H.J. Terry Suh, MIT

Leveraging Structure for Efficient and Dexterous Contact-Rich Manipulation
[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
Part 2. Local Planning / Control via Dynamic Smoothing
Part 1. Understanding RL with Randomized Smoothing
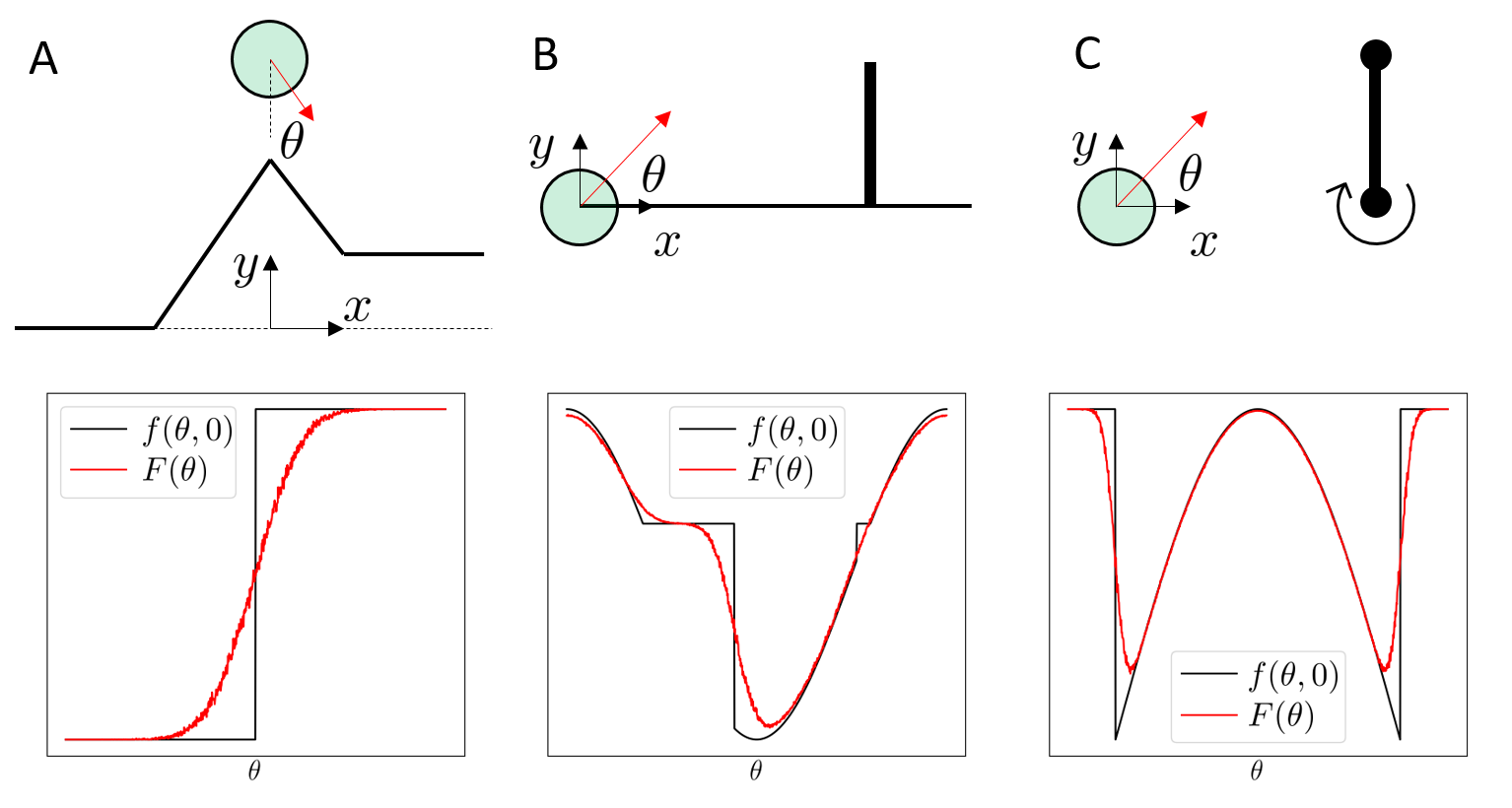
Introduction

[TRO 2023, TRO 2025]
Introduction
Why contact-rich manipulation?
What has been done, and what's lacking?
What is manipulation?
How hard could this be? Just pick and place!
Rigid-body manipulation: Move object from pose A to pose B

A
B
Manipulation is NOT pick & place

[ZH 2022]
[SKPMAT 2022]
[PSYT 2022]

[ST 2020]


Manipulation: An Important Problem

Matt Mason, "Towards Robotic Manipulation", 2018
Manipulation: An Important Problem
Matt Mason, "Towards Robotic Manipulation", 2018
Manipulation is a core capability for robots to broaden the spectrum of things we can automate in this world.



DexAI
TRI Dishwasher Demo

Flexxbotics
ETH Zurich, Robotic Systems Lab
What is Contact-Rich Manipulation?
Why should there be an inherent value in studying
manipulation that is rich in contact?
What is Contact-Rich Manipulation?
Why should there be an inherent value in studying
manipulation that is rich in contact?
Matt Mason, "Towards Robotic Manipulation", 2018
Manipulation
What is Contact-Rich Manipulation?
Matt Mason, "Towards Robotic Manipulation", 2018
Manipulation
What is Contact-Rich Manipulation?
Matt Mason, "Towards Robotic Manipulation", 2018
Manipulation
What is Contact-Rich Manipulation?
Matt Mason, "Towards Robotic Manipulation", 2018
Manipulation
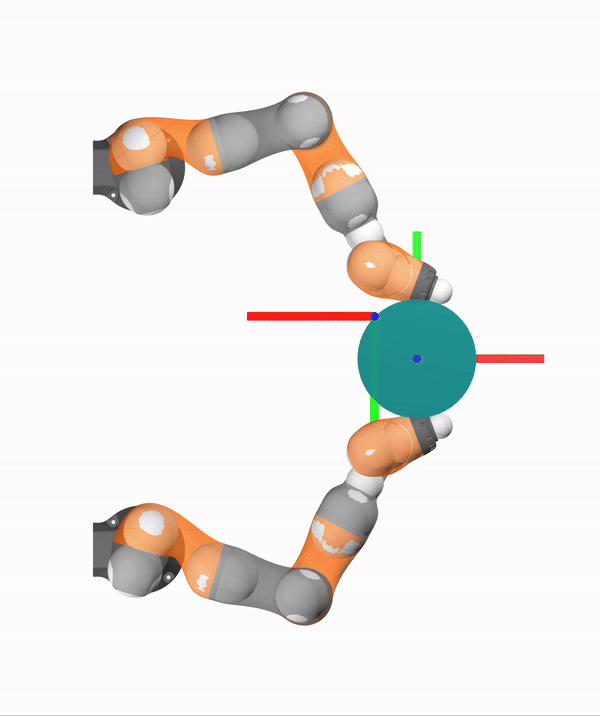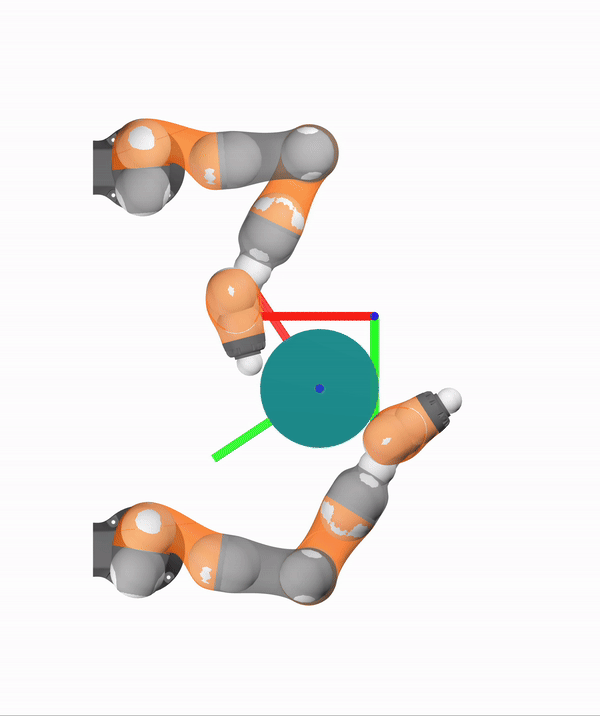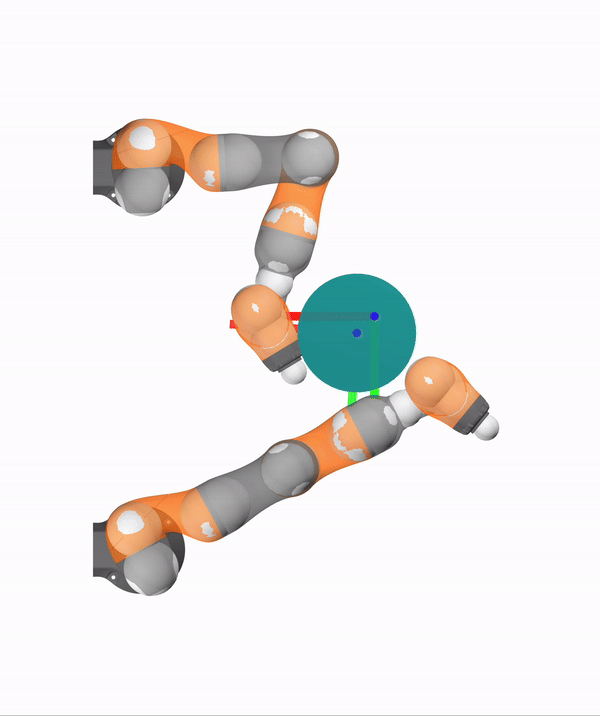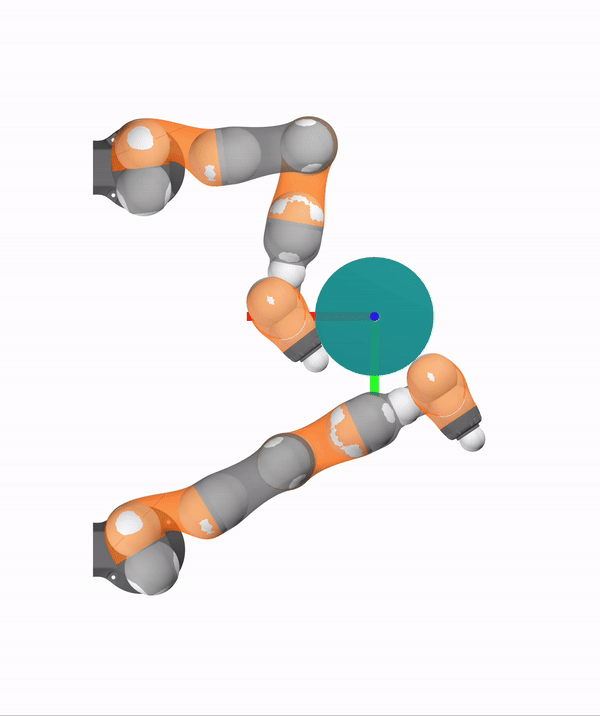

- Where do I make contact?
- Where should I avoid contact?
- With what timing?
- What do I do after making contact?
What is Contact-Rich Manipulation?
Matt Mason, "Towards Robotic Manipulation", 2018
Manipulation
- Where do I make contact?
- Where should I avoid contact?
- With what timing?
- What do I do after making contact?
As possibilities become many, strategic decisions become harder.
What is Contact-Rich Manipulation?
Manipulation
Manipulation that strategically makes decisions about contact after considering multiple possible ways of selecting contact, especially when such possibilities are many.
Contact-Rich Manipulation
H.J. Terry Suh, PhD Thesis
Matt Mason, "Towards Robotic Manipulation", 2018
What is Contact-Rich Manipulation?
Manipulation
Manipulation that strategically makes decisions about contact after considering multiple possible ways of selecting contact, especially when such possibilities are many.
Contact-Rich Manipulation
H.J. Terry Suh, PhD Thesis
Matt Mason, "Towards Robotic Manipulation", 2018
- Doesn't necessarily have to behaviorally result in many contacts.
What is Contact-Rich Manipulation?
Manipulation
Manipulation that strategically makes decisions about contact after considering multiple possible ways of selecting contact, especially when such possibilities are many.
Contact-Rich Manipulation
H.J. Terry Suh, PhD Thesis
Matt Mason, "Towards Robotic Manipulation", 2018
- Doesn't necessarily have to behaviorally result in many contacts.
- Shouldn't artificially restrict possible contacts from occuring.
Case 1. Whole-Body Manipulation
Do not make contact
(Collision-free Motion Planning)
Make Contact
Human
Robot
Slide inspired by Tao Pang's Thesis Defense & TRI Punyo Team

Case 2. Dexterous Manipulation
Human
Robot

Wonik Allegro Hand

Why Contact-Rich Manipulation?
A capable embodied intelligence must be able to exploit its physical embodiment to the fullest.
Manipulation that strategically makes decisions about contact after considering multiple possible ways of selecting contact, especially when such possibilities are many.
Contact-Rich Manipulation
H.J. Terry Suh, PhD Thesis
[TRO 2023, TRO 2025]
Introduction
Why contact-rich manipulation?
What has been done, and what's lacking?
[TRO 2023, TRO 2025]
Introduction
What has been done, and what's lacking?
Why contact-rich manipulation?
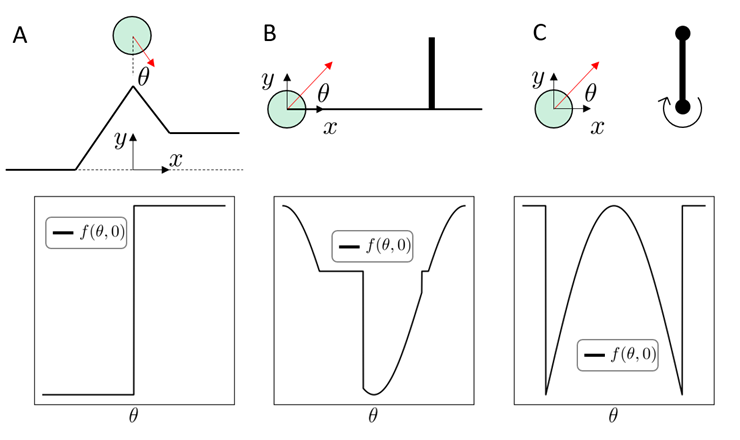
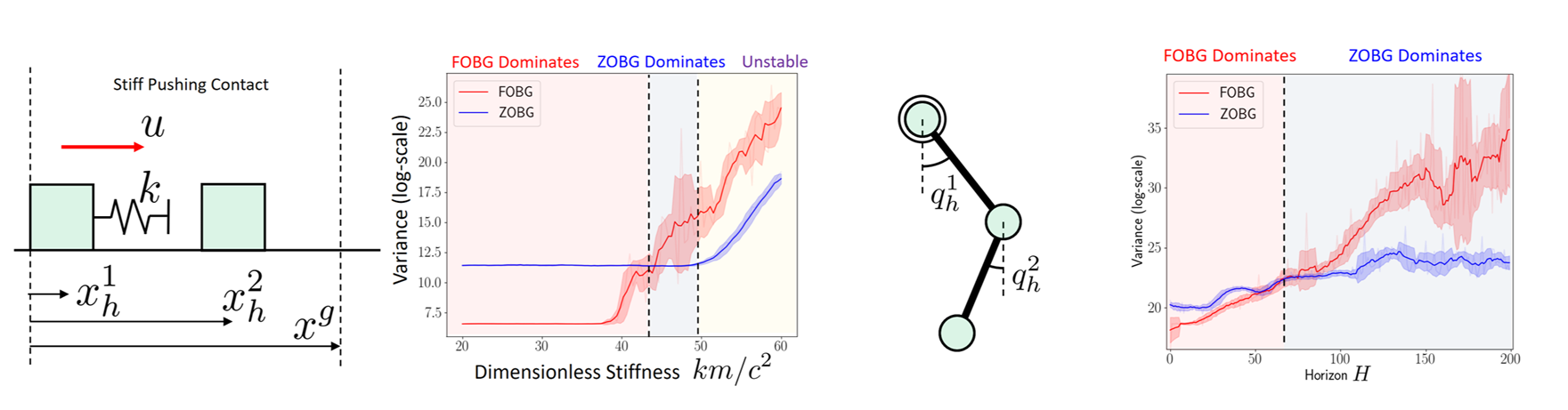
Fundamental Challenges
Cost
Cost
Cost
Fundamental Challenges
Flatness and Stiffness spells difficulty for local gradient-based optimizers.
Cost
Cost
Cost
Smooth Analysis
But GIVEN a contact event, the landscape is smooth.
Cost
Cost
Cost

[Salisbury Hand, 1982]
[Murray, Li, Sastry]

What can we do given a contact mode?
Smooth Planning & Control
Combinatorial Optimization
Cost
Cost
Cost
Can we try to globally search for the right "piece"?
Hybrid Dynamics & Combinatorial Optimization
Contact dynamics as a "hybrid system" with continuous and discrete components.
[Sreenath et al., 2009]
Hybrid Dynamics & Combinatorial Optimization
[Hogan et al., 2009]
[Graesdal et al., 2024]
Beautiful results in locomotion & manipulation
Problems with Mode Enumeration
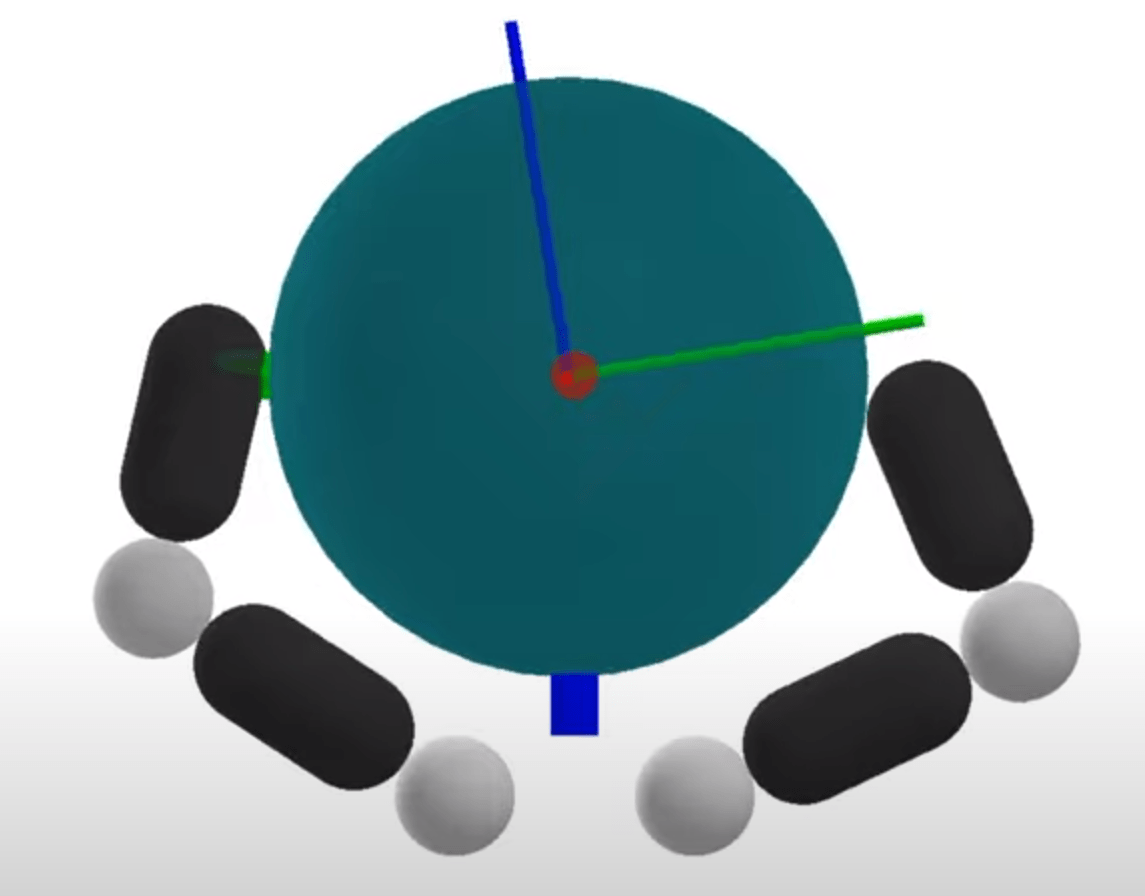
System
Number of Modes
\begin{aligned}
N = 2
\end{aligned}
\begin{aligned}
N = 3^{\binom{9}{2}}
\end{aligned}
No Contact
Sticking Contact
Sliding Contact
Number of potential active contacts
Problems with Mode Enumeration
System
Number of Modes
\begin{aligned}
N = 3^{\binom{20}{2}} \approx 4.5 \times 10^{90}
\end{aligned}
The number of modes scales terribly with system complexity
\begin{aligned}
N = 2
\end{aligned}
\begin{aligned}
N = 3^{\binom{9}{2}}
\end{aligned}
No Contact
Sticking Contact
Sliding Contact
Number of potential active contacts
Contact Relaxation & Smooth NLP
[Posa et al., 2015]
[Mordatch et al., 2012]
Reinforcement Learning
[OpenAI et al., 2019]
[Handa et al., 2024]
Reinforcement Learning
[OpenAI et al., 2019]
Summary of Previous Approaches
Classical Mechanics
Contact Scalability
Efficiency
Global Scope


