機器學習大雜燴
講師:王勻
今天會學到什麼
- 針對問題建神經網路
- 神經網路的各種神奇應用
- 體驗神經網路的強大
精通keras精通python-
唬爛
(類)神經網路!
原理
數學
實作
唬爛
神經網路是什麼?
神經網路,一言以蔽之,曰:「萬能函數」
什麼意思?
神經網路可以變成任意的函數
(任意 \(\R\rightarrow\R\) 的連續函數)
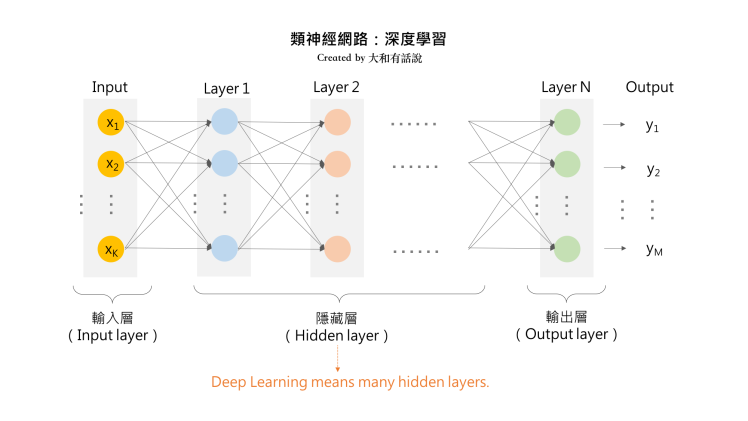
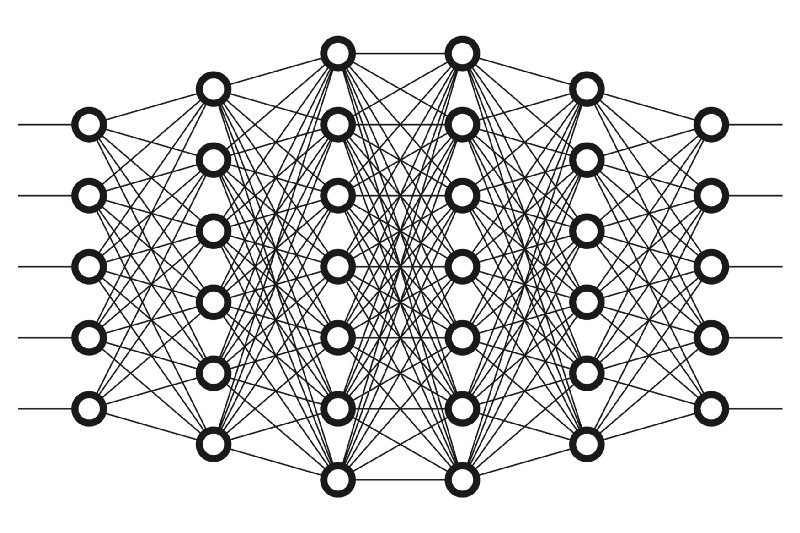
神經網路
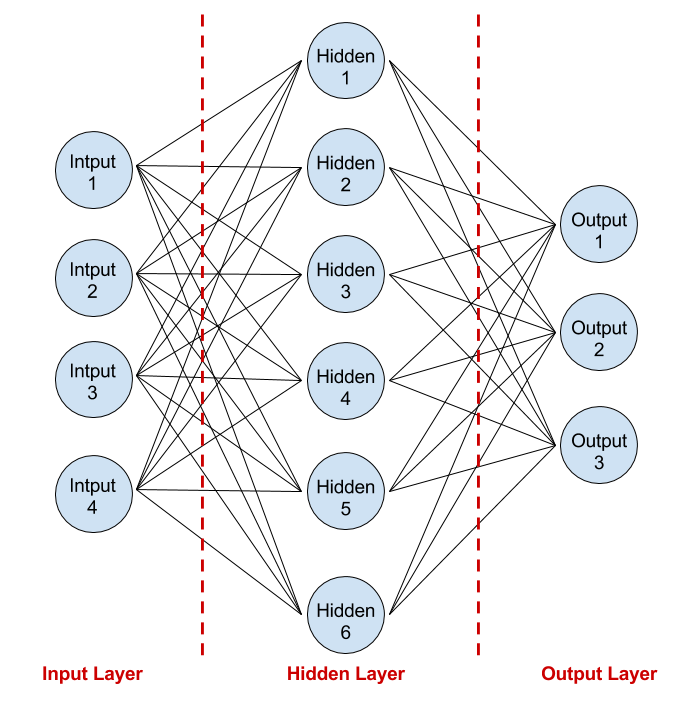
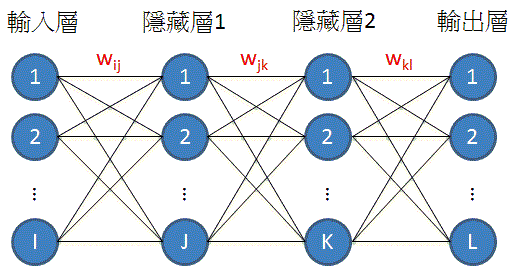
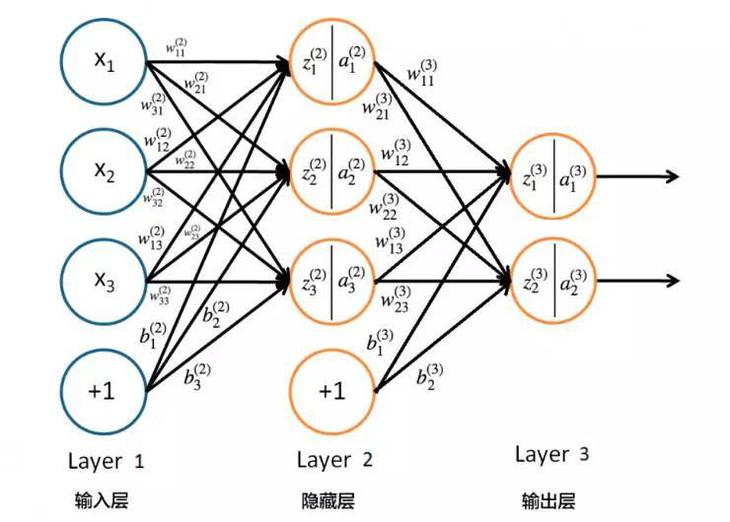
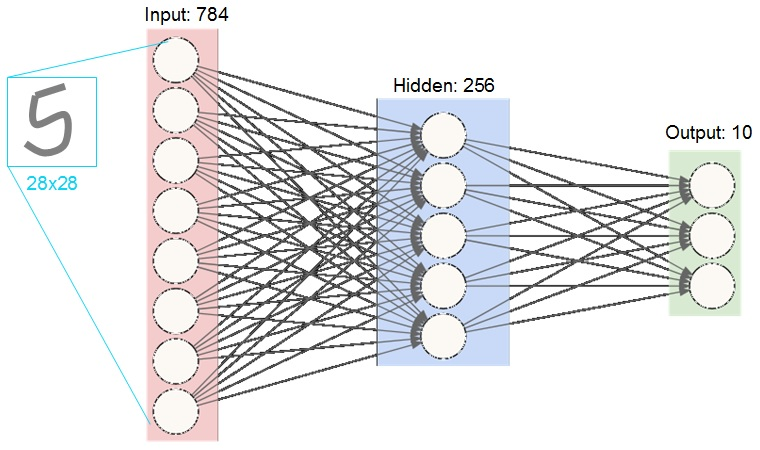
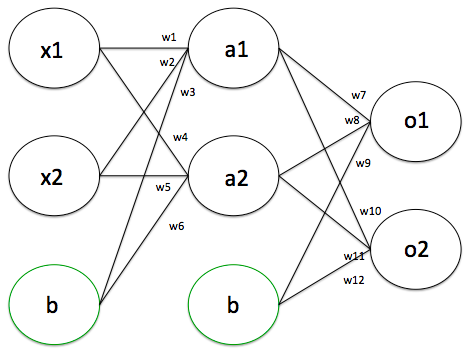
神經網路的特徵
- 一排一排的節點
- 第一排連到第二排、第二排連到第三排...
