PUBG Fortune Teller
吳易倫 李政諺
Motivation
- Compare with friends
- Discover talent
- Improve gaming ability
Data collection


Sample nicknames of players
PUBG official API
Third party API
User status Database
Query resource id of player
Get stats of each player per month
Data collection
| Solo(單排) | Duo(雙排) | Squad(四排) | |
| TPP(第三人稱) | Solo-TPP | Duo-TPP | Squad-TPP |
| FPP(第一人稱) | Solo-FPP | Duo-FPP | Squad-FPP |
Data collection
| Sample | Query id | Get stats | |
|---|---|---|---|
| # of players | 70000 | 43000 | 22000 |
| May | Mar, Apr | ... | May, Apr...Jan | |
|---|---|---|---|---|
| # of players | 19000 | ~19000 | ... | 12659 |
# of players who have played more than 5 matchs
# of players at each step
Data collection
| Attribute Name | Description | Mean |
|---|---|---|
| damage_dealt_avg | 每場平均傷害量 | 122.16 |
| kills_sum | 擊殺數量 | 71.05 |
| matches_cnt | 總場數 | 81.16 |
| topten_cnt | 前10名場數 | 8.13 |
| assists_sum | 協助擊殺 | 5.11 |
| headshot_kills_sum | 爆頭總數 | 15.03 |
| time_survived_avg | 每場平均存活時間 | 715.34 |
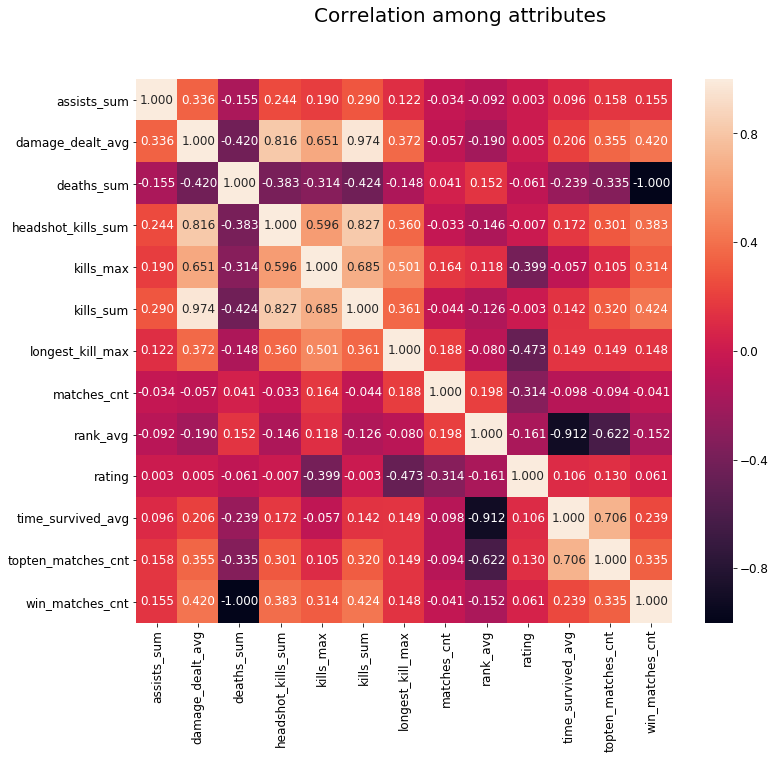
Correlation among attributes
Problem Formulation
-
Input: a sequence of stats in the previous months
-
Output: damage_dealt_avg in next few months
Models
- Lasso
- Linear Regression
- DNN
- LSTM+DNN
- AutoEncoder+DNN
- Lasso
- Linear Regression
- DNN
- LSTM+DNN
- AutoEncoder+DNN
Lasso
Least Absolute Shrinkage and Selection Operator
{1\over 2}\Vert y-XW\Vert_2^2+\alpha\Vert W\Vert_1^1+\gamma\sum_{t=1}^{m-1}\Vert w_{t+1}-w_t\Vert
- The optimization objective for Lasso is:
X:=\text{input stats matrix},X\in R^{N\times n}
n:=\text{the size of concatenated stats vector},n\in N
m:=\text{the number of
forecast value}, m\in N
y:=\text{target label matrix},y\in R^{N\times m}
W:=\text{weighting matrix},W\in R^{n\times m}
W=[w_1,w_2,...,w_m],w_i\in R^{n\times 1}
N:=\text{the size of training data}
Lasso
