1º Workshop de Integração da Pós-Graduação
Victor Sanches Portella
Maio, 2026
Pesquisa em Teoria do
Aprendizado de Máquina
Pesquisa Atualmente
Otimização para ML
Algoritmos Aleatorizados
Privacidade Diferencial
Online Learning
Ciência da Computação Teórica
Aprendizado de Máquina
Otimização para ML
Por que otimização de primeira ordem?
Treinar um modelo de ML normalmente é modelado via optimização irrestrita
Modelos de ML tendem a serem GRANDES
\displaystyle \min_{x \in \mathbb{R}^{d}}~f(x)
\(d\) é GRANDE
\(O(d)\) tempo e espaço por iteração é preferível
\displaystyle x_{t+1} = x_t - \alpha \nabla f(x_t)
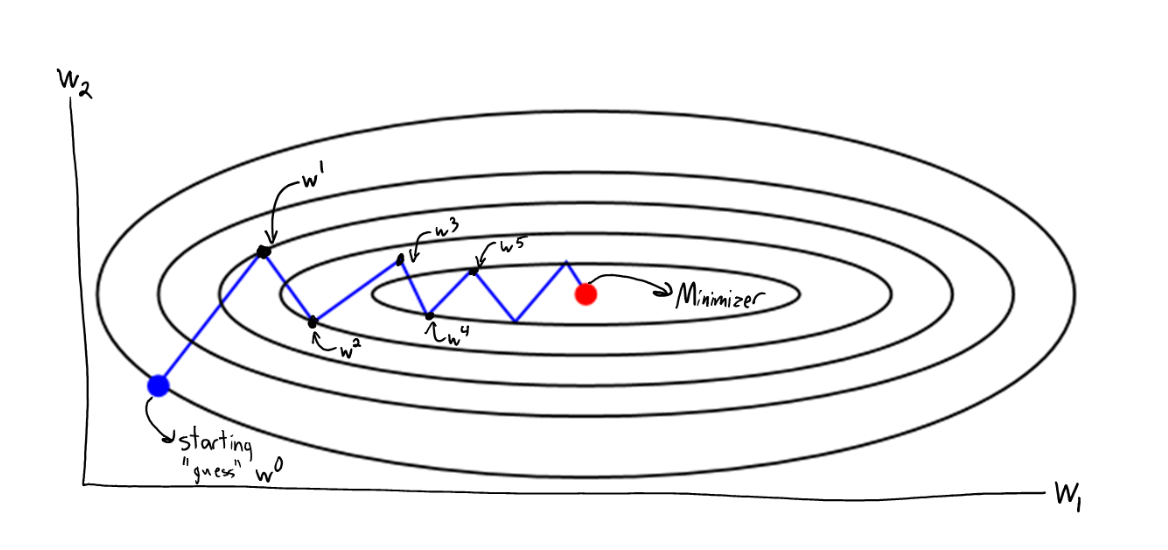
Algoritmo adaptativos em otimização
Um tamanho de passo "Adaptivo" para cada parâmetro
Uma definição formal de Online Learning (AdaGrad)
Hypergradient
Adam, RMSProp, RProp
Aprox. 2nd Order Methods
Desenhado para funções adversariais e não suave
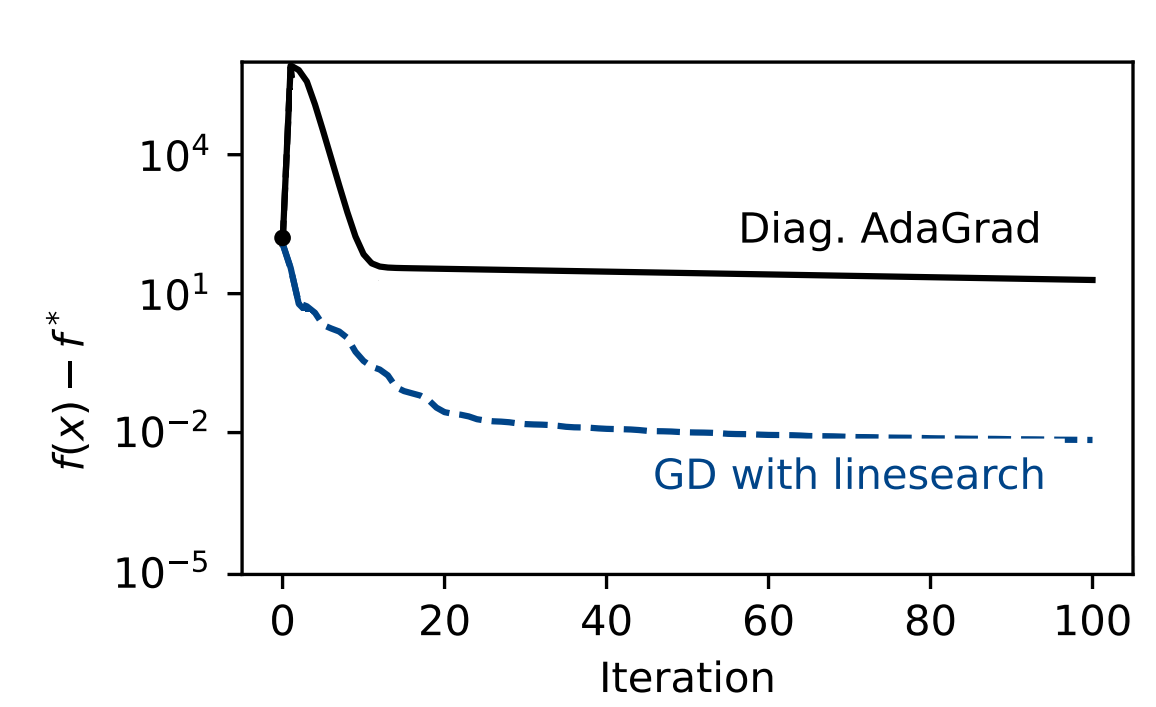
Busca em linha clássica é melhor em problemas simples

