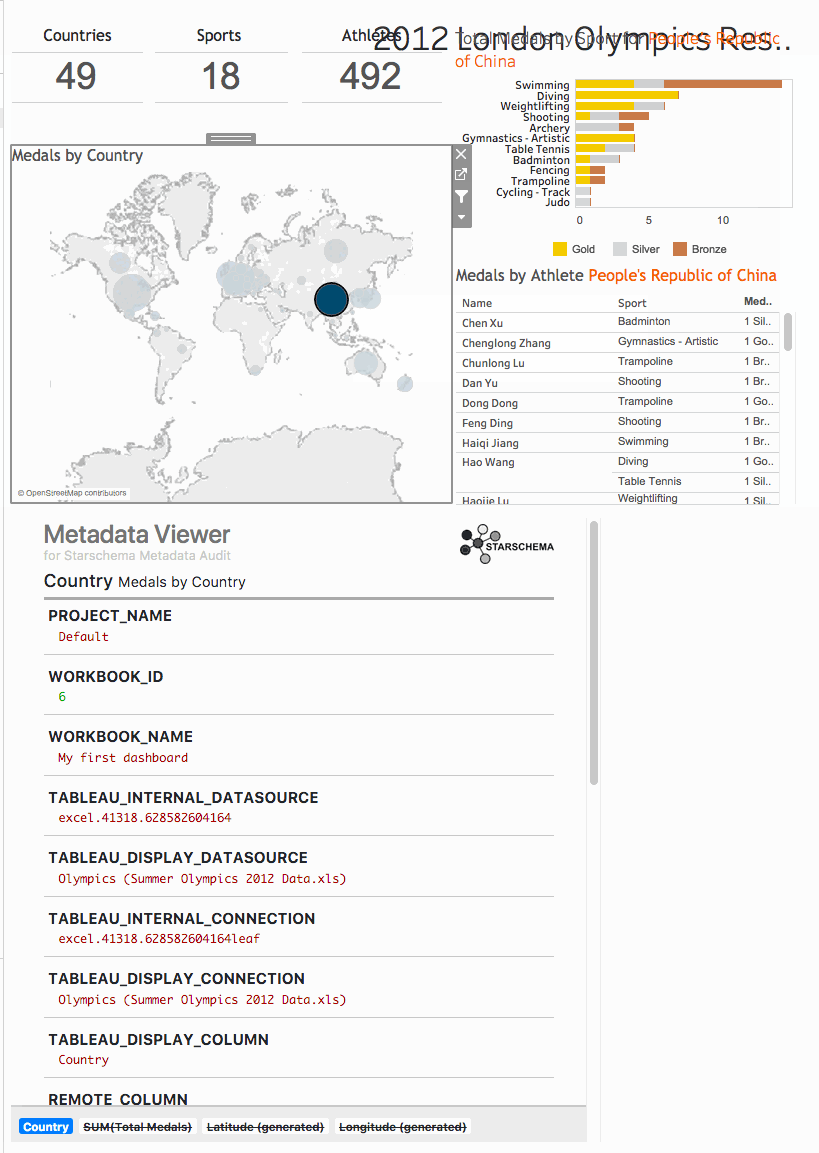
DEMO
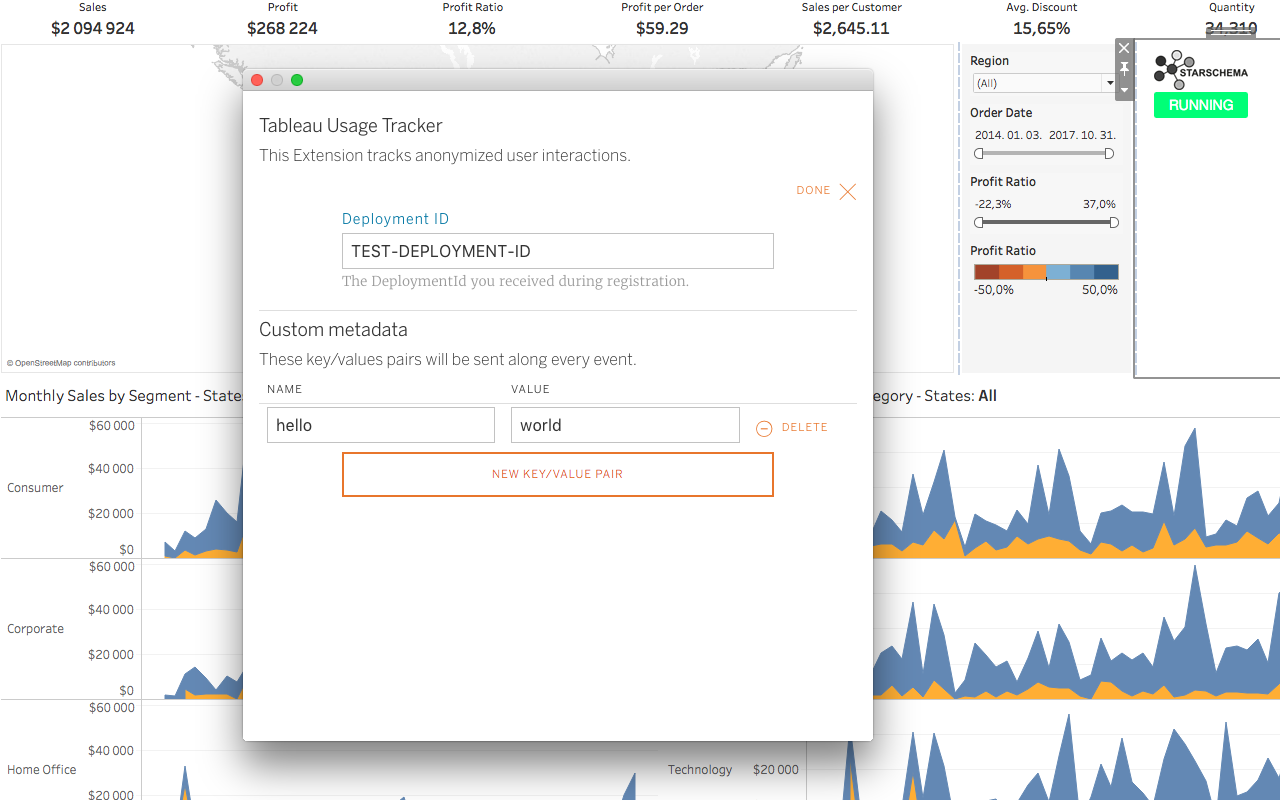
How to understand your users?
Tableau Tracker Demo
Advanced Topics
Off-site backup
Problem
Traditional Tableau backups can quickly grow into hundreds of GB-s and take hours to create on your primary node.
Backup frequency will necessary go down and if a problem occurs between backups multiple day’s worth of data might be lost.