Summary of Previous Approaches
Classical Mechanics
Hybrid Dynamics &
Combinatorial Optimization
Contact Scalability
Efficiency
Global Scope
Summary of Previous Approaches
Classical Mechanics
Hybrid Dynamics &
Combinatorial Optimization
Contact Relaxation &
Smooth Nonlinear Programming
Contact Scalability
Efficiency
Global Scope
Summary of Previous Approaches
Classical Mechanics
Hybrid Dynamics &
Combinatorial Optimization
Contact Relaxation &
Smooth Nonlinear Programming
Reinforcement Learning
Contact Scalability
Efficiency
Global Scope
Summary of Previous Approaches
Classical Mechanics
Hybrid Dynamics &
Combinatorial Optimization
Contact Relaxation &
Smooth Nonlinear Programming
Reinforcement Learning
Contact Scalability
Efficiency
Global Scope
How can we achieve all three criteria?
Introduction
What has been done, and what's lacking?
Why contact-rich manipulation?
Part 3. Global Planning for Contact-Rich Manipulation
Part 2. Local Planning / Control via Dynamic Smoothing
Part 1. Understanding RL with Randomized Smoothing
Introduction
Preview of Results
Our Method
Contact Scalability
Efficiency
Global Planning
60 hours, 8 NVidia A100 GPUs
5 minutes, 1 Macbook CPU

[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
Part 2. Local Planning / Control via Dynamic Smoothing
Part 1. Understanding RL with Randomized Smoothing
Introduction
[TRO 2023, TRO 2025]
Part 1. Understanding RL with Randomized Smoothing
Why does RL
perform well?
Why is it considered inefficient?
Can we do better with more structure?
[RA-L 2021, ICML 2022]
[TRO 2023, TRO 2025]
Part 1. Understanding RL with Randomized Smoothing
Why does RL
perform well?
Why is it considered inefficient?
Can we do better with more structure?
[RA-L 2021, ICML 2022]
How does RL search through these difficult problems?
Original Problem
\begin{aligned}
\min_x F(x)
\end{aligned}
[ICML 2022]
Cost
Cost
Cost
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
How does RL search through these difficult problems?
Randomized Smoothing
\begin{aligned}
\min_x \mathbb{E}_w F(x+w)
\end{aligned}
[ICML 2022]
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
How does RL search through these difficult problems?
Randomized Smoothing
\begin{aligned}
\min_x \mathbb{E}_w F(x+w)
\end{aligned}
[ICML 2022]
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
Noise regularizes difficult landscapes,
allevates flatness and stiffness,
abstracts contact modes.
[TRO 2023, TRO 2025]
Part 1. Understanding RL with Randomized Smoothing
Why does RL
perform well?
Why is it considered inefficient?
Can we do better with more structure?
[RA-L 2021, ICML 2022]
How does RL search through these difficult problems?
Randomized Smoothing
\begin{aligned}
\min_x \mathbb{E}_w F(x+w)
\end{aligned}
[ICML 2022]
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
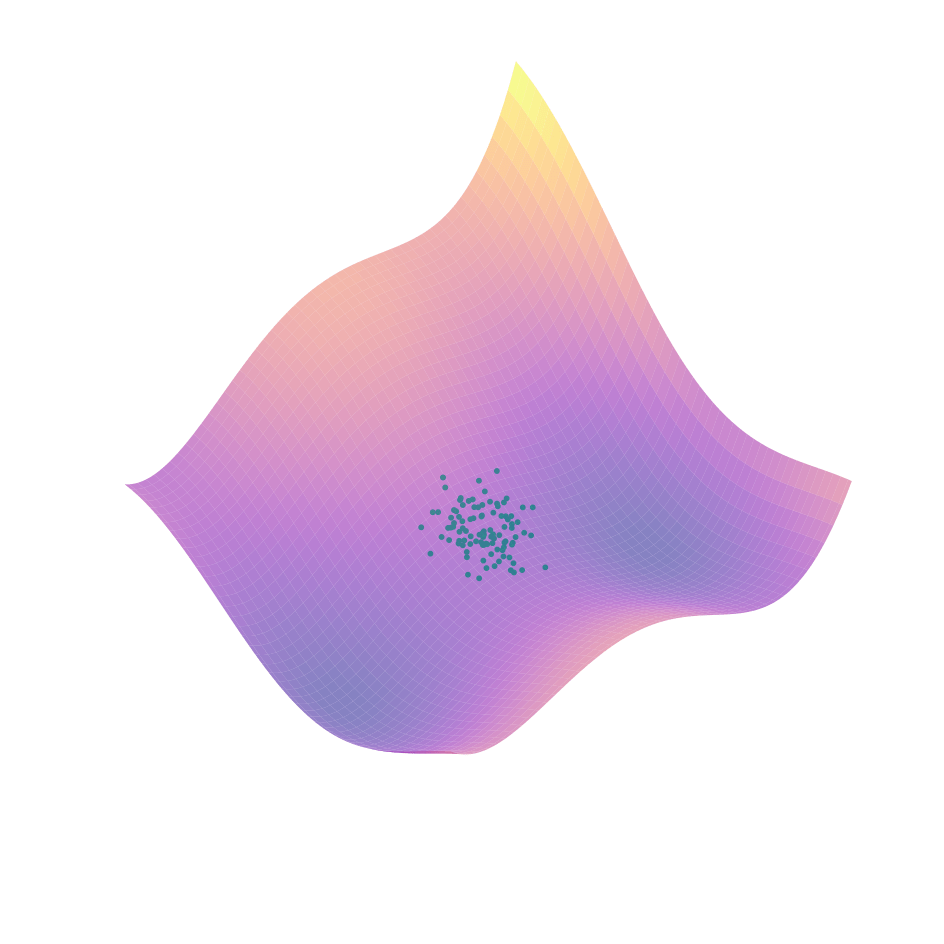
But how do we take gradients of a stochastic function?
\nabla_x \mathbb{E}_w F(x+w)
Estimation of Gradients with Monte Carlo
\begin{aligned}
& \nabla_x\mathbb{E}_{w\sim\rho}F(x+{w}) \\
= & \min_{\mathbf{J},\mu}\mathbb{E}_{w\sim\rho}\|F(x + w) - (\mathbf{J}w +\mu)\|^2 \\
\approx & \frac{1}{N}\sum^N_{i=1} \|F(x + w_i) - (\mathbf{J}w_i +\mu)\|^2
\end{aligned}
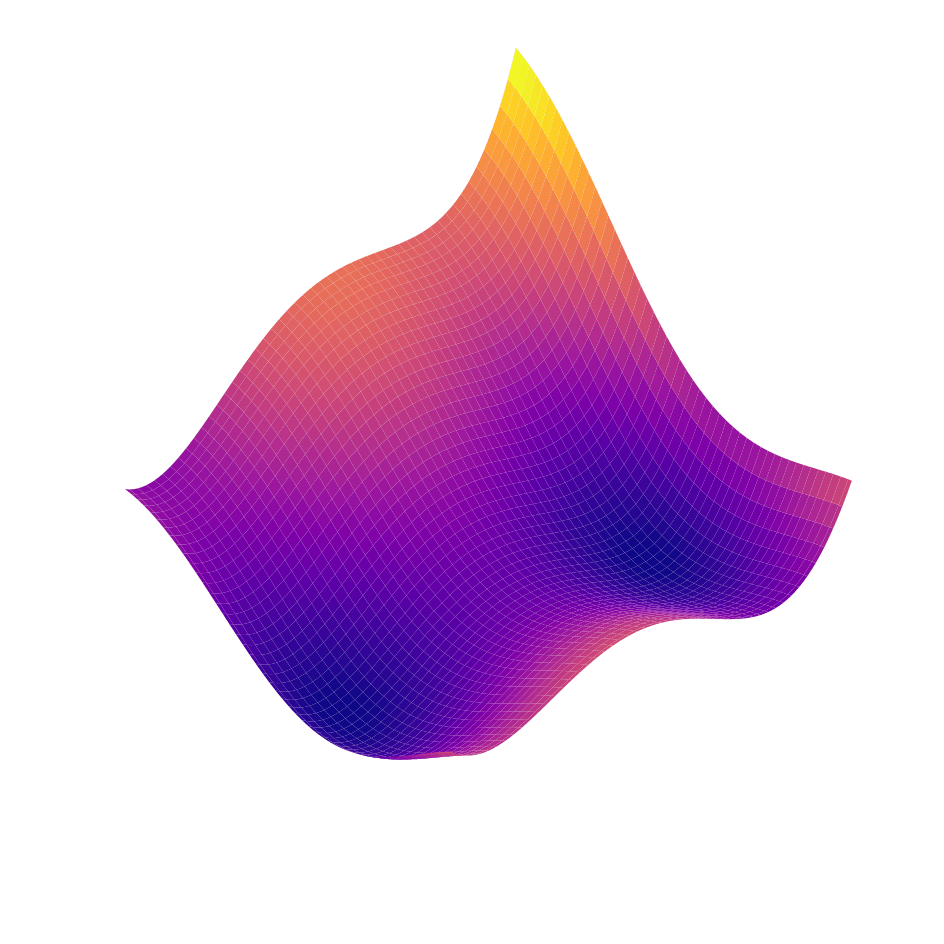
Zeroth-Order Gradient Estimator
- Stein Gradient Estimator
- REINFORCE
- Score Function / Likelihood Ratio Estimator
Estimation of Gradients with Monte Carlo
\begin{aligned}
& \nabla_x\mathbb{E}_{w\sim\rho}F(x+{w}) \\
= & \min_{\mathbf{J},\mu}\mathbb{E}_{w\sim\rho}\|F(x + w) - (\mathbf{J}w +\mu)\|^2 \\
\approx & \frac{1}{N}\sum^N_{i=1} \|F(x + w_i) - (\mathbf{J}w_i +\mu)\|^2
\end{aligned}
Zeroth-Order Gradient Estimator
- Stein Gradient Estimator
- REINFORCE
- Score Function / Likelihood Ratio Estimator
Estimation of Gradients with Monte Carlo

\begin{aligned}
& \nabla_x\mathbb{E}_{w\sim\rho}F(x+{w}) \\
= & \min_{\mathbf{J},\mu}\mathbb{E}_{w\sim\rho}\|F(x + w) - (\mathbf{J}w +\mu)\|^2 \\
\approx & \frac{1}{N}\sum^N_{i=1} \|F(x + w_i) - (\mathbf{J}w_i +\mu)\|^2
\end{aligned}
Zeroth-Order Gradient Estimator
- Stein Gradient Estimator
- REINFORCE
- Score Function / Likelihood Ratio Estimator
Estimation of Gradients with Monte Carlo
\begin{aligned}
& \nabla_x\mathbb{E}_{w\sim\rho}F(x+{w}) \\
= & \min_{\mathbf{J},\mu}\mathbb{E}_{w\sim\rho}\|F(x + w) - (\mathbf{J}w +\mu)\|^2 \\
\approx & \frac{1}{N}\sum^N_{i=1} \|F(x + w_i) - (\mathbf{J}w_i +\mu)\|^2
\end{aligned}
Zeroth-Order Gradient Estimator
- Stein Gradient Estimator
- REINFORCE
- Score Function / Likelihood Ratio Estimator
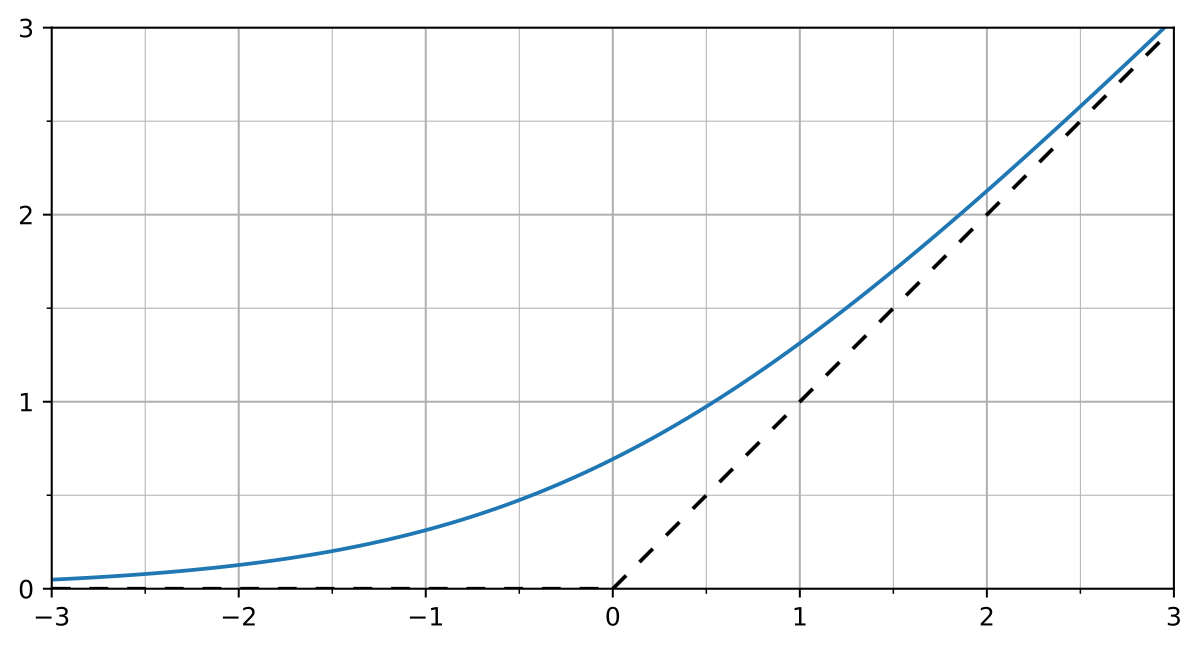
But what if we had access to gradients?
Leveraging Differentiable Physics
First-Order Randomized Smoothing
\begin{aligned}
& \frac{\partial}{\partial x}\mathbb{E}_{w\sim\rho}F(x+{w}) \\
= & \mathbb{E}_{w\sim\rho}\frac{\partial F}{\partial x}(x + w) \\
\approx & \frac{1}{N}\sum^N_{i=1} \frac{\partial F}{\partial x}(x + w_i)
\end{aligned}
- Gradient Sampling Algorithm
From John Duchi's Slides on Randomized Smoothing, 2014
Leveraging Differentiable Physics
First-Order Randomized Smoothing
\begin{aligned}
& \frac{\partial}{\partial x}\mathbb{E}_{w\sim\rho}F(x+{w}) \\
= & \mathbb{E}_{w\sim\rho}\frac{\partial F}{\partial x}(x + w) \\
\approx & \frac{1}{N}\sum^N_{i=1} \frac{\partial F}{\partial x}(x + w_i)
\end{aligned}
- Gradient Sampling Algorithm
From John Duchi's Slides on Randomized Smoothing, 2014
So which one should we use?
Comparison of Efficiency
Bias
Variance
First-Order Estimator
Zeroth-Order Estimator
\nabla_x \mathbb{E}_w F(x+w)
Comparison of Efficiency
Analytic Expression
First-Order Gradient Estimator
Zeroth-Order Gradient Estimator
- Requires differentiability over dynamics
- Generally lower variance.
- Least requirements (blackbox)
- High variance.
Possible for only few cases
Structure
Efficiency
\nabla_x \mathbb{E}_w F(x+w)
[TRO 2023, TRO 2025]
Part 1. Understanding RL with Randomized Smoothing
Why does RL
perform well?
Why is it considered inefficient?
Can we do better with more structure?
[RA-L 2021, ICML 2022]
Bias
Variance
First-Order Estimator
Zeroth-Order Estimator
Comparison of Efficiency
Analytic Expression
First-Order Gradient Estimator
Zeroth-Order Gradient Estimator
- Requires differentiability over dynamics
- Generally lower variance.
- Least requirements (blackbox)
- High variance.
Possible for only few cases
Structure
Efficiency
\nabla_x \mathbb{E}_w F(x+w)
Can we transfer this promise to RL?
Leveraging Differentiable Physics

Do Differentiable Simulators Give Better Gradients?
Leveraging Differentiable Physics
Do Differentiable Simulators Give Better Gradients?
Bias of First-Order Estimation
Bias of First-Order Estimation
Bias of First-Order Estimation
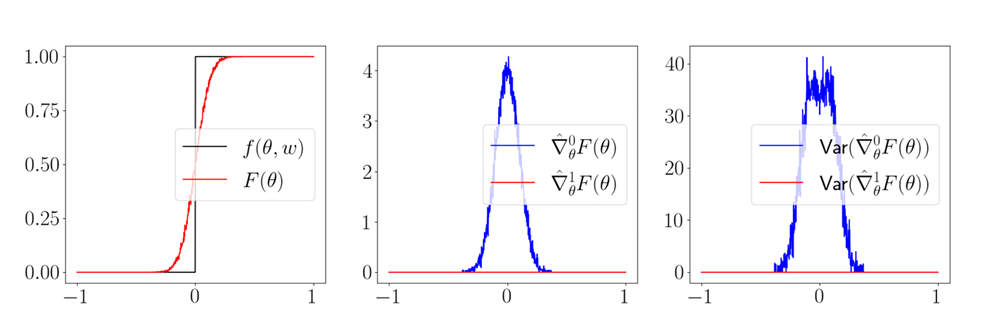
\begin{aligned}
\nabla_x \mathbb{E}_w F(x + w) & = \mathbb{E}_w F(x + w) = \frac{1}{N}\sum^N_{i=1}\nabla_x F(x + w_i)
\end{aligned}
Bias of First-Order Estimation
Variance of First-Order Estimation
First-order Estimators CAN have more variance than zeroth-order ones.
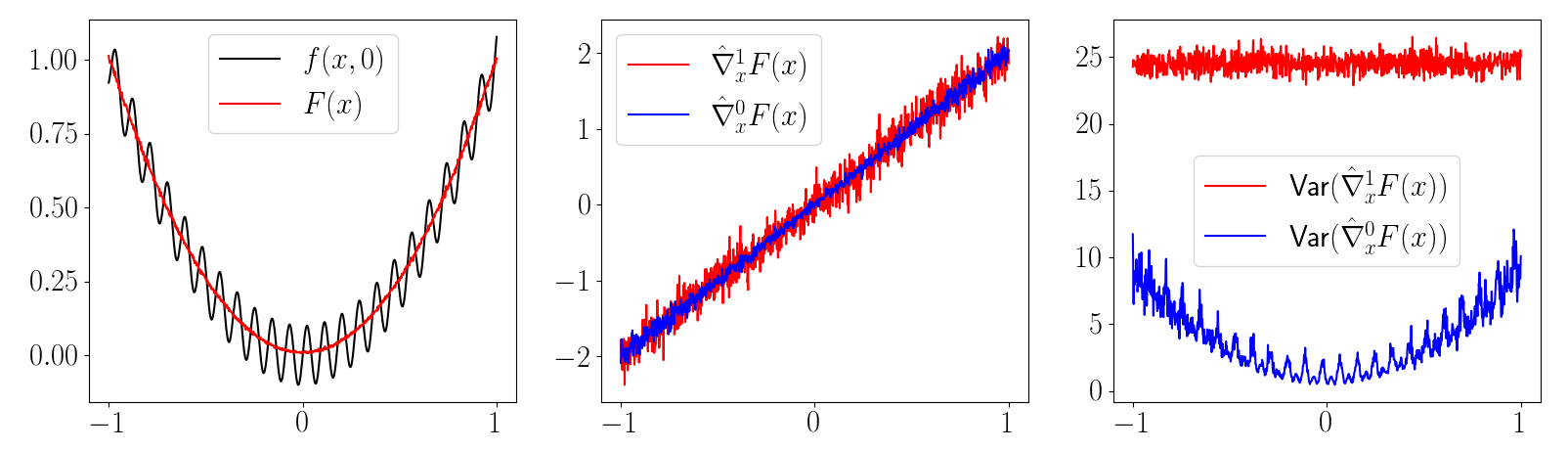
Variance of First-Order Estimation

