Buscando por
Tamanhos de Passo por Coordenada Ótimos com
Victor Sanches Portella
ime.usp.br/~victorsp
junto de Frederik Kunstner, Nick Harvey, e Mark Schmidt
Multidimensional Backtracking





Março, 2026
Métodos de Primeira Ordem
Por que otimização de primeira ordem?
Treinar um modelo de ML normalmente é modelado via optimização irrestrita
Modelos de ML tendem a serem GRANDES
\displaystyle \min_{x \in \mathbb{R}^{d}}~f(x)
\(d\) é GRANDE
Métodos de primeira ordem (ex: usando gradientes) se encaixam
(Ainda mais as versões estocásticas)
\(O(d)\) tempo e espaço por iteração é preferível
O Caso de Otimização Convexa
\(f\) é convexa
Não é o caso de Redes Neurais
Métodos ainda úteis na teoria e prática
\displaystyle \Bigg\{
Mais condições para obtermos taxas de convergência:
\(L\)-suave
\displaystyle \min_{x \in \mathbb{R}^{d}}~f(x)
\(\mu\)-fortemente convexa



\preceq \nabla^2 f(x) \preceq
L \cdot I
\mu \cdot I
"Fácil de otimizar"
Gradient Descent
\displaystyle x_{t+1} = x_t - \alpha \nabla f(x_t)
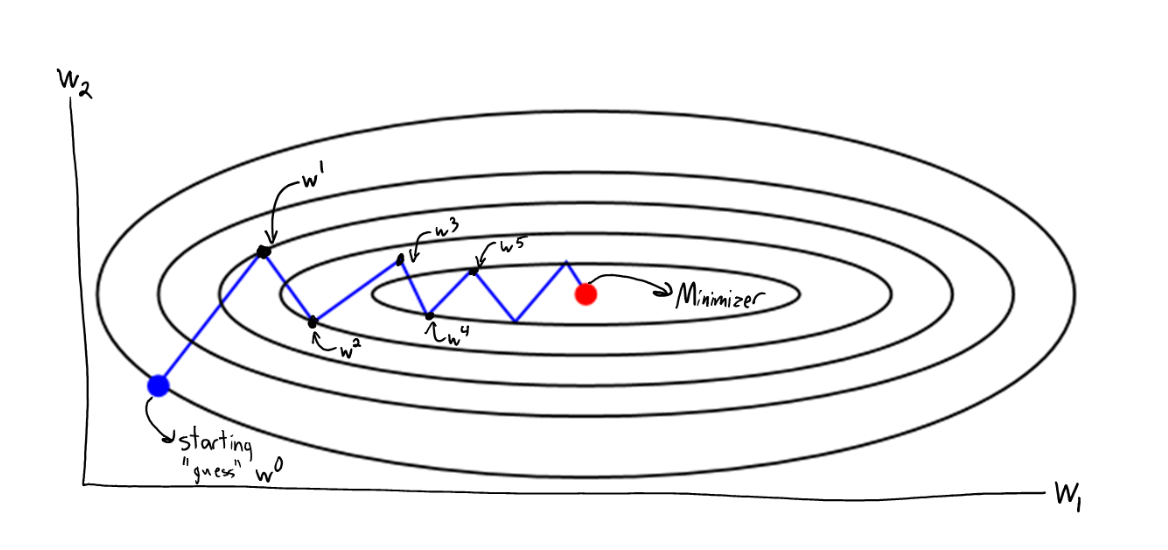
Qual tamanho de passo \(\alpha\) escolher?
\displaystyle \implies
\displaystyle f(x_t) - f(x_*) \leq \left( 1 - \frac{\mu}{L} \right)^t (f(x_0) - f(x_*))
Núm. de condição
\displaystyle \alpha = \frac{1}{L}
\displaystyle \kappa = \frac{L}{\mu}
\(\kappa\) Grande \(\implies\) Função difícil
Condição de Armijo
Qual tamanho de passo escolher?
Se sabemos \(L\), \(\alpha = 1/L\) sempre funciona
a é ótima
E se não conhecemos \(L\)?
\displaystyle x_{t+1} = x_t - \tfrac{1}{L} \nabla f(x_t)
\displaystyle f(x_{t+1}) \leq f(x_t) - \tfrac{1}{L} \tfrac{1}{2} \lVert \nabla f(x_t) \rVert_2^2
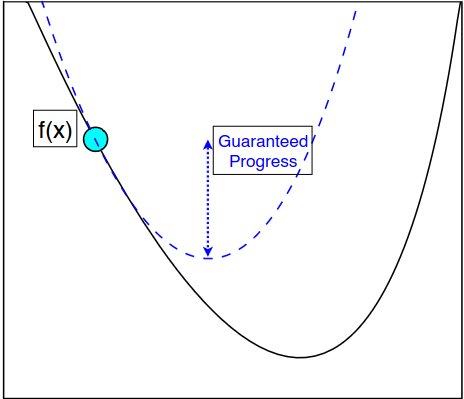
"Descent Lemma"
Ideia: Escolher \(\alpha\) grande and checar se "Descent lemma" vale
(Localmente \(1/\alpha\)-suave)
no pior caso
\alpha_{\max}
Backtracking Line Search (Busca em linha)
Busca em linha: testa se \(\alpha_{\max}/2\) nos dá progresso o suficiente:
\displaystyle f(x_{t+1}) \leq f(x_t) - \alpha_{\max} \tfrac{1}{2} \lVert \nabla f(x_t) \rVert_2^2
Se falhar, CORTE todos os candidatos maiores que \(\alpha_{\max}/2\)
0
\tfrac{\alpha_{\max}}{2}
\tfrac{1}{L}
\tfrac{\alpha_{\max}}{4}
Além de busca em linha?