Solution
Off-load backup to external computers: stream postgres repository outside the cluster and replicate filestore. Build tsbak files on separate machine. This also supports point-in-time recovery.
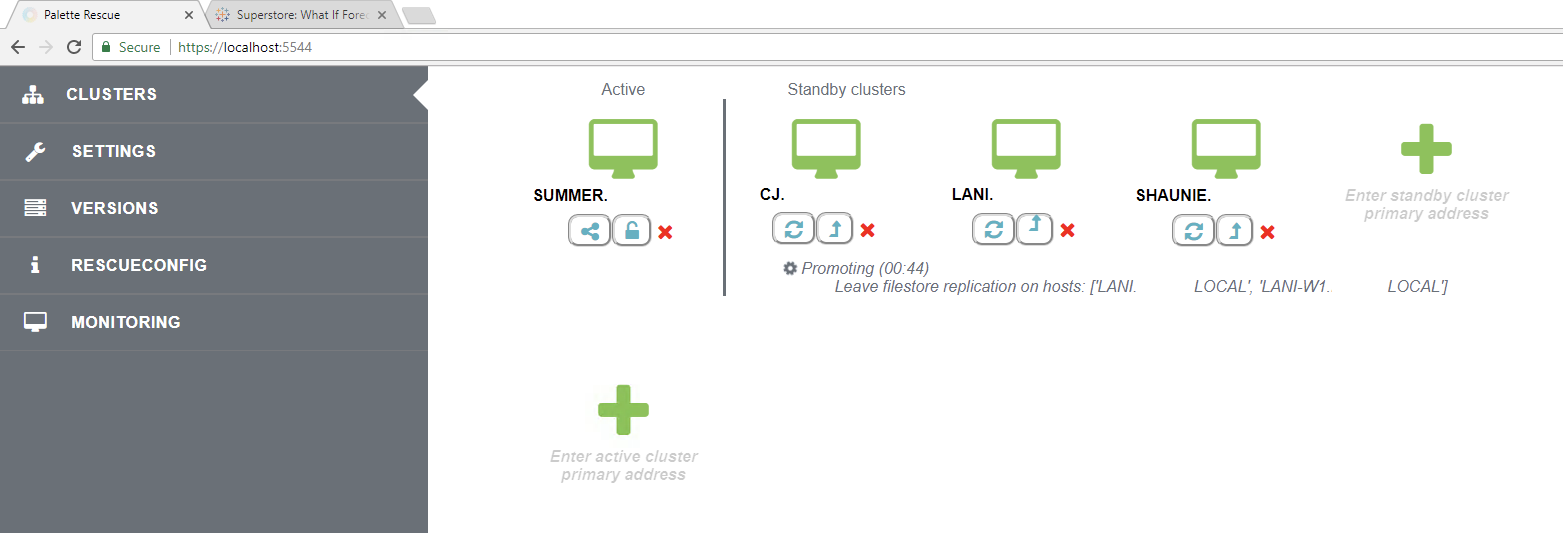
Disaster Recovery /
Multi-region Replicatoin
Traffic Management
Problem
CEO spends 2$m on data visualisation then cries that her reports are slow
Backgound jobs fail to make their SLA