The characteristics of objective function:
- L1 penalty
- Reduce training time
- Robust
- feature selection
- L2 penalty
- Stable
{1\over 2}\Vert y-XW\Vert_2^2+\alpha\Vert W\Vert_1^1+\gamma\sum_{i=1}^{n-1}\Vert w_{i+1}-w_i\Vert_1^1
Lasso
The third term is useless
{1\over 2}\Vert y-XW\Vert_2^2+\alpha\Vert W\Vert_1^1+\gamma\sum_{i=1}^{n-1}\Vert w_{i+1}-w_i\Vert_1^1
NN models
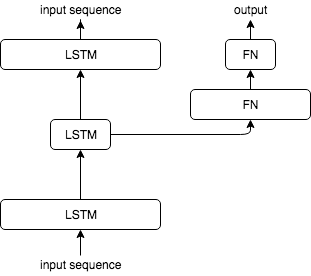
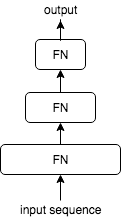
DNN
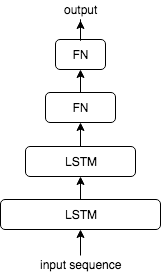
LSTM+DNN
LSTM-Autoencoder+DNN
Results:single target
| Model | MSE | Baseline |
|---|---|---|
| Lasso | 4067 | 5987 |
| Linear Regression | 4088 | 5987 |
| DNN | 4402 | 5987 |
| LSTM+DNN | 4417 | 5987 |
| LSTM-Autoencoder+DNN | 4460 | 5987 |
Train input: 1, 2, 3 Train output: 4
Test input: 2, 3, 4 Test output: 5
Results:single target
| Train input | Train output | Test input | Test output | MSE | Baseline |
|---|---|---|---|---|---|
| 1 | 2 | 2 | 3 | 4044 | 5751 |
