Once-For-All: Train One Network and Specialize for Effective Deployment
SysDL Reading Group
Two ways of doing Hardware-aware NAS


- Bilevel optimization - sample, then train
- Inner-most training loop is very slow. Compounds across NetworkSpace and DeviceSpace
- DARTS, ProxylessNAS,...
- The training is decoupled from the search - train once, then sample
- Amortizes the overall GPU cost
- OFA!!
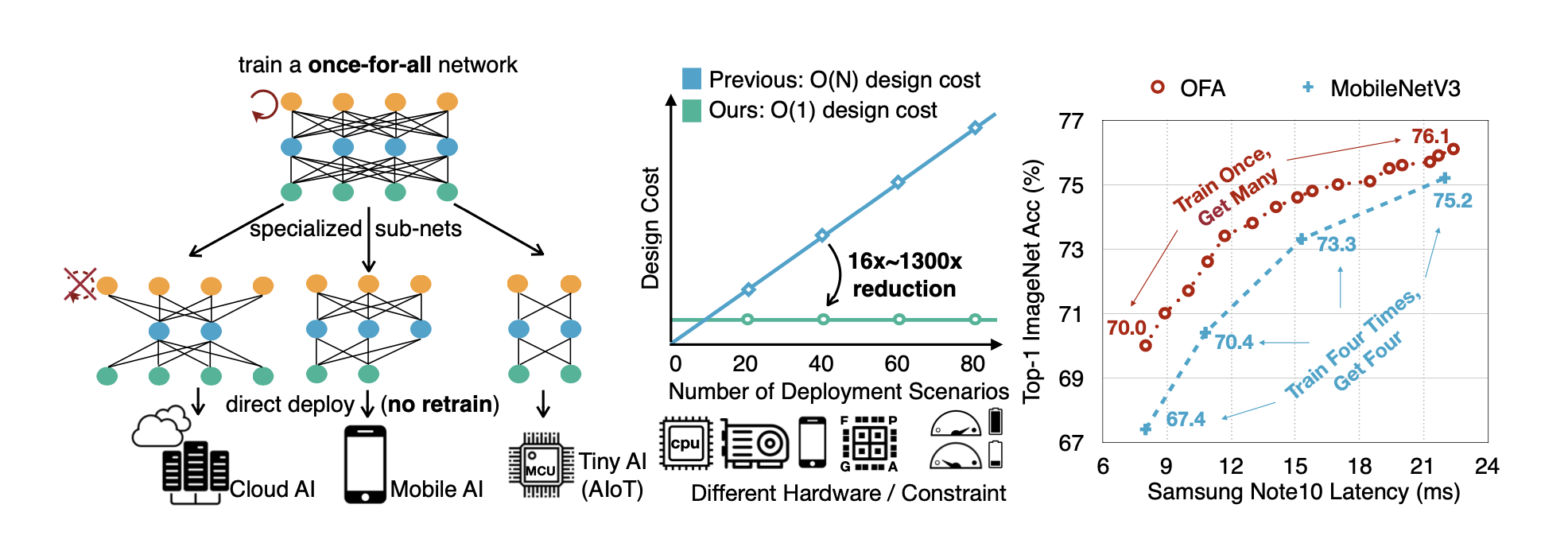
Once for All: Overview
Once for All: Challenges
- Training the superNet is non-trivial: Requires joint-optimization of weights of \( 10^{19} \) subnetworks to maintain its accuracy
- Computationally expensive to enumerate all possible sub-networks to get exact gradient-update in each step
- Different sub-networks interfere with each other making the superNet training infinitely harder
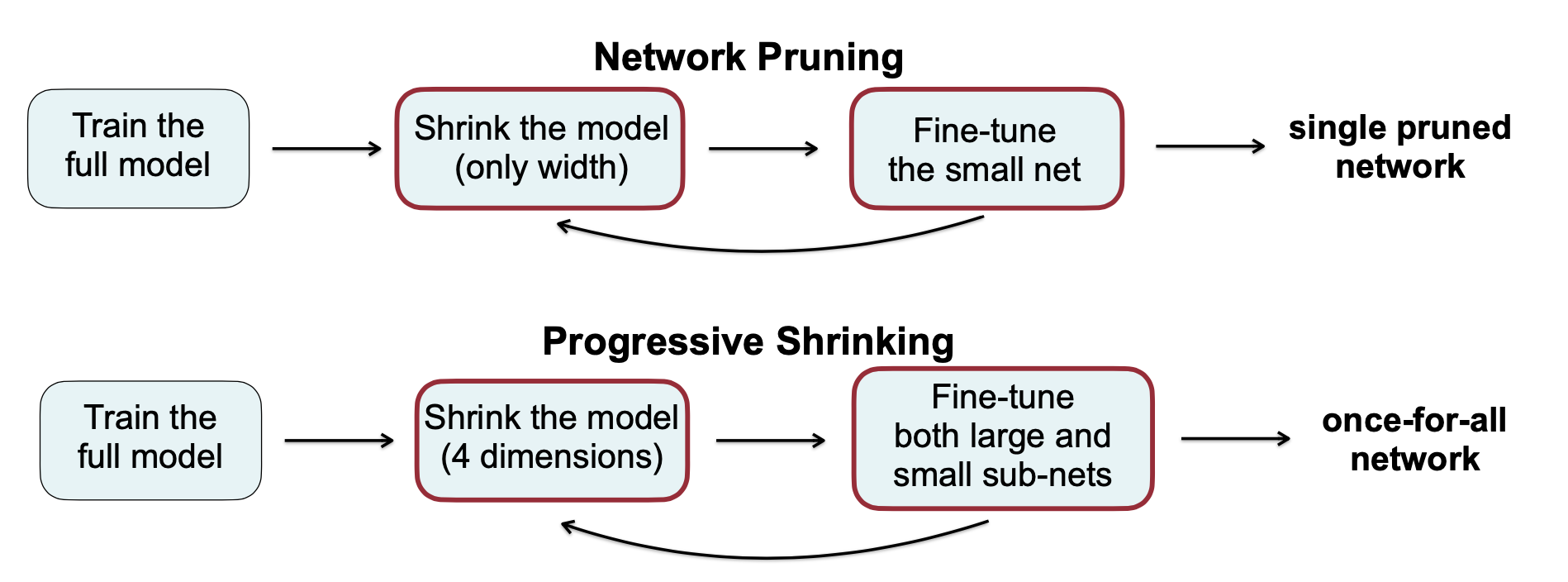