- 每個連線上都有權重
- 每個節點都是一個數字
- 激勵函數activation function(非線性)
神經網路
- 一排一排的節點們\(\Longrightarrow\)layers(層)
- 兩排之間兩兩相聯\(\Longrightarrow\)fully connected
- 節點上的數字\(\Longrightarrow\)layer output
- activation function\(\Longrightarrow\)activation function
模型 v.s. 函數
模型 = 函數 with 參數
函數:
\(y=f(x)=3x+4\)
\(y=f(x)=\log_{71}^x22\)
模型:
\(y=f(x)=ax+b\)
\(y=f(x)=\log_{71}^xa\)
模型 = 有符號(非變數)的函數
模型放入不同的參數會形成不同的函數
神經網路強在哪?
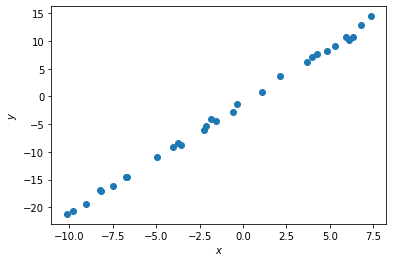
- 線性函數
- \(y=ax+b\)
- 找出最適合的 \(a\) 和 \(b\)
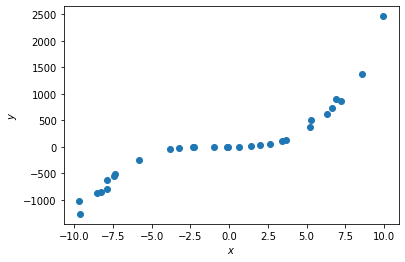
- 三次多項式(?)
- \(y=ax^3+bx^2+cx+d\)
- 找出最適合的 \(a,b,c,d\)
- 週期函數!
- 三角函數(?)
- \(y=a\sin(bx+c)+d\)
- 找出最適合的 \(a,b,c,d\)
- 週期函數!
- 三角函數(?)
- \(y=a\sin(bx+c)+d\)
- 找出最適合的 \(a,b,c,d\)
- 線性函數
- \(y=ax+b\)
- 找出最適合的 \(a\) 和 \(b\)
- 三次多項式(?)
- \(y=ax^3+bx^2+cx+d\)
- 找出最適合的 \(a,b,c,d\)
模型
機器學習or公式
假如我選錯模型怎麼辦?
\(\rightarrow\) 不斷嘗試各種模型,直到得出滿意的結果
假如我看不出是哪種模型怎麼辦?
\(\rightarrow\) 任何 \(\R\rightarrow\R\) 的函數都可以用神經網路達成
- 線性函數
- \(y=ax+b\)
- 找出最適合的 \(a\) 和 \(b\)
- 三次多項式(?)
- \(y=ax^3+bx^2+cx+d\)
- 找出最適合的 \(a,b,c,d\)
- 週期函數!
- 三角函數(?)
- \(y=a\sin(bx+c)+d\)
- 找出最適合的 \(a,b,c,d\)
神經網路的基本運算
加權和 \(\rightarrow\) 通過激勵函數 \(\rightarrow\) 加權和 \(\rightarrow\) 通過激勵函數 \(\cdots\)
\(1\)
\(2\)
\(3\)
\(-2\)
\(5\)
\(4\)
\(1\times4+2\times-2=0\)
\(1\times3+2\times5=13\)
activation function
\(0.999\)
\(0.5\)
\(\cdots\)
線性運算
非線性運算
神經網路的核心--激勵函數
各種激勵函數:
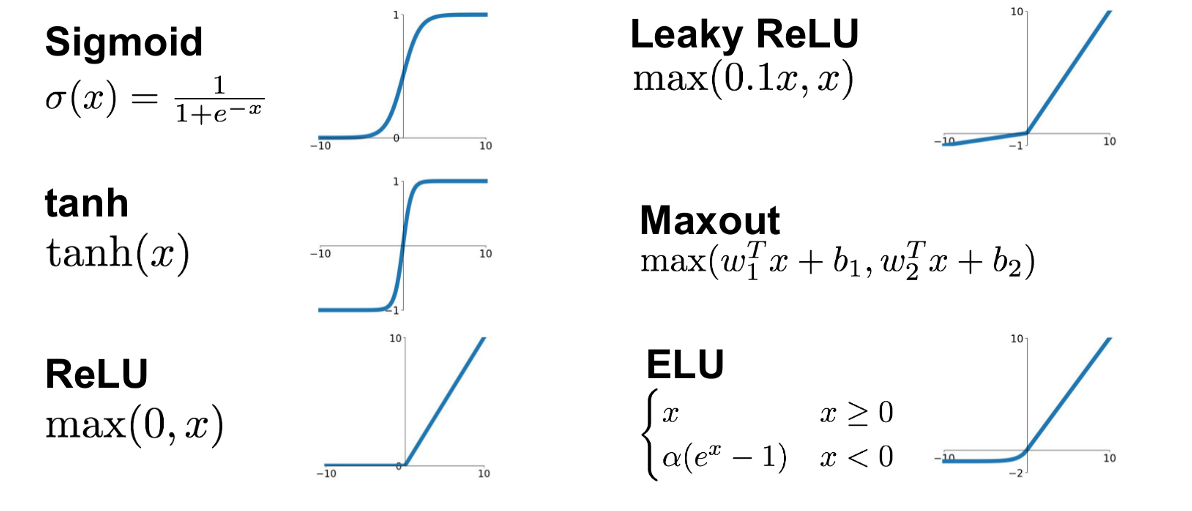
神經網路的核心--激勵函數
為什麼要激勵函數?
- 假如沒有激勵函數
- \(\Longrightarrow\) 只剩權重
- \(\Longrightarrow\) 線性模型
- \(\Longrightarrow\) 有侷限性
需要非線性的激勵函數幫忙!