| 2 | 3 | 3 | 4 | 3855 | 5470 |
| 1,2 | 3 | 2,3 | 4 | 3783 | 5471 |
| 3 | 4 | 4 | 5 | 4468 | 5987 |
| 2,3 | 4 | 3,4 | 5 | 4177 | 5987 |
| 1,2,3 | 4 | 2,3,4 | 5 | 4067 | 5987 |
Lasso
Results
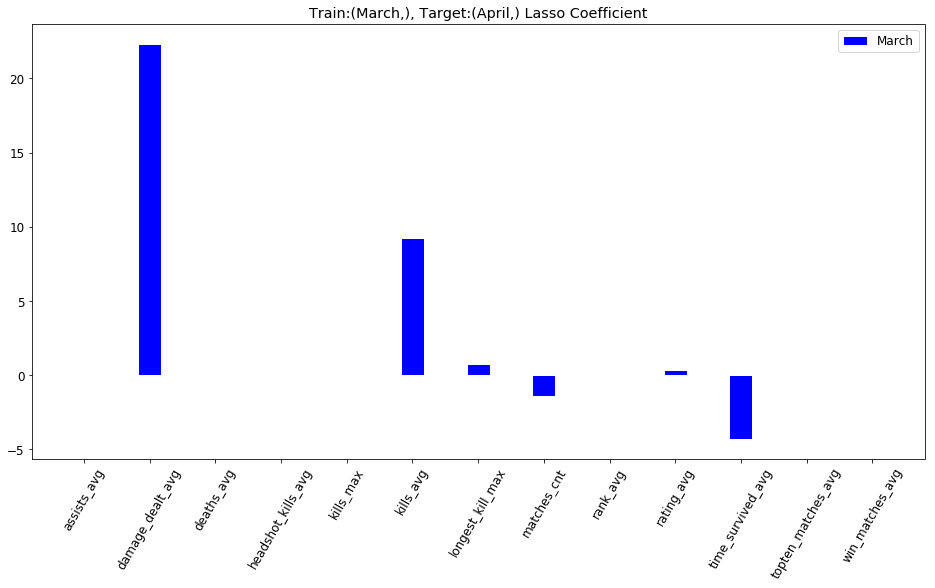
damage_dealt_avg
kills_avg
time_survived_avg
Results
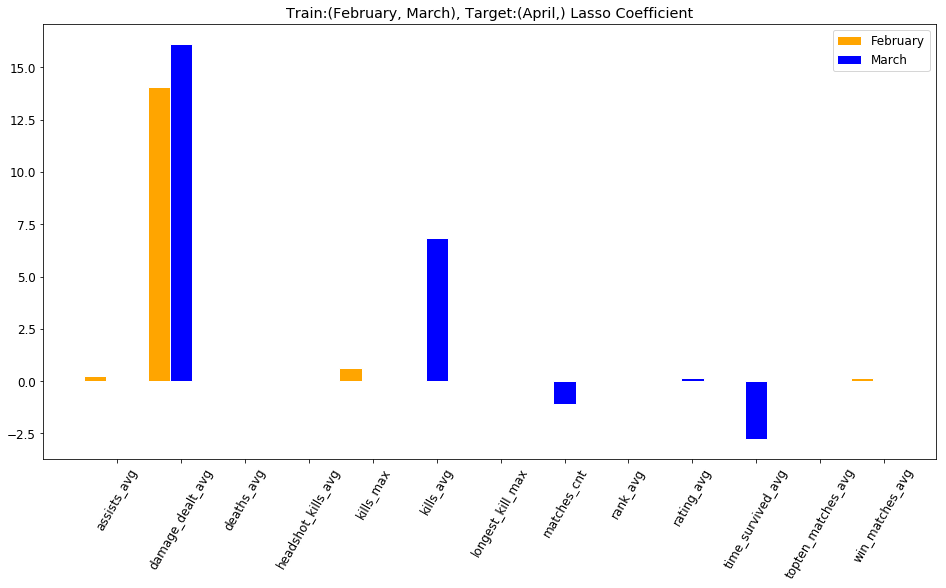
damage_dealt_avg
kills_avg
time_survived_avg
Results
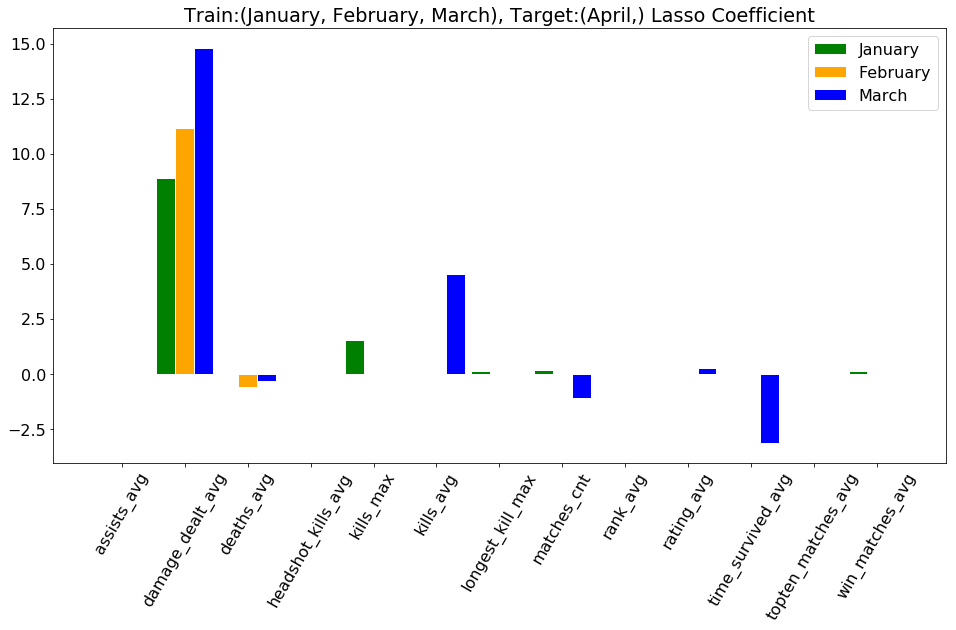
damage_dealt_avg
kills_avg
time_survived_avg
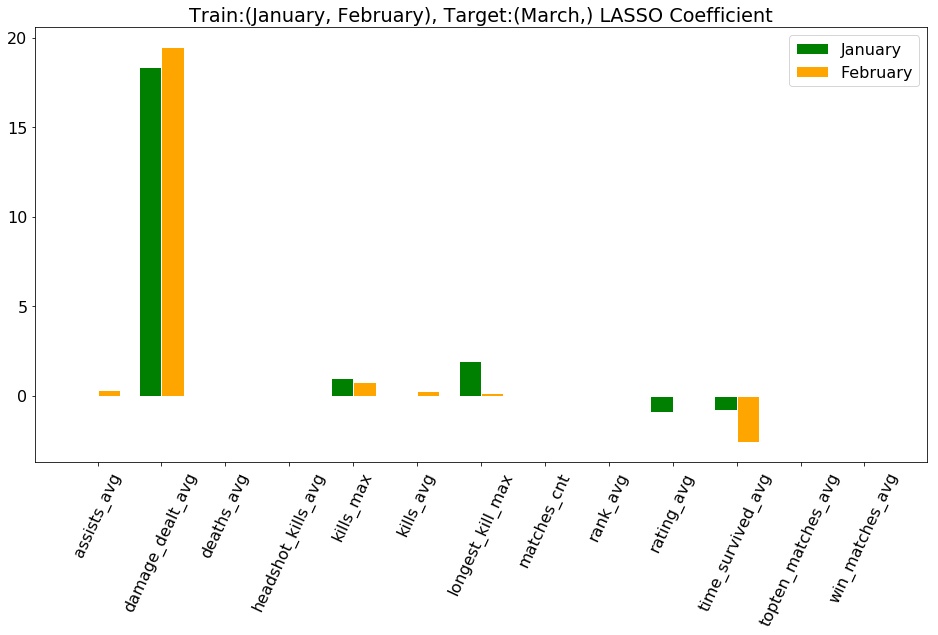
Results:Multi-target
| Train input | Train output | Test input | Test output | MSE | Baseline |
|---|---|---|---|---|---|
| 2 | 3,4 | 3 | 4,5 | 4148 | 5825 |
| 1,2 | 3,4 | 2,3 | 4,5 | 4122 | 5825 |
Results:Multi-target
Results:Multi-target
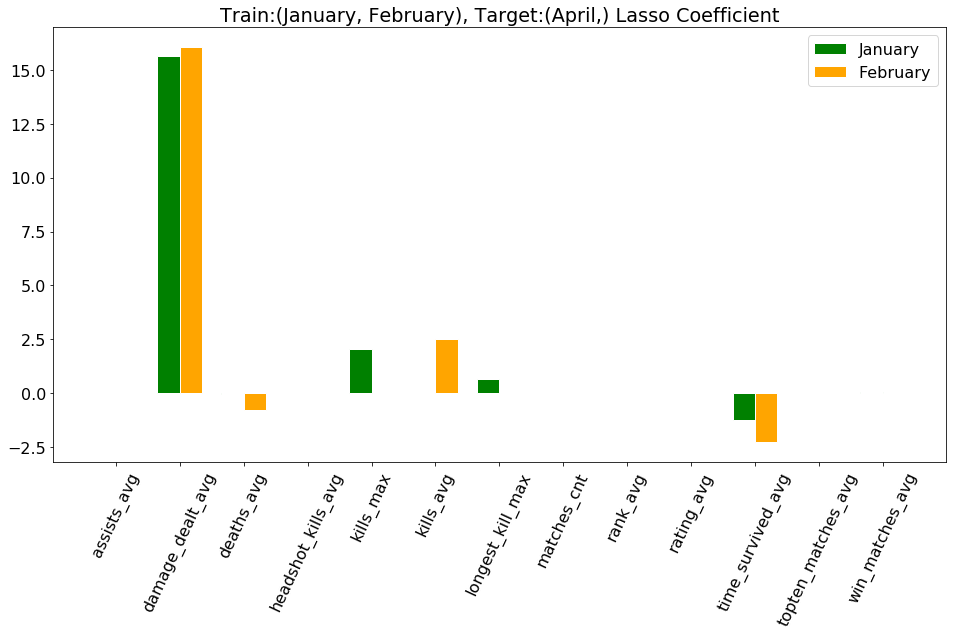
Future Work
- Collect more data
- Recommend teammates
Charts
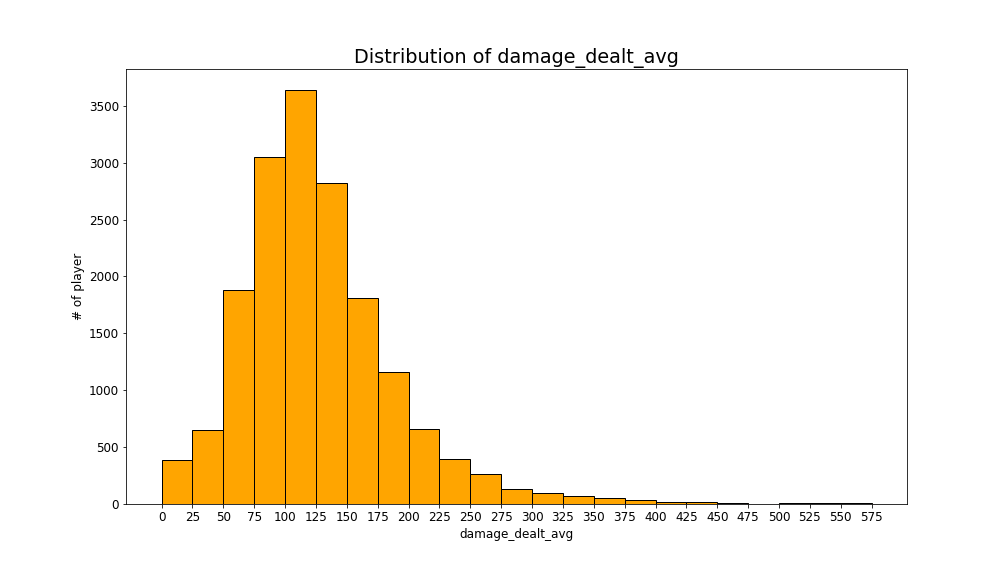
Charts
PUBG Fortune Teller
By w86763777



