Learning mid-level representations for computer vision
Stavros Tsogkas

Short introduction
Diploma: Electronic and Computer Engineering
Ph.D.: Mid-level representations for modelling objects
Postdoctoral fellow
Deep learning success stories
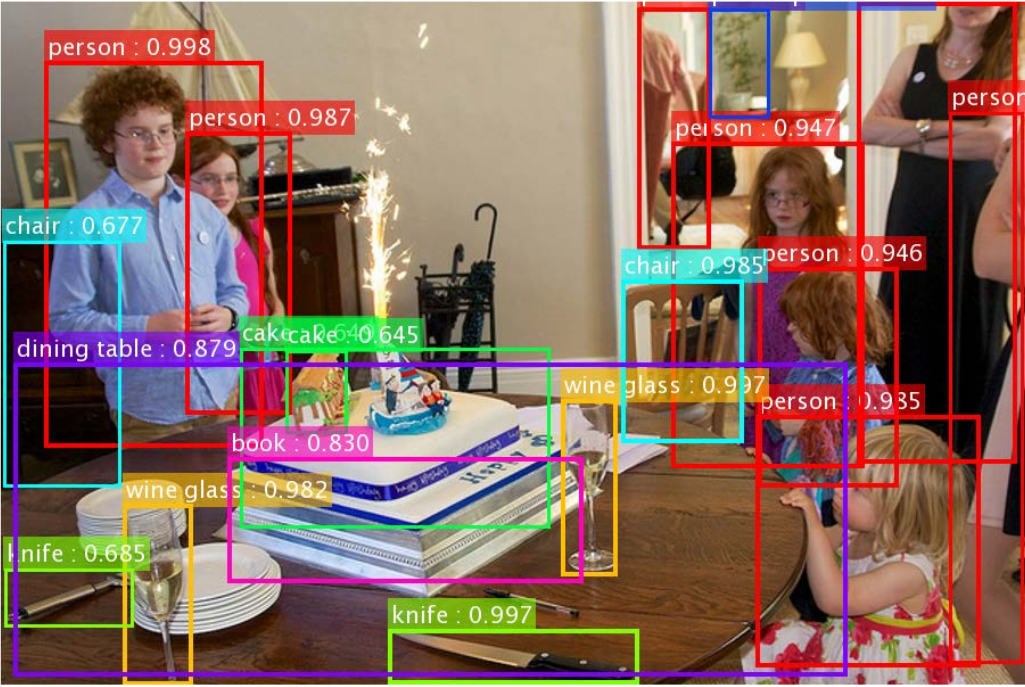
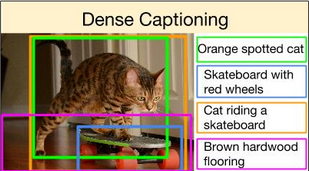
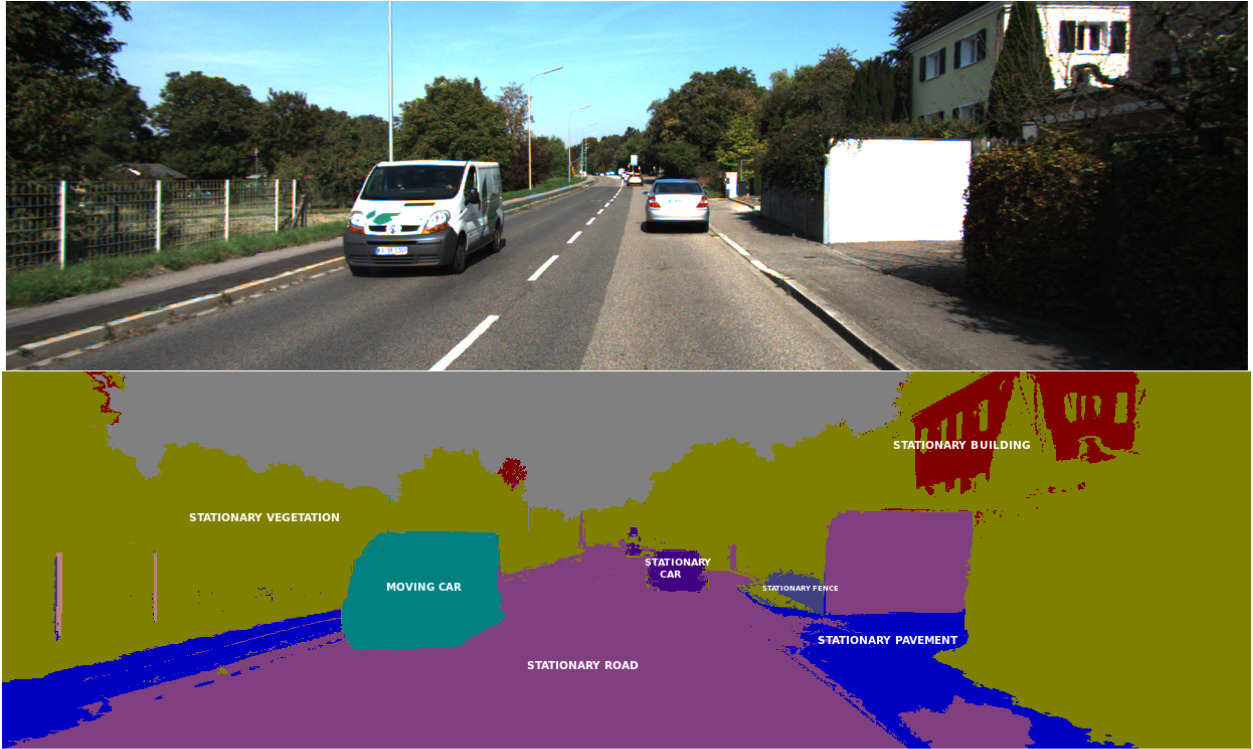
Image captioning
Semantic segmentation
Edge detection
Object detection
But CNNs can be easily fooled...


+\epsilon
=
noise
"gibbon"
99.3% confidence
"panda"
57.7% confidence
...and do not generalize well

Correctly classified
Incorrectly classified
Original images
Negative images
CNNs favour appearance over shape

Zebra or an elephant with stripes?
People learn general rules instead

What makes a table, a table?
flat surface
vertical support


Constellation table by Fulo
What are mid-level representations?