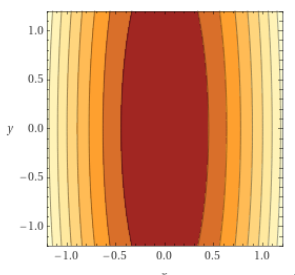
\displaystyle f(x) = x^T A x
\displaystyle A =
\begin{pmatrix}
1000 & 0 \\
0 & 0.001
\end{pmatrix}
\displaystyle \kappa = 10^{-6}
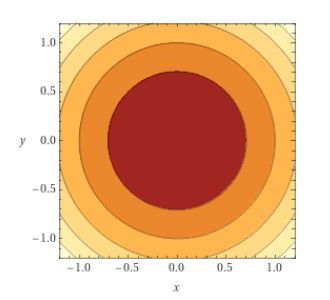
\displaystyle x_{t+1} = x_t -
\begin{pmatrix}
0.001 & 0 \\
0 & 1000
\end{pmatrix}
\nabla f(x_t)
Converge em 1 passo
\(P\)
Conseguimos calcular \(P\) automaticamente?
"Se adaptar à \(f\)"
Precondicionador \(P\)
Otimização "Adaptativa"

Métodos "adaptativos"
Podemos convergir mais rápido com um precondicionador (diagonal)
(Quasi-)Newton
\displaystyle \Bigg \{
Convergência superlinear perto da sol.
O que é um bom \(P\)?
Garantias globais fracas
x_{t+1} = x_t - \phantom{P} \nabla f(x_t)
P
x_{t+1} = x_t - \phantom{P} \nabla f(x_t)
x_{t+1} = x_t - \phantom{P} \nabla f(x_t)
P
P \approx (\nabla^2 f(x_t))^{-1}
Online Learning
Garantias formais até no caso adversarial
\displaystyle \Bigg \{
Muito conservador (ex: AdaGrad)
"Primos" (ex: Adam) tem poucas garantias
Hypergradient
Trata achar \(P\) como um prob. de otimização
Instável e quase zero teoria
\displaystyle \Bigg \{
P_t \approx ( \sum_{i} \nabla f(x_i) \nabla f(x_i)^T)^{-1/2}

"Fixing" AdaGrad
"AdaGrad inspired an incredible number of clones, most of them with similar, worse, or no regret guarantees.(...) Nowadays, [adaptive] seems to denote any kind of coordinate-wise learning rates that does not guarantee anything in particular."
Francesco Orabona in "A Modern Introduction to Online Learning", Sec. 4.3

State of Affairs
adaptive methods
f(x_t) - f(x_*) \displaystyle \lesssim \left( 1 - O\Big(\frac{1}{\kappa}\Big) \right)^t
only guarantee (globally)
In Smooth
and Strongly Convex optimization,
Should be better if there is a good Preconditioner \(P\)
Online Learning
Smooth Optimization
1 step-size
\(d\) step-sizes
(diagonal preconditioner )
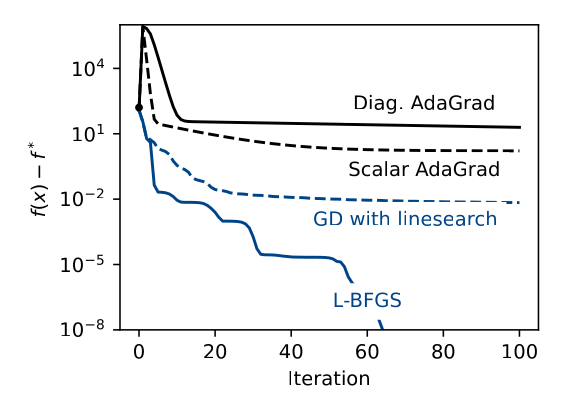
Backtracking Line-search
Diagonal AdaGrad
Multidimensional Backtracking
Scalar AdaGrad
(and others)
(and others)
(non-smooth optmization)
Preconditioner Search
Precondicionador (Diagonal) Ótimo
\displaystyle \frac{1}{\kappa} P^{-1} \preceq \nabla^2 f(x) \preceq P^{-1}
Tamanho de passo ótimo: o maior que garante progresso
Precondicionador ótimo: maior (??) que garante progresso
\displaystyle P = \tfrac{1}{L} I
\displaystyle \kappa = \tfrac{L}{\mu}
\(L\)-suave
\(\mu\)-fort. convexa
\(f\) é
and
\preceq \nabla^2 f(x) \preceq
L \cdot I
\mu \cdot I
Precondicionador Diagonal Ótimo
\(\kappa_* \leq \kappa\), idealmente \(\kappa_* \ll \kappa\)
Sobre matrizes diagonais
\displaystyle P_*
minimiza \(\kappa_*\) tal que
\displaystyle \frac{1}{\kappa_*} P^{-1} \preceq \nabla^2 f(x) \preceq P^{-1}
De Busca em linha para busca de precondicionador
Busca em Linha
\displaystyle \Bigg\{
Vale a pena se \(\sqrt{2d} \kappa_* \ll 2 \kappa\)
\displaystyle f(x_t) - f(x_*) \leq\Big(1 - \phantom{\frac{1}{2}} \cdot \frac{1}{\kappa}\Big)^t (f(x_0) - f(x_*))
\displaystyle
\frac{1}{2}
Multidimensional Backtracking
\displaystyle \Bigg\{
(nosso alg.)
