Training Spiking Neural Networks Using Backpropagation
Kaito Kishi
岡研究室(生命情報学科)
2018-03-29 @機械学習交流会
ニューラルネットワーク (NN) は脳神経系をモデル化したものである
間違ってはいない
だが
従来の NN は McCulloch-Pitts Model を基にしている
McCulloch-Pitts Model
y=f(u)
u=\sum^n_{i=1}w_ix_i-\theta
f(u)=
{
0\ (u\leq0)
1\ (u>0)
この伝達関数を微分可能な非線形関数に変えて,複数ニューロンからなる層を重ねたものがよく知られる NN
つまり,今の NN は膜電位上昇によるスパイク発火表現を捨てている
生物学的に妥当なニューロンモデル
Integrate-and-fire
I(t)=C_m \frac{dV_m(t)}{dt}
膜電位が徐々に上昇し,閾値に達したら発火する.このときに膜電位の値はリセットされる
V_m^+(t)-=V_{th}
Leaky Integrate-and-fire (LIF)
I(t)-\frac{V_m}{R_m}=C_m \frac{dV_m(t)}{dt}
Integrate-and-fire で膜電位の漏れを考慮したもの
V_m^+(t)-=V_{th}
これを NN に組み込む
Spiking Neural Network (SNN)
しかし,問題は山積
・どうやって入力する?
・何をもって出力結果とする?
・どうやって学習する?
などなど...
Training Deep Spiking Neural Networks Using Backpropagation
そこで,SNN の教師あり学習の手法を考案したのが,今回紹介する
概要
・
・
・
・
・
・
・
・
・
・
・
・
・
・
・
入力値は常に発火
入力を受けて膜電位が上昇し,閾値を超えたら発火
出力層のうち,スパイク数の最も多いものを出力値と定める
順伝播の膜電位
x_k(t)=\sum_p \exp{\left(\frac{t_p-t}{\tau_{mp}}\right)}
a_i(t)=\sum_q \exp{\left(\frac{t_q-t}{\tau_{mp}}\right)}
V_{mp,i}(t)=\sum_{k=1}^m w_{ik}x_k(t)-V_{th,i}a_i(t)
順伝播の膜電位
x_k(t)=\sum_p \exp{\left(\frac{t_p-t}{\tau_{mp}}\right)}
a_i(t)=\sum_q \exp{\left(\frac{t_q-t}{\tau_{mp}}\right)}
V_{mp,i}(t)=\sum_{k=1}^m w_{ik}x_k(t)-V_{th,i}a_i(t)
入力履歴.より直近でより多い方が発火する
出力履歴.発火した直後は発火しづらくなる
逆伝播
L=\frac{1}{2}||\textbf{o}-\textbf{y}||^2+\sum_{l\in hidden}\sum_iL_w(l,i)
\delta_i^{(L)}=\frac{\partial L}{\partial o_i}=o_i-y_i
誤差関数
正則化の項
o_i=\frac{\#spike_i}{\max_j{(\#spike_j)}}
ただし,
ゆえに,
スパイク数
逆伝播
\delta_i^{(l)}=\frac{g_i^{(l)}}{\overline{g}^{(l)}}\sqrt{\frac{M^{(l+1)}}{m^{(l+1)}}}\sum_j^{n^{(l+1)}}w_{ji}^{(l+1)}\delta_j^{(l+1)}