Low-level: Edges
- class agnostic
- not discriminative

High-level: person segmentation
- class specific
- not generalizable
Mid-level:
-
discriminative and robust
-
shareable across object categories
-
simpler to model, scalable
Mid-level representations include






textures
object parts
symmetries



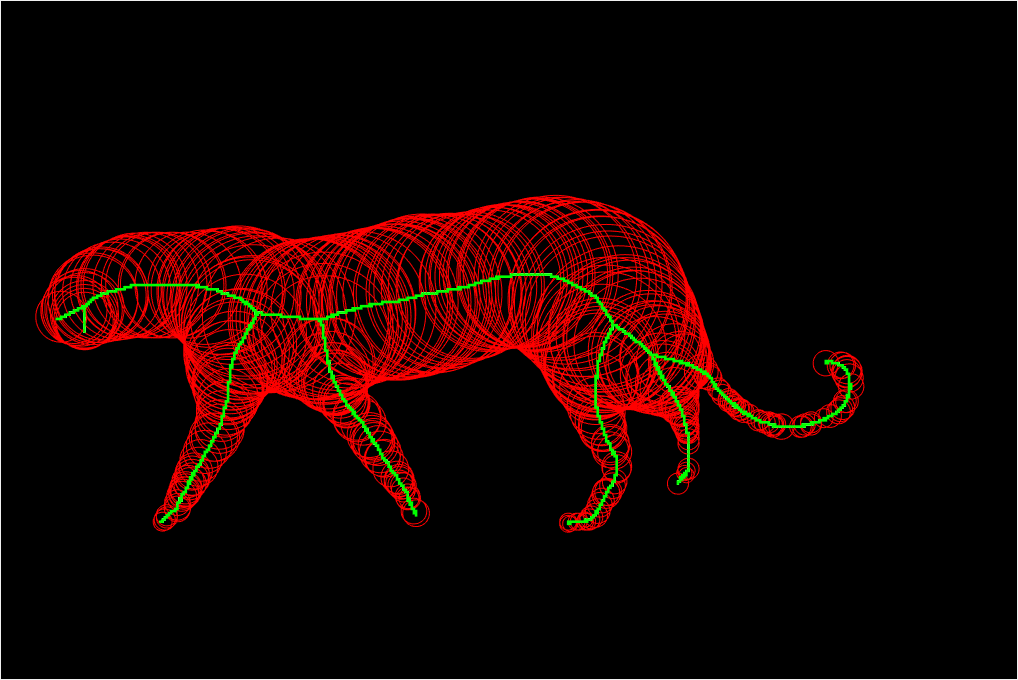
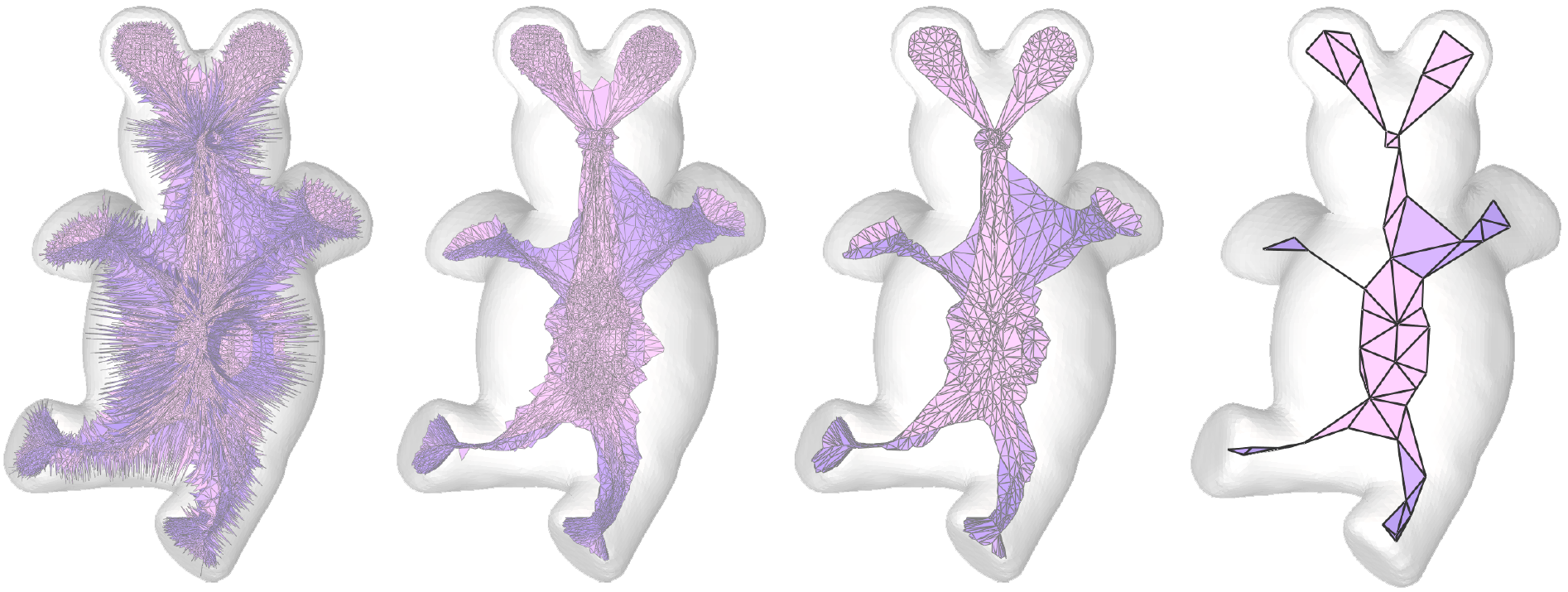
Medial axis detection
Symmetry is everywhere




Global symmetry is unstable


But local symmetry is more robust
Medial Axis Transform (MAT)

Medial Axis Transform (MAT)
MAT applications

Shape matching and recognition
Shape simplification
Shape deformation with volume preservation
MAT for natural images is not obvious





So let's learn it from data!



Image from BSDS300
Ground-truth segmentation
Ground-truth skeleton
Medial point detection: binary classification problem
Dense feature extraction

Multiple scales
Multiple orientations
\theta_1
\theta_2
\theta_3
Computing symmetry probabilities










Orientation
Scale
Symmetry probability
Non-maximum suppression
MAT should be invertible

