DDIA 10
3 different types of systems
- Services (Online)
take and process requests/instructions asap - Batch Processing (Offline)
Crunch through large input runs a job and produces output - Stream processing (near-real-time)
mix between online and offline, consumes input and produces output, but operates on events shortly after they happen
Unix Tools
- Log Analysis
- using commands like awk sed grep sort uniq xargs
- can perform surprisingly well
- Unix Philosophy
-
Uniform interface
- Plumbing analogy - pipes (unix files, mostly ASCII)
- Separation of logic and wiring
- Compose small tools into systems
- Transparency and experimentation
- immutable cmd, end anywhere, output for later
-
Uniform interface
- limitation: run on single machine
Custom programs
- Not as concise as unix tools but readable
- Ability to have in-memory aggregation
ruby programs
MapReduce
MapReduce
- Fairly blunt and brute force, surprisingly effective
- does not modify input; no side effects
- read and write files on a distributed filesystem

blunt and brute force
Distributed File Systems
- Hadoop Distributed File System: HDFS
- Shared nothing principle (as opposed to Network Attached Storage and Storage Area Network)
- Daemon process running on each machine, exposing a network service that allows other nodes to access files stored on that machine
- In order to tolerate machine and disk failures, file blocks are replicated on multiple machines
- ensure coding scheme such as Reed–Solomon codes, kind like RAID.
- Scales well (1000+ machines, Pentabytes data)
- Other examples: Google File System, GlusterFS, Quantcast File Systems, Amazon S3, Azure blob storage, Openstack swift are similar
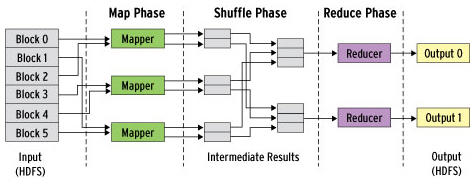
MapReduce Job Execution
- Programming framework to process large datasets
- Mapper - once for every input record, generate n independent key value pairs (prepare data)
- Reducer - takes key value pairs, matching keys and iterates over values (process data)

mapper and reducer
Distributed Execution
- Parallelised based on partition
- Putting compute near data
- reduce computation also parallelised
- Shuffle phase (sorting) is done in stages
MapReduce Workflow
- Chain MapReduce into workflows
- Hadoop chaining is done by dir name
- Hadoop workflow schedulers: including Oozie, Azkaban, Luigi, Airflow, and Pinball
- Workflow for recommendation systems can be 50-100 MapReduce jobs
- Higher-level Hadoop tools: Pig, Hive, Cascading, Crunch, and FlumeJava.

Luigi in azkaban
Reduce Joins & Grouping
- Associations: foreign key in relational model, document reference in document model, edge in graph model
- MapReduce has no concept of indexes—at least not in the usual sense
- eg: 1 fact table + 1 db table as star schema
- copy db table over to distributed file system and MapReduce the fact to table records
- One way of looking at this architecture is that mappers “send messages” to the reducers.
- When a mapper emits a key-value pair, the key acts like the destination address for value
- separates network communication from application logic
Group By:
- The simplest way is to set up the mappers so that the key-value pairs they produce use the desired grouping key.
- Another common use for grouping is collating all the activity events for a particular user session, in order to find out the sequence of actions that the user took—a process called sessionisation. (e.g. for A/B testing)
sequence of action
Handling Skew
- “bringing all records with the same key to the same place” breaks down if there is large amount of data to single key.
- e.g. celebrities in Social media
- A.k.a linchpin objects or hot keys.
- If join input has hot keys, there are a few algorithms you can use to compensate. (e.g. skewed join method in Pig, sharded join method in Crunch)
- Hive’s skewed join optimisation takes an alternative approach.
- When grouping records by a hot key and aggregating them, you can perform the grouping in two stages.
Map-Side Joins:
- The reduce-side approach advantage: no need to make assumptions about input data.
- if you can make assumptions about your input data, it is possible to make joins faster by using map-side join.
- Use a cut-down MapReduce job with no reducers and no sorting.