g_i^{(l)}=\frac{1}{V_{th,i}}
\overline{g}^{(l)}=\sqrt{E\left[\left(g_i^{(l)}\right)^2\right]}
M^{(l+1)}
は層
l
におけるニューロン数
m^{(l+1)}
はそのうちアクティブなニューロン数
ただし,
逆伝播
\Delta w_{ij}^{(l)}=-\eta_w\sqrt{\frac{M^{(l+1)}}{m^{(l)}}}\delta_i^{(l)}x_j^{(l)}
\Delta V_{th}^{(l)}=-\eta_{th}\sqrt{\frac{M^{(l+1)}}{m^{(l)}M^{(l)}}}\delta_i^{(l)}\gamma a_i^{(l)}
結果 (2 層でMNIST)
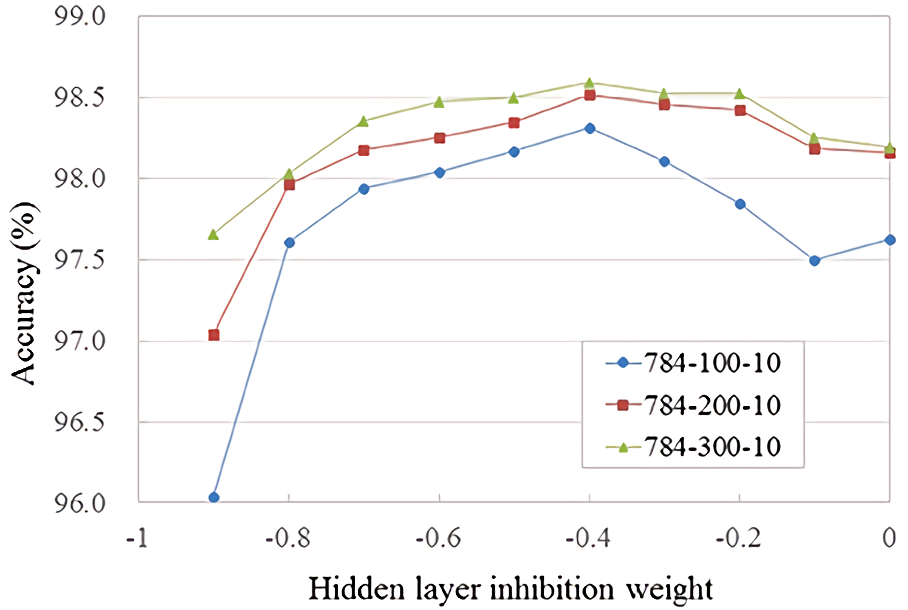
2 層の SNN では今までの 98.64% を抜き,トップ(98.88%)
※NN では Goodfellow の 99.06%
結果 (CNN で MNIST)
99.31%
SNN のトップは 99.42% なので,負けてはいるものの,これは 64 のアンサンブル結果なので,単体だったら,92.70% であったので勝ち
従来の SNN との違い
従来の SNN は普通の NN で学習させて,これを SNN に変換していた
それに対して,直接スパイク情報から学習できるようにした
補足:SNN は今までの NN と同様に任意の関数を近似可能
まとめ
- SNN であっても出力値に意味づけをして,これと誤差をとることで従来の NN と同じように誤差逆伝播をすることができる.
- 従来の NN と同様に ADAM などが有効に働いた.
従来の NN の資産を有効に活用して,SNN が適している問題を解くことができるのではないだろうか
SNN が適している問題
補足:生物学的妥当性
今回は個人的に教師ありの SNN がほしかったので,誤差逆伝播を用いる論文を紹介したが,脳では STDP を用いているので脳を再現したいならば,そちらをあたるべきと思われる.個人的に今気になっている論文は,
STDP-based spiking deep convolutional neural networks for object recognition
補足:WTA circuits
V_{mp,i}(t)=\sum_{k=1}^m w_{ik}x_k(t)-V_{th,i}a_i(t)
+\sigma V_{th,i}\sum_{j=1,j\ne i}^n \kappa_{ij}a_j(t)
(-1\le\kappa\le0)
発火すると,その周りのニューロンを抑制する.
→ 出力を際だたせるのに効いていそう
補足:Regularizations
L_w(l,i)=\frac{1}{2}\lambda\exp{\left(\beta\left(\sum_j^{M^{(l)}}\left(w_{ij}^{(l)}\right)^2-1\right)\right)}
これで重みを一定範囲内に収めようとしている
閾値については,訓練時の順伝播中に徐々に小さくするというもの
これらの正則化により,安定した精度を出せていた
実装してみた
Spiking MoYF
- MNIST のうち,0, 1, 2 は何とか学習できた.全体については GPU がないと無理そう
- 重みの正則化はどうしても発散してしまい実装できなかった
- 閾値は変化させていない
- STDP はまた今度やる
今の state-of-the-art
(多分)既に奪われてた...
twitter: @TRSasasusu
deck
By trsasasusu