MAT^{-1}
MAT^{-1}
Generative definition of medial disks



\mathbf{p}_i
r_i
\mathbf{p}_j
r_j
- f: summarizes patch (encoding)
- g: reconstructs patch (decoding)
f
g
D^I_{\mathbf{p}_i,r_i}
D^I_{\mathbf{p}_j,r_j}
\tilde{D}^I_{\mathbf{p}_j,r_j}
\tilde{D}^I_{\mathbf{p}_i,r_i}
[\bar{R}_i,\bar{G}_i,\bar{B}_i]
[\bar{R}_j,\bar{G}_j,\bar{B}_j]
e(
)\approx 0
,
,
e(
) \gg 0
AppearanceMAT definition
...
for all p,r
\text{Objective: } \min_{\mathbf{p},r} \sum_{i=1}^m e_{\mathbf{p}_i,r_i}
g \circ f \circ D
\text{Constraint: } I=\bigcup_{i=1}^m D^I_{\mathbf{p}_i,r_i}
AMAT Demo
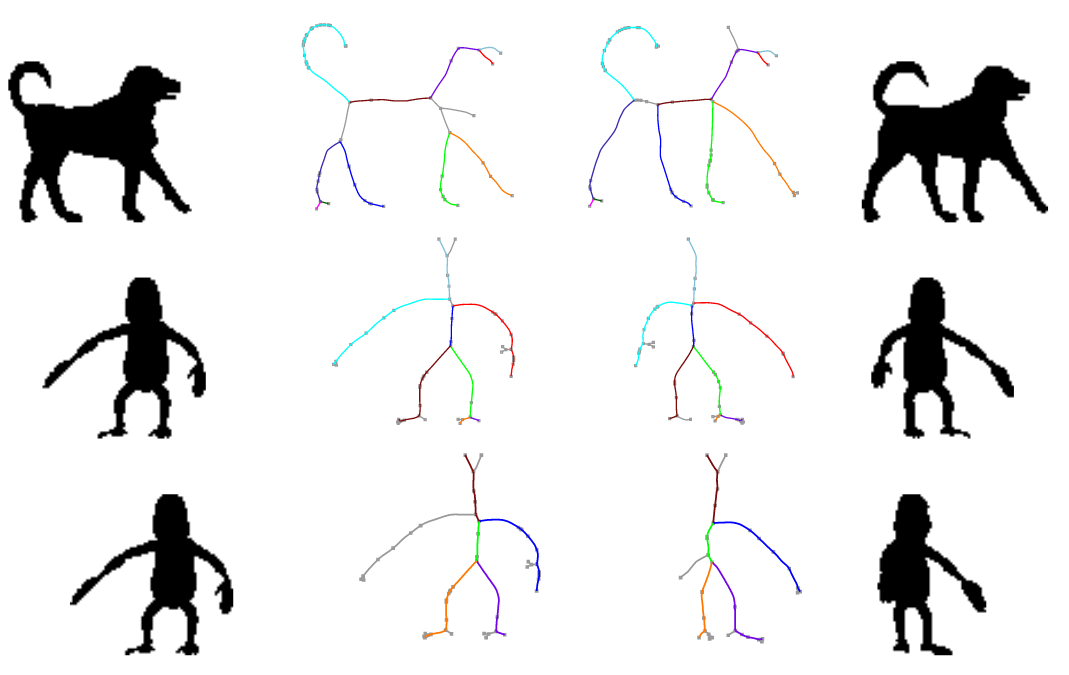
Grouping points together...



- space proximity
- smooth scale variation
- color similarity
color similarity
Input
AMAT
Groups
(color coded)
...opens up possibilities

Thinning
Segmentation
Object proposals
and more...
Qualitative results

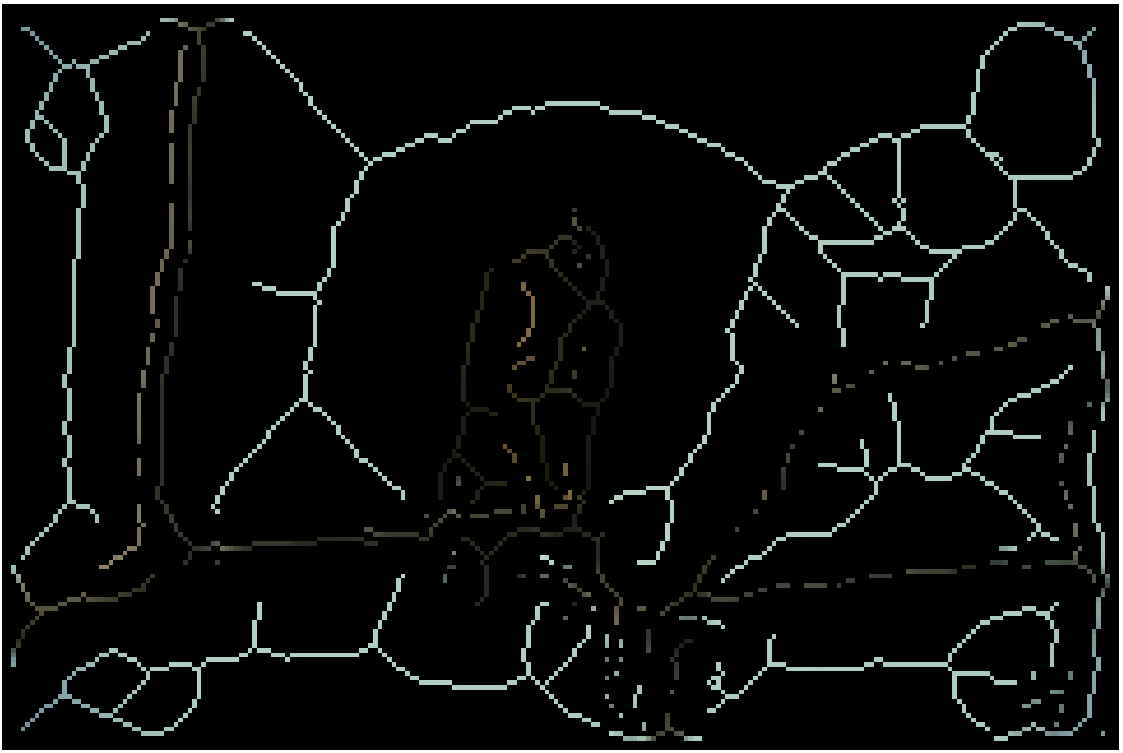
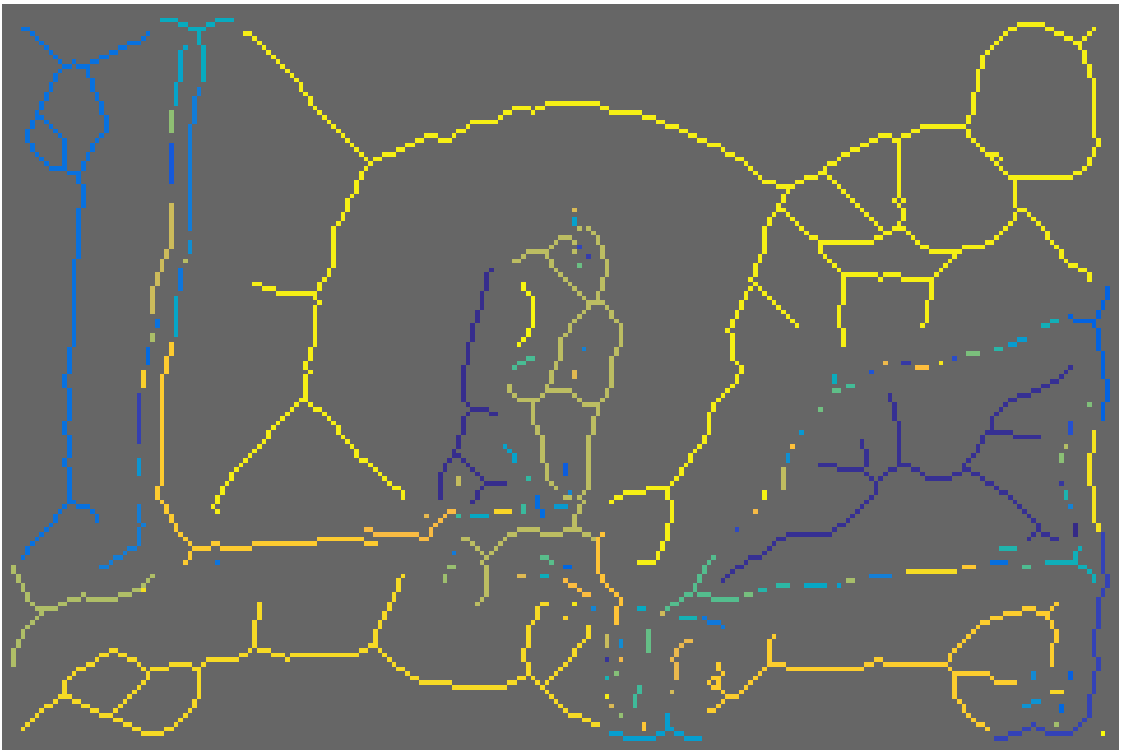