神經網路的核心--激勵函數
如何選擇激勵函數?
sigmoid
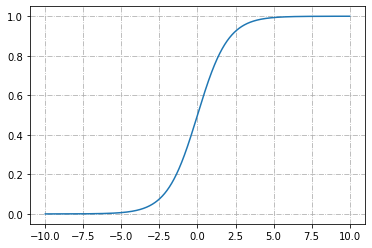
- 輸出介於0~1
- 模糊地帶(非0非1)少
- \(\Rightarrow\)適合表示機率
- 少用(避免梯度消失)
神經網路的核心--激勵函數
如何選擇激勵函數?
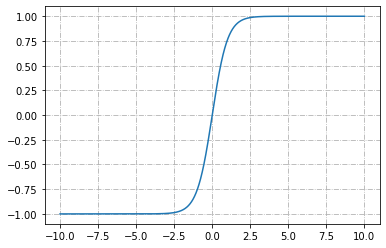
tanh
- 輸出介於-1~1
- 模糊地帶(非-1非1)少
- 類似sigmoid
- \(\Rightarrow\)適合表示二元分類
- 少用(避免梯度消失)
神經網路的核心--激勵函數
如何選擇激勵函數?
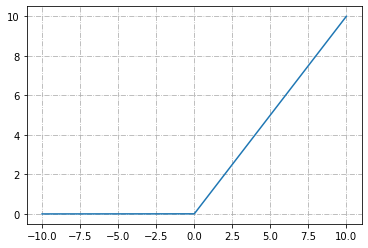
ReLU
- 線性函數的組合
- 計算快速
- 模仿細胞運作
- 運用效果佳
- \(\Rightarrow\)最常作中間層激勵函數
神經網路的核心--激勵函數
如何選擇激勵函數?
Softmax
- 多元分類的輸出層
- 理論的產物
- 計算不同類別的機率
神經網路的結構--layers
如何建構神經網路?
各種不同的layer
-
fully connected layer
-
convolutional layer
-
LSTM layer
-
Pooling layer
-
Flatten layer
fully connected layer(Dense)
- 兩層之間的點都兩兩相連
\(a_0\)
\(a_1\)
\(a_2\)
\(a_3\)
\(b_0\)
\(b_1\)
\(b_2\)
\(b_3\)
layer1
layer2
convolutional layer(Conv)
- 殘缺的fully connected layer(?)
- 處理相同pattern重複出現(圖片)
LSTM layer
long short-term memory
- 處理前後互相影響的東西
- 音訊、文字、影片 ...
\(a_0\)
\(a_1\)
\(a_2\)
\(a_3\)
\(b_0\)
\(b_1\)
\(b_2\)
\(b_3\)
layer1
layer2
t=0
t=1
t=2
t=3
Pooling layer 池化
- 分塊取最大值(or平均值...)
- 縮小圖片
- 沒錯,就是拿來對付圖片
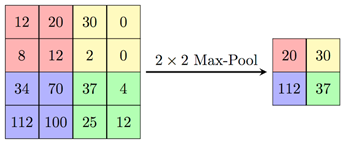
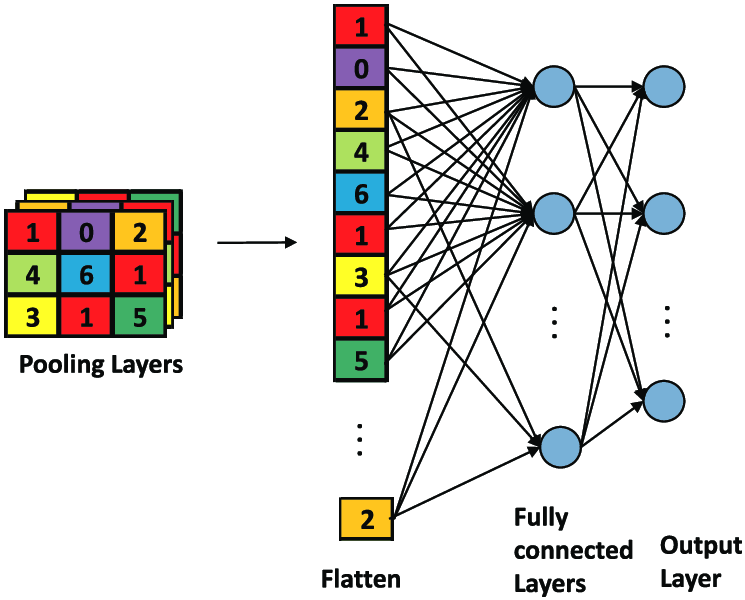
Flatten layer 壓平
- 把矩陣壓成一條(一維)陣列
loss functions
- 告訴電腦函數的好壞
- 根據誤差調整模型
- categorical cross entropy
- binary cross entropy
- mean square root
categorical cross entropy
for classification tasks
順便介紹一下分類問題吧!
我們所期望的分類器:


f(
)=\texttt{"cat"}
f(
)=\texttt{"dog"}
但\(\cdots\)神經網路要是 \(\R\rightarrow\R\) 的函數!
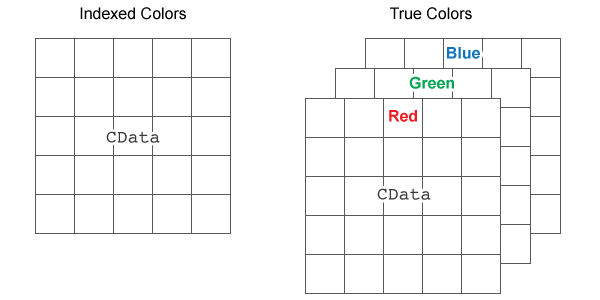
圖片:可以用pixel表示成RGB的陣列
那文字呢?
轉成ascii碼絕對不是好方法!
\(\Rightarrow\) 我們常以「屬於每個類別的機率(機率分布)」作為神經網路的輸出(機率是實數)
假如要分貓、狗、鳥三個類別:
\Rightarrow
\begin{bmatrix}
1\\
0\\
0
\end{bmatrix}

\Rightarrow
\begin{bmatrix}
0\\
1\\
0
\end{bmatrix}
\Rightarrow
\begin{bmatrix}
0\\
0\\
1
\end{bmatrix}
f(\texttt{image})=
\begin{bmatrix}
P_{cat}\\
P_{dog}\\
P_{bird}
\end{bmatrix}
cross entropy
f(\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space)=
\begin{bmatrix}
P_{cat}\\
P_{dog}\\
P_{bird}
\end{bmatrix}
\leftrightarrow
\begin{bmatrix}
1\\
0\\
0
\end{bmatrix}
f(\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space)=
\begin{bmatrix}
P_{cat}\\
P_{dog}\\
P_{bird}
\end{bmatrix}
\leftrightarrow
\begin{bmatrix}
0\\
1\\
0
\end{bmatrix}
f(\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space)=
\begin{bmatrix}
P_{cat}\\
P_{dog}\\
P_{bird}
\end{bmatrix}
\leftrightarrow
\begin{bmatrix}
0\\
1\\
0
\end{bmatrix}
cross entropy
計算兩個機率分布的相似度
cross entropy
- 當你在做分類問題、算機率
- cross entropy!!!