# backtracks \(\lesssim\)
\displaystyle d \cdot \log\Big( \alpha_0 \cdot L\Big)
\displaystyle f(x_t) - f(x_*) \leq\Big(1 - \phantom{\frac{1}{\sqrt{2d}}} \cdot \frac{1}{\phantom{\kappa_*}}\Big)^t (f(x_0) - f(x_*))
\displaystyle\frac{1}{\sqrt{2d}}
\displaystyle \kappa_*
# backtracks \(\leq\)
\displaystyle \log\Big(\alpha_{0} \cdot L \Big)
Multidimensional Backtracking
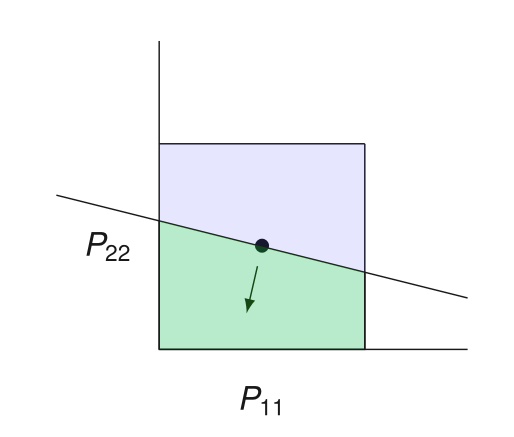
Por que a busca ingênua não funciona?
Busca em linha:
\displaystyle f(x_{t+1}) \leq f(x_t) - \tfrac{\alpha_{\max}}{2} \tfrac{1}{2} \lVert \nabla f(x_t) \rVert_2^2
"Progresso como se \(f\) fosse
\(\frac{2}{\alpha_{\max}}\)-smooth"
Se não, CORTA candidatos maiores que \(\alpha_{\max}/2\)
0
\alpha_{\max}
\tfrac{\alpha_{\max}}{2}
\tfrac{1}{L}
\tfrac{\alpha_{\max}}{4}
Testa se \(\alpha_{\max}/2\) garante progresso suficiente:
Passo candidatos: intervalo \([0, \alpha_{\max}]\)
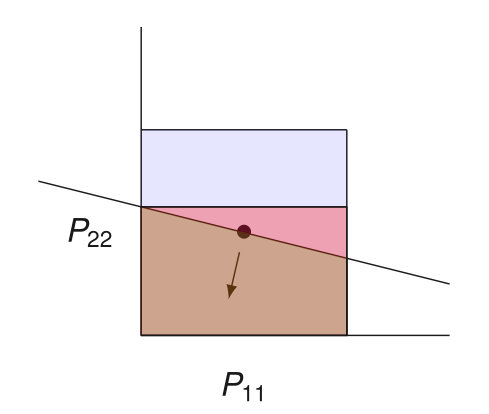
Por que a busca ingênua não funciona?
