Leave a comment
Meta conditional tweet evaluation
Deductive team
Jaan Ugrinsky, Nargizahon Abduvaliyeva, Nikita Jerschov and Lucas Vogel
FH Potsdam, Sommersemester 2016
Betreut von
Prof. Dr. Marian Dörk, Prof. Dr. Tobias Schröder und Prof. Marion Godau

Die Annahme
1.
Beiträge auf Twitter besitzen Twitter- und Kontext/Diskurs-spezifische Eigenheiten - in ihrer Struktur und in der Form ihres Inhaltes - die sie kategorisierbar machen.
2.
Diese Twitter-spezifischen Eigenheiten lassen es zu, mit Hilfe von Computern und später machine-learning, große Mengen von Beiträgen zu analysieren.
Herangehensweise
Intuition als Inspiration
Wir nutzten die eigene Intuition um in den kurzen Texten interessante Muster und Zusammenhänge zu identifizieren.
Diese versuchten wir in Filter zu übersetzen, die der Computer auf eine große Menge von Diskurs-Beiträgen anwenden kann.
Bearbeitung
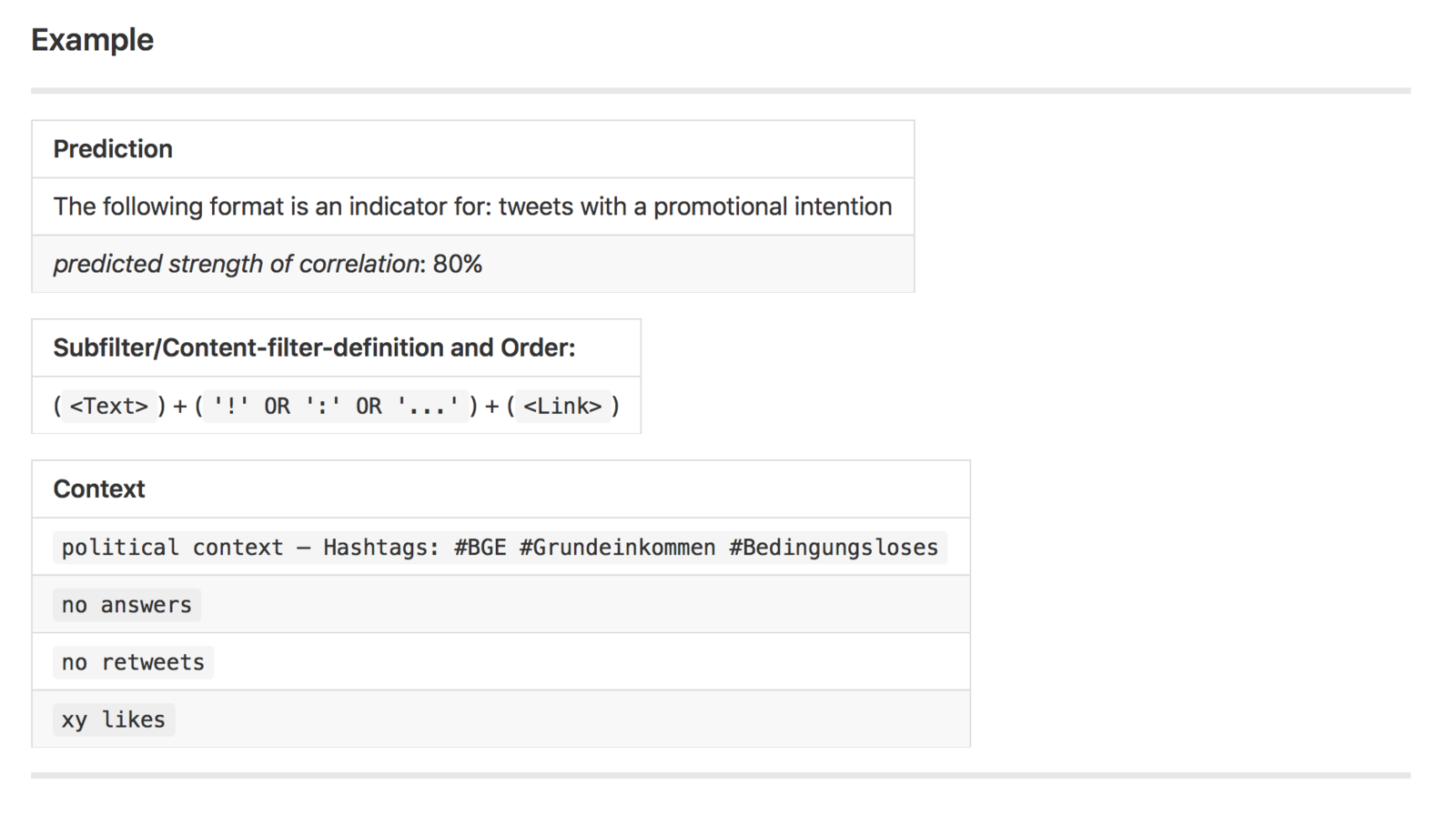
Die Thesen
Diese waren ein Zwischenschritt bei dem die intuitiven Interpretationen möglichst präzise und unter bestimmten Kriterien beschrieben wurden
Die Filter
Es war die Idee im nächsten Schritt (auch im Sinne einer Arbeitsteilung) diese Thesen in Code zu übersetzen
Thesen
Technische Umsetzung
Wir nutzten Node.js, die Twitter API und MongoDB um die Tweets zu bekommen, zu speichern und zu verarbeiten.