Mas o que "adaptativo" significa?
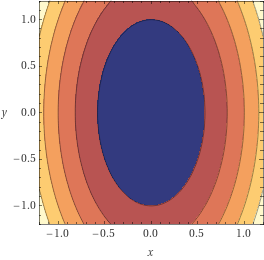
Definition of an Optimal Preconditioner
\displaystyle \kappa(\nabla^2 f(\mathbf{x})) \gg 1
\displaystyle \displaystyle \kappa(\mathbf{P}_*^{1/2} \nabla^2 f(\mathbf{x}) \mathbf{P}_*^{1/2}) = \kappa_*
\displaystyle \kappa_*
\displaystyle f(\mathbf{x}_{t+1}) - f^* \leq \left( 1 - \frac{1}{\phantom{\kappa_{*}}}\right) (f(\mathbf{x}_t) - f^*)
\displaystyle \mathbf{x}_{t+1} = \mathbf{x}_t - \eta \nabla f(\mathbf{x}_t)
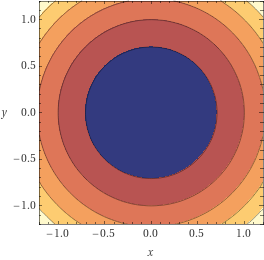
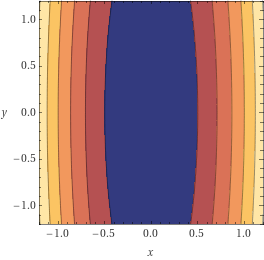
Adaptividade em problemas
suaves e
fortemente convexos
\displaystyle \kappa(\mathbf{P}^{1/2} \nabla^2 f(\mathbf{x}) \mathbf{P}^{1/2}) > 1
\displaystyle \kappa_{\mathbf{P}}
\displaystyle f(\mathbf{x}_{t+1}) - f^* \leq \left( 1 - \frac{1}{\phantom{\kappa_{*}}}\right) (f(\mathbf{x}_t) - f^*)
\displaystyle \kappa_{}
\displaystyle f(\mathbf{x}_{t+1}) - f^* \leq \left( 1 - \frac{1}{\phantom{\kappa_{*}}}\right) (f(\mathbf{x}_t) - f^*)
Multidimensional Backtracking