categorical_crossentropy
就是cross entropy
binary_crossentropy
二元分類問題
sparse_categorical_crossentropy
用0取代
\begin{bmatrix}
1\\
0\\
0
\end{bmatrix}
,1取代
\begin{bmatrix}
0\\
1\\
0
\end{bmatrix}
,\cdots
mean square error
for scalar prediction
loss=\sum\limits_{i=1}^d(x_i-\hat{x_i})^2
代表預測的數值\((x_i)\)與正確的數值\(\hat{x_i}\)的差的大小(平方)
cosine similarity
for vector prediction
loss=\frac{\vec{x_{pre}}\cdot\vec{x_{ans}}}{|\vec{x_{pre}}|\cdot|\vec{x_{ans}}|}
計算預測向量和實際向量的夾角cosine值
optimizers
train你的模型的工具
概念:
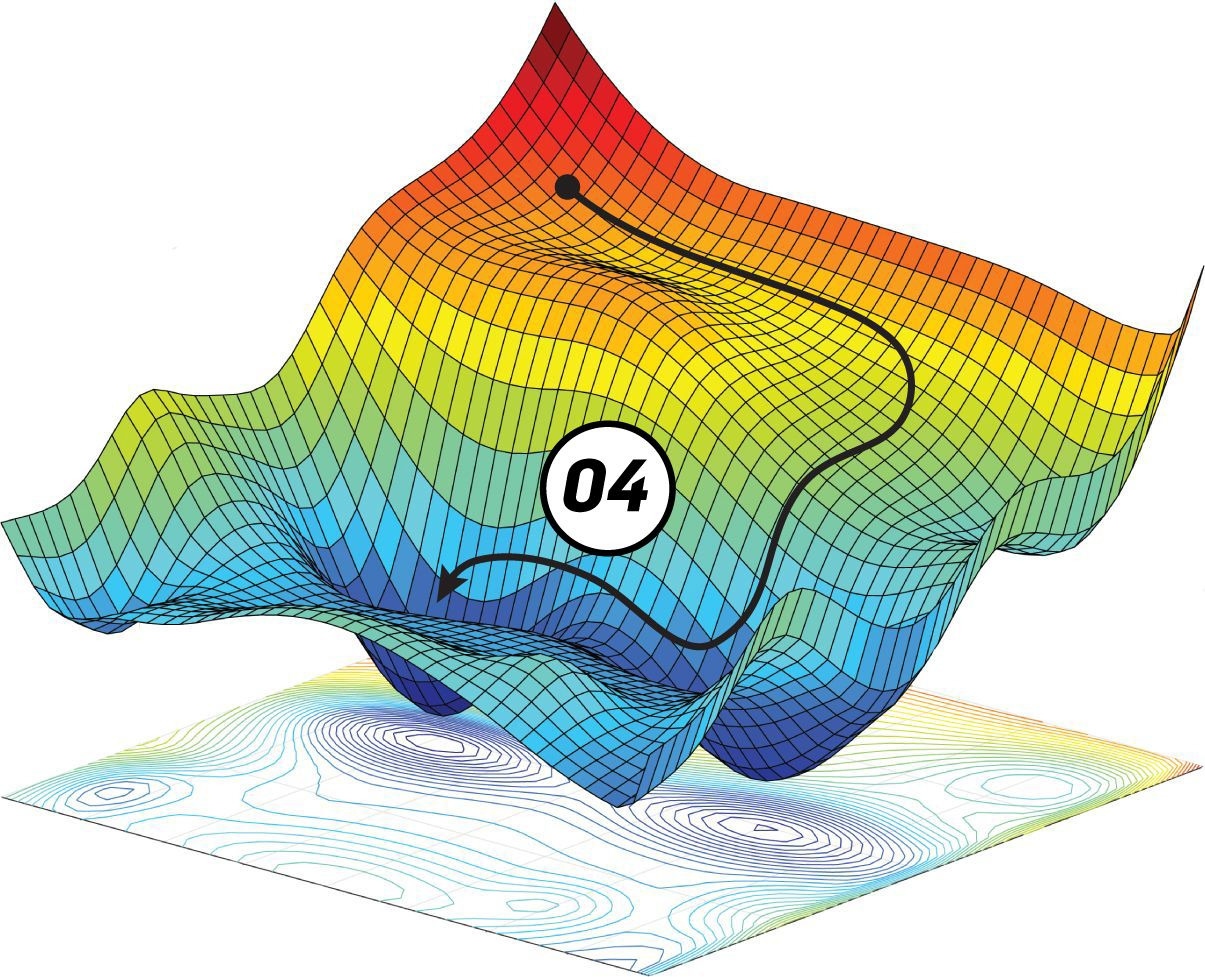
往loss低的地方走!
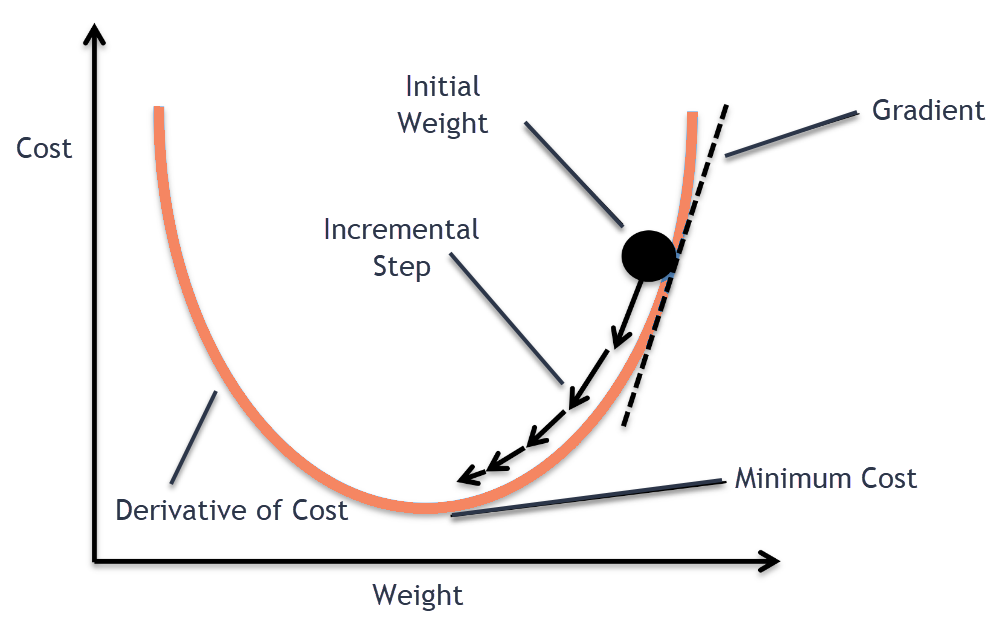
optimizers
train你的模型的工具
-
往低的地方走
-
順著坡度走
-
計算坡度
-
微分!!!
