


Tomas Delvechio
Student, PHP and Python Developer. Newbie on Hadoop env.
Son procesos, herramientas y técnicas que tienen por objetivo el tratamiento de volúmenes de información de fuentes diversas que no es viable procesar en dispositivos individuales en tiempos adecuados para los procesos de las organizaciones.
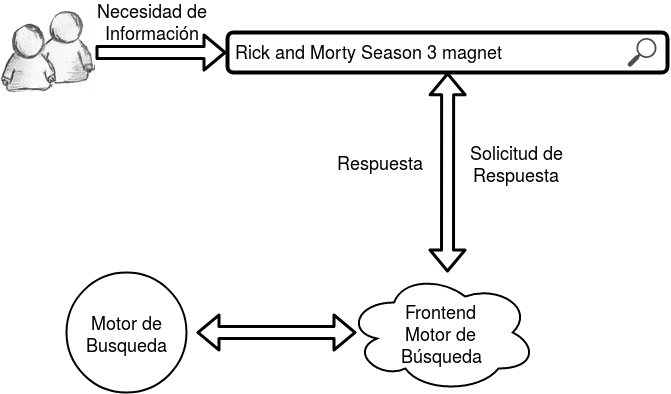
Técnicas de resolución de necesidades de información sobre colecciones de documentos sin estructura
Cluster
Procesamiento Distribuido
Indice Invertido / Posting List
Commodity Hardware (siguiente slide)
Colección de documentos
Escalabilidad vertical y horizontal
By Tomas Delvechio
Una introducción a los problemas de big data en un contexto de recursos limitados