\phi
- No force when not in contact
- Spring-damper behavior when in contact
Variance of First-Order Estimation
\phi
- No force when not in contact
- Spring-damper behavior when in contact
Variance of First-Order Estimation
\phi
- No force when not in contact
- Spring-damper behavior when in contact
Prevalent for models that approximate contact through spring-dampers!
Gradients
Gradients
Bias
Variance
Common lesson from stochastic optimization:
1. Both are unbiased under sufficient regularity conditions
2. First-order generally has less variance than zeroth order.
Bias
Variance
Bias
Variance
1st Pathology: First-Order Estimators CAN be biased.
2nd Pathology: First-Order Estimators can have MORE
variance than zeroth-order.
Stiffness still hurts us in improving performance and efficiency
[TRO 2023, TRO 2025]
Part 1. Understanding RL with Randomized Smoothing
Why does RL
perform well?
Why is it considered inefficient?
Can we do better with more structure?
[RA-L 2021, ICML 2022]
Bias
Variance
First-Order Estimator
Zeroth-Order Estimator
Bias
Variance
First-Order Estimator
Zeroth-Order Estimator
[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
Part 2. Local Planning / Control via Dynamic Smoothing
Part 1. Understanding RL with Randomized Smoothing
Introduction
[TRO 2023, TRO 2025]
Part 2. Local Planning / Control via Dynamic Smoothing
Can we do better by understanding dynamics structure?
How do we build effective local optimizers for contact?
Utilizing More Structure
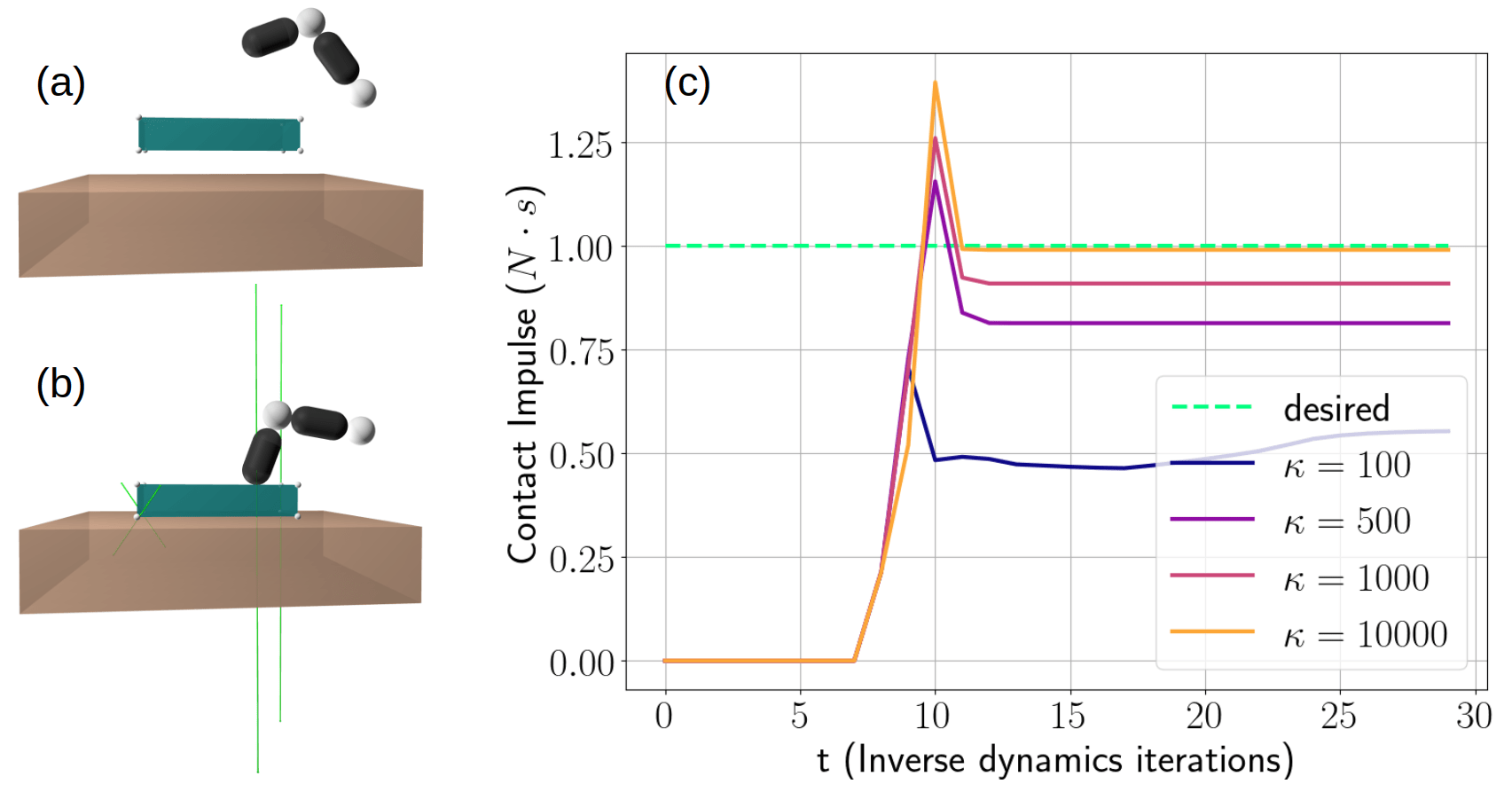
\lambda = k\min(\phi,0) + d\min(\phi,0)v
\phi
- No force when not in contact
- Spring-damper behavior when in contact
Tackling stiffness requires us to rethink about the models we use to simulate contact
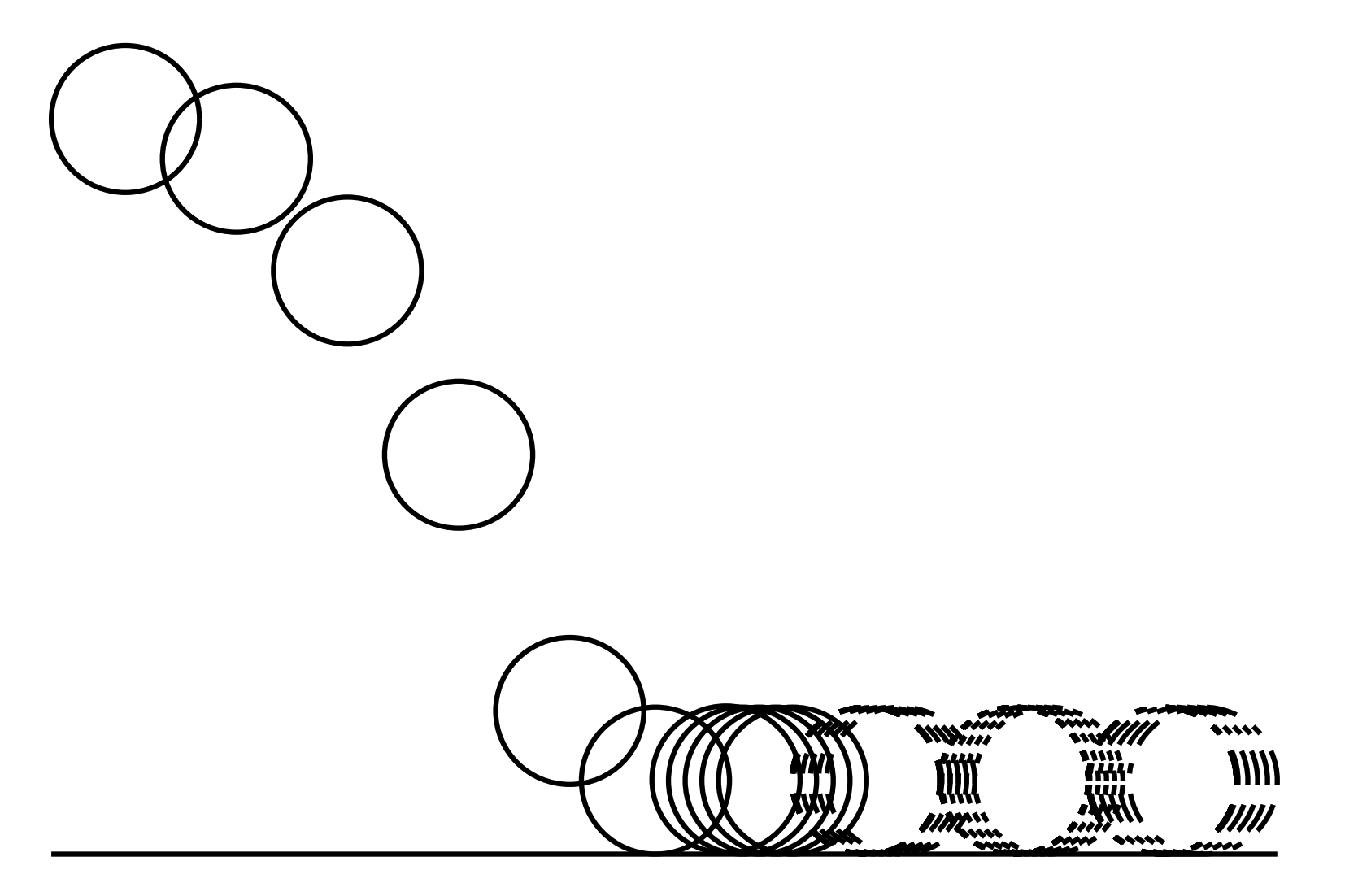
Intuitive Physics of Contact
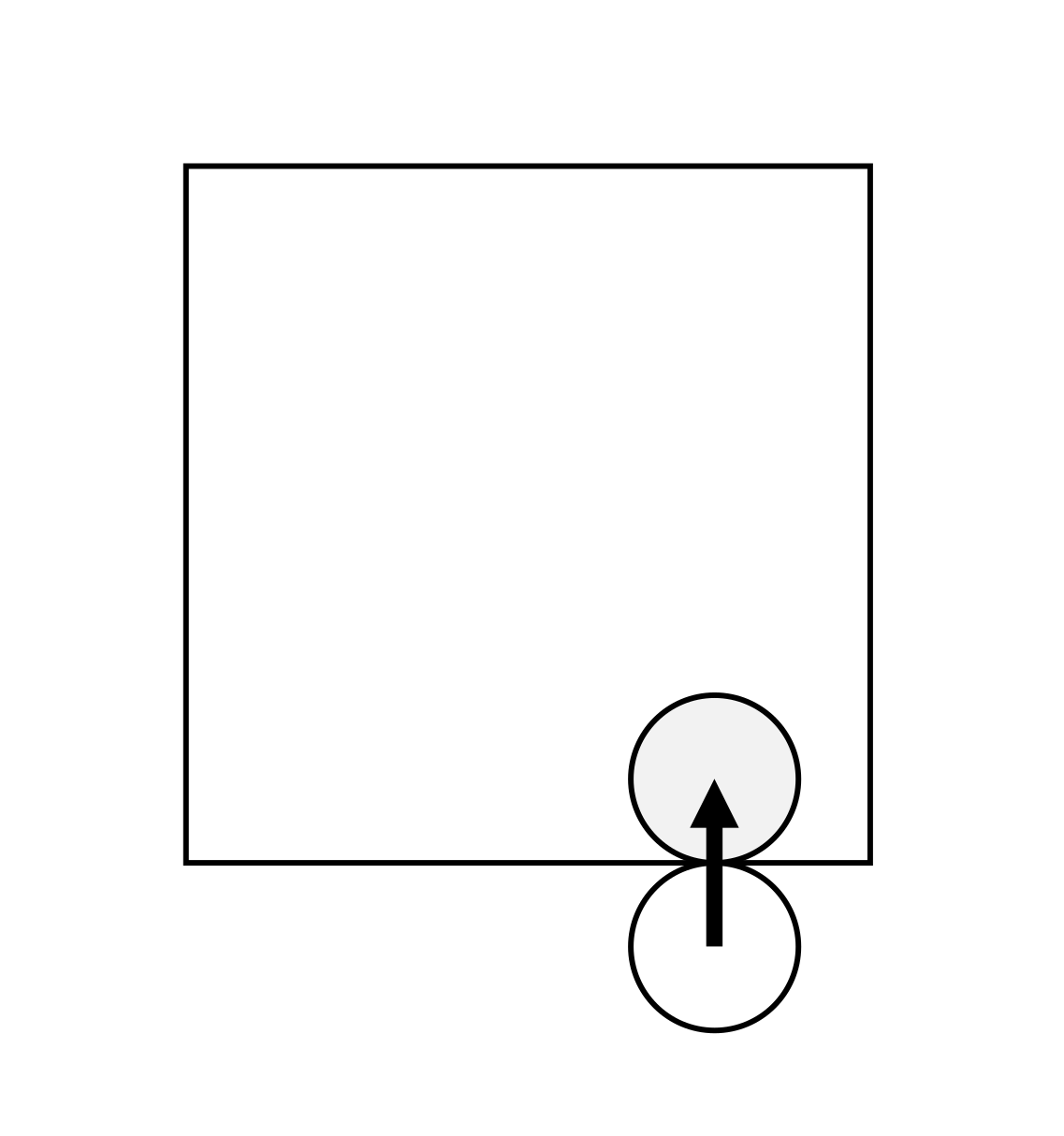
Where will the box move next?
Intuitive Physics of Contact
How did we know? Did we really have to integrate stiff springs?
Intuitive Physics of Contact
Intuitive Physics of Contact
How did we know? Did we really have to integrate stiff springs?
Constraint-Driven Simulations can simulate longer horizon behavior
Intuitive Physics of Contact
Intuitive Physics of Contact
Intuitive Physics of Contact
Did we think about velocities at all? Or purely reason about configuration?
Quasistatic Modeling & Optimization-Based Sim.
Optimization-Based Simulation
Quasistatic Modeling
[Stewart & Trinkle, 2000]
[Mujoco, Todorov 2012]
[SAP Solver (Drake), CPH, 2022]
[Dojo, HCBKSM 2022]

[Howe & Cutkosky 1996]
[Lynch & Mason 1996]
[Halm & Posa 2018]
[Pang & Tedrake 2021]
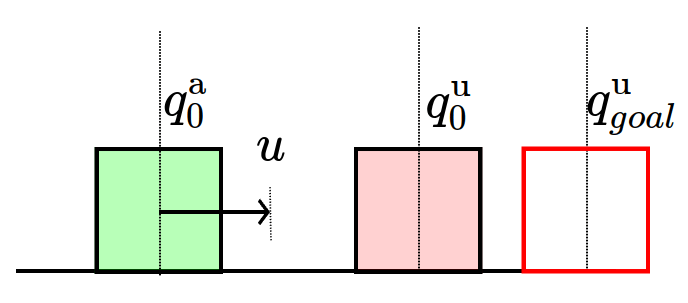
CQDC: A Quasi-dynamic Simulator for Manipulation

Dr. Tao Pang
Robot commands as
State only comprises of configurations
- Actuated configurations (Robot)
- Unactuated configurations (Object)
q^\mathrm{u}
q^\mathrm{a}
- Position command to an stiffness controller

u
Convex
Quasidynamic
Differentiable
Contact Model

CQDC: A Quasi-dynamic Simulator for Manipulation
CQDC: A Quasi-dynamic Simulator for Manipulation
CQDC: A Quasi-dynamic Simulator for Manipulation
\begin{aligned}
\min_{{\color{red}q^\mathrm{u}_+}} &\;\;\frac{1}{2}({\color{red}q^\mathrm{u}_+} - q^\mathrm{u})^\top \mathbf{M}_\mathrm{u} ({\color{red}q^\mathrm{u}_+} - q^\mathrm{u}) \\
\text{s.t.} & \;\; \phi(q^\mathrm{u},{\color{blue}q^\mathrm{a}_\text{cmd}}) \geq 0
\end{aligned}
\begin{aligned}
q^\mathrm{u}
\end{aligned}
\begin{aligned}
{\color{red}q^\mathrm{u}_+}
\end{aligned}
Non-Penetration
Minimum Energy Principle
CQDC: A Quasi-dynamic Simulator for Manipulation
\begin{aligned}
\min_{q+} \quad \frac{1}{2}q_+^\top \mathbf{P} q_+ + b^\top q \\
\text{subject to} \quad \mathbf{J}_i q_+ + c_i \in \mathcal{K}_i
\end{aligned}
Second-Order Cone Program (SOCP)
We can use standard SOCP solvers to solve this program


Uses Drake as Backbone
Allows us to separate complexity of "contact" from complexity of "highly dynamic".
CQDC Simulator
Sensitivity Analysis
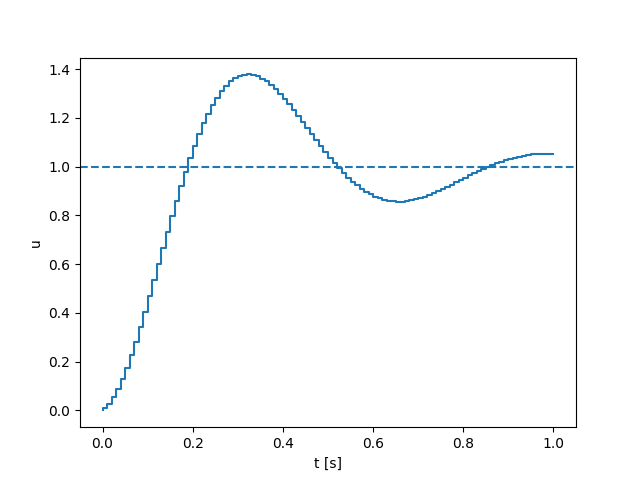
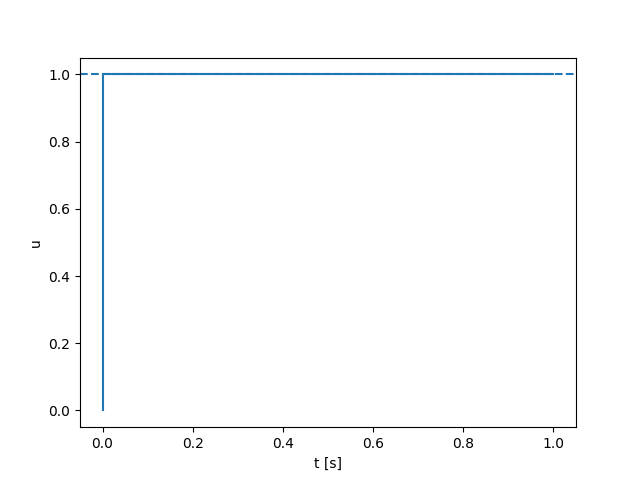
Spring-damper modeling
Quasi-static Dynamics
\begin{aligned}
\frac{\partial x_T}{\partial x_0}=\frac{\partial x_T}{\partial x_{T-1}}\cdots \frac{\partial x_1}{\partial x_0} \end{aligned}
\begin{aligned}
\frac{\partial x_T}{\partial x_0}
\end{aligned}
Directly obtained by sensitivity analysis
Jumping from one equilibrium to another lets us compute long horizon gradients temporally, allowing us to be less stiff.
Figures from Tao Pang's Defense, 2023
Constrained Optimization
\begin{aligned}
\min_{{\color{red}q^\mathrm{u}_+}} &\;\;\frac{1}{2}({\color{red}q^\mathrm{u}_+} - q^\mathrm{u})^\top \mathbf{M}_\mathrm{u} ({\color{red}q^\mathrm{u}_+} - q^\mathrm{u})\;\;\text{s.t.} \;\; \phi(q^\mathrm{u},{\color{blue}q^\mathrm{a}_\text{cmd}}) \geq 0
\end{aligned}
Constrained Optimization
\begin{aligned}
\min_{{\color{red}q^\mathrm{u}_+}} &\;\;\frac{1}{2}({\color{red}q^\mathrm{u}_+} - q^\mathrm{u})^\top \mathbf{M}_\mathrm{u} ({\color{red}q^\mathrm{u}_+} - q^\mathrm{u})\;\;\text{s.t.} \;\; \phi(q^\mathrm{u},{\color{blue}q^\mathrm{a}_\text{cmd}}) \geq 0
\end{aligned}
=
+
\infty
\infty
0
Log-Barrier Relaxation
=
+
\infty
\infty

\begin{aligned}
\min_{{\color{red}q^\mathrm{u}_+}} &\;\;\frac{1}{2}({\color{red}q^\mathrm{u}_+} - q^\mathrm{u})^\top \mathbf{M}_\mathrm{u} ({\color{red}q^\mathrm{u}_+} - q^\mathrm{u}) -\log \phi(q^\mathrm{u},{\color{blue}q^\mathrm{a}_\text{cmd}})
\end{aligned}


Log-Barrier Relaxation
=
+
\infty
\infty
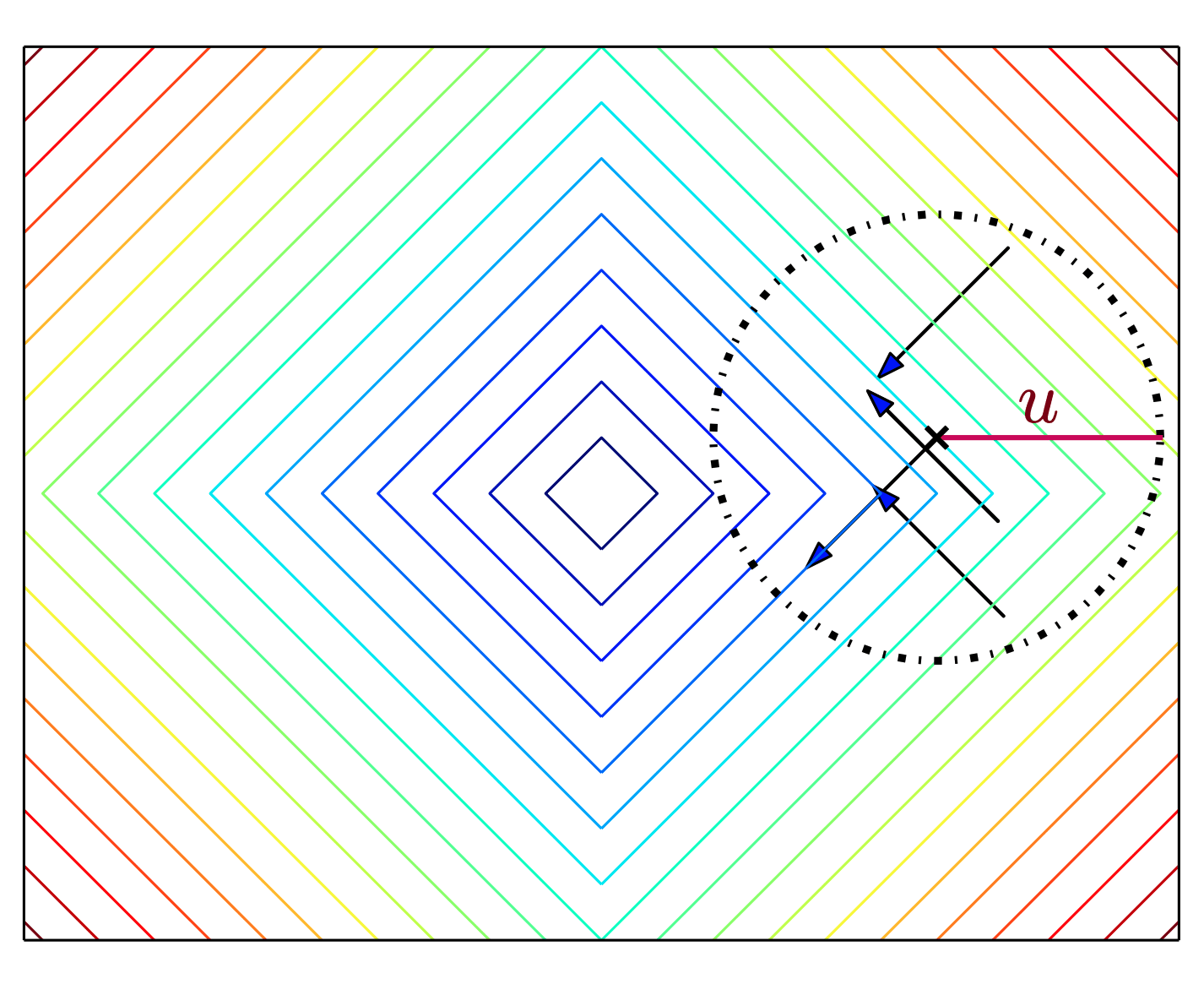
Constraints have an inversely proportional effect to distance.
\begin{aligned}
\min_{{\color{red}q^\mathrm{u}_+}} &\;\;\frac{1}{2}({\color{red}q^\mathrm{u}_+} - q^\mathrm{u})^\top \mathbf{M}_\mathrm{u} ({\color{red}q^\mathrm{u}_+} - q^\mathrm{u}) -\log \phi(q^\mathrm{u},{\color{blue}q^\mathrm{a}_\text{cmd}})
\end{aligned}
Barrier-Smoothed Dynamics