ㄏㄏ我們才沒有要講這個
optimizers
以下幾種強大的優化器(?)
- SGD (optimizers之祖)
- Adam
- Adagrad
- RMSprop
- ......
輕輕鬆鬆啦!
是不是開始想睡了
講那得多東西
我還是不懂
神經網路啊
該如何建出神經網路
-
釐清你的輸入是什麼、該怎麼以數字呈現
-
釐清你的輸出是什麼、該怎麼以數字呈現
*神經網路搭建成功的關鍵:shape(神經元排列形狀)的維持
如果我要做圖片辨識...?
輸入:圖片
輸出:類別

怎麼表示成數字?
- 點陣圖
- RGB
怎麼表示成數字?
abcde- 第 \(i\) 類?
- 屬於第 \(i\) 類的機率!
若有三個類別(cat dog bird)
輸出可能是:
P_{cat}=0.01\\
P_{dog}=0.31\\
p_{bird}=0.68
輸入:圖片
- 一張圖片由 \((\text{長}\times\text{寬})\) 個 pixels 組成
- 彩色
- 一個 pixel 由 RGB 三個 0~255 的整數組成
- 一張圖片的 \(\texttt{shape}=(\text{長},\text{寬},3)\)
- 黑白
- 一個 pixel 由一個 0~255 的整數組成
- \(\texttt{shape}=(\text{長},\text{寬},1)\)
輸出:機率
- 若有 \(k\) 個類別:
- 輸出一條 \(k\) 個數字的陣列,總和是 \(1\)
- \(\texttt{shape}=(k,)\)
Now We Have...
\texttt{input\_shape}=(\text{長},\text{寬},3)
\texttt{output\_shape}=(\texttt{num\_of\_classes},)
and then ?
input layer
output layer
hidden layer
hidden layer
hidden layer
hidden layer
\(\vdots\)
選擇隱藏層
圖片 \(\Leftrightarrow\) Convolution
relu
convolution
convolution
relu
\(\vdots\)
input layer
activation和其他layers通常交錯排列
Convolution
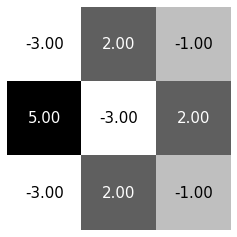

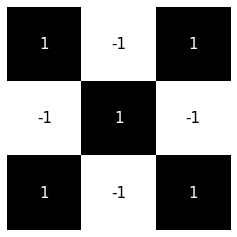
\(\texttt{shape}=(5,5,1)\)
\(\texttt{Conv}(3,3)\)
\(\texttt{shape}=(3,3,1)\)
\(\texttt{shape}=(n,n,1)\)
\(\texttt{shape}\\=(n-k+1,n-k+1,1)\)
\(\texttt{Conv}(k,k)\)
kernal
Convolution
\(\texttt{shape}=(5,5,1)\)
\(\texttt{Conv}(6,(3,3))\)
\(\texttt{shape}=(3,3,6)\)
\(\texttt{shape}=(n,n,1)\)
\(\texttt{shape}\\=(n-k+1,n-k+1,x)\)
\(\texttt{Conv}(x,(k,k))\)
\(n\) kernals
Convolution
- \(\texttt{Conv(a,(b,c))}\Rightarrow a \text{ 個 } b \times c \text{ 的 kernal}\)
- 圖片辨識通常kernal_size都是\((3,3)\)
- 也可以用Dense取代,但Conv的訓練較容易
立體結構\(\xrightarrow{\text{壓平}}\)直線排列\(\xrightarrow{\texttt{Dense+softmax}}\)機率分布
決策
特徵提取
輸入
Flatten
softmax
Dense
\(\vdots\)
input layer
relu
convolution
relu
convolution
舉個例
convolution(1,(3,3))
relu
convolution(10,(3,3))
relu
relu
convolution(10,(3,3))
Flatten
softmax
Dense(10)
input layer (28,28,1)
relu
convolution(5,(3,3))
(10,)
(10,)
(400,)
(20,20,1)
(20,20,1)
(22,22,10)
(22,22,10)
(24,24,10)
(24,24,10)
(26,26,5)
(26,26,5)
(28,28,1)
SO !
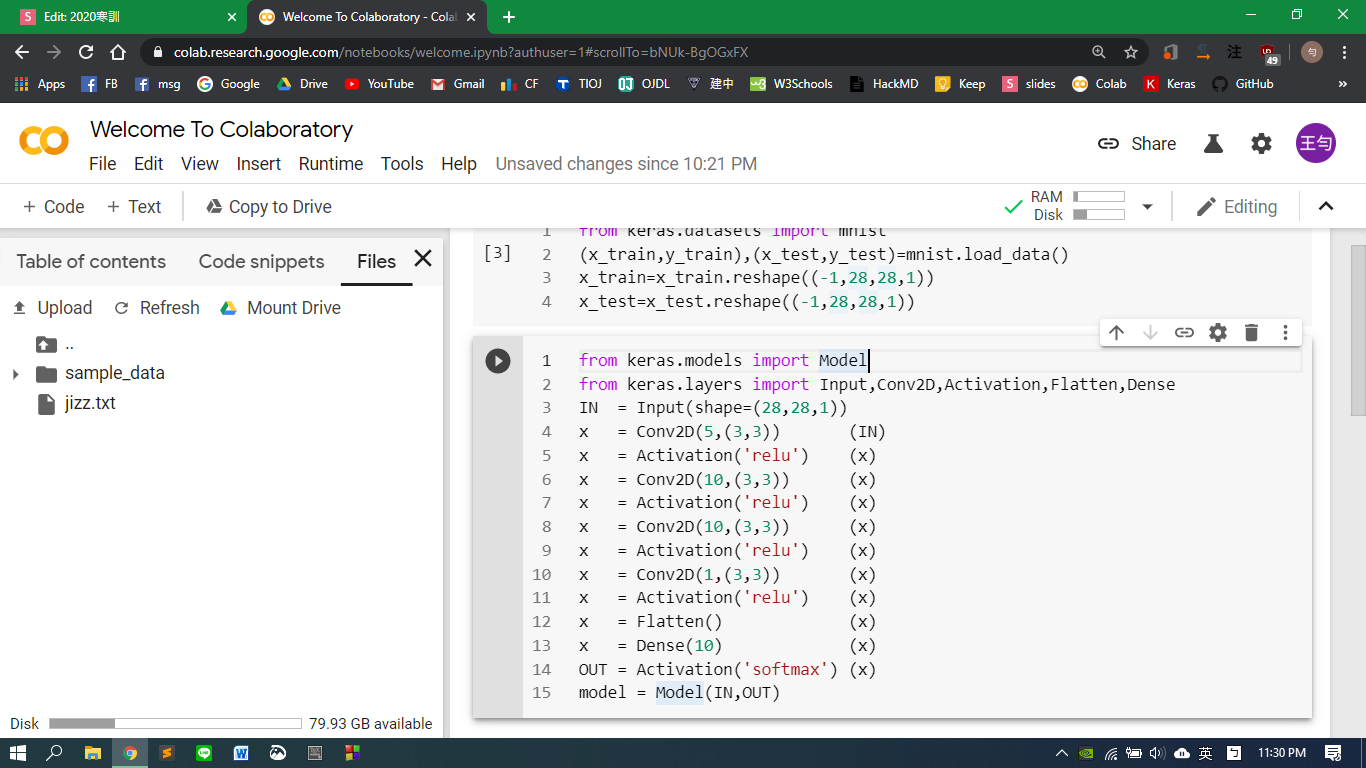
神經網路的實現:Keras (+Python)


import keras
from keras.models import Model
from keras.layers import ...classes for different layers
relu
Flatten
softmax
Dense(10)
input layer (28,28,1)
convolution(5,(3,3))
Conv2D(5,(3,3))
Input(shape=(28,28,1))
Dense(10)
Activation('softmax') or Softmax()
Flatten()
Activation('relu') or ReLU()
convolution(1,(3,3))
relu
convolution(10,(3,3))
relu
relu
convolution(10,(3,3))
Flatten
softmax
Dense(10)
input layer (28,28,1)
