KIMONO
SCRAPING THE WEB
SCRAPING PRIMER
WEB CRAWLING
WEB SCRAPING
The process of processing a web document and extracting information out of it.
the process of iteratively finding and fetching web links starting from a list of seed URL's
ETHICS OF SCRAPING
There is absolutely no technical difference between an automated computer viewing a website and a human-driven computer viewing a website."
ETHICAL CHALLENGES
-
Affecting the experience of others by hitting the server too hard
-
Certain uses of data may be copyright violations
- Breaking ToS is not illegal, but it may be considered a breach of contract
CREATE A SCRAPER
STEP ONE
DONT CREATE A SCRAPER
... if copy/paste is faster
DONT CREATE A SCRAPER
... if there is an API
OK, CREATE A SCRAPER
with Kimono, a web-based scraping tool
... but only if
-
The source you are scraping is somewhat clearly structured, and cleanly coded
- The content needs to be static, instead of dynamically generated with JavaScript, no AJAX calls
-
You don't mind your work being public to all
- You don't have complicated auth requirements
- You don't mind the reliance on a third-party service
#builtwithkimono
API SETUP

START PAGE
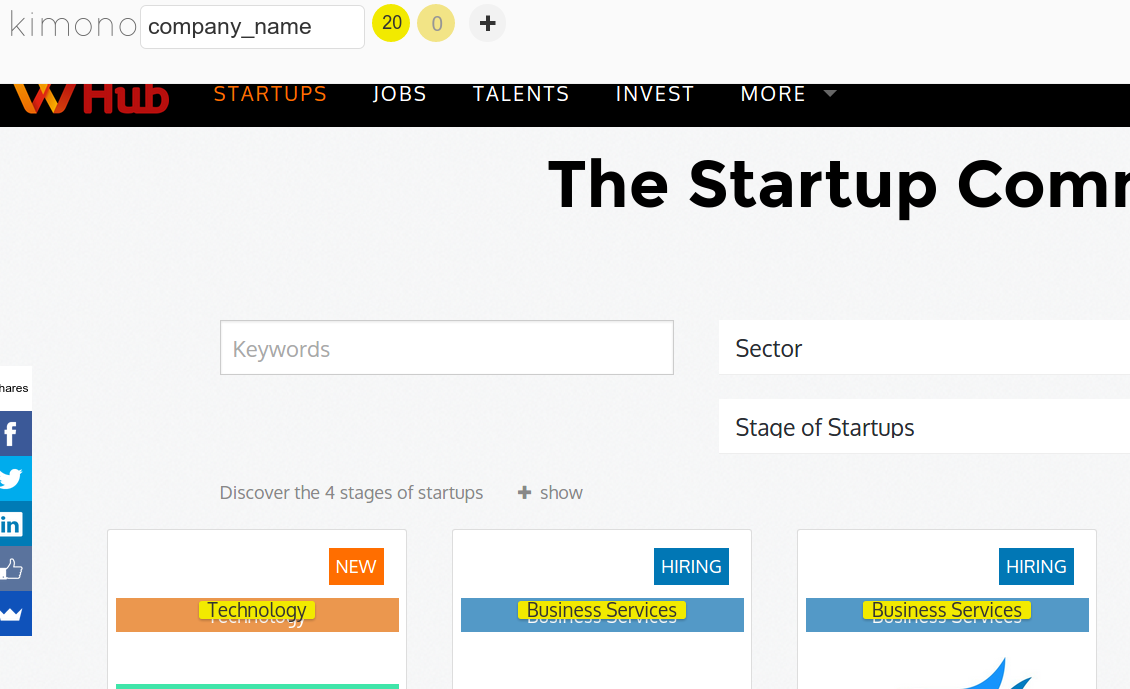
RECOGNISE SIMILAR DATA