Initial Configuration
1-Step Dynamics
(Low Smoothing)

1-Step Dynamics
(High Smoothing)
Barrier smoothing creates force from a distance
Benefits of Smoothing
[ICML 2022]
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
F(x)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
\begin{aligned}
\mathbb{E}_wF(x+w)
\end{aligned}
Recall smoothing achieves abstraction of contact modes
Benefits of Smoothing
True Dynamics
Local Model
Benefits of Smoothing
Smoothed Dynamics
Local Model
Benefits of Smoothing
Smoothed Dynamics
Local Model
Barrier Smoothing can also abstract contact modes!
But does it have the exact same effect as randomized?
Randomized-Smoothed Dynamics

Initial Configuration
1-Step Dynamics
Sampling
Equivalence of Smoothing Schemes
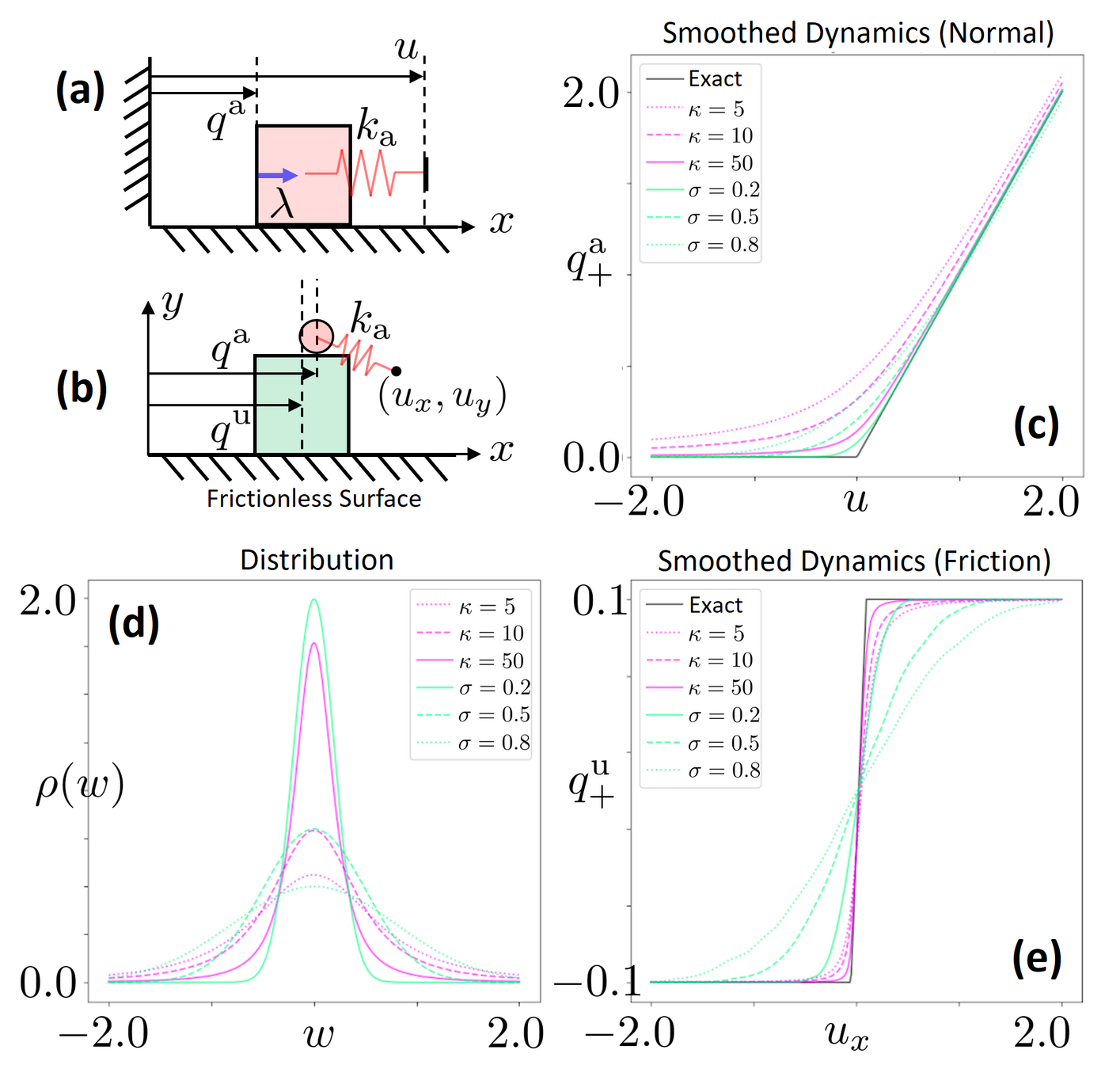
\rho(w) = \sqrt{\frac{4 c}{(w^\top c w + 4)^3}}
The two smoothing schemes are equivalent!
(There is a distribution that corresponds to barrier smoothing)
Randomized Smoothing
Barrier Smoothing
Analytic Expression
First-Order Gradient Estimator
Zeroth-Order Gradient Estimator
- Requires differentiability over dynamics
- Generally lower variance.
- Least requirements (blackbox)
- High variance.
Possible for only few cases
Structure
Efficiency
Comparison of Efficiency
[TRO 2023, TRO 2025]
Part 2. Local Planning / Control via Dynamic Smoothing
Can we do better by understanding dynamics structure?
How do we build effective local optimizers for contact?
Back to Dynamics
\begin{aligned}
q^\mathrm{u}_{next} = f(q,u)
\end{aligned}
True Dynamics
How do we build a computationally tractable local model for iterative optimization?
True Dynamics
Back to Dynamics
\begin{aligned}
q^\mathrm{u}_{next} = \frac{\partial f}{\partial u}\delta u + f(q,u)
\end{aligned}
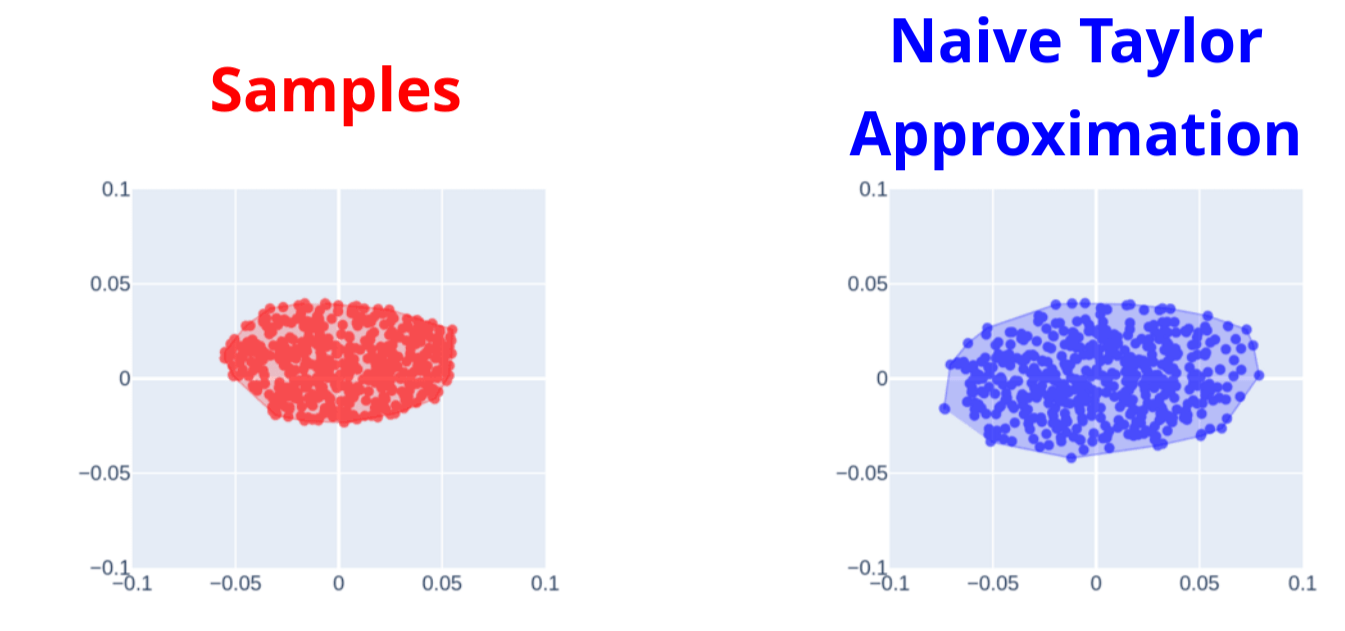
Is this a good local model?
Local Model
First-Order Taylor Approximation
Gradients too myopic, suffers from flatness
Back to Dynamics
Local Model
Is this a good local model?
Gradients are more useful due to smoothing
First-Order Taylor Approximation
on Smoothed Dynamics
\begin{aligned}
q^\mathrm{u}_{next} = \frac{\partial f_{\color{red}\rho}}{\partial u}\delta u + f_{\color{red}\rho}(q,u)
\end{aligned}
Back to Dynamics
Local Model
Is this a good local model?
First-Order Taylor Approximation
on Smoothed Dynamics
Gradients are more useful due to smoothing
Still violates some fundamental characteristics of contact!
\begin{aligned}
q^\mathrm{u}_{next} = \frac{\partial f_{\color{red}\rho}}{\partial u}\delta u + f_{\color{red}\rho}(q,u)
\end{aligned}
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = f(q, u + \delta u)
\end{aligned}
Dynamics
\begin{aligned}
\|{\color{green}\delta u}\|_2\leq \varepsilon
\end{aligned}
What does this imply about reachable sets?
?
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
Linear Map
\begin{aligned}
\|{\color{green}\delta u}\|_2\leq \varepsilon
\end{aligned}
?
What does this imply about reachable sets?
What does this imply about reachable sets?
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
Linear Map
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}}
\end{aligned}
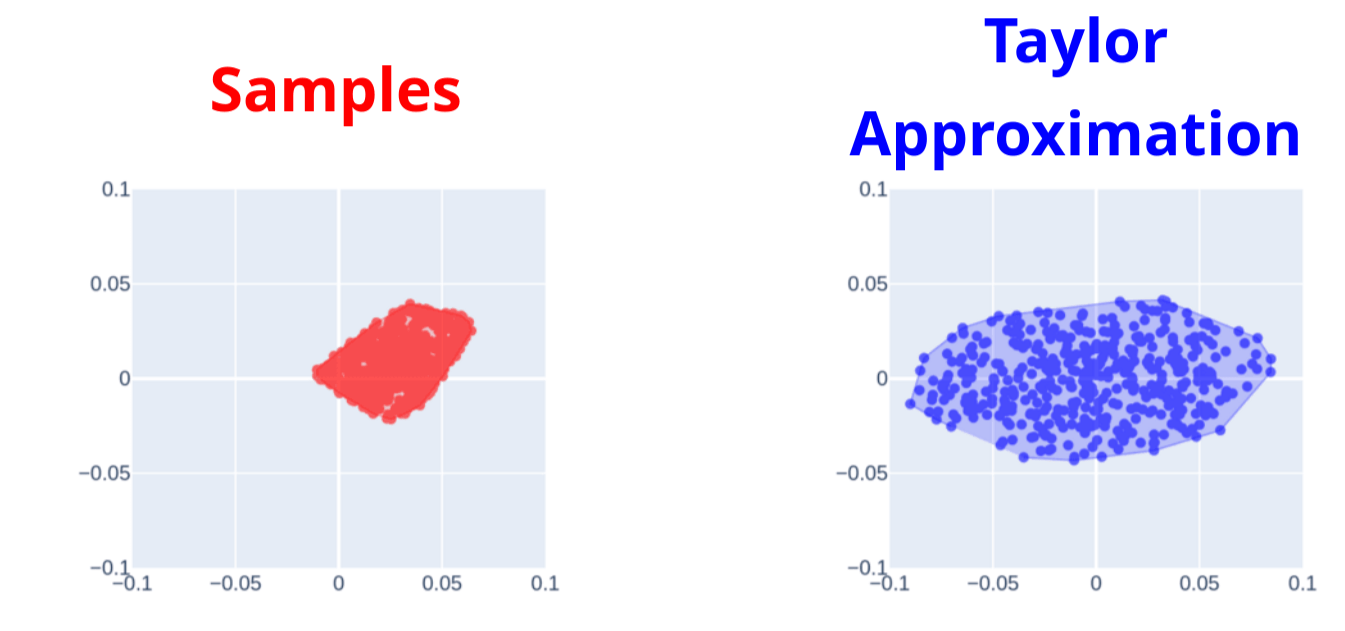
We can make ellipsoidal approximations of the reachable set
\begin{aligned}
\|{\color{green}\delta u}\|_2\leq \varepsilon
\end{aligned}
We can make ellipsoidal approximations of the reachable set
True Samples
Samples from Local Model
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
What does this imply about reachable sets?
Linear Map

True Samples
Samples from Local Model
What does this imply about reachable sets?
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
Linear Map
What are we missing here?
True Samples
Samples from Local Model
What does this imply about reachable sets?
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
Linear Map
Qualification on Contact Impulses
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
Dynamics (Primal)
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}}
\end{aligned}
\begin{aligned}
{\color{magenta}\lambda} = \frac{\partial \lambda_{\rho}}{\partial u}{\color{green}\delta u} + \lambda_{\rho}(q,u)
\end{aligned}
Contact Impulses (Dual)
\begin{aligned}
{\color{magenta}\lambda}
\end{aligned}
\begin{aligned}
\|{\color{green}\delta u}\|_2\leq \varepsilon
\end{aligned}
The Friction Cone
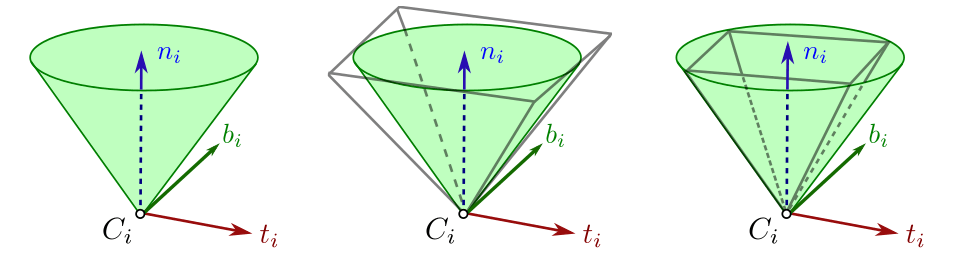
*image taken from Stephane Caron's blog
Unilateral
(Can't pull)
Coulomb Friction
Friction Cone
+
=
Qualification on Contact Impulses
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
Dynamics (Primal)
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}}
\end{aligned}
\begin{aligned}
{\color{magenta}\lambda} = \frac{\partial \lambda_{\rho}}{\partial u}{\color{green}\delta u} + \lambda_{\rho}(q,u)
\end{aligned}
Contact Impulses (Dual)
\begin{aligned}
{\color{magenta}\lambda}
\end{aligned}
+
*image taken from Stephane Caron's blog
\begin{aligned}
{\color{magenta}\lambda}\in \{\mu\lambda_n \geq \|\lambda_t\|_2\}
\end{aligned}
Contact is unilateral
\begin{aligned}
\|{\color{green}\delta u}\|_2\leq \varepsilon
\end{aligned}
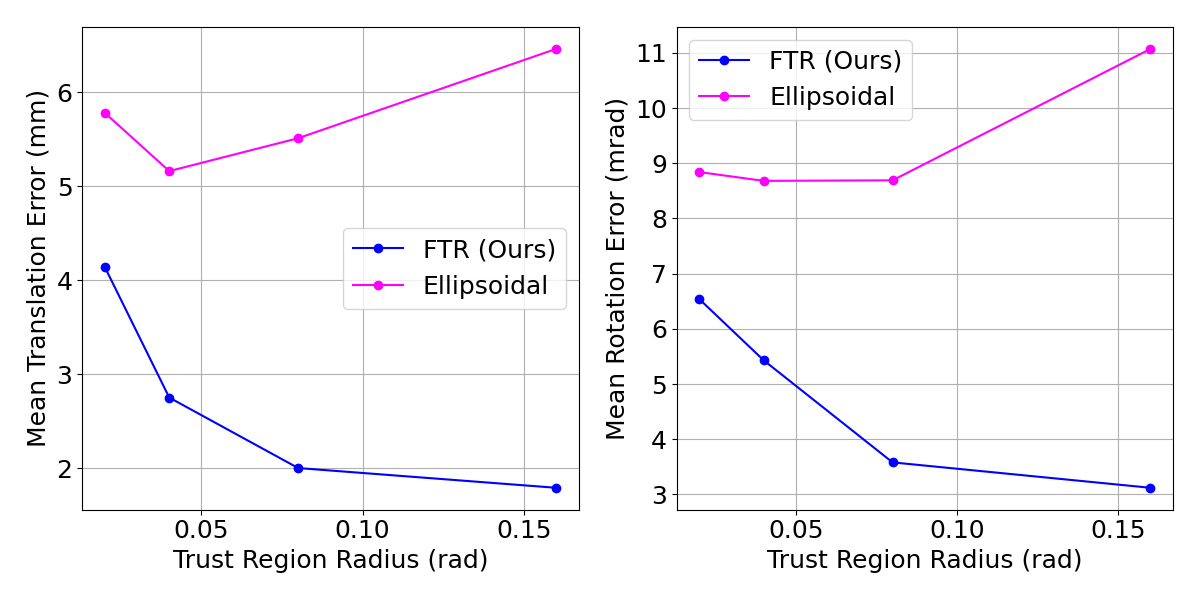
Feasible Trust Region
Dynamics (Primal)
Contact Impulses (Dual)
\begin{aligned}
{\color{magenta}\lambda}\in \{\mu\lambda_n \geq \|\lambda_t\|_2\}
\end{aligned}
Trust Region Size
\begin{aligned}
\|{\color{green}(\delta q, \delta u)}\|_2\leq \varepsilon
\end{aligned}
\begin{aligned}
\color{green}
\mathcal{T}(q, u) =\{(\delta q, \delta u)\}
\end{aligned}
Feasible Trust Region
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
\begin{aligned}
{\color{magenta}\lambda} = \frac{\partial \lambda_{\rho}}{\partial u}{\color{green}\delta u} + \lambda_{\rho}(q,u)
\end{aligned}
Motion Set
\begin{aligned}
\color{green}
\mathcal{T}(q, u) =\{(\delta q, \delta u)\}
\end{aligned}
Feasible Trust Region
\begin{aligned}
\color{blue}
\mathcal{M}(q,u)=\{q^\mathrm{u}_{next}\}
\end{aligned}
Motion Set
Dynamics (Primal)
Contact Impulses (Dual)
\begin{aligned}
{\color{magenta}\lambda}\in \{\mu\lambda_n \geq \|\lambda_t\|_2\}
\end{aligned}
Trust Region Size
\begin{aligned}
\|{\color{green}(\delta q, \delta u)}\|_2\leq \varepsilon
\end{aligned}
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
\begin{aligned}
{\color{magenta}\lambda} = \frac{\partial \lambda_{\rho}}{\partial u}{\color{green}\delta u} + \lambda_{\rho}(q,u)
\end{aligned}
Contact Impulse Set
\begin{aligned}
\color{green}
\mathcal{T}(q, u) =\{(\delta q, \delta u)\}
\end{aligned}
Feasible Trust Region
\begin{aligned}
\color{magenta}
\mathcal{C}(q,u)=\{\lambda\}
\end{aligned}
Contact Impulse Set
Dynamics (Primal)
Contact Impulses (Dual)
\begin{aligned}
{\color{magenta}\lambda}\in \{\mu\lambda_n \geq \|\lambda_t\|_2\}
\end{aligned}
Trust Region Size
\begin{aligned}
\|{\color{green}(\delta q, \delta u)}\|_2\leq \varepsilon
\end{aligned}
\begin{aligned}
{\color{blue}q^\mathrm{u}_{next}} = \frac{\partial f_{\rho}}{\partial u}{\color{green}\delta u} + f_{\rho}(q,u)
\end{aligned}
\begin{aligned}
{\color{magenta}\lambda} = \frac{\partial \lambda_{\rho}}{\partial u}{\color{green}\delta u} + \lambda_{\rho}(q,u)
\end{aligned}
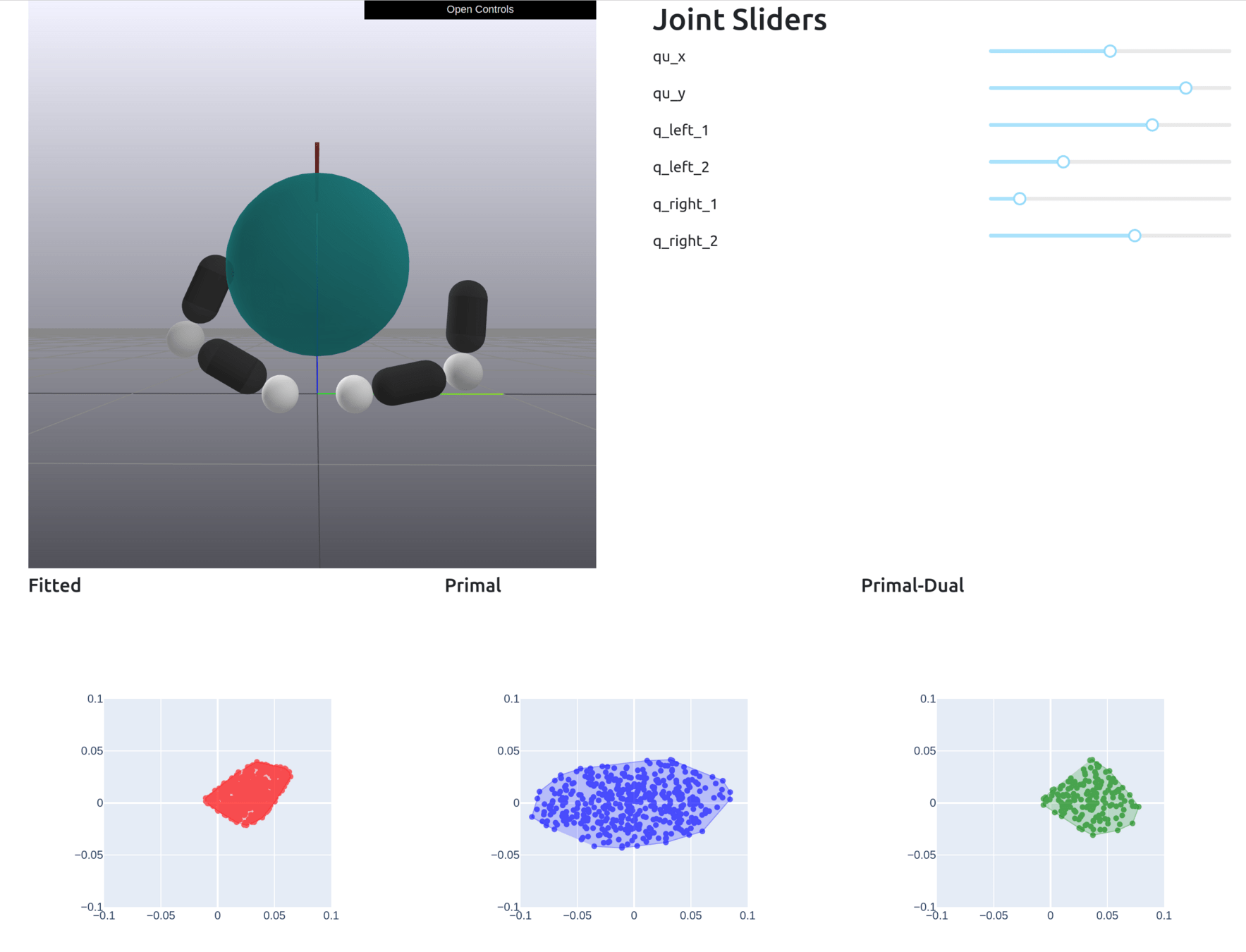
Now we have a close match with real samples
Motion Set
No Constraints
True Samples
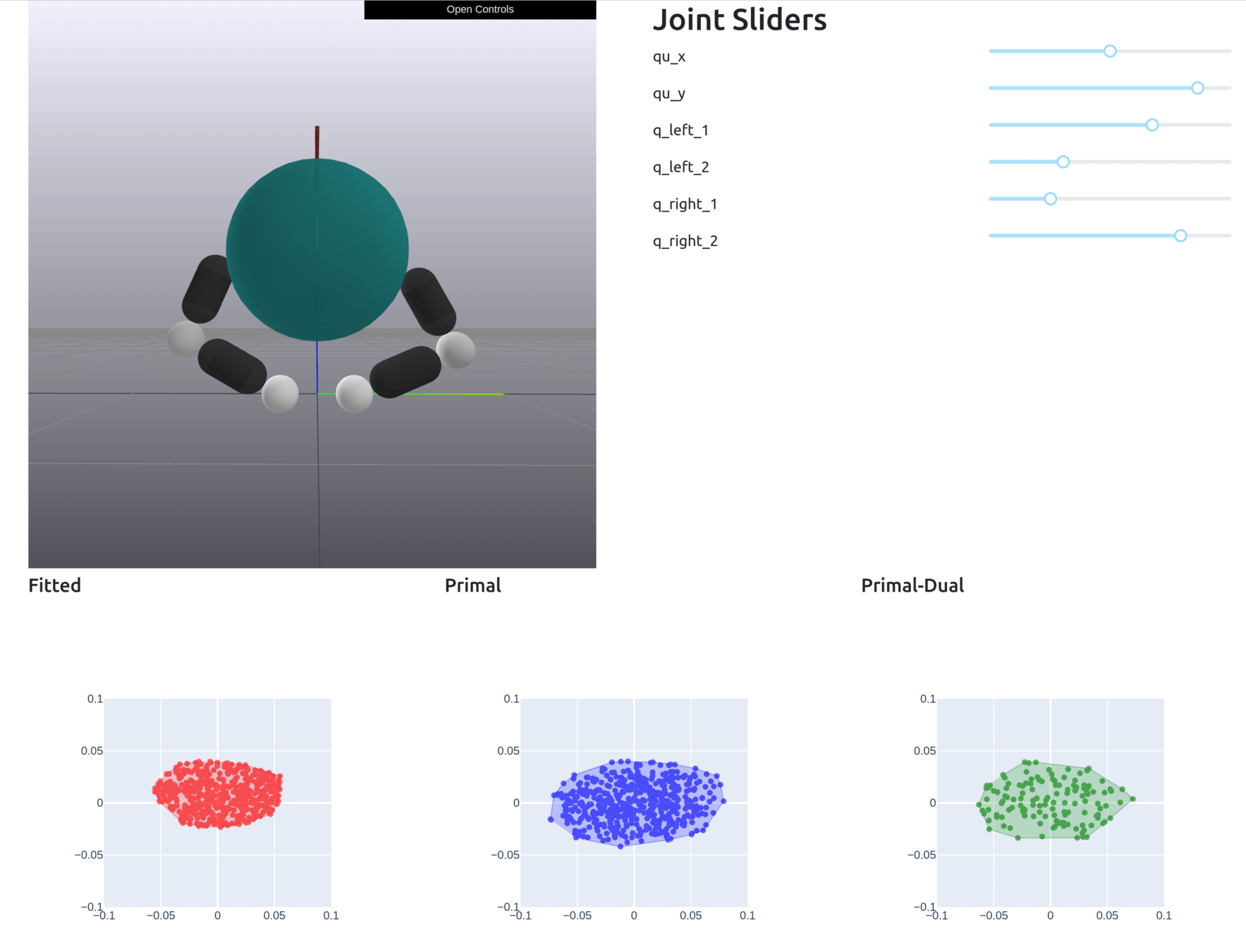
Motion Set
No Constraints
True Samples
Closer to ellipse when there is a full grasp