relu
convolution(5,(3,3))
x=Conv2D(1,(3,3))(x)
x=Activation('relu')(x)
x=Conv2D(10,(3,3))(x)
x=Activation('relu')(x)
x=Activation('relu')(x)
x=Conv2D(10,(3,3))(x)
x=Flatten()(x)
OUT=Activation('softmax')(x)
x=Dense(10)(x)
IN=Input(shape=(28,28,1))
x=Activation('relu')(x)
x=Conv2D(5,(3,3))(IN)
model = Model(IN,OUT)AT LAST
x=Conv2D(1,(3,3))(x)
x=Activation('relu')(x)
x=Conv2D(10,(3,3))(x)
x=Activation('relu')(x)
x=Activation('relu')(x)
x=Conv2D(10,(3,3))(x)
x=Flatten()(x)
OUT=Activation('softmax')(x)
x=Dense(10)(x)
IN=Input(shape=(28,28,1))
x=Activation('relu')(x)
x=Conv2D(5,(3,3))(IN)
model.compile(loss='sparse_categorical_crossentropy',optimizer='SGD')分類問題 \(\Rightarrow\texttt{categorical\_crossentropy}\)
optimizer 隨便選
model.summary()model.fit(x_train,y_train,epochs=10)Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 26, 26, 5) 50
_________________________________________________________________
activation_7 (Activation) (None, 26, 26, 5) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 24, 24, 10) 460
_________________________________________________________________
activation_8 (Activation) (None, 24, 24, 10) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 22, 22, 10) 910
_________________________________________________________________
activation_9 (Activation) (None, 22, 22, 10) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 20, 20, 1) 91
_________________________________________________________________
activation_10 (Activation) (None, 20, 20, 1) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 400) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 4010
_________________________________________________________________
activation_11 (Activation) (None, 10) 0
=================================================================
Total params: 5,521
Trainable params: 5,521
Non-trainable params: 0
_________________________________________________________________以 \(\texttt{x\_train}\)(input) 和 \(\texttt{y\_train}\)(target output) 作為訓練資料訓練神經網路,跑遍整個訓練資料10次
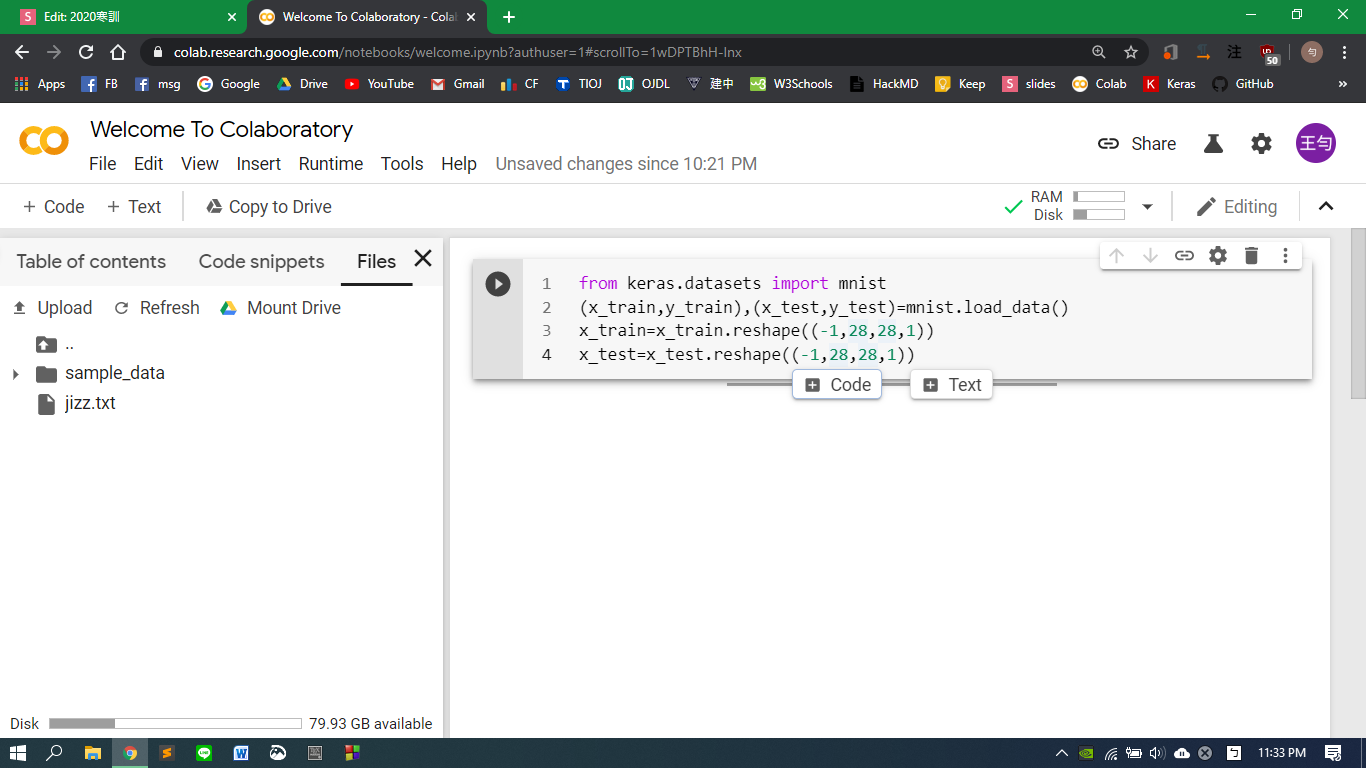
實際應用一下 MNIST
from keras.datasets import mnist
(x_train,y_train),(x_test,y_test)=mnist.load_data()
x_train=x_train.reshape((-1,28,28,1))
x_test=x_test.reshape((-1,28,28,1))
輸入(x_train):\(28\times28\) 的灰階圖片
shape = \((28,28,1)\)
輸出(y_train):圖片對應到的數字
shape = \((1,)\)
\(\texttt{x\_train}\)
\(\texttt{y\_train}\)
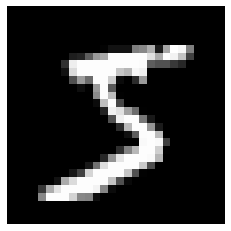
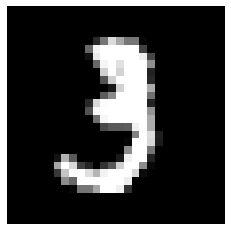
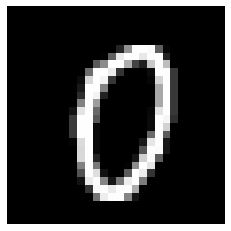
\(5\)
\(3\)
\(0\)

新增
開啟
使用GPU
新增
code
block
檔案管理
Why Colab ?