Busca de precondicionador:
Testa se \(P\) garante progresso o suficiente
Precondicionadores candidatos: diagonais contidas num hipercubo
Se não, CORTE tudo maior que \(P\)
"Progresso se \(f\) fosse
\(P\)-suave"
\displaystyle f(x_{t+1}) \leq f(x_t)
- \tfrac{1}{2} \lVert \nabla f(x_t) \rVert_P^2
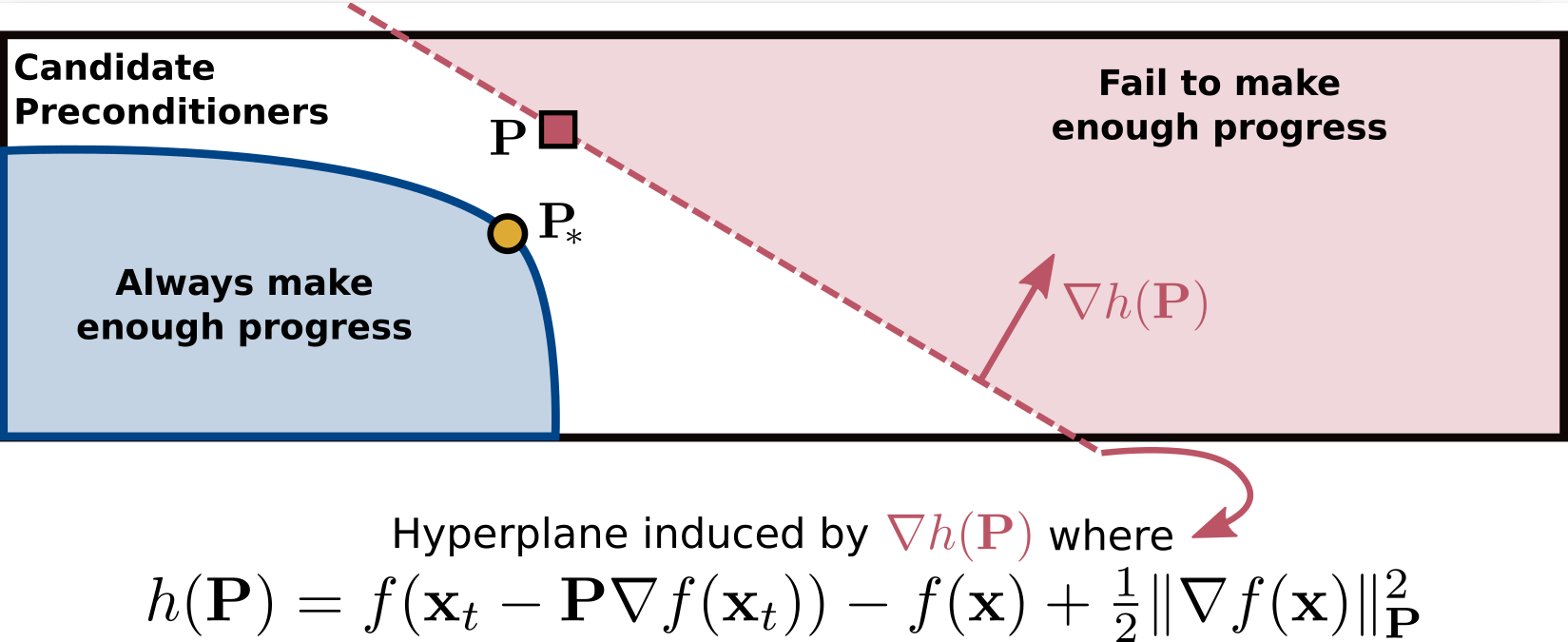
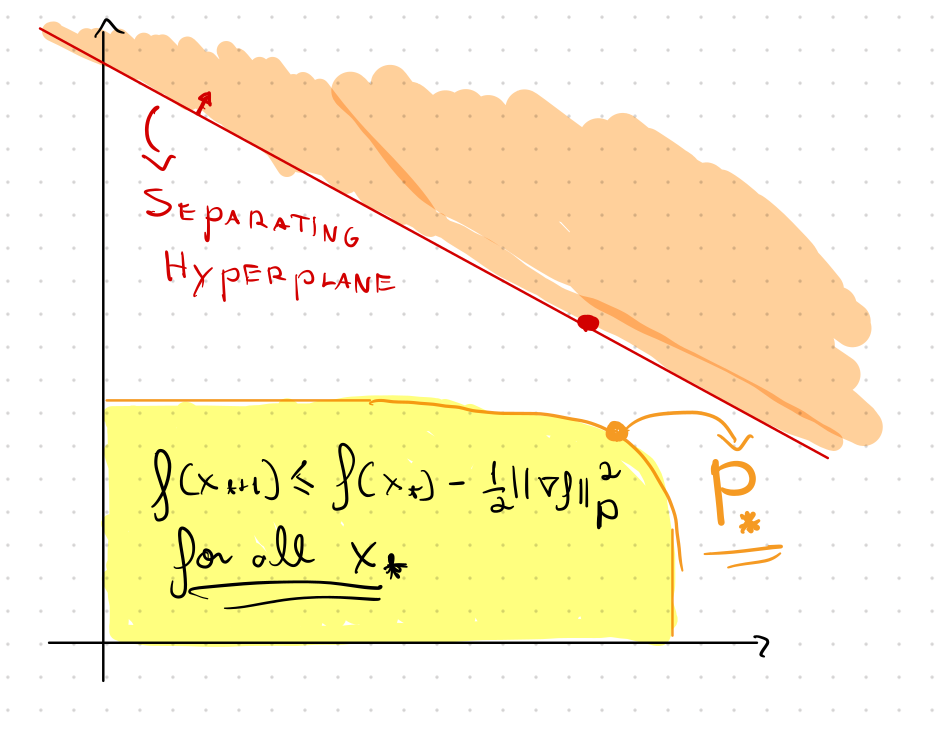
Convexidade ao resgate
Se \(P\) não garante progresso suficiente,
Quais candidatos podemos jogar fora?