The gradients take into account manipulator singularities
Motion Set
No Constraints
True Samples
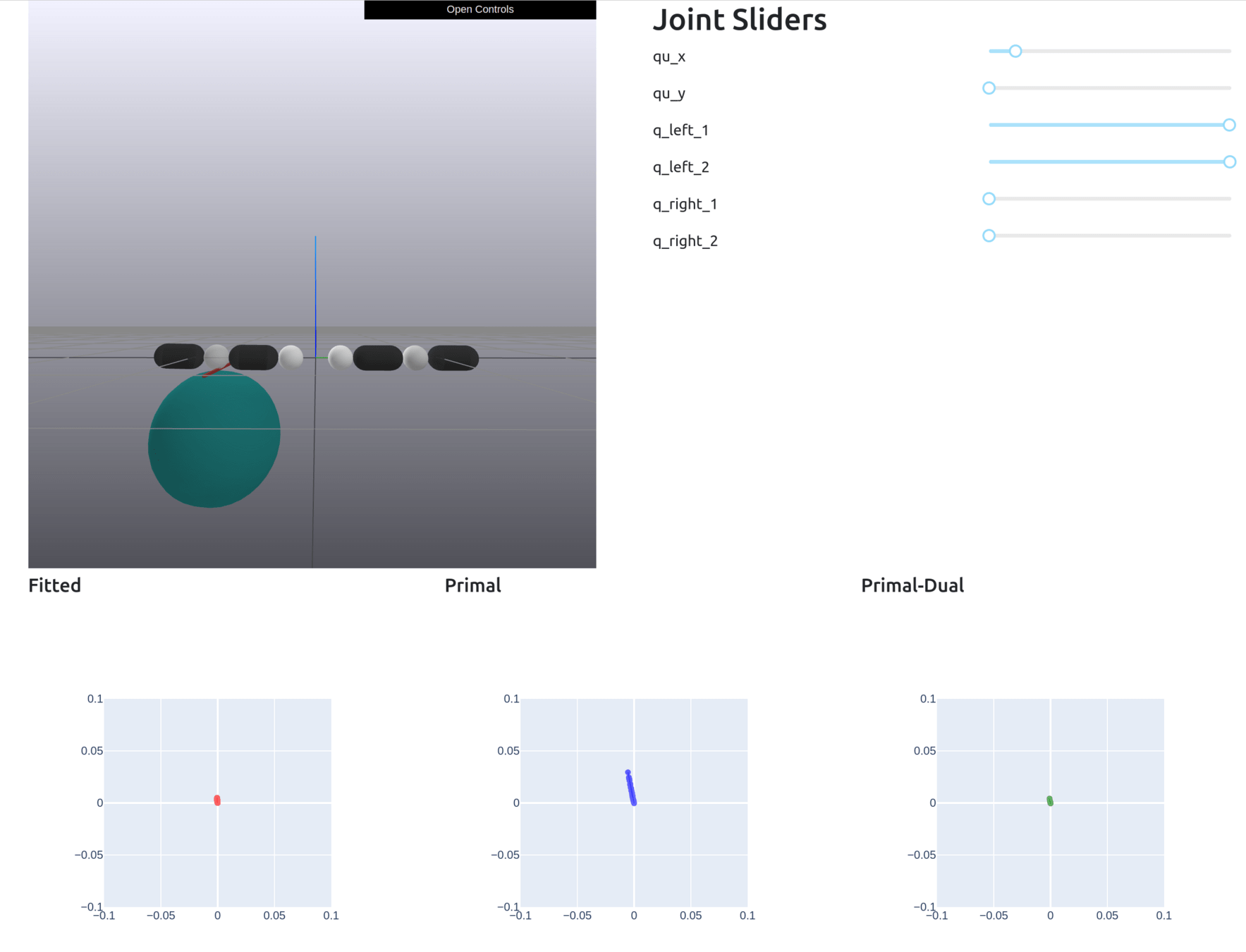
Motion Set
No Constraints
True Samples
Can also add additional convex constraints (e.g. joint limits)
Finding Optimal Action: One Step
\begin{aligned}
\min_{\delta u} \quad & \|q^\mathrm{u}_{goal} - q^\mathrm{u}_+\|^2 + \|\delta u\|^2 \\
\text{s.t.} \quad & q_+ \in \mathcal{M}_\varepsilon(q,u)
\end{aligned}
Get to the goal
Minimize effort
Motion Set Constraint
\begin{aligned}
\color{blue}
\mathcal{M}(q,u)=\{q^\mathrm{u}_{next}\}
\end{aligned}
\begin{aligned}
\color{red}
q^\mathrm{u}_{goal}
\end{aligned}
\begin{aligned}
\color{blue}
q
\end{aligned}
\begin{aligned}
\delta u
\end{aligned}
\begin{aligned}
\min_{\delta u_{0:T-1},\delta q_{0:T}} \quad & \|q^\mathrm{u}_{goal} - q^\mathrm{u}_T\|^2 + \sum^{T-1}_{t=0}\|u_{t+1} - u_t\|^2 \\
\text{s.t.} \quad & q_{t+1}\in \mathcal{M}_\varepsilon(q_t,u_t) \\
& q_0 = q_{initial} \\
& u_t = \bar{u}_t + \delta u_t \quad\quad\forall t\in\{0,\cdots,T-1\}
\end{aligned}
Get to the goal
Minimize effort
Multi-Horizon Optimization
Motion Set Constraint
Trajectory Optimization: Step 1
q_0
q_1
q_2
q_3
q_4
q_5
q_6
u_0
u_1
u_2
u_3
u_4
u_5
Roll out an input trajectory guess to obtain an initial trajectory.
u_{0:T-1}
q_\mathrm{goal}
Trajectory Optimization: Step 2
q_0
q_1
q_2
q_3
q_4
q_5
q_6
u_0
u_1
u_2
u_3
u_4
u_5
Linearize around each point to obtain a local dynamics model around the trajectory
(q_t,u_t)
q_\mathrm{goal}
Trajectory Optimization: Step 3
q_0
q_1
q_2
q_3
q_4
q_5
q_6
u_0
u_1
u_2
u_3
u_4
u_5
q_\mathrm{goal}
\delta q_1^\star
u_0 + \delta u_0^\star
u_1 + \delta u_1^\star
q_1 + \delta q_1^\star
\delta q_2^\star
\delta q_3^\star
\delta q_4^\star
\delta q_5^\star
u_2 + \delta u_2^\star
u_3 + \delta u_3^\star
u_4 + \delta u_4^\star
u_5 + \delta u_5^\star
q_2 + \delta q_2^\star
q_3 + \delta q_3^\star
q_4 + \delta q_4^\star
q_5 + \delta q_5^\star
q_6 + \delta q_6^\star
\delta q_6^\star
Use our subproblem to solve for a new input trajectory
u_{0:T-1}^\star = u_{0:T-1} + \delta u^\star_{0:T-1}
Trajectory Optimization: Iteration
q_0
q_1
q_2
q_3
q_4
q_5
q_6
u_0
u_1
u_2
u_3
u_4
u_5
q_\mathrm{goal}
Roll out the new input trajectory guess and repeat til convergence
u_{0:T-1}^\star
Model Predictive Control (MPC)
q_0
q_1
q_2
q_3
q_4
q_5
q_6
u_0
u_1
u_2
u_3
u_4
u_5
Plan a trajectory towards the goal in an open-loop manner
Model Predictive Control (MPC)
q_0
q_1^\mathrm{planned}
u_0
Execute the first action.
Due to model mismatch, there will be differences in where we end up.
q_1^\mathrm{real}
Model Predictive Control (MPC)
q_0
q_1^\mathrm{planned}
u_0
Replan from the observed state,
execute the first action,
and repeat.
q_1^\mathrm{real}
q_2
q_3
q_4
q_5
q_6
u_1
u_2
u_3
u_4
u_5
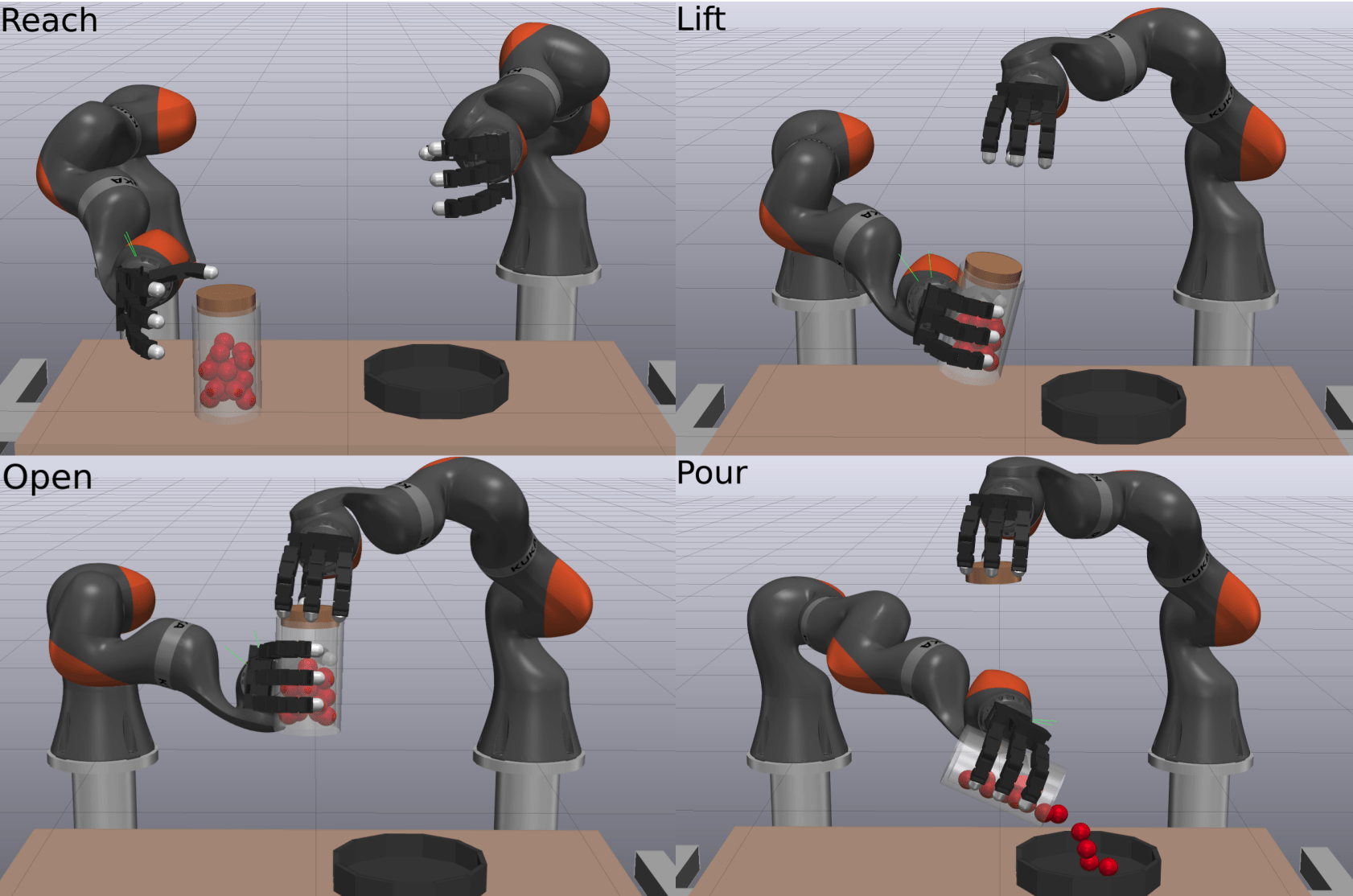
MPC Rollouts
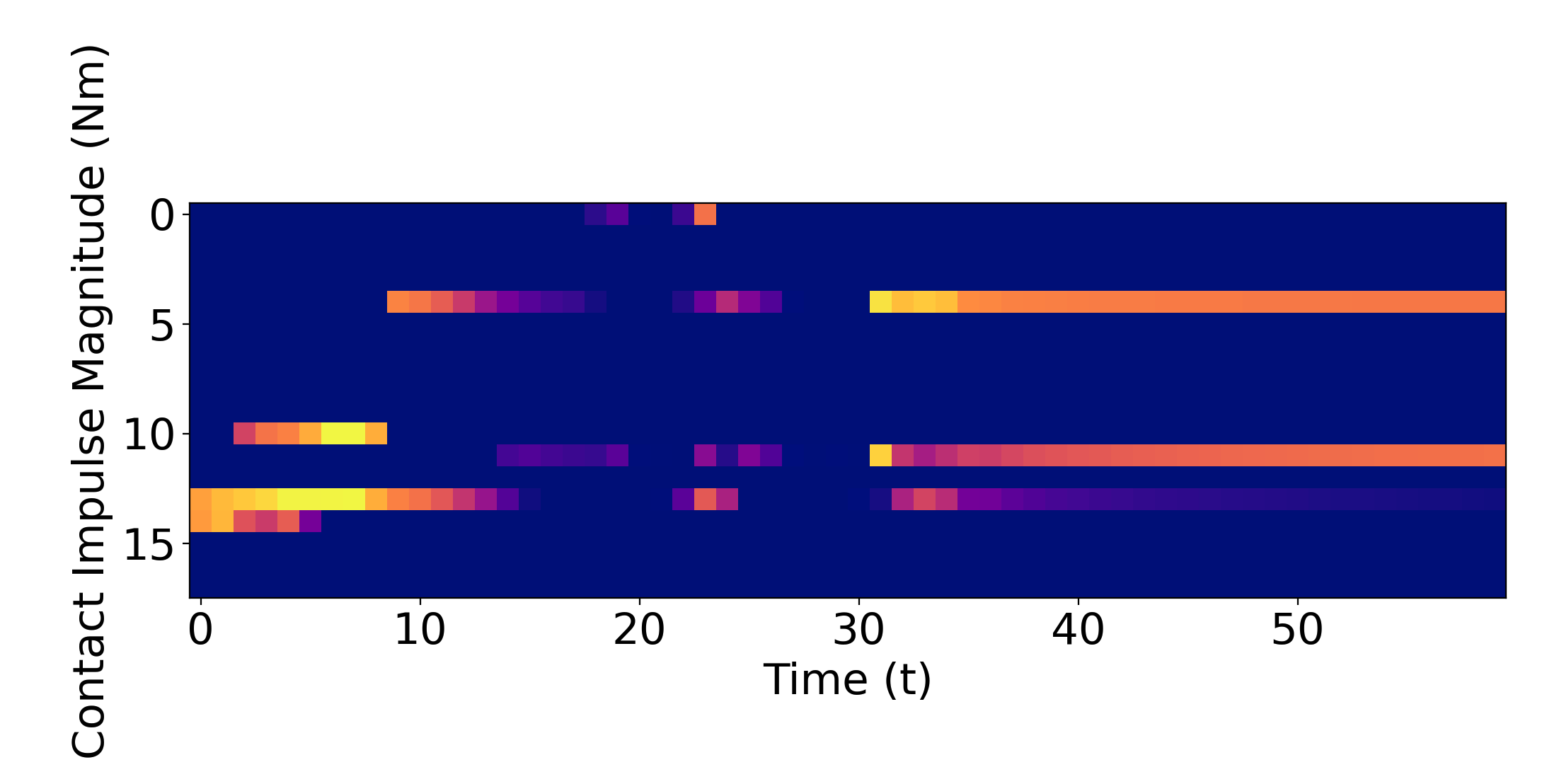
Able to stabilize to plan to the goal in a contact-rich manner
MPC Rollouts
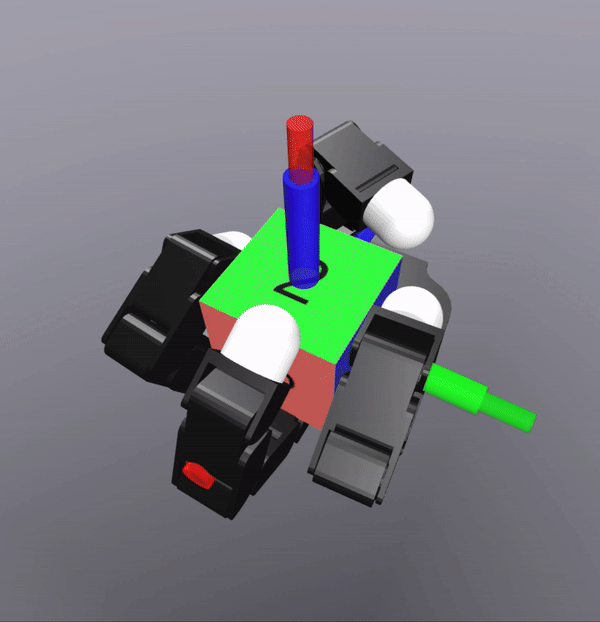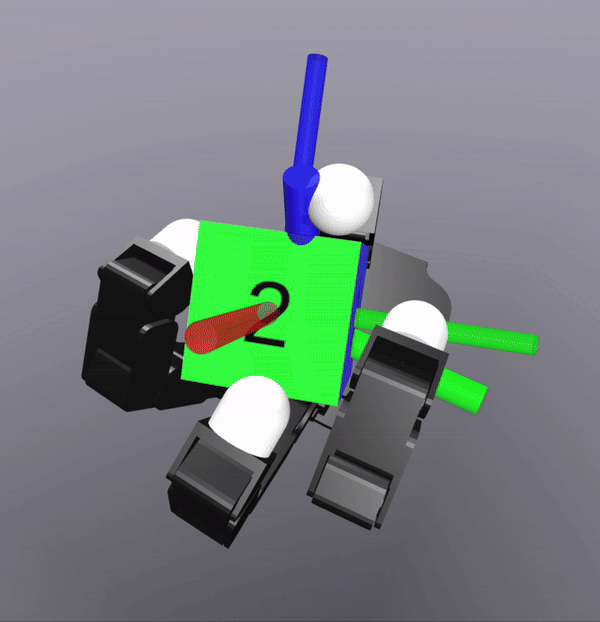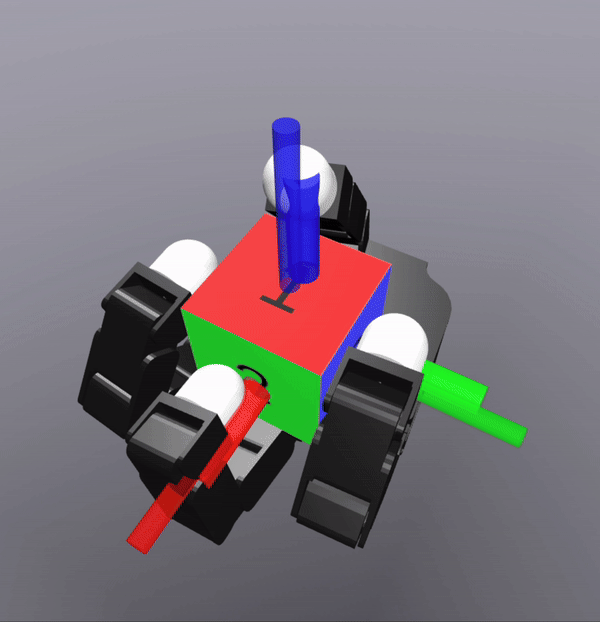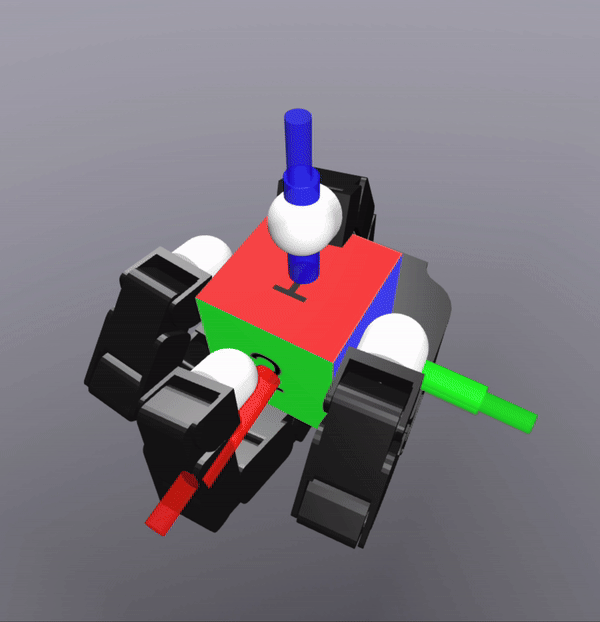