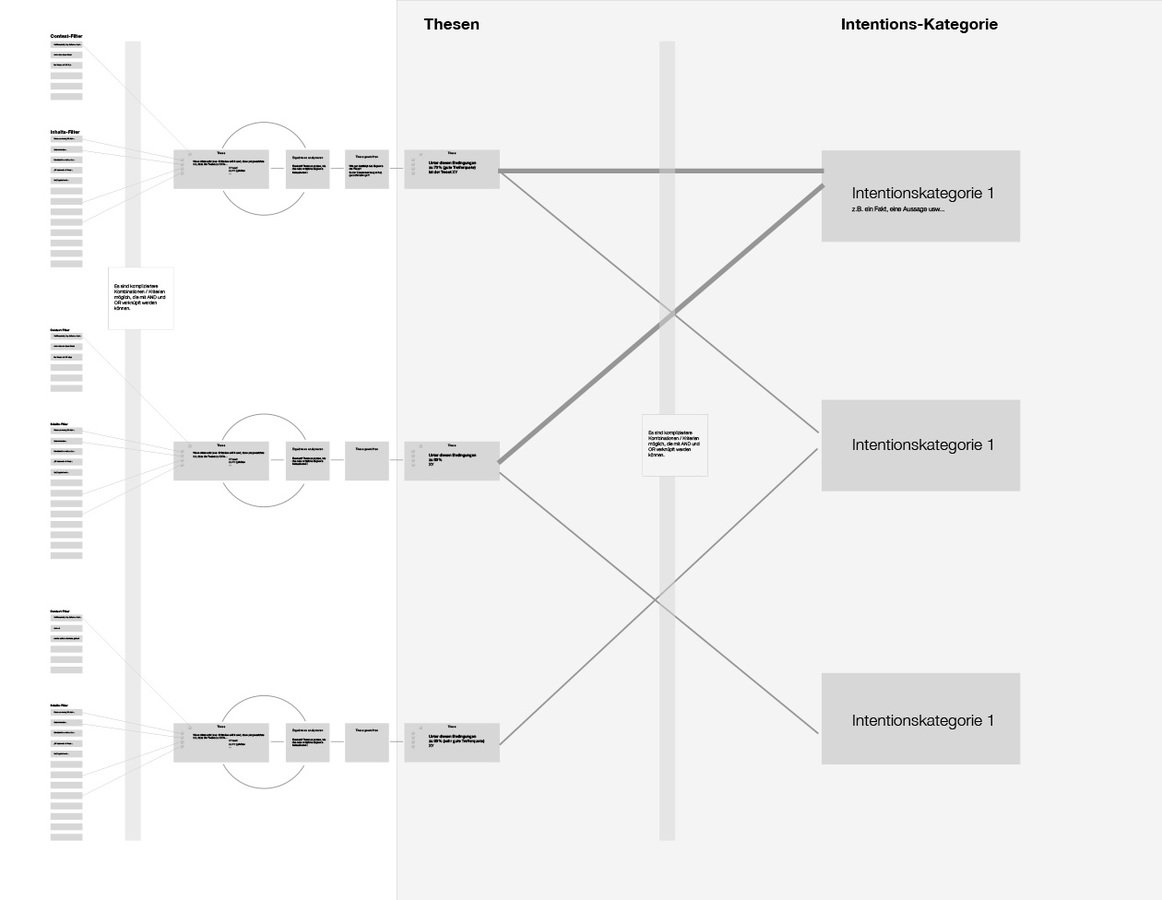
Desweiteren haben wir eine theoretische Projekt-Struktur angedacht, die eine modulare Herangehensweise vorschlägt um den aufwändigen Prozess - die Thesen/Filter aktuell zu halten oder zu erweitern - zu crowdsourcen.