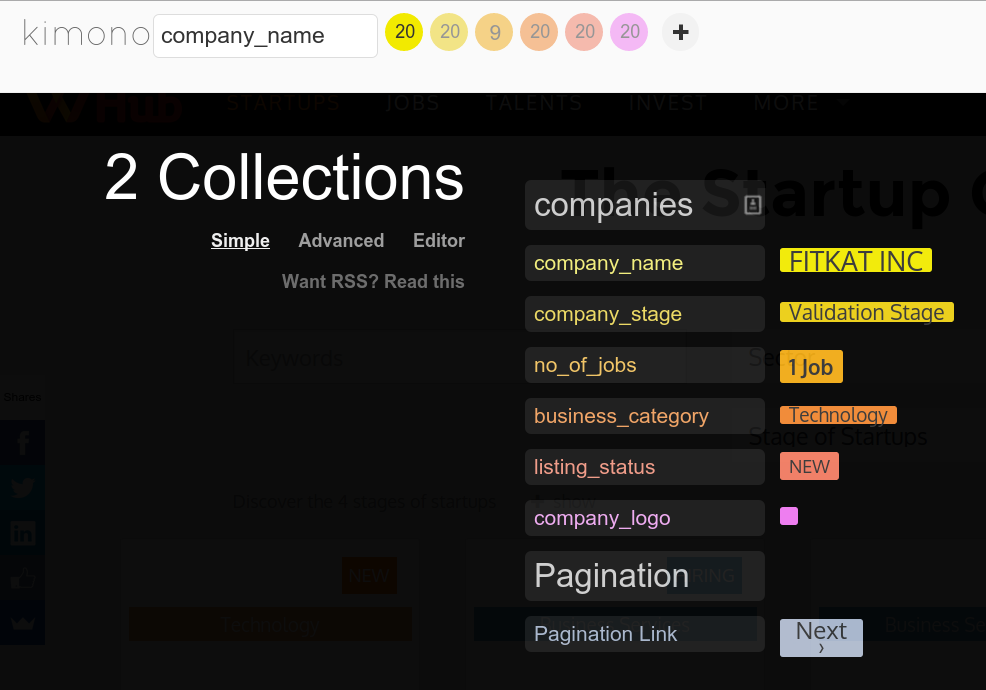
STRUCTURED DATA
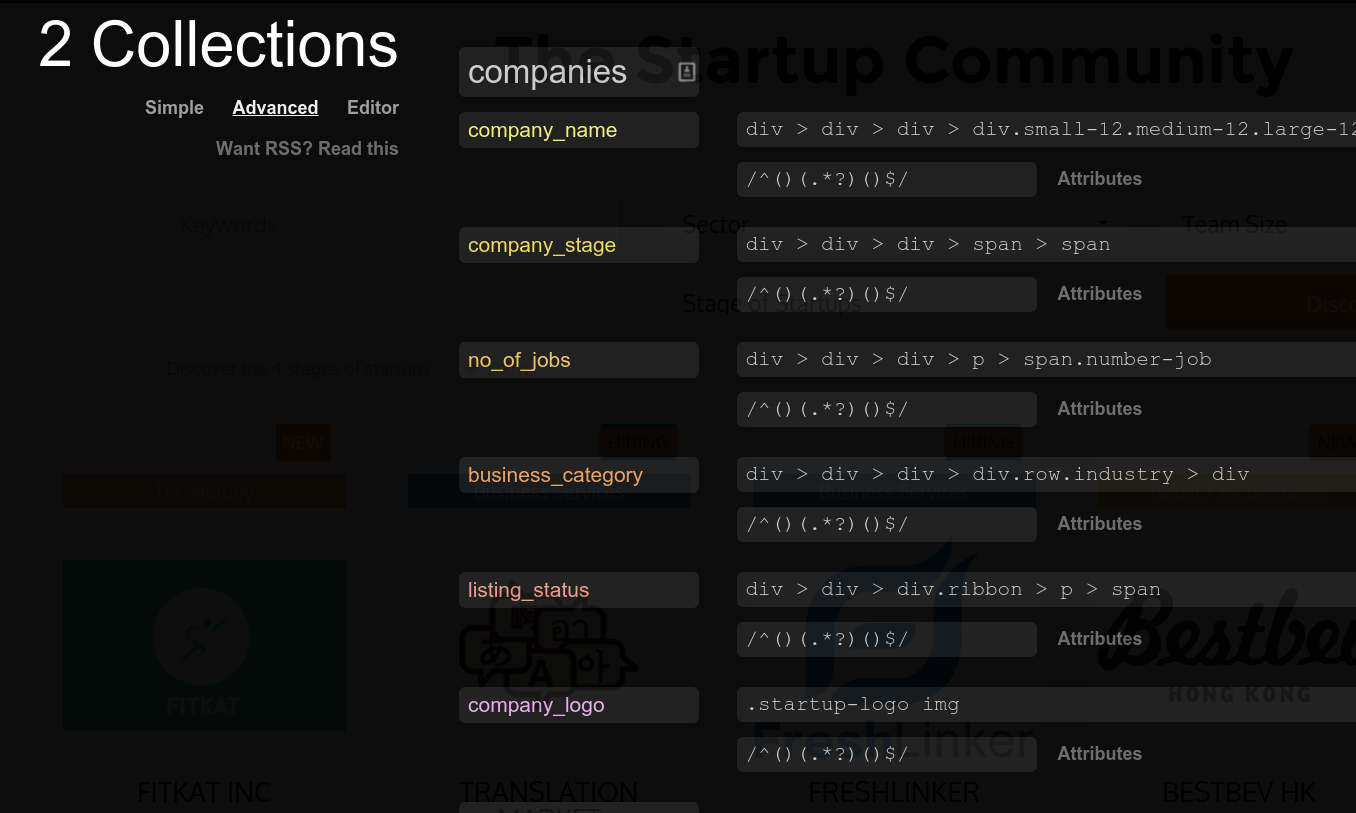
MANUALLY CORRECT IF NEEDED
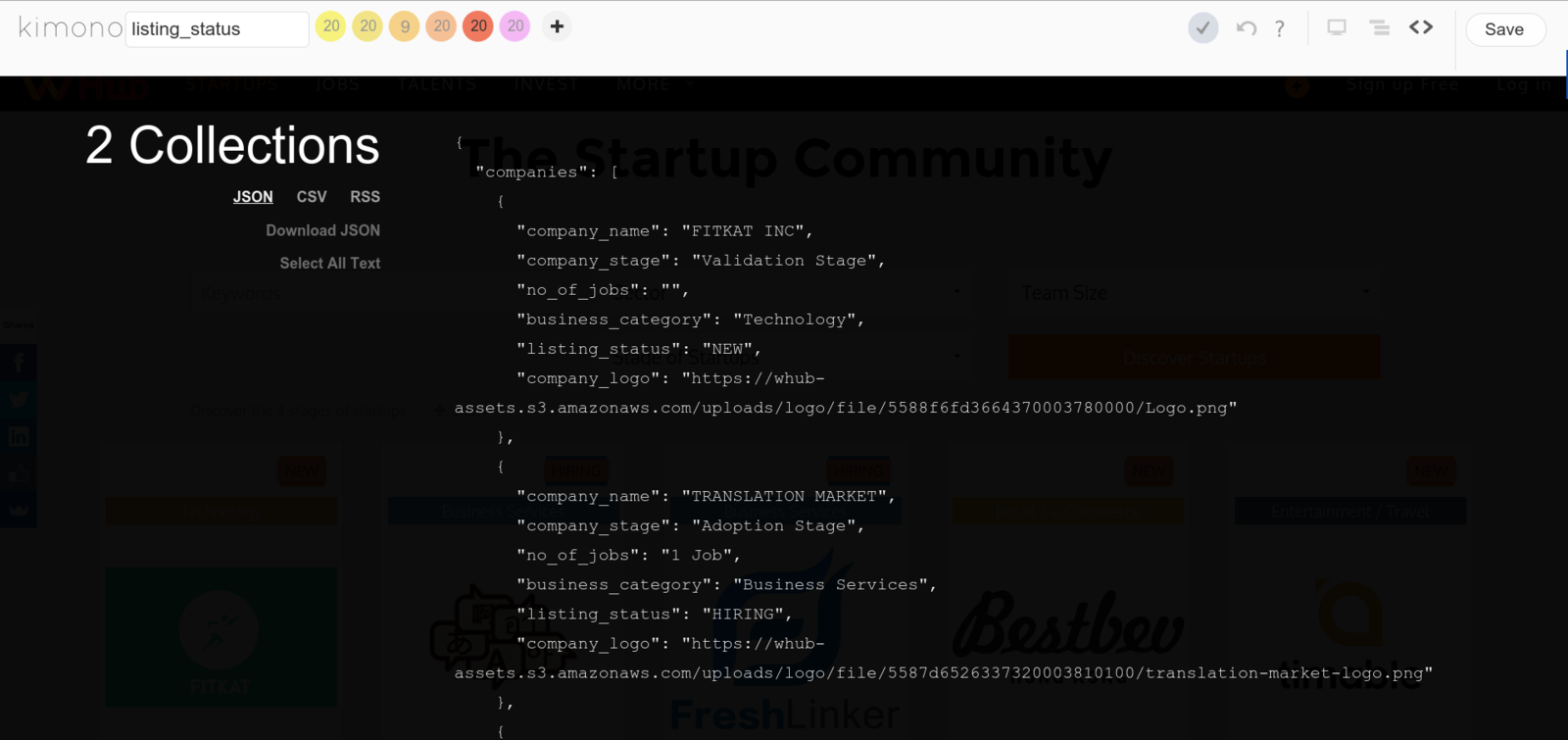
PREVIEW API END POINT
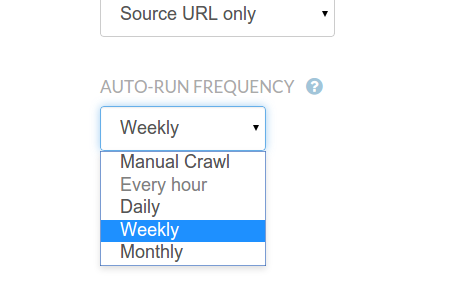
SET A SCHEDULE
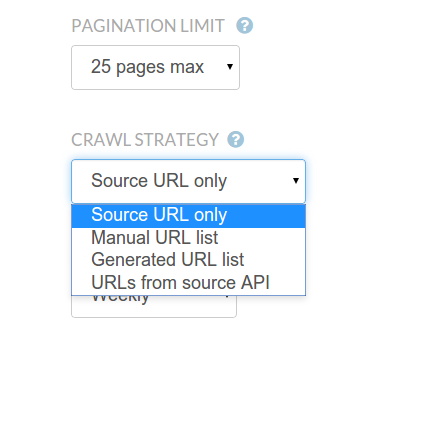
SET A CRAWL STRATEGY
USE YOUR API
