
DATA SCIENCE
natural language processing
WHAT IS NATURAL
LANGUAGE PROCESSING
The interface between human and computer language
Consider lexical ambiguity resolution:
The selection of one of multiple possible meanings of a phrase.
Humans are great at this.
Computers are not.
How do we teach computers to understand human language?
How do we discern the meaning of sea in the following sentences?
“The driftwood floated in from the sea.”
“My cousin is dealing with a sea of troubles.”
Large body of water:
“The driftwood floated in from the sea.”
Figurative large quantity:
“My cousin is dealing with a sea of troubles.”
You can make rules-based models.
But these are fragile.
Language isn’t static.
Semantic models perform very well, but are slow.
Statistical models with the right features can carry us really far.
NLP APPLICATIONS
Take two minutes and jot down any common, real-world examples of
NLP that you can think of.
Find your 2 nearest neighbors and see if you can come up with more.
What did you come up with?
Let’s run down some common, well-known tasks.
Speech Recognition
“Hello, HAL. Do you read me? Do you read me, HAL?”
“Affirmative, Dave. I read you.”
The best speech recognition sostware incorporate language models
along with the audio signal.
Machine Translation
Google Translate.
Are there even any competitors?
They’re able to incorporate trillions of words into their language models
and elicit user feedback on results.
Question Answering
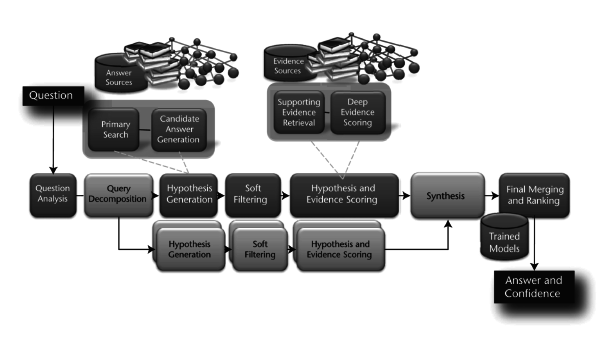
Most applications are less visible.
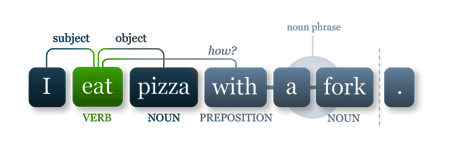
Part of Speech Tagging/Parse trees
Aids in many other NLP tasks
e.g. Named Entity Recognition
Topic Modeling
Finding latent groupings of documents based on the words therein.
Different topics generate words at particular frequencies, so you can work backwards from the words in a document to the topics.
Useful for news aggregators, or segmenting a proprietary corpus.
Sentiment Analysis
Determining the emotional content of a document.
Most often applied to tweets with marketing implications.
Many approaches proposed.
At this point, you may be imagining some uses of NLP in your own work.
BASIC NLP PRACTICE
First order of business:
Split text into sentences or words.
If you want to parse sentences, it helps to have sentences.
Relatively easy for English.
Sentences end with periods, words are separated by spaces.
There are some oddballs, though.
“Dr. Oz promised me magic weight-loss pills; they didn’t work.”
“omg the food was so gross the portions were tiny ill never go back”
Challenge A
challenge_a.ipynb
segmentation
We went over easier examples, but you can imagine difficulties in other
languages.
Luckily, statistical models can tolerate some level of messy data.
Second order of business:
normalize word forms
LinkedIn sees 6,000+ variations on the job title, “Software Engineer”
They see 8,000+ variations on the company, “IBM”
They have to recognize all of these and understand they are the same.
On a smaller scale, it is often useful to strip away conjugations and
other modifiers.
This is called stemming.
science, scientist => scien
swim, swimming, swimmer => swim
The resulting text is unreadable, but retains semantic content.
Challenge B
challenge_b.ipynb
stemming
The classic, standard English stemmer is the Porter stemmer.
Stemming is very useful to reduce feature set size.
It can sometimes degrade performance.
Why?
Some words are so very common that they provide no information to a statistical language model.
We should remove these stop words.
Note: different languages have different stop words, and they may have meaning in other languages.
Aside from looking up a list, how can you find stop words?
Term frequency
N_{term}/N_{terms\ in\ document}
N_{documents\ containing\ term}/N_{documents}
Document frequency
Stop words will have a high document frequency
What about highly discriminative words?
tf-idf
(N_{term}/N_{terms\ in\ document}) * log(N_{documents\ containing\ term}/N_{documents})
Largest for words that occur more frequently in a document, but occur in fewer documents overall.
term frequency-inverse document frequency
Challenge C
challenge_c.ipynb
stop words/tf-idf
Stop word removal and tf-idf weighting are reliable ways to improve many natural language models.
Let’s finally do something interesting.
There’s gold in them thar sentiment analysis hills!
Marketers want to know whether their audience’s engagement with
their brand is positive or negative in nature.
Some say the stock market fluctuates with the mood on Twitter.
Challenge D
challenge_d.ipynb
sentiment classifier
Finding training data is really hard.
Humans are good at handling ambiguity, but that’s not the same as being accurate.
Miscommunication happens all the time
Natural Language Processing comprises many, very hard problems.
Most are outside the scope of the course, but hopefully you have an idea of what questions to ask if you encounter an NLP problem.
References
- How to build your own 'Watson'
- Introduction to Topic Models
- LDA (Popular Topic Model)
- Gemsim
- Stanford Sentiment Analysis
Resources
Natural Language Processing
By Mart van de Ven