\(P \) garante progresso suficiente \(\iff\) \(h(P) \leq 0\)
\displaystyle
h(P) = \phantom{f(x - P \nabla f(x)) - (f(x) - \tfrac{1}{2} \lVert \nabla f(x) \rVert_P^2)}
\displaystyle
\phantom{h(P) = f(x - P \nabla f(x)) }- (f(x) - \tfrac{1}{2} \lVert \nabla f(x) \rVert_P^2)
\displaystyle
\phantom{h(P) = }f(x - P \nabla f(x))\phantom{ - (f(x) - \tfrac{1}{2} \lVert \nabla f(x) \rVert_P^2)}
\displaystyle \nabla h(P)
Convexidade \(\implies\)
induz um hiperplano separador
"Hypergradient"
Ideia principal
Convexidade ao resgate
Se \(P\) não garante progresso suficiente,
Quais candidatos podemos jogar fora?
\(P \) garante progresso suficiente \(\iff\) \(h(P) \leq 0\)
\displaystyle
h(P) = \phantom{f(x - P \nabla f(x)) - (f(x) - \tfrac{1}{2} \lVert \nabla f(x) \rVert_P^2)}
\displaystyle
\phantom{h(P) = f(x - P \nabla f(x)) }- (f(x) - \tfrac{1}{2} \lVert \nabla f(x) \rVert_P^2)
\displaystyle
\phantom{h(P) = }f(x - P \nabla f(x))\phantom{ - (f(x) - \tfrac{1}{2} \lVert \nabla f(x) \rVert_P^2)}
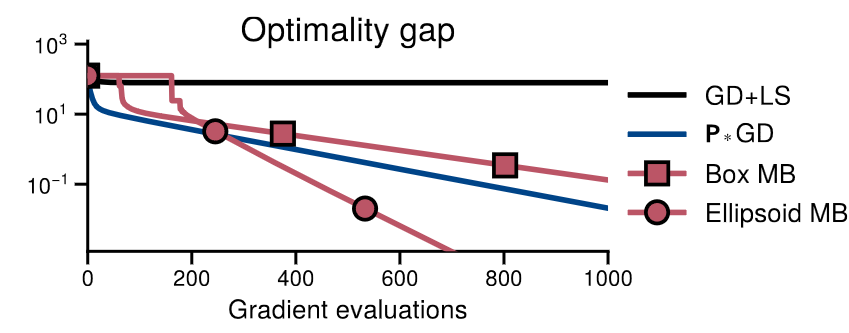
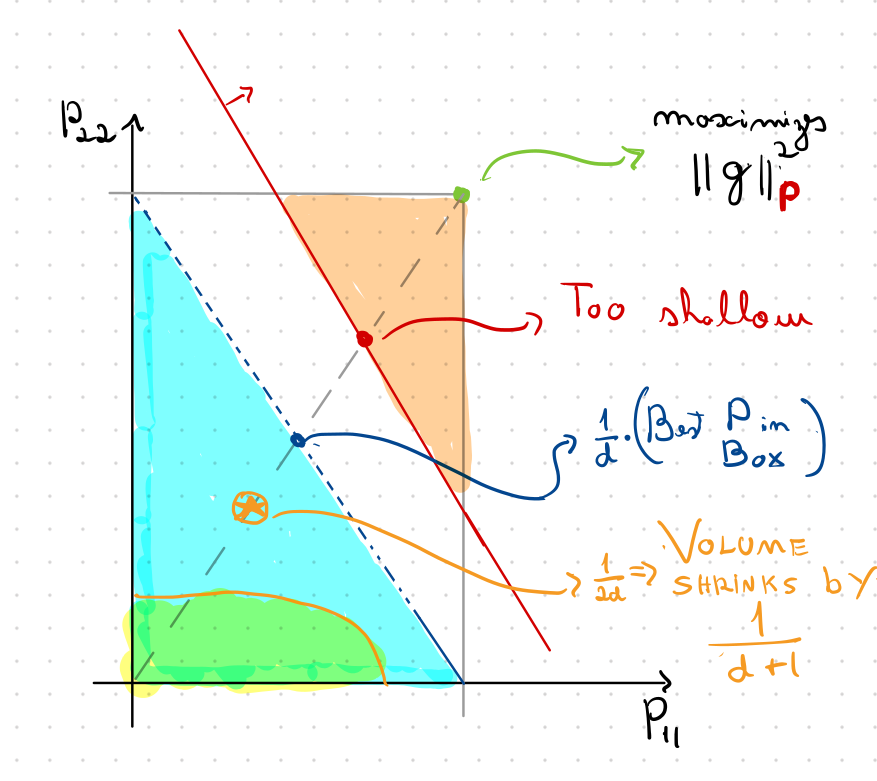
Boxes vs Ellipsoids
\displaystyle f(x_t) - f(x_*) \lesssim\Big(1 - \phantom{\frac{1}{d}} \cdot \frac{1}{\kappa_*}\Big)^t