The controller also successfully scales to the complexity of dexterous hands
Force Control
Having a model of contact impulses allows us to perform force control
\begin{aligned}
\min_{\delta u_{0:T-1},\delta q_{0:T}} \quad & \|\lambda_{goal} - \lambda\|^2 + \sum^{T-1}_{t=0}\|u_{t+1} - u_t\|^2 \\
\text{s.t.} \quad & \lambda\in \mathcal{C}_\varepsilon(q_t,u_t) \\
& q_0 = q_{initial} \\
& u_t = \bar{u}_t + \delta u_t \quad\quad\forall t\in\{0,\cdots,T-1\}
\end{aligned}
Applied desired forces
Minimize effort
Contact Impulse Set
Force Control

Is the friction cone constraint necessary?
\varepsilon
\varepsilon
Hardware Setup
Small IR LEDs which allow motion capture & state estimation


iiwa bimanual bucket rotation
allegro hand in-hand reorientation
Mocap markers

[TRO 2023, TRO 2025]
Part 2. Local Planning / Control via Dynamic Smoothing
Can we do better by understanding dynamics structure?
How do we build effective local optimizers for contact?
[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
Part 2. Local Planning / Control via Dynamic Smoothing
Part 1. Understanding RL with Randomized Smoothing
Introduction
[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
What are fundamental limits of local control?
How can we address difficult exploration problems?
How do we achieve better global planning?
Reduction to Motion Planning over Smooth Systems
Smoothing lets us...
- Abstract contact modes
- Gets rid of discreteness coming from granular contact modes.
Contact-Rich Manipulation
Motion Planning over Smooth Systems
\approx


Discreteness of Motion Planning
Discreteness of Motion Planning
Discreteness of Motion Planning
Discreteness of Motion Planning
Discreteness of Motion Planning
Discreteness of Motion Planning
Discreteness of Motion Planning
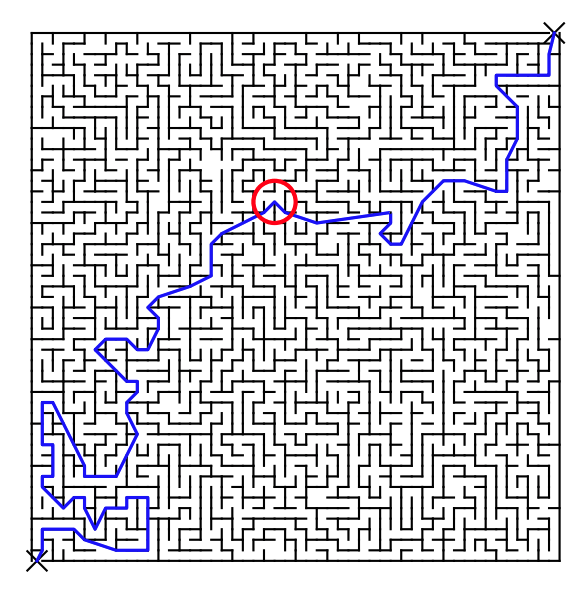
Marcucci et al., 2022
Motion Planning over Smooth Systems is not necessarily easier
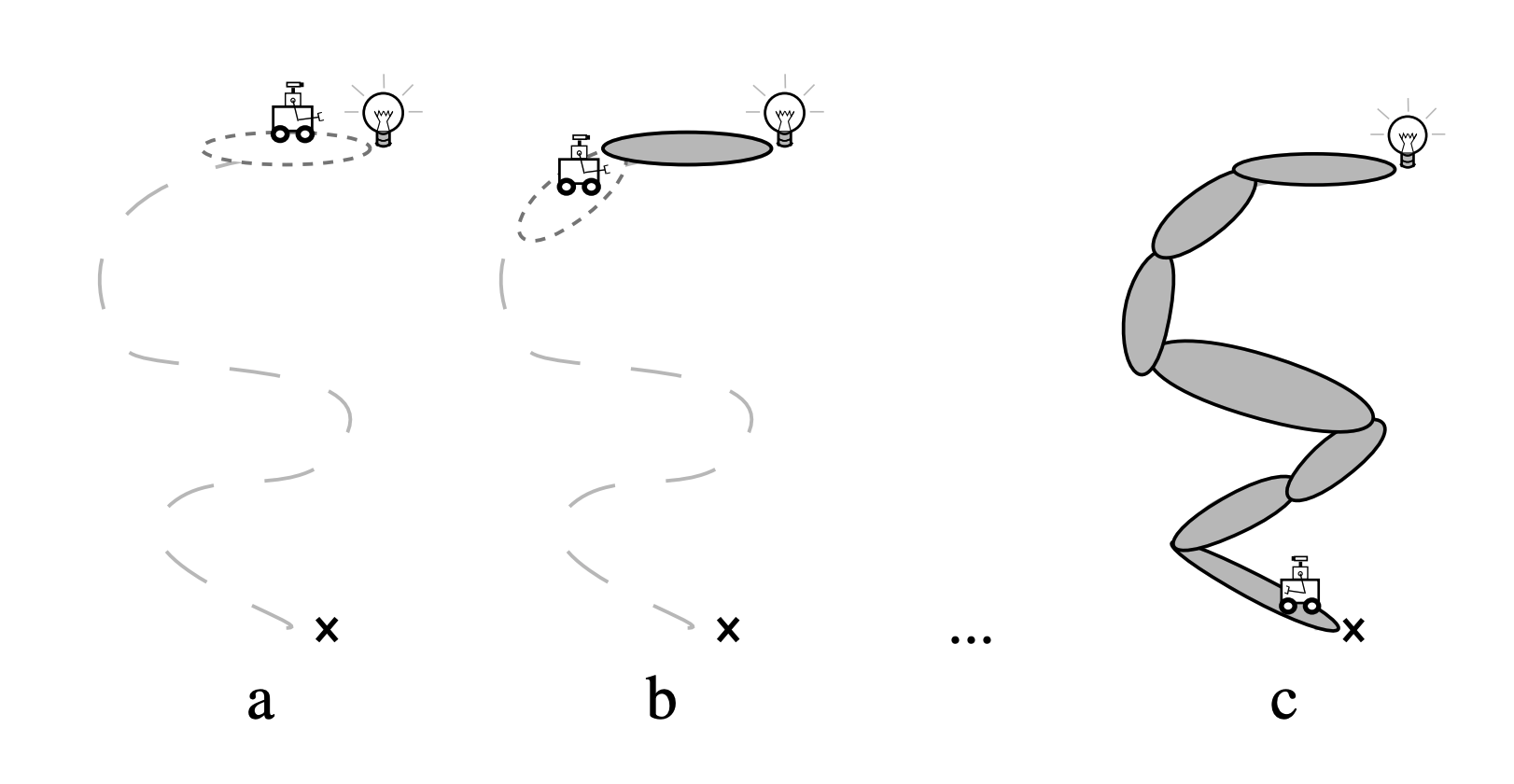
The Exploration Problem

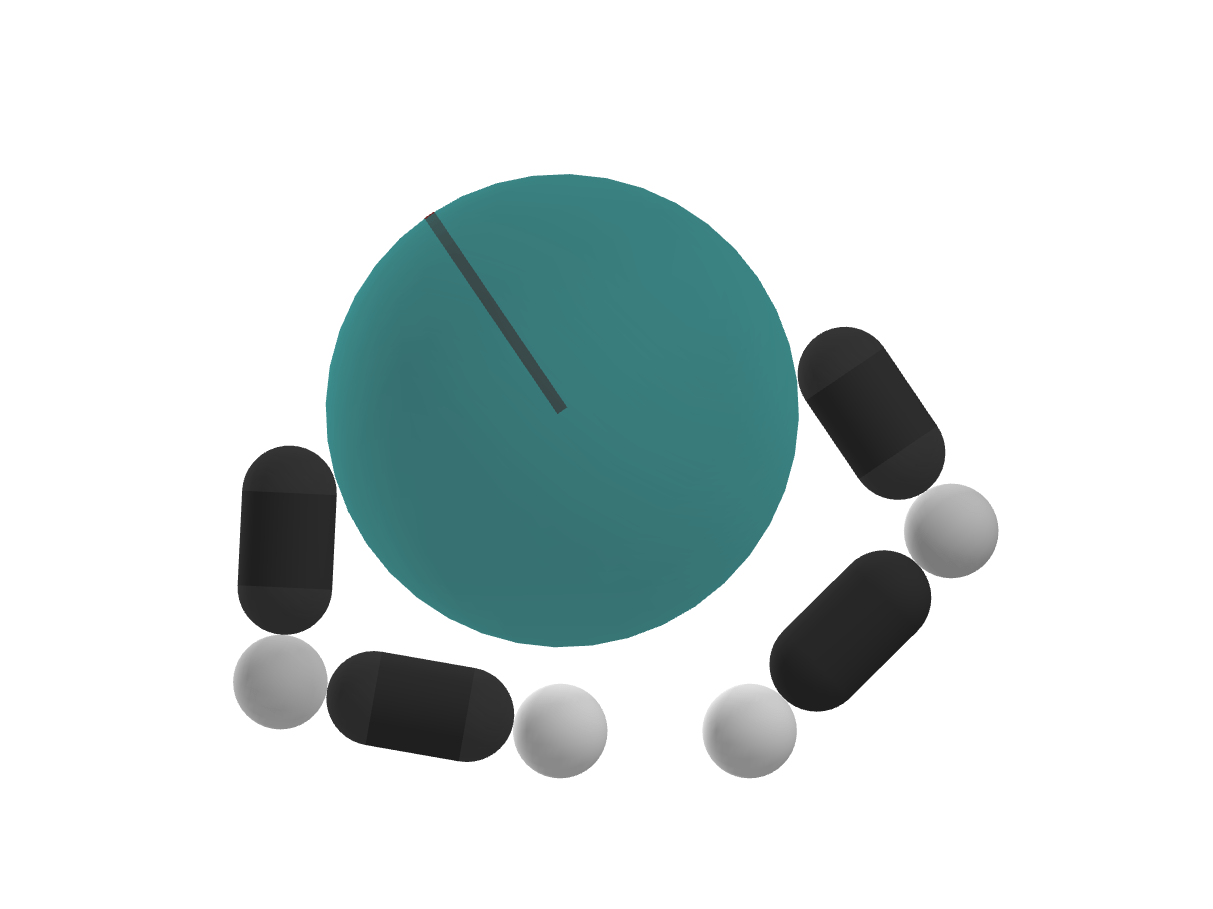
How do we push in this direction?
How do we rotate further in presence of joint limits?
How do we push in this direction?
The Exploration Problem
The Exploration Problem
How do I know that I need to open my finger to grasp the box?
[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
What are fundamental limits of local control?
How can we address difficult exploration problems?
How do we achieve better global planning?
The Exploration Problem
Because I have seen that this state is useful!
Local Control