Web Authoring slows down the system when users are experimenting
Solution
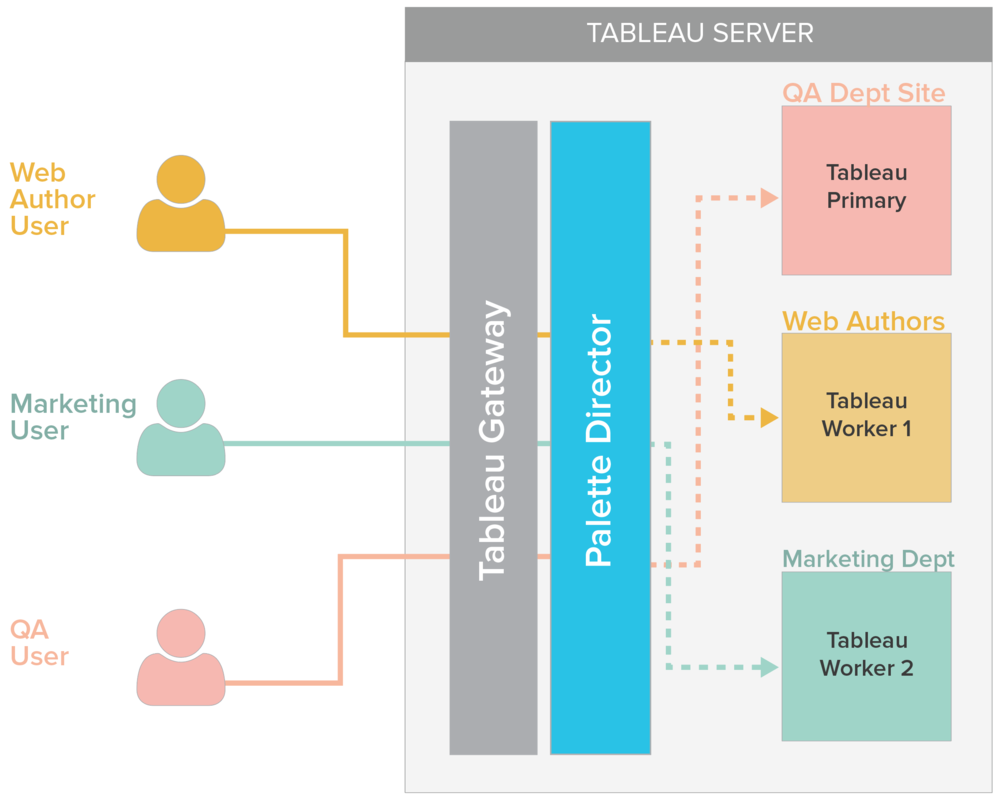
Isolate unpredictable load (QA site, interactive users, special set of background jobs) to dedicated hosts/processes
Route specific user groups to dedicated resources
Traffic Management
Questions?
Tamas Foldi
tfoldi@starschema.com / twitter: @tfoldi
DCTUG
By Tamas Foldi
DCTUG
DCTUG