\displaystyle
\frac{1}{d}
\(P\) perto da origem \(\implies\) queda de volume em caso de corte
\(P\) perto da borda \(\implies\) melhor taxa de convergência
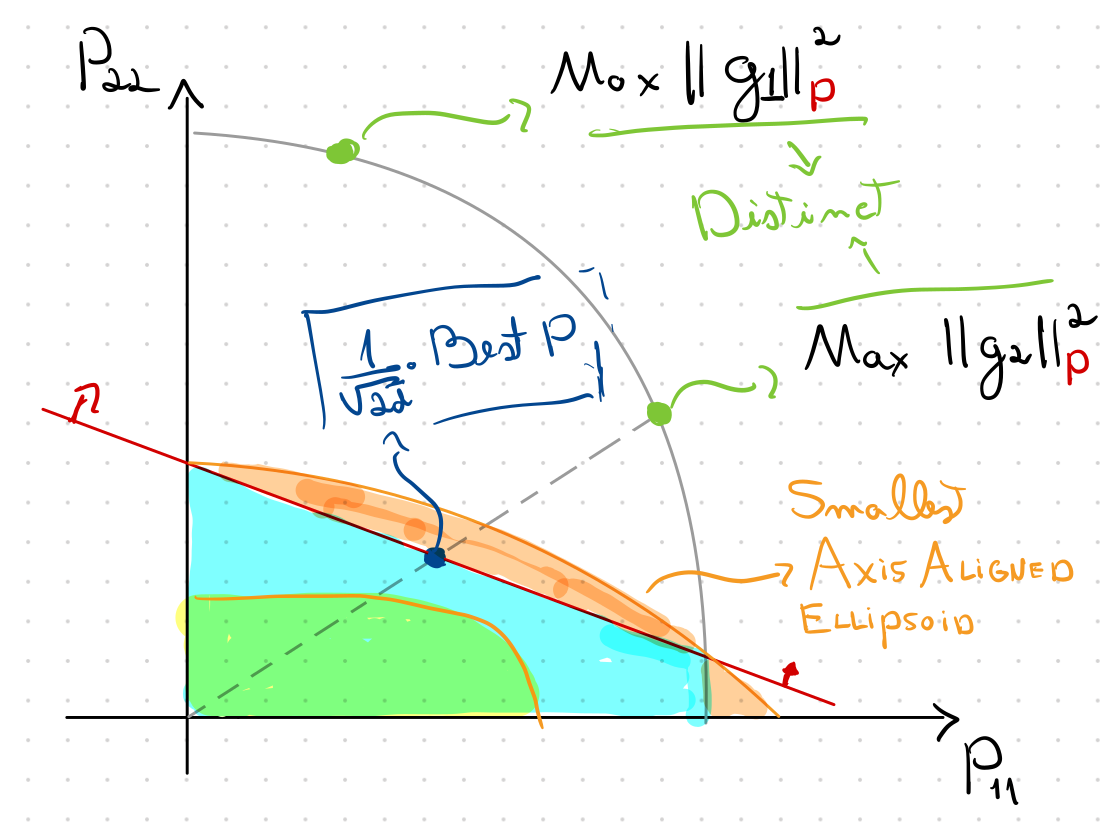
Elipisoides ao resgate!

that maximizes
Ellipsoid Method to the Rescue
that maximizes

\(\Omega(d^3)\) de tempo por iteração
O problema é muito simétrico!
\(O(d)\) por iteração
\displaystyle f(x_t) - f(x_*) \lesssim\Big(1 - \phantom{\frac{1}{\sqrt{2d}}} \cdot \frac{1}{\kappa_*}\Big)^t
\displaystyle
\frac{1}{\sqrt{2d}}
Experimentos
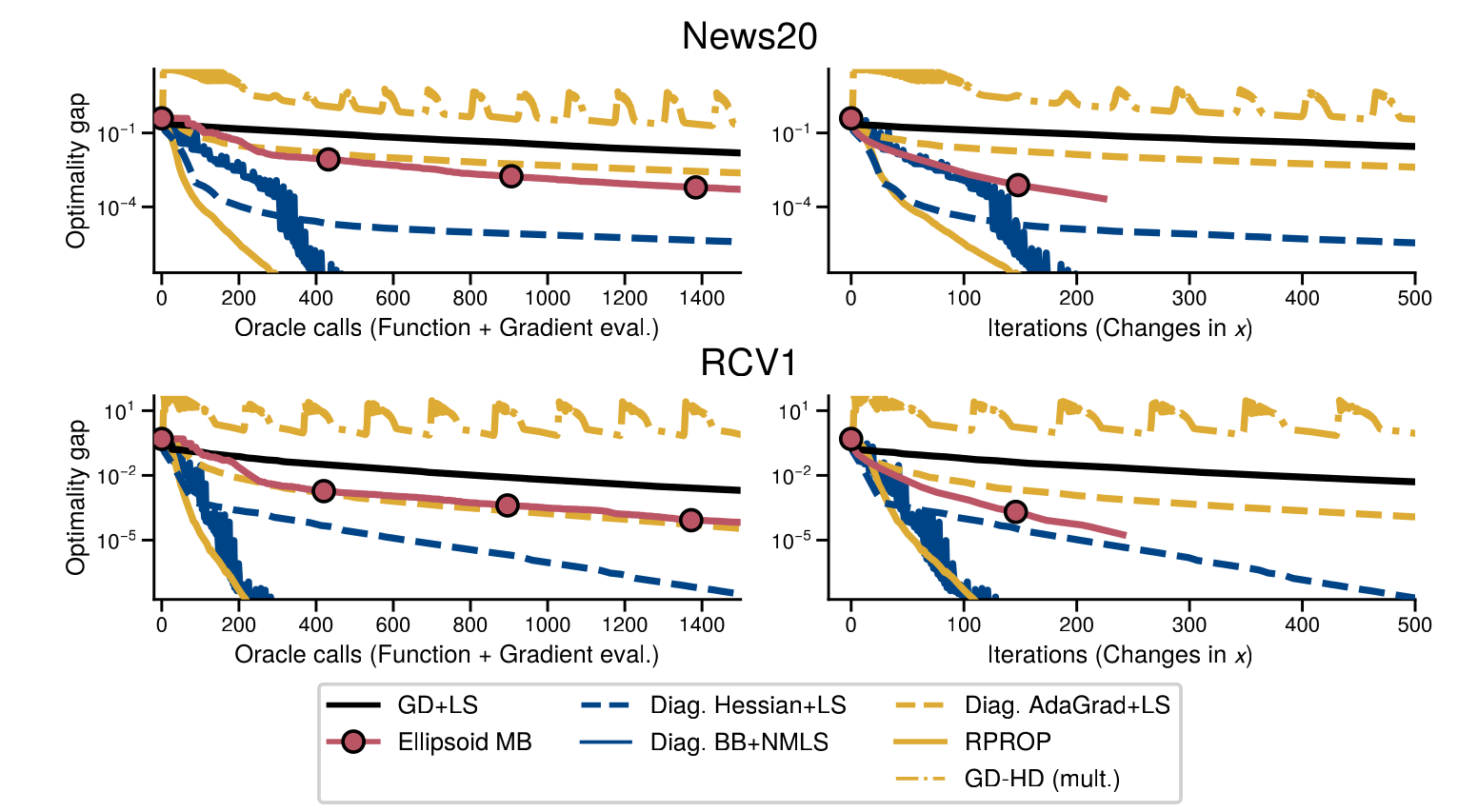
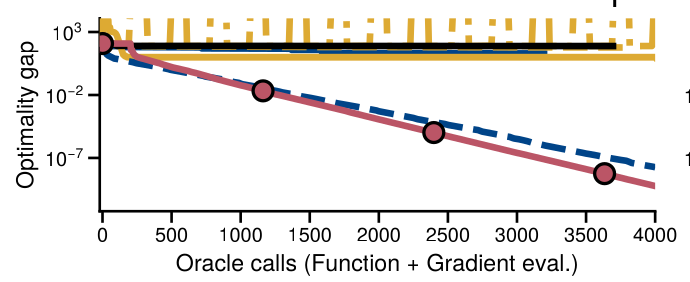
\kappa \approx 10^{13}
\kappa_* \approx 10^{2}
Experimentos
Conclusões
Trabalhos seguintes com novas ideias para otimização adaptativa
Um uso de "hypergradients" baseado em teoria
ML Opt encontra Métodos de corte
Obrigado!

arxiv.org/abs/2306.02527





Additional Slides
Box as Feasible Sets
How Deep to Query?
Ellipsoid Method to the Rescue
Convexity to the Rescue
Gradient Descent and Line Search
Why first-order optimization?
Training/Fitting a ML model is often cast a (uncontrained) optimization problem