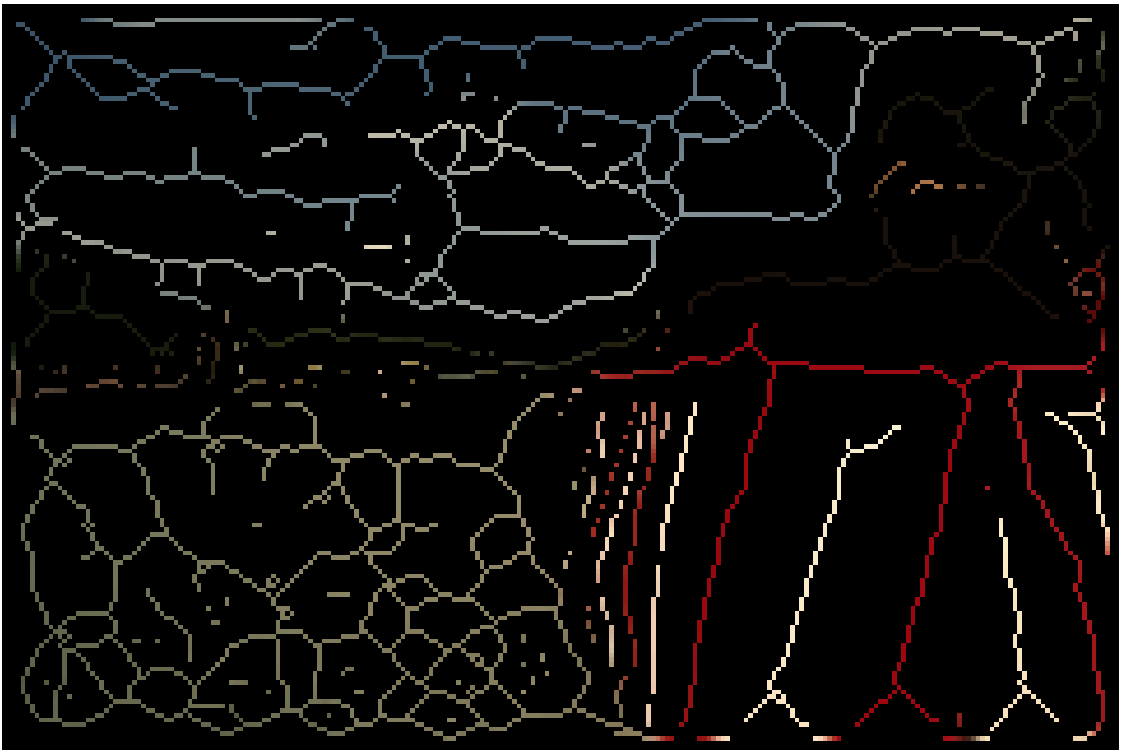
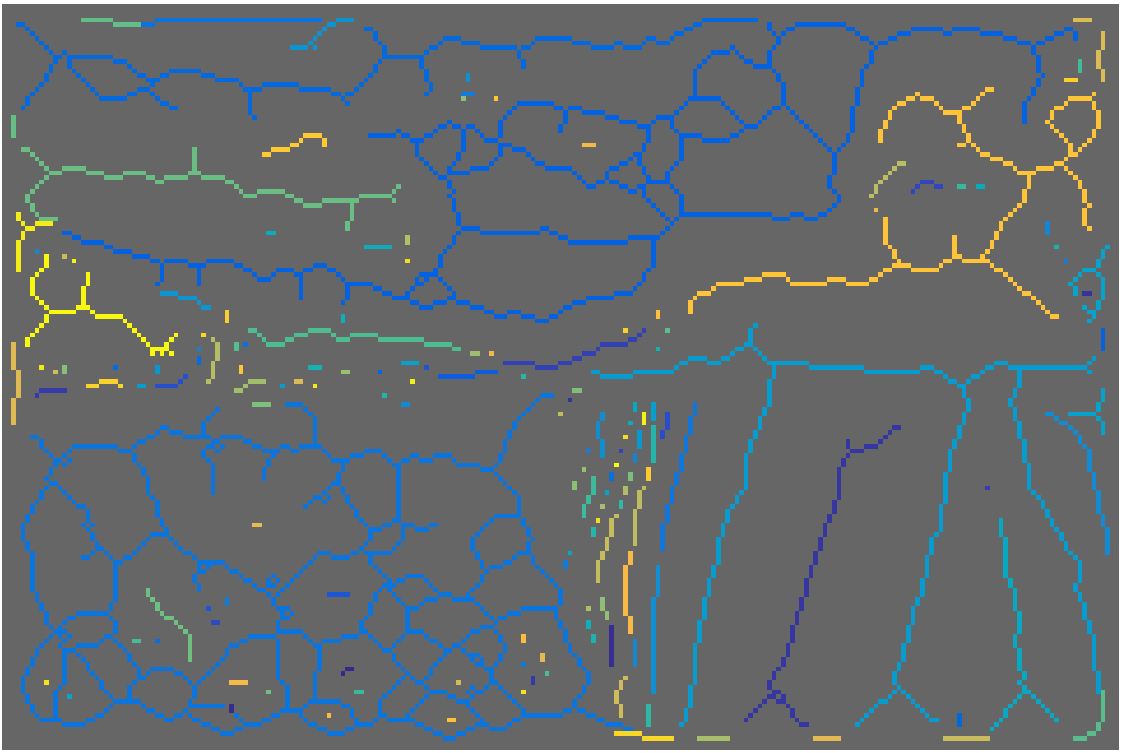