What is a sequence of actions I must take to push the box down?
Local Search for Open-Loop Actions
The Reset Action Space
What is a sequence of actions I must take to push the box down?
Where should I place my finger if I want to make progress towards the goal?
Local Search for Open-Loop Actions
Global Search for Initial Configurations
The Reset Action Space
Utilizing the MPC Cost
Our Local Controller
\begin{aligned}
{\color{red}V(q^\mathrm{a}_\mathrm{init}; q^\mathrm{u}_\mathrm{init};q^\mathrm{u}_{goal})\coloneqq}
\end{aligned}
How well does the policy perform when this controller is run closed-loop?
\begin{aligned}
\min_{\delta u_{0:T-1},\delta q_{0:T}} \quad & \|{\color{red}q^\mathrm{u}_{goal}} - q^\mathrm{u}_T\|^2 + \sum^{T-1}_{t=0}\|u_{t+1} - u_t\|^2 \\
\text{s.t.} \quad & q_{t+1}\in \mathcal{M}_\varepsilon(q_t,u_t) \\
& q_0^\mathrm{u} = {\color{red}q^\mathrm{u}_{init}} \\
& q_0^\mathrm{a} = {\color{red}q^\mathrm{a}_{init}} \\
& u_t = \bar{u}_t + \delta u_t \quad\quad\forall t\in\{0,\cdots,T-1\}
\end{aligned}
Get to the goal
Minimize effort
Motion Set Constraint
The Actuator Relocation Problem
\begin{aligned}
\min_{q^\mathrm{a}_\mathrm{init}} \quad & V^\pi(q^\mathrm{a}_\mathrm{init}; q^\mathrm{u}_\mathrm{init};q^\mathrm{u}_{goal}) \\
\text{s.t.} \quad & \phi_i(q^\mathrm{a}_\mathrm{init}, q^\mathrm{u}_\mathrm{init})\geq 0
\end{aligned}
Choose best initial actuator configuration for MPC
Non-penetration constraints
Where should I place my finger if I want to make progress towards the goal?
Global Search for Initial Configurations
Robustness Considerations
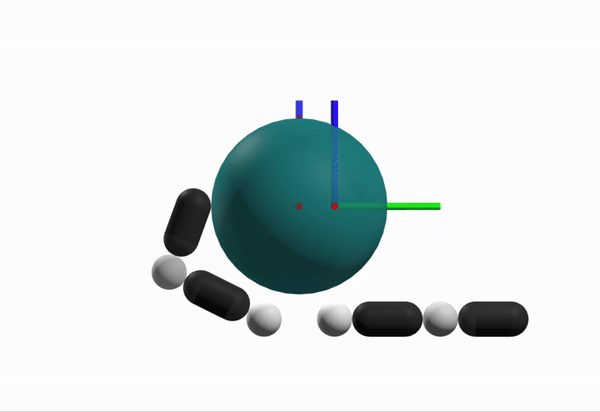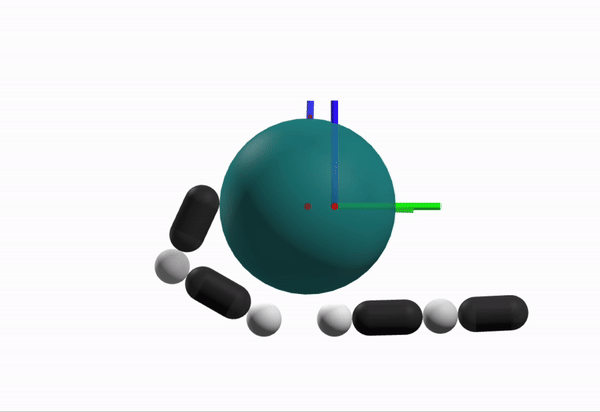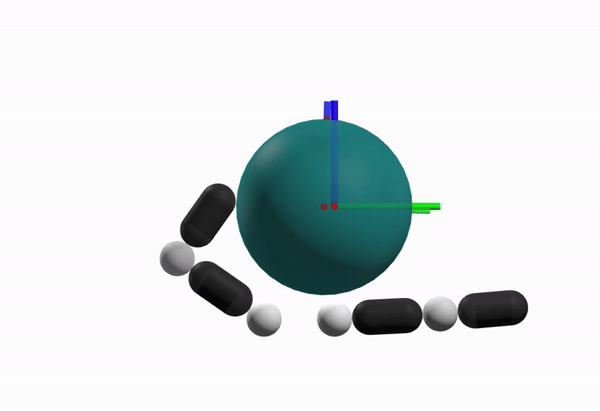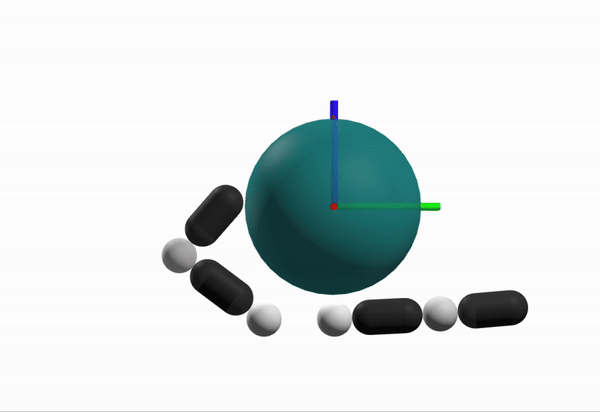
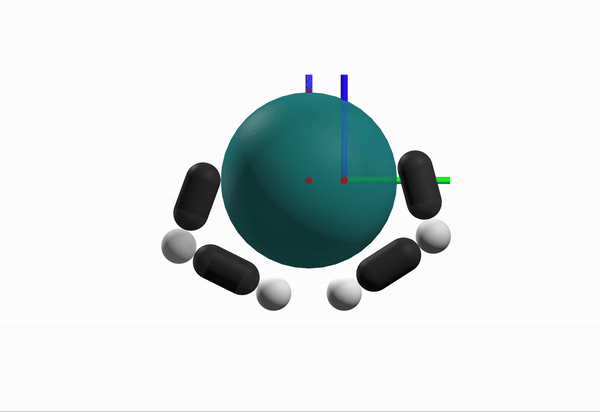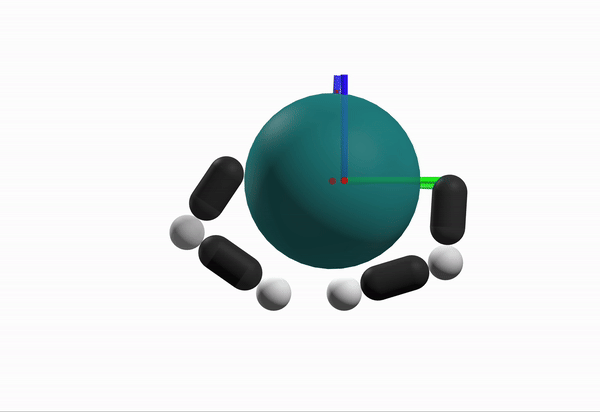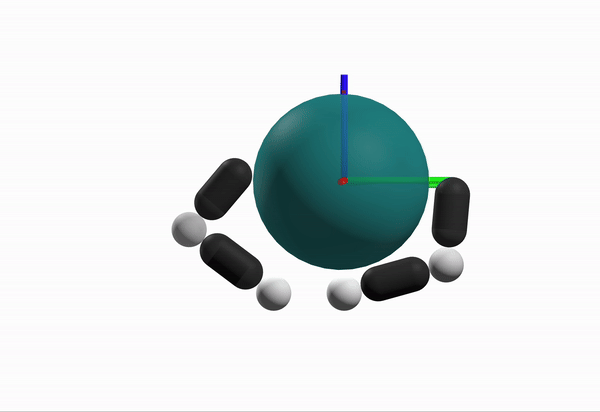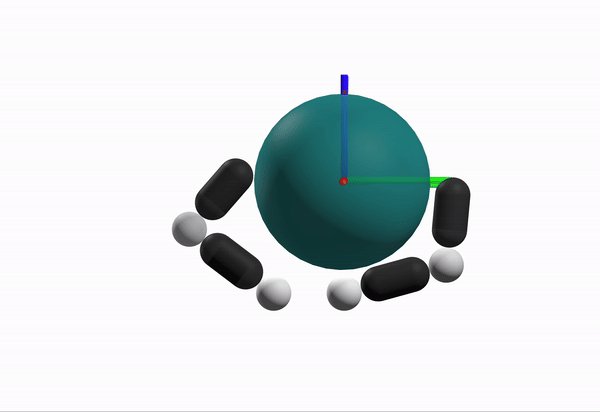
What is a better configuration to start from?
Robustness Considerations
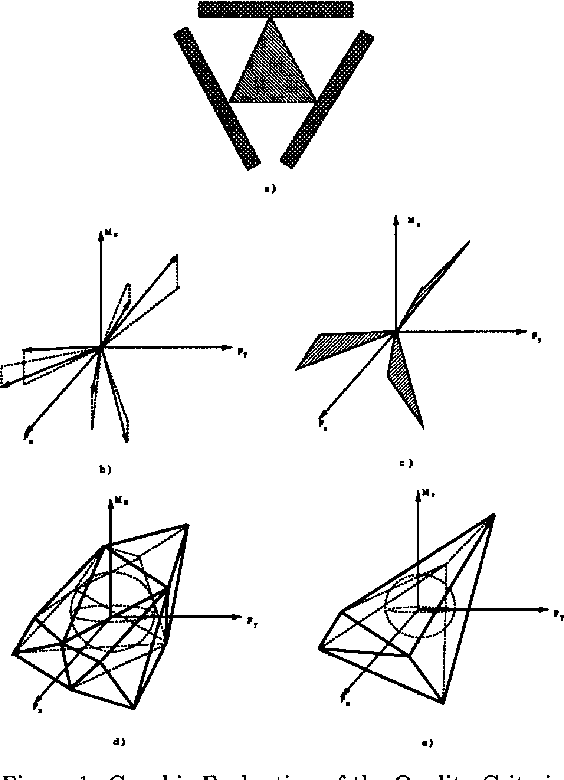
[Ferrari & Canny, 1992]
We prefer configurations that can better reject disturbances
Regularizing with Robustness
\begin{aligned}
\min_{q^\mathrm{a}_\mathrm{init}} \quad & V^\pi(q^\mathrm{a}_\mathrm{init}; q^\mathrm{u}_\mathrm{init};q^\mathrm{u}_{goal}) + {\color{red} \alpha r(q^\mathrm{a}_{init};q^\mathrm{u}_\mathrm{init})^2} \\
\text{s.t.} \quad & \phi_i(q^\mathrm{a}_\mathrm{init}, q^\mathrm{u}_\mathrm{init})\geq 0\\
& q^\mathrm{a}_\mathrm{lb} \leq q^\mathrm{a}_\mathrm{init} \leq q^\mathrm{a}_\mathrm{ub}
\end{aligned}
How do we efficiently find an answer to this problem?
The Actuator Relocation Problem
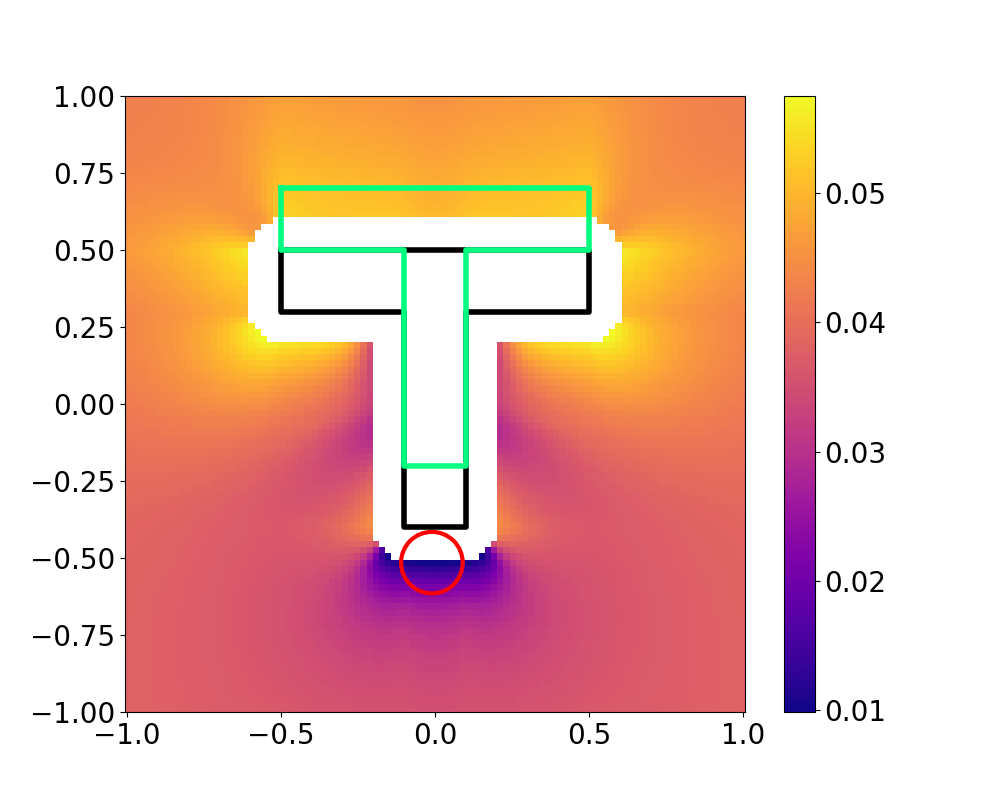
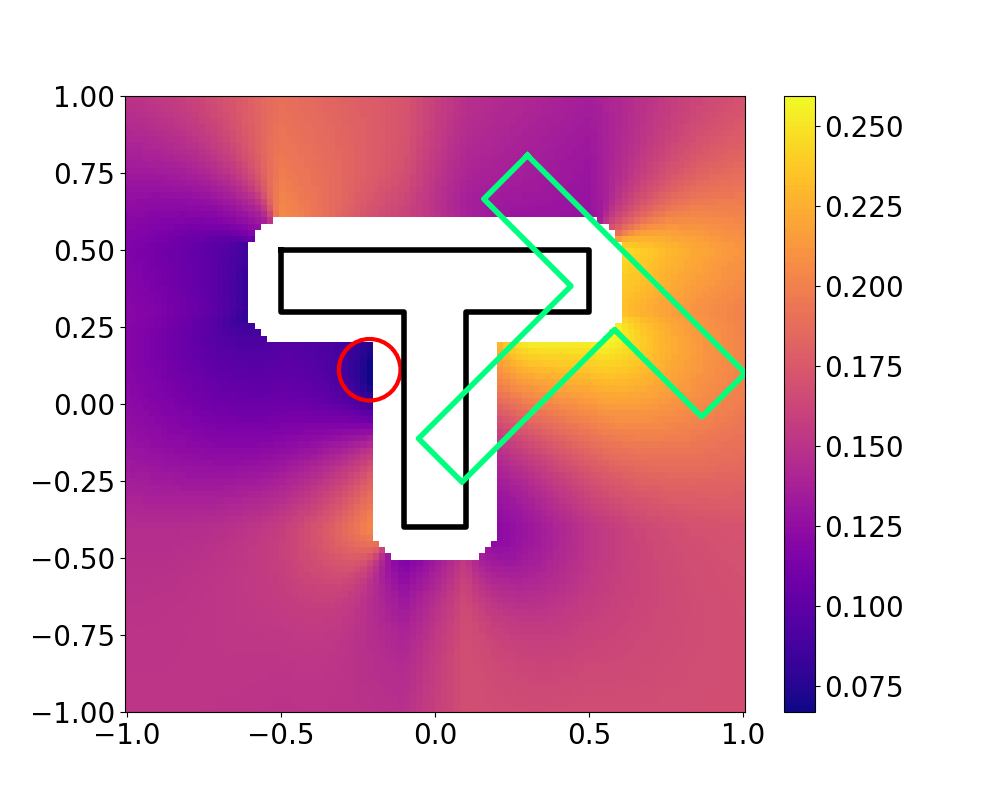
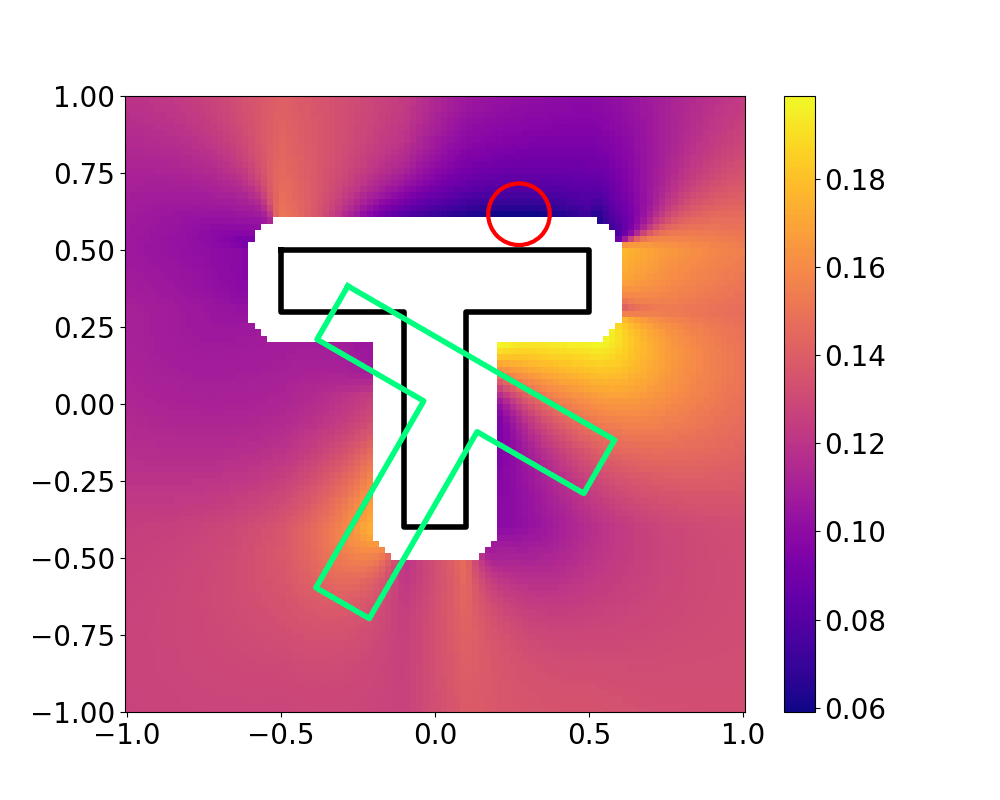
Landscape of the value function is much more complex,
so we resort to sampling-based search
Grasp Synthesis Procedure
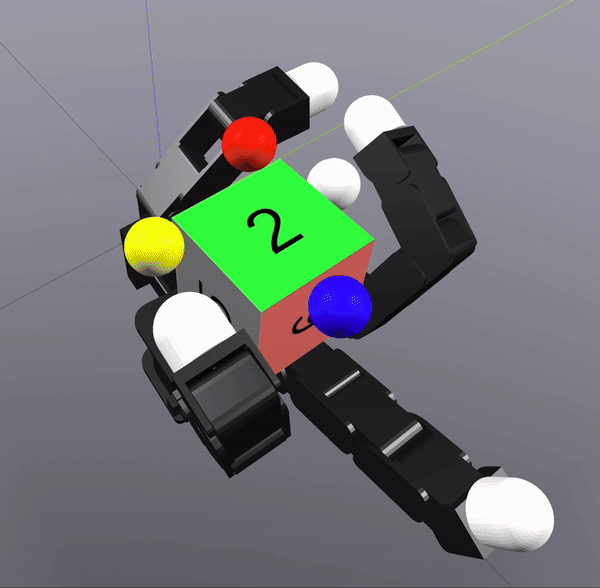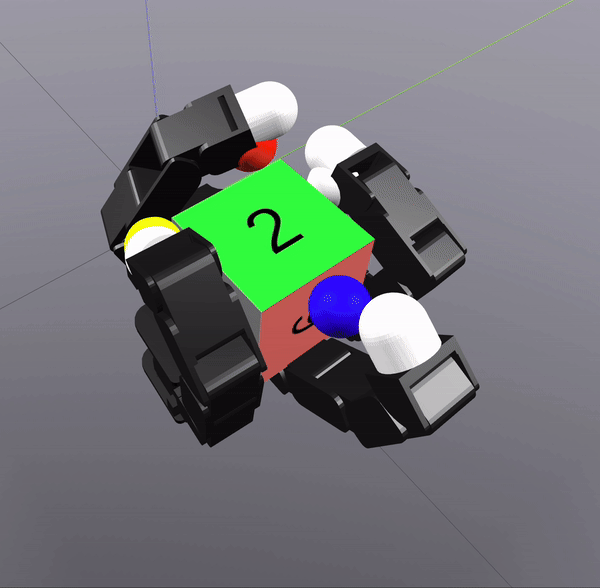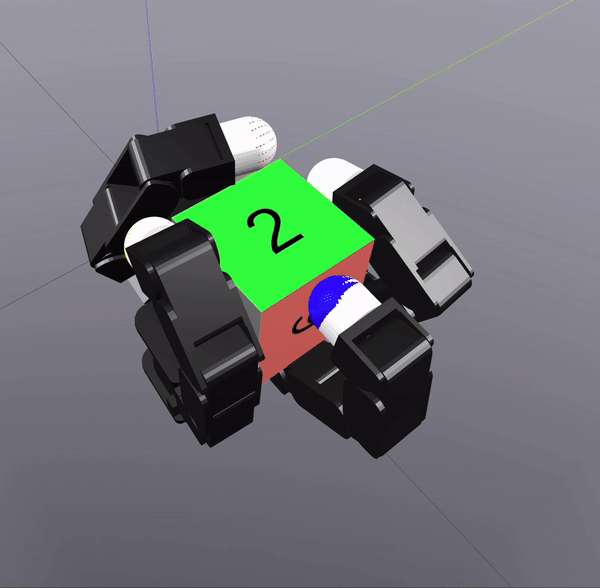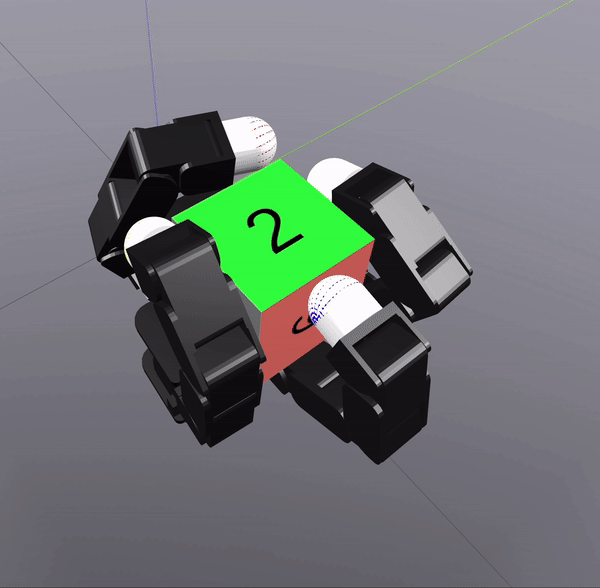

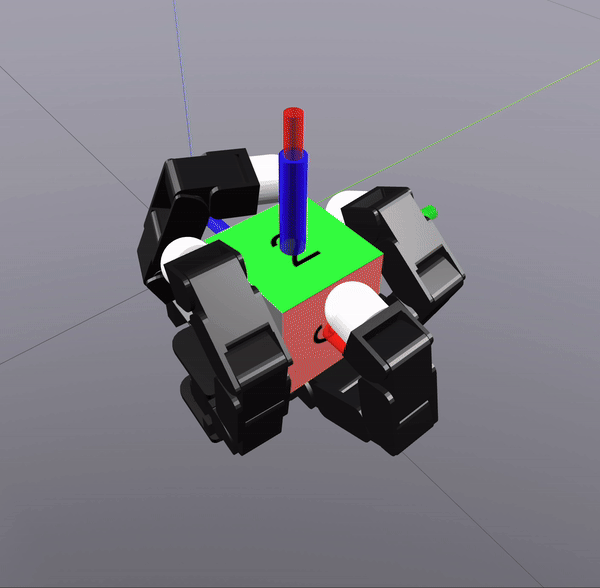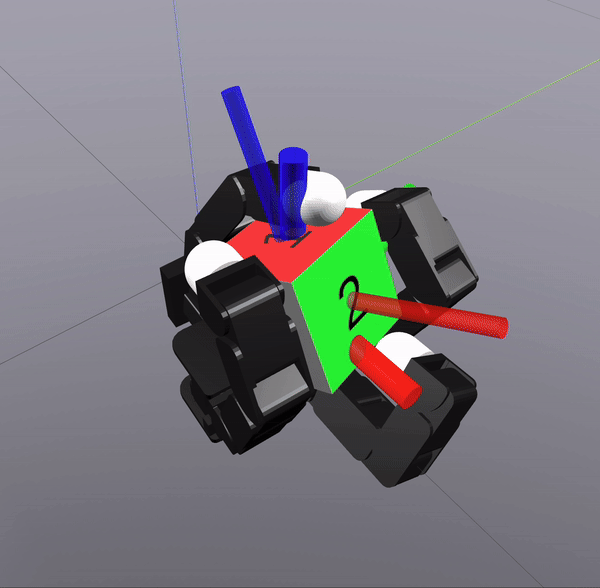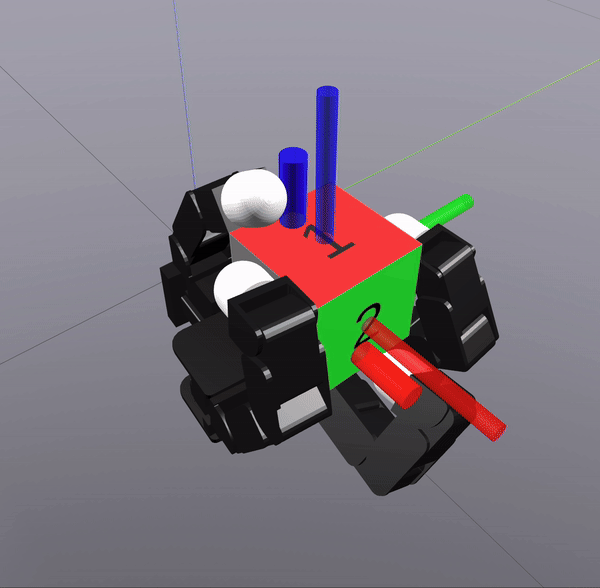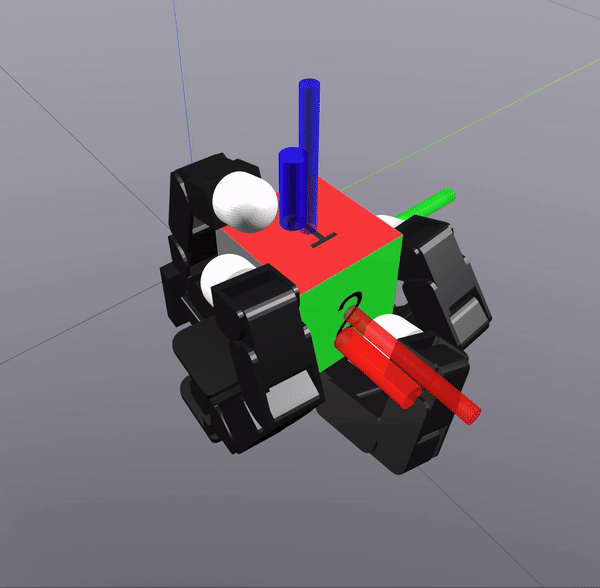
Sampling-Based Search on
Reduced-Order System
Differential Inverse Kinematics to find Hand Configuration
Verification with MPC rollouts
Grasp Synthesis Results
Pitch + 90 degrees
Yaw + 45 degrees
Pitch - 90 degrees
Konidaris & Barto,
Skill Chaining (2009)
Primitive View on Grasp Synthesis + MPC