Usually in ML, models tend to be BIG
\displaystyle \min_{x \in \mathbb{R}^{d}}~f(x)
\(d\) is BIG
Running time and space \(O(d)\) is usually the most we can afford
First-order (i.e., gradient based) methods fit the bill
(stochastic even more so)
Usually \(O(d)\) time and space per iteration
Convex Optimization Setting
\displaystyle f(y) \geq f(x) + \langle \nabla f(y), x - y\rangle + \frac{L}{2}\lVert x - y \rVert_2^2
\(f\) is convex
Not the case with Neural Networks
Still quite useful in theory and practice
\displaystyle \Bigg\{
More conditions on \(f\) for rates of convergence
\(L\)-smooth
\displaystyle \min_{x \in \mathbb{R}^{d}}~f(x)
\(\mu\)-strongly convex
\displaystyle f(y) \leq f(x) + \langle \nabla f(y), x - y\rangle + \frac{\mu}{2}\lVert x - y \rVert_2^2
Gradient Descent
\displaystyle x_{t+1} = x_t - \alpha \nabla f(x_t)
Which step-size \(\alpha\) should we pick?
\displaystyle \implies
\displaystyle f(x_t) - f(x_*) \leq \left( 1 - \frac{\mu}{L} \right)^t (f(x_0) - f(x_*))
Condition number
\displaystyle \alpha = \frac{1}{L}
\displaystyle \kappa = \frac{L}{\mu}
\(\kappa\) Big \(\implies\) hard function
What Step-Size to Pick?