- Solution: Progressive Shrinking Algorithm
Progressive Shrinking: Overview
- Instead of optimizing all subnetworks in one-shot, OFA trains the largest superNetwork first
- Then, it progressively fine-tunes smaller architectures to support smaller sub-networks that share the weights with the largest trained network
- This fine-tuning can be along the axes of resolution, depth, width and kernel-size
Problem Formalization
\( \min_{w_0} \sum_{arch_i} L_{val} ( C(W_0, arch_i)) \)
The overall objective is to optimize \( W_o \) to make each supported sub-network maintain the same accuracy as independently training the network
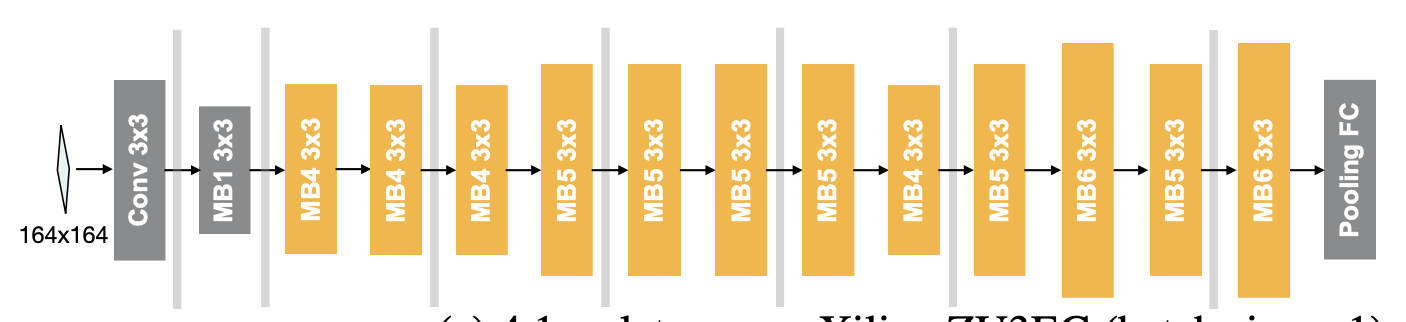
Architecture Space
Units
Gradually reducing feature size and increasing channel numbers
Arbitrary depth, width and kernel size
Depth: {2,3,4}
Ex.Ratio: {3,4,6},
Kern Size: {3,5,7}
\( 2 \times 10^{19} \)