Input
AMAT
Groups
Reconstruction
Part segmentation
Fully convolutional neural networks






P(person)
P(horse)
:
P(dog)

dog
person

Finetune for part segmentation
head
torso
arms
legs
hands
Part segmentation in natural images






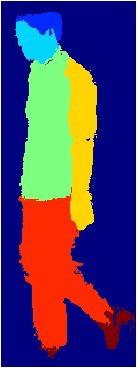


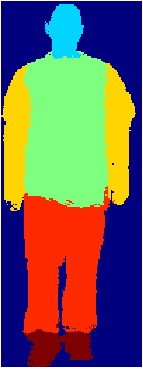




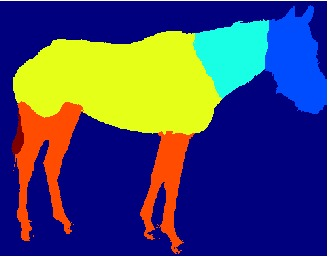
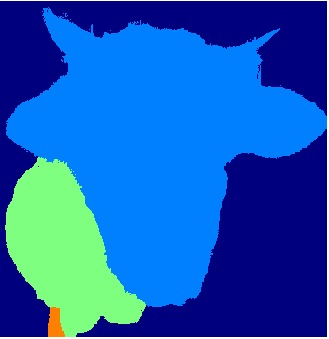
Small parts are lost due to downsampling





RGB: 152x152
L1: 142x142
L2: 71x71
L3: 63x63
L4: 55x55
L5 25x25
L6 21x21
Extract features at multiple scales

Scale 1x
Scale 1.5x
Scale 2x

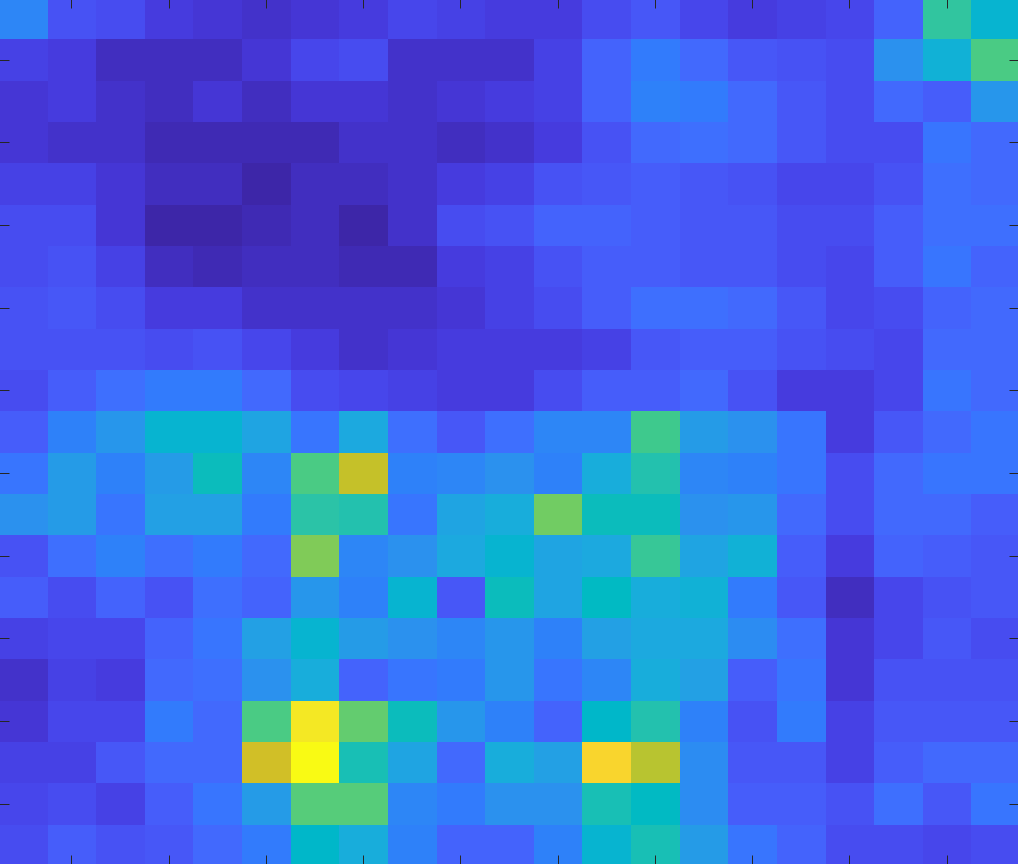
Use features from the ideal scale
Multi-scale analysis improves results...