-
Google提供的強大GPU運算資源
-
多數modules皆已安裝
-
可直接連結 Google Drive
-
F R E E
Why not ?
GAN
Generative Adversarial Network
生成對抗網絡
給定一些真實樣本
訓練一個能模仿該樣本的神經網路


generator生成器
生成圖片
discriminator判別器
辨別機器生成的圖片或真實的圖片
\(\Rightarrow\) 二元分類
將生成的圖片和真實的圖片混在一起,讓discriminator分辨
- generator目標:騙過discriminator
- discriminator目標:正確的分辨真偽
generating seed
生成圖片的依據
-
雖然都是同一種圖片,但要有差異性
-
一個seed對應到一張圖片
-
不同seed生成的圖片都不一樣
generator: seed\(\rightarrow\)圖片
discriminator: 圖片\(\rightarrow\)yes/no
輸入與輸出
圖片的二元分類
generator: \(\texttt{(\_,)}\rightarrow\texttt{(28,28)}\)
discriminator: \(\texttt{(28,28)}\rightarrow\texttt{(1,)}\)
輸入與輸出 shape
\(x_0\)
\(x_1\)
\(x_2\)
\(x_3\)
\(x_4\)
\(a_0\)
\(a_1\)
\(a_2\)
\(a_3\)
\(a_4\)
\(a_5\)
\(a_6\)
\(b_0\)
\(b_1\)
\(b_2\)
\(b_3\)
\(b_4\)
\(b_5\)
\(b_6\)
\(c_0\)
\(c_1\)
\(c_2\)
\(c_3\)
\(c_4\)
\(c_5\)
\(c_6\)
- \(x\) : generating seed
- \(c\) : 圖片\((28\times28)\)
-
值域 :
- \(-1\leq c\leq1\) (tanh)?
- \(0\leq c\leq1\) (sigmoid)?
- \(c\) : 圖片\((28\times28)\)
- \(y\) : 真實圖片的機率 0~1
\(c_0\)
\(c_1\)
\(c_2\)
\(c_3\)
\(c_4\)
\(c_5\)
\(c_6\)
\(d_0\)
\(d_1\)
\(d_2\)
\(d_3\)
\(d_4\)
\(d_5\)
\(d_6\)
\(e_0\)
\(e_1\)
\(e_2\)
\(e_3\)
\(e_4\)
\(e_5\)
\(e_6\)
\(y_0\)
"""每次處理幾筆資料:"""
batch_size=32
"""生成batch_size個隨機的seed:"""
seed=np.random.normal(size=(batch_size,128))
"""根據seeds生成圖片:"""
generated_img=generator.predict(seed)
"""取得真實的圖片:"""
true_img=get_true_img(batch_size)
"""discriminator要將真實圖片辨別成1(true),生成圖片辨別成0(faked):"""
discriminator.train_on_batch(true_img,np.ones((bacth_size,)))
discriminator.train_on_batch(generated_img,np.zeros((bacth_size,)))\texttt{generator.input\_shape=(128,)}\\
\texttt{generator.output\_shape=(28,28)}
\texttt{discriminator.input\_shape=(28,28)}\\
\texttt{discriminator.output\_shape=(1,)}
training discriminator
"""每次處理幾筆資料:"""
batch_size=32
"""生成batch_size個隨機的seed:"""
seed=np.random.normal(size=(batch_size,128))
"""訓練結合的網路:"""
train_gen.train_on_batch(seed,np.ones((batch_size,)))training generator
IN=Input((128,))
IMG=generator(IN)
discriminator.trainable=False
OUT=discriminator(IMG)
train_gen=Model(IN,OUT)
train_gen.compile(loss='binary_crossentropy',optimizer='Adam')\(x_0\)
\(x_1\)
\(x_2\)
\(x_3\)
\(x_4\)
\(a_0\)
\(a_1\)
\(a_2\)
\(a_3\)
\(a_4\)
\(a_5\)
\(a_6\)
\(b_0\)
\(b_1\)
\(b_2\)
\(b_3\)
\(b_4\)
\(b_5\)
\(b_6\)
\(c_0\)
\(c_1\)
\(c_2\)
\(c_3\)
\(c_4\)
\(c_5\)
\(c_6\)
\(d_0\)
\(d_1\)
\(d_2\)
\(d_3\)
\(d_4\)
\(d_5\)
\(d_6\)
\(e_0\)
\(e_1\)
\(e_2\)
\(e_3\)
\(e_4\)
\(e_5\)
\(e_6\)
\(y_0\)
generator
discriminator (fixed)
seed
generated_img
\(P_{true}\)
generator目的:使用seed生成的圖片通過discriminator後,
\(P_{true}\) 可以增加 \(\Rightarrow \texttt{x=seed,y=1}\)
\(\texttt{train\_gen}\)
還需要完成的是...