If we know \(L\), picking \(1/L\) always works
and is worst-case optimal
What if we do not know \(L\)?
Locally flat \(\implies\) we can pick bigger step-sizes
\displaystyle x_{t+1} = x_t - \tfrac{1}{L} \nabla f(x_t)
If \(f\) is \(L\) smooth, we have
\displaystyle f(x_{t+1}) \leq f(x_t) - \tfrac{1}{L} \tfrac{1}{2} \lVert \nabla f(x_t) \rVert_2^2
"Descent Lemma"
Idea: Pick \(\eta\) big and see if the "descent condition" holds
(Locally \(1/\eta\)-smooth)
Beyond Line-Search?
\displaystyle f(x) = x^T A x
\displaystyle A =
\begin{pmatrix}
1000 & 0 \\
0 & 0.001
\end{pmatrix}
\displaystyle \kappa = 10^{-6}
\displaystyle x_{t+1} = x_t -
\begin{pmatrix}
0.001 & 0 \\
0 & 1000
\end{pmatrix}
\nabla f(x_t)
Converges in 1 step
\(P\)
\(O(d)\) space and time \(\implies\) \(P\) diagonal (or sparse)
Can we find a good \(P\) automatically?
"Adapt to \(f\)"
Preconditioer \(P\)
"Adaptive" Optimization Methods
Adaptive and Parameter-Free Methods
\displaystyle x_{t+1} = x_t - P_t \cdot \nabla f(x_t)
Preconditioner at round \(t\)
AdaGrad from Online Learning
\displaystyle P_t = \Big( \sum_{i \leq t} \nabla f(x_i) \nabla f(x_i)^T \Big)^{1/2}
\displaystyle \mathrm{Diag}\Big( \sum_{i \leq t} \nabla f(x_i) \nabla f(x_i)^T \Big)^{1/2}
or
Better guarantees if functions are easy
while preserving optimal worst-case guarantees in Online Learning
Attains linear rate in classical convex opt (proved later)
But... Online Learning is too adversarial, AdaGrad is "conservative"
In OL, functions change every iteration adversarially
"Fixing" AdaGrad
But... Online Learning is too adversarial, AdaGrad is "conservative"
"Fixes": Adam, RMSProp, and other workarounds
"AdaGrad inspired an incredible number of clones, most of them with similar, worse, or no regret guarantees.(...) Nowadays, [adaptive] seems to denote any kind of coordinate-wise learning rates that does not guarantee anything in particular."
Francesco Orabona in "A Modern Introduction to Online Learning", Sec. 4.3
Hypergradient Methods
Idea: look at step-size/preconditioner choice as an optimization problem
Gradient descent on the hyperparameters
How to pick the step-size of this? Well...

Little/ No theory
Unpredictable
... and popular?!
Second-order Methods
P_t = \nabla^2 f(x_t)
Newton's method
is usually a great preconditioner
Superlinear convergence
...when \(\lVert x_t - x_*\rVert\) small
Newton may diverge otherwise
Using step-size with Newton and QN method ensures convergence away from \(x_*\)
Worse than GD
\displaystyle f(x_t) - f(x_*) \leq \left( 1 - \frac{1}{\kappa^2} \right)^t (f(x_0) - f(x_*))
\displaystyle \phantom{\kappa}^2
\(\nabla^2 f(x)\) is usually expensive to compute
P_t \approx \nabla^2 f(x_t)
should also help
Quasi-Newton Methods, e.g. BFGS
State of Affairs
(Quasi-)Newton: needs Hessian, can be slower than GD
Hypergradient methods: purely heuristic, unstable
Online Learning Algorithms: Good but pessimistic theory
at least for smooth optimization it seems pessimistic...
Online Learning
Smooth Optimization
1 step-size
\(d\) step-sizes
(diagonal preconditioner )
Backtracking Line-search
Diagonal AdaGrad
Coordinate-wise
Coin Betting
(non-smooth opt?)
Multidimensional Backtracking
Scalar AdaGrad
Coin-Betting
What does it mean for a method to be adaptive?
Por que a busca ingênua não funciona?
Busca em linha: testa se \(\alpha_{max}/2\) garante progresso suficiente:
\displaystyle f(x_{t+1}) \leq f(x_t) - \tfrac{\alpha_{\max}}{2} \tfrac{1}{2} \lVert \nabla f(x_t) \rVert_2^2
Armijo condition
Se não, CORTA candidatos maiores que \(\alpha_{\max}/2\)
Busca por precondicionador:
0
\alpha_{0}
\tfrac{\alpha_{0}}{2}
\tfrac{1}{L}
\tfrac{\alpha_{0}}{4}
Testamos se \(P\) garante progresso suficiente:
Espaço de candidatos: matrizes com diagonais em um cubo
Se não, CORTA candidatos maiores que \(P\)
\displaystyle f(x_{t+1}) \leq f(x_t)
- \tfrac{1}{2} \lVert \nabla f(x_t) \rVert_P^2
Preconditioner Search - 20 min - SeMaP
By Victor Sanches Portella