Projekt-Struktur/Flow
Die Ergebnisse
Wir haben ein Set von zufälligen 1000+ Tweets händisch in die zwei Kategorien "promotional" und "opinion" eingeteilt.
Wir haben dann zum Vergleich einen ersten Prototypen programmiert, der einige unserer extrahierten Thesen auf dieselben Tweets anwendet.
Anschließend haben wir die beiden Ergebnisse Verglichen.
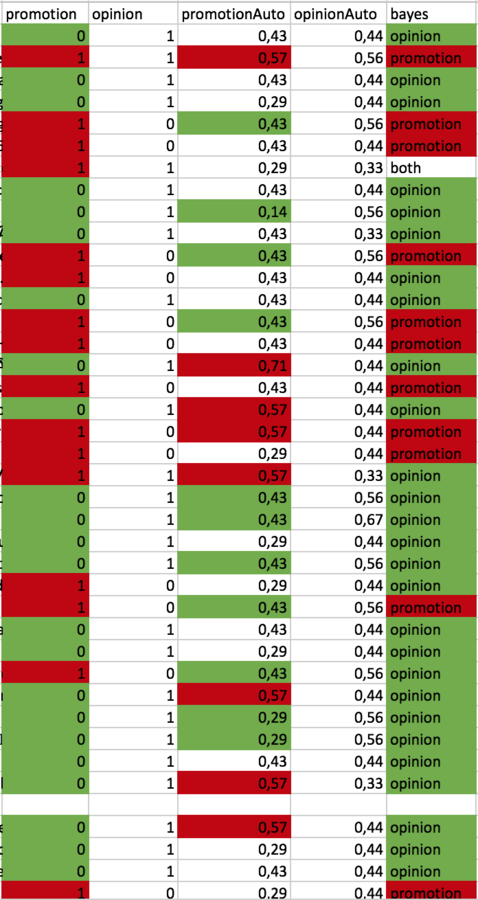
Vergleich
Hier sieht man einmal links die menschliche Einschätzung, dann die Einschätzung unseres Algorythmus und ganz rechts die Ergebnisse eines trainierten Bayes-Verfahren.
Die Ergebnisse
48 %
Erfolgsquote
Promotion: 55 %
Opinion: 42 %
Vorsicht Manipulation!
Stand
Die Ergebnisse sind mehr als exemplarische Machbarkeitsstudie zu verstehen. Viele der theoretisch angedachten Konzepte und Definitionen konnten aus zeitlichen und technischen Gründen nicht umgesetzt werden.
Auch das Datenset ist ein Dummy-Datenset aus zufälligen Twitter-Tweets. In dem theoretischen Konzept sind die Thesen jedoch z.T. Diskurs/Hashtag-Abhängig um bessere Aussagen treffen zu können.
Wie kann es weitergehen?
Wie man bereits in der Vergleichstabelle sehen kann, wäre eine solche Gegenüberstellung mit ausdefinierten Thesen/Filtern und einem Diskurs-spezifischen Datenset sehr interessant.
Auch können wir uns eine Integration des Bayes-Verfahren vorstellen. Eine Verquickung der Ergebnisse unserer Twitter-spezifischen Eigenheiten mit der Trainierbarkeit des Bayes-Verfahrens wäre hoch spannend.
Vielen Dank!
https://github.com/FH-Potsdam/leaveacomment/tree/master/deductive
https://github.com/FH-Potsdam/leaveacomment-deductive-proof-of-concept
Mehr auf:
Leave a commentLeave a comment
By Lucas Vogel