\displaystyle f(\mathbf{x}_{t+1}) - f^* \leq \left( 1 - \frac{1}{\phantom{\color{red}\sqrt{2d}}} \frac{1}{\phantom{\color{blue}\kappa_{*}}}\right) (f(\mathbf{x}_t) - f^*)
\displaystyle \sqrt{2d}
\displaystyle \kappa_*
\displaystyle \mathbf{x}_{t+1} = \mathbf{x}_t - \phantom{\color{blue}\mathbf{P}_{\!*}} \nabla f(\mathbf{x}_t)
\displaystyle
{\mathbf{P}_{\!*}}
\displaystyle \mathbf{x}_{t+1} = \mathbf{x}_t - \phantom{\color{red}\mathbf{P}} \nabla f(\mathbf{x}_t)
\displaystyle {\mathbf{P}}
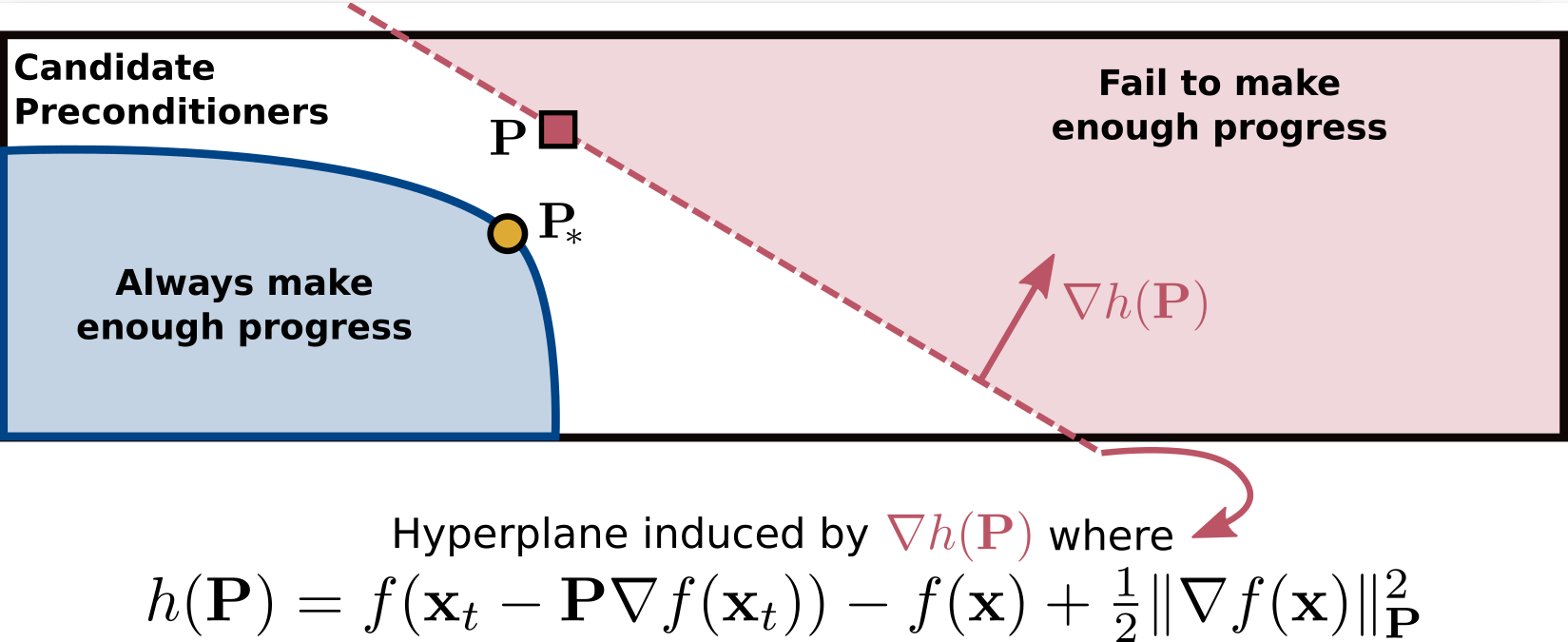
Ideia básica do algoritmo
f(\mathbf{x}_t - \mathbf{P} \nabla f(\mathbf{x}_t))
\mathbf{x}_{t+1} = \mathbf{x}_t - \mathbf{P} \nabla f(\mathbf{x}_t)
A cada iteração
If
If
tem
progresso suficiente
Atualize \(\mathbf{x}\):
Else
Atualize \(\mathbf{P}\) e conjunto de passos candidatos
Busca de Precondicionador Diagonal
Aprendizado Online
Aprendizado Online com Experts
Jogador
Adversário
\(n\) Experts
0.5
0.1
0.3
0.1
Pesos
p_t
1
-1
0.5
-0.3
Custos
\ell_t \in [-1,1]^n
Penalidade do Jogador:
\langle \ell_t, p_t \rangle
Adversário sabe a estratégia do Jogador