- 建構 \(\texttt{generator}\)、\(\texttt{discriminator}\)
- \(\texttt{def get\_true\_img(batch\_size):}\)
- training process
from keras.datasets import mnist
(x1,y1),(x2,y2)=mnist.load_data()
"""取的所有標籤是0的圖片:"""
indices=[]
for i in range(len(y1)):
if y1[i]==0:
indices.append(i)
"""隨機出batch_size個indices,並回傳這些indices對應的圖片:"""
def get_true_img(bacth_size):
random_indices=np.random.randint(0,len(indices),size=(batch_size,))
return x1[random_indices]
"""
a=[0,1,4,9,16]
b=[4,2,1,0,1]
a[b]==[16,4,1,0,1]
"""\(\texttt{get\_true\_img():}\)
batch_size=32
epochs=50
"""預先設置好全0和全1的陣列:"""
true=np.ones(batch_size)
false=np.zeros(batch_size)
for epoch in range(epochs):
"""產生隨機的batch_size個種子:"""
seed=np.random.normal(size=(batch_size,))
"""根據seed生成圖片:"""
gen_img=generator.predict(seed)
"""取得batch_size張真實圖片:"""
true_img=get_true_img(batch_size)
"""訓練:"""
discriminator.train_on_batch(gen_img,false)
discriminator.train_on_batch(true_img,true)
train_gen.train_on_batch(seed,true)training process
import numpy as np
from keras.models import Model
from keras.layers import Input
from keras.optimizers import Adam
from keras.datasets import mnist
seed_shape=(128,)
img_shape=(28,28)
########################################################################
# building generator
########################################################################
# building discriminator
########################################################################
IN=Input((128,))
IMG=generator(IN)
discriminator.trainable=False
OUT=discriminator(IMG)
train_gen=Model(IN,OUT)
train_gen.compile(loss='binary_crossentropy',optimizer=Adam())
########################################################################
(x1,y1),(x2,y2)=mnist.load_data()
"""取的所有標籤是0的圖片:"""
indices=[]
for i in range(len(y1)):
if y1[i]==0:
indices.append(i)
"""隨機出batch_size個indices,並回傳這些indices對應的圖片:"""
def get_true_img(bacth_size):
random_indices=np.random.randint(0,len(indices),size=(batch_size,))
return x1[random_indices]
########################################################################
batch_size=32
epochs=1000
"""預先設置好全0和全1的陣列:"""
true=np.ones(batch_size)
false=np.zeros(batch_size)
for epoch in range(epochs):
"""產生隨機的batch_size個種子:"""
seed=np.random.normal(size=(batch_size,))
"""根據seed生成圖片:"""
gen_img=generator.predict(seed)
"""取得batch_size張真實圖片:"""
true_img=get_true_img(batch_size)
"""訓練:"""
discriminator.train_on_batch(gen_img,false)
discriminator.train_on_batch(true_img,true)
train_gen.train_on_batch(seed,true)建構generator和discriminator
discriminator
就像數字辨識一樣?
(1,)
(1,)
(400,)
(20,20,1)
(20,20,1)
(22,22,10)
(22,22,10)
(24,24,10)
(24,24,10)
(26,26,5)
(26,26,5)
(28,28,1)
Conv2D(1,(3,3))
Activation('relu')
Conv2D(10,(3,3))
Activation('relu')
Activation('relu')
Conv2D(10,(3,3))
Flatten()
Activation('sigmoid')
Dense(1)
Input(shape=(28,28,1))
Activation('relu')
Conv2D(5,(3,3))
generator ?
(128,)
(28,28)
Input(shape=(28,28,1))
Activation('tanh')
(28,28)
Reshape((28,28))
(784,)
Dense(28*28)
try try see !
怎麼知道效果好不好...?
def sample():
n,m=4,6
"""建立n*m格圖:"""
fig,ax=plt.subplots(n,m)
"""隨機n*m個seeds:"""
seed=np.random.normal(size=(n*m,)+seed_shape)
"""取得generator根據seeds生成的圖片:"""
img=generator.predict(seed).reshape((n,m)+img_shape)
"""畫圖:"""
for i in range(n):
for j in range(m):
ax[i][j].axis('off')
ax[i][j].imshow(img[i][j],cmap='binary_r')
plt.show()import numpy as np
from keras.optimizers import Adam
from keras.layers import Dense, Activation, Input, Dropout, Reshape, Conv2DTranspose, Activation, Conv2D, Flatten, LeakyReLU, BatchNormalization, UpSampling2D, ZeroPadding2D
from keras.models import Model, Sequential
from keras.datasets import mnist, fashion_mnist
import matplotlib.pyplot as plt
# https://github.com/eriklindernoren/Keras-GAN/blob/master/acgan/acgan.py
# ==================================================
img_shape=(28,28)
noise_shape=(128,)
opt=Adam(0.0002, 0.5)
rate=0.
act=LeakyReLU()
# ==================================================
gen_input=Input(shape=noise_shape)
x=Dense(7*7*64)(gen_input)
x=Dropout(rate)(x)
x=act(x)
x=Reshape(target_shape=(7,7,64))(x)
x=Conv2D(64,(3,3),padding='same')(x)
x=Dropout(rate)(x)
x=act(x)
x=UpSampling2D()(x)
x=Conv2D(32,(3,3),padding='same')(x)
x=Dropout(rate)(x)
x=act(x)
x=UpSampling2D()(x)
x=Conv2D(16,(3,3),padding='same')(x)
x=Dropout(rate)(x)
x=act(x)
x=Conv2D(1,(3,3),padding='same')(x)
x=Reshape(target_shape=img_shape)(x)
x=Activation('tanh')(x)
generator=Model(gen_input,x)
# generator.summary()
# ==================================================
dis_input=Input(shape=img_shape)
x=Reshape(target_shape=img_shape+(1,))(dis_input)
# img_shape+(1,) = (28,28)+(1,) = (28,28,1)
x=Conv2D(16,(3,3),padding='valid')(x)
x=Dropout(rate)(x)
x=act(x)
x=Conv2D(32,(3,3),padding='valid')(x)
x=Dropout(rate)(x)
x=act(x)
x=Conv2D(64,(3,3),padding='valid')(x)
x=Dropout(rate)(x)
x=act(x)
x=Conv2D(128,(3,3),padding='valid')(x)
x=Dropout(rate)(x)
x=act(x)
x=Flatten()(x)
x=Dense(1)(x)
x=Activation('sigmoid')(x)
discriminator=Model(dis_input,x)
# discriminator.summary()
# ==================================================
x=Input(shape=img_shape)
y=discriminator(x)
dis_train=Model(x,y)
dis_train.compile(loss='binary_crossentropy',optimizer=opt)
# dis_train.summary()
discriminator.trainable=False
x=Input(shape=noise_shape)
y=generator(x)
y=discriminator(y)
gen_train=Model(x,y)
gen_train.compile(loss='binary_crossentropy',optimizer=opt)
# gen_train.summary()
# ==================================================
def sample():
n,m=4,6
fig,ax=plt.subplots(n,m)
noise=np.random.normal(size=(n*m,)+noise_shape)
img=generator.predict(noise).reshape((n,m)+img_shape)
for i in range(n):
for j in range(m):
ax[i][j].axis('off')
# img[i][j]=(img[i][j]+0.5).astype('int32')
ax[i][j].imshow(img[i][j],cmap='binary_r')
plt.show()
# ==================================================
(x1,y1),(x2,y2)=mnist.load_data()
x1=x1/255
x2=x2/255
# x_train=x1
indices=[i for i in range(len(y1)) if y1[i]==8]
x_train=x1[indices]
batch_size=32
epochs=3000
# ==================================================
true=np.ones((batch_size,))
false=np.zeros((batch_size,))
for epoch in range(1,epochs+1):
indices=np.random.randint(0,len(x_train),size=(batch_size,))
true_img=x_train[indices]
noise=np.random.normal(size=(batch_size,)+noise_shape)
# true_img=[]
# for i in indices:
# true_img.append(x_train[i])
gen_img=generator.predict(noise)
gen_train.train_on_batch(noise,true)
dis_train.train_on_batch(true_img,true)
dis_train.train_on_batch(gen_img,false)
if epoch%200==0:
print('%5d/%5d'%(epoch,epochs))
sample()2020寒訓
By thomaswang2003