Training the Once-for-all network
- Naive Approaches
- It can be viewed as a multi-objective problem where each objective corresponds to one sub-network. Prohibitive
- Sample few sub-networks in each backward step and update them rather than enumerate all of them. Significant accuracy drop
-
Progressive Shrinking
- To prevent interference between sub-networks, enforce a training order from large sub-networks to small sub-networks
- PS allows initializing small sub-networks with the most important weights of well-trained large sub-networks, which expedites the training process
Training the Once-for-all network
- Progressive Shrinking

Training the Once-for-all network
- Progressive Shrinking

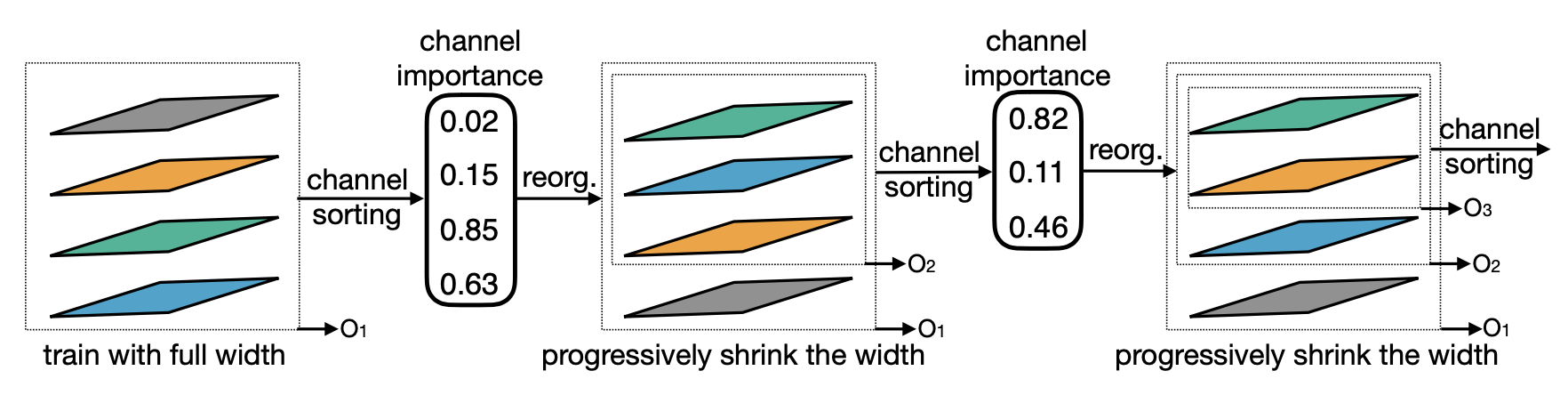
706 extra parameters per layer
Results Once-for-all network

Results Once-for-all network

Results Once-for-all Comparisions

Results Once-for-all Comparisions

Results Once-for-all network Co-Designed Solutions

Results Once-for-all network Co-Designed Solutions

deck
By Vinod Ganesan