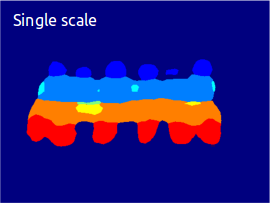
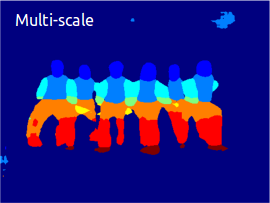
...and is efficient for images with many objects
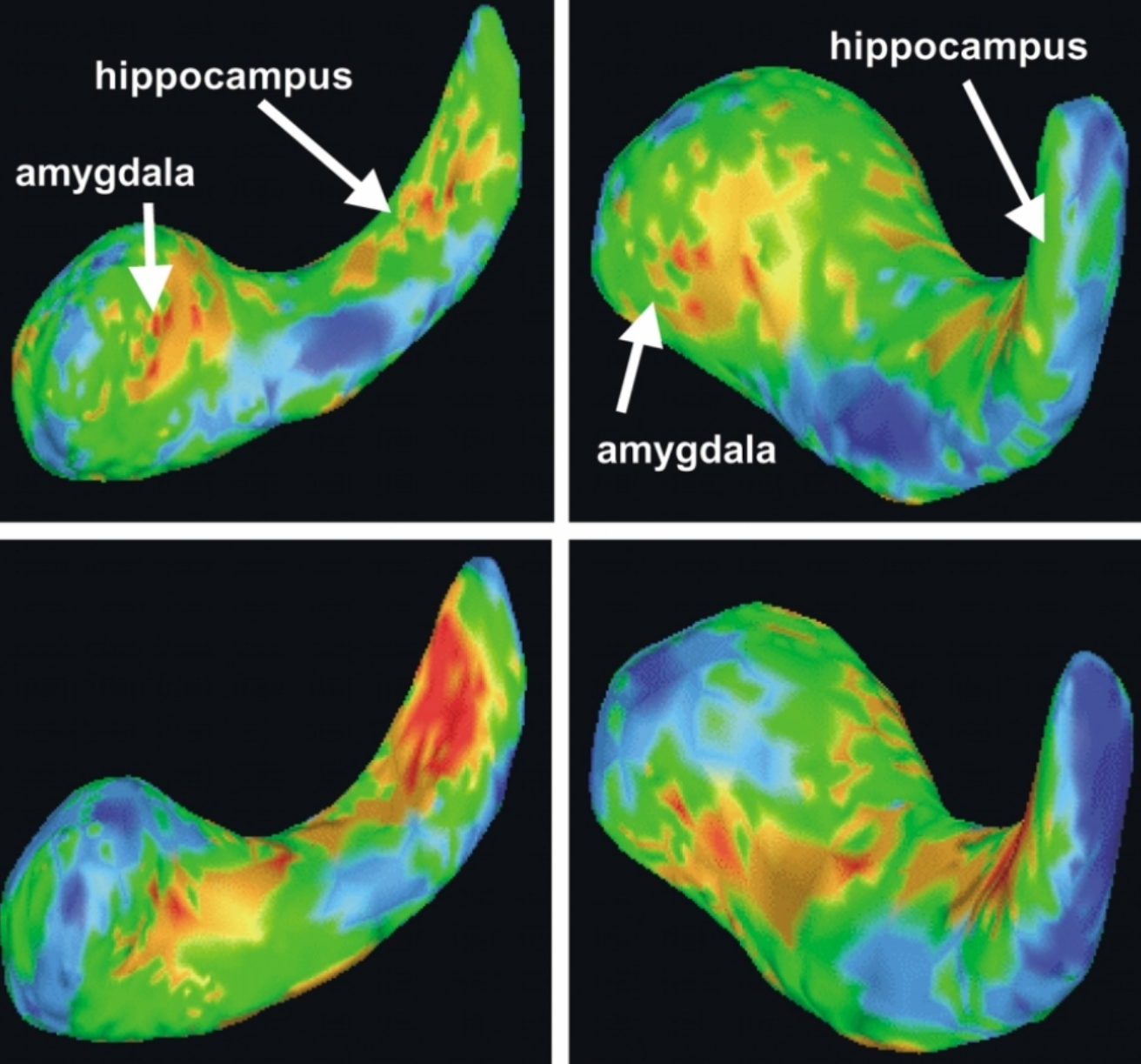
Segmenting brain "parts" is also important
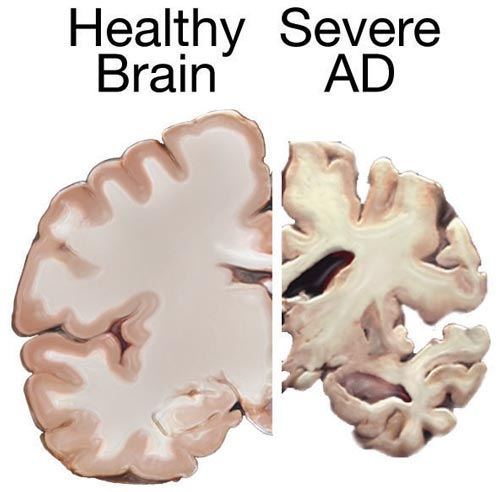
Alzheimer's:
structure degeneration
Schizophrenia: volume abnormalities
[Shenton M.E. et al., Psychiatry Res. 2002]
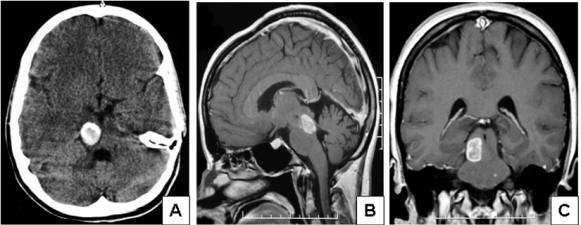
Tumors: avoid radiation on sensitive regions
[Hoehn D. et al., Journal of Medical Cases, 2012]
Why automatic segmentation?
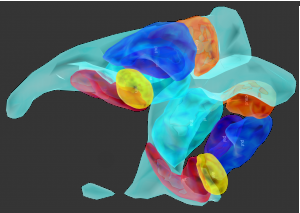

Putamen
Ventricle
Caudate
Amygdala
Hippocampus
Visualization and inspection
No need for manual annotation
(time consuming, need experts,
limited reproducibility)
Non-invasive diagnosis and treatment
Intensity in MRI is not enough



Spatial arrangement patterns matter
Segmenting subcortical structures in 2D FMRI with FCNNs
P(thalamus)
P(putamen)
:
P(caudate)
:
P(white matter)



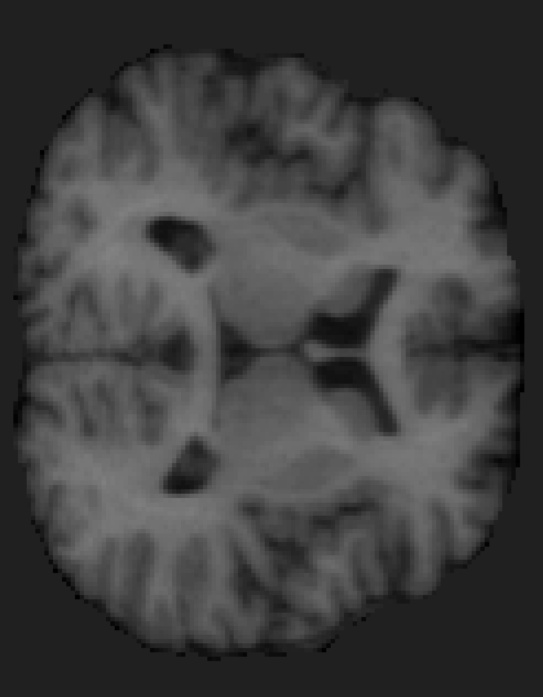
2D slice
thalamus
white matter
Subcortical brain structure segmentation using FCNNs, Tsogkas et al., ISBI 2016
From 2D slice to 3D volume segmentation


CNN architecture

-
16 layers including max-pooling and dropout.
-
Dilated convolutions for higher resolution.
-
Compact architecture (~4GB GPU RAM)
MRF enforces volume homogeneity