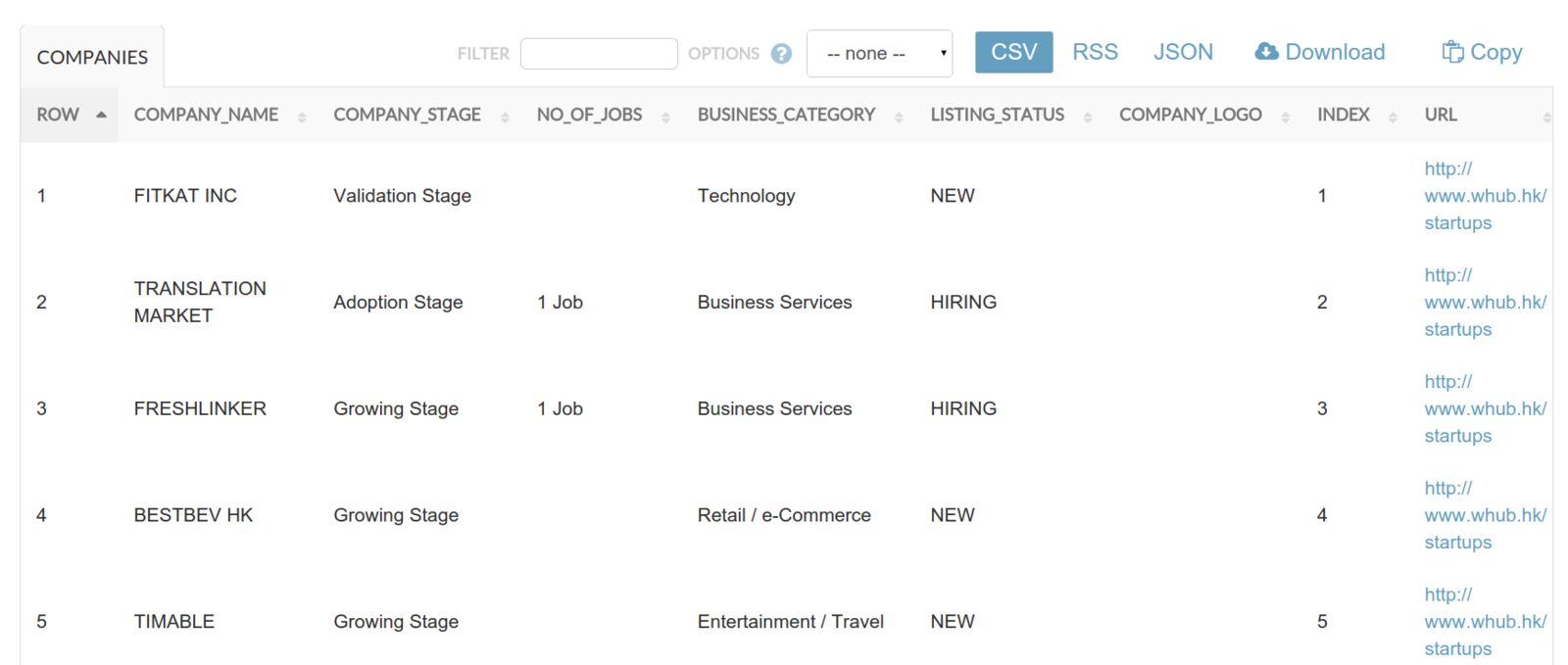
ACCESS AS JSON / CSV / RSS
SYNC WITH A GOOGLE SHEET
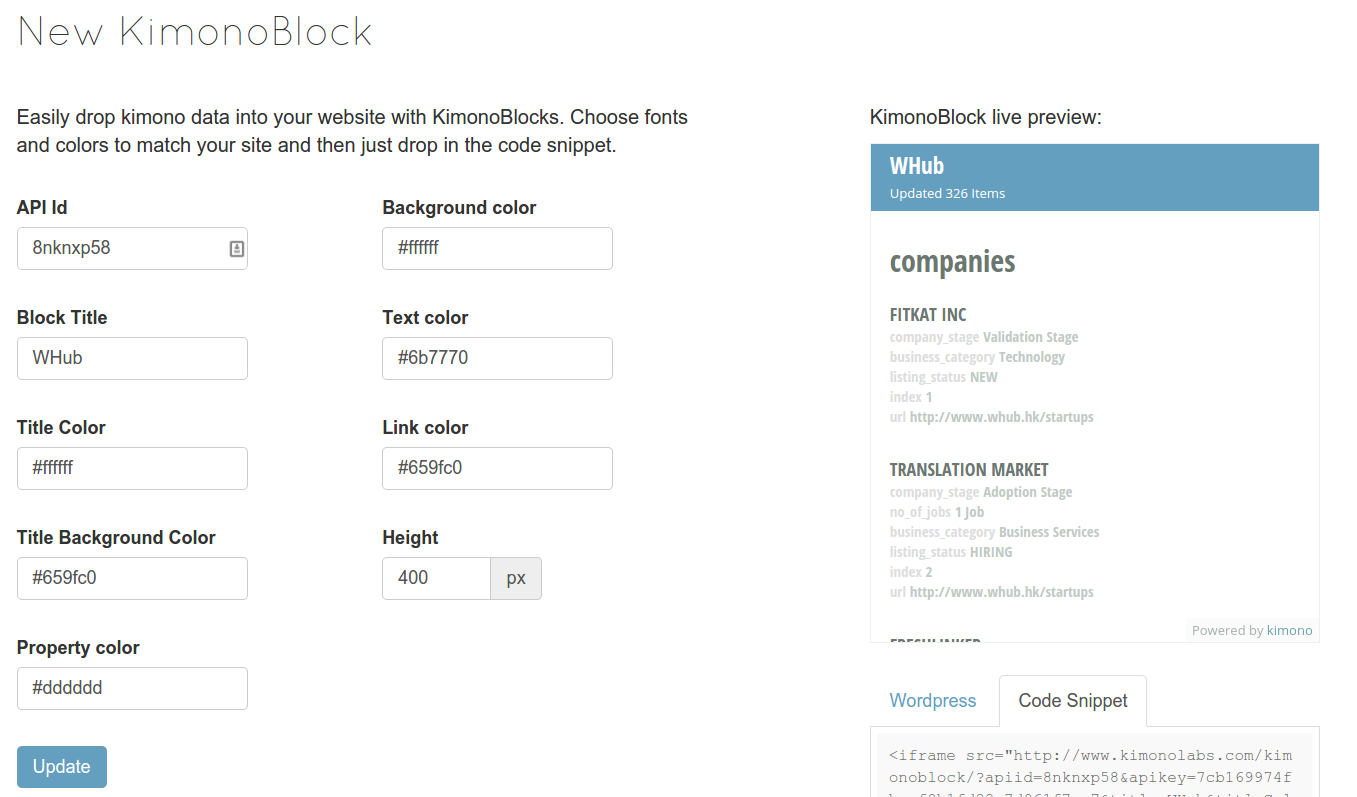
ADD A WIDGET TO YOUR SITE
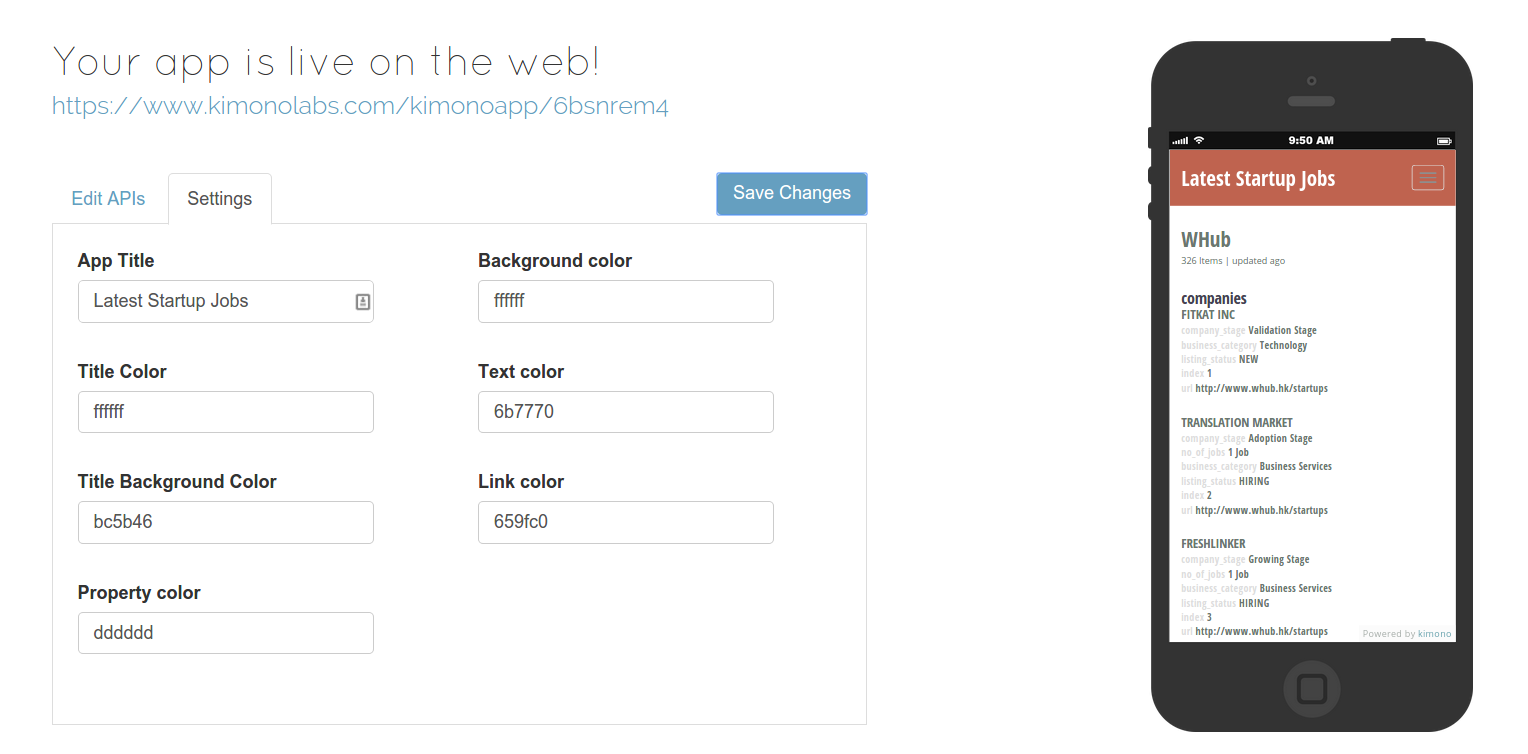
DISTRIBUTE AS AN APP
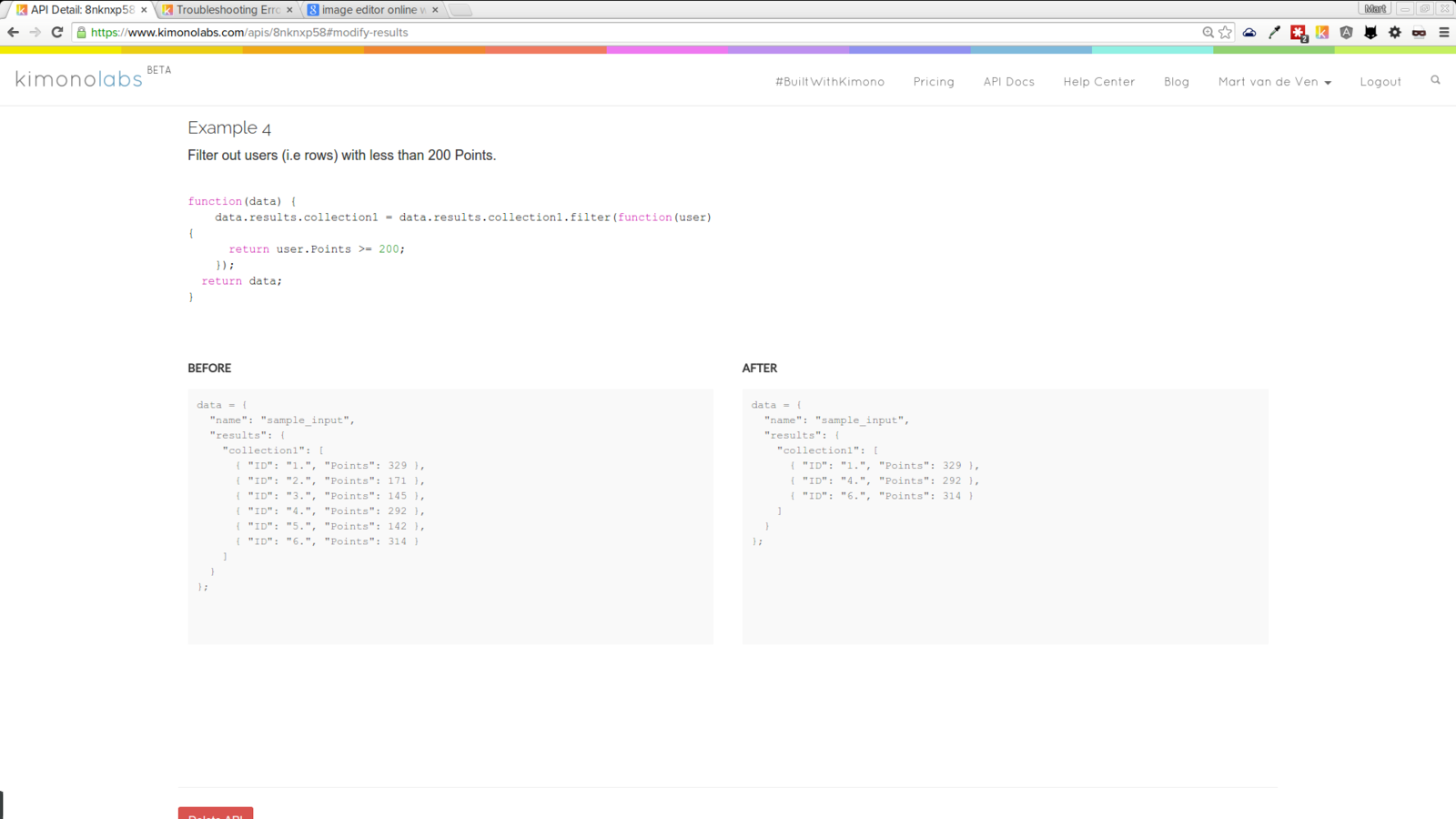
TRANSFORM THE DATA
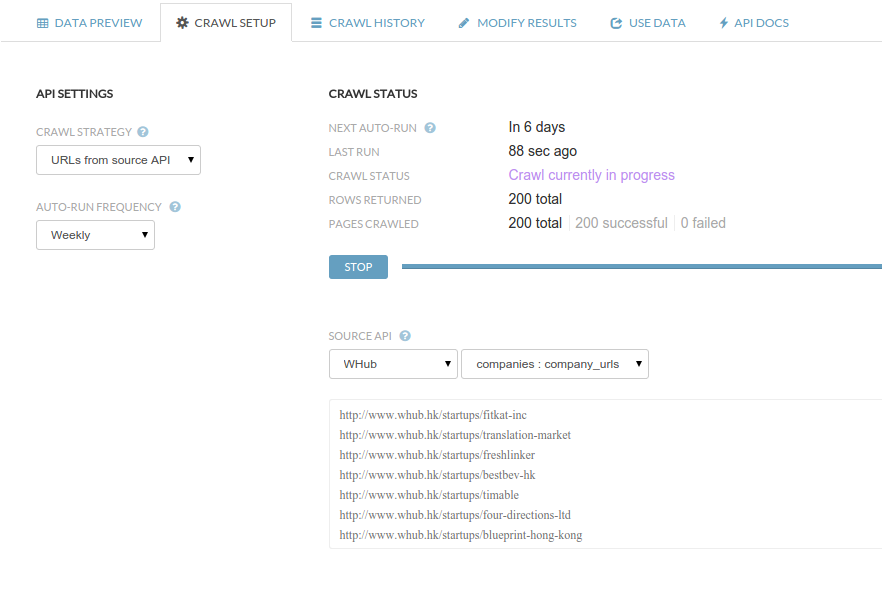
GET SEED URLS FOR 2ND SCRAPER
DEMO
FREE TIER
- Crawl up to 10,000 with a single API
- Access your data in standard formats JSON/CSV/RSS
- Email alerts and webhooks
- Access to the past 30 days of historic data
- Integrations with google sheets and wordpress
BUSINESS TIER
- Probably not for you, but offers
- Private APIs
- Auth support (currently in Beta and also available for free)
- Change Detection
- Outsourced API creation and maintainance
PRICING
m@type.hk
mart van de ven
TALK BY
@tijptjik
Kimono - Scraping the Web
By Mart van de Ven
Kimono - Scraping the Web
Guide to Kimono, a Visual Web Scraper