Performance medida
através de regret
Otimização adaptativa
Boosting
Bandits
Modelando Online Learning em Tempo Contínuo

Análise frequentemente limpa
Playground para design de algoritmos
Gradient flow útil para otimização suave
\displaystyle
\partial_t x_t = - \nabla f(x_t)
Pergunta Central: Como modelar optimization
não-suave (online) em tempo contínuo?
Por que usar ?
tempo contínuo
Custos Adversariais em Tempo Contínuo
Custo Total de um Expert \(i\):


\displaystyle
L_t(i) = \sum_{s = 1}^t \ell_s(i)
Perspectiva útil: \(L(i)\) is a realização de um
passeio aleatório
realização de um
Movimento Browniano
Tempo Discreto
Tempo Contínuo
\displaystyle
L_t(i) = B_t(i)
O Efeito da falta de suavidade
Lema de Ito
(Teorema Fundamental do Cálculo Estocástico)
\displaystyle
f(B_t) - f(B_0) = \int_{0}^T f'(B_t) \mathrm{d} B_t
\displaystyle
+ ~\frac{1}{2} \int_{0}^T f'' (B_t) \mathrm{d} t
\(B(t)\) muito não-suave \(\implies\) termos de segunda ordem importam
Ideia: Usar cálculo estocástico para guiar o design de algoritmos

Suave
Não-suave
Algoritmos Online Adaptativos
Otimização Linear Online
Quantile Regret
Privacidade Diferencial
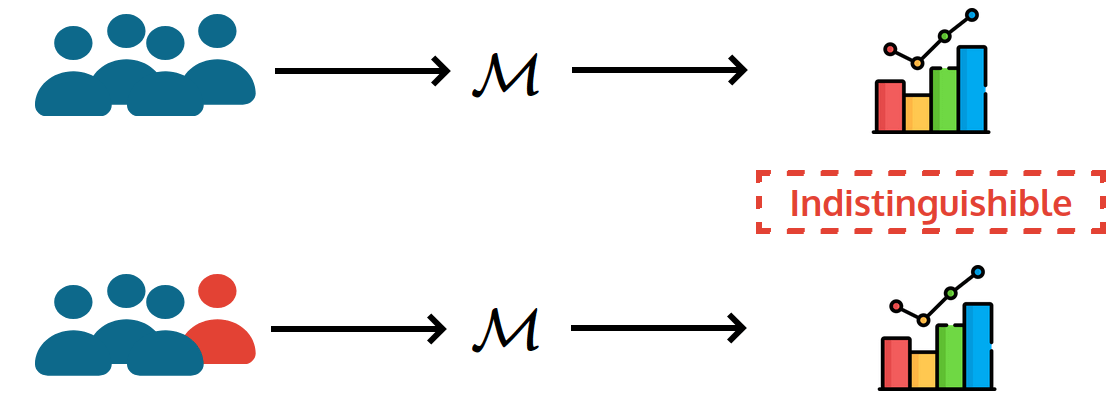
O que queremos dizer com "privacidade"?
Objetivo informal: Resultado não deve revelar (muito) sobre qualquer indivíduo em particular
Diferente de falhar de segurança (ex: invasão de servidor)
Resultado
Análise de Dados
Trivial se o resultado não tiver informação sobre a entrada
Privacidade Diferencial
\displaystyle
\mathcal{M}
\displaystyle
\mathcal{M}
Indistinguíveis
O que pode ser aprendido com um indivíduo
(provavelmente) pode ser aprendido sem o mesmo
Uma definição: Privacidade Diferencial
Algoritmos online em streams de dados
Um Problema:
Contar (aprox.) o número de elementos distintos em um stream de \(N\) itens de \(n\) tipos
Queremos usar espaço sublinear
Exemplo: Contador de número de ouvintes de uma música
Itens chegam sequencialmente
\(N\) e \(n\) são GRANDES

[Ícones de Pokemon por Roundicon Freebies em flaticon.com]




Revisitando Algoritmos de Streaming
Será que alguns algoritmos aletorizador possuem
garantias de privacidade sem modificações?
Normalmente, injetamos ruído/aleatoridade em algoritmos para conseguir garantias de PD
Mas muito algoritmos (online) são naturalmente aleatorizados!
LLMs e o Trabalho em Teoria
AI for Math




Hype e problemas com "IA"




Evento posgrad IME-USP
By Victor Sanches Portella