S^{*}=\text{argmin}E(S) = \sum_{i\in\mathcal{V}}\green{U_i} + \lambda\sum_{(i,j)\in\mathcal{E}}\orange{P_{ij}}
i
j
f(CNN output)
d(intensities)
Solve with \(\alpha\)-expansion
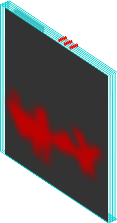
MRF removes spurious responses
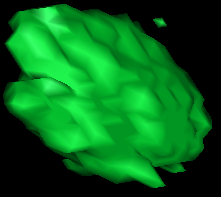
CNN
CNN+MRF
Deep priors for coregistration and cosegmentation
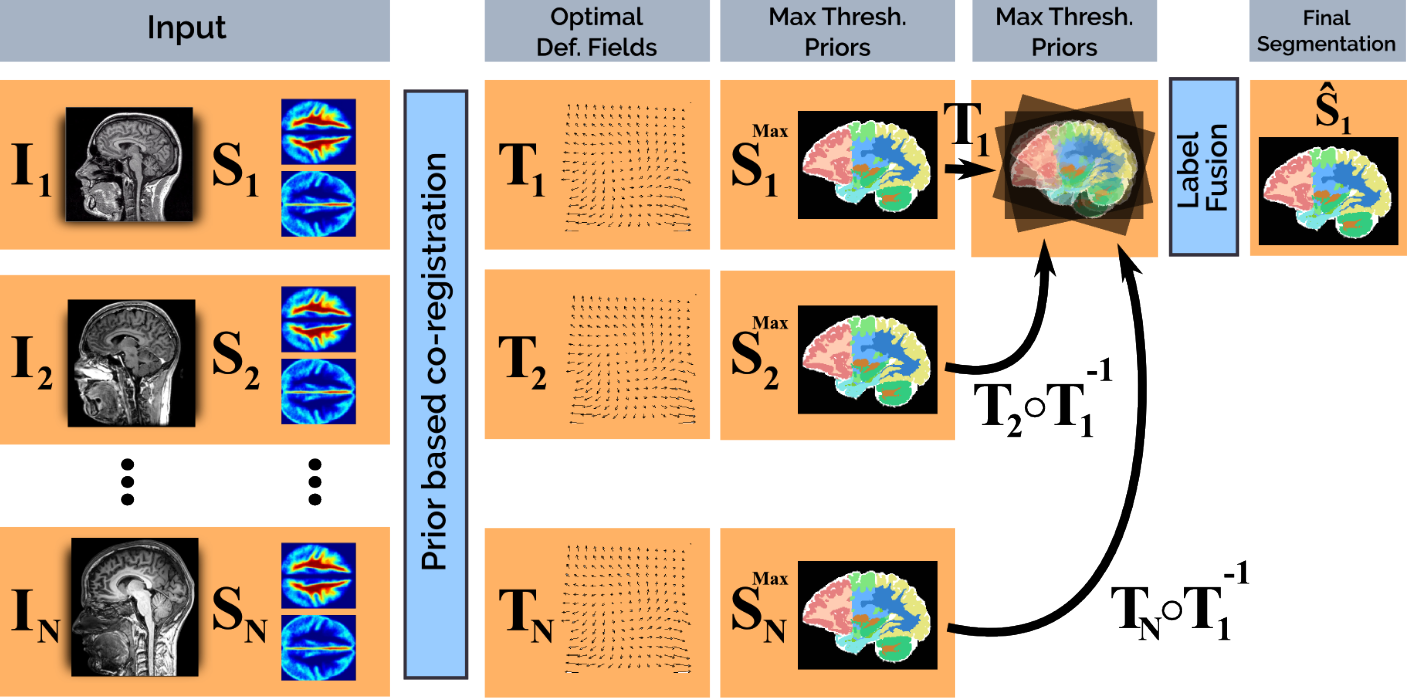
Shakeri et al., Prior-based coregistration and cosegmentation, MICCAI 2016
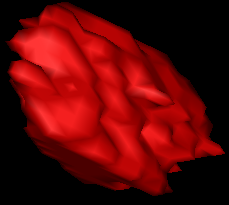
3D segmentation results
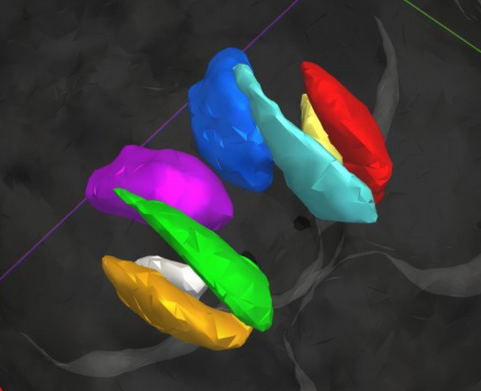
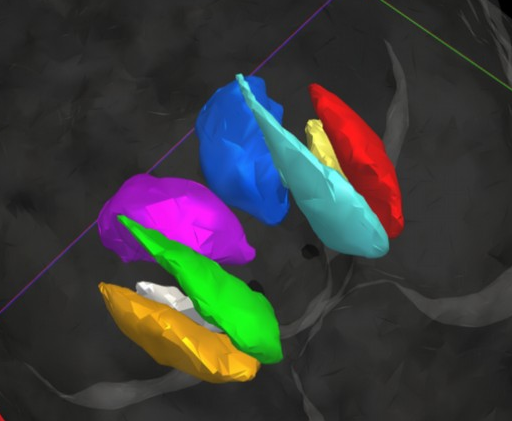
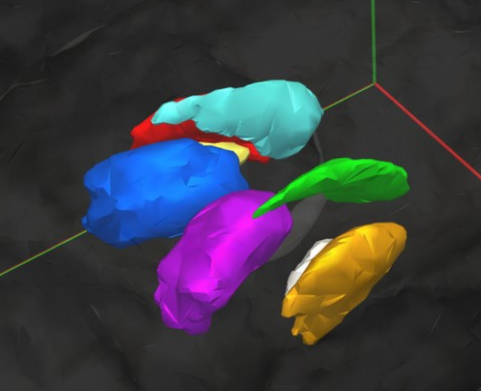
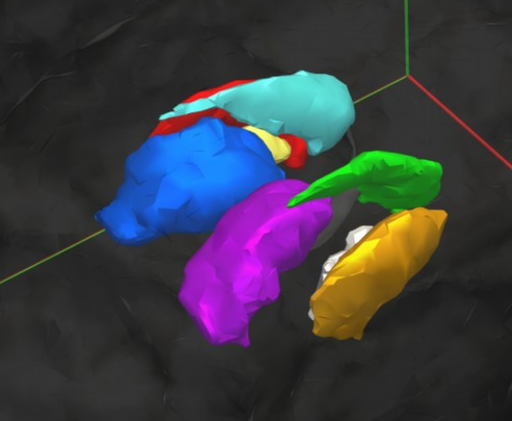
Our results
Groundtruth
Future work
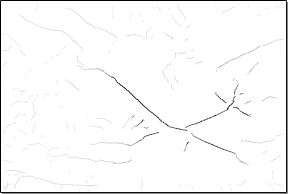
Recognition in line drawings