faster joins
Broadcast hash joins:
- Simplest map-side join in the case where large dataset is joined with a small dataset.
- Small dataset needs to be loaded entirely into memory in each mappers
- Broadcast: each mapper for a partition of the large input reads the entirety of the small dataset
- Hash: use of a hash table.
- E.g. Pig (under the name “replicated join”), Hive (“MapJoin”), Cascading, and Crunch, Data-warehouse engine Impala.
- Instead of loading the small join input into an in-memory hash table, an alternative is to store the small join input in a read-only index on the local disk. (fit in OS’ page cache, almost as fast as memory)
Partitioned hash joins:
- If the inputs to map-side join are partitioned in the same way, then hash join approach can be applied to each partition independently.
- Only works if both of the join’s inputs have the same number of partitions, with records assigned to partitions based on the same key and same hash function.

records assigned to partitions
Map-side merge joins:
- Not only partitioned in the same way, but also sorted based on the same key.
- MapReduce workflows with map-side joins:
- When the output of a MapReduce join is consumed by downstream jobs, the choice of map-side or reduce-side join affects the structure of the output.
- Knowing about the physical layout of datasets in the distributed filesystem becomes important when optimising join strategies.
- In the Hadoop ecosystem, this kind of metadata about the partitioning of datasets is often maintained in HCatalog and the Hive metastore.
Output of Batch Workflows
Building search indexes
- documents in, indexes out.
- Google’s original use of MapReduce was to build indexes for its search engine, which was implemented as a workflow of 5 to 10 MapReduce jobs. (e.g. still used today by Lucene/Solr)
- Full-text search index: it is a file (the term dictionary) in which you can efficiently look up a particular keyword and find the list of all the document IDs containing that keyword (the postings list).
Key-value stores as output
- database files in, database out
- Another common use for batch processing is to build machine learning systems such as classifiers (e.g., spam filters, anomaly detection, image recognition) and recommendation systems (e.g., people you may know, products recommendation, or related searches)
- Build a brand-new database inside the batch job and write it as files to the job’s output directory in the distributed filesystem, just like the search indexes in the last section.
- Various key-value stores support building database files in MapReduce jobs, including Voldemort, Terrapin, ElephantDB, and HBase bulk loading.
Batch process output philo
- In the process, the input is left unchanged, any previous output is completely replaced with the new output, and there are no other side effects.
- By treating inputs as immutable and avoiding side effects (such as writing to external databases), batch jobs not only achieve good performance but also become much easier to maintain.
- On Hadoop, some of those low-value syntactic conversions are eliminated by using more structured file formats: e.g. Avro, Parquet
Hadoop VS Distributed Databases
Similarities
- Hadoop is somewhat like a distributed version of Unix, where HDFS is the filesystem and MapReduce is a quirky implementation of a Unix process(which happens to always run the sort utility between the map phase and the reduce phase).
- MapReduce and a Distributed Filesystem provides something much more like a general-purpose operating system that can run arbitrary programs.
arbitrary programs
Storage Diversity
- Databases require you to structure data according to a particular model while files in distributed filesystem are just byte sequences
- Collecting data in raw form, allows the data collection to be sped up
- Sushi principle: “raw (data) is better”
- Indiscriminate data dumping shifts burden of interpreting the data from producer to consumer (Schema on read)
- There may not be one ideal data model, but different views onto the data suitable for different purposes.
- Data modelling still happens, but in a separate step, decoupled from the data collection.
Processing models diversity
- MapReduce gave engineers the ability to easily run their own code over large datasets.
- Sometimes having two processing models, SQL and MapReduce, is not enough.
- The system is flexible enough to support a diverse set of workloads in same cluster.
- Not having to move data around makes it a lot easier to derive value from the data, and a lot easier to experiment with new processing models.
Designing for freq. faults
- Massively Parallel Processing DB prefer to keep as much data as possible in memory (e.g., using hash joins) to avoid the cost of reading from disk.
- MapReduce is very eager to write data to disk, for fault tolerance, and the dataset is too big to fit in memory.
- Overcommitting resources in turn allows better utilisation of machines and greater efficiency compared to systems that segregate production and non-production tasks.
- It’s not because the hardware is particularly unreliable, it’s because the freedom to arbitrarily terminate processes enables better resource utilisation in a computing cluster.
Beyond MapReduce
MapReduce Flaws
- Depending on volume of data, structure of data, and type of processing being done with it, other tools may be more appropriate for expressing a computation.
- Implementing a complex processing job using the raw MapReduce APIs is quite hard and laborious—need to implement join algorithms from scratch.
- In response to the difficulty of using MapReduce directly, various higher-level programming models (Pig, Hive, Cascading, Crunch) were created as abstractions on top of MapReduce.
Intermediate State
- MapReduce’s approach of fully materializing intermediate state has downsides compared to Unix pipes: (C: which derived from its advantages)
- A MapReduce job can only start when all tasks in the preceding jobs (that generate its inputs) have completed;
- Mappers are often redundant: they just read back the same file just written by a reducer, and prepare it for next stage of partitioning and sorting.
- Storing intermediate state in a distributed file system means those files are replicated across several nodes, which is overkill for temporary data.
Dataflow engines
- New execution engine created to solve previous problems. E.g. Spark, Tez, and Flink.
- Handle an entire workflow as one job, rather than breaking it up into independent sub jobs.
- Since they explicitly model the flow of data through several processing stages, these systems are known as dataflow engines.