TLP & LPK (2014)

Toussaint
Logic-Geometric Programming (2015)
We have introduced discreteness by defining a primitive
\begin{aligned}
\textrm{Move}(q^\mathrm{u}_\mathrm{init}, q^\mathrm{u}_\mathrm{goal})
\end{aligned}
TM & JU & PP & RT
Graph of Convex Sets (2023)
Tedrake,
LQR-Trees (2009)
[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
What are fundamental limits of local control?
How can we address difficult exploration problems?
How do we achieve better global planning?
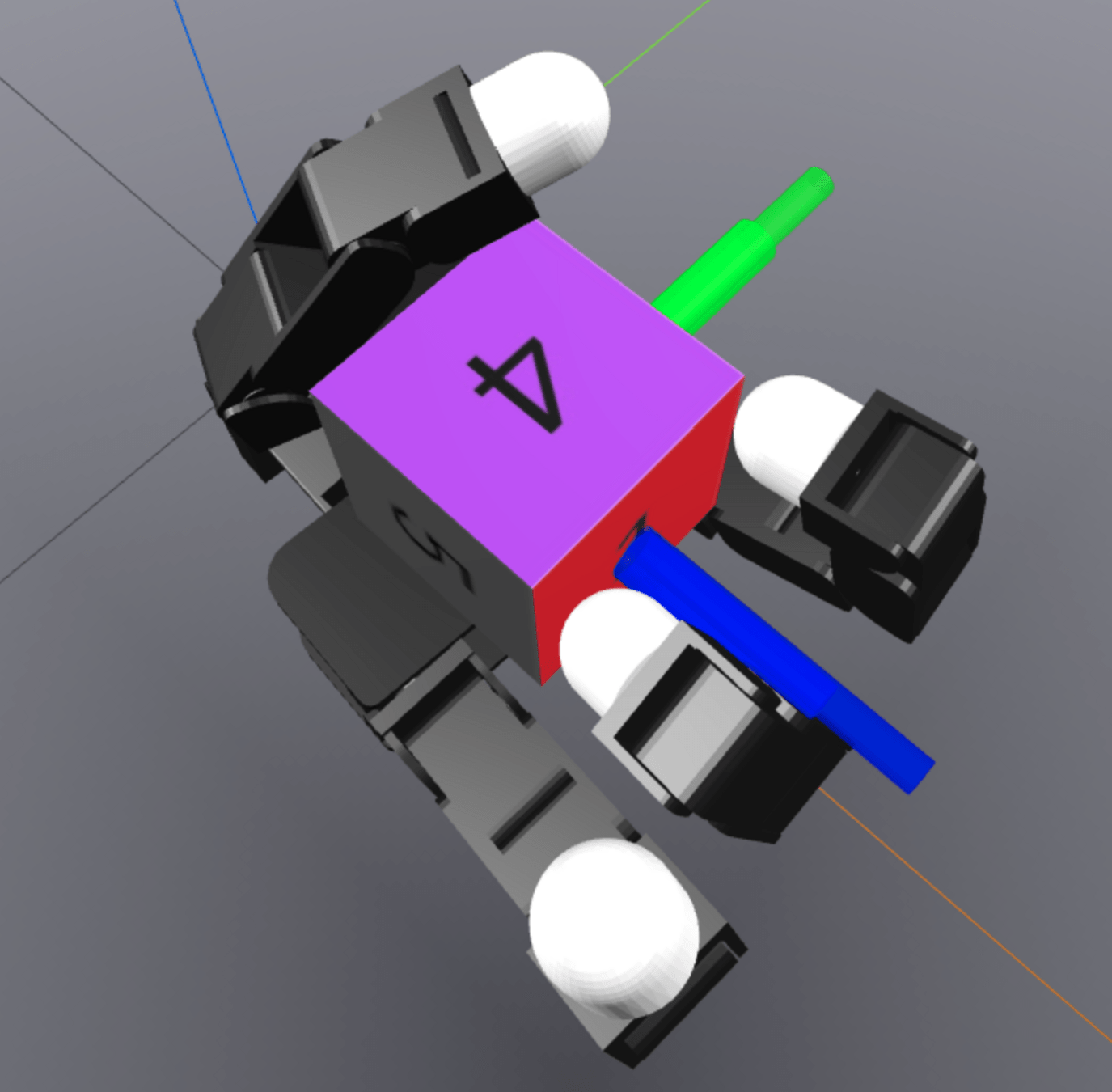
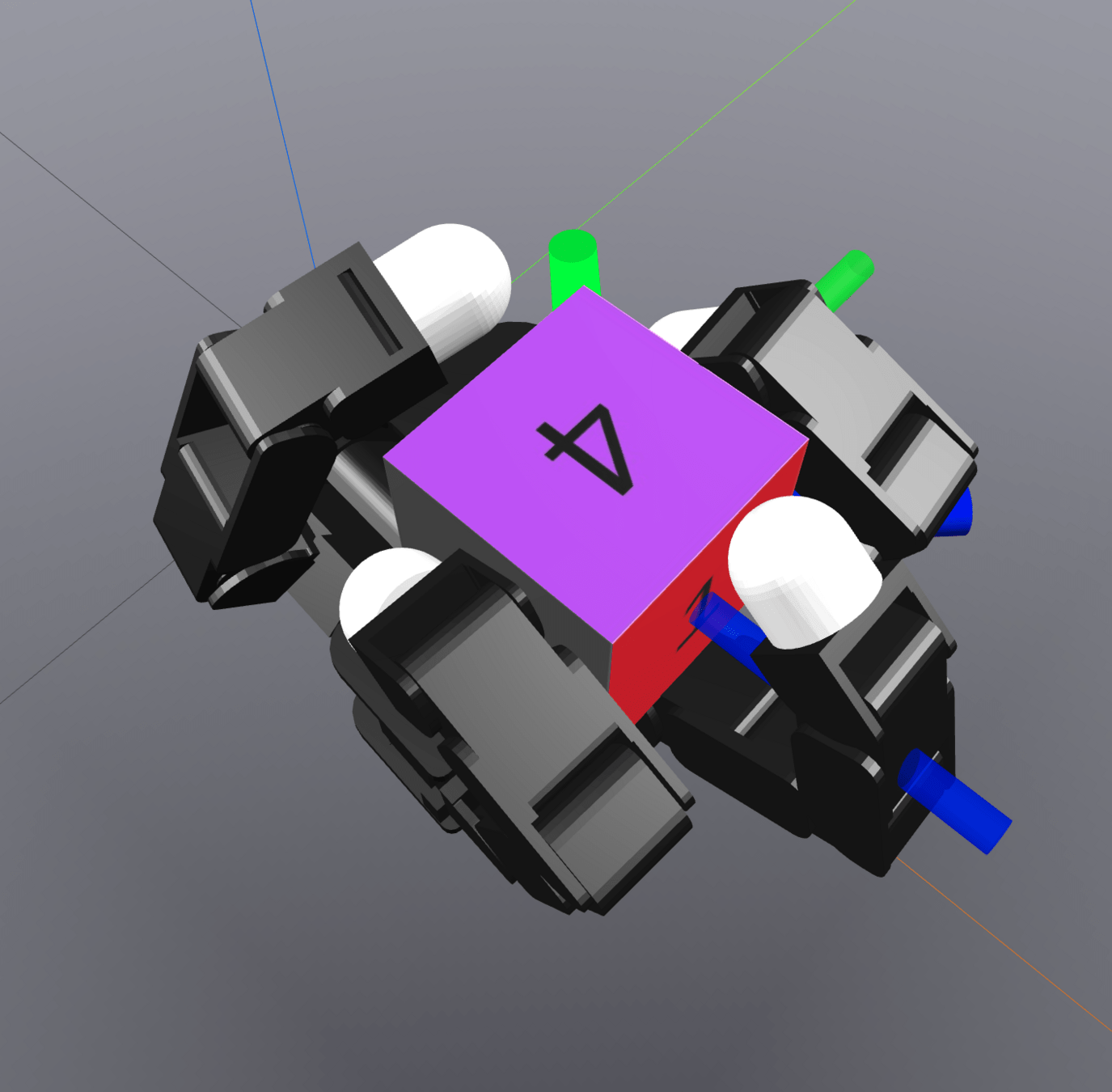
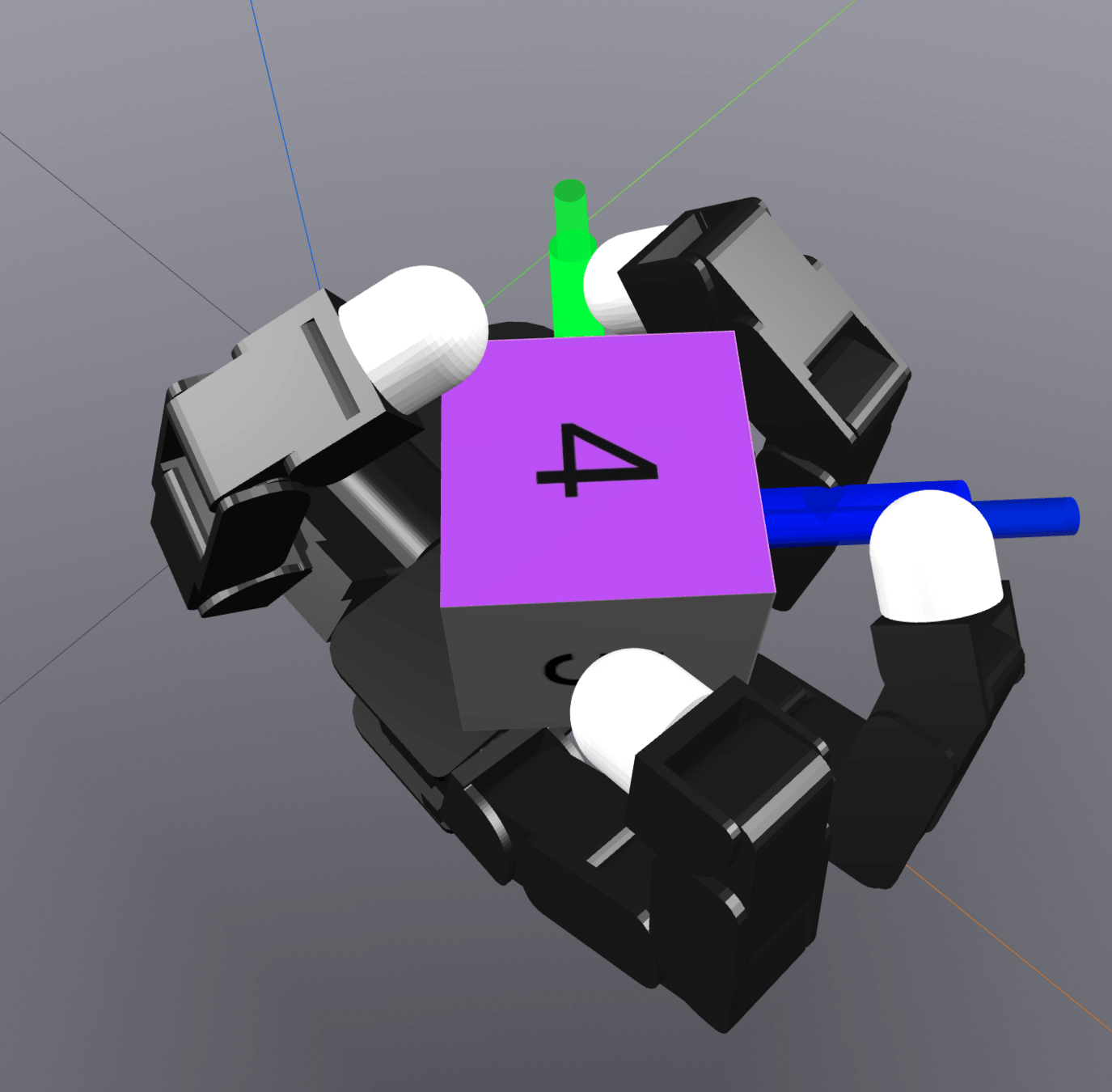
Chaining Local Actions
q^\mathrm{a}
q^\mathrm{u}_x
q^\mathrm{u}_y
q_0
q_1
q_1'
q_2
MPC
MPC
q_2^\mathrm{u}
q_0^\mathrm{u}
q_1^\mathrm{u}
Regrasp
(Collision-Free Motion Planning)

q^\mathrm{a}
q^\mathrm{u}_x
q^\mathrm{u}_y
q_0
q_1
q_1'
q_2
MPC
MPC
q_2^\mathrm{u}
q_0^\mathrm{u}
q_1^\mathrm{u}
Regrasp
(Collision-Free Motion Planning)
Chaining Local Actions
Chaining Local Actions
Conditions for the Framework
- Object is stable during regrasp (Acts like a predicate for the move primitive)
- Local controller is able to correct for small errors while chaining actions together
q^\mathrm{a}
q^\mathrm{u}_x
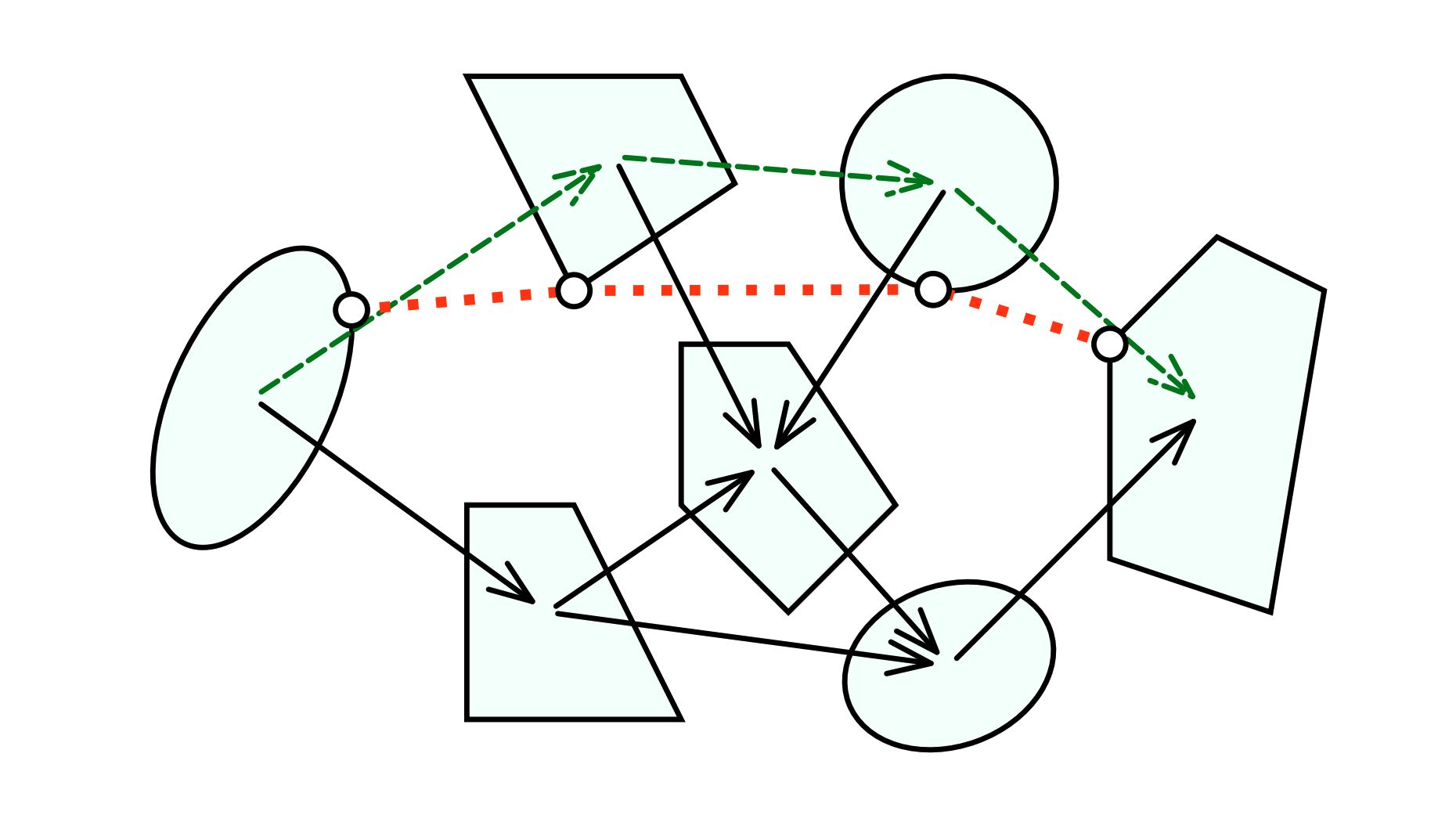
Roadmap Approach to Manipulation
Offline, build a roadmap of object configuration and keep collection of nominal plans as edges
q^\mathrm{u}_y
Roadmap Approach to Manipulation
q^\mathrm{a}
q^\mathrm{u}_x
Roadmap Approach to Manipulation
When getting a new goal that is not in the roadmap, try to connect from nearest node.
q^\mathrm{u}_y
q^\mathrm{u}_\mathrm{goal}
[TRO 2023, TRO 2025]
Part 3. Global Planning for Contact-Rich Manipulation
What are fundamental limits of local control?
How can we address difficult exploration problems?
How do we achieve better global planning?
Part 3. Global Planning for Contact-Rich Manipulation
Part 2. Local Planning / Control via Dynamic Smoothing
Part 1. Understanding RL with Randomized Smoothing
Introduction
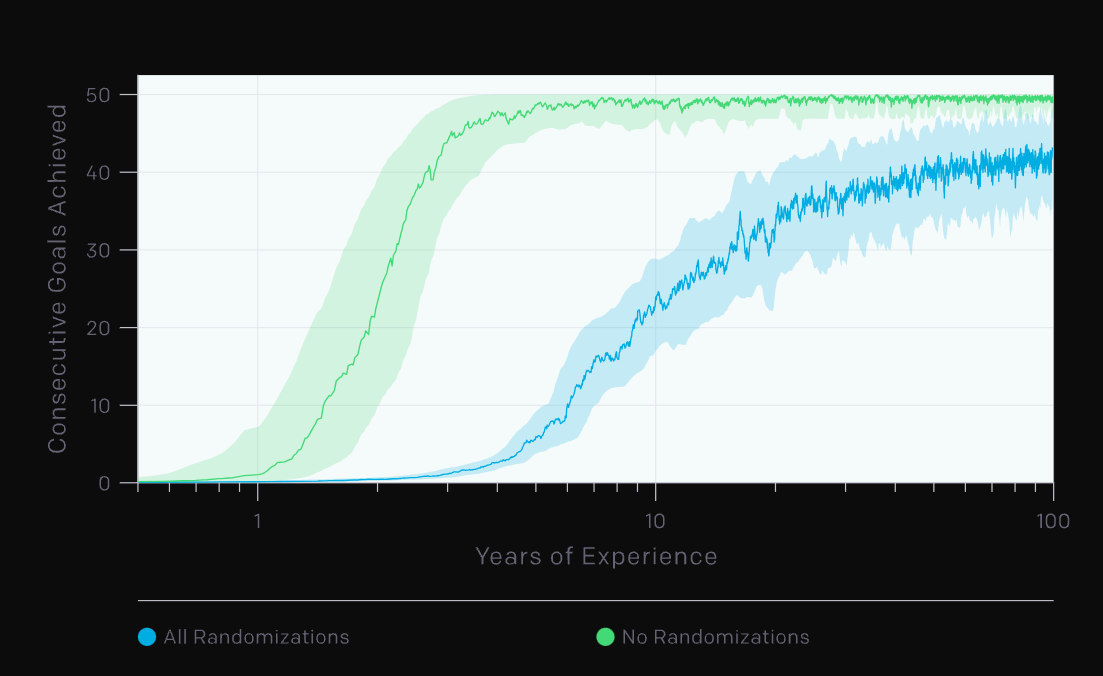
Preview of Results
Our Method
Contact Scalability
Efficiency
Global Planning
60 hours, 8 NVidia A100 GPUs
5 minutes, 1 Macbook CPU
Thesis Defense (XX)
By Terry Suh