Chair
Monitor
Basket
Office
Intuitive form of communication
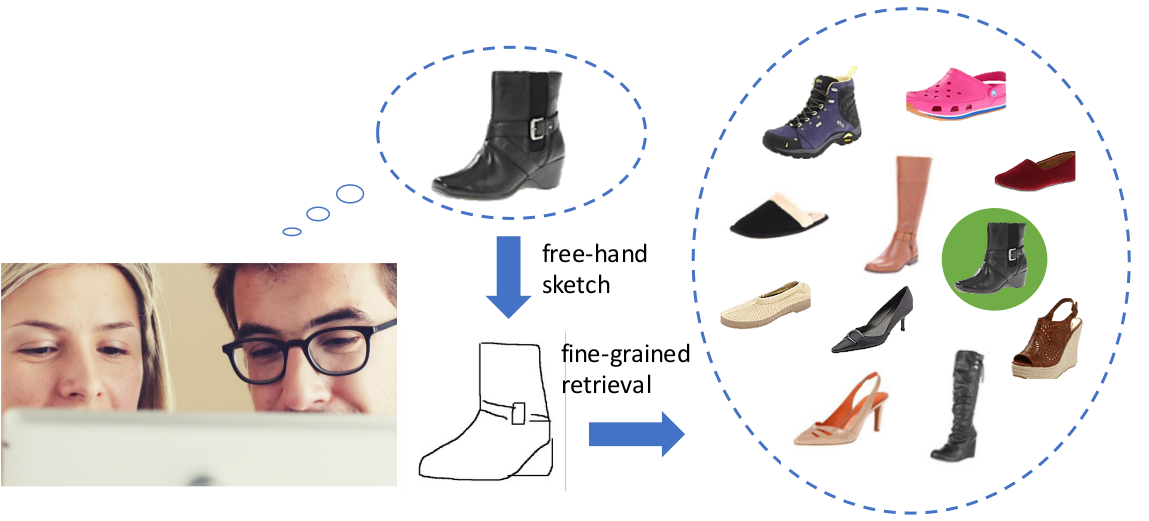

Sketch-based image retrieval
3D models from sketches
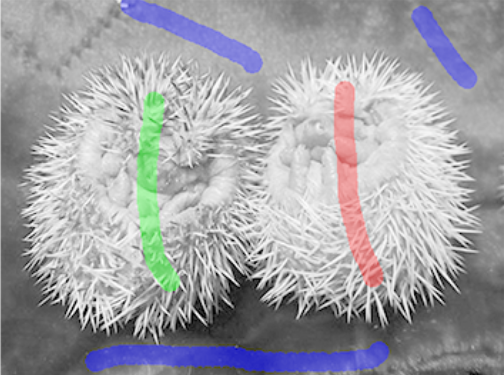
Gestalt grouping principles
Proximity
Parallelism
Continuity
Closure
Learn to group from synthetic data
Use CNN to extract point embeddings
\mathbf{e}_1
\mathbf{e}_2
\mathbf{e}_3
||\mathbf{e}_1 - \mathbf{e}_3|| \approx 0
||\mathbf{e}_1 - \mathbf{e}_2|| \gg 0
Points on the same shape have similar embeddings
Points on different shapes have dissimilar embeddings
Cluster embeddings to obtain groups
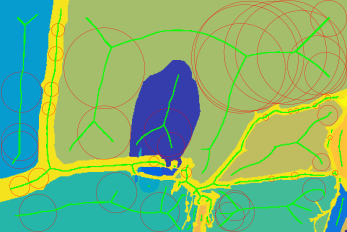
Application to complex scenes?

Edge detector result
RNNs for shape embeddings
\mathbf{p}_1
\mathbf{p}_2
\mathbf{p}_3
\mathbf{p}_4
\mathbf{p}_5
N
\mathbf{p}_1
\mathbf{h}_1
N
\mathbf{p}_2
\mathbf{h}_2
N
N
N
\mathbf{p}_3
\mathbf{h}_3
\mathbf{p}_4
\mathbf{h}_4
\mathbf{p}_5
\mathbf{h}_5
triangle
square
circle
-
grouping
-
classification
Autoencoders for image patches


Input patch \(P\)
Reconstruction \(\tilde P\)
Reconstruction loss \(L(P, \tilde{P})\)
Self supervised task
encoder
decoder
Applications


Painterly rendering
Interactive segmentation
Constrained image editing
Synergy with IMAGES group
- Class-specific priors for 2D to 3D reconstruction
- Mid-level representations for structure preserving style transfer.
- Joint 3D shape and texture reconstruction
- Medical image segmentation
Collaboration with industry partners


Teaching and supervision experience
-
Teaching assistant (CentraleSupélec)
- Signal Processing
- Computer Vision
- Machine learning for computer vision (MVA)
-
Visiting lecturer (CentraleSupélec/ESSEC)
- MSc in Data Science and Business Analytics
-
Student supervision (University of Toronto)
- 8 undergrad and masters students
Teaching
-
Bachelor
- Signal Processing
- Algorithm Design
- Artificial intelligence
-
Diplome d'ingenieur et Master
- Apprentissage pour l'image et la reconnaissance d'objets (IMA205).
- Techniques avancées en vision par ordinateur (IMA905).
- Machine Learning (SD-TSIA210).
-
Potential new courses:
- Deep learning.
Acknowledgements










Mahsa Shakeri
Enzo Ferrante
Siddhartha Chandra
Eduard Trulls
P.A. Savalle
George Papandreou
Sven Dickinson
Nikos Paragios
Iasonas Kokkinos
Andrea Vedaldi
Thank you for your attention!

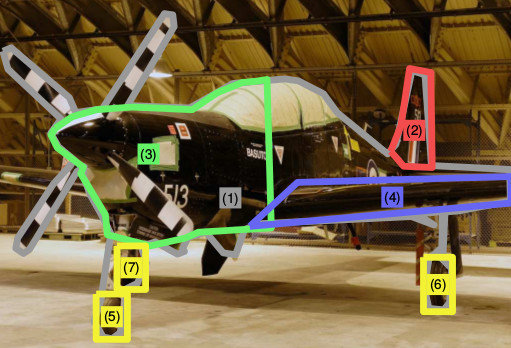


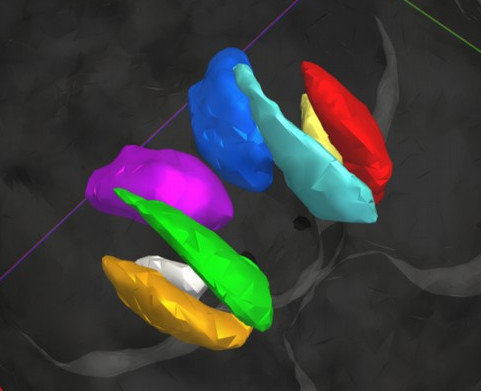
Symmetry
Medical imaging
Segmentation and parts
Learning mid-level representations for computer vision (short)
By tsogkas