dataflow engine
Dataflow engines benefits
- Offers several advantages compared to the MapReduce model:
- Expensive work such as sorting need only be performed in places where it is actually required.
- no unnecessary map tasks
- Can make locality optimizations.
- Usually sufficient for intermediate state between operators to be kept in memory or written to local
- Operators can execute as soon as input is ready;
- Existing Java Virtual Machine (JVM) processes can be reused to run new operators, reducing startup overheads compared to MapReduce (which launches a new JVM for each task).
Fault tolerance
- if task fails, it can be restarted with same input
- Spark, Flink, and Tez avoid writing intermediate state:
- if machine fails and intermediate state is lost, it is recomputed from other available data
- To recompute, framework must keep track —which input partitions used, which operators applied
- important to know whether the computation is deterministic.
- non-deterministic operators: kill the downstream operators run again
- if intermediate data is much smaller than source data, or if the computation is CPU-intensive, it is cheaper to materialise the intermediate data
Materialization Discussion
- Flink especially is built around the idea of pipelined execution: that is, incrementally passing the output of an operator to other operators, and not waiting for the input to be complete before starting to process it.

Passing operator to operator
Graphs & Iter. Processing
- In graph processing, the data itself has the form of a graph.
- This need often arises in machine learning applications such as recommendation engines, or in ranking systems. (e.g. PageRank)
- Iterative style: (works, but very inefficient with MapReduce)
- 1. An external scheduler runs a batch process to calculate one step of the algorithm.
- 2. When the batch process completes, the scheduler checks whether it has finished.
- 3. If it has not yet finished, the scheduler goes back to step 1 and runs another round of the batch process.
The Pregel processing model
Pregel Model
- As an optimization for batch processing graphs, the bulk synchronous parallel (BSP) model of computation has become popular. Aka. “Pregel model”.
(implemented by Apache Giraph, Spark’s GraphX API, and Flink’s Gelly API.) - Idea behind Pregel: one vertex can “send a message” to another vertex, and typically those messages are sent along the edges in a graph.
- In each iteration, a function is called for each vertex, passing it all the messages that were sent to it—much like a call to the reducer. (It’s a bit similar to the actor model)
Fault tolerance
- Pregel implementations guarantee that messages are processed exactly once at their destination vertex in the following iteration.
- This fault tolerance is achieved by periodically check-pointing the state of all vertices at the end of an iteration. (i.e., writing their full state to durable storage.)
Parallel execution
- A vertex does not need to know on which physical machine it is executing; when it sends messages to other vertices, it simply sends them to a vertex ID.
Parallel execution computing
High-Level APIs & Lang.
- Spark and Flink also include their own high-level dataflow APIs, often taking inspiration from FlumeJava.
- These dataflow APIs generally use relational-style building blocks to express a computation:
- joining datasets on the value of some field;
- grouping tuples by key;
- filtering by some condition;
- and aggregating tuples by counting, summing, or other functions.
Declarative Query Lang.
- Move toward declarative query languages:
- Choice of join algorithm can make a big difference to the performance of a batch job;
- This is possible if joins are specified in a declarative way: the application states which joins are required, and the query optimiser decides how
- Hive, Spark DataFrames, and Impala also use vectorized execution: iterating over data in a tight inner loop that is friendly to CPU caches, and avoiding function calls.
- batch processing frameworks begin to look more like MPP databases (and can achieve comparable performance) they retain their flexibility advantage.
Specialisation diff. domains
- Another domain of increasing importance is statistical and numerical algorithms, which are needed for machine learning applications such as classification and recommendation systems.
Sources
- https://comeshare.net/2020/04/22/designing-data-intense-application-chapter-10-batch-processing/
DDIA 10
By tzyinc




